動態場景下基于YOLOv5和幾何約束的視覺SLAM算法
2024-02-22 03:44:10王鴻宇吳岳忠陳玲姣陳茜
包裝工程 2024年3期
王鴻宇,吳岳忠,2*,陳玲姣,陳茜
動態場景下基于YOLOv5和幾何約束的視覺SLAM算法
王鴻宇1,吳岳忠1,2*,陳玲姣1,陳茜1
(1.湖南工業大學 軌道交通學院,湖南 株洲 412007; 2.湖南省智能信息感知及處理技術重點實驗室,湖南 株洲 412007)
移動智能體在執行同步定位與地圖構建(Simultaneous Localization and Mapping,SLAM)的復雜任務時,動態物體的干擾會導致特征點間的關聯減弱,系統定位精度下降,為此提出一種面向室內動態場景下基于YOLOv5和幾何約束的視覺SLAM算法。首先,以YOLOv5s為基礎,將原有的CSPDarknet主干網絡替換成輕量級的MobileNetV3網絡,可以減少參數、加快運行速度,同時與ORB-SLAM2系統相結合,在提取ORB特征點的同時獲取語義信息,并剔除先驗的動態特征點。然后,結合光流法和對極幾何約束對可能殘存的動態特征點進一步剔除。最后,僅用靜態特征點對相機位姿進行估計。在TUM數據集上的實驗結果表明,與ORB-SLAM2相比,在高動態序列下的ATE和RPE都減少了90%以上,與DS-SLAM、Dyna-SLAM同類型系統相比,在保證定位精度和魯棒性的同時,跟蹤線程中處理一幀圖像平均只需28.26 ms。該算法能夠有效降低動態物體對實時SLAM過程造成的干擾,為實現更加智能化、自動化的包裝流程提供了可能。
視覺SLAM;動態場景;目標檢測;光流法;對極幾何約束
視覺SLAM(Simultaneous Localization and Mapping)技術在包裝行業的應用日益廣泛,其通過分析相機捕獲的圖像信息,實現對環境的實時感知和三維重建。例如,在自動化包裝生產線上,運用視覺SLAM技術能夠使機器人精準辨認并定位包裝盒,從而精確執行抓取、搬運和擺放的任務。這不僅大幅提高了包裝的效率,同時確保了作業的精準度,降低了對人工的依賴。視覺SLAM在應對復雜和動態變化的包裝環境時展現出其獨特優勢,能夠實時更新地圖信息以適應環境變化,確保定位精度。例如,在處理不同大小和形狀商品的包裝任務時,視覺SLAM能夠協助機器人迅速適應新任務,避免了重新設定程序的繁瑣過程。
隨著計算機圖形算力的不斷提高,大量優秀的視覺SLAM算法被相繼提出[1],主要分為如PTAM[2](Parallel Tracking and Mapping)、ORB-SLAM2[3]的特征點法和DSO[4](Direct Sparse Odometry)、D3VO[5](Deep Direct Dense Visual Odometry)的直接法2類。然而,上述視覺SLAM算法均假設在靜態環境下運行,但在實際場景下會出現實時運動的行人和車輛(高動態物體)和臨時移動的物品(低動態物體),致使假設并不成立。
針對上述問題,國內外學者的方法主要分為2種。一種是基于幾何的傳統算法,Dai等[6]使用Delaunay三角剖分來為地圖中的點構建圖狀結構,以識別它們的鄰近性。接著移除在多個關鍵幀中有差異的邊緣,最終實現動態物和靜態背景的區分。張有全等[7]提出了一種緊耦合的視覺慣性SLAM系統,該系統采用了直接法和共視圖優化。在跟蹤線程中,結合IMU信息和基于稀疏圖像對齊的直接法來進行初始位姿的估計。雖然依靠幾何算法能在一定程度上提高定位精度,但當場景中存在較多弱紋理區域、光照強度變化時,系統性能就會明顯下降,甚至失效。另一種是隨著深度學習在計算機視覺領域中不斷取得突破性的成果,基于目標檢測、語義分割等深度學習方法對特征點做先驗語義信息標注,與傳統視覺SLAM結合以剔除動態物體的特征點[8]。Zhong等[9]提出了基于目標檢測網絡SSD[10]的Detect-SLAM系統,只檢測ORB-SLAM關鍵幀中的運動對象,利用語義信息并通過一種實時傳播關鍵點運動概率的方法剔除動態特征點。Yu等[11]提出了DS-SLAM系統,該系統在ORB-SLAM2的基礎上結合SegNet[12]實時語義分割網絡與運動一致性檢測,可以有效降低動態環境中行人的影響。同樣,在ORB-SLAM2基礎上Bescos等[13]提出了DynaSLAM系統,通過神經網絡Mask R-CNN[14]分割具有先驗信息的動態目標,再利用多視圖幾何分割潛在的動態特征點,但是算力和功耗要求高,實時性較差。Yan等[15]提出一種結合幾何信息和語義信息的DGS-SLAM系統,設計了一種語義關鍵幀選擇策略對ORB關鍵幀與語義關鍵幀區分,同時融合幾何與語義(YOLACT)先驗殘差對運動目標進行檢測。
本文在ORB-SLAM2的基礎框架上進行改進,主要改進和創新如下。
1)添加了一條新的動態目標檢測線程,用輕量級的MobileNetV3網絡替換YOLOv5s原有的主干網絡,并將目標檢測提取到的場景語義信息和ORB特征點相結合獲取圖像信息,利用目標檢測算法預測先驗的動態區域并剔除其中的動態特征點。
2)提出一種動態特征點剔除策略,首先剔除被先驗語義信息標注的動態特征點,然后,結合光流法和對極幾何約束對可能殘存的動態特征點進一步剔除。
1 系統概述
1.1 系統框架
ORB-SLAM2系統的良好性能是基于靜態場景的假設,實際場景中,動態物體會直接影響特征點間的關聯匹配,導致建圖時出現“鬼影”等現象。因此,本文在原有ORB-SLAM2系統的視覺里程計中,添加了目標檢測線程和剔除動態特征點模塊。改進后的系統框架如圖1所示,利用輕量級的目標檢測網絡YOLOv5s-MobileNetV3檢測圖像序列中的運動目標并獲取語義信息,在視覺里程計中提取到ORB特征點的同時根據語義信息剔除先驗的動態特征點。由于環境中可能會存在潛在的動態物體以及運動模糊的對象,而出現被目標檢測網絡漏檢的情況。因此,在完成相鄰2幀的待定靜態特征點匹配后,利用RANSAC算法得到兩圖像間的基礎矩陣。然后結合對極幾何約束和金字塔LK光流法對可能殘存的動態特征點進一步剔除[16]。最后,僅用剩余的靜態特征點對相機位姿進行估計。
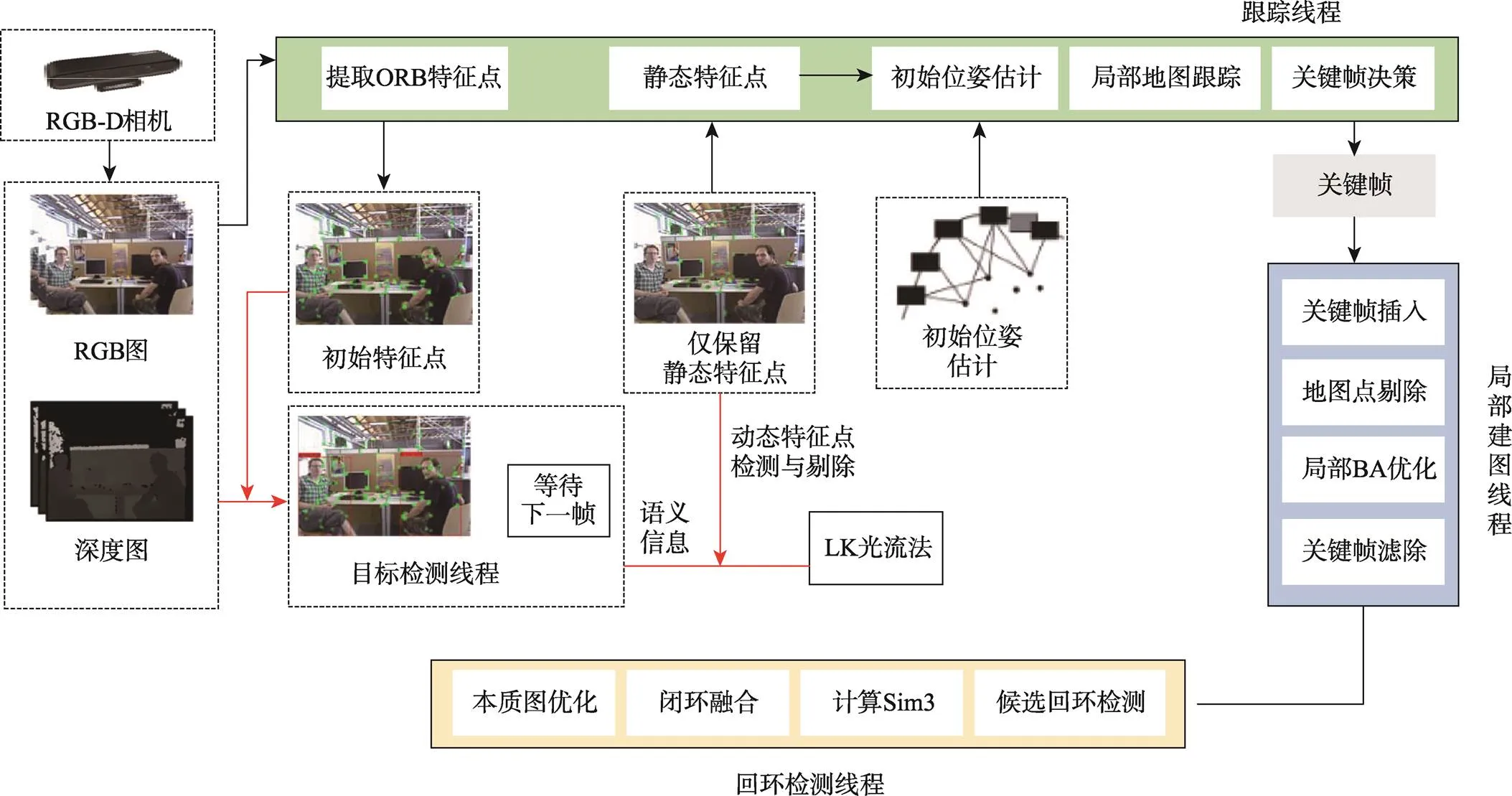
圖1 改進后的系統框架
1.2 輕量級目標檢測網絡YOLOv5s- MobileNetV3
YOLOv5是當前較為先進的單階段目標檢測算法之一。相較于YOLOv4擁有更好的增強方式,相較于當前最新的YOLOv7和YOLOv8,訓練和推理速度也要快很多,其具有較低的內存占用和泛化能力強的優勢。這使得YOLOv5在移動設備或者資源受限的系統中更具優勢。因此,選擇YOLOv5作為本文的目標檢測網絡是合理的選擇。YOLOv5s的模型參數量約為7.5 M,是YOLOv5系列當中模型最小、運行速度最快的網絡,在NVIDIA V100 GPU上,平均每張圖片的推理時間僅為0.002 s,滿足實時處理的標準[17]。
MobileNet神經網絡結合了逐深度卷積(Depthwise,DW)和逐點卷積(Pointwise,PW),形成了深度可分離卷積(Depthwise Separable Convolution,DSC),使能夠構建并訓練小型網絡模型。相較于常規卷積,它在確保準確性的前提下,運算時間縮短約11%,模型參數也減少約14%。MobileNetV3[18]由Google在2019年提出,與V1和V2相比,其在精度、推理速度、模型結構等方面上都得到有效提升,網絡結構如圖2所示。考慮到本文更傾向于輕量化卷積網絡模型,因此將YOLOv5s的Backbone用MobileNetV3-Small替代,并調整了各層的特征圖使其對齊。YOLOv5s的Neck需要3種尺度的特征圖,它們分別來自3-P3/8、8-P4/16和11-P5/32,如圖3所示。
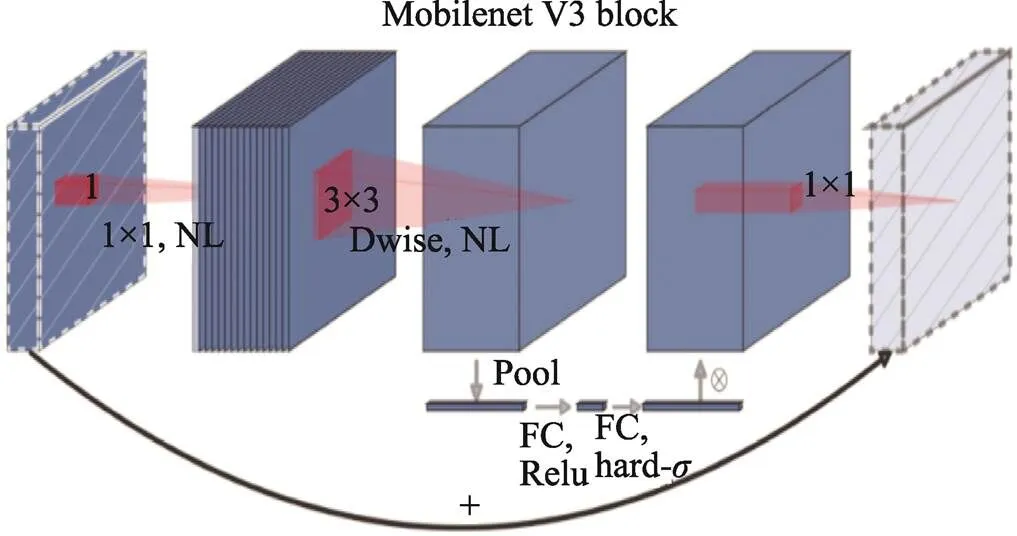
圖2 MobileNetV3的網絡結構

圖3 對Backbone的改進
1.3 動態特征點剔除策略
1.3.1 先驗動態區域特征點剔除
在經過目標檢測線程確定動態特征點后,先剔除動態物體范圍內的特征點,具體剔除過程:假設跟蹤線程中提取到第幀圖像的特征點集合A,如式(1)所示。
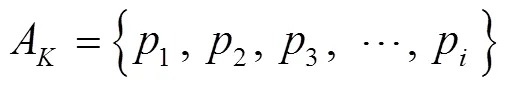
然后基于先驗知識確定動態特征點的集合D,如式(2)所示。
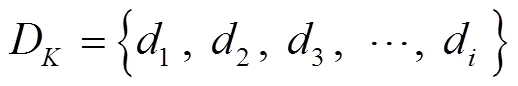
如果滿足以式(3)條件,則將P標記為動態特征點,并將其從集合A中剔除,剩下的特征點視為準靜態特征點,它們集合記為S,如式(4)所示。
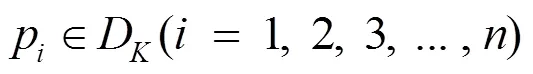
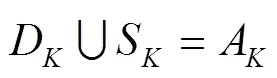
實際環境中還可能存在以下特殊情況:除了提前視為動態物體的“人、貓、狗”,還可能忽略“隨手拿起翻閱的書本”和“使用電腦需要移動的鼠標”等潛在動態物體,只有在其他外在因素作用下才會被視為動態物體;現實中的動態物體往往是不規則的形狀,而目標檢測網絡的預測框則是規則的矩形區域,這樣會使動態物體周圍原本的靜態特征點被暴力剔除,甚至導致后續特征點匹配時出現跟蹤丟失。因此,還需要結合對極幾何約束和LK光流法再次進行剔除,在剔除動態特征點的前提下,盡可能保留較多的靜態特征點。
1.3.2 對極幾何約束
在基于目標檢測線程剔除動態特征點后,需要對當前幀和參考幀的準靜態特征點進行特征匹配,以計算兩特征點之間的漢明距離得到匹配點對,取升序排列前1/3的點對通過RANSAC算法求解出基礎矩陣。具體計算過程如下:如圖4所示,1和2為來自同一相機的連續2幀圖像,1和2則是一對特征匹配點,1和2為是相機的中心,點是11和22的交點,11和22則是各幀極線,極線求解過程如式(5)~(7)所示。
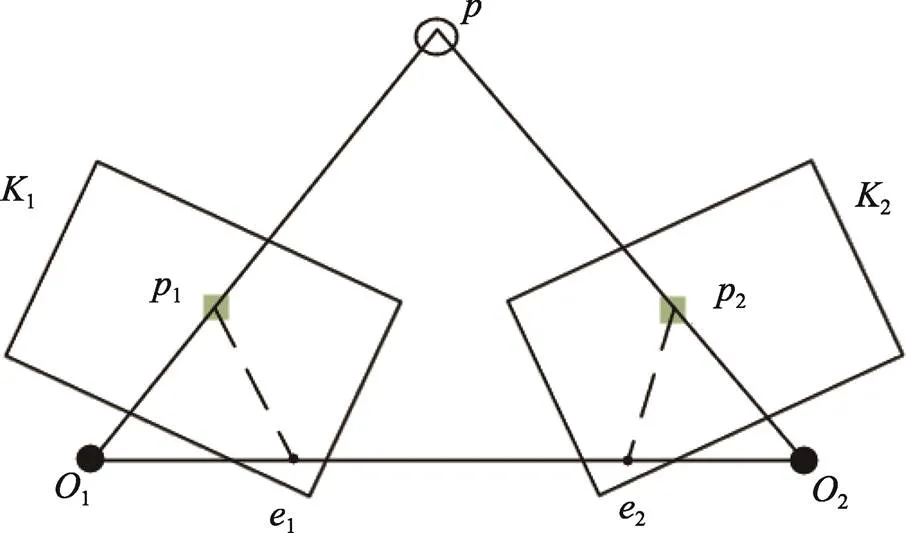
圖4 對極幾何約束示意圖
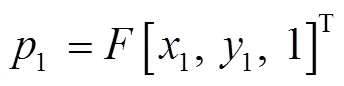

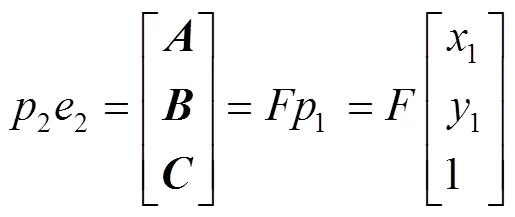
式中:、、為線向量。點2與對應極線之間的距離如式(8)所示。
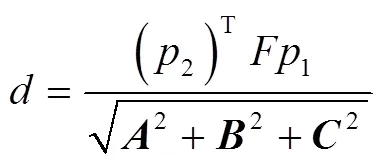
將準靜態特征點到極線的距離與設定好的閾值范圍ε比較。如果超出閾值范圍,則被視為動態特征點被剔除,本文實驗部分ε取[0.3, 0.7]。若出現物體的運動方向與相機平行,也能滿足對極幾何約束的條件,因此本文選擇LK光流法對動態特征點做進一步剔除。
1.3.3 LK光流法
光流法基于圖像序列中像素在時間上的變化和相鄰幀的關系來分析前后幀間的匹配,從而獲取物體的運動數據。這里選擇計算量較稠密光流少的LK光流法,如圖5所示。該方法基于3個假設:(1)灰度不變,圖像中相同位置的像素灰度在每幀圖像中不改變;(2)小運動,相鄰幀之間的位移是較小的;(3)空間一致,相鄰像素具有相似的運動[19]。從假設(1)可知在灰度不變時,有:
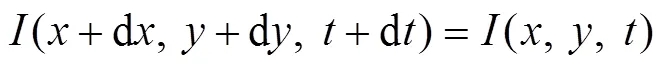
式中:和d為相鄰幀的對應時間;(,,)和(d,d,d)是像素點在相鄰幀中的位置。從假設(2)對式(9)左側進行泰勒級數展開,保留一階項,得到:
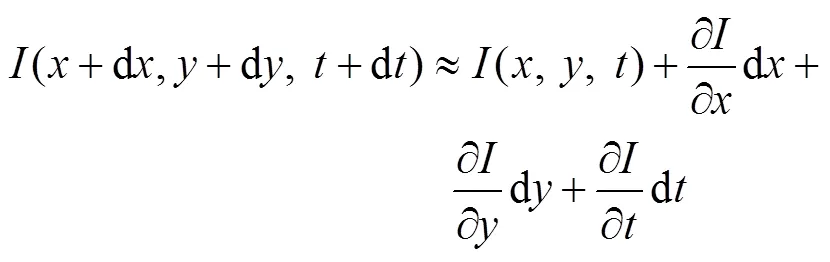
將式(9)和(10)相加,兩邊同時除以d,得到:
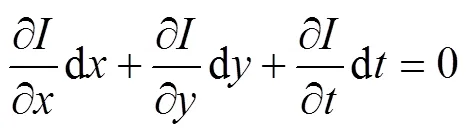
式中:d/d和d/d分別為像素在和軸上的運動速度,記為、。同時/和/則是圖像在該點和方向的梯度,記為I、I。圖像灰度隨時間的變化量記為I,有:
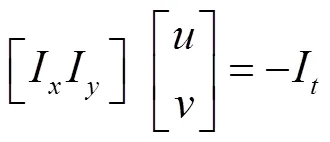
由于計算的是像素的運動,所以引入額外的約束來計算。根據假設(3),選擇3×3窗口內9個具有同樣的運動的像素點,有:
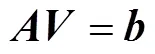
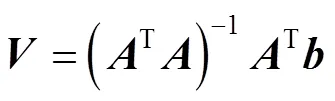
通過LK光流法求得剩余特征點的光流大小后,計算其平均值與標準差,通過式(16)~(17)判斷特征點是否為動態點。
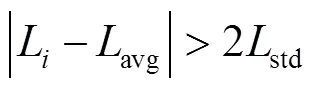
或
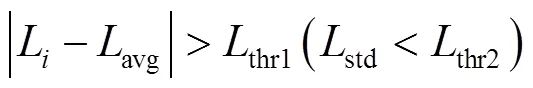
式中:L為第個特征點的光流大小;avg、std分別為各特征點光流大小的平均值和標準差;thr1和thr2為設定的閾值。當L滿足上述關系時,則認為是動態特征點并剔除。
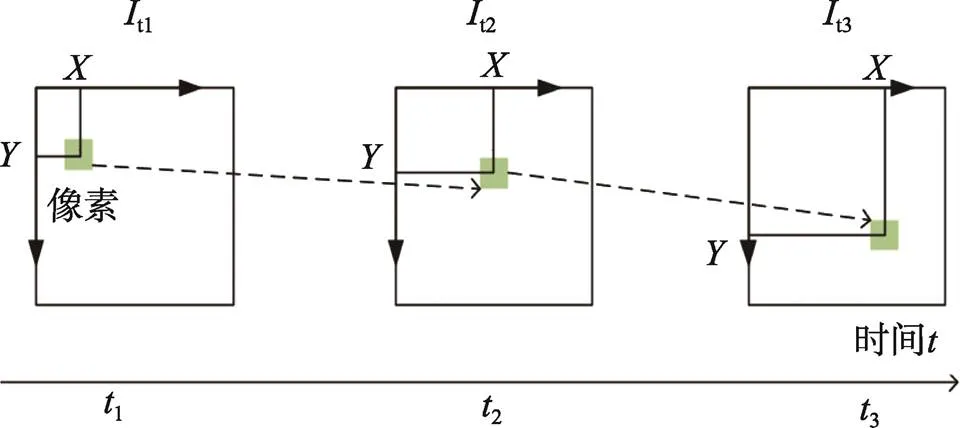
圖5 LK光流法示意圖
2 實驗結果與分析
2.1 輕量化目標檢測算法實驗
本實驗選取COCO數據集對改進后的輕量化目標檢測網絡YOLOv5s進行驗證。COCO數據集涵蓋了80個目標類別,考慮到本文算法應用場景主要是室內動態環境,因此針對性地將“人、貓、狗”類別的數據集進行實驗驗證,其余類別暫定是靜態對象。經過訓練后,輕量化的目標檢測網絡YOLOv5s-MobileNetV3與其余的YOLOv5不同版本在CPU上的驗證結果如表1所示。其中,mAP@0.5指在閾值0.5處設置的IOU(交并比)的平均精度均值(Mean Average Precision, mAP)。因為在目標檢測中,當預測框與真實框的IOU值大于0.5時,通常認為檢測結果是正確的,mAP值越高,說明模型的性能越好。
從表1可以看出,與原有的YOLO5s算法對比,在替換原有的主干網絡后,算力要求降低至6.2GFLPOS,模型參數量降低至3.8M。雖然MAP降低了2.3%,但是檢測速度提高了27幀/s。在犧牲了一小部分精度的同時,提高了運行速度。因此,可以滿足輕量化目標檢測算法在資源受限的設備上對精度和實時性的要求。
2.2 TUM數據集
本文采用公開數據集TUM RGB-D對改進后ORB-SLAM2算法做整體性能評估。它包含在室內場景中采集到的RGB 圖像、深度圖像及位姿真實值等內容,常被學者用來做SLAM算法的評估。選取TUM數據集中5個不同序列進行測試,分別是fr3_walking_xyz、fr3_walking_static、fr3_walking_rpy、fr3_walking_halfsphere和 fr3_sitting_static。其中,前4組的fr3_walking屬于高動態場景,表示2個人在桌子周圍進行走動并伴隨著坐立之間的姿態轉換;第5組的fr3_ sitting表示2個人坐在桌子前,桌上的物品和肢體會有輕微移動。xyz、static、rpy、halfsphere則代表著相機做不同方向的運動。
2.3 動態特征點剔除效果
圖6中圖像來源于fr3_walking_halfsphere高動態場景序列,此時桌前的人在拿著書本做小范圍運動,人和書本均是運動狀態。圖6a是ORB-SLAM2算法對圖像提取特征點的結果,可以看出此時靜態和動態區域的特征點都被提取。圖6b是僅通過目標檢測算法得到先驗語義信息,并剔除動態特征點的結果,可以看出人的動態特征點基本被剔除,但書本屬于潛在的動態物體而其特征點并未被完全剔除。圖6c是基于目標檢測網絡、對極幾何約束和光流法共同作用的結果,可以看出此時書本上的剩余動態特征點也已經被完全剔除,且人周圍原本的靜態特征點并未被暴力剔除,剔除動態特征點的同時保留了更多的靜態特征點,用于后續初始位姿估計。
表1 輕量化目標檢測算法在CPU上驗證

Tab.1 Lightweight object detection algorithm verified on the CPU
注:一個GFLOPS(gigaFLOPS)等于每秒10億次的浮點運算。

圖6 動態特征點剔除效果對比
2.4 改進后ORB-SLAM2算法性能評估
2.4.1 誤差結果對比
選取絕對軌跡誤差(Absolute Trajectory Error,ATE)以及相對位姿誤差(Relative PoseError,RPE)為算法性能評價指標。ATE是相機位姿的估計值和真實值的直接差值,能直觀地反映出算法精度和軌跡全局一致性。RPE是計算2個相同時間戳上相機位姿的估計值和真實值之間的差異,反映出連續位姿上的累積誤差信息,包括平移和旋轉兩部分[20]。其中,以均方根誤差RMSE、平均值Mean以及標準差STD這3個參數對ATE和RPE這2個指標進行統計,RMSE以及STD能夠反映系統的魯棒性,Mean則能夠反映位姿估計的精度。為了直觀地看出改進后的算法性能提升,在同一組數據集序列將ORB-SLAM2與本文算法做對比。這里將提升效率(Improvements)定義為,其公式見式(18)。
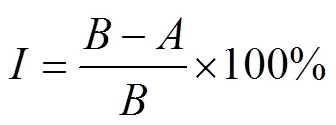
式中:為改進之后(After)的算法,即本文算法結果;為改進之前(Before)的算法,即ORB-SLAM2算法結果。表2、表3和表4分別是改進前后算法的ATE、RPE(平移部分)和RPE(旋轉部分)的運算結果。
表2 ATE實驗結果對比
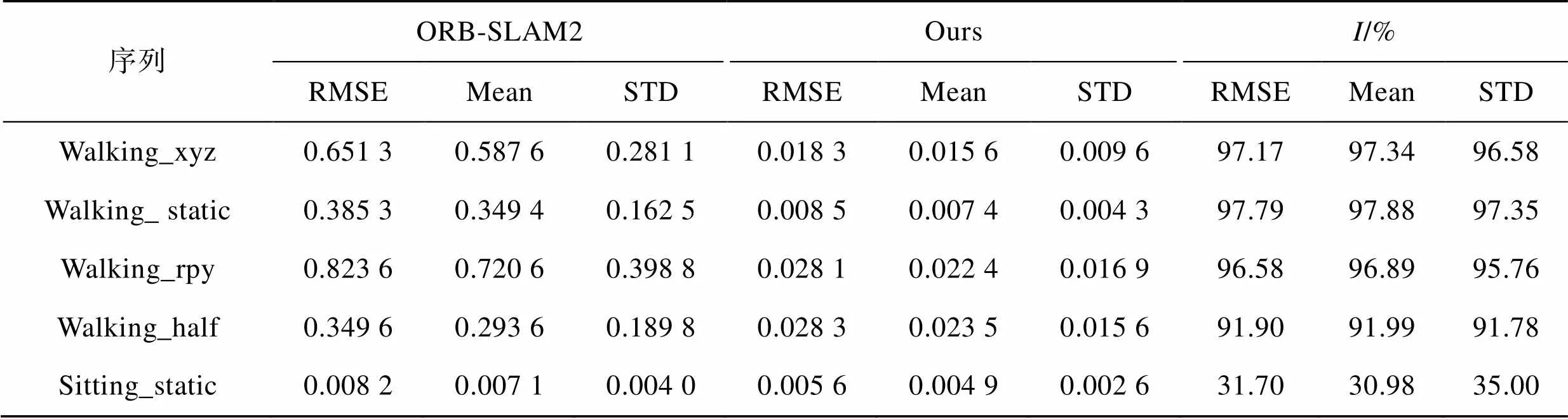
Tab.2 Comparison of ATE experimental results
表3 RPE平移部分實驗結果對比
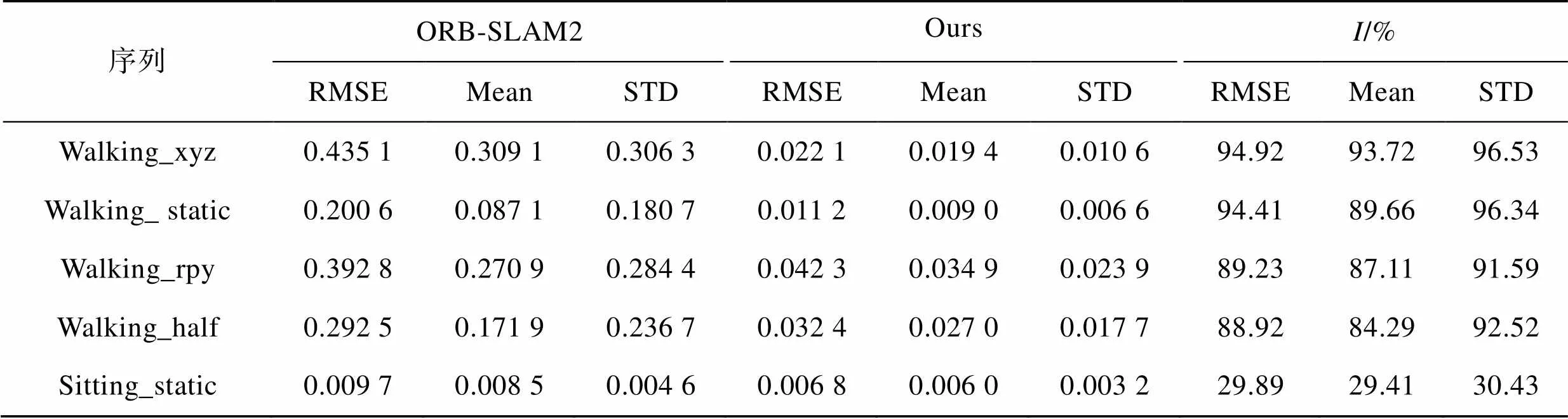
Tab.3 Comparison of experimental results of RPE translation part
表4 RPE旋轉部分實驗結果對比
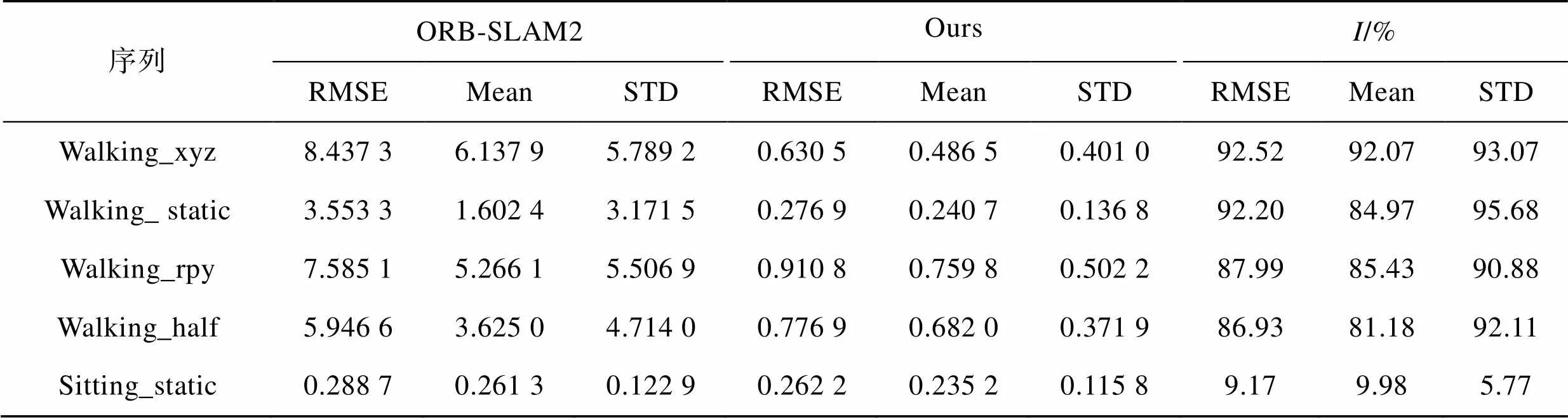
Tab.4 Comparison of experimental results of RPE rotation part
從表2的對比結果可知,在ATE方面,4組高動態序列的RMSE、Mean以及STD相較于改進之前的ORB-SLAM2算法均有大幅度的提升,誤差可減小90%以上。尤其是在Walking_ static序列,RMSE、Mean和STD最高分別提升了97.79%、97.88%和97.35%。實驗結果表明,在高動態場景下的本文算法可以顯著提高視覺SLAM系統的定位精度和魯棒性。在低動態序列Sitting_static中,各項指標雖也有一定的提升,但相較于高動態序列的提升并不明顯。這是由于該序列中的動態物體較少,且原ORB-SLAM2算法在低動態場景下本身就有著良好的表現。從表3和表4的對比結果可以看出,在RPE方面的結論與上述類似:本文算法在高動態序列中提升效果明顯,在低動態序列中有一定提升但并不明顯。
圖7和圖8分別是ORB-SLAM2與本文算法ATE對比和RPE對比,圖7a~c是ORB-SLAM2的結果,圖7d~f是本文算法。圖7中,黑色代表真實的相機軌跡,藍色是預測估計的路徑。紅線則表示兩者的誤差,線越短,精確度越高。圖8中,誤差波動越小則代表系統越穩定。顯然,在室內動態場景下,本文算法在定位精度和魯棒性上都超越了原有ORB-SLAM2算法。
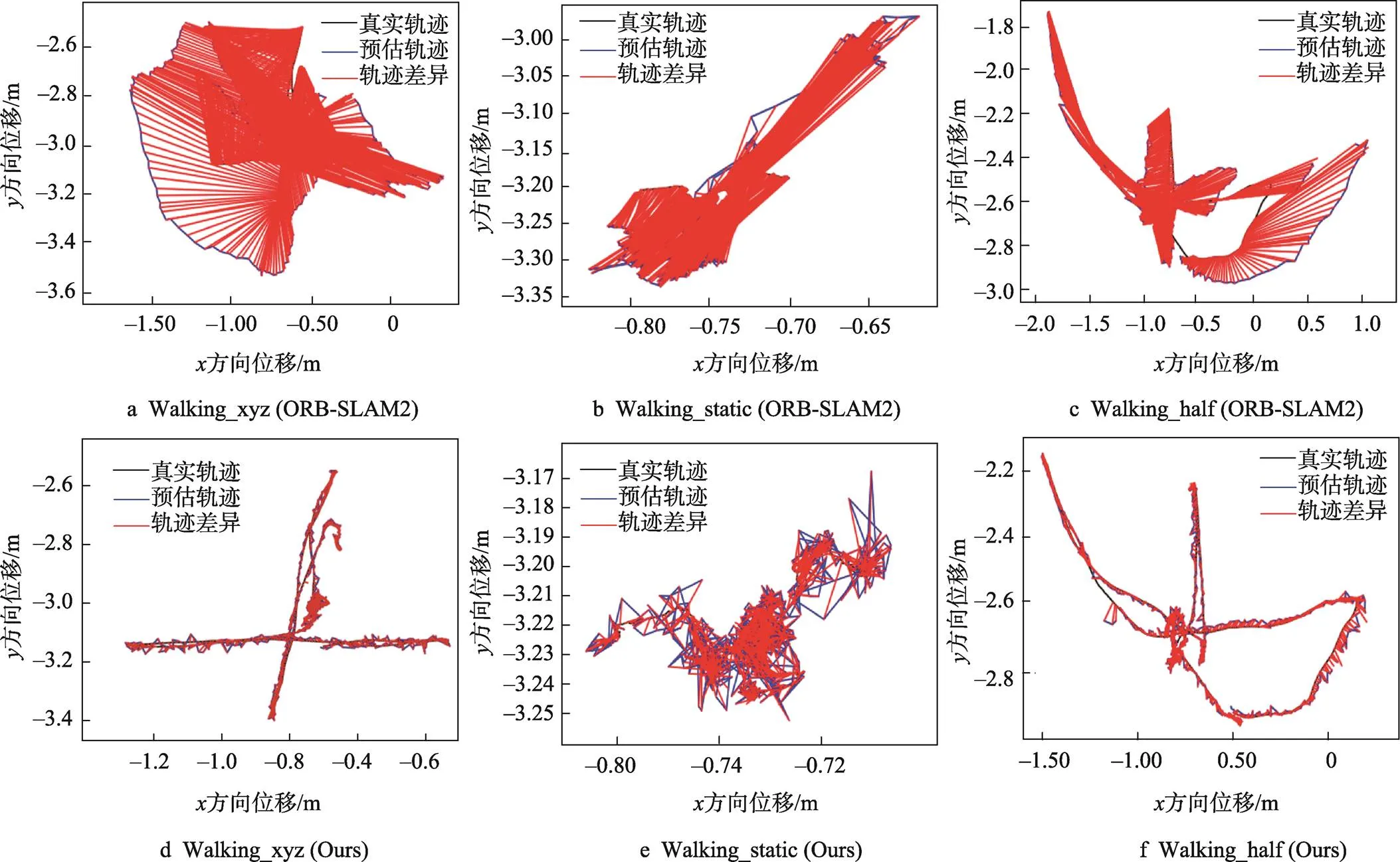
圖7 ORB-SLAM2與本文算法的ATE對比
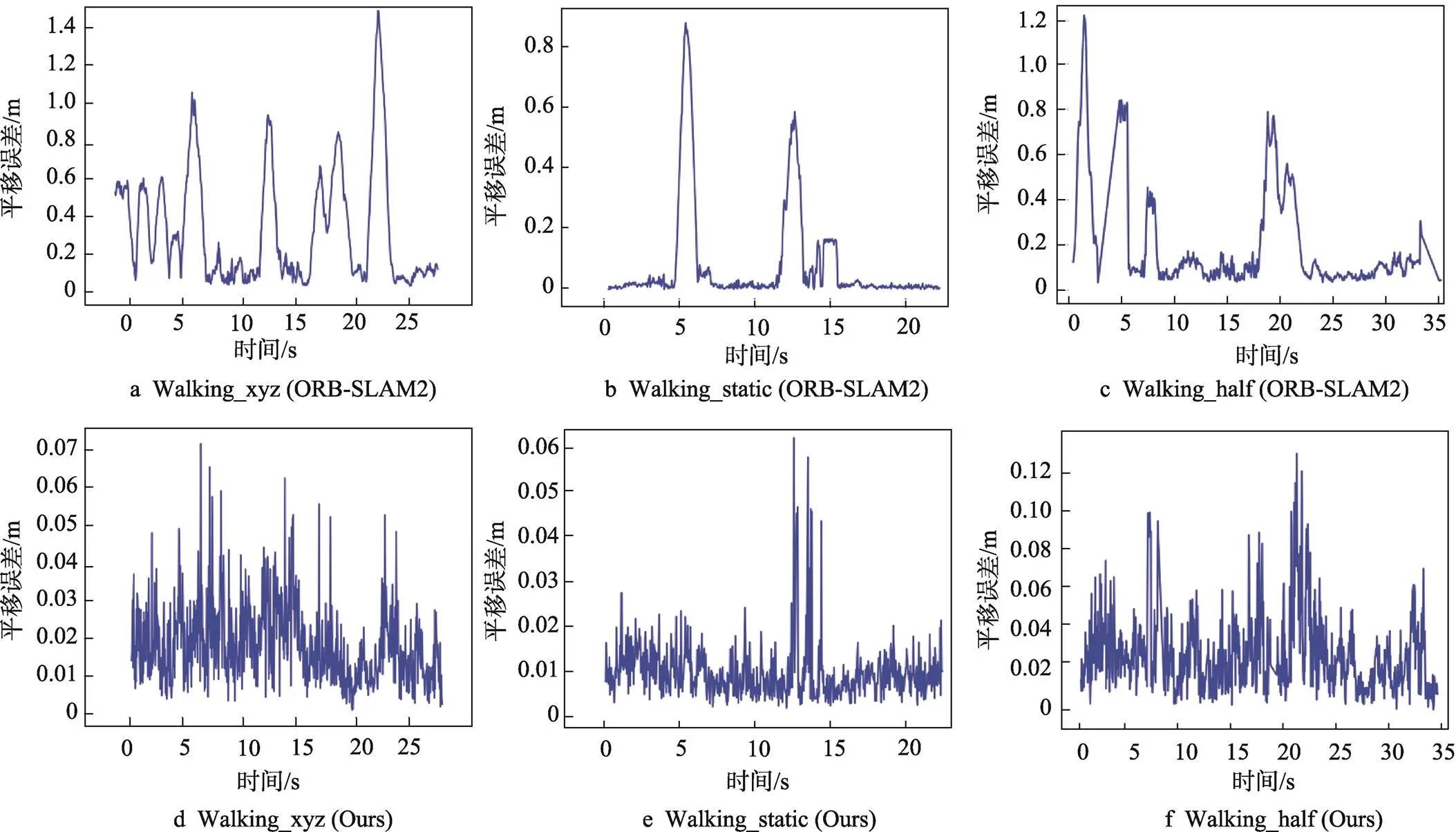
圖8 ORB-SLAM2與本文算法的RPE對比
2.4.2 與同類型其他算法對比
為了進一步驗證改進算法的性能,將其與其他同類型的優秀算法進行比較。其中,DS-SLAM和DynaSLAM是在ORB-SLAM2的基礎上改進,通過語義分割網絡提取動態場景的語義信息;DVO-SLAM是利用相鄰圖像之間的像素光度誤差來進行相機運動估計和場景重建。同類型算法絕對軌跡誤差對比結果如表5所示。從5組動態場景序列的實驗可知,在以下列出的算法中,Dyna-SLAM、DS-SLAM和本文算法定位精度較高。本文算法在精度上取得至少次優的結果,有著良好的表現。
表6列出了3種算法處理一幀圖片所需的時間。其中,DS-SLAM和DynaSLAM采用以逐像素的方式對動態對象進行檢測比較耗時,而本文采用輕量級目標檢測網絡,在運行速度上超越了上述的2種算法。因此,本文算法在保證定位精度和魯棒性的同時,也具有較好的實時性。
表5 同類型算法ATE實驗結果對比

Tab.5 Comparison of ATE experimental results of similar algorithms
注:“—”是指原論文中并未提供該數據,粗體表示最優結果,而次優的結果則用下劃線標注。
表6 跟蹤時間對比

Tab.6 Comparison of tracking time
3 結語
本文提出了一種面向室內動態場景的視覺SLAM算法,在原有ORB-SLAM2的視覺里程計上,添加了目標檢測線程和剔除動態特征點模塊。融合YOLOv5s輕量級目標檢測網絡實時檢測動態物體,在提取ORB特征點的同時獲取語義信息并剔除先驗的動態特征點。考慮到存在潛在動態物體和漏檢的情況,結合光流法和對極幾何約束對可能殘存的動態特征點進一步剔除。實驗結果表明,與ORB-SLAM2相比,改進后的算法在高動態序列下能夠大幅提升SLAM系統的定位精度和魯棒性,跟蹤線程中處理一幀圖像平均只需28.26 ms,與其他同類型優秀算法相比,本文算法在定位精度和實時性方面都具有一定的優勢,有望未來在包裝行業扮演更加重要的角色。但是,還存在一些需要改進的地方,例如,需要提高算法的實時性,或者構建質量較高語義八叉樹地圖,以便于能夠執行導航等更高級的任務。
[1] 王柯賽, 姚錫凡, 黃宇, 等. 動態環境下的視覺SLAM研究評述[J]. 機器人, 2021, 43(6): 715-732.
WANG K S, YAO X F, HUANG Y, et al. Review of Visual SLAM in Dynamic Environment[J]. Robot, 2021, 43(6): 715-732.
[2] KLEIN G, MURRAY D. Parallel Tracking and Mapping for Small AR Workspaces[C]// 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, IEEE, 2007: 225-234.
[3] MUR-ARTAL R, TARDóS J D. Orb-slam2: An Open-Source Slam System for Monocular, Stereo, and rgb-d Cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262.
[4] ENGEL J, KOLTUN V, CREMERS D. Direct Sparse Odometry[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(3): 611-625.
[5] YANG N, STUMBERG L, WANG R, et al. D3vo: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1281-1292.
[6] DAI W C, ZHANG Y, LI P, et al. RGB-D SLAM in Dynamic Environments Using Point Correlations[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 373-389.
[7] 張有全, 祁宇明, 鄧三鵬, 等. 直接法和共視圖優化的視覺慣性SLAM系統研究[J]. 自動化與儀器儀表, 2022, 271(5): 197-203.
ZHANG Y Q, QI Y M, DENG S P, et al. Research on Visual-Inertial SLAM System Based on Direct Method and Common View Optimization[J]. Automation and Instrumentation, 2022, 271(5): 197-203.
[8] 朱東瑩, 鐘勇, 楊觀賜, 等. 動態環境下視覺定位與建圖的運動分割研究進展[J]. 計算機應用, 2023, 43(8): 2537-2545.
ZHU D Y, ZHONG Y, YANG G C, et al. Research Progress on Motion Segmentation of Visual Localization and Mapping in Dynamic Environment[J]. Journal of Computer Applications, 2023, 43(8): 2537-2545.
[9] ZHONG F, WANG S, ZHANG Z, et al. Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial[C]// 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), IEEE, 2018: 1001-1010.
[10] LIU W, ANGUELOV D, ERHAN D. SSD: Single Shot MultiBox Detector[C]// European Conference on Computer Vision, 2016: 21-37.
[11] YU C, LIU Z, LIU X, et al. DS-SLAM: a Semantic Visual SLAM Towards Dynamic Environments[C]// 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Piscataway, USA: IEEE, 2018: 1168-1174.
[12] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
[13] BESCOS B, FACIL J M, CIVERA J, et al. DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 4076-4083.
[14] JOHNSON J W. Adapting Mask-Rcnn for Automatic Nucleus Segmentation[J]. arXiv e-prints, 2018, 3: 1-7.
[15] YAN L, HU X, ZHAO L, et al. DGS-SLAM: A Fast and Robust RGBD SLAM in Dynamic Environments Combined by Geometric and Semantic Information[J]. Remote Sensing, 2022, 14(3): 795-819.
[16] 李博, 段中興. 室內動態環境下基于深度學習的視覺里程計[J]. 小型微型計算機系統, 2023, 44(01): 49-55.
LI B, DUAN Z X. Visual Odometer Based on Deep Learning in Dynamic Indoor Environment[J]. Journal of Chinese Computer Systems, 2023, 44(1): 49-55.
[17] 伍子嘉, 陳航, 彭勇, 等. 動態環境下融合輕量級YOLOv5s的視覺SLAM[J]. 計算機工程, 2022, 48(08): 187-195.
WU Z J, CHEN H, PENG Y, et al. Visual SLAM with Lightweight YOLOv5s in Dynamic Environment[J]. Computer Engineering, 2022, 48(8): 187-195.
[18] HOWARD A, SANDLER M, CHU G, et al. Searching for Mobilenetv3[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 1314-1324.
[19] LI G, YU L, FEI S. A Binocular MSCKF-Based Visual Inertial Odometry System Using LK Optical Flow[J]. Journal of Intelligent & Robotic Systems, 2020, 100(3): 1179-1194.
[20] 張恒, 徐長春, 劉艷麗, 等. 基于語義分割動態特征點剔除的SLAM算法[J]. 計算機應用研究, 2022, 39(5): 1472-1477.
ZHANG H, XU C C, LIU Y L, et al. SLAM Algorithm Based on Semantic Segmentation and Dynamic Feature Point Elimination[J]. Application Research of Computers, 2022, 39(5): 1472-1477.
Visual SLAM Algorithm Based on YOLOv5 and Geometric Constraints in Dynamic Scenes
WANG Hongyu1,WU Yuezhong1,2*,CHENLingjiao1,CHENXi1
(1. School of Railway Transportation, Hunan University of Technology, Hunan Zhuzhou 412007, China;2.Key Laboratory for Intelligent Information Perception and Processing Technology, Hunan Zhuzhou 412007, China)
When mobile intelligence agent performs the complex task of Simultaneous Localization And Mapping (SLAM), the interference of dynamic objects will weaken the correlation between feature points and the degradation of the system's localization accuracy. In this regard, the work aims to propose a visual SLAM algorithm based on YOLOv5 and geometric constraints for indoor dynamic scenes. First, based on YOLOv5s, the original CSPDarknet backbone network was replaced by a lightweight MobileNetV3 network, which could reduce parameters and speed up operation, and at the same time, it was combined with the ORB-SLAM2 system to obtain semantic information and eliminate a priori dynamic feature points while extracting ORB feature points. Then, the possible residual dynamic feature points were further culled by combining the optical flow method and epipolar geometric constraints. Finally, only static feature points were used for camera position estimation. Experimental results on the TUM data set showed that both ATE and RPE were reduced by more than 90% on average under high dynamic sequences compared with ORB-SLAM2, and the processing of one frame in the tracking thread took only 28.26 ms on average compared with the same type of systems of DS-SLAM and Dyna-SLAM, while guaranteeing localization accuracy and robustness. The algorithm can effectively reduce the interference caused by dynamic objects to the real-time SLAM process. It provides a possibility for more intelligent and automatic packaging process.
visual SLAM; dynamic scene; target detection; optical flow method; epipolar geometric constraints
TB486;TP242
A
1001-3563(2024)03-0208-10
10.19554/j.cnki.1001-3563.2024.03.024
2023-10-25
國家重點研發計劃項目(2022YFE010300);湖南省自然科學基金項目(2021JJ50050,2022JJ50051,2023JJ30217);湖南省教育廳科學研究項目(22A0422,21A0350,21B0547,21C0430);中國高校產學研創新基金重點項目(2022IT052);湖南省研究生創新基金項目(CX20220835)
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
