基于小波壓縮深度學習重構的多圖像光學加密
2024-02-22 07:59:18賈德寶敬世偉
計算機工程與設計 2024年2期
關鍵詞:模型
郭 媛,賈德寶,敬世偉,翟 平
(齊齊哈爾大學 計算機與工程學院,黑龍江 齊齊哈爾 161006)
0 引 言
隨著大數(shù)據(jù)技術的快速發(fā)展和信息傳輸能力的不斷增強,傳統(tǒng)的單圖像加密[1]傳輸已經(jīng)不能滿足日益增長的信息需求。越來越多的學者開始研究多圖像加密技術[2-4],石等[5]提出了基于壓縮感知的多圖像加密方法,但該方法只作用于相同大小的圖像且加解密速度慢;Zeng等[6]提出了小波變換和菲涅爾變換的多彩色圖像加密方法,該方法通過提取4張圖像的低頻部分,同一類型通道重新組合一張新圖,但該方法只能加密固定的4張圖像。
隨著多圖像可同時加密的圖像越來越多,相應的密文體積也變得越大[7-10],而圖像壓縮是解決密文體積大的有效手段。Hashim等[11]提出了一種新的基于統(tǒng)計規(guī)則的數(shù)字圖像加密壓縮方法,通過路徑掃描得到一維像素序列,記錄方差濾波后的像素值和像素頻率,基于統(tǒng)計的規(guī)則進行壓縮,但該方法只是在空域?qū)D像進行操作,壓縮比例較小;李等[12]用離散余弦變換(DCT)將原始圖像變換到頻域的高頻與低頻部分,但在高壓縮比條件下會有比較明顯方塊效應。沈等[13]利用整數(shù)小波變換對圖像壓縮,對壓縮后的明文進行交叉組合,最后將組合的圖像動態(tài)分割生成多張密文實現(xiàn)多圖像加密,但這種方法加密速度慢。李等[14]基于Logistic混沌映射,利用明文像素對其迭代,生成一個隨機相位掩碼,增強了隨機相位模板的敏感性和隨機性,但該混沌初始值少,密鑰空間較小,安全性能較低。在圖像重構方面,傳統(tǒng)的重構算法重構時間長,重構效果差,不能滿足顯示設備快速發(fā)展的需求。張等[15]提出一種基于深度學習的快速超分辨率圖像重建方法,使用級聯(lián)的小卷積核以取得重建速度上的提升,加深卷積網(wǎng)絡以取得重建質(zhì)量上的提升;Li等[16]使用生成對抗網(wǎng)絡對圖像重構,該網(wǎng)絡由生成器和判別器兩個模型組成,訓練過程中相互修正,能夠獲得更接近人眼真實感知的重構圖像,但對于高精度重構不適用,且網(wǎng)絡計算較復雜,學習速度慢。
綜上所述,本文基于小波變換對多張不同大小、不同類型的圖像進行壓縮,并將壓縮后的多張圖像進行先行后列重排;使用FDT-DRPE光學加密系統(tǒng)提高加密速度,并對FDT-DRPE進行改進,添加矢量分解和螺旋相位變換;將Logistic與sine混沌級聯(lián)再添加到sin函數(shù)構造L_S混沌系統(tǒng);提出比特分層深度學習網(wǎng)絡模型(BHCN),對圖像進行比特分層作為網(wǎng)絡輸入,并通過在網(wǎng)絡訓練中對輸入圖像加入高斯噪聲來增強圖像的抗噪聲和抗剪切能力。
1 基本原理
1.1 小波壓縮與多圖像重組
本文采用二維離散小波變換對圖像f(x,y) 壓縮,圖像中的二維小波變換表示為
(1)
逆變換
(2)
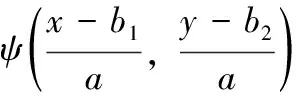
為了能加密任意數(shù)量、類型和大小的圖像,首先對原圖進行小波壓縮,只保留低頻LL,并將得到的低頻圖像按先行后列的形式組合成一個新圖像,針對彩色圖像先進行通道的分離,然后再用同樣的方式組合。其圖像大小運用式(3)來計算

(3)
1.2 改進的FDT-DRPE
傳統(tǒng)的FDT-DRPE克服了4f系統(tǒng)中的透鏡和隨機相位模板都需要精確定位,靈活性不高的問題[17],但是FDT-DRPE對第一塊隨機相位模板和第一衍射距離不夠敏感。本文通過在FDT-DRPE前加入矢量分解將輸入圖像由實值轉換為復值表示,并結合螺旋相位變換來提高衍射距離的敏感性。改進后的過程如圖1所示。
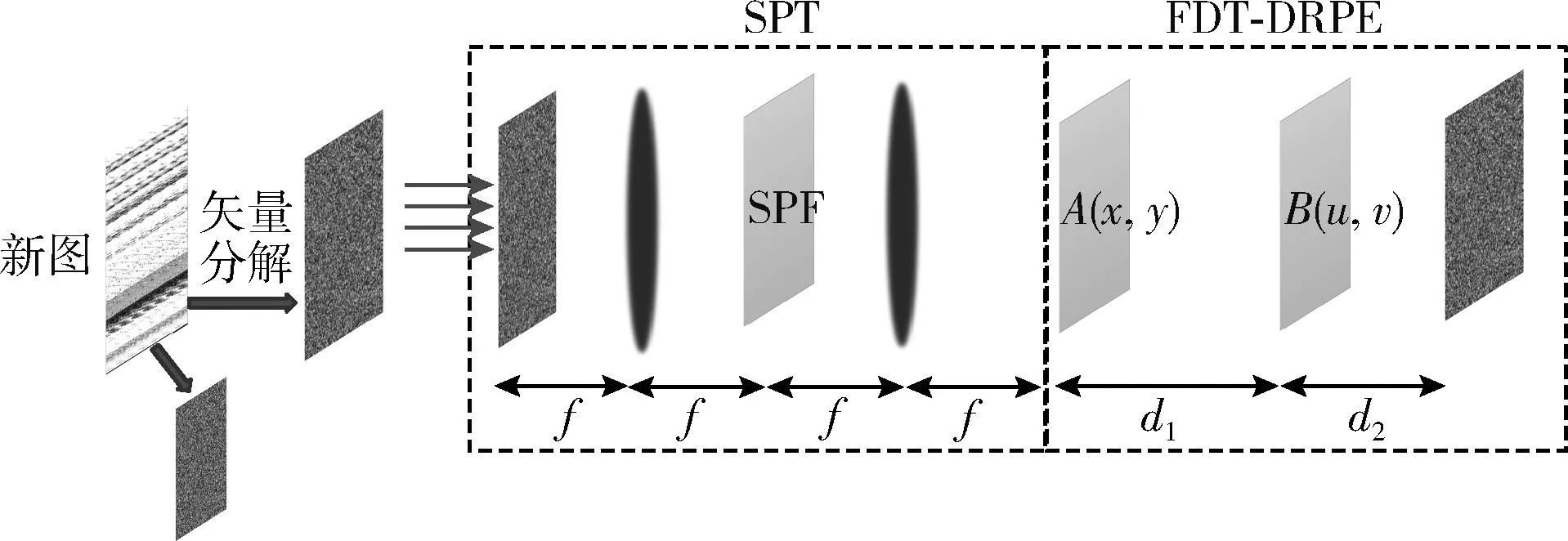
圖1 改進的FDT-DRPE
單位等模矢量分解表示為
(4)
其中,Z1為復數(shù)形式的分解結果,F(xiàn)為歸一化后的明文信息,α為隨機相位角,解密時用式(5)
F=|exp(iα)+Z1|
(5)
螺旋相位變換(spiral phase transform,SPT)的正變換為
FSPT(x,y)=SPT{Z1(x,y)}=IFT{SPFq·FT{Z1(x,y)}}
(6)
SPT的逆變換為
FISPT(x,y)=ISPT{FSPT(x,y)}=
IFT{SPFq*×FT{FSPT(x,y)}}
(7)
其中,F(xiàn)T為傅里葉變化,IFT為傅里葉逆變換,SPFq為螺旋相位空間函數(shù),SPFq*為其復共軛
SPFq=exp{iqφ(u,v)}
(8)
(9)
式中:φ(u,v) 是頻率空間中的極角坐標,i是虛數(shù)單位。SPFq在原點處沒有定義,函數(shù)值可以按0或1來處理,稱為奇點,q為修正參數(shù)。
菲涅爾雙隨機相位編碼與解碼表示為
FDRPE(x,y)=FDTd1{FDTd2[FSPT(x,y)·
A(x,y)]·B(u,v)}
(10)
FSPT(x,y)=FDT-d1{FDT-d2[FDRPE(x,y)]·
B*(u,v)}·A*(x,y)
(11)
A(x,y)、 B(u,v) 為空域和頻域的隨機相位模板,A*(x,y)、 B*(u,v) 為其復共軛。
1.3 L_S混沌系統(tǒng)構造
本文采用Logistic與sine混沌級聯(lián)再添加到sin函數(shù)的方式,使其能夠在整個參數(shù)區(qū)間都能達到滿映射的狀態(tài)。
Logistic混沌系統(tǒng)映射定義為
xn+1=μxn(1-xn)
(12)
其中,0≤μ≤4稱為分枝參數(shù),對任意的xn∈(0,1),Logistic系統(tǒng)始終可以保證xn+1始終位于(0,1)內(nèi),混沌動力系統(tǒng)研究指出,當3.569 945<μ≤4時,Logistic映射處于混沌態(tài)。
Sine映射定義為
xn+1={μsin(πxn)}/4
(13)
Logistic與sine級聯(lián)再變換可表示為
(14)
由圖2可知Logistic與sine級聯(lián)產(chǎn)生的連續(xù)混沌參數(shù)在[0,4]的區(qū)間,明顯比Logistic與sine的參數(shù)區(qū)間更寬,從而使得其密鑰空間更大,抗蠻力攻擊能力更強。

圖2 分岔圖
通過混沌產(chǎn)生隨機密鑰和相位模板,可以減小密鑰的體積并具有更好的隨機性。
1.4 基于比特分層卷積神經(jīng)網(wǎng)絡重構模型BHCN
為使特征提取層獲得更多圖像細節(jié),本文對輸入圖像進行比特分層來作為深度學習模型的輸入,模型共計5個卷積層,卷積核大小分別為9×9,5×5,3×3,1×1,3×3,激活函數(shù)使用Leaky Relu函數(shù),均方誤差(MSE)作為損失函數(shù),優(yōu)化器采用Adam。
模型的卷積的運算過程表示為
Fi(Xi)=max(0,Wi*Xi+Bi)
(15)
Xi+1=LeakyReLU(Fi(Xi))
(16)
其中,Wi與Bi分別代表濾波器的系數(shù)和偏置參數(shù),*表示卷積運算,Wi包含ni個c×fi×fi,c表示輸入的通道數(shù),F(xiàn)i為濾波器空間大小,Bi是一個ni維向量,代表ni個偏置。Leaky ReLU()為激活函數(shù),雖然ReLu具有訓練速度快的優(yōu)勢,但當x<0的情況下,神經(jīng)元在訓練中會出現(xiàn)不可逆死亡現(xiàn)象。而Leaky ReLu當x<0時,它的值不再是0,而是一個較小的斜率函數(shù),這樣就不會丟失x<0的全部信息,公式為
(17)
網(wǎng)絡模型如圖3所示。

圖3 比特分層網(wǎng)絡結構
網(wǎng)絡訓練集使用BSD500前400張圖片,并進行翻轉、旋轉操作得到2400張圖片作為訓練集,后100張圖片同樣處理作為測試集,初始學習率為0.001,迭代50 000次,每10 000次學習率降低1/2。使用Pytorch開源工具訓練網(wǎng)絡,設備配置為Intel Core i7-10130 CPU,內(nèi)存32 G,顯卡GTX2080Ti。為提高網(wǎng)絡的抗噪聲能力,訓練時在輸入圖像添加σ=0.01的高斯噪聲。
2 加解密過程
2.1 密鑰生成
將該混沌系統(tǒng)(L-S)與系統(tǒng)加密時間和明文的SHA-256進行關聯(lián),實現(xiàn)一次一密的加密效果。首先求出當前加密時間和明文的SHA-256H1和H2并進行異或運算求得H3,再將H3每八位分為一組,可以表示為H3=h1,h2,…,h32, 其中hi為hi=[hi,0,hi,1,…,hi,7], 并用其生成如下的動態(tài)密鑰
x0=mod(x′0+h1⊕h2⊕h3⊕h4/256,1)
(18)
μ1=mod(μ′1+h5⊕h6⊕h7⊕h8/64,4)
(19)
N0=mod(n′0+h9⊕h10⊕h11⊕h12,200)+100
(20)
d1=mod(d′1+h13⊕h14⊕h15⊕h16⊕h17/64,4)
(21)
d2=mod(d′2+h18⊕h19⊕h20⊕h21⊕h22/64,4)
(22)
λ=mod(λ′+h23⊕h24⊕h25⊕h26⊕h27/256,7)*10-6
(23)
q=q′+h28⊕h29⊕h30⊕h31⊕h32
(24)
其中,x0、μ1、N0為混沌的初值參數(shù)和預迭代次數(shù),d1、d2、λ、q為菲涅爾雙隨機相位編碼的第一第二衍射距離、波長和螺旋相位模板的修正系數(shù)。x′0、μ′1、n′0、d′1、d′2、λ′、q′為初始參數(shù)。
2.2 加密過程
本文先將多張圖像(f1-fn)進行小波壓縮,提取低頻(L1-Ln)部分,再將低頻圖像按先行后列組成一張灰度圖像F,并對該圖像進行矢量分解得到純相位信息圖像F1,再對其進行螺旋相位變換得到F2,最后將其放入菲涅爾的雙隨機相位編碼系統(tǒng)中得到密文C,加密過程如圖4所示。
詳細步驟如下:
步驟1 輸入多張不同類型、大小的圖像f1-fn,通過小波變換提取低頻部分L1-Ln。
步驟2 將得到的低頻圖像進行重組得到一個一維的矩陣F,并作歸一化處理。
步驟3 計算F和當前時間的SHA256,并通過得到的值通過動態(tài)密鑰的生成式(18)到式(24)得到x0、μ1、N0、d1、d2、λ、q。
步驟4 將x0、μ1帶入L-S混沌系統(tǒng)中先迭代N0次,再動態(tài)迭代3*m*n(m,n為加密圖像的長寬)次,截取三段序列生成r1,r2,r3隨機序列矩陣,再放入式(25)到式(27)中生成隨機模板
rmp1=r1×2π
(25)
rpm2=exp(i×2π×mod(r2×10,1))
(26)
rpm3=exp(i×2π×mod(r3×100,1))
(27)
步驟5 將 rmp1和F帶入式(4)中進行矢量分解,得到F1。
步驟6 將q帶入式(8)中求得SPFq模板,與F1一起帶入式(6)得到螺旋相位變換后的圖像F2。
步驟7 將rmp2、rmp3,λ和F2帶入式(10)中進行雙隨機相位編碼得到密文C。
2.3 解密與重構
解密過程為加密的逆過程,模板的生成與加密同樣的處理,數(shù)值取加密模板的復共軛。解密的原理如圖5所示。
將解密得到的重組圖像F分離得到多張圖像的低頻(LL)部分,通過填充0作為圖像的高頻部分,并進行逆小波變換得到模糊圖像,對該圖像進行比特分層得到n*8個圖像,再將得到的圖像放入訓練好的模型得到清晰圖像。
3 實驗分析
為驗證本文算法的有效性和可行性,選取一張256×256的彩色圖、一張512×512的灰度圖、一張256×256的CT圖、一張128×128的顯微鏡下細胞圖作為明文。設置x′0、μ′1、n′0、d′1、d′2、λ′和q′分別為0.49、4.1、500、4、5、9和3000,再根據(jù)新組成圖像和加密時間的SHA-256生成 動態(tài)密鑰。加解密結果如圖6所示。明文圖像具有很強的相關性,攻擊者就可以通過相關性特征來恢復圖像,表1給出了水平、垂直和對角的相鄰像素相關系數(shù),以此來評估算法的加密效果。

表1 相鄰像素相關性

圖6 加解密與重構效果
由圖6可見本算法一次完成了4張不同類型、大小的圖片同時加密。密文大小為所有明文的1/4,具有壓縮效果,便于密文的傳輸。密文圖像完全看不出明文信息且解密圖像在肉眼條件下與明文無差別。表1可見本算法可有效破壞像素間相關性,增加安全性。
3.1 壓縮與加密性能分析
通常來說,壓縮率決定著多圖像加密密文的大小,但加密圖像的數(shù)量、大小、類型以及壓縮與加密的時間也是重要的評價指標,為測試本文系統(tǒng)的壓縮與加密性能,與文獻[2,6,13]進行多維度對比,結果見表2。
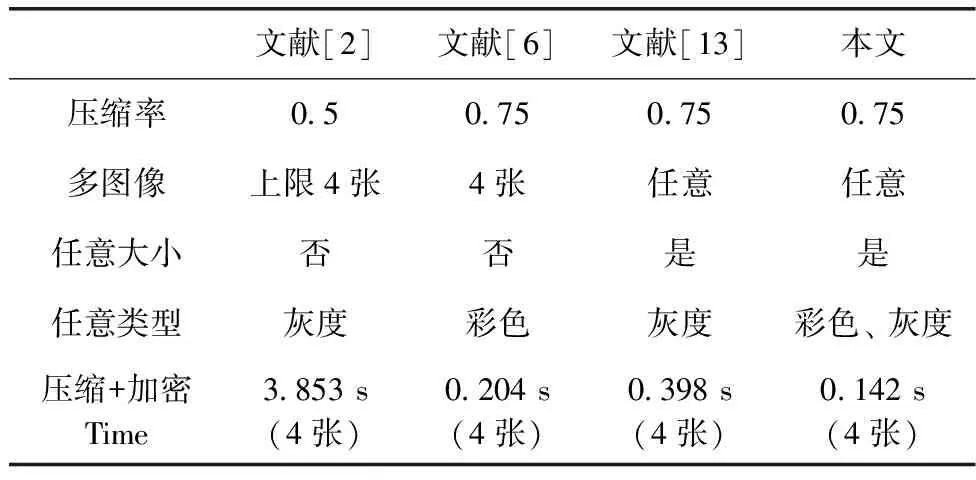
表2 壓縮與加密性能對比
由表2可知,本文在整體性能表現(xiàn)更好,相比文獻[2,6,13],本文對加密圖像的數(shù)量、大小沒有限制,壓縮率上優(yōu)于文獻[2],并可以加密任意類型圖像;在同時壓縮與加密4張圖像時,本文在時間上最優(yōu)。
3.2 密鑰空間分析
本文的密鑰包括明文與當前時間的哈希值(SHA-256)以及混沌的初值參 (x0、μ1、N0) 數(shù)和光學的衍射距離 (d1、d2)、 頻率(λ)和相位旋轉參數(shù)(q)。通過表3的密鑰敏感性分析得出敏感度再乘以其范圍就為其秘鑰空間,故本文的密鑰空間至少10220。從安全的角度,Liu等[18]指出抵抗蠻力攻擊的密鑰空間大小為2100就可以抵御蠻力攻擊,10220>>2100,所以本算法的密鑰空間對窮舉攻擊是安全的。

表3 魯棒性分析數(shù)值表示
3.3 魯棒性分析
密文在傳輸過程中極易受到噪聲污染和數(shù)據(jù)丟失的情況,本文通過在網(wǎng)絡模型訓練中對輸入圖像添加高斯噪聲來增強密文的抗噪聲和抗剪切能力。將圖6(e)的密文加入0.1的高斯噪聲、0.1的椒鹽噪聲和1/4的剪切操作后,分別放入不加噪聲模型和加噪聲模型中重構,重構效果如圖7所示,并通過式(32)計算不添加噪聲模型和添加噪聲模型的PSNR,計算結果見表3。
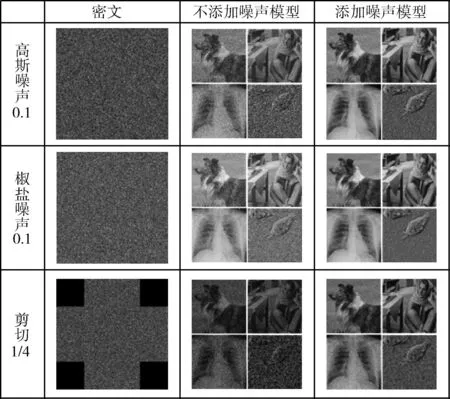
圖7 魯棒性分析
圖7可見,即使在訓練中不添加噪聲仍能看出明文信息,說明網(wǎng)絡的穩(wěn)定性較好,而在訓練中添加噪聲后,可以得到更加清晰的明文,細節(jié)表現(xiàn)更好,由此可見添加噪聲后的網(wǎng)絡模型間接增強了密文的抗噪聲和抗剪切能力;由表3可知對輸入圖像添加噪聲后模型的PSNR比不添加噪聲的模型平均提高了7.49 dB。
3.4 敏感性分析
3.4.1 密鑰敏感性分析
密鑰敏感性表示當其中任何一個密鑰發(fā)生非常微小的變化時,生成的密文表現(xiàn)出巨大差別,同樣對于解密的明文來說,已經(jīng)失去了原始明文的全部特征。通過變化前后的相關系數(shù)來作為敏感性的指標,當相關系數(shù)越接近0時,表示密鑰的敏感性越強,計算公式如下
(28)

表4表示通過改變單一變量x′0、μ′1、n′0、d′1、d′2、λ′、q′,H1、H2后,改變前后的密文與解密圖像相關系數(shù)。

表4 密鑰敏感性分析
由表4可知,無論在加密還是在解密過程中密鑰改變前后密文和解密圖像的相關系數(shù)都很接近于0,說明加密出來的密文或解密的解密圖像完全不同。
圖8展示了圖6中密文在x′0改變10-14時的解密圖像。當密鑰發(fā)生微小變化時,得到的圖像沒有任何特征信息,說明本文加密算法對密鑰極其敏感。
3.4.2 明文敏感性分析
明文的敏感性表現(xiàn)在密鑰不變的情況下,對明文進行細微的變化后,得到的相應密文與原密文幾乎無任何共同點和共同特征,使得加密系統(tǒng)無法破譯。表5是通過計算圖6(a)~圖6(d)的像素改變率(number of pixels change rate,NPCR)和統(tǒng)一平均變化強度(unified average changing intensity,UACI)來驗證該加密系統(tǒng)具有很強的抗差分攻擊能力,公式如下
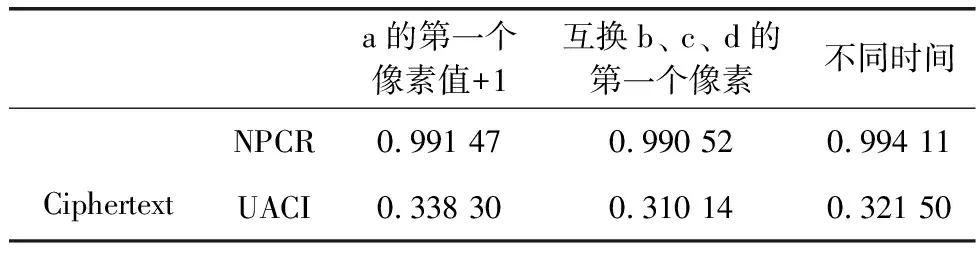
表5 明文敏感性分析
(29)
(30)
(31)
其中,C1表示原始加密圖像,C2為改變原始圖像的某一像素點后的加密圖像,M×N為加密圖像的大小。
由表5可知,無論明文圖像改變?nèi)我庖稽c像素值還是加密的時間不同,密文圖像幾乎全部發(fā)生了變化,可見該加密系統(tǒng)具有較強的明文敏感性,并驗證了加密系統(tǒng)具有一次一密的特點。
3.5 重構質(zhì)量和性能分析
本文采用峰值信噪比PSNR與結構相似性SSIM作為重構質(zhì)量的評價標準,PSNR的值越大表示圖像重構的質(zhì)量越高,PSNR的公式表示為
(32)
MAX表示圖像點顏色最大值,L表示損失函數(shù),本文的損失函數(shù)為式MSE損失函數(shù)。SSIM從亮度、對比度和結構3個層次進行相似度比較,值在0~1之間,越接近1表示兩幅圖越相似,SSIM的公式表示為
SSIM(x,y)=l(x,y)α·c(x,y)β·s(x,y)γ
(33)
(34)
(35)
(36)
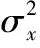
表6列出了圖6(a)~圖6(d)使用文獻[5,7,10,11,14]加解密的重構效果與重構時間,并對圖6(a)~圖6(d)采用本文的方式壓縮與加密,再放入不同的深度學習模型中來分析重構效果與重構時間。并分別選取傳統(tǒng)算法與深度學習模型在重構時間和重構效果上表現(xiàn)較優(yōu)的與本文模型在視覺效果上進行對比,如圖9所示。

表6 重構質(zhì)量分析

圖9 重構效果對比
表6可以看出,本文重構圖像的PSNR與SSIM要明顯優(yōu)于文獻[5,7,10,11];并在重構時間上明顯優(yōu)于傳統(tǒng)算法。對比其它深度學習模型,本文使用比特分層的預處理方式,PSNR都在34 dB以上,優(yōu)勢明顯;0.5 s的重構時間也優(yōu)于大部分模型結合。圖9可以看出,SRCNN、MSRN和文獻[10]圖像恢復模糊,無法重構出細節(jié)信息,文獻[14]在PSNR方面與本文相當,但本文的SSIM更高,具有更清晰的重構效果,在細節(jié)恢復上,本文明顯精度更高。
3.6 模型泛化能力
為驗證本文模型具有較好的泛化能力,分別從Set14、B100、Urban100中選取4張圖片做測試,并計算4張圖片的平均峰值信噪比(PSNR)和結構相似性(SSIM),表7為實驗驗證結果。
由表7可知在3個不同數(shù)據(jù)集上驗證的結果,PSNR的平均值都超過34 dB,說明恢復圖像的圖像質(zhì)量較高,具有較好的泛化能力。
4 結束語
本文提出一種可實現(xiàn)任意張數(shù)、大小和類型的多圖像同時加密算法。采用小波壓縮將密文體積減小到原來的1/4,提高傳輸效率;構造L_S混沌系統(tǒng),并將明文SHA256和加密時間SHA256密鑰進行關聯(lián),密鑰空間超過10210,改進FDT-DRPE光學加密系統(tǒng)具有光學加密的并行性,0.142 s可同時加密4張圖片,并解決了第一個衍射距離和第一塊模板的不敏感。提出比特分層卷積神經(jīng)網(wǎng)絡(BHCN)重構模型,重構圖像PSNR超過34 dB,重構細節(jié)效果更好,精度更高,SSIM值超過0.94;通過在訓練中對輸入圖像添加高斯噪聲,使密文在受到0.1高斯和椒鹽噪聲后,仍能較清晰的恢復圖像,且可抵御一定的剪切攻擊。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
