智能制造系統(tǒng)可靠性與風險評估模型
2024-03-04 12:24:02段春艷王佳潔王皓博張文娟
同濟大學學報(自然科學版) 2024年2期
段春艷, 王佳潔, 王皓博, 張文娟
(同濟大學 機械與能源工程學院,上海 201804)
伴隨著信息技術的高速發(fā)展,在全球制造業(yè)向智能制造調整的大方向下,德國政府提出“工業(yè)4.0”戰(zhàn)略,美國提出“工業(yè)互聯(lián)網(wǎng)”戰(zhàn)略,我國也提出了“中國制造2025”戰(zhàn)略。智能制造已成為世界各國振興實體經(jīng)濟和發(fā)展新興產(chǎn)業(yè)的支柱和核心,是進一步提升國家競爭力和可持續(xù)發(fā)展能力的基礎和關鍵。智能制造系統(tǒng)是智能制造工廠的核心,該系統(tǒng)本身的系統(tǒng)復雜性、規(guī)模龐大以及外部環(huán)境的不確定性,使得系統(tǒng)和產(chǎn)品的可靠性受到人、設備、生產(chǎn)管理和環(huán)境等眾多因素的影響[1]。因此,迫切需要對智能制造系統(tǒng)進行可靠性和風險評估研究。
針對智能制造系統(tǒng),大部分學者主要集中對質量控制方面、智能工藝規(guī)劃等進行了相關研究,Kang等[2]在質量控制方面,基于人類質量控制系統(tǒng)研究了智能制造系統(tǒng)檢測性能的影響。Liu 等[3]針對智能制造系統(tǒng)的智能工藝規(guī)劃問題,基于網(wǎng)絡圖拓撲提出了一個混合整數(shù)線性規(guī)劃模型。此外,很多學者對企業(yè)資源計劃(enterprise resource planning,ERP)、制造執(zhí)行系統(tǒng)(manufacturing execution system,MES)及工廠控制層進行了調查研究。姚弘等[4]對ERP和工廠控制層之間的信息流動進行了研究,將監(jiān)控軟件劃分為各個模塊,并對整個系統(tǒng)中的信息網(wǎng)絡進行了分析。尤建新等[5]分析了MES系統(tǒng)可能存在的風險,應用組合權重和灰色關聯(lián)分析法對失效模式與影響分析(failure mode and effects analysis,F(xiàn)MEA)模型進行優(yōu)化并構建了MES 風險分析模型。現(xiàn)今學者們對智能制造系統(tǒng)的研究主要集中在對某一層次的深入研究,對整個系統(tǒng)可靠性及風險評估的研究較少。智能制造系統(tǒng)的復雜性和實用性使其可靠性與風險評估研究雖然有一定難度但十分重要。
FMEA 作為一種系統(tǒng)的、面向群體的、結構化的、主動的、有效的可靠性分析和風險評估方法,可用于識別系統(tǒng)、產(chǎn)品、過程和服務中潛在的失效模式,評估不同失效模式所產(chǎn)生的影響,并分配有限的資源進行改進或消除失效模式[6],已被廣泛應用于企業(yè)質量管理與風險分析中,對企業(yè)產(chǎn)品、服務及過程的可靠性提高具有有效性[5]。FMEA被廣泛應用于從航天領域到醫(yī)療行業(yè)等不同領域的可靠性和風險管理研究之中[7-8],并作為一個完善的風險管理工具取得了很好的效果,得到了專家學者們的認可,并且在持續(xù)的研究中不斷發(fā)展。然而傳統(tǒng)的FMEA在使用過程中會有一定的缺點,如使用精確的數(shù)字對失效模式的風險因子進行評估,沒有考慮各個風險因子之間相對權重,計算出的RPN(風險優(yōu)先數(shù))值相同但其實際失效模式的風險含義會完全不同[9],因此專家學者們提出了很多方法改進FMEA。針對使用精確的數(shù)值對失效模式進行評估的缺陷,很多學者通過將模糊理論與FMEA 模型相結合來改進模型,如Qin 等[10]將區(qū)間二型模糊集與證據(jù)推理方法相結合用于改進FMEA 使之更有效地處理不確定性。而其中多準則決策方法作為常用于解決具有多個、沖突的準則或目標的現(xiàn)實問題的方法[11],在近年來常用來改進FMEA 以彌補或改進后兩種缺陷,Li 等[12]提出了一種基于層次分析法的改進FMEA,將其用于海上浮式風力機故障原因分析,通過對比研究驗證了該方法的創(chuàng)新性和可行性。Ba?han 等[13]采用逼近理想解排序法(TOPSIS)改進FMEA 模型,對船舶航行中的風險進行排序并提出改進措施和預防方案。隨著機器學習相關理論的興起,也有越來越多的研究將機器學習與FMEA相結合,如人工神經(jīng)網(wǎng)絡[14]都被應用在優(yōu)化FMEA 模型,分析失效模式提高系統(tǒng)的可靠性。
智能制造系統(tǒng)內(nèi)部模塊數(shù)量多、結構復雜且影響因素眾多,維持正常高效運行面臨眾多挑戰(zhàn),針對智能制造系統(tǒng)進行可靠性和風險評估研究將具有重要的研究價值。FMEA作為可靠性與風險評估的重要方法,已有許多學者應用其對大型系統(tǒng)或智能制造系統(tǒng)的某一部分進行過可靠性與風險分析,并得到了較好的分析結果[12],但對整個系統(tǒng)的可靠性與風險評估的研究還比較缺乏;同時,運用多準則妥協(xié)解排序法(vlsekriterijumska optimizacija i kompromisno resenje,VIKOR)等多準則決策方法改進FMEA可獲得更準確的結果。因此,本文將在系統(tǒng)梳理智能制造系統(tǒng)不同模塊潛在失效模式和影響分析基礎上,綜合運用TOPSIS 法思想、模糊層次分析法(FAHP)、熵權法和模糊VIKOR 方法以及PAM(partition around medoids)聚類算法,提出一種基于改進FMEA的智能制造系統(tǒng)可靠性與風險評估模型,并與傳統(tǒng)FMEA、中間模型分析結果進行對比,以驗證所提出模型的準確性;并力求根據(jù)結果分析,為智能制造系統(tǒng)風險預防和可靠性提升提出建議。
1 改進FMEA模型構建
1.1 失效模式及其影響分析評估
由于人的決策具有模糊性,針對傳統(tǒng)FMEA 使用精確的數(shù)字對失效模式的風險因子進行評估的缺點,本文使用三角模糊數(shù)進行計算分析。傳統(tǒng)FMEA 中,以1-10 之間的整數(shù)作為風險因子的評估標準,在本文中,通過5個語言變量對風險因子進行評估,各個語言變量對應的評估標準如表1。

表1 語言變量對應評估標準及其對應三角模糊數(shù)Tab. 1 Evaluation criteria of linguistic variables and its triangle fuzzy numbers
設FMEA 團隊中共有p名專家,對m個失效模式FMi 的3 個風險因子進行評估評分,將評分語言變量轉化為三角模糊數(shù),得到對應的模糊評價值x?ij(k)=(lij,mij,uij),x?ij(k)表示第k(k=1,2,…,p)個專家對第i(i=1,2,...,m)個失效模式的第j(j=1,2,…,n)個風險因子的評分值,所有的模糊評價值構成的模糊評價矩陣X?k=(x?ij(k))m×n,k=1,2,...,p。
1.2 專家權重
考慮到TOPSIS法[15]的基本原理為在歸一化后的原始矩陣中,找到有限方案中的最優(yōu)方案和最劣方案,然后分別計算出評估對象與最優(yōu)方案和最劣方案之間的距離,以得到評估對象與最優(yōu)方案之間的相對接近程度;本文參考TOPSIS法,將平均值設為最優(yōu)方案,距離平均值最遠的值設為最劣方案,并計算每個專家距離這些方案的歐式距離得到的值歸一化后以得到各專家的權重:
(1)將各個專家的模糊評價矩陣按式(1)去模糊化得到各專家的評價矩陣Xk
(2)考慮群體差異最小,將平均值設為最優(yōu)方案,從而確定各個風險因子最優(yōu)方案與最劣方案:
(3)計算第k個專家距離最優(yōu)方案與最劣方案的歐式距離:
(4)計算第k個專家的相對接近程度Ck
(5)歸一化后得到第k個專家的權重λk
(6)將第k個專家的模糊評價矩陣乘以相應權重相加后得到FMEA 專家評估組的模糊評價矩陣X?=(x?ij)m×n。
1.3 風險因子組合權重
針對傳統(tǒng)FMEA沒有考慮各個風險因子之間相對權重,層次分析法(AHP)被用來在多層次的層次結構中通過兩兩比較得出比率尺度,而FAHP更是將模糊理論與AHP結合,更適于處理專家的模糊表達,因此,本文將選用FAHP計算主觀權重。熵權法可以避免人為因素的干擾,衡量出風險因子信息量的大小。因此,本文使用熵權法進行客觀權重計算以彌補主觀權重計算方法的不足,并通過乘法合成法計算風險因子的組合權重。表2給出了風險因子兩兩對比評價語言變量和三角模糊數(shù)之間的轉換關系,可以使用該轉換關系來評估風險因素的主觀權重向量。
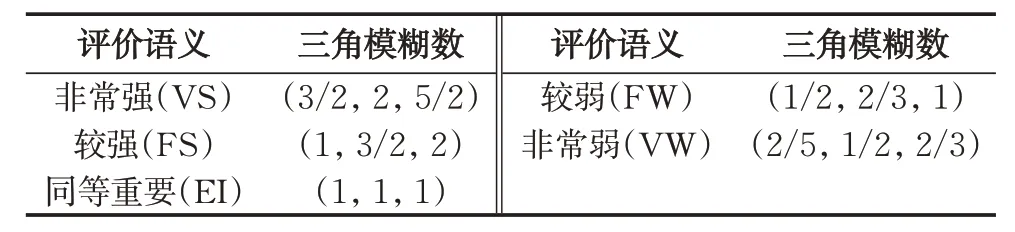
表2 風險因子評價語言變量對應三角模糊數(shù)Tab. 2 Risk factor evaluation linguistic variables corresponding to triangle triangular fuzzy numbers
獲得專家評分結果后,將其轉化為三角模糊數(shù),將第k個專家的模糊評價矩陣乘以相應權重相加后獲得兩兩比較矩陣,本文中對S、O、D 進行比較評分,最終得到兩兩對比矩陣如下:A?=(a?ij)n×n,其中每個a?ij均為一組三角模糊數(shù)(aij′,aij′′,aij′′′),a?ij=1/a?ji,由該矩陣獲得各個風險因子主觀權重的步驟如下[16]:
(1)計算第i個風險因子的模糊綜合程度:
(2)假設有兩個模糊綜合程度S1、S2,其中S1=(a?i1′,a?i1′′,a?i1′′′),S2=(a?i2′,a?i2′′,a?i2′′′),S2≥S1的可能性程度如式(9)中所定義:
式中:μs1(x)和μs2(y)分別為S1、S2的隸屬函數(shù)。
(3)一個三角模糊數(shù)S大于k個三角模糊數(shù)Si(i=1,...,k,k≠i)的可能性程度由式(10)計算:
(4)則n個風險因子的主觀權重為ws*j=(d′(A1),d′(A2),...,d′(An))T,其 中d′(Ai)=minV(Si≥Sj),j=1,2,...,n,j≠i。
歸一化后,得到各風險因子的主觀權重:
該方法從頭至尾的計算過程中均是三角模糊數(shù)在主導,沒有進行任何的轉化,對多元算子也沒有規(guī)避,使得思維的模糊性和不確定性的表述有了保障。
根據(jù)熵權法的原理,如果某一風險因子信息熵越大,那么它傳遞的決策者偏好信息越少,其權重也應較小;如果某一風險因子信息熵越小,那么它傳遞的決策者偏好信息越多,其權重也應較大。因此熵權法常用于獲取客觀權重,使用熵權法獲得客觀權重的步驟如下[17]:
(1)將風險因子的模糊評價矩陣去模糊化后得到風險因子的明確置信矩陣:X=(xij)m×n,其中,每個xij均為非模糊數(shù)。
(2)定義第j個風險因子的信息熵為
其中:
(3)計算各個風險因子的客觀權重:
組合權重通過集成主觀權重和客觀權重得到權重信息,它可以更精確地反映某一風險因子的重要性程度。在本文中,使用乘法合成法確定其組合權重,第j個風險因子的組合權重為
1.4 基于模糊VIKOR的FMEA失效模式排序
模糊VIKOR方法是VIKOR方法在模糊環(huán)境中的延伸,主要用于解決具有不可公度和沖突標準的離散模糊多準則問題[18]。因此本文應用模糊VIKOR 方法來確定各個失效模式的排序,步驟如下[18]:
(1)確定各個風險因子的最優(yōu)值和最劣值,由此確定:
(2)計算最大群體效應值S?i和最小個人遺憾值R?i:
其中為各風險因子的組合權重。
(3)計算綜合評價值Q?i:
(4)將值S?i、R?i、Q?i去模糊化后得到S、R、Q值并按遞減順序排序,產(chǎn)生三個序列。在獲得排序結果后,需要滿足以下兩個條件,才能使Q值最小的方案為最佳方案:(A)QA(2)-QA(1)≥1/(m-1),其中QA(1)是排序結果中最優(yōu)方案的Q值,QA(2)是排序結果中次優(yōu)方案的Q值,m為失效模式總數(shù)。(B)排序的穩(wěn)定性:最優(yōu)方案的S值或R值同樣也要最優(yōu),這樣才能確保Q值最小的方案為最優(yōu)方案。若上述條件不能同時滿足,則可得到妥協(xié)解,有如下2種情況: (C)若滿足條件(A),則獲得一組妥協(xié)解:A(1)、A(2)。(D)若不滿足條件(A)但滿足(B),則獲得一組妥協(xié)解:A(1)、...、A(M)。其中,M是根據(jù)式QA(M)-QA(1)<1/(m-1) 確定的最大化M值。
1.5 基于PAM聚類算法的FMEA失效模式分析
PAM(partition around medoids)算法又被稱為K-中心點算法。PAM 算法使用簇中非中心點到簇中心點的距離來衡量聚類效果,其復雜性很高但邏輯較簡單,所以適用于小型數(shù)據(jù)庫的聚類處理[19]。本文將使用失效模式的綜合評價值Q和RPN 值對失效模式進行聚類。PAM算法的步驟如下[20]:
(1) 在m個數(shù)據(jù)對象中隨機選擇k′個點,作為初始中心集。
(2) 計算每個非代表對象到各中心點的距離,將其分配給離其最近的簇中,本文使用歐式距離。
(3) 對于每個非中心對象Oh,依次執(zhí)行以下過程:用當前點Oh替換其中一個中心點Oi,并計算替換所產(chǎn)生的總代價函數(shù)若小于0,則替換,反之不替換中心點。代價函數(shù)依據(jù)每一個非選中對象Oj通過如下4種情況的不同公式進行計算:第一種情況:Oj當前屬于Oi為代表點的簇中,Oj2為Oj的第二接近中心點,且Oj離Oj2比Oh近,此時Cjih=d(Oj,Oj2)-d(Oj,Oi);第二種情況:Oj當前屬于Oi為代表點的簇中,Oj2為Oj的第二接近中心點,且Oj離Oh比Oj2近,此時Cjih=d(Oj,Oh)-d(Oj,Oi);第三種情況:Oj當前屬于另一個非Oi而是Oj2為代表點的簇中,且Oj離Oj2比Oh近,此時Cjih=0;第四種情況:Oj當前屬于另一個非Oi而是Oj2為代表點的簇中,且Oj離Oh比Oj2近,此時Cjih=d(Oj,Oh)-d(Oj,Oj2)。
(4) 得到一個k′個中心點的集合,根據(jù)最小距離原則重新將所有對象劃分到離其最近的簇中。
2 案例研究
本節(jié)對智能制造系統(tǒng)實際應用中的失效模式進行排序分析,尋找到4 位智能制造領域專家對各個失效模式的風險因子按照表1中提到的評分標準進行評分。專家一為智能制造系統(tǒng)實施顧問,專家二為信息化咨詢專家,專家三為信息化項目高級經(jīng)理,專家四為智能制造領域的高校學者。4 位專家分屬智能制造系統(tǒng)的不同領域,對同一失效模式會從不同的角度進行評判。
2.1 確定失效模式及其影響分析評估
工作分解結構法(work breakdown structure,WBS)可用于復雜的項目,通常采用從上至下的方法對項目進行逐層分解[21]。首先運用WBS 對智能制造系統(tǒng)從上至下進行分析,并結合頭腦風暴法、專家訪談和相關文獻梳理,對智能制造系統(tǒng)進行風險識別。初步將其劃分為ERP、MES和工廠控制層[22]三層結構,然后對各個層級進一步分析。本文將ERP 分為生產(chǎn)控制、物流管理、財務管理三大模塊,運用WBS對三個模塊進一步分解為生產(chǎn)計劃管理、物料需求計劃管理等6 個小模塊,如圖1 所示;制造執(zhí)行系統(tǒng)協(xié)會將MES 的經(jīng)典功能模型劃分為資源分配和狀態(tài)、運作/詳細調度等[23]共11 個模塊。同時添加MES 調整及拓展模塊,對MES 進行子模塊的劃分,得到最終子模塊如圖1所示。圖中BOM表示物料清單。通過咨詢相關專家,本文將工廠控制層劃分為生產(chǎn)設備和控制設備兩個模塊。最終匯總得到的智能制造系統(tǒng)WBS圖如圖1所示。
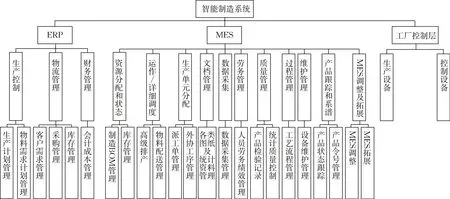
圖1 智能制造系統(tǒng)WBS圖Fig. 1 WBS diagram of intelligent manufacturing system
由于系統(tǒng)中會存在一些共同存在的失效模式,這些失效模式會對三大模塊都產(chǎn)生影響,將它們總結出來作為共有的失效模式,最終將智能制造系統(tǒng)失效模式及其后果和原因失效模式匯總得到表3。
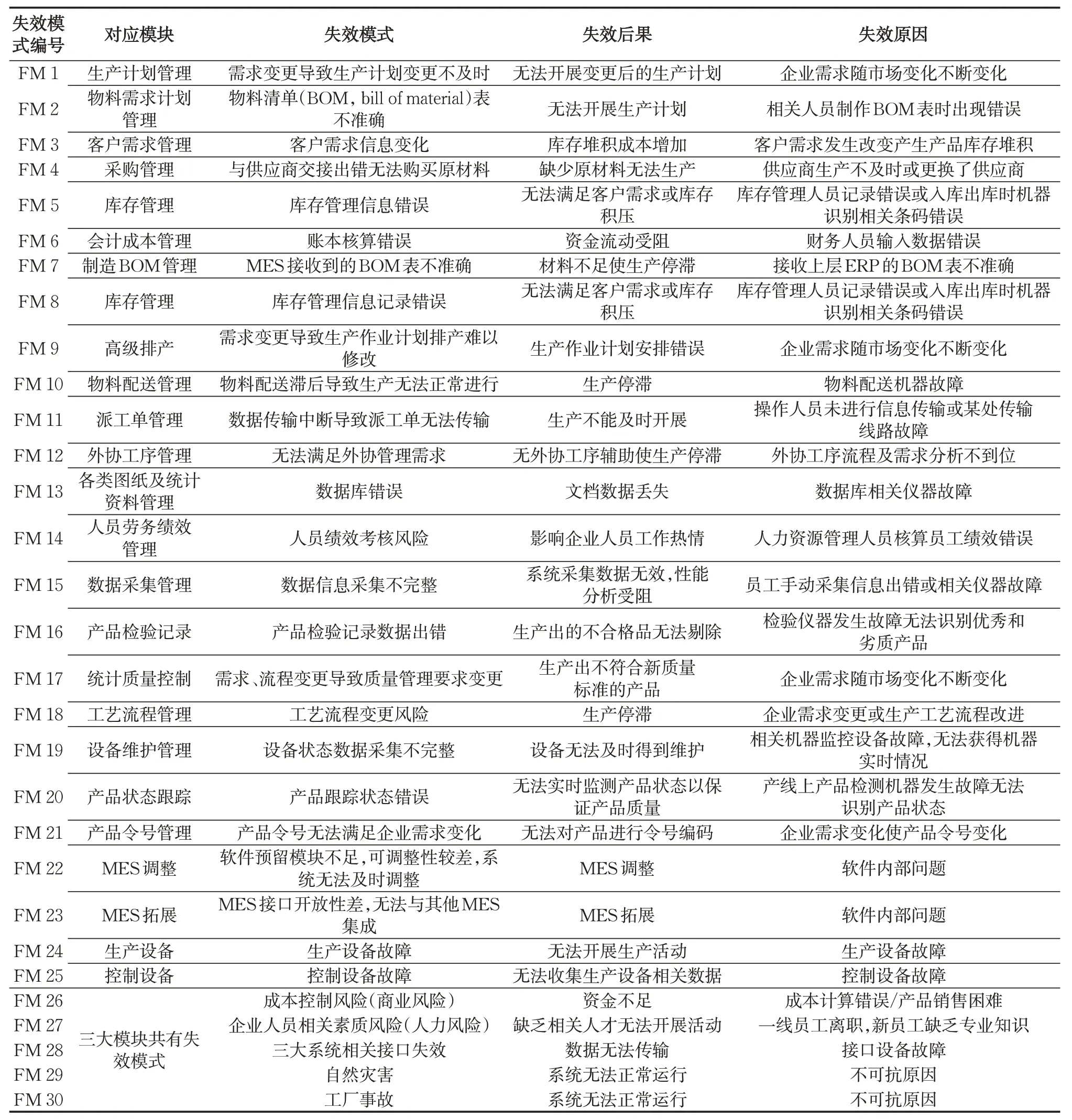
表3 智能制造系統(tǒng)失效模式及其后果和原因Tab. 3 Failure modes of intelligent manufacturing system and their consequences and causes
經(jīng)分析共得到智能制造系統(tǒng)中潛在的30 種失效模式,收集匯總各個專家的評分情況,得到表4。

表4 專家評分表Tab. 4 Expert rating table
2.2 確定風險排序
4位專家對失效模式進行評分后,使用式(1)—(7)可得到專家權重λ1=0.289 5,λ2=0.240 4,λ3=0.176 4,λ4=0.293 7。對風險因子使用表2進行兩兩比較評分,匯總后將第k個專家的模糊評價矩陣乘以相應權重相加后獲得兩兩比較矩陣,如表5所示。
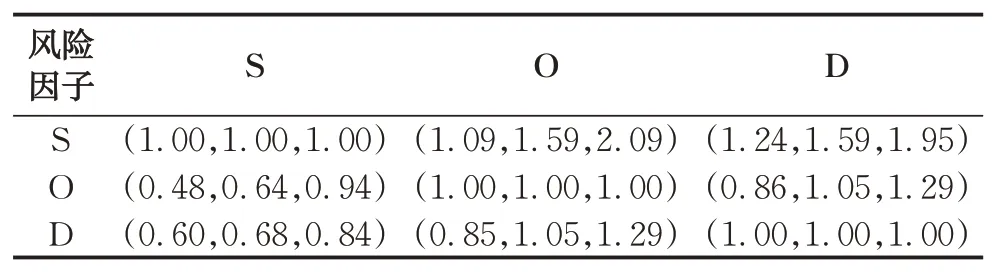
表5 風險因子兩兩比較矩陣Tab. 5 Pairwise comparison matrix of risk factors
使用式(8)—(11)可得風險因子的主觀權重為=(0.592, 0.210, 0.198)。再按照式(12)—(14)可得各個風險因子的客觀權重為=(0.146 2,0.464 7, 0.389 1)。將主客觀權重代入式(15),可得組合權重=(0.331 5, 0.373 9, 0.294 6)。
使用模糊VIKOR方法對失效模式進行排序,首先按照式(16)確定各個風險因子的模糊最優(yōu)、最劣值,本文取最大評價值為模糊最優(yōu)值。再按照式(17)—(19)計算各個失效模式的S?i、R?i和Q?i值。按照式(1)對其進行去模糊化,得到S,R,Q值的明確值,并以此進行從小到大的排序,得到表6。其中QA(2)-QA(1)=0.002 3≤1/29≈0.345,可知FM26 不滿足條件(A),由于QA(3)-QA(1)=0.034 1≤1/29,QA(4)-QA(1)=0.040>1/29,所以得到妥協(xié)解FM26、FM20、FM23。由于要對失效模式進行排序,F(xiàn)M23的Q值與FM26之差接近閾值,且除在S值中排名較前,R和Q值中排名都靠后,因此失效模式排序為FM20和FM26并列第一,F(xiàn)M23第三。
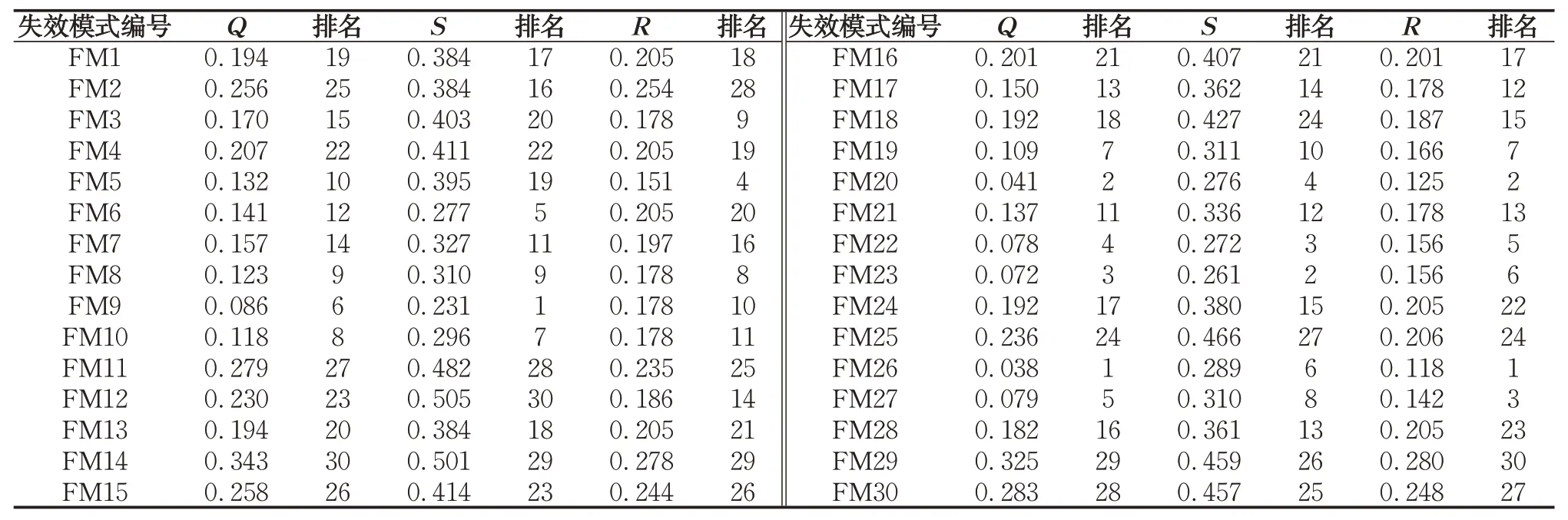
表6 失效模式明確Q, S, R值Tab. 6 Explicit Q, S, and R values of failure modes
根據(jù)傳統(tǒng)FMEA模型計算RPN值,通過由傳統(tǒng)FMEA 得到的RPN 值歸一化后和改進FMEA 得到的綜合評價值Q進行PAM聚類分析,將失效模式聚為3 類,通過python3.9 聚類結果如圖2 所示。圖中“Cluster1”、“Cluster2”、“Cluster3”是由聚三類得到的三個簇,“Cluster Center”標注了每個簇對應的聚類中心所在位置。
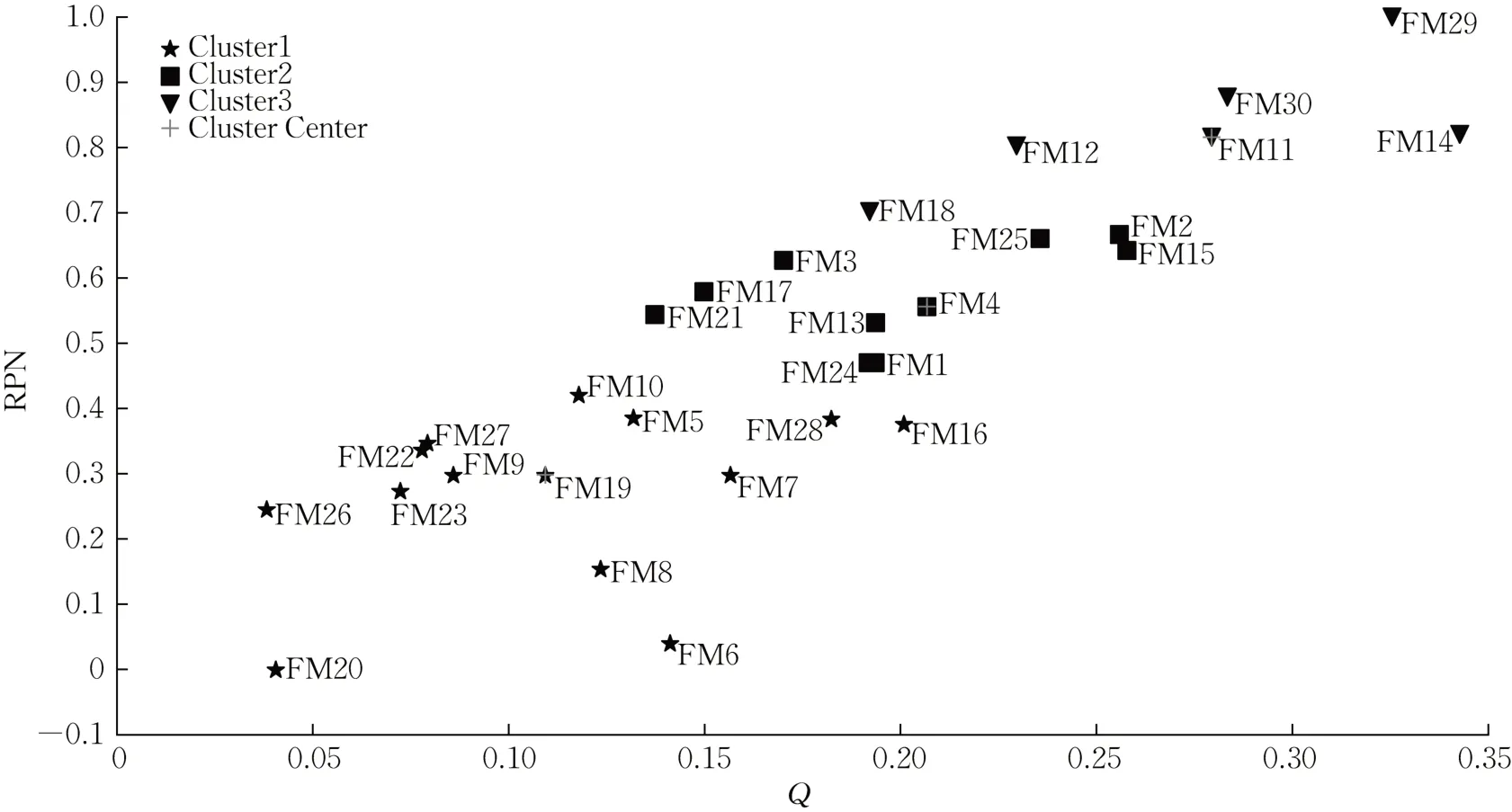
圖2 改進FMEA的PAM聚類結果圖Fig. 2 Results of PAM clustering of improved FMEA
分別按照傳統(tǒng)FMEA模型的RPN值、僅用熵權法改進的FMEA 模型(根據(jù)式(12)—(14)計算)、僅用VIKOR 改進的FMEA 模型、僅用三角模糊數(shù)改進的FMEA模型(根據(jù)式(1)計算)對失效模式進行排序,得到4 組排序并與改進FMEA 得到的排序進行匯總對比,得到表7。
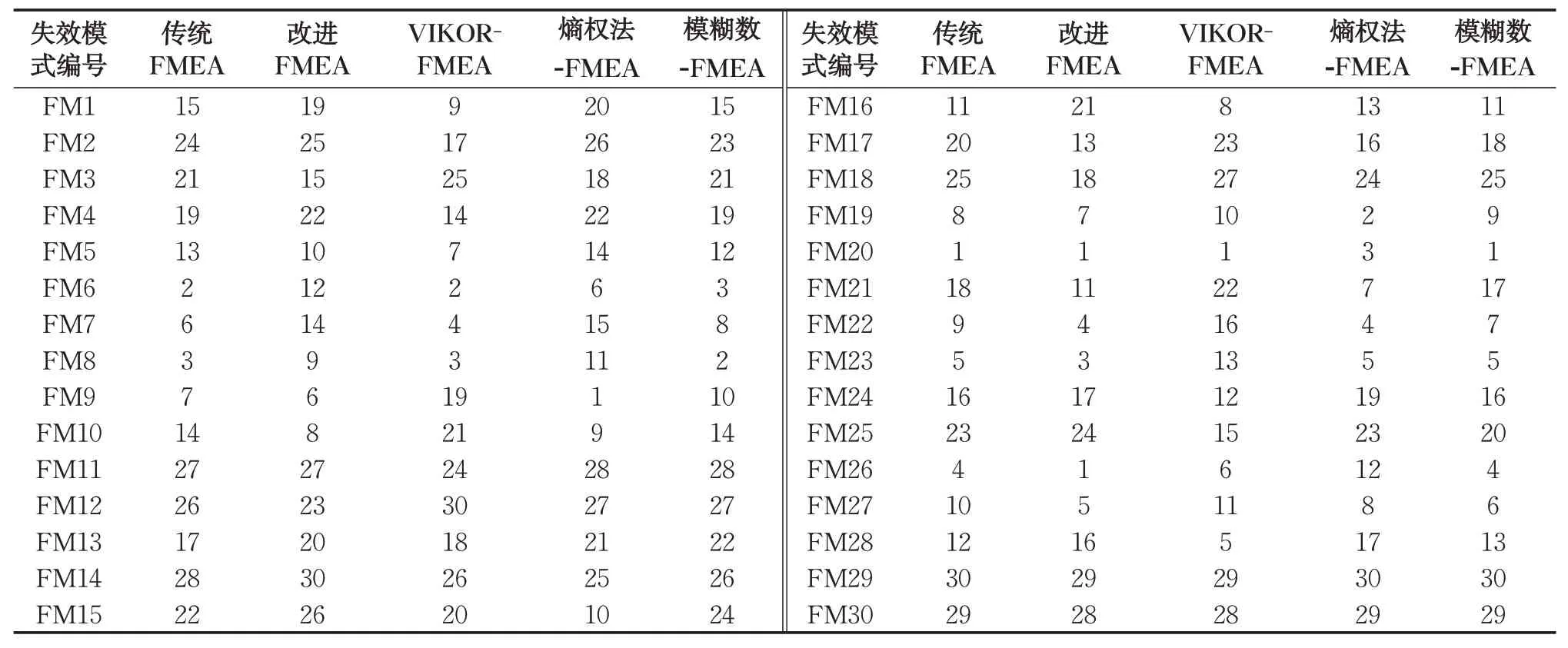
表7 改進FMEA與傳統(tǒng)FMEA、VIKOR-FMEA、熵權法-FMEA、模糊數(shù)-FMEA排序對比Tab. 7 Comparison of improved FMEA with traditional FMEA, VIKOR-FMEA, entropy weight method-FMEA,and fuzzy number-FMEA
2.3 對風險排序進行比較分析
將傳統(tǒng)FMEA、改進FMEA、VIKOR-FMEA、熵權法-FMEA、模糊數(shù)-FMEA 的排序結果匯總到圖3 中。
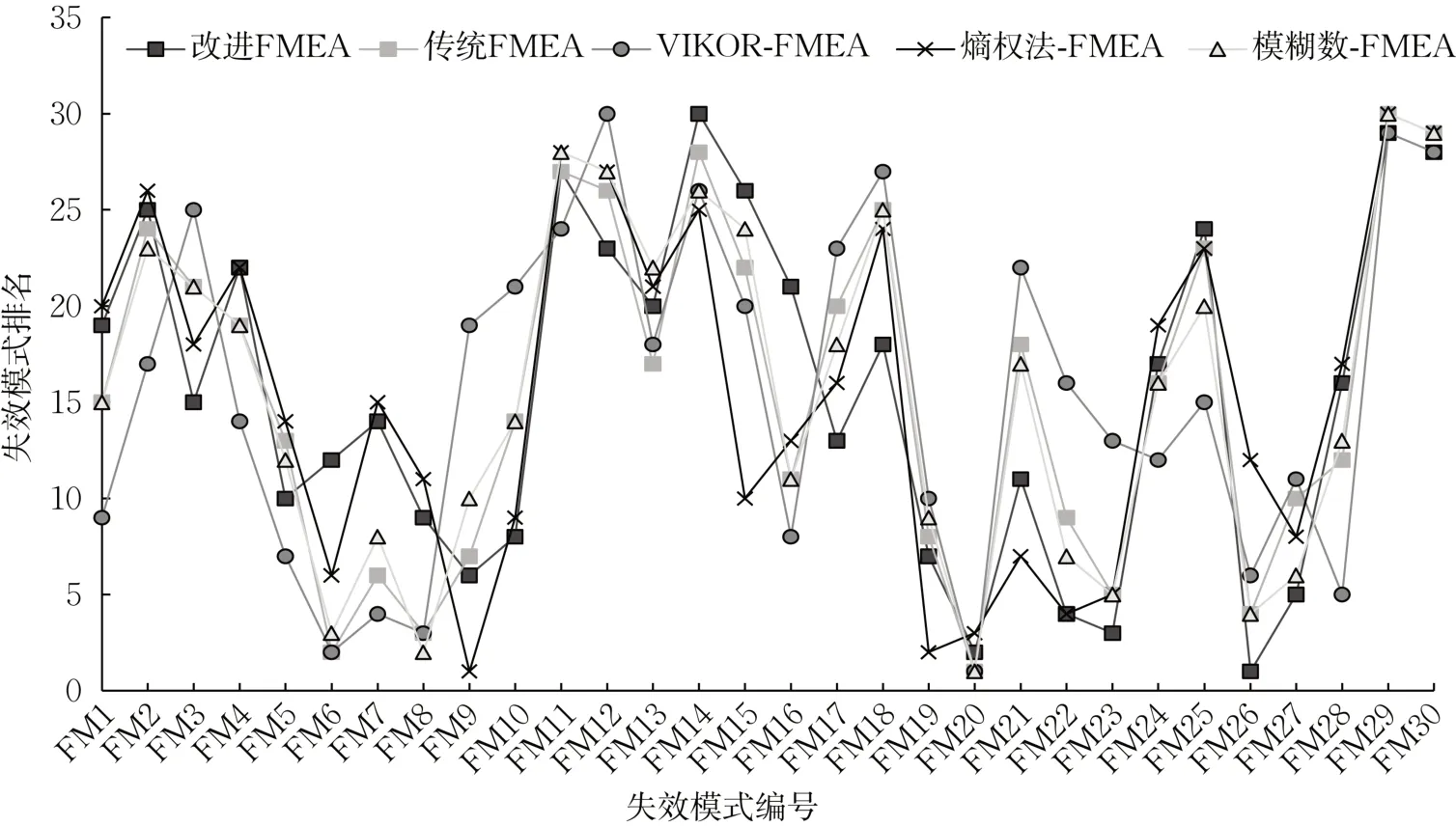
圖3 改進FMEA、傳統(tǒng)FMEA、VIKOR-FMEA、熵權法-FMEA、模糊數(shù)-FMEA排序結果對比圖Fig. 3 Comparison of ranking results between improved FMEA, traditional FMEA, VIKOR-FMEA, entropy weight method-FMEA, and fuzzy number-FMEA
從圖3可以看出,改進后FMEA和傳統(tǒng)FMEA以及其他中間模型的排序結果總體而言有一定的一致性,尤其是靠前和靠后的失效模式,說明改進后FMEA模型的有效性。在某些關鍵的失效模式排序上,改進模型相較其他模型有一定的改善。改進模型與3個中間模型對比排序也各有不同,與只運用三角模糊數(shù)進行改進的FMEA模型取得的結果進行對比,F(xiàn)M6和FM8的排名相差較多,主要原因是FM6和FM8各個專家評分不一致,因此在無專家權重的情況下,每一個專家賦予相同的權重導致最后結果偏離團隊多數(shù)成員對失效模式評估偏好,從而使結果出現(xiàn)偏差。只運用熵權法改進的FMEA與改進模型有諸多不同,如FM9、FM15、FM19、FM21、FM26都與其他4種模型有明顯的排名差異,究其原因,僅用熵權法進行風險因子的權重計算后得到的客觀權重與實際情況有一定差異,其發(fā)生度占比過高,嚴重度占比過低,可能是由于熵權法中發(fā)生度對應的信息熵較低,各個失效模式之間的發(fā)生度差異程度較大從而導致賦權較高,而嚴重度對應的信息熵較高,各個失效模式之間的嚴重度差異度不大而導致賦權較低,進而導致最后的排序與其余4個模型的排序明顯不同。改進模型與僅用VIKOR法進行改進的FMEA模型取得的結果進行對比,其中FM2、FM12等多種失效模式都有明顯不同,究其原因,僅用VIKOR法進行改進缺少專家權重和風險因子權重的計算以及模糊理論的應用。賦予專家相同的權重使得評價矩陣可能因為一個專家的分數(shù)與平均值相差過多而帶來整體評估的浮動,以及風險因子的權重相同進行計算與實際情況有一定的偏差,模糊理論的缺失也使得評估值偏差較大,導致計算出的最大群體效應值和最小個體遺憾值與實際有一定的偏差,最終使得計算得到的綜合評價值排序與其余模型的排序有一定的差距。
本文基于TOPSIS 法的思想計算專家權重,使用模糊理論對S、O、D 三個風險因子的評估進行改進,獲得更符合實際情況的評價矩陣;將FAHP法和熵權法相結合,對風險因子的權重進行改進;使用模糊VIKOR方法對失效模式進行排序,使排序結果更加準確。因此,改進后的FMEA方法在實際應用時具有更好的準確性和靈活性。
2.4 對失效模式進行分析和改善建議
由圖3可知,F(xiàn)M20作為幾個模型中綜合最靠前的失效模式,其內(nèi)容為產(chǎn)品跟蹤狀態(tài)錯誤。產(chǎn)品跟蹤狀態(tài)錯誤將會對整個系統(tǒng)的各個模塊銜接和運作造成嚴重影響,因此在今后系統(tǒng)管理過程中應提高對產(chǎn)品跟蹤狀態(tài)進行檢查的頻率或使用更為創(chuàng)新的工具進行故障檢測。FM26作為改進模型下的并列第一,其內(nèi)容為成本控制風險(商業(yè)風險),因此在今后系統(tǒng)管理過程中應當對整個系統(tǒng)的成本控制投入更多的精力和增強對各個環(huán)節(jié)的把控以盡量減少商業(yè)風險。
對失效模式發(fā)生的原因,通過系統(tǒng)分析上述失效模式并與專家訪談確認,將失效原因分為5個種類:網(wǎng)絡傳輸錯誤、人為操作失誤、硬件機器故障、軟件內(nèi)部錯誤、管理層次風險。通過對失效模式由傳統(tǒng)FMEA 得到的RPN 值和改進FMEA 得到的綜合評價值Q進行PAM聚類分析,將失效模式聚為3類,得到的結果由圖2所示。經(jīng)過對失效模式的原因進行追溯分析,“Cluster1”,“Cluster2”以及“Cluster3”的失效原因涵蓋全部5種原因并涉及智能制造系統(tǒng)的三個層級。“Cluster1”包含F(xiàn)M5,F(xiàn)M6,F(xiàn)M7,F(xiàn)M8,F(xiàn)M9,F(xiàn)M10,F(xiàn)M16,F(xiàn)M19,F(xiàn)M20,F(xiàn)M22,F(xiàn)M23,F(xiàn)M26,F(xiàn)M27,F(xiàn)M28,這一類的RPN值很高,Q值很低,這說明其對智能制造系統(tǒng)的運行有著強烈的影響,應投入最大的資源進行防范與監(jiān)控,經(jīng)過對失效模式的原因進行追溯分析,其中較為主要的原因就是硬件機器故障和網(wǎng)絡傳輸錯誤,今后應當通過增強員工備份意識和定期對硬件進行檢測和優(yōu)化從而得到適當?shù)馗纳啤!癈luster2”包含F(xiàn)M1,F(xiàn)M2,F(xiàn)M3,F(xiàn)M4,F(xiàn)M13,F(xiàn)M15,F(xiàn)M17,F(xiàn)M21,F(xiàn)M24,F(xiàn)M25,這一類失效模式的RPN值與綜合評價值Q皆處于中等水平,說明其對智能制造系統(tǒng)的影響不及前一個失效模式簇,對其的防范與監(jiān)控不必投入過多的資源,“Cluster2”中較為主要的失效原因是軟件內(nèi)部錯誤、人為操作失誤以及管理層次風險,為避免軟件內(nèi)部錯誤,需注意定期對軟件進行升級優(yōu)化和及時進行備份。針對人為操作失誤,可以通過加強員工對故障的防范意識得到改善。針對管理層次風險,可以要求管理層的決策要慎之又慎從而得到改善。“Cluster3”包含F(xiàn)M11,F(xiàn)M12,F(xiàn)M14,F(xiàn)M18,F(xiàn)M29,F(xiàn)M30,這一類的RPN值很低,Q值很高,說明其對智能制造系統(tǒng)運行的影響較弱,對其的防范與監(jiān)控適當投入資源即可。“Cluster3”中較為主要的原因有管理層次風險和很難被分類的自然災害。自然災害極少發(fā)生,管理過程中可以盡量減少對其資源的投入,但是也需要做好預案,發(fā)生時能夠及時響應減少損失。
3 結語
本文通過全面的文獻梳理和專家訪談總結出了智能制造系統(tǒng)中存在的或潛在的主要失效模式,隨后綜合運用逼近理想解排序法思想、三角模糊數(shù)、FAHP法、熵權法、乘法合成法和模糊VIKOR法以及PAM 聚類算法建立基于改進FMEA 的智能制造系統(tǒng)可靠性與風險評估模型。通過與傳統(tǒng)FMEA、中間模型結果對比分析表明,本文所改進的FMEA模型對智能制造系統(tǒng)失效模式的風險排序更為合理準確,可為智能制造系統(tǒng)可靠性與風險評估管理人員提供積極的決策建議,進而促進我國傳統(tǒng)企業(yè)向智能工廠轉型升級。本文對智能制造系統(tǒng)的失效模式進行了系統(tǒng)分析,提出了基于改進FMEA和PAM聚類的智能制造系統(tǒng)可靠性與風險評估模型,所提出模型相較于傳統(tǒng)FMEA有一定的優(yōu)勢,但仍存在一些不足:比如,失效模式的識別可能還不夠全面,本文的失效模式是通過系統(tǒng)梳理智能制造系統(tǒng)相關研究和專家訪談總結確定的,雖已盡可能的接近實際情況,但智能制造系統(tǒng)結構十分復雜,相關機器設備等都結合了最新的技術,隨著技術的進步與發(fā)展,所識別的失效模式仍可能不夠全面。伴隨著智能制造的不斷發(fā)展,F(xiàn)MEA 作為一種廣泛使用的可靠性設計與分析工具,今后的研究中應更加注重以技術導向代替頭腦風暴來確定失效模式,使失效模式的評估更加客觀。
作者貢獻聲明:
段春艷:負責論文研究概念、技術路線和方案的提出,把握論文的邏輯結構,修改論文。
王佳潔:完成論文方法的創(chuàng)新改進,數(shù)據(jù)的計算和論文初稿的撰寫與修改。
王浩博:收集研究數(shù)據(jù)、分析數(shù)據(jù)。
張文娟:指導論文的撰寫和修改。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2022年11期)2022-02-14 07:14:12
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
