面向工業(yè)過(guò)程的圖像生成及其應(yīng)用研究綜述
2024-03-04 02:04:12郭海濤喬俊飛
自動(dòng)化學(xué)報(bào) 2024年2期
湯 健 郭海濤 夏 恒 王 鼎 喬俊飛
工業(yè)物聯(lián)網(wǎng)、大數(shù)據(jù)、人工智能、云計(jì)算等新一代信息技術(shù)的發(fā)展,使得工業(yè)過(guò)程能夠在傳統(tǒng)的控制與決策基礎(chǔ)上融入視覺(jué)感知信息[1].目前,計(jì)算機(jī)視覺(jué)模型已能夠依據(jù)工業(yè)圖像建立運(yùn)行工況識(shí)別模型、產(chǎn)品質(zhì)量檢測(cè)模型和難測(cè)參數(shù)量化模型[2-4],這些模型對(duì)復(fù)雜工業(yè)環(huán)境適應(yīng)能力的強(qiáng)弱通常是決定其能否實(shí)際應(yīng)用的關(guān)鍵[5].
基于深度學(xué)習(xí)(Deep learning,DL)的視覺(jué)感知模型已在諸多領(lǐng)域得到廣泛應(yīng)用[6-9],其具有以下優(yōu)勢(shì): 1)能夠自動(dòng)學(xué)習(xí)特征;2)能夠獲得具有完備性和非冗余性、強(qiáng)于人工獲取方式的特征;3)能夠?qū)W習(xí)復(fù)雜問(wèn)題的非線性可分“分界面”;4)具有通用的問(wèn)題解決思路和技術(shù)框架.復(fù)雜工業(yè)過(guò)程中的圖像存在可解釋性差、干擾性強(qiáng)、標(biāo)記成本高等問(wèn)題,這導(dǎo)致大量數(shù)據(jù)難以有效使用[10],使得視覺(jué)感知模型在應(yīng)用中存在識(shí)別精度低、魯棒性差等現(xiàn)狀[11].以城市固廢焚燒(Municipal solid wastes incineration,MSWI) 過(guò)程[12]為例,存在的問(wèn)題包括[13]:1)燃燒過(guò)程中固有的飛灰、高溫等因素使得火焰圖像清晰度差;2)在爐排前端和后端進(jìn)行燃燒的極端異常火焰圖像稀缺;3)物料組分的不可控性和控制參數(shù)的波動(dòng)性導(dǎo)致火焰圖像的可解釋性差;4)火焰圖像難以標(biāo)記.因此,該領(lǐng)域?qū)σ曈X(jué)信息的處理依然依靠運(yùn)行專家,存在難以避免的主觀性和隨意性[14].可見(jiàn),因存在異常圖像稀缺、圖像對(duì)比度低和噪聲干擾大等問(wèn)題,常用視覺(jué)模型難以適用于具有強(qiáng)污染、多噪聲和圖像類別不完備等特性的工業(yè)過(guò)程.顯然,實(shí)際訓(xùn)練集的分布不符合期望全集分布已成為制約計(jì)算機(jī)視覺(jué)應(yīng)用和發(fā)展的主要因素之一.
如何獲取符合期望分布的訓(xùn)練圖像集仍是一個(gè)開(kāi)放性的難題.圖像生成[15]是解決該難題的方法之一.目前,已有的相關(guān)研究包括: 文獻(xiàn)[16-17]闡述玻爾茲曼機(jī)研究進(jìn)展,包括亥姆霍茲?rùn)C(jī)、深度玻爾茲曼機(jī)(Deep Boltzmann machines,DBM)和深度置信網(wǎng)絡(luò)(Deep belief network,DBN)等;文獻(xiàn)[18]梳理傳統(tǒng)自編碼器(Auto-encoder,AE)模型及其衍生變體模型的研究現(xiàn)狀、分析其存在的問(wèn)題與挑戰(zhàn)和展望未來(lái)的發(fā)展趨勢(shì);文獻(xiàn)[19-21]概述生成對(duì)抗網(wǎng)絡(luò)(Generative adversarial networks,GAN)的基本思想、梳理相關(guān)理論與應(yīng)用研究;文獻(xiàn)[22]根據(jù)似然函數(shù)處理方法對(duì)深度生成模型進(jìn)行分類,包括基于受限玻爾茲曼機(jī)(Restricted Boltzmann machines,RBM)、變分AE (Variational AE,VAE)的近似方法[23]、能夠避免求極大似然過(guò)程的諸如GAN的隱式方法、對(duì)似然函數(shù)進(jìn)行適當(dāng)變形的流模型和自回歸模型;文獻(xiàn)[24]介紹基于去噪擴(kuò)散概率模型(Denoising diffusion probabilistic models,DDPMs)[25-26]、噪聲條件分?jǐn)?shù)網(wǎng)絡(luò)(Noise conditioned score networks,NCSNs)[27]和隨機(jī)微分方程(Stochastic differential equations,SDEs)[28]3 種通用擴(kuò)散模型框架,并討論與其他深度生成模型的關(guān)系.但是,這些文獻(xiàn)綜述主要聚焦于圖像生成在計(jì)算機(jī)領(lǐng)域的應(yīng)用,其核心問(wèn)題是如何更好地?cái)M合訓(xùn)練集的概率密度分布.因工業(yè)過(guò)程具有強(qiáng)污染、多噪聲和不確定等特性而使得圖像生成更加復(fù)雜,其核心在于: 如何結(jié)合過(guò)程機(jī)理,借助小樣本集“創(chuàng)造”出期望的圖像集.因此,有必要結(jié)合工業(yè)過(guò)程的實(shí)際特性,針對(duì)性地對(duì)工業(yè)圖像生成及其應(yīng)用研究進(jìn)行綜述.
本文面向?qū)嶋H需求,對(duì)工業(yè)過(guò)程圖像生成、生成圖像評(píng)估與應(yīng)用進(jìn)行綜述,主要貢獻(xiàn)包括: 1)梳理面向工業(yè)過(guò)程的圖像生成技術(shù)和工業(yè)領(lǐng)域潛在圖像生成技術(shù);2)結(jié)合圖像生成領(lǐng)域的研究成果,面向?qū)嶋H工業(yè)過(guò)程需求,依據(jù)流程將現(xiàn)有算法從工業(yè)圖像生成、生成圖像評(píng)估和應(yīng)用3 個(gè)方面進(jìn)行綜述;3)提出面向工業(yè)過(guò)程圖像生成及其應(yīng)用的未來(lái)研究方向與挑戰(zhàn).
1 面向工業(yè)過(guò)程的圖像生成技術(shù)
1.1 圖像生成的定義與分類
圖像生成的目標(biāo)函數(shù)如下
式中,G*表示最優(yōu)生成模型,pG和pdata表示生成數(shù)據(jù)和真實(shí)數(shù)據(jù)的概率分布,Div(·) 表示散度.
由式(1)可知,圖像生成的定義為: 尋找生成模型參數(shù),使生成的數(shù)據(jù)與真實(shí)的數(shù)據(jù)概率分布的散度最小.本文給出如圖1 所示的深度生成模型分類框架.
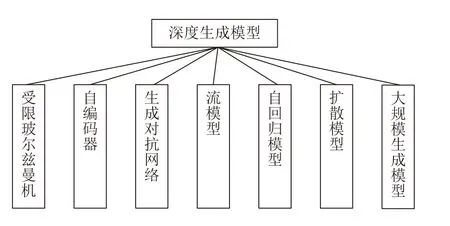
圖1 深度生成模型分類Fig.1 Classification of deep generation model
由圖1 可知,深度生成模型包括: 1)受限玻爾茲曼機(jī)[29]及以其為基礎(chǔ)模塊的深度置信網(wǎng)絡(luò)[30]、深度玻爾茲曼機(jī)[31]等模型;2)自編碼器及其改進(jìn)模型;3)生成對(duì)抗網(wǎng)絡(luò)[32]以及改進(jìn)模型;4)以非線性獨(dú)立分布估計(jì)(Non-linear independent components estimation,NICE)為基礎(chǔ)的常規(guī)流(Normalizing flow)模型[33]及其改進(jìn)模型;5)包括神經(jīng)自回歸密度估計(jì)(Neural autoregressive distribution estimation,NADE)[34]、像素循環(huán)神經(jīng)網(wǎng)絡(luò)(Pixel recurrent neural network,PixelRNN)[35]、掩碼AE 分布估計(jì)(Masked AE for distribution estimation,MADE)[36]以及WaveNet[37]等在內(nèi)的自回歸模型;6)擴(kuò)散模型以及其改進(jìn)模型;7)以ChatGPT 和GPT-4 為代表的大規(guī)模生成模型.
在上述模型中,用于圖像生成的GAN、AE、流模型和擴(kuò)散模型的論文出版情況如圖2~5 所示.

圖2 GAN 模型論文出版情況Fig.2 Publication status of GAN model

圖3 AE 模型論文出版情況Fig.3 Publication status of AE model

圖4 流模型論文出版情況Fig.4 Publication status of flow-based model
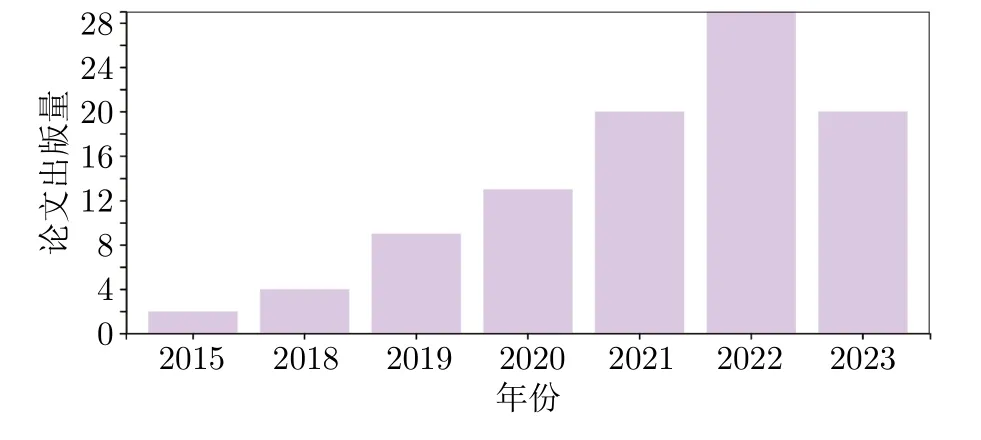
圖5 擴(kuò)散模型論文出版情況Fig.5 Publication status of diffusion model
1.2 面向工業(yè)過(guò)程的圖像生成定義
面向工業(yè)過(guò)程的圖像生成任務(wù)可表示為
式中,Gind*表示最優(yōu)的生成模型,表示工業(yè)過(guò)程生成數(shù)據(jù)的概率分布,表示真實(shí)數(shù)據(jù)的概率分布.
1.3 面向工業(yè)過(guò)程的圖像生成及應(yīng)用流程
面向復(fù)雜工業(yè)過(guò)程的圖像生成及其應(yīng)用流程如圖6 所示.
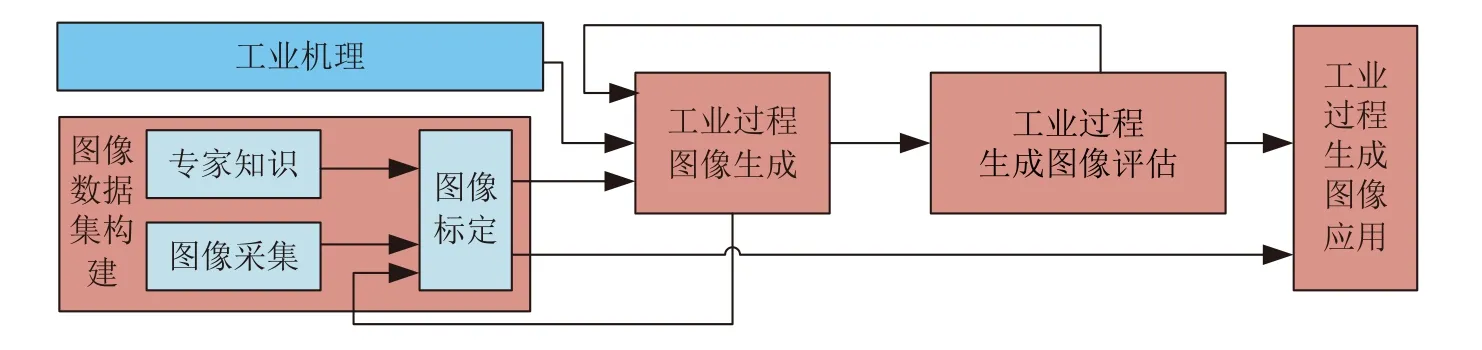
圖6 面向工業(yè)過(guò)程的圖像生成及應(yīng)用流程Fig.6 Image generation and application process for industrial process
由圖6 可知,具體流程為: 首先,構(gòu)建圖像數(shù)據(jù)集,主要包括圖像采集和基于專家知識(shí)的圖像標(biāo)定;然后,針對(duì)真實(shí)圖像數(shù)據(jù)存在的問(wèn)題,結(jié)合工業(yè)機(jī)理構(gòu)建圖像生成模型;接著,定性或定量評(píng)估生成圖像的質(zhì)量和多樣性并選擇合格圖像,若再次進(jìn)行圖像生成仍不滿足要求,重新通過(guò)圖像采集和圖像標(biāo)定構(gòu)建圖像數(shù)據(jù)集;最后,構(gòu)建基于生成和真實(shí)圖像的數(shù)據(jù)集以進(jìn)行生成圖像應(yīng)用.
本文重點(diǎn)關(guān)注工業(yè)過(guò)程圖像的生成模型構(gòu)建、生成圖像評(píng)估和應(yīng)用等方面.
1.4 面向工業(yè)過(guò)程的生成圖像評(píng)估框架
雖然生成模型,特別是GAN,得到了廣泛的關(guān)注,但如何對(duì)所生成的圖像進(jìn)行評(píng)估和選擇仍然是待解決的開(kāi)放性問(wèn)題.面向生成圖像的評(píng)估模型架構(gòu)[38]如圖7 所示.

圖7 對(duì)生成圖像的評(píng)估架構(gòu)Fig.7 Evaluation architecture for generated images
傳統(tǒng)生成圖像的評(píng)估框架為: 先將真實(shí)圖像集和生成圖像集進(jìn)行特征提取,再對(duì)所提取的特征向量進(jìn)行度量計(jì)算.該評(píng)估框架涉及多種不同的特征提取網(wǎng)絡(luò)和度量準(zhǔn)則.以真實(shí)圖像集Xr、生成圖像集Xg和特征提取器為輸入,以度量準(zhǔn)則FID (Fréchet inception distance)值為輸出的評(píng)估過(guò)程為: 首先,加載特征提取器提取兩個(gè)圖像集的特征矩陣zr與zg;然后,計(jì)算特征矩陣的多元正態(tài)分布均值μr與μg以及協(xié)方差矩陣Covr與Covg;接著,計(jì)算矩陣的跡 Tr(·);最后,根據(jù)式(3)計(jì)算FID 值
這類算法旨在度量生成數(shù)據(jù)集與真實(shí)數(shù)據(jù)集之間的相似度.
1.5 面向工業(yè)過(guò)程的圖像生成應(yīng)用需求
目前,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network,CNN)是視覺(jué)領(lǐng)域的主要研究方向.例如,文獻(xiàn)[39]結(jié)合CNN 和圖像分割定位變壓器內(nèi)部熱缺陷的故障;文獻(xiàn)[40]改進(jìn)CNN 以預(yù)測(cè)設(shè)備部件的坐標(biāo)、方向角和類別類型;文獻(xiàn)[41]在CNN 中引入局部聚集描述符向量以增加特征表示的魯棒性和增強(qiáng)識(shí)別模型的精度.但是,以CNN 為代表的監(jiān)督網(wǎng)絡(luò)模型的準(zhǔn)確率常取決于訓(xùn)練樣本標(biāo)簽的質(zhì)量與規(guī)模.
工業(yè)過(guò)程的圖像采集設(shè)備長(zhǎng)期處于強(qiáng)干擾環(huán)境中,這導(dǎo)致圖像的獲取和標(biāo)定存在困難[14];此外,數(shù)據(jù)的不均衡分布也是工業(yè)過(guò)程中的常見(jiàn)問(wèn)題[42-43].諸多研究表明,在數(shù)據(jù)分布不平衡的情況下,數(shù)據(jù)增強(qiáng)處理有助于提高模型性能[44-46].傳統(tǒng)數(shù)據(jù)增強(qiáng)是通過(guò)幾何變換(如平移、縮放和旋轉(zhuǎn))和通道變換合成圖像[47],其局限性在于無(wú)法真實(shí)地創(chuàng)建新的樣本,所生成的樣本仍然受限于原始數(shù)據(jù)的范圍和特征.圖像生成技術(shù)采用GANs、VAEs 或DDPMs 等生成模型,能夠更加逼真地生成新樣本,結(jié)合工業(yè)領(lǐng)域特有的機(jī)理知識(shí),理論上能夠創(chuàng)造出更豐富、更貼近真實(shí)的數(shù)據(jù)樣本,能夠擴(kuò)展數(shù)據(jù)的多樣性和覆蓋范圍,進(jìn)而能夠在訓(xùn)練過(guò)程中更好地捕捉數(shù)據(jù)分布的細(xì)微特征以提升模型的泛化能力.
針對(duì)復(fù)雜工業(yè)過(guò)程中的圖像存在可解釋性差、干擾性強(qiáng)、標(biāo)記成本高等問(wèn)題,其圖像生成方法可從以下角度進(jìn)行分析研究: 1)樣本分布不均問(wèn)題,正常和異常數(shù)據(jù)分布存在嚴(yán)重偏差[48];2)樣本多樣性問(wèn)題,極端異常的圖像缺失;3)樣本可解釋性問(wèn)題,特定圖像在不同程度上與工業(yè)機(jī)理相關(guān).
2 工業(yè)領(lǐng)域潛在圖像生成相關(guān)技術(shù)
GAN、VAE、流模型、PixelRNN 和擴(kuò)散模型等算法及其變體在工業(yè)領(lǐng)域的圖像生成中均具有潛在應(yīng)用前景.
2.1 GAN
GAN 由生成器G和判別器D組成,前者通過(guò)隨機(jī)噪聲z生成圖像,后者判斷輸入圖像為真的概率.具體而言,G與D是相互競(jìng)爭(zhēng)的判別過(guò)程和欺騙過(guò)程,前者為D判別圖像真假時(shí)的參數(shù)更新過(guò)程,后者為G企圖欺騙D時(shí)通過(guò)D的損失更新G的過(guò)程.GAN 的目標(biāo)函數(shù)如下
式中,V(D,G) 表示真實(shí)數(shù)據(jù)與生成數(shù)據(jù)的差異程度,下標(biāo) r 表示真實(shí)數(shù)據(jù),pr和pz表示真實(shí)數(shù)據(jù)的概率分布和z服從的高斯分布.
為便于GAN 的數(shù)學(xué)描述,采用下標(biāo) g 表示生成數(shù)據(jù)的概率分布.假設(shè)真實(shí)數(shù)據(jù)和生成數(shù)據(jù)的概率分布pr和pg為定值,D可擬合任意函數(shù).
首先,考慮任何給定G,求解最佳D,即D*.訓(xùn)練D時(shí),固定G的參數(shù),在 m axD V(D,G) 的過(guò)程中,D*表示如下
然后,假設(shè)每輪D均是最優(yōu)的且G可擬合任意函數(shù).此時(shí),固定判別網(wǎng)絡(luò)參數(shù),更新生成網(wǎng)絡(luò)參數(shù),m inG V(D,G) 的結(jié)果如下
式中,DJS為JS (Jensen-Shannon)散度.由式(6)可得pg=pr為最優(yōu)解,即生成器能夠擬合真實(shí)數(shù)據(jù)的概率分布.
最后,G根據(jù)其學(xué)習(xí)到的概率分布生成符合真實(shí)數(shù)據(jù)概率分布的新樣本.
GAN 利用判別器的特性避開(kāi)了求解似然函數(shù)的復(fù)雜過(guò)程,這使得GAN 非常靈活且適用性強(qiáng),其代表模型包括DCGAN、WGAN 和BigGAN 等.GAN 的變體模型如表1 所示.

表1 基于GAN 的變體Table 1 Variants based on GAN
2.2 VAE
VAE 由編碼器和解碼器組成,其核心理念是學(xué)習(xí)潛在的空間.理論上,空間中的每個(gè)點(diǎn)均對(duì)應(yīng)著數(shù)據(jù)的一個(gè)潛在表示,進(jìn)而可在空間中進(jìn)行數(shù)據(jù)的插值、生成和探索.VAE 的簡(jiǎn)要過(guò)程為: 首先,編碼器將輸入數(shù)據(jù)映射到潛在空間中的概率分布,即將輸入數(shù)據(jù)轉(zhuǎn)換為潛在變量的均值μ和標(biāo)準(zhǔn)差σ以表征該分布;然后,采用重參數(shù)化技巧對(duì)該分布進(jìn)行可微分采樣以獲得潛在變量;最后,解碼器接收在潛在空間采樣的潛在變量并將其映射回原始數(shù)據(jù)空間,進(jìn)而生成一個(gè)與原始輸入數(shù)據(jù)相似的樣本.
VAE 采用變分下界作為其優(yōu)化目標(biāo)函數(shù),如下
式中,Lrecon表示重構(gòu)損失,其常采用均方差(Mean squared error,MSE)或交叉熵(Cross-entropy)作為度量準(zhǔn)則以衡量生成樣本與原始輸入數(shù)據(jù)間的差異;設(shè)x為輸入數(shù)據(jù),為重構(gòu)數(shù)據(jù),則重構(gòu)損失可表示為 M SE(x,) 或Cross-entropy (x,).
在式(7)中,Lreg表示正則化項(xiàng),通常是通過(guò)最小化KL (Kullback-Leibler)散度DKL約束潛在變量分布與預(yù)定義先驗(yàn)分布間的相似性,進(jìn)而使得潛在空間具有平滑性.設(shè)q(z|x) 是給定輸入數(shù)據(jù)x時(shí)潛在變量z的后驗(yàn)分布,p(z) 是預(yù)定義的先驗(yàn)分布,則Lreg表示如下
式中,σi和μi分別表示編碼器輸出的第i個(gè)潛在變量的均值和標(biāo)準(zhǔn)差.
VAE 的訓(xùn)練過(guò)程旨在學(xué)習(xí)適當(dāng)?shù)臐撛诒硎竞徒獯a器,進(jìn)而使得樣本能夠在潛在空間中平滑地插值并進(jìn)行生成,其代表模型包括重要性加權(quán)自編碼器和輔助深度生成模型等.VAE 的變體類型如表2所示.
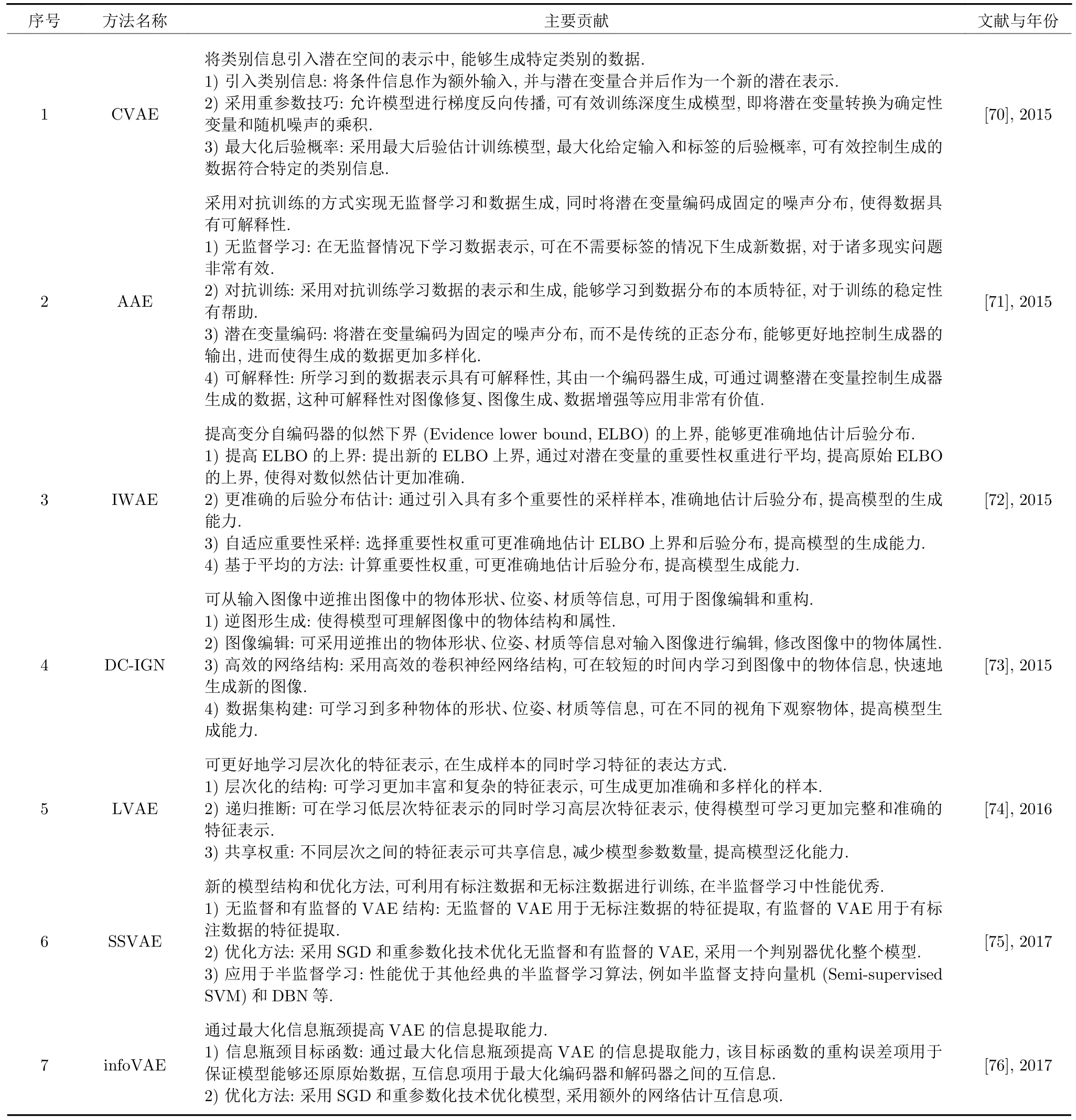
表2 基于VAE 的變體Table 2 Variants based on VAE
2.3 流模型
流模型通常由多個(gè)能夠進(jìn)行可逆變換的耦合層組成,其核心理念是通過(guò)逐層的可逆變換將簡(jiǎn)單的先驗(yàn)分布映射為復(fù)雜的數(shù)據(jù)分布,進(jìn)而實(shí)現(xiàn)對(duì)數(shù)據(jù)分布的建模.耦合層由變換層(Transform layer)和標(biāo)量變換層(Scalar transform layer)組成,前者對(duì)部分的潛在變量進(jìn)行非線性變換,后者對(duì)另外部分的潛在變量進(jìn)行可逆的線性變換,進(jìn)而在保持模型可逆性的同時(shí)引入復(fù)雜的非線性.由于變換是可逆的,流模型可實(shí)現(xiàn)從數(shù)據(jù)空間到潛在空間的反向映射,因此其具有計(jì)算潛在變量和生成樣本的能力.
流模型的訓(xùn)練目標(biāo)是最大似然估計(jì),即最大化訓(xùn)練數(shù)據(jù)在流模型下的概率.由于流模型結(jié)構(gòu)的可逆性,可通過(guò)變量變換法計(jì)算樣本的概率密度函數(shù),其目標(biāo)函數(shù)可表示為如下式所示的負(fù)對(duì)數(shù)似然(Negative log-likelihood,NLL)損失
式中,LFlow表示負(fù)對(duì)數(shù)似然損失,xi表示第i個(gè)樣本,N表示輸入樣本的總數(shù).根據(jù)變量變換法,p(xi)可表示為,zi表示xi的潛在變量,表示潛在變量與數(shù)據(jù)樣本間的雅可比矩陣.式(9)可進(jìn)一步展開(kāi),如下式所示
式中,第一項(xiàng)表示zi在模型先驗(yàn)分布下的負(fù)對(duì)數(shù)似然,通常假設(shè)zi服從多維高斯分布;第二項(xiàng)為雅可比行列式的負(fù)對(duì)數(shù),用于考慮變換從潛在空間到數(shù)據(jù)空間的縮放.
在實(shí)際流模型的訓(xùn)練中,可采用SGD 等優(yōu)化算法最小化負(fù)對(duì)數(shù)似然損失.
綜上,流模型將真實(shí)數(shù)據(jù)分布通過(guò)轉(zhuǎn)換函數(shù)映射到給定的簡(jiǎn)單分布,是一種采用可逆函數(shù)構(gòu)造似然函數(shù)、直接優(yōu)化模型參數(shù)和利用可逆結(jié)構(gòu)的特性生成圖像的精確模型,其代表模型是常規(guī)流模型、變分流模型和可逆殘差網(wǎng)絡(luò).流模型類型如表3 所示.
2.4 PixelRNN
PixelRNN 采用循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent neural network,RNN)建模像素間的條件概率分布生成圖像,能夠?qū)崿F(xiàn)逐像素的生成,其關(guān)鍵是捕獲了像素之間的橫向和縱向依賴關(guān)系,后者能夠通過(guò)循環(huán)神經(jīng)網(wǎng)絡(luò)或其他序列模型建模.在生成某個(gè)像素值時(shí),PixelRNN 考慮了該像素的左邊和上邊的像素值以及已經(jīng)生成的像素值.
PixelRNN 通常可采用交叉熵最小化負(fù)對(duì)數(shù)似然損失,其目標(biāo)函數(shù)如下式所示
式中,qi表示第i個(gè)像素值,N表示像素的總數(shù),P(qi|q1,q2,···,qi-1)表示在給定生成的像素值情況下預(yù)測(cè)當(dāng)前像素值的條件概率.
由于每個(gè)像素的生成均依賴于已生成的像素,所以PixelRNN 的生成速度慢.PixelCNN 通過(guò)像素生成過(guò)程的并行化能夠同時(shí)生成一個(gè)像素位置的所有通道值,進(jìn)而提高了生成速度.
綜上,PixelRNN 是將圖片的像素作為循環(huán)神經(jīng)網(wǎng)絡(luò)的輸入,在本質(zhì)上是自回歸神經(jīng)網(wǎng)絡(luò)在圖片處理上的應(yīng)用,其代表模型是Row LSTM 和Diagonal BiLSTM 等.PixelRNN 技術(shù)及其變體類型如表4 所示.

表4 PixelRNN 模型Table 4 PixelRNN model
2.5 擴(kuò)散模型
擴(kuò)散模型由逆流模型和生成模型組成,訓(xùn)練過(guò)程涉及逆擴(kuò)散和正擴(kuò)散階段.其中,前者通過(guò)逆流模型將真實(shí)數(shù)據(jù)樣本逐步轉(zhuǎn)化為噪聲樣本,進(jìn)而使轉(zhuǎn)化后的噪聲樣本盡可能接近噪聲分布;后者通過(guò)生成模型將噪聲樣本逐步轉(zhuǎn)化為真實(shí)數(shù)據(jù)樣本,進(jìn)而使轉(zhuǎn)化后的噪聲樣本逐步逼近真實(shí)數(shù)據(jù)分布.在生成過(guò)程中,從初始噪聲樣本開(kāi)始,通過(guò)多次迭代正向擴(kuò)散將噪聲樣本逐步轉(zhuǎn)化為逼真的數(shù)據(jù)樣本,其每個(gè)迭代步驟均涉及逆流模型和生成模型的操作.
在本質(zhì)上,擴(kuò)散模型的訓(xùn)練過(guò)程是通過(guò)最大似然估計(jì)獲取生成數(shù)據(jù)的概率分布,如下式所示
式中,xt表示在時(shí)間步t時(shí)的數(shù)據(jù)樣本,T表示總時(shí)間步數(shù),p(xt|xt-1,···,x1) 表示在給定時(shí)間步的數(shù)據(jù)樣本下預(yù)測(cè)當(dāng)前時(shí)間步數(shù)據(jù)樣本的條件概率分布.通常,擴(kuò)散模型的目標(biāo)函數(shù)會(huì)被分解為每個(gè)時(shí)間步的預(yù)測(cè)誤差,進(jìn)而保證可采用諸如均方差或交叉熵等標(biāo)準(zhǔn)的損失函數(shù).
綜上,擴(kuò)散模型通過(guò)控制噪聲信號(hào)的逐步變化生成數(shù)據(jù)樣本,并且支持逆向過(guò)程和條件生成,能夠產(chǎn)生高質(zhì)量的樣本且具有較高的靈活性和可解釋性.代表性的擴(kuò)散模型如表5 所示.

表5 擴(kuò)散模型和Visual ChatGPT 大規(guī)模模型Table 5 Diffusion model and Visual ChatGPT large-scale model
2.6 Visual ChatGPT 大規(guī)模模型
將ChatGPT 和多個(gè)SOTA 視覺(jué)基礎(chǔ)模型連接,能夠?qū)崿F(xiàn)在對(duì)話系統(tǒng)中理解和生成圖片的Visual ChatGPT 大規(guī)模模型,其詳細(xì)描述如表5 所示.
3 工業(yè)過(guò)程圖像生成及其評(píng)估與應(yīng)用研究現(xiàn)狀
結(jié)合本文第1.3 節(jié)給出的流程,本節(jié)將從面向工業(yè)過(guò)程的圖像生成、生成圖像評(píng)估和生成圖像應(yīng)用共3 個(gè)方面進(jìn)行研究現(xiàn)狀的綜述(如圖8 所示),并展開(kāi)敘述每個(gè)方向的子類.

圖8 面向工業(yè)過(guò)程的圖像生成及其應(yīng)用研究現(xiàn)狀結(jié)構(gòu)圖Fig.8 Structure diagram of the current research status of image generation and its application on industrial process
3.1 工業(yè)過(guò)程圖像生成研究現(xiàn)狀
本文從復(fù)雜工業(yè)過(guò)程圖像生成存在問(wèn)題的視角出發(fā),將工業(yè)過(guò)程圖像生成從面向樣本分布不均、面向多樣性不足和面向噪聲干擾大等3 個(gè)方向進(jìn)行綜述.
3.1.1 面向樣本分布不均的圖像生成現(xiàn)狀
針對(duì)工業(yè)過(guò)程樣本分布不均的問(wèn)題,可采用生成器擬合小樣本分布以擴(kuò)充樣本數(shù)據(jù)的策略,主要包括VAE、GAN 和混合VAE 與GAN 模型等策略.
1) VAE 模型: 通過(guò)將原始數(shù)據(jù)映射至低維表示空間進(jìn)而有效地捕捉數(shù)據(jù)特征.由于在低維空間中表征的數(shù)據(jù)分布可能會(huì)更加的均勻,VAE 有助于減少樣本分布不均所導(dǎo)致的問(wèn)題,從而有效地提高生成器的性能.相關(guān)的研究包括: 文獻(xiàn)[96]采用卷積編碼器(Convolution encoder,CE)進(jìn)行數(shù)據(jù)增強(qiáng)和文獻(xiàn)[97]采用卷積自編碼器(Convolution autoencoder,CAE)進(jìn)行數(shù)據(jù)擴(kuò)充.
2) GAN 模型: 通過(guò)改進(jìn)GAN 模型的策略控制樣本數(shù)量的均衡,進(jìn)而實(shí)現(xiàn)更好的數(shù)據(jù)生成效果.相關(guān)研究如下文所示.
文獻(xiàn)[98]提出了自適應(yīng)平衡生成網(wǎng)絡(luò)(Adaptive balance GAN,AdaBalGAN),其創(chuàng)新點(diǎn)包括:改進(jìn)條件GAN (Condition GAN,cGAN)以生成高保真度的模擬晶圓圖并對(duì)缺陷類別進(jìn)行分類,設(shè)計(jì)自適應(yīng)生成控制器后根據(jù)分類準(zhǔn)確性平衡每種缺陷類型的樣本數(shù)量.該對(duì)抗過(guò)程分為兩個(gè)階段: 訓(xùn)練生成器和判別器用來(lái)生成指定類別的高保真晶圓圖;訓(xùn)練分類器用來(lái)準(zhǔn)確識(shí)別真實(shí)或合成晶圓圖的缺陷模式,其結(jié)構(gòu)圖如圖9 所示.
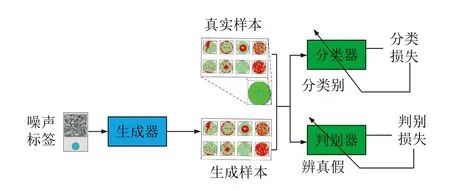
圖9 AdaBalGAN 結(jié)構(gòu)圖[98]Fig.9 Structure of AdaBalGAN[98]
文獻(xiàn)[99]開(kāi)發(fā)了面向邊緣的GAN (Edge-oriented GAN,EOGAN)以創(chuàng)建逼真的紅外圖像,核心是將所提取的邊緣特征作為先驗(yàn)知識(shí)指導(dǎo)紅外圖像生成,其訓(xùn)練和測(cè)試過(guò)程如圖10 所示.

圖10 EOGAN 訓(xùn)練和測(cè)試過(guò)程[99]Fig.10 Training and testing process of EOGAN[99]
文獻(xiàn)[100]提出了旨在增強(qiáng)漏磁信息有效性的改進(jìn)cGAN,在軸向-徑向-軸向空間處理融合后的漏磁信息,利用生成器的損失函數(shù)構(gòu)建多傳感器信息進(jìn)而增強(qiáng)漏磁信息,提高模型在缺陷生成方面的效果.
文獻(xiàn)[101]提出將生成樣本與實(shí)際樣本按比例混合后替代生成樣本的方式增強(qiáng)模型生成能力的改進(jìn)GAN (Improving GAN,IGAN),能夠在一定程度上避免模態(tài)崩潰,其結(jié)構(gòu)如圖11 所示,其中隨機(jī)噪聲z服從高斯分布,α是取值區(qū)間在(0,1)內(nèi)的混合比例系數(shù).
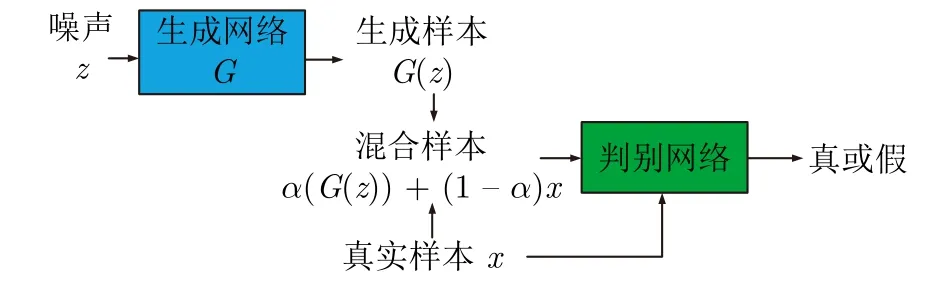
圖11 IGAN 結(jié)構(gòu)[100]Fig.11 Structure of IGAN[100]
3)混合VAE 與GAN 模型: 通過(guò)結(jié)合VAE 的潛在變量建模和GAN 的數(shù)據(jù)生成優(yōu)點(diǎn),期望實(shí)現(xiàn)更好的數(shù)據(jù)分布捕捉和生成效果.
面向自動(dòng)缺陷檢測(cè)過(guò)程,文獻(xiàn)[102]提出基于GAN 的缺陷樣本生成框架,其貢獻(xiàn)體現(xiàn)在: 1)提出區(qū)域訓(xùn)練策略,即在圖像局部區(qū)域建立損失函數(shù)以適用于局部圖像到圖像的轉(zhuǎn)換任務(wù);2)設(shè)計(jì)編碼器-解碼器的圖像生成器,能夠結(jié)合不同尺度的圖像特征生成局部缺陷,同時(shí)保持無(wú)缺陷區(qū)域基本不變;3)引入小波對(duì)生成圖像進(jìn)行細(xì)化,恢復(fù)高頻信息,避免圖像模糊.
綜上,上述方法均是通過(guò)生成稀缺區(qū)域的圖像以達(dá)到彌補(bǔ)樣本分布不平衡的目的,其難點(diǎn)在于如何設(shè)計(jì)合適的模型結(jié)構(gòu)、網(wǎng)絡(luò)結(jié)構(gòu)和學(xué)習(xí)算法等.
3.1.2 面向樣本多樣性不足的圖像生成現(xiàn)狀
多采用圖像到圖像的轉(zhuǎn)換,即通過(guò)源域特征豐富目標(biāo)域特征的方式解決此處的樣本多樣性不足的問(wèn)題,其核心是基于GAN 的循環(huán)一致性網(wǎng)絡(luò).為進(jìn)一步增加樣本的多樣性,針對(duì)不同問(wèn)題采取以下方法.
1)增加對(duì)抗損失: 引入能夠增加多樣性的對(duì)抗損失.文獻(xiàn)[103] 提出用于圖像生成的表面檢測(cè)GAN (Surface defect-GAN,SDGAN),通過(guò)引入D2 對(duì)抗損失[104]增加多樣性,通過(guò)采用循環(huán)一致?lián)p失生成模型學(xué)習(xí)少量的缺陷樣本和大量的無(wú)缺陷樣本以獲得更全面的特征,其結(jié)構(gòu)如圖12 所示.

圖12 SDGAN 結(jié)構(gòu)[103]Fig.12 Structure of SDGAN[103]
2) 改進(jìn)判別器: 增加對(duì)細(xì)節(jié)特征的學(xué)習(xí).文獻(xiàn)[105]針對(duì)基于GAN 的循環(huán)一致性結(jié)構(gòu)難以學(xué)習(xí)到更為豐富的圖像特征問(wèn)題,提出引入膠囊網(wǎng)絡(luò)作為判別器以學(xué)習(xí)細(xì)節(jié)特征的DuCaGAN,其結(jié)構(gòu)如圖13 所示.

圖13 DuCaGAN 結(jié)構(gòu)[105]Fig.13 Structure of DuCaGAN[105]
3)組合多種GAN: 針對(duì)不同的工業(yè)需求特點(diǎn)采用不同的GAN 網(wǎng)絡(luò).針對(duì)自動(dòng)缺陷檢測(cè)系統(tǒng)的圖像分割任務(wù),文獻(xiàn)[106]提出采用DCGAN 和CycleGAN 生成缺陷圖像、采用PatchMatch 和周期性空間GAN (Periodic space GAN,PSGAN)生成無(wú)缺陷合成圖像的策略,如圖14 所示.

圖14 周期性紋理圖像的數(shù)據(jù)增強(qiáng)過(guò)程[106]Fig.14 Data enhancement process for periodic texture image[106]
4)基于樣式轉(zhuǎn)換: 通過(guò)不同部件或背景的轉(zhuǎn)換實(shí)現(xiàn)主體特征保留和復(fù)雜場(chǎng)景處理.
面向焊接過(guò)程中的對(duì)接板形變預(yù)測(cè),文獻(xiàn) [107]提出基于 cGAN 產(chǎn)生焊接參數(shù)和形變數(shù)據(jù)以獲得新樣式.面向夜間環(huán)境中的目標(biāo)檢測(cè)任務(wù),針對(duì)背景模糊和光線暗淡導(dǎo)致檢測(cè)困難的問(wèn)題,文獻(xiàn)[108]提出將不易檢測(cè)的夜間圖像轉(zhuǎn)換成易檢測(cè)的白天圖像的策略,其首先以夜間圖像為輸入,基于GAN 生成與白天環(huán)境相似的虛擬目標(biāo)場(chǎng)景,再通過(guò)深度卷積特征融合和多尺度ROI (Region of interest)池化構(gòu)建基于Faster R-CNN (Region-convolution neural networks)目標(biāo)檢測(cè)系統(tǒng).
雖然上述方法能夠增加樣本的多樣性,但面向工業(yè)領(lǐng)域而言,如何生成符合期望的樣本集仍是有待解決的開(kāi)放性問(wèn)題,原因在于特定的工業(yè)圖像特征通常是與特定的工業(yè)機(jī)理相關(guān)聯(lián)的.顯然,為更好地生成工業(yè)圖像樣本,需要更為深入地了解相關(guān)機(jī)理并將其融入到圖像生成過(guò)程中.這需要與特定行業(yè)的領(lǐng)域?qū)<疫M(jìn)行密切合作,以便更好地生成符合實(shí)際需求的樣本集.由上述研究現(xiàn)狀可知,此類算法的研究關(guān)鍵點(diǎn)之一是式(1)中的pdata難以表征真實(shí)數(shù)據(jù)的概率分布preal,即如何表征preal為新增的難點(diǎn).
3.1.3 面向樣本噪聲干擾大的圖像生成現(xiàn)狀
噪聲干擾大的樣本采用圖像采樣和轉(zhuǎn)換方法進(jìn)行處理,即將強(qiáng)噪聲轉(zhuǎn)化為弱噪聲或無(wú)噪聲,主要包括基于cGAN、WGAN (Wasserstein GAN)和CycleGAN 的方法.
1)基于cGAN 的去噪: 模型通過(guò)學(xué)習(xí)從帶有噪聲的圖像到干凈圖像的映射,實(shí)現(xiàn)圖像的噪聲去除,同時(shí)利用額外的條件信息,有助于模型更好地理解噪聲的性質(zhì),從而能夠更準(zhǔn)確地去除噪聲.
文獻(xiàn)[109]采用由生成器和判別器組成的基于cGAN 的圖像到圖像轉(zhuǎn)換模型pix2pix[110]去除光反射噪聲.其中,原始噪聲圖像作為輸入,手動(dòng)去噪圖像作為判別器和生成器的訓(xùn)練目標(biāo),去噪示意如圖15所示.

圖15 焊接點(diǎn)去噪示意圖[111]Fig.15 Schematic diagram of welding point denoising[111]
文獻(xiàn)[111] 提出了基于cGAN 的印刷電路板(Printed circuit boards,PCBs)圖像去噪策略,其生成器與判別器之間通過(guò)對(duì)抗性訓(xùn)練的迭代優(yōu)化提高生成圖像的質(zhì)量.
2)基于WGAN 的去噪: 本質(zhì)上是采用Wasserstein 距離量化生成圖像與真實(shí)圖像之間的分布差異,以減少訓(xùn)練中的模式崩潰和梯度消失問(wèn)題,從而能夠更準(zhǔn)確地衡量生成圖像的質(zhì)量,促使生成器產(chǎn)生更真實(shí)干凈的圖像.
醫(yī)療領(lǐng)域,為了解決細(xì)胞圖像的模糊性問(wèn)題,文獻(xiàn)[112]提出基于WGAN 的圖像去噪訓(xùn)練框架,包括生成子網(wǎng)絡(luò)、基于MSE 的學(xué)習(xí)和對(duì)抗學(xué)習(xí)3個(gè)模塊.其中,生成子網(wǎng)絡(luò)模塊用于學(xué)習(xí)噪聲圖像與去噪圖像之間的映射關(guān)系,基于MSE 的學(xué)習(xí)模型用于指導(dǎo)生成子網(wǎng)絡(luò)快速學(xué)習(xí)映射關(guān)系,對(duì)抗學(xué)習(xí)子模塊用于幫助生成子網(wǎng)絡(luò)學(xué)習(xí)真實(shí)干凈圖像的分布空間.
3)基于CycleGAN 的去噪: 針對(duì)具有噪聲的原始圖像領(lǐng)域和去除噪聲后的圖像領(lǐng)域,目標(biāo)是通過(guò)CycleGAN 的生成器和判別器將噪聲圖像映射至干凈圖像領(lǐng)域,進(jìn)而實(shí)現(xiàn)噪聲的去除.
面向無(wú)人機(jī)航空攝影任務(wù),文獻(xiàn)[113] 針對(duì)因天氣原因?qū)е碌恼掌肼晢?wèn)題,提出了SlimRGBD (Slim reCNN-GAN)去噪系統(tǒng);針對(duì)沙漠地震數(shù)據(jù)中噪聲強(qiáng)且與有效信號(hào)的頻帶存在嚴(yán)重重疊的問(wèn)題,文獻(xiàn)[114]引入CycleGAN 進(jìn)行去噪;針對(duì)單幅圖像去霧,文獻(xiàn)[115]提出基于CycleGAN 的端到端注意力網(wǎng)絡(luò),其生成器設(shè)計(jì)除包括注意力模塊、編碼器-解碼器結(jié)構(gòu)和密集塊外,引入了諸如暗通道、顏色衰減和最大對(duì)比度等多個(gè)先驗(yàn)以獲取注意力圖,同時(shí)提出顏色損失補(bǔ)償機(jī)制以避免顏色失真.
針對(duì)醫(yī)療領(lǐng)域,面向低劑量計(jì)算機(jī)斷層掃描(Low-dose computed tomography,LDCT)圖像存在的高噪聲問(wèn)題,文獻(xiàn)[116]提出了基于CycleGAN的圖像域去噪;面向原始光學(xué)相干層析成像(Optical coherence tomography,OCT)圖像的質(zhì)量問(wèn)題,文獻(xiàn)[117]提出了能夠?qū)崿F(xiàn)視網(wǎng)膜OCT 圖像的端到端散斑抑制和對(duì)比度增強(qiáng)的cGAN 框架,以解決散斑噪聲會(huì)模糊視網(wǎng)膜結(jié)構(gòu)、影響視覺(jué)質(zhì)量以及降低后續(xù)圖像分析任務(wù)性能等問(wèn)題;進(jìn)一步,文獻(xiàn)[118]提出基于風(fēng)格轉(zhuǎn)換和cGAN 的OCT 圖像斑點(diǎn)噪聲抑制模型,其包括: a) 采用CycleGAN 學(xué)習(xí)兩個(gè)OCT 圖像數(shù)據(jù)集間的樣式轉(zhuǎn)移以獲得真值數(shù)據(jù)集;b)基于PatchGAN 機(jī)制采用小型cGAN 模型抑制OCT 圖像中的斑點(diǎn)噪聲.可見(jiàn),與處理樣本噪聲相關(guān)的技術(shù)已在醫(yī)療等領(lǐng)域得到廣泛應(yīng)用.
上述研究將強(qiáng)噪聲轉(zhuǎn)化為弱噪聲或零噪聲以提升圖像質(zhì)量和進(jìn)行信息還原.在工業(yè)實(shí)際應(yīng)用中,在選擇適當(dāng)?shù)姆椒〞r(shí)還需要考慮噪聲的類型、數(shù)據(jù)分布和任務(wù)需求.
綜上可知,針對(duì)上述3 類工業(yè)過(guò)程圖像生成問(wèn)題,所采用的解決策略在本質(zhì)上是不同的,對(duì)應(yīng)的數(shù)學(xué)視角分析如表6 所示.

表6 工業(yè)過(guò)程圖像生成問(wèn)題的本質(zhì)Table 6 The essence of image generation problems in industrial process
面向樣本分布不均的問(wèn)題,其生成模型和下游任務(wù)模型可表示為fG1(Xtraining) 和fDT1(fG1(Xtraining),Xtraining),對(duì)應(yīng)的不采用fG1(·) 的下游任務(wù)直接模型可表示為,此時(shí)fG1(·) 的目的是使fDT1(·) 模型不會(huì)因?yàn)闃颖镜姆植疾痪a(chǎn)生過(guò)擬合現(xiàn)象.假設(shè)能夠擬合任意函數(shù),那么對(duì)于任意的fG1(·) 和fDT1(·),則一定存在使得下式成立
由式(13)可得,受限于樣本分布不均,下游任務(wù)模型性能的提升必然是有限的.當(dāng)Xtraining不服從XReal分布時(shí),在借助領(lǐng)域知識(shí)的情況下,必然存在fG1(Xtraining) 也無(wú)法服從XReal分布的現(xiàn)象.此時(shí),雖然fDT1(fG1(Xtraining),Xtraining) 在Xtraining上的測(cè)試準(zhǔn)確率可能會(huì)得到提升,但在面對(duì)XReal時(shí),其準(zhǔn)確率會(huì)較低.
面向樣本多樣性不足的問(wèn)題,其生成模型和下游任務(wù)模型可表示為fG2(Xtraining,Xno_label) 和fDT2(fG2(Xtraining,Xno_label),Xtraining),對(duì)應(yīng)的不采用fG2(·) 下游任務(wù)直接模型可表示為此時(shí)fG2(·) 的目的是要獲取符合全局分布的數(shù)據(jù)集以使得下游模型的魯棒性更強(qiáng).當(dāng)Xtraining的分布不服從XReal分布、而Xno_label的分布卻能夠很接近XReal分布時(shí),下游模型fDT2(·) 的性能相對(duì)于是能夠得到顯著提升的.
面向樣本噪聲干擾大問(wèn)題,其生成模型和下游任務(wù)模型可表示為fG3(Xtraining) 和fDT3(fG3(Xtraining)),對(duì)應(yīng)的不采用fG3(·) 的下游任務(wù)直接模型可表示為,此時(shí)fG3(·) 的目的是使下游模型能夠更好“理解”工業(yè)圖像.當(dāng)是具有自適應(yīng)去噪能力的端到端模型時(shí),則對(duì)于任意的fG3(·) 和fDT3(·),一定會(huì)存在使得下式成立
由式(14)可得,受限于樣本中的噪聲干擾,下游任務(wù)模型性能的提升有限.
綜上可知,針對(duì)樣本分布不均和噪聲干擾大問(wèn)題,已有生成模型難以有效表征preal;針對(duì)多樣性不足問(wèn)題而言,已有生成模型通過(guò)對(duì)Xno_label數(shù)據(jù)的學(xué)習(xí)能夠嘗試獲得足以表征preal的圖像集.由于涉及數(shù)據(jù)采集與標(biāo)定時(shí)的場(chǎng)景缺失和知識(shí)缺乏等因素,此類研究在工業(yè)領(lǐng)域現(xiàn)場(chǎng)中的應(yīng)用較少.因此,如何更有效地生成具有較強(qiáng)表征性的工業(yè)圖像集,仍需結(jié)合工業(yè)機(jī)理和領(lǐng)域知識(shí)進(jìn)行深入研究.
3.2 工業(yè)過(guò)程生成圖像評(píng)估研究現(xiàn)狀
通常,生成圖像的評(píng)估指標(biāo)應(yīng)該滿足以下標(biāo)準(zhǔn):1)能夠檢測(cè)生成圖像的生成質(zhì)量;2)能夠檢測(cè)生成圖像集的多樣性;3)能夠檢測(cè)生成圖像的可理解性或可控性;4)評(píng)價(jià)指標(biāo)具備有界性;5)不可承受過(guò)高計(jì)算復(fù)雜度;6)能夠檢測(cè)生成圖像的語(yǔ)義不變性;7)能夠檢測(cè)圖像細(xì)微的形變和瑕疵.
因缺乏明確的似然概率度量[119],早期研究采用具有主觀性的視覺(jué)方式對(duì)GANs 所生成的圖像進(jìn)行評(píng)價(jià).之后,文獻(xiàn)[68]提出GAN-train 策略,通過(guò)對(duì)比基于cifar100 數(shù)據(jù)集和基于合成圖像訓(xùn)練的CNN 判別器性能進(jìn)行生成圖像評(píng)估.進(jìn)一步,文獻(xiàn)[120]提出了同時(shí)進(jìn)行GAN-train 和GAN-test的評(píng)估策略,具體為: GAN-train 采用GAN 生成的圖像訓(xùn)練判別器并測(cè)量其在真實(shí)測(cè)試圖像上的性能,進(jìn)而評(píng)價(jià)GAN 圖像的多樣性和真實(shí)感;GAN-test采用真實(shí)圖像訓(xùn)練判別器并基于GAN 生成的圖像進(jìn)行評(píng)估,進(jìn)而衡量GAN 圖像的真實(shí)感.此外,初始得分(Inception score,IS)[121]和FID[122-123]也常被用作評(píng)估生成圖像質(zhì)量的指標(biāo).
本文將文獻(xiàn)[124-125]所綜述的定量和定性的生成圖像評(píng)價(jià)指標(biāo)進(jìn)行整理,如表7 所示.

表7 生成圖像評(píng)估指標(biāo)Table 7 Evaluation index for generated image
在面向樣本多樣性不足的研究中,期望的生成樣本需要服從全局分布,而不是僅擬合訓(xùn)練樣本的概率分布.以MSWI 過(guò)程為例,燃燒線極端異常的火焰圖像不存在于通常所獲取的訓(xùn)練樣本集中,因此,通常的評(píng)估方法不適用于這種情況.如何結(jié)合特定行業(yè)圖像固有關(guān)鍵特征對(duì)應(yīng)的機(jī)理知識(shí)對(duì)其進(jìn)行綜合評(píng)估和篩選,是工業(yè)生成圖像評(píng)估算法研究的難點(diǎn)之一.
3.3 工業(yè)過(guò)程生成圖像應(yīng)用研究現(xiàn)狀
當(dāng)前針對(duì)工業(yè)過(guò)程圖像生成的研究主要聚焦于故障識(shí)別和工況監(jiān)測(cè)等任務(wù),基于工業(yè)圖像進(jìn)行反饋控制和關(guān)鍵參數(shù)量化等方面的研究較為缺乏.以MSWI 過(guò)程為例,構(gòu)建完備的火焰圖像模板庫(kù)可用于量化燃燒線,從而支撐基于圖像的實(shí)時(shí)燃燒控制.但是在數(shù)據(jù)分析中發(fā)現(xiàn),燃燒線異常的火焰圖像稀缺[14],極端異常的火焰圖像缺失.因此,如何基于真實(shí)圖像和生成圖像構(gòu)建完備模板庫(kù)是實(shí)現(xiàn)上述目標(biāo)的關(guān)鍵[13].圖像生成技術(shù)在基于模板匹配的目標(biāo)跟蹤領(lǐng)域具有廣泛的應(yīng)用潛力.具體來(lái)說(shuō),模板匹配是指采用預(yù)定義的圖像模板與實(shí)際場(chǎng)景中的圖像進(jìn)行匹配,以達(dá)到目標(biāo)檢測(cè)和識(shí)別的目的.在進(jìn)行燃燒線量化時(shí),首先采用圖像生成技術(shù)獲取系列的火焰圖像,然后構(gòu)建完備模板庫(kù),最后采用模板匹配技術(shù)實(shí)現(xiàn)圖像量化.這種方法可代替?zhèn)鹘y(tǒng)的基于經(jīng)驗(yàn)的燃燒線控制方法,進(jìn)而提升智能化水平.
綜上,本節(jié)從面向識(shí)別任務(wù)和面向以目標(biāo)跟蹤任務(wù)為代表的關(guān)鍵參數(shù)量化兩個(gè)方面進(jìn)行研究現(xiàn)狀的分析.
3.3.1 面向識(shí)別/檢測(cè)任務(wù)的生成圖像應(yīng)用現(xiàn)狀
在實(shí)際生產(chǎn)線上,因缺陷圖像不足和標(biāo)注成本過(guò)高等原因,很難獲得具有足夠多樣性的缺陷樣本數(shù)據(jù).文獻(xiàn)[98,102,105]均基于GAN 提出面向特定工業(yè)行業(yè)的圖像生成策略,構(gòu)建缺陷識(shí)別模型.文獻(xiàn)[103]提出基于SDGAN 提升缺陷識(shí)別準(zhǔn)確率,其首先采用循環(huán)損失和D2 對(duì)抗損失訓(xùn)練SDGAN,然后采用FID 評(píng)估缺陷圖片質(zhì)量,最后構(gòu)建缺陷識(shí)別CNN 模型,結(jié)構(gòu)如圖16 所示.
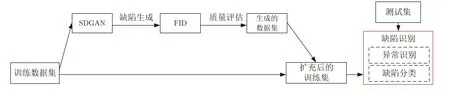
圖16 基于SDGAN 數(shù)據(jù)增強(qiáng)的檢測(cè)過(guò)程[103]Fig.16 Detection process based on data enhancement of SDGAN[103]
文獻(xiàn)[96]提出基于CE 增強(qiáng)和深度可分卷積構(gòu)建缺陷分類模型,采用mobilenet V1 和V2 訓(xùn)練兩個(gè)模型,表明輕量化的深度卷積可減少模型參數(shù)和計(jì)算量.文獻(xiàn)[97]提出基于CAE 數(shù)據(jù)增強(qiáng)的缺陷檢測(cè)模型,采用Xception 進(jìn)行晶圓缺陷檢測(cè)和分類.
面向自動(dòng)缺陷檢測(cè)系統(tǒng)中的缺陷圖像分割任務(wù),文獻(xiàn)[106]提出采用DCGAN 和CycleGAN 生成缺陷圖像、采用PatchMatch 和PSGAN 生成無(wú)缺陷合成圖像的策略,其在數(shù)據(jù)增強(qiáng)基礎(chǔ)上提出基于CycleGAN 的周期性紋理缺陷分割框架,表明該框架優(yōu)于現(xiàn)有的弱監(jiān)督分割方法,結(jié)構(gòu)如圖17 所示.
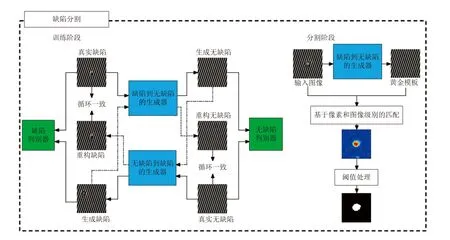
圖17 周期性紋理圖像的缺陷分割過(guò)程[106]Fig.17 Defect segmentation process of periodic texture image[106]
以GAN 為代表的圖像生成算法已應(yīng)用于工業(yè)缺陷檢測(cè)領(lǐng)域,因其具有更佳的數(shù)據(jù)增強(qiáng)、特征提取、樣本平衡能力而備受關(guān)注.然而,由于訓(xùn)練過(guò)程不穩(wěn)定、生成數(shù)據(jù)存在噪聲等問(wèn)題,其性能和穩(wěn)定性仍需進(jìn)一步研究.因此,在采用GAN 進(jìn)行工業(yè)缺陷檢測(cè)時(shí),需要進(jìn)行充分的實(shí)驗(yàn)和評(píng)估,以驗(yàn)證其應(yīng)用效果并對(duì)其優(yōu)化方法進(jìn)行探討,從而提高工業(yè)應(yīng)用中的實(shí)用性.
下面綜述在電氣設(shè)備識(shí)別、管道漏磁檢測(cè)和焊接頭檢測(cè)等過(guò)程中的應(yīng)用現(xiàn)狀.
3.3.1.1 電氣設(shè)備識(shí)別過(guò)程
該過(guò)程存在的問(wèn)題包括工業(yè)過(guò)程溫度分布過(guò)于集中、設(shè)備形狀尺寸不確定以及識(shí)別背景復(fù)雜等.文獻(xiàn)[99]提出基于EOGAN 生成數(shù)據(jù)的電氣設(shè)備識(shí)別框架,首先采用預(yù)處理和分割技術(shù)提取邊緣信息,然后在訓(xùn)練階段將圖像數(shù)據(jù)與邊緣特征進(jìn)行匹配以生成紅外圖像,最后在基于邊緣特征的圖像生成階段構(gòu)建識(shí)別模型,其策略如圖18 所示.

圖18 電氣設(shè)備識(shí)別方法的結(jié)構(gòu)[99]Fig.18 Architecture of identification method for electrical equipment[99]
上述研究存在的局限性在于: 1)采用的數(shù)據(jù)集規(guī)模相對(duì)較小,所提方法的適用性和魯棒性有待采用更為廣泛和多樣化的數(shù)據(jù)集進(jìn)行驗(yàn)證;2)未考慮在實(shí)際應(yīng)用中可能存在的不確定性因素,如設(shè)備老化、環(huán)境變化等因素可能會(huì)導(dǎo)致生成的合成數(shù)據(jù)與真實(shí)數(shù)據(jù)存在差異;3)數(shù)據(jù)需要進(jìn)行后續(xù)處理才能用于設(shè)備識(shí)別,在實(shí)際應(yīng)用中需要考慮更快速和實(shí)時(shí)的識(shí)別方法.
3.3.1.2 管道漏磁檢測(cè)過(guò)程
存在的問(wèn)題是檢測(cè)環(huán)境不穩(wěn)定和設(shè)備異常會(huì)導(dǎo)致信息不完整.文獻(xiàn)[100]提出基于多傳感器融合的方法,用于處理信息不完整情況下的缺陷表征問(wèn)題.基于3 種不同類型的傳感器信號(hào)(磁場(chǎng)強(qiáng)度、相位和高斯噪聲)并采用改進(jìn)的cGAN 生成缺陷信號(hào)樣本,以彌補(bǔ)傳感器數(shù)據(jù)缺失的情況.研究表明,該方法可顯著提高缺陷表征的準(zhǔn)確性和魯棒性,降低傳感器數(shù)據(jù)缺失造成的影響,其策略如圖19 所示.

圖19 信息不完全下漏磁缺陷表征的多傳感器融合框架[100]Fig.19 Multi-sensor fusion framework for magnetic flux leakage defect characterization under incomplete information[100]
值得注意的是,該研究?jī)H基于模擬的信號(hào)數(shù)據(jù)集進(jìn)行,并未在實(shí)際漏磁檢測(cè)場(chǎng)景中進(jìn)行驗(yàn)證.此外,該方法可能會(huì)受到缺失數(shù)據(jù)位置和數(shù)量等因素的影響,因此其應(yīng)用范圍具有局限性.
3.3.1.3 焊接頭檢測(cè)過(guò)程
該過(guò)程存在問(wèn)題是: 1)不合格焊接點(diǎn)的樣本稀缺;2)焊點(diǎn)具有紋理弱、對(duì)比度弱和存在腐蝕等復(fù)雜特性;3)噪聲干擾大.
文獻(xiàn)[101]通過(guò)集成GAN 和AE 構(gòu)建了具有圖像數(shù)據(jù)生成、特征提取和模式識(shí)別功能的網(wǎng)絡(luò)結(jié)構(gòu),首先采用改進(jìn)GAN 擴(kuò)展不合格點(diǎn)焊接頭的圖像數(shù)據(jù)集,然后結(jié)合專家經(jīng)驗(yàn)通過(guò)AE 選擇圖像的特征向量,最后利用隱馬爾科夫模型判斷點(diǎn)焊質(zhì)量.該方法能夠解決標(biāo)準(zhǔn)GAN 中生成的圖像樣本分布不均和多樣性不足的問(wèn)題.
文獻(xiàn)[176]采用CycleGAN 實(shí)現(xiàn)工件與焊縫之間的樣式轉(zhuǎn)換,進(jìn)而實(shí)現(xiàn)數(shù)據(jù)集的擴(kuò)展,其應(yīng)用過(guò)程如圖20 所示.

圖20 焊接頭檢測(cè)與識(shí)別框架[176]Fig.20 Welded joint inspection and identification framework[176]
首先,針對(duì)訓(xùn)練樣本不足的問(wèn)題,結(jié)合圖像處理和GAN 生成高質(zhì)量的訓(xùn)練樣本;然后,建立訓(xùn)練樣本的更新機(jī)制以保證深度神經(jīng)網(wǎng)絡(luò)模型能夠覆蓋所有樣本;最后,利用深度神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)焊接頭的檢測(cè)與識(shí)別.實(shí)驗(yàn)表明,該方法能夠快速高效地完成焊接頭的檢測(cè)與識(shí)別.
文獻(xiàn)[109]應(yīng)用pix2pix[110]消除焊接圖像中的噪聲以實(shí)現(xiàn)圖像增強(qiáng),提出基于多源傳感圖像進(jìn)行熔透檢測(cè)的新框架,其能夠同步分析多種類型的光學(xué)傳感圖像,包括圖像預(yù)處理、圖像選擇和焊縫熔透分類3 個(gè)采用深度學(xué)習(xí)進(jìn)行增強(qiáng)的階段.
綜上,基于GAN 的圖像增強(qiáng)在焊接頭檢測(cè)中應(yīng)用廣泛.該技術(shù)通過(guò)學(xué)習(xí)原始圖像中的信息生成高質(zhì)量圖像,能夠提高焊接頭缺陷、幾何形狀、尺寸和質(zhì)量檢測(cè)的準(zhǔn)確性與可靠性.通過(guò)增強(qiáng)圖像的細(xì)節(jié)、清晰度和紋理等特征,可顯著提高焊接頭檢測(cè)的效果.
3.3.2 面向目標(biāo)跟蹤任務(wù)的生成圖像應(yīng)用現(xiàn)狀
3.3.2.1 工業(yè)領(lǐng)域
近年來(lái),孿生網(wǎng)絡(luò)(Siamese network)的突出精度和速度使其在目標(biāo)跟蹤研究中廣受關(guān)注,尤其是在視頻監(jiān)控和自動(dòng)駕駛等領(lǐng)域[177-178],但其在復(fù)雜工業(yè)過(guò)程中的應(yīng)用仍需要進(jìn)一步深入.
以對(duì)MSWI 過(guò)程的燃燒火焰進(jìn)行跟蹤為例,目前還存在如下開(kāi)放性問(wèn)題: 1)生成虛假火焰圖像以增強(qiáng)數(shù)據(jù)集的數(shù)量和質(zhì)量,提高火焰目標(biāo)跟蹤算法的魯棒性和泛化能力;2)生成虛擬火焰圖像用于訓(xùn)練火焰邊界檢測(cè)模型,以便能夠更準(zhǔn)確地檢測(cè)火焰的位置和形態(tài);3)火焰的形態(tài)和顏色等信息會(huì)不斷發(fā)生變化,而成像設(shè)備故障、物質(zhì)遮擋等因素可能會(huì)導(dǎo)致火焰圖像中出現(xiàn)缺失區(qū)域,這需要采用圖像生成技術(shù)進(jìn)行填充,從而更好地進(jìn)行燃燒火焰的跟蹤;4)火焰的形態(tài)和顏色等信息能夠反映爐膛內(nèi)的燃燒狀態(tài),生成虛擬火焰圖像可用于訓(xùn)練模型預(yù)測(cè)火焰狀態(tài)的變化趨勢(shì),從而更好地控制和優(yōu)化爐內(nèi)燃燒過(guò)程.
因此,面向目標(biāo)跟蹤的圖像生成技術(shù)在工業(yè)領(lǐng)域具有廣泛的應(yīng)用前景,如在MSWI 過(guò)程中,其可用于增強(qiáng)數(shù)據(jù)集的數(shù)量和質(zhì)量、檢測(cè)火焰邊界、填充缺失數(shù)據(jù)和預(yù)測(cè)火焰狀態(tài)的變化趨勢(shì)等.
3.3.2.2 其他領(lǐng)域
SINT (Siamese instance search tracker)算法[179]是基于孿生網(wǎng)絡(luò)的跟蹤算法的代表之一,其采用孿生網(wǎng)絡(luò)訓(xùn)練識(shí)別與初始目標(biāo)外觀相匹配的候選圖像位置,進(jìn)而將目標(biāo)跟蹤問(wèn)題轉(zhuǎn)化為匹配問(wèn)題.相比之下,SiamFC 算法[180]在初始階段訓(xùn)練全卷積網(wǎng)絡(luò)用于解決相似性學(xué)習(xí)問(wèn)題,在推理期間對(duì)學(xué)習(xí)到的匹配函數(shù)進(jìn)行在線評(píng)估,能夠以超實(shí)時(shí)速度運(yùn)行.SiamRPN 算法[181]將RPN (Region proposal network)網(wǎng)絡(luò)應(yīng)用于目標(biāo)跟蹤任務(wù),用錨框替代多尺度卷積過(guò)程,進(jìn)一步提升了跟蹤速度和精度.
盡管上述跟蹤算法表現(xiàn)出色,但均采用固定模板進(jìn)行跟蹤,在目標(biāo)出現(xiàn)旋轉(zhuǎn)、形變和運(yùn)動(dòng)模糊等外觀變化時(shí)容易出現(xiàn)模板匹配錯(cuò)誤,進(jìn)而導(dǎo)致目標(biāo)跟蹤失敗.為此,CFNet 算法[182]在SiamFC 算法框架中引入可微相關(guān)濾波器,采用嶺回歸微調(diào)初始模板,從而可在跟蹤過(guò)程中更新模板.另外,文獻(xiàn)[183]提出了動(dòng)態(tài)Siamese 網(wǎng)絡(luò),通過(guò)快速轉(zhuǎn)換學(xué)習(xí)模型,能夠有效地從歷史幀中在線學(xué)習(xí)目標(biāo)外觀變化.此外,文獻(xiàn)[184]在目標(biāo)跟蹤過(guò)程中采用GAN 生成所需要的模板.
以上算法在一定程度上提高了跟蹤性能,但在目標(biāo)外觀發(fā)生變化時(shí),會(huì)存在跟蹤失敗的情況.由于圖像生成算法能夠在目標(biāo)跟蹤中生成跟蹤目標(biāo)的模板、學(xué)習(xí)目標(biāo)的潛在表示、進(jìn)行數(shù)據(jù)的增強(qiáng)更新以適應(yīng)變化[184],因此應(yīng)用前景廣闊.
4 討論與分析
4.1 方法比較
面向工業(yè)過(guò)程的圖像生成、生成圖像評(píng)估和生成圖像應(yīng)用共3 個(gè)視角的相關(guān)研究統(tǒng)計(jì)結(jié)果詳見(jiàn)表8.
由表8 可知:
1)工業(yè)過(guò)程圖像生成.從問(wèn)題角度分析,其主要能夠解決樣本分布不均、多樣性不足和噪聲干擾大3 類問(wèn)題.具體而言,從解決問(wèn)題的視角出發(fā),針對(duì)不同的類別應(yīng)采用不同的策略: 面向樣本分布不均,主要采用通過(guò)生成樣本擬合小樣本分布的方式,主要度量指標(biāo)為樣本稀疏度和樣本相似度,該策略能夠有效提高下游識(shí)別模型的泛化性能;面向樣本多樣性不足,主要采用圖像到圖像的轉(zhuǎn)換方式,借助源域特征擴(kuò)充目標(biāo)域特征,相較于原始目標(biāo)域圖像集,目標(biāo)域特征更加豐富,能夠在一定程度上解決目標(biāo)域圖像缺失問(wèn)題,該策略能夠有效提高下游識(shí)別模型的魯棒性;面向樣本噪聲干擾大,主要采用圖像到圖像的轉(zhuǎn)換方式,借助清晰圖像集的概率分布修正噪聲干擾大圖像集的概率分布,進(jìn)而去除噪聲,該策略能夠有效提高圖像的可解釋性.
2)工業(yè)過(guò)程生成圖像評(píng)估.生成圖像評(píng)估模型的架構(gòu)涵蓋了輸入圖像與生成圖像之間的比較和分析過(guò)程,用于確定兩者之間的相似性和差異,其流程通常包括預(yù)處理、特征提取、相似性度量和評(píng)估指標(biāo)計(jì)算等步驟.定量指標(biāo)雖然能夠提供客觀的數(shù)值結(jié)果,但在極端異常工業(yè)過(guò)程圖像的評(píng)估方面可能存在一定困難,無(wú)法準(zhǔn)確反映生成圖像的真實(shí)質(zhì)量和特殊特征.定性指標(biāo)主要是指基于人工方式的主觀評(píng)估,包括專家評(píng)審、用戶調(diào)查和視覺(jué)感知實(shí)驗(yàn)等方法,盡管該指標(biāo)主要依賴于經(jīng)驗(yàn)和主觀判斷,但在評(píng)估特殊生成圖像時(shí)卻具有一定優(yōu)勢(shì),能夠更全面、準(zhǔn)確地評(píng)估圖像的視覺(jué)質(zhì)量、真實(shí)性和感知一致性.在未來(lái)研究中,需要改進(jìn)和發(fā)展更為準(zhǔn)確可靠的定量指標(biāo),需要在評(píng)估中融入更多的工業(yè)特征和領(lǐng)域知識(shí).此外,還可以探索基于深度學(xué)習(xí)的生成圖像質(zhì)量評(píng)估算法,以提高評(píng)估的自動(dòng)化程度和準(zhǔn)確性.
3)工業(yè)過(guò)程生成圖像應(yīng)用.目前,對(duì)于工業(yè)過(guò)程生成圖像應(yīng)用的研究主要側(cè)重于故障識(shí)別和工況監(jiān)測(cè)等任務(wù),面向工業(yè)生成圖像進(jìn)行反饋控制和關(guān)鍵參數(shù)量化等方面的相關(guān)研究相對(duì)較少.本文將生成圖像應(yīng)用劃分為面向識(shí)別/檢測(cè)任務(wù)和面向目標(biāo)跟蹤任務(wù)兩類.針對(duì)識(shí)別/檢測(cè)任務(wù),主要集中在電氣設(shè)備識(shí)別、漏磁檢測(cè)和焊接檢測(cè)等方面,研究者采用不同的圖像生成方式獲取具有特定目標(biāo)的圖像,以便進(jìn)行算法的訓(xùn)練和性能的評(píng)估.針對(duì)目標(biāo)跟蹤任務(wù),目前的研究主要涉及其他非工業(yè)過(guò)程領(lǐng)域,能夠生成具有已知運(yùn)動(dòng)軌跡和特征的目標(biāo),進(jìn)而提供訓(xùn)練數(shù)據(jù)或進(jìn)行算法測(cè)試.未來(lái)研究中,工業(yè)生成圖像還可以用于過(guò)程難測(cè)參數(shù)的檢測(cè)和控制,模擬在不同參數(shù)條件下的系統(tǒng)性能和響應(yīng),進(jìn)而拓寬其在工業(yè)領(lǐng)域中的潛在應(yīng)用價(jià)值.
4.2 討論與分析
結(jié)合以上分析,本文總結(jié)了面向工業(yè)過(guò)程的圖像生成及其應(yīng)用的未來(lái)研究方向,如下所示.
1)結(jié)合工業(yè)背景知識(shí)增加生成圖像的多樣性.目前的生成研究主要采取擬合已有真實(shí)小樣本數(shù)據(jù)和使用圖像到圖像轉(zhuǎn)換的策略,通過(guò)將大量無(wú)標(biāo)簽樣本融入生成過(guò)程以增加樣本多樣性[103,105-107].然而,在工業(yè)環(huán)境中,如何生成同時(shí)具有全局分布特征和強(qiáng)解釋性的樣本仍然是一個(gè)挑戰(zhàn).筆者認(rèn)為,解決方案之一是引入工業(yè)機(jī)理知識(shí)和領(lǐng)域?qū)<抑R(shí)約束,進(jìn)而生成符合工業(yè)過(guò)程實(shí)際物理規(guī)律的工業(yè)圖像,以提高生成結(jié)果的可靠性和可控性.此外,也可以考慮將不同類型的工業(yè)過(guò)程數(shù)據(jù)(如傳感器數(shù)據(jù)、文本數(shù)據(jù)等)與工業(yè)圖像相結(jié)合,實(shí)現(xiàn)基于多模態(tài)的工業(yè)過(guò)程圖像生成.
2)結(jié)合擴(kuò)散模型、Prompt learning 和大型生成模型的圖像生成.筆者認(rèn)為,在面向工業(yè)過(guò)程圖像生成及其應(yīng)用的未來(lái)研究中,結(jié)合擴(kuò)散模型、Prompt learning 和大型生成模型將具有里程碑式的重要意義.擴(kuò)散模型能夠通過(guò)控制噪聲信號(hào)的逐步變化生成數(shù)據(jù)樣本,支持逆向過(guò)程和條件生成,可產(chǎn)生與GAN 方法相媲美的高質(zhì)量樣本.通過(guò)改進(jìn)和擴(kuò)展擴(kuò)散模型應(yīng)對(duì)不同工業(yè)領(lǐng)域的特定挑戰(zhàn),顯然能夠提高視覺(jué)感知模型的準(zhǔn)確性和泛化能力.基于Prompt learning 技術(shù),理論上是能夠通過(guò)設(shè)計(jì)適當(dāng)?shù)奶崾拘畔⒁龑?dǎo)生成模型輸出符合工業(yè)過(guò)程特征的圖像;如何設(shè)計(jì)提示信息,如何在生成過(guò)程中引入領(lǐng)域?qū)<抑R(shí)與物理約束信息,是提高生成結(jié)果可控性和準(zhǔn)確性的關(guān)鍵之一.大型生成模型能夠?qū)W習(xí)大規(guī)模數(shù)據(jù)集的知識(shí),通過(guò)文本描述能夠生成高質(zhì)量、可解釋的圖像,但受限于缺乏可訓(xùn)練樣本和領(lǐng)域知識(shí)等因素,如何生成工業(yè)領(lǐng)域性強(qiáng)的圖像還有待解決.因此,結(jié)合擴(kuò)散模型、Prompt learning 和大型生成模型的圖像生成技術(shù)將能夠?yàn)楣I(yè)過(guò)程圖像生成的未來(lái)研究提供新的契機(jī).
3)對(duì)圖像去噪與圖像生成進(jìn)行協(xié)同優(yōu)化的圖像生成.受傳感器噪聲、光照變化或物體振動(dòng)等多種因素的影響,工業(yè)過(guò)程圖像常常包含噪聲和偽影[109,111],過(guò)度擬合噪聲數(shù)據(jù)會(huì)導(dǎo)致模型記憶隨機(jī)噪聲的模式,進(jìn)而影響模型的泛化能力[189].因此,需要研究如何設(shè)計(jì)能夠同時(shí)學(xué)習(xí)圖像去噪和圖像生成任務(wù)的一體化模型,通過(guò)共享特征表示和參數(shù),使得去噪和生成過(guò)程能夠相互促進(jìn),進(jìn)而提高生成結(jié)果的質(zhì)量和準(zhǔn)確性.此外,針對(duì)具體的工業(yè)過(guò)程,其噪聲結(jié)構(gòu)往往具有獨(dú)特性,例如在MSWI 過(guò)程中,噪聲主要源自飛灰、雜質(zhì)以及高溫對(duì)攝像頭的影響.筆者認(rèn)為,未來(lái)研究需要根據(jù)噪聲結(jié)構(gòu)中所存在的先驗(yàn)信息選擇或改進(jìn)更為適合的算法,這將有助于提高工業(yè)圖像去噪效果.
4)基于生成圖像的工業(yè)模板庫(kù)構(gòu)建與更新及在下游應(yīng)用.通常的工業(yè)圖像模板庫(kù)因存在異常樣本分布不均和極端異常樣本缺失等問(wèn)題,導(dǎo)致難測(cè)參數(shù)和控制模型的泛化性能和魯棒性能受到限制[190].從模板庫(kù)的構(gòu)建和更新視角而言,簡(jiǎn)單的線性更新策略顯然難以滿足工業(yè)現(xiàn)場(chǎng)的所有可能情況;此外,該更新策略在空間維度上是恒定的,無(wú)法實(shí)現(xiàn)局部更新.因此,有必要采用基于生成圖像的策略構(gòu)建完備的工業(yè)圖像模板庫(kù)以解決上述問(wèn)題.從難測(cè)參數(shù)檢測(cè)的角度分析,基于圖像生成的模板庫(kù)能夠提供完備的圖像特征,能夠涵蓋各種可能的異常情況,從而提高難測(cè)參數(shù)的檢測(cè)能力.從基于圖像進(jìn)行控制[191]的角度分析,基于圖像生成的模板庫(kù)的數(shù)據(jù)具有完備性,能夠與控制策略建立較為完整的映射,進(jìn)而支撐實(shí)現(xiàn)更為準(zhǔn)確和精細(xì)的工業(yè)過(guò)程控制.此外,生成模型還可以根據(jù)不同的控制策略生成相應(yīng)的圖像樣本,用于評(píng)估控制系統(tǒng)的性能.因此,通過(guò)構(gòu)建和更新完備的工業(yè)圖像模板庫(kù)并將其應(yīng)用于難測(cè)參數(shù)檢測(cè)和控制優(yōu)化,在未來(lái)有望提升工業(yè)過(guò)程控制系統(tǒng)的性能.
5)基于生成圖像與過(guò)程參數(shù)工業(yè)模板庫(kù)的產(chǎn)品質(zhì)量?jī)?yōu)化研究.本文認(rèn)為,通過(guò)利用模板庫(kù)中的圖像樣本和相關(guān)參數(shù)信息,進(jìn)行基于生成圖像與過(guò)程參數(shù)工業(yè)模板庫(kù)的產(chǎn)品質(zhì)量?jī)?yōu)化將是未來(lái)的重要研究領(lǐng)域.首先,需要收集、整理和標(biāo)注大量的樣本數(shù)據(jù),即構(gòu)建的模板庫(kù)應(yīng)包含不同工業(yè)產(chǎn)品的圖像樣本以及與其相關(guān)的質(zhì)量參數(shù),以支持后續(xù)的產(chǎn)品質(zhì)量?jī)?yōu)化研究.然后,利用生成模型技術(shù)擴(kuò)充樣本庫(kù)中的樣本數(shù)量,即通過(guò)生成圖像模擬不同參數(shù)和條件下的產(chǎn)品.最后,結(jié)合圖像處理和機(jī)器學(xué)習(xí)方法,通過(guò)分析生成的圖像樣本和與之相關(guān)的參數(shù)信息,建立預(yù)測(cè)模型以優(yōu)化產(chǎn)品質(zhì)量.顯然,上述研究將會(huì)推動(dòng)工業(yè)領(lǐng)域質(zhì)量管理和控制技術(shù)的發(fā)展,實(shí)現(xiàn)對(duì)產(chǎn)品質(zhì)量的優(yōu)化和改進(jìn),提高工業(yè)生產(chǎn)的效率和競(jìng)爭(zhēng)力.
6)基于生成圖像跟蹤特征目標(biāo)的工業(yè)過(guò)程控制和優(yōu)化.本文認(rèn)為,基于生成圖像跟蹤特征目標(biāo)在助力工業(yè)過(guò)程的控制和優(yōu)化方面具有較大的應(yīng)用潛力,具體表現(xiàn)在: 可用于工業(yè)過(guò)程目標(biāo)的感知和識(shí)別,目標(biāo)位置、狀態(tài)和運(yùn)動(dòng)軌跡的實(shí)時(shí)監(jiān)測(cè);基于跟蹤信息實(shí)現(xiàn)自適應(yīng)的控制和優(yōu)化策略,進(jìn)行更高效、精確和可靠的工業(yè)生產(chǎn)過(guò)程跟蹤控制;通過(guò)比較生成圖像與預(yù)期目標(biāo)圖像的差異進(jìn)行異常檢測(cè)和故障診斷,及時(shí)檢測(cè)和識(shí)別工業(yè)過(guò)程中的異常行為或故障情況,支撐容錯(cuò)控制算法的設(shè)計(jì)與實(shí)現(xiàn);通過(guò)實(shí)時(shí)監(jiān)測(cè)目標(biāo)的位置和狀態(tài)對(duì)資源進(jìn)行優(yōu)化分配和利用,進(jìn)而提高生產(chǎn)效率和資源利用率;通過(guò)自動(dòng)化的生成圖像分析和目標(biāo)跟蹤,促進(jìn)工業(yè)過(guò)程的智能化和無(wú)人化,減少對(duì)人力資源的依賴,提高對(duì)生產(chǎn)過(guò)程的可控性和安全性.未來(lái)的研究方向包括提高生成圖像跟蹤的精度和穩(wěn)定性,探索更為有效的目標(biāo)識(shí)別和跟蹤算法以及將其與工業(yè)過(guò)程的控制和優(yōu)化相結(jié)合,提高工業(yè)過(guò)程的智慧化水平,實(shí)現(xiàn)更為高效、可持續(xù)和安全的工業(yè)生產(chǎn).
5 總結(jié)與展望
本文首先概述了圖像生成研究現(xiàn)狀,闡釋了工業(yè)過(guò)程圖像生成的定義、流程、評(píng)估和應(yīng)用需求;然后,簡(jiǎn)要分析了在工業(yè)領(lǐng)域具有潛在應(yīng)用價(jià)值的圖像生成算法;接著,依據(jù)圖像生成流程,從圖像生成、生成圖像評(píng)估和應(yīng)用3 個(gè)視角進(jìn)行詳細(xì)綜述;最后,討論了這些算法的技術(shù)特點(diǎn)和研究難點(diǎn).筆者認(rèn)為,為獲得具有全局分布特性的工業(yè)過(guò)程生成圖像樣本集,未來(lái)的研究主要面臨著以下挑戰(zhàn):
1)大規(guī)模模型的融入: 隨著深度學(xué)習(xí)的快速發(fā)展,大規(guī)模模型在圖像生成任務(wù)中已經(jīng)展現(xiàn)出巨大潛力.考慮到將大規(guī)模模型應(yīng)用于工業(yè)過(guò)程中需要解決計(jì)算資源消耗、模型復(fù)雜度和訓(xùn)練效率等問(wèn)題,未來(lái)的挑戰(zhàn)應(yīng)致力于如何通過(guò)高效地融入大規(guī)模模型以提升特定行業(yè)的生成圖像的質(zhì)量和效率.
2)多模態(tài)場(chǎng)景的生成: 工業(yè)過(guò)程涉及多種場(chǎng)景和特征,單一的生成模型難以覆蓋所有工況下的圖像生成需求.研究人員可探索設(shè)計(jì)具有多模態(tài)特性的生成模型,通過(guò)將每個(gè)模態(tài)專注于特定的工業(yè)場(chǎng)景或特征等方式提高生成圖像的逼真度和多樣性,包括考慮但不限于在光照、材質(zhì)、形狀等方面的變化.
3)基于生成圖像的關(guān)鍵參數(shù)檢測(cè)和工業(yè)過(guò)程控制: 在工業(yè)過(guò)程中,生成的圖像中不僅包含視覺(jué)信息,其還蘊(yùn)含關(guān)鍵過(guò)程參數(shù)和控制信息.研究如何準(zhǔn)確提取生成圖像中的關(guān)鍵過(guò)程參數(shù)并將其應(yīng)用于工業(yè)過(guò)程的控制和優(yōu)化是一個(gè)重要的開(kāi)放性問(wèn)題.未來(lái)的研究可探索基于生成圖像的關(guān)鍵過(guò)程參數(shù)檢測(cè)和工業(yè)過(guò)程優(yōu)化控制策略,進(jìn)而實(shí)現(xiàn)工業(yè)過(guò)程的智慧運(yùn)行.
綜上所述,面向工業(yè)過(guò)程的圖像生成及其應(yīng)用研究面臨著大規(guī)模模型的融入、多模態(tài)場(chǎng)景的生成和基于生成圖像的關(guān)鍵參數(shù)檢測(cè)和工業(yè)過(guò)程控制等挑戰(zhàn).解決這些挑戰(zhàn)將為工業(yè)領(lǐng)域提供更高質(zhì)量、多樣化和可控的圖像生成技術(shù),并推動(dòng)工業(yè)過(guò)程的創(chuàng)新和進(jìn)步.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
