整合卷積與高效自注意力機制的圖像分類模型
2024-03-05 01:47:00田鑫馳王亞剛
小型微型計算機系統 2024年3期
田鑫馳,王亞剛,尹 鐘,陳 浩
(上海理工大學 光電信息與計算機工程學院,上海200093)
0 引 言
神經網絡是過去幾年深度學習領域最重要的研究課題之一,Krizhevsky等人[1]提出的AlexNet使得研究者們重新認識了卷積神經網絡(Convolutional Neural Network,CNN).后續在此基礎上出現了很多性能更加優秀的網絡,如Simonyan等人[2]提出的VGG首次嘗試更深的網絡結構,旨在疊加更多的卷積層以獲得更優秀的特征提取性能.He等人[3]認為簡單加深模型深度會造成網絡性能衰減,提出了一種瓶頸殘差結構來減少特征退化問題.卷積運算依賴于固定的感受野,只能提取到感受野附近的特征信息.依靠多個卷積層可以一定程度上緩解全局感受野的缺失,但大量堆疊卷積或池化層會造成特征退化,使得網絡丟失學習到的信息,導致模型性能下降.Woo等人[4]嘗試采用更大的卷積核來擴大感受野,卻帶來了龐大的參數量和計算資源浪費.由于傳統的卷積神經網絡在全局特征表示方面存在著巨大的困難,導致在準確率性能方面無法實現更大地突破.
2017年谷歌提出的自注意力機制[5]首次被應用于自然語言處理領域并迅速成為其主流架構.隨后Dosovitskiy等人[6]提出的Vision Transformer(ViT)首次將自注意力機制應用在計算機視覺,并在許多領域都表現出了顯著的優勢,例如目標檢測[7]、語義分割[8]和圖像去雨[9]等.然而ViT還存在著許多尚待解決的問題.一方面由于自注意力機制缺乏局部表征的特性,導致Transformer模型在處理底層信息(如圖像的邊緣和角落部分)會耗費大量的運算資源.另一方面,ViT缺乏卷積特有的圖像歸納偏置屬性導致模型參數量和計算復雜度過于龐大.Dai等人[10]已經證明圖像歸納偏置對于計算機視覺任務來說是極其重要的.尤其在數據量有限的情況下,ViT的模型性能會出現較大的衰退,原因在于多頭注意力中頭之間過分靈活的信息交互能力為模型帶來了極高的過擬合風險.
基于上述討論,本文提出了一種高效的圖像分類模型.CSNet(Convolution with Self-Attention Network)沿用多階段分辨率下采樣的結構,在模型淺層階段使用一種特殊的卷積特征提取模塊(Convolution Block).它在繼承大核卷積大范圍感受野的同時,還減少了不必要的計算浪費.在深層階段利用附帶深度可分離注意力機制的全局特征構建模塊(Attention Block),將深度可分離卷積融合在自注意力機制中,使得多頭注意力的全局依賴性由輸入信息和卷積感受野及其鄰域的權重共同決定.在數據量有限的情況下有效降低了過擬合的風險.通過以分階段的方式逐步堆疊Convolution Block和Attention Block,可以很好地整合兩種不同類型的特征構建模塊來促進表征學習,為圖像分類領域提供了一個強大的識別網絡.
1 相關工作
1.1 自注意力機制與Vision Transformer
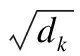
(1)
Vision Transformer(ViT)是第1個將自注意力機制應用在計算機視覺領域的模型.圖1所示為ViT的工作原理.首先將輸入的一張圖片劃分為一連串尺寸相同且不重復的二維標記,然后將這些標記與附帶一組表征區域位置信息的位置編碼一起送入Transformer Block中對全局特征信息進行建模.最后送入分類頭進行分類.其中自注意力機制是Transformer Block收集全局信息的主要依據.ViT擁有相較于CNN更加巨大的參數量和計算損耗,且只能應對固定尺寸的輸入信息,不適用于一些更加密集的視覺預測任務.Li等人[12]認為ViT中的自注意力機制在編碼低層次特征信息方面效率不高.即大部分的計算量都用來提取輸入圖片低層次的信息,這阻礙了它們在高效學習表征方面的巨大潛力.

圖1 Vision Transformer結構Fig.1 Structure of Vision Transformer
1.2 卷積神經網絡與自注意力機制的結合
卷積運算有著獨特的跨度不變和權重共享的特性,使得卷積神經網絡可以應對任意大小的輸入信息.卷積操作擅長減少局部冗余,避免不必要的計算量,通過聚合每個感受野像素及其鄰域的上下文信息來構建特征圖.之后有很多工作嘗試將卷積加入自注意力機制中,因為卷積所擁有的圖像歸納偏置可以很好地彌補自注意力所缺失的捕獲局部特征信息的能力.CvT[13]替換了Self-Attention中原有的線性映射層,輸入序列通過3個卷積層分別獲得矩陣Q、K、V,并通過跨步卷積來減少獲取標記的計算復雜度.MobileViT[14]將ViT中的Transformer Block與特殊設計的純卷積模塊組合起來,在保持高準確率的同時擁有較低的參數量和模型規模,使其可以在移動設備中很好地發揮優勢.CPVT[15]和CSwin Transformer[16]則采用了基于卷積的位置編碼,降低了模型計算的復雜度,尤其在下游任務中變現優異.CoAtNet[10]在模型前兩個階段采用MBConv[17]來獲取圖片的底層信息,并且詳細討論了卷積模塊與Transformer Block最優的組合方式,表現出極強的模型性能.本文延續了這種卷積模塊與Transformer Block互補的整體架構,在模型前期階段選擇利用卷積來構建特征信息.
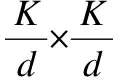
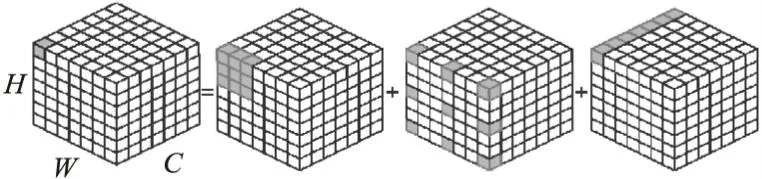
圖2 卷積分解操作Fig.2 Convolutional decomposition
本文將上述卷積分解的思想運用在CSNet前期的卷積特征提取模塊中以增大卷積運算的感受野.通過分解后的不同類型卷積層感受野及其鄰域的上下文信息聚合來彌補全局感受野的缺失.
2 CSNet
本節將介紹CSNet的詳細架構.CSNet延續PVT[19]多階段分辨率下采樣的整體結構,在4個特征提取階段中分別使用Convolution Block和Attention Block相結合的形式.首先描述了CSNet中的各種特征提取模塊的詳細架構,其次解釋了一些關鍵模塊,如Convolution Block中的卷積等效分解.最后討論了CSNet與現有的CNN和Transformer模型之間的區別,顯示了其在準確性和模型規模上較先前工作的優勢.
2.1 Convolution Block
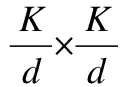
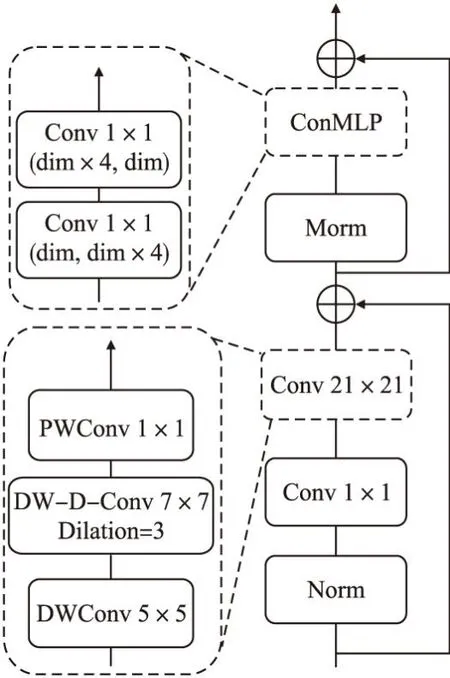
圖3 卷積特征提取模塊Fig.3 Convolution block
Params=K×K×Cin×Cout
FLOPs=K×K×Cin×Cout×H×W
(2)
而進行上述卷積分解操作后的參數量和計算量分別為:
(3)
其中Cin與Cout分別為圖像的輸入與輸出通道數.CSNet中的Convolution Block將一個21×21的卷積分解為一個7×7的深度可分離卷積、擴張率為3的7×7深度擴張可分離卷積,最后經過一個1×1的點卷積來還原通道數以實現殘差連接.由公式(2)和公式(3)可以看出,當卷積核與擴張率越大時,參數量與計算量的減少更加明顯,也說明了此種對大核卷積分解方法的高效性.
與ViT中的Transformer Block相比,Convolution Block采用一個名為ConMLP的模塊來代替原有的多層感知機(MLP)結構.兩者的區別是將MLP中的線性映射層替換為卷積核大小和步距都為1的卷積層.該結構設計的思路源于在ViT的Transformer Block中,輸入序列X∈N×C經過多頭注意力層后進入多層感知機(全連接層)結構,無需調整輸入形狀即可連接到下一個特征構建模塊.ConMLP若沿用原始MLP結構,在經過分解卷積模塊后需要將輸入序列X∈H×W×C先展平為X∈N×C,經過全連接層后為了能與下一個卷積特征提取模塊有效連接,不得不再將輸入形狀還原回X∈H×W×C.當模型規模較大,即Convolution Block重復次數和卷積層輸出通道數變大時,使用MLP結構會消耗大量的運算資源,使得模型變得難以訓練.在一個特征提取模塊內使用相同性質的結構可以有效減少計算復雜度.故ConMLP中用1×1的卷積層來代替原始MLP中的全連接層.
Convolution Block同樣使用先提高輸出通道維度再還原的結構,在每個模塊前進行批量歸一化(Batch Normalization,BN)來加快模型收斂.在BN后使用GELU激活函數,利用殘差連接以減少特征退化.Convolution Block放置在靠前階段中利用較大感受野的靜態卷積更好地捕獲局部信息,以減少自注意力機制花費過多的計算資源去構建圖像底層特征信息,有效地提升了模型的運算效率.
2.2 DWMSA與Attention Block
Zhou等人[20]認為在多頭自注意力機制(Mutil-head Self-Attention,MSA)中隨著Transformer Block的增多,一部分頭在堆疊多次特征構建模塊后會學習到重復的特征信息,造成計算資源浪費和模型性能衰退.注意力退化的根本原因在于多頭注意力機制的輸出動態地取決于輸入表示,即學習到的權重信息無法去影響模型的學習偏好.MSA中過于靈活的頭為模型帶來動態的全局感受野和捕獲不同空間位置復雜信息能力的同時,也伴隨著很高的過擬合風險.尤其在數據量并不充足時,這種現象會更加頻繁地出現.卷積的輸出僅取決于感受野及其鄰域的權重信息,這種特性使得卷積神經網絡在有限的數據集下的表現要比Transformer模型更好.故本文考慮將卷積的特性引入到多頭注意力機制中來緩解注意力崩潰的問題.
對于卷積操作Attention Block主要考慮深度可分離卷積,它可以在保持準確率的前提下有效降低普通卷積的計算量.更為重要的是,深度可分離卷積的輸出取決于感受野及其鄰域附近的權重,可以幫助MSA擺脫全局注意力依賴.圖4所示為本文提出的深度可分離注意力機制(DepthWise Mutil-head Self-Attention,DWMSA).具體來說,對于一個二維輸入標記X∈N×C,沿空間維度還原成原始輸入圖像X∈H×W×C后,送入深度可分離卷積提取卷積感受野及其鄰域特征信息,同時加入注意力機制所或缺的卷積圖像歸納偏置.深度可分離卷積的加入使得多頭注意力機制擁有了捕獲底層特征相關的位置信息的能力.在特征構建過程進行到更深層次時,DWMSA對于位置信息的獲取將更加顯著.如果在獲取輸入標記前沒有加入深度可分離卷積,整個注意力特征構建模塊的輸出將全部動態地取決于輸入信息,無法區分局部附近特征關系的差異.如語義分割任務[21](天空和大海中的相同藍色斑塊會被分割為同一類別).為了防止原始二維標記內部信息被破壞,在深度可分離卷積運算之后將三維圖像重新展平為X∈N×C,使用層歸一化(Layer Normalization)處理.最后通過線性映射分別得到矩陣Q、K、V.為了緩解每個頭之間學習到相同的特征信息,減少注意力崩潰的問題,在Softmax之后使用一個1×1的普通卷積來加強各個頭之間的信息聯系與交互.最后與V相乘獲取注意力圖.深度可分離注意力機制的表達式可以為:
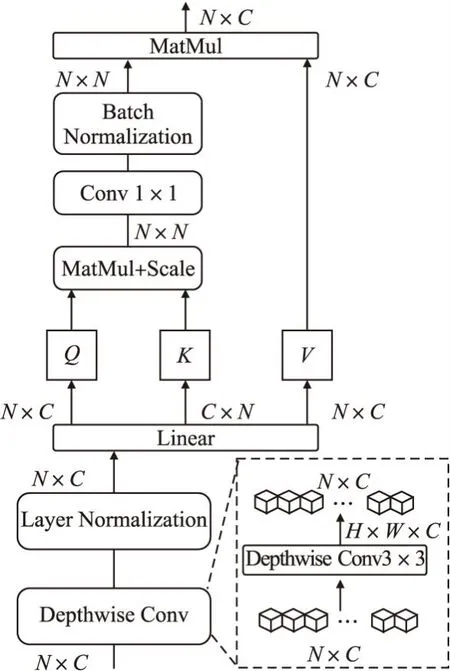
圖4 深度可分離注意力機制Fig.4 DepthWise mutil-head self-attention(DWMSA)
(4)
上式中BN表示Batch Normalization,Conv1×1表示卷積核大小為1的普通卷積運算.
圖5(a)圖和圖5(b)圖分別為ViT中的Transformer Block和CSNet中的Attention Block.兩種特征構建模塊唯一的區別是將Transformer Block中的多頭注意力機制(MSA)替換為更加高效的深度可分離注意力機制(DWMSA).仍然保留線性MLP來擴展通道維度,在每個模塊前使用Layer Normalization且利用殘差連接來防止特征退化.將Attention Block放置在CSNet的深層階段中可以最大化發揮深度可分離注意力機制的全局特征信息提取的能力,還可以通過深度可分離卷積捕獲局部空間信息的特性為自注意力機制加入所需的卷積特性以提高模型的泛化能力和準確率.最終Attention Block的輸出表達式為:
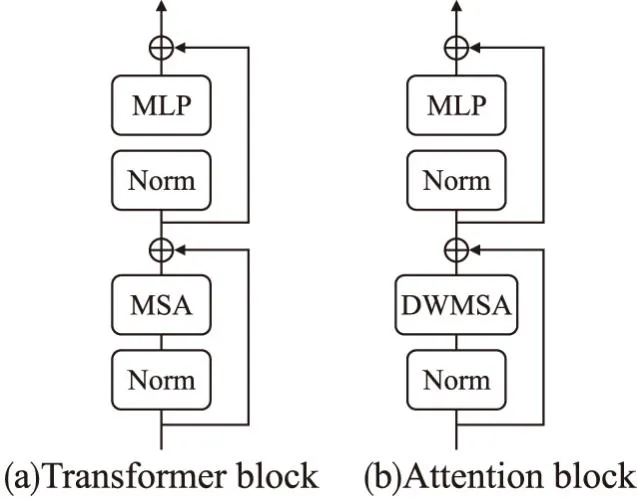
圖5 注意力特征提取模塊Fig.5 Attention block
y=x′+MLP(LN(x′)) x′=x+DWMSA(LN(x))
(5)
其中LN代表Norm模塊,即Layer Normalization操作.
2.3 CSNet整體結構
圖6所示為CSNet的整體結構.圖中L表示對應特征提取模塊重復的次數,FC表示最后用來分類的線性映射層.模型整體沿用多階段分辨率下采樣的架構,共分為4個不同類型的階段(Stage)來分別構建特征信息.前兩個階段(模型淺層階段)采用Convolution Block,后兩個階段(模型深層階段)采用Attention Block進行特征提取.下采樣模塊采用一個3×3的普通卷積層將分辨率下采樣的同時提高輸出通道數.除第1個下采樣模塊的下采樣率(即步距S)為4以外,其余階段S均設置為2.Convolution Block中的卷積分解模塊和Attention Block中的DWMSA都采用預激活結構[22].與ViT模型相比,CSNet放棄了使用原始位置編碼.原因在于Attention Block中的DWMSA利用深度可分離卷積的特性在感受野及其鄰域附近已經提取到了部分權重信息,其中包含了原始圖像的位置信息.同樣也沒有選擇增加一個額外的分類標記,而是利用類似卷積神經網絡的結構將全局平均池化層應用于最后階段的輸出,以獲得簡單的輸出表示.

圖6 CSNet結構Fig.6 Structure of CSNet
為了適應不同規模的應用場景,根據每個Stage的模塊重復次數和輸出通道數的不同實例化了3種不同模型容量的CSNet,分別名為CSNet-Tiny、CSNet-Small和CSNet-Base.表1所示為3種模型變體的詳細架構.其中C表示每個Stage的輸出通道數.H表示多頭注意力機制中頭的個數.R表示不同特征提取模塊中ConMLP和MLP輸出通道維度的擴展倍數.對于不同規模的CSNet模型,特征構建階段統一使用C-C-A-A的模塊組合方式,其中C和A分別表示本文提出的Convolution Block和Attention Block.不同模塊組合方式的性能對比將在3.4.2節中進行詳細說明.
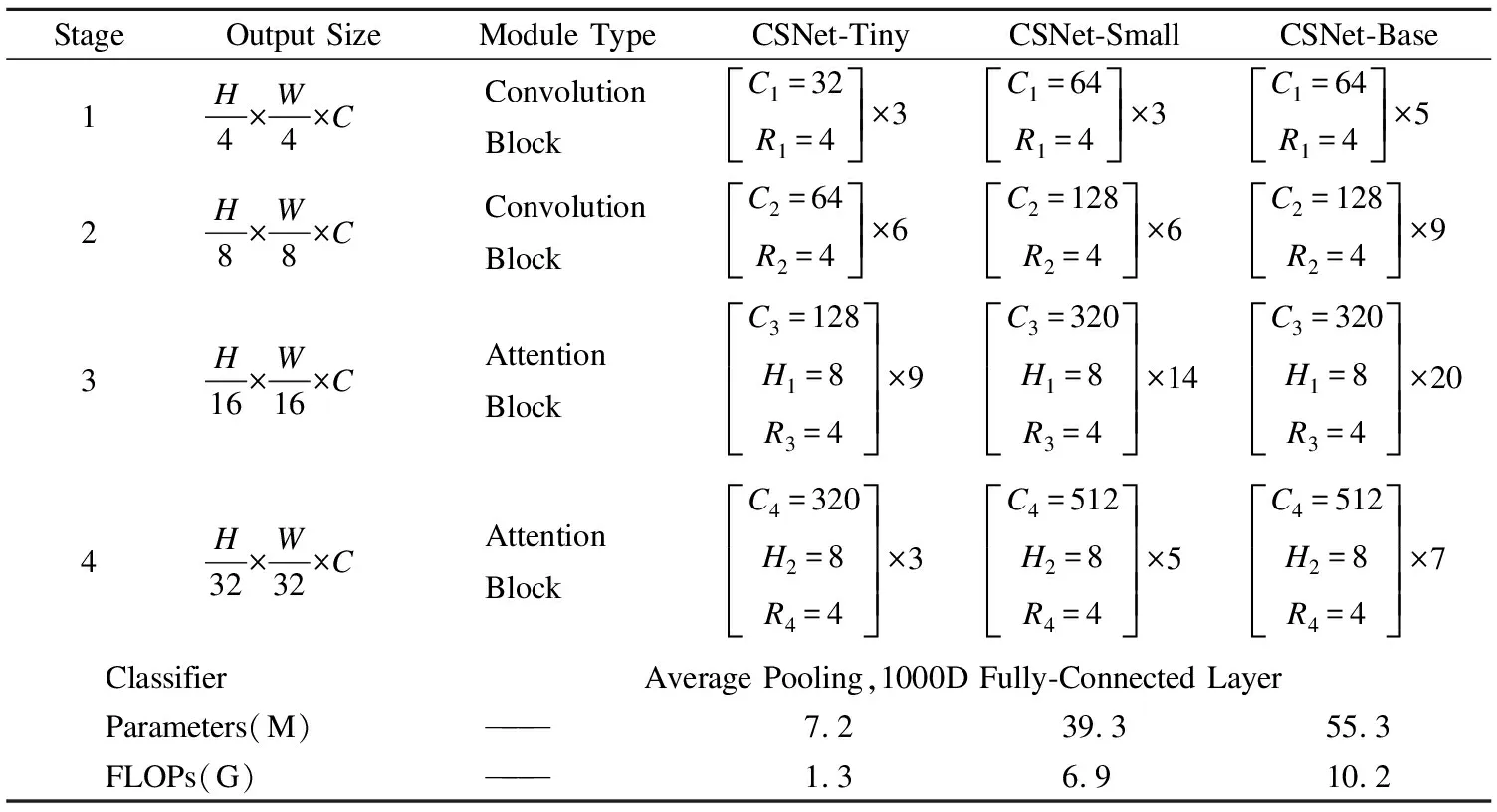
表1 不同規模的CSNet Table 1 Different sizes of CSNet
3 實驗與分析
在這一節中,實驗分別在ImageNet-1K和CIFAR-10數據集上評估了CSNet模型的圖像分類性能.隨后在提出的Convolution Block中嘗試不同卷積核大小和擴張率的搭配來尋找較為合適的卷積分解運算.最后綜合模型的參數量和準確率,找到了不同模塊之間最佳的組合方式.
3.1 實驗環境及模型訓練
實驗全部在PyTorch框架下進行訓練.對于ImageNet-1K數據集來說,訓練過程使用動量大小為0.9的AdamW優化器,總共訓練300個epochs,使用余弦衰減學習率策略[23]和20個epochs的線性預熱階段(Linear warm-up[24]).模型使用交叉熵損失函數(Cross Entropy Loss).交叉熵損失函數的表達式為:
(6)
訓練使用總批量大小(Batch Size)為1024(訓練過程使用4個GPU并行,每個GPU上有256幅圖像).特別的,訓練CSNet-Base時Batch Size調整為512.所有訓練模型初始的學習率設置為0.002,權重衰減為0.05.數據增強策略使用簡單的隨機水平翻轉,隨機擦除.使用標簽平滑策略[25]對網絡進行正則化.整個訓練過程默認使用分辨率為224×224的圖像.對于CIFAR-10數據集的訓練,初始學習率設置為0.02,權重衰減為0.0001.采用動量為0.9的AdamW優化器,批量大小為128,總共訓練150個epochs.
3.2 數據集介紹
CIFAR-10是一個用于圖像分類的小型數據集.該數據集共有6萬張分辨率大小為32×32的彩色圖像.一共有10個類別,如貓、汽車和飛機等.其中訓練集包含5萬張圖像,測試集包含1萬張圖像.
ImageNet-1K數據集共有1000個分類類別,其中包含約130萬張訓練圖像和5萬張驗證圖像.作為圖像分類領域最為廣泛使用的公共數據集,在ImageNet-1K上測試出的實驗結果通常被作為模型普遍的性能指標.在訓練過程中將ImageNet-1K數據集中所有圖像的輸入分辨率調整為224×224.
3.3 模型性能對比實驗
在這一部分中,實驗將CSNet的模型性能與許多先進的分類模型分別在ImageNet-1K和CIFAR-10數據集上進行了對比.
在ImageNet-1K上的對比結果如表2所示.對比的模型包含了卷積模型、Transformer模型和CNN與Transformer相結合的模型.在模型規模較小的情況下,CSNet-Tiny比ResNet-18[3]、PoolFormer-S12[26]和T2T-ViT-12[27]的準確率分別高出8.0%,、0.6%和1.3%,同時參數量和FLOPs都有不同程度的減少.在模型規模較大時,CSNet相較于卷積模型有了明顯的優勢.如CSNet-Small比ResNet-101的準確率高出4.4%,而相應的參數量和FLOPs則分別下降了12.1%和12.7%.CSNet-Small與RegNetY-8G[28]相比則在FLOPs方面上表現出優勢.對于Transformer模型來說,CSNet也表現出了顯著的性能優勢.CSNet-Small的準確率在比PVT-M[18]提高了0.6%的情況下,依然能保持較小的參數量和計算復雜度.當需要使用更大規模的模型應對復雜場景時,CSNet-Base也能展示出較Transformer模型更加優秀的性能表現.如CSNet-Base的準確率比DeiT-B[29]和T2T-ViT-24分別提高了0.8%和0.3%,參數量分別下降了36.2%和13.8%,FLOPs相對應的分別下降了70.6%和32.0%.圖7展示了CSNet與其他分類網絡的性能對比圖.可以清晰直觀地看出CSNet相較于這些網絡在參數量及FLOPs性能指標上都有明顯的優勢.
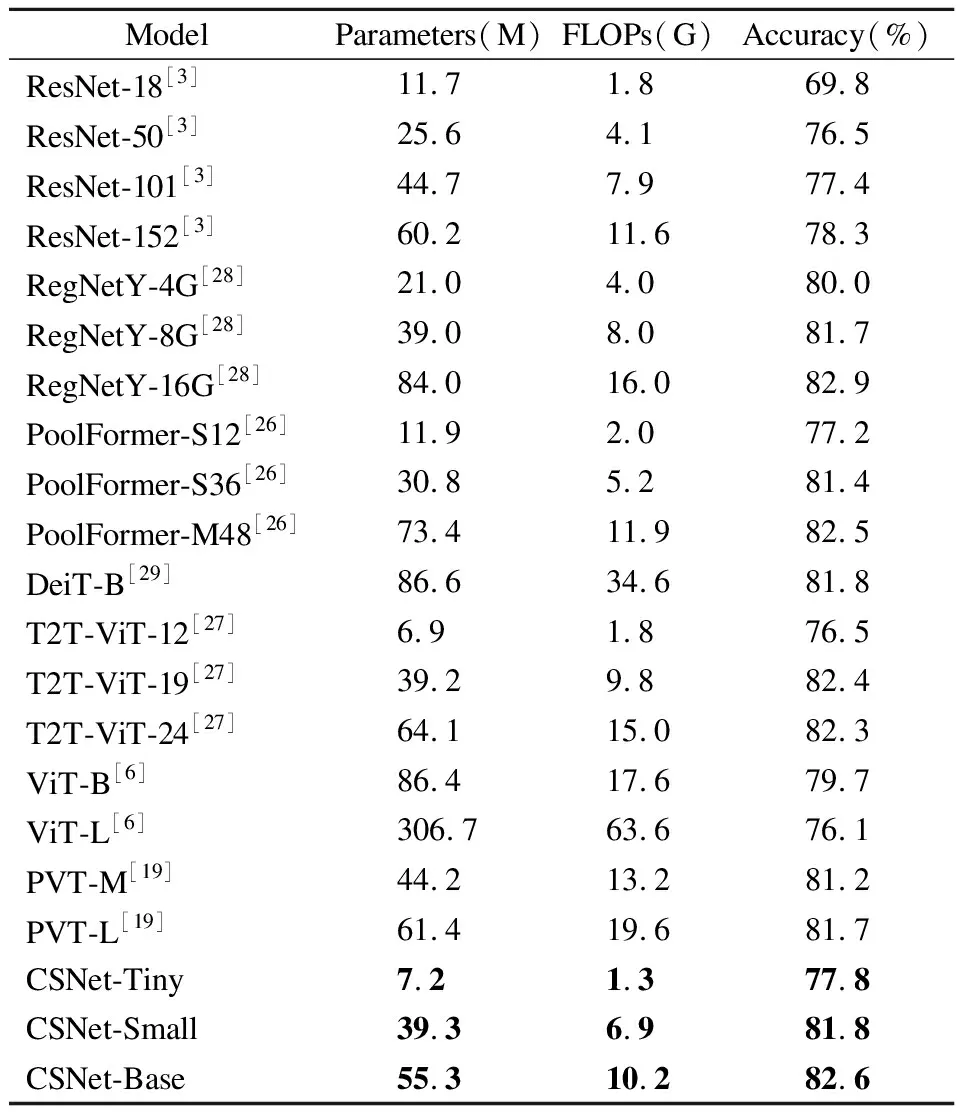
表2 ImageNet-1K上的模型對比試驗Table 2 Model comparison experiments on ImageNet-1K
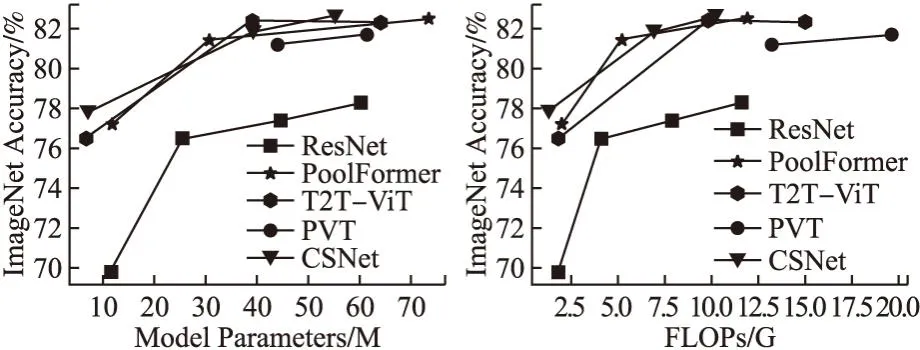
圖7 模型性能對比圖Fig.7 Model performance comparison
上一組對比實驗已經驗證了在大型數據集上不同規模的CSNet能夠有良好的表現.為了進一步研究CSNet在各種不同應用情況下的適應性,在小型數據集CIFAR-10上測試了CSNet的模型表現,對比結果如表3所示.可以看出CSNet-Small和CSNet-Base在CIFAR-10上的準確率分別達到了98.6%和98.9%,性能優于ResNet、ViT和T2T-ViT模型.實驗證明了CSNet擁有比傳統CNN模型更好的模型性能和比Transformer模型更好的泛化性,能夠在小型數據量的下游任務中取得良好的效果.
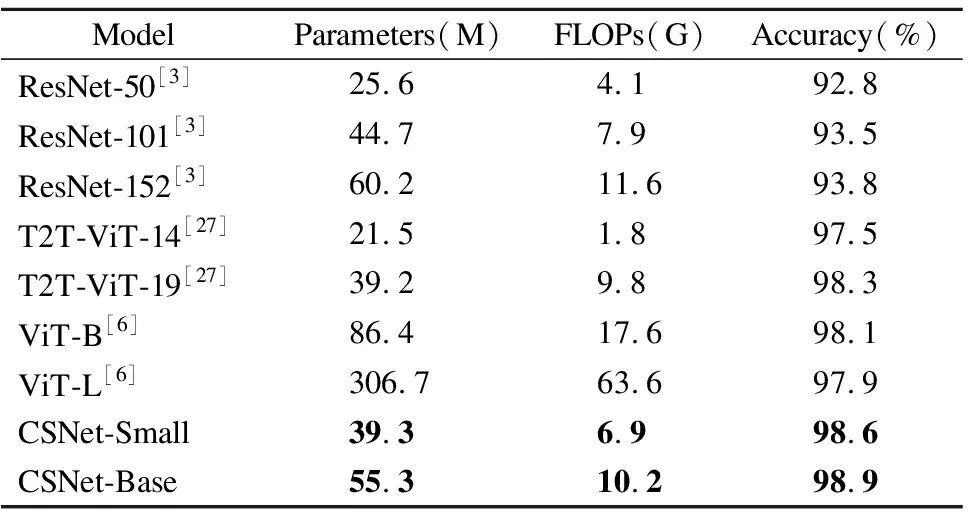
表3 CIFAR-10上的模型對比試驗Table 3 Model comparison experiments on CIFAR-10
3.4 消融實驗
3.4.1 分解不同大小的卷積層
CSNet的Convolution Block利用將一個大核卷積分解為一個深度可分離卷積、一個深度可分離擴張卷積和一個點卷積的思想來捕獲長距離的關系.在這一部分中,實驗選取CSNet-Tiny在ImageNet-1K上測試Convolution Block中不同卷積核大小以選擇最優的大型卷積核予以分解.表4展示了4種附帶不同大小擴張率(Dilation rate)的卷積核.從表中可以清楚地看到,當卷積核大小分別為21和28,擴張率分別為3和4時,準確率達到了最高的77.8%.21×21與7×7的卷積核相比,在參數量和FLOPs只有小幅提升的前提下,準確率上升了0.2%.上述現象表明大核卷積對于計算機視覺任務是十分重要的.在參數量與計算復雜度相似的情況下,更大的卷積核意味著更大的感受野,可以提取到更多區域的特征信息.28×28與21×21的卷積核相比,準確率方面沒有明顯的提高,但卻增加了少量的參數和FLOPs.故CSNet的Convolution Block都默認分解卷積核大小為的卷積運算.
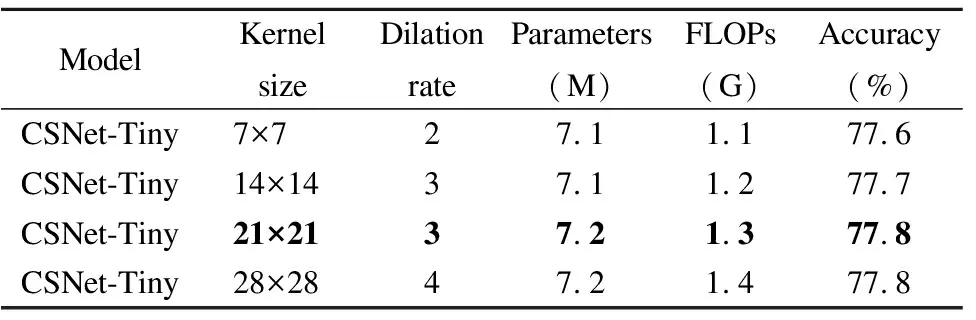
表4 分解不同大小卷積核的性能表現Table 4 Performance of decomposing different size convolutional kernels
3.4.2 CSNet中模塊的不同組合
CSNet與CoAtNet[10]分階段組合不同模塊的整體架構相同.為了更好地發揮卷積提取底層信息的優勢,各模塊的組合應遵守Convolution Block在前期階段處理低層次特征信息的約定.這導致出現了3種不同階段的模型變體.從Stage 1~Stage 4分別為C-C-C-A、C-C-A-A和C-C-A-A的組合模式,其中C和A分別代表Convolution Block和Attention Block.為了能系統地研究每種模塊組合的性能,實驗使用CSNet-Small測試了3種不同模型變體在ImageNet-1K上的準確率.由表5可以看出,組合模式為C-C-C-A的模型變體擁有最多的參數量和計算復雜度,準確率只達到了80.9%.造成上述現象的原因是在CSNet整體結構中Stage3占據了大部分的模塊重復次數.當輸出通道數隨著階段數增大后,Convolution Block中的分解卷積運算占據了大部分的計算量.組合模式分別為C-C-A-A和C-A-A-A的模型變體在參數量和計算復雜度相近的情況下,準確率分別達到了81.8%和81.6%.對于C-C-A-A和C-C-A-A來說,都在前期Stage利用了Convolution Block中卷積提取局部特征信息的能力來增強模型的泛化能力.從最后的準確率可以看出,C-C-A-A比C-A-A-A組合模式的準確率高0.2%.先前的一些工作[30]已經證明了自注意力機制所擁有的全局感受野在計算機視覺領域是非常重要的.上述現象表明僅僅擁有更多的Attention Block并不意味著更好地視覺處理能力.綜上所述,不同模型容量的CSNet均采用C-C-A-A的模塊組合方式.
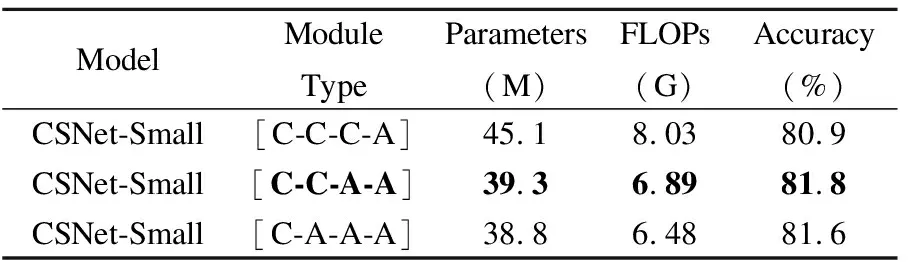
表5 不同模塊組合的性能表現Table 5 Performance of different module combinations
3.5 類激活圖可視化
Grad-CAM[31]可以用于可視化模型的鑒別區域.圖8展示了Grad-CAM分別對ResNet-101,Swin-T[32]和CSNet-Small在ImageNet數據集上的類激活圖可視化.可以看出,與ResNet相比CSNet擁有更加寬廣的視覺范圍,這得益于在模型淺層擴張卷積較大的感受野.與Swin相比,CSNet可以更為準確和完整地定位目標物體,尤其圖片中有其他標簽物體時,CSNet表現出更加顯著的優勢.例如第1張輸入圖片CSNet準確注意到了整個狗的部分,并忽略了旁邊的人物.

圖8 類激活圖可視化Fig.8 Gradient-weighted class activation mapping
4 結束語
本文提出了一種全新高效的圖像分類網絡,命名為CSNet.它可以有效地分階段結合卷積與自注意力模塊以克服全局感受野缺失和局部表征不足等問題.在模型淺層階段將大核卷積分解為3種不同類型的卷積層,在保持較少參數的同時彌補了傳統卷積神經網絡較小感受野所帶來的局限性.在深層階段使用本文提出的深度可分離注意力機制,利用深度可分離卷積捕獲局部空間交互的能力來緩解多頭注意力機制極高的過擬合風險和對于數據本身嚴重的依賴性.尤其在數據量和模型規模有限的情況下也能利用全局感受野來捕獲特征信息以實現較高的準確率.實驗表明CSNet擁有強大的特征建模能力,在圖像分類任務中以適量的參數和計算復雜度取得了優異的性能表現.
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年21期)2018-11-09 01:23:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
