基于PSO的聯合任務卸載與緩存算法研究
2024-03-05 07:41:24周天清
無線電工程 2024年3期
關鍵詞:關聯
周天清,許 銘
(華東交通大學 信息工程學院,江西 南昌 330013)
0 引言
近年來,各類計算敏感(Computation-Sensitive,CS)型和高數據率(High-Rate,HR)服務不斷涌現,如移動游戲、認知輔助和虛擬/增強現實服務等。這些服務帶來諸多便利和娛樂的同時,也帶來了大量挑戰:它們往往有較大的任務數據或較高的計算量,導致了移動終端(Mobile Terminal,MT)計算資源和能量緊張的問題,也造成了頻譜和回程資源短缺的問題。為緩解MT的壓力,云計算技術被提出。通過云計算技術,MT的計算和緩存工作可交由遠程云端完成。但是,對于擁有CS和HR服務的MT而言,云計算技術具有明顯的缺陷[1]。具體而言,在當今高度擁擠的主干網絡上,將所有數據流量傳輸到遠程云端不切實際,尤其是對于高速增長的分布式數據流量。
為克服上述挑戰,移動邊緣計算(Mobile Edge Computing,MEC)和緩存技術被視為新型網絡架構中重要且不可或缺的部分。基于此,MEC網絡產生,它將數據服務和計算應用的前沿從云計算中心推向網絡的邏輯邊緣,從而使得計算和緩存工作能在數據源附近進行。在具備MEC和緩存功能的MEC網絡中,計算和緩存服務器被裝備到小基站(Small Base Station,SBS),這樣不僅可以縮短MT(目的地)與數據源之間的距離,還可以大大減少回程鏈路的資源消耗[2-3]。
盡管計算和緩存服務器的部署可以極大地支持CS和HR服務,保證較好的用戶體驗,但可能導致MT關聯(選擇)更為復雜[3-4]。在具備MEC和緩存的MEC網絡中,MT關聯不僅涉及基站的選擇,還需考慮計算和緩存模式的選擇。這意味著,在此類MEC網絡中,MT關聯可能會變得更為復雜且具挑戰性。
近年來,聯合邊緣計算與緩存的相關研究逐步熱化。在計算資源與存儲容量的限制下,文獻[5]執行MT選擇以最小化加權網絡時延;文獻[6]執行MT選擇與資源分配以最優化網絡吞吐量、計算與緩存費用。針對大數據MEC網絡,文獻[7]聯合考慮計算、緩存、通信與控制以優化網絡時延與帶寬消耗;文獻[8]聯合優化計算卸載決策、緩存部署、MT計算能力與發射功率以折衷網絡時延與能耗。在緩存與截止時延約束條件下,文獻[9]聯合考慮緩存、計算與通信以最小化加權和能耗,涉及軟件獲取、緩存與廣播,任務上傳、執行與結果下載。針對2層MEC網絡,文獻[10]聯合考慮數據緩存與計算卸載以折衷網絡時延與能耗;文獻[11]針對多任務系統,聯合考慮計算卸載、服務緩存、功率與計算資源分配以最小化所有MT的計算與延時費用。在緩存、功率與時延約束下,針對雙向計算任務模型,文獻[12]嘗試優化緩存與卸載決策以最小化平均使用帶寬。針對邊緣服務網絡,文獻[13]聯合執行計算卸載與內容緩存以最小化所有任務的響應時延。針對異構霧無線接入網絡,文獻[14]研究了聯合MT關聯、帶寬和功率分配以及緩存部署,同時考慮了能量效率和跨層干擾緩解。針對海上通信MEC網絡,文獻[15]嘗試優化任務卸載以降低任務時延與能耗。
上述研究鮮有聯合考慮頻譜、計算與緩存資源分配,很少涉及多蜂窩場景,且基本考慮有線回程。考慮到CS與HR服務對時延的敏感性,而服務時延直接影響到用戶網絡體驗,類似于文獻[3],本文以最小化MT平均時延為目標。同時,在多蜂窩無線回程網絡架構下,本文采用與其相同的頻帶劃分機制。不同于文獻[3],本文按MT所需資源占其服務基站的所有MT所需資源的比例分配頻譜、計算與緩存資源。這種根據需求比例分配資源的方式極大地削減了問題的規模,降低了算法復雜度。另外,本文考慮使用粒子群優化(Particle Swarm Optimization,PSO)[16]開發相應的MT關聯與資源分配算法。經仿真驗證,在按需求比例分配資源的方式下,該算法取得了較文獻[3]算法更優的性能。
1 系統模型
1.1 網絡模型
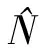
1.2 資源模型
為降低網絡干擾,本文采用了頻分和時分方案。具體而言,帶寬為W的系統頻帶F被劃分成F1和F2兩部分,帶寬分別為為ηW與(1-η)W,其中η為頻帶劃分因子且滿足0≤η≤1;信道相干塊T被分割成T1和T2兩個時隙且滿足T1+T2=T,分別用于上行鏈路和下行鏈路傳輸。此外,假定MT的上下行接入鏈路使用頻帶F1,但分別利用時隙T1和T2;假定MT的上下行回程鏈路使用頻帶F2,但分別利用時隙T1和T2;在上下行接入鏈路中,假定F1的 3個等帶寬子帶F1,1、F1,2、F1,3供不同鄰簇使用,其中一個宏小區構成一個簇;在上下行回程鏈路中,假定F2的3個等帶寬子帶F2,1、F2,2、F2,3供不同鄰簇使用。
顯然,通過采用不同的時隙,上下行接入鏈路間的干擾可以被消除,且上下行回程鏈路間的干擾也可被消除;通過使用不同的頻帶,接入鏈路和回程鏈路間的干擾可被消除。此外,在上下行接入鏈路中,任意2個宏小區因使用不同的頻帶而消除彼此間的干擾;類似地,在上下行回程鏈路中,任意2個宏小區因使用不同的頻帶而消除彼此間的干擾。
1.3 通信模型
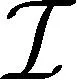
在上下接入鏈路中,任意子帶(如F1,1、F1,2或F1,3)被均分給每個宏小區(簇)內的所有SBS;在上下行回程鏈路中,任意子帶(如F2,1、F2,2或F2,3)被均分給每個宏小區(簇)內的所有SBS;在上下行接入鏈路中,分配給SBS的頻帶被切片分配給其所關聯的MT;類似地,在上下行回程鏈路中,分配給SBS的頻帶被切片分配給其所關聯的MT。假定在下行接入和回程鏈路中,每個基站的頻帶切片只傳輸一個文件,這意味著文件索引與基站子信道索引一一對應,它們可以互用。
顯然,通過上述頻帶劃分方式,宏小區內任意 2個SBS間的上行接入干擾與下行接入干擾均可被消除;宏小區內任意2個SBS間的上行回程干擾與下行回程干擾均可被消除;小小區內任意2個MT間的上行接入干擾與下行接入干擾均可被消除;小小區內任意2個MT間的上行回程干擾與下行回程干擾均可被消除;在下行接入和回程鏈路上,小區內任意2個MT傳輸文件時不會產生相互干擾。
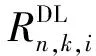
(1)
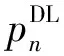

(2)
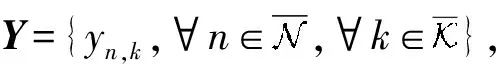
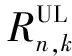
(3)
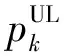
(4)
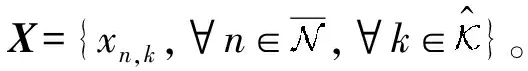
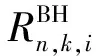
(5)
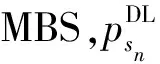
(6)
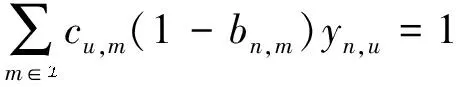
1.4 緩存模型
在現實中,文件請求通常遵循某種分布(例如Zipf分布),這種分布往往可以通過對歷史數據流進行統計分析獲取。換言之,在仿真過程中,文件的緩存索引可根據某種分布預先生成。值得注意的是,當所需文件已在SBS上緩存時,HRT可直接從其所關聯的SBS上獲取,否則HRT只能通過所關聯的SBS與最近MBS間的回程鏈路從核心網絡獲取。
于是,HRTk從SBSn下載文件i所花費的下行接入時間(時延)為:
(7)
HRTk通過SBSn和MBSsn間的回程鏈路下載文件i所花費的下行回程時延為:
(8)
因此,HRTk從SBSn獲取文件i的平均時延為:
(9)
1.5 計算模型

(10)
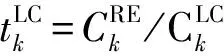
(11)
忽略計算結果下載時間,完成CSTk的計算任務所需時間為:
(12)
2 問題規劃
針對MEC網絡,為在資源約束條件下提升MT的CS與HR服務的質量,即降低任務計算和文件獲取時延,進而改進用戶網絡體驗,本文嘗試最小化MT的平均時延,即:
(13)
式中:wk為平均時延權重參數。此外,因為CSTk至多關聯至一個SBS,而HRTk必須關聯某一個SBS,因此存在:
(14)
在實際系統中,頻譜帶寬總是有限的。因此,分配給所有CST的上行接入總帶寬不能超過它們所關聯的SBSn的上行接入帶寬,這意味著:
(15)
同時,分配給所有HRT的下行接入總帶寬不能超過它們所關聯的SBSn的下行接入帶寬,即:
(16)
分配給所有HRT的下行回程總帶寬不能超過它們所關聯的SBSn的下行回程帶寬,即:
(17)
此外,任意緩存服務器的存儲容量都是有限的。因此,任意SBSn所緩存的文件量不能超過該基站的存儲容量Dn,即:
(18)
任意計算服務器的計算能力都是有限的,因此,任意SBSn分配給其所關聯CST的總計算資源不能超過該基站的計算資源,即:
(19)
為支持CSTk通過SBSn與最近MBS間的回程鏈路從核心網絡獲取文件i,下行接入數據速率應小于或等于下行回程數據速率,即:
(20)
本文所考慮的優化問題可規劃為:
(21)
3 PMARA算法
容易發現,式(21)為非線性混合整數優化問題,其最優閉式解難以獲取。為處理該類問題,集群智能算法可能是一種不錯的選擇。目前,此類算法因具有對各類問題的較強適應性而被廣泛應用[17-19]。PSO作為集群智能算法的成員之一,因具備收斂速度高、參數少與算法易實現等特點,已被廣泛應用于處理各類復雜問題[16]。為求解式(21),提出了基于PSO的MT關聯與資源分配(PSO-based MT Association and Resource Allocation,PMARA)算法尋找其最優化解。
3.1 粒子編碼

(22)
式中:w1和w2分別為對文件儲存超出SBS存儲空間和下行回程速率過低的懲罰系數。
3.2 粒子速度及位置更新
(23)
(24)
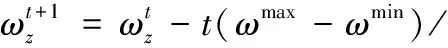
(25)
式中:ωmax和ωmin分別為最大、最小慣性權重,為PMARA算法的最大迭代次數。在PSO中,慣性權重控制著算法的探索能力,更大的可以使算法更容易跳出局部最優,提升搜索能力,而較小的有助于算法收斂。顯然,算法迭代初期時的探索能力較強,但隨著迭代次數的增加而逐步弱化,算法亦是趨于收斂。
(26)
(27)
式中:ψ(χ)表示對χ向下取整。
為保證全局最佳粒子v向著局部最小值移動,即保證PMARA算法的收斂性,該粒子的速度更新為:
(28)
(29)
然后,分別將式(28)和式(29)代入式(26)和 式(27),可得全局最佳粒子v的更新位置為:
最后,縮放因子κt可更新為:
(32)
式中:N1和N2分別表示連續成功的次數和連續失敗的次數,n1和n2表示閾值參數。當新一輪迭代后的全局最優值與上次迭代后的全局最優值相同時,搜索失敗,其他情況代表成功。顯然,N1>n1表示算法朝著更優值搜索成功的次數大于n1,此時增大κt以增加粒子朝此方向更新的速度;N2>n2表示朝著更優值搜索失敗的次數大于n2,此時縮小κt以降低粒子朝此方向更新的速度;在不滿足以上情況時,κt保持不變。
下面給出了PMARA算法的具體流程:
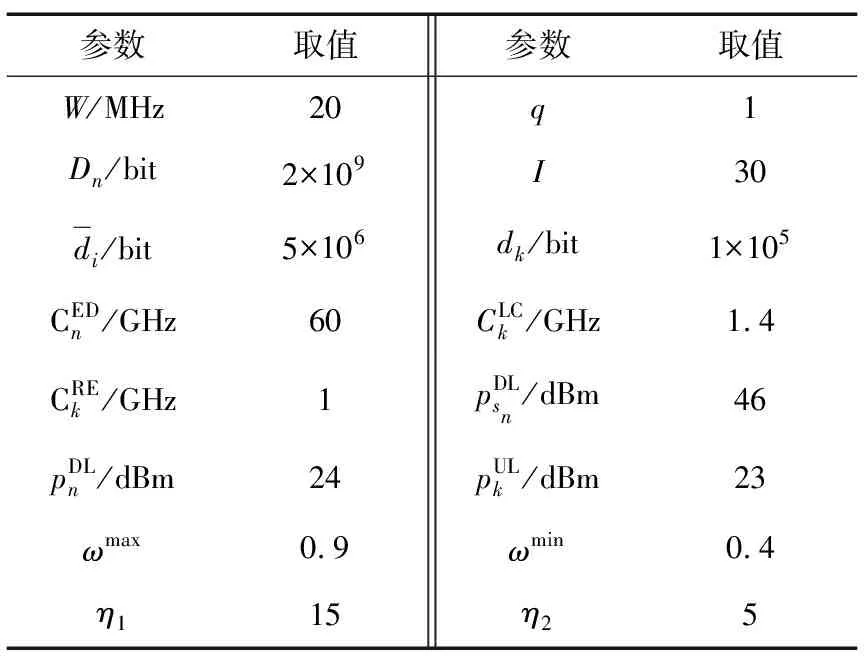
① 利用最佳信道關聯(Association with Best Channel Gain,ABCG)規則[3]初始化粒子的位置,利用式(2)、式(4)、式(6)和式(11)計算資源占比,利用式(22)計算所有粒子的適應度值,并設置迭代次序t=1。
② 令初始位置為個體最佳粒子的位置,并從它們中找到全局最佳粒子,最后以(0,1)的隨機數初始化個體最佳粒子與全局最佳粒子的速度。
③ 根據式(25)更新普通粒子的慣性權重,并利用式(23)和式(24)更新它們的速度,最后以式(26)和式(27)更新它們的位置。
④ 利用式(28)和式(29)更新全局最佳粒子的速度,并以式(30)和式(31)更新它們的位置。
⑤ 利用式(2)、式(4)、式(6)和式(11)計算資源占比,利用式(22)計算所有粒子的適應度值,最后以式(32)更新它們的縮放因子。
⑥ 更新所有粒子的歷史最佳位置,讓這些擁有歷史最佳位置的粒子為個體最佳粒子,并從它們中找到適應度值最高的粒子作為全局最佳粒子。
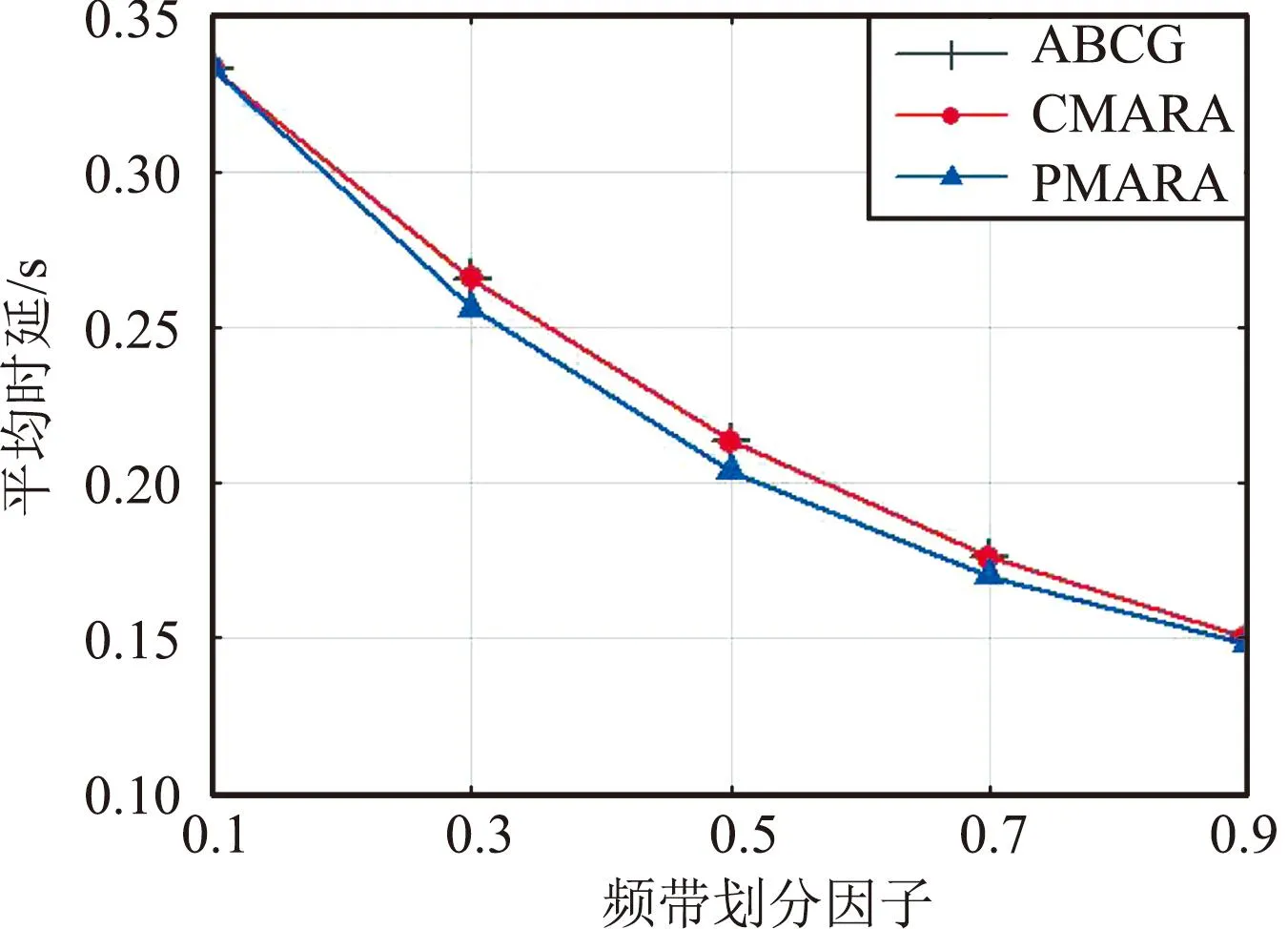
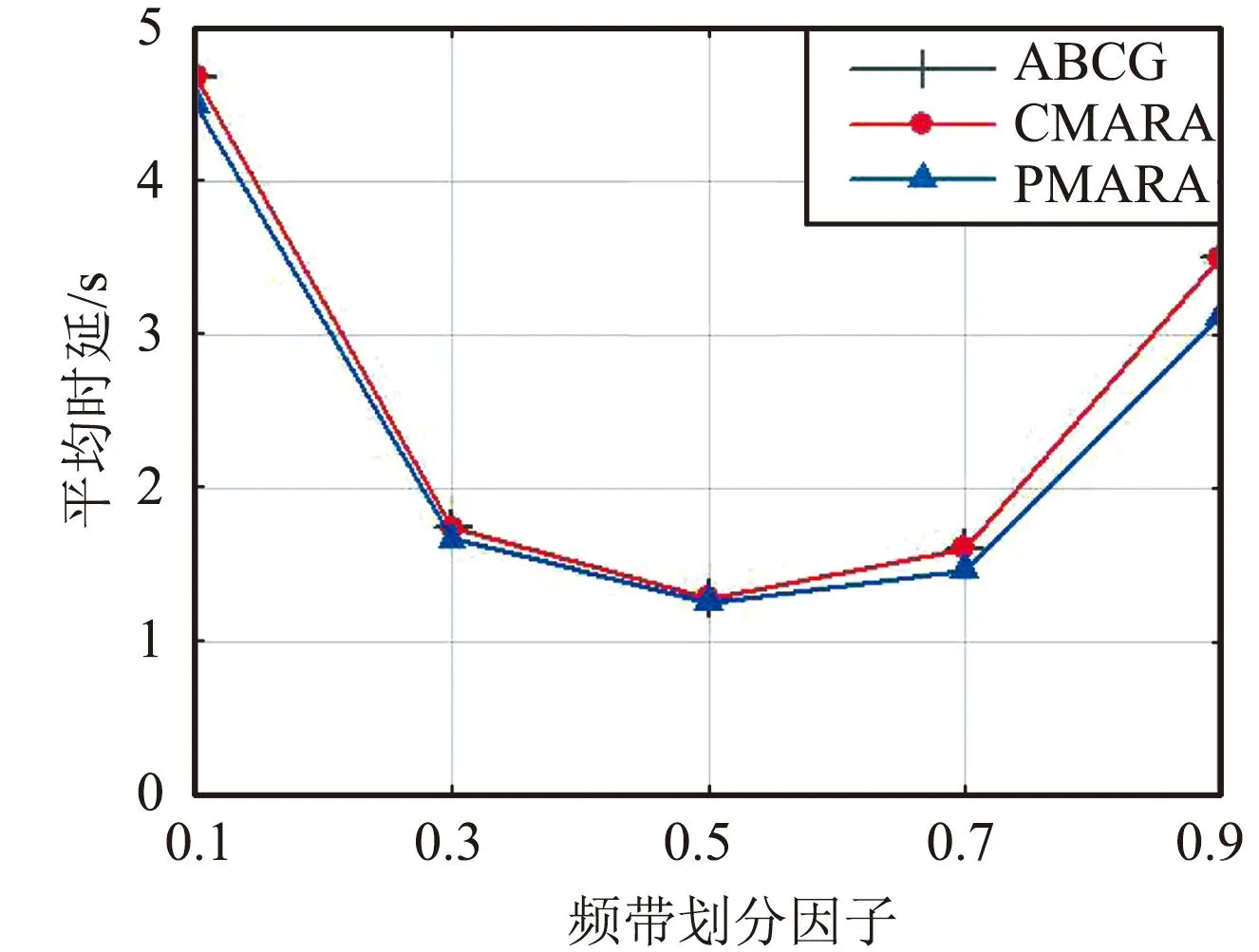
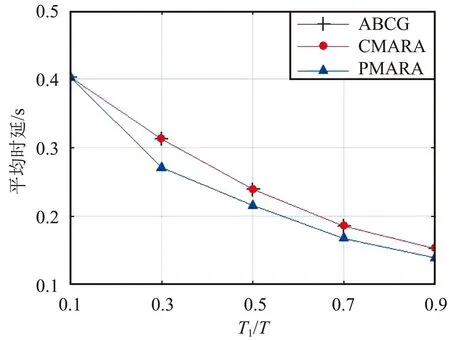
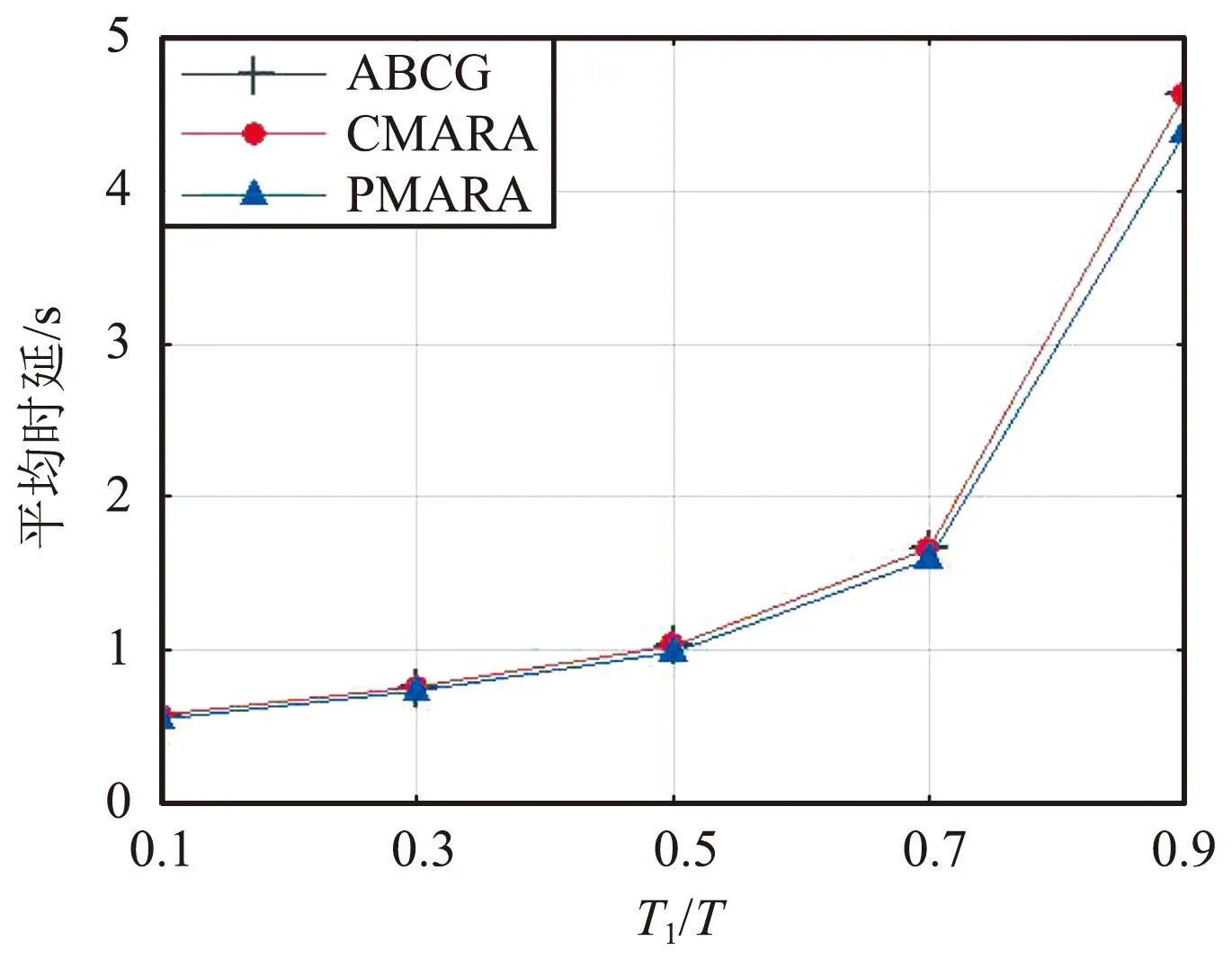
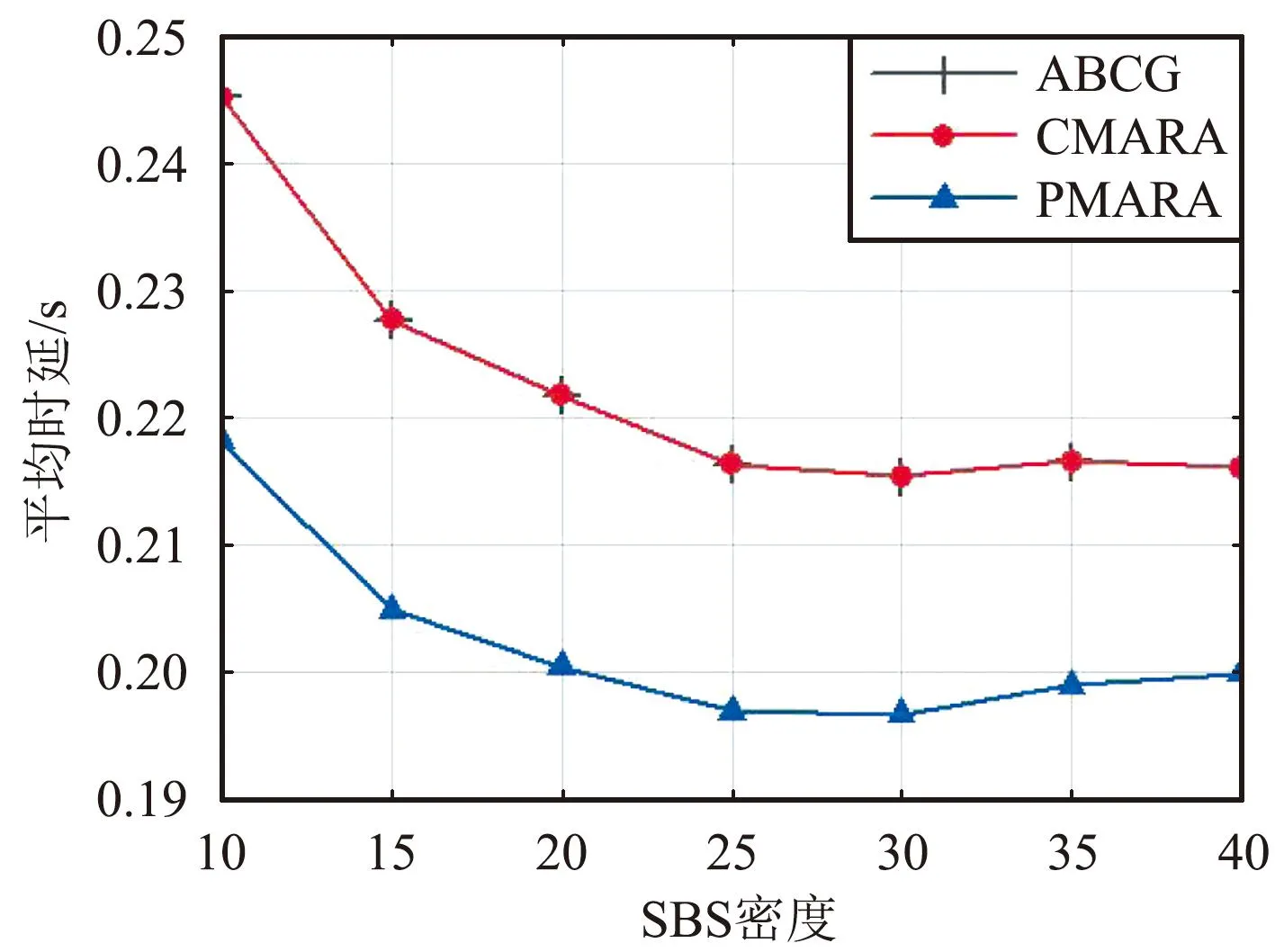
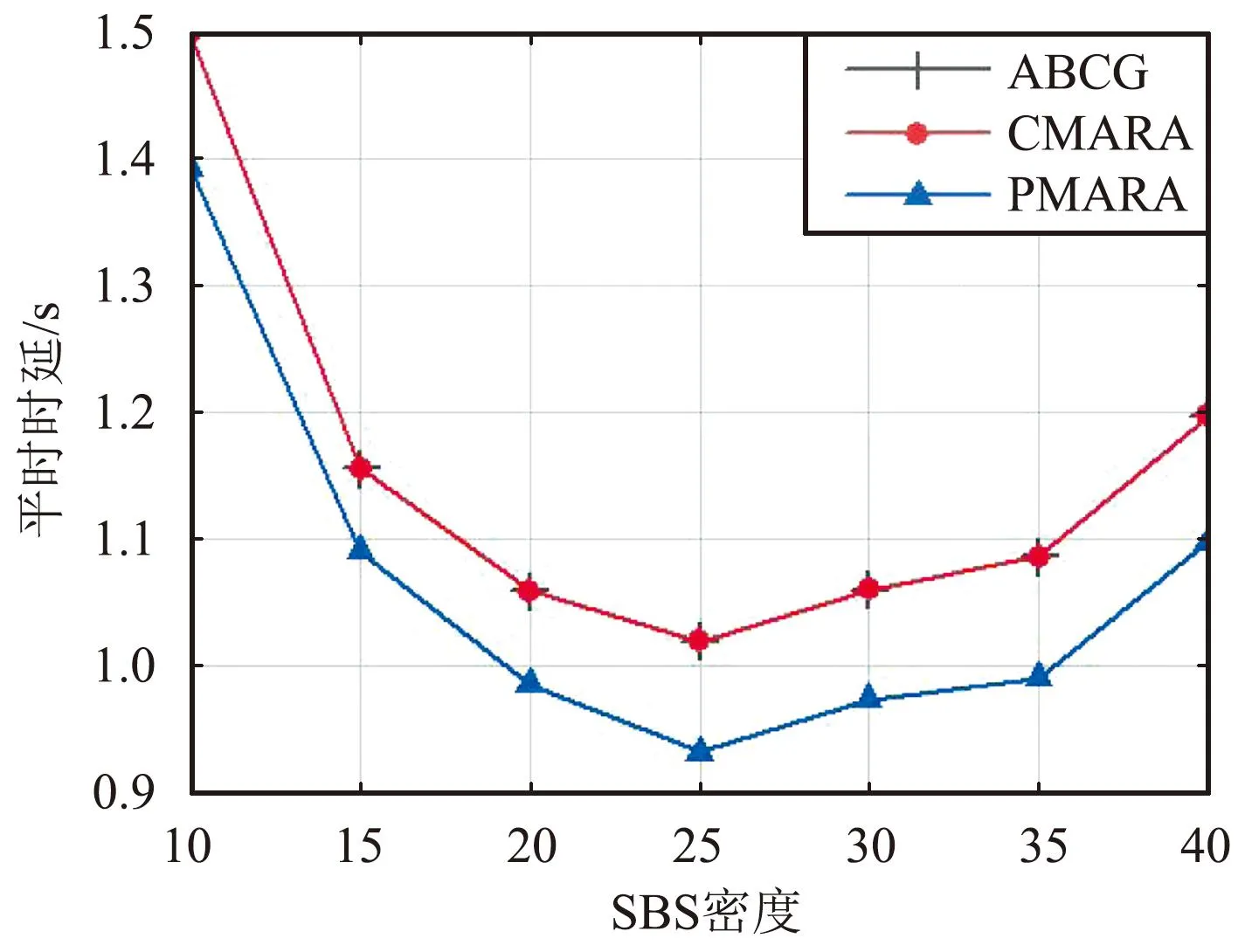
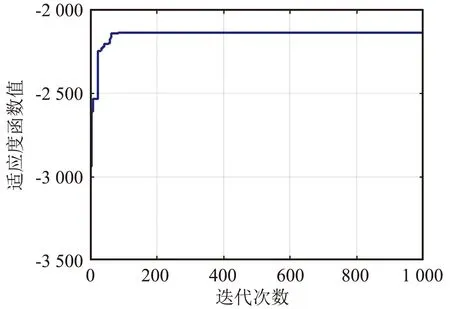
⑦ 更新迭代指示:t=t+1;如果t 在PMARA算法中,① 初始化粒子位置,分配計算資源并計算所有粒子的適應度值;② 初始化個體最佳粒子的位置,確立全局最佳粒子,并初始化這些粒子的速度;③ 更新普通粒子的速度與位置;④ 更新全局最佳粒子的速度與位置;⑤ 重新分配計算資源和計算所有粒子的適應度值;⑥ 更新個體最佳粒子與全局最佳粒子;⑦ 判斷PSO算法是否繼續迭代,若否則輸出全局最佳粒子的位置,最后通過粒子編碼規則將其映射為式(21)的解。顯然,PMARA算法通過迭代更新粒子的位置從而找到優化 式(21)的解。 表1 仿真參數 仿真結果表明,PMARA算法可能獲得較CMARA算法更低的時延,CMARA算法達到了與ABCG算法幾乎相同的性能。不難發現,ABCG算法用于初始化PMARA和CMARA算法。在相同初始條件下,CMARA算法因不能嚴格滿足資源與速率約束而無法迭代更新其性能,因此達到了同ABCG算法幾乎相同的性能;但是,PMARA算法因將這些約束作為懲罰項添加至適應度函數,不需要嚴格滿足這些約束而能迭代更新其性能,因此達到了較ABCG算法更好的性能。 圖1顯示了頻帶劃分因子η對2類MT平均時延的影響,其中圖1(a)和1(b)分別顯示了η對CST平均時延和HRT平均時延的影響。因為η的增加導致上行數據速率的增加,所以圖1(a)中CST的平均時延隨著η的增加而下降。同樣,圖1(b)中HRT的平均時延也隨著η的增加而先下降。但是,在高η域,HRT的平均時延卻隨著η的增加而增加。其原因在于,隨著η的增加,越來越多的MT關聯到SBS以獲取文件。當MT增加到一定程度時,許多MT因資源不足而不得不通過回程鏈路從核心網獲取文件。這意味著,增加的η會導致回程時延增加。 (a)CST的平均時延 (b)HRT的平均時延 圖2顯示了占比T1/T對2類MT平均時延的影響,其中圖2(a)和圖2(b)分別顯示了T1/T對CST平均時延和HRT平均時延的影響。因為T1/T的增加導致上行數據速率的增加,所以圖2(a)中CST的平均時延隨著T1/T的增加而下降。因為T1/T的增加導致下行數據速率與下行回程數據速率的下降,所以 圖2(b)中HRT的平均時延隨著T1/T的增加而增加。 (a)CST的平均時延 (b)HRT的平均時延 圖3顯示了SBS密度ρ(宏小區內MT的個數)對2類MT平均時延的影響,圖3(a)和圖3(b)分別顯示了ρ對CST平均時延和HRT平均時延的影響。因為ρ的增加導致MT越發接近服務基站,其上行數據速率隨之增加,所以圖3(a)中CST的平均時延均隨著ρ的增加而下降。但是,因為ρ的增加導致MT越發接近服務基站,其下行數據速率隨之增加,所以圖3(b)中HRT的平均時延初始隨著ρ的增加而增加。但是,當SBS密度增加到一定程度時,用戶接收的下行干擾帶來的損耗將超過拉進服務距離帶來的增益,因此圖3(b)中HRT的平均時延后期隨著ρ的增加而增加。 (a)CST的平均時延 (b)HRT的平均時延 圖4顯示了PMARA算法的收斂情況。可以看出,PMARA算法具有較快的收斂速度,能在有限迭代次數內找到優化問題的解。 圖4 PMARA算法的收斂情況Fig.4 Convergence of PMARA algorithm 為滿足CS和HR服務需求,針對具備邊緣計算與緩存功能、支持無線回程的多蜂窩MEC網絡,本文首先按需求比例分配頻譜、計算與緩存資源,然后開發出PMARA算法以最小化所有MT的時延之和。總體上,PMARA算法可獲得較其他現有算法更低的MT(包括CST和HRT)時延。這意味著, PMARA算法能更好地滿足2類MT分別對CS和HR服務的通信需求。在未來工作中,可融入非正交多址接入以提升網絡資源利用率,并考慮上行功率控制以降低網絡能耗與干擾。4 仿真分析
5 結束語
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
