基于深度學(xué)習(xí)的網(wǎng)絡(luò)安全命名實(shí)體識(shí)別方法
2024-03-05 07:35:22李大嶺張浩軍王家慧李世龍
無(wú)線電工程 2024年3期
李大嶺,張浩軍,王家慧,李世龍
(1.河南工業(yè)大學(xué) 信息科學(xué)與工程學(xué)院,河南 鄭州450001;2.河南省糧食信息處理國(guó)際聯(lián)合實(shí)驗(yàn)室,河南 鄭州450001)
0 引言
隨著大數(shù)據(jù)時(shí)代的到來(lái),網(wǎng)絡(luò)入侵、病毒感染等網(wǎng)絡(luò)攻擊事件越來(lái)越頻繁,網(wǎng)絡(luò)攻擊嚴(yán)重影響了計(jì)算機(jī)使用的安全性。沒(méi)有網(wǎng)絡(luò)安全就沒(méi)有國(guó)家安全,為了保證網(wǎng)絡(luò)空間安全,國(guó)家通過(guò)各種技術(shù)實(shí)時(shí)監(jiān)測(cè)網(wǎng)絡(luò),產(chǎn)生了大量的網(wǎng)絡(luò)安全數(shù)據(jù)。同時(shí)網(wǎng)絡(luò)空間還存在大量的安全信息、漏洞信息等。
為有效地從海量的網(wǎng)絡(luò)安全信息中抽取實(shí)體,本文提出一種融合漢字多源信息的中文命名實(shí)體識(shí)別(Named Entity Recognition,NER)方法。在Embedding層使用BERT模型融合漢字偏旁部首信息和字符頻率信息獲取字向量,并使用改進(jìn)的Para-Lattice模型對(duì)字向量和詞向量進(jìn)行融合,使得字向量能更準(zhǔn)確表達(dá)字符的信息,進(jìn)而提升模型的性能。
1 相關(guān)工作
命名實(shí)體識(shí)別任務(wù)的目的是識(shí)別出人類自然語(yǔ)言中專有名詞的實(shí)體[1]。基于深度學(xué)習(xí)的NER任務(wù)可以轉(zhuǎn)換為序列標(biāo)注任務(wù)[2],將大量帶有標(biāo)簽標(biāo)注的數(shù)據(jù)樣本輸入到模型進(jìn)行訓(xùn)練,最后由模型進(jìn)行預(yù)測(cè)。統(tǒng)計(jì)機(jī)器學(xué)習(xí)算法在NER中得到廣泛應(yīng)用,隱馬爾可夫模型(Hidden Markov Model,HMM)[3]、支持向量機(jī)(Support Vector Machine,SVM)[4]和條件隨機(jī)場(chǎng)(Conditional Random Fields,CRF)[5]等機(jī)器學(xué)習(xí)算法被廣泛疊加到深度學(xué)習(xí)模型中,其中CRF因?yàn)槟芨玫孬@取標(biāo)簽之間的狀態(tài)轉(zhuǎn)移信息,從而被廣泛應(yīng)用到NER任務(wù)中。
隨著人工智能的發(fā)展,神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)逐漸應(yīng)用到各個(gè)領(lǐng)域,基于深度學(xué)習(xí)的NER模型在領(lǐng)域內(nèi)逐漸占據(jù)主導(dǎo)地位。Wu等[6]開發(fā)了一個(gè)深度神經(jīng)網(wǎng)絡(luò),通過(guò)無(wú)監(jiān)督學(xué)習(xí)從大型無(wú)標(biāo)記語(yǔ)料庫(kù)生成詞嵌入,使用最小特征工程方法識(shí)別中國(guó)臨床文檔中的臨床實(shí)體。Zhang等[7]首次提出基于字符和詞典的Lattice-LSTM模型,模型會(huì)編碼輸入字符以及語(yǔ)詞典匹配的所有潛在詞語(yǔ),得益于豐富的詞匯,模型在數(shù)據(jù)集上取得了很好的表現(xiàn)。Li等[8]提出FLAT模型,將晶格結(jié)構(gòu)轉(zhuǎn)化為扁平結(jié)構(gòu),模型可以通過(guò)位置編碼來(lái)捕獲詞信息,有良好的并行計(jì)算能力。Ma等[9]把詞典信息編碼到字符表示層,并設(shè)計(jì)了一個(gè)編碼規(guī)則來(lái)盡可能地保留詞典的匹配結(jié)果,模型效率提升,同時(shí)提升了性能。楊飄等[10]通過(guò)BERT預(yù)訓(xùn)練模型獲取字向量,將字向量序列輸入到BiGRU-CRF模型中,在MSRA數(shù)據(jù)集上實(shí)驗(yàn)結(jié)果表明模型的性能得到提升。
此外,針對(duì)網(wǎng)絡(luò)安全領(lǐng)域NER研究工作。Joshi等[11]基于CRF算法構(gòu)建了一個(gè)用于識(shí)別文本中與網(wǎng)絡(luò)安全相關(guān)的實(shí)體、概念和關(guān)系的模型。Lal等[12]提出了一種基于SVM算法的從非結(jié)構(gòu)化文本中提取網(wǎng)絡(luò)安全相關(guān)術(shù)語(yǔ)的信息識(shí)別方法。Mulwad等[13]設(shè)計(jì)了一種基于SVM算法的識(shí)別系統(tǒng),提取用來(lái)描述漏洞和攻擊的概念實(shí)體。秦婭等[14]結(jié)合特征模板提出一種CNN-BiLSTM-CRF的網(wǎng)絡(luò)安全實(shí)體識(shí)別方法,在大規(guī)模網(wǎng)絡(luò)安全數(shù)據(jù)集上表現(xiàn)良好。楊秀璋等[15]針對(duì)高級(jí)可持續(xù)威脅(Advanced Persistent Threat, APT)分析報(bào)告,提出一種BERT-BiLSTM-CRF的APT攻擊實(shí)體識(shí)別模型,在數(shù)據(jù)集上取得了很好的表現(xiàn)。
針對(duì)中文網(wǎng)絡(luò)安全領(lǐng)域的NER任務(wù),提出改進(jìn)的一種融合字向量和詞向量的深度學(xué)習(xí)模型。考慮到中文預(yù)訓(xùn)練模型BERT僅提取漢字的信息,并沒(méi)有涉及到漢字的偏旁部首,因此提取字向量時(shí)將漢字偏旁部首信息和字符頻率信息與BERT字向量進(jìn)行融合,進(jìn)而提升模型性能。
2 模型與方法
本文模型如圖1所示,整個(gè)模型分為3層,Embedding層將BERT字向量、融合字頻信息的F-FI向量和偏旁部首信息向量進(jìn)行拼接,Para-Lattice層充分獲取詞匯信息,CRF層通過(guò)學(xué)習(xí)標(biāo)簽間的狀態(tài)轉(zhuǎn)移信息構(gòu)建狀態(tài)轉(zhuǎn)移矩陣進(jìn)行預(yù)測(cè)。
2.1 詞嵌入層
Embedding層任務(wù)是將輸入到模型中的字序列映射成低維度的稠密向量輸入到Para-Lattice層中。本文的Embedding層分為BERT模塊、F-FI模塊和PianPang模塊三部分。其中BERT模塊利用預(yù)訓(xùn)練的BERT模型將輸入序列轉(zhuǎn)換為實(shí)向量。圖2為BERT模型的輸入表示。
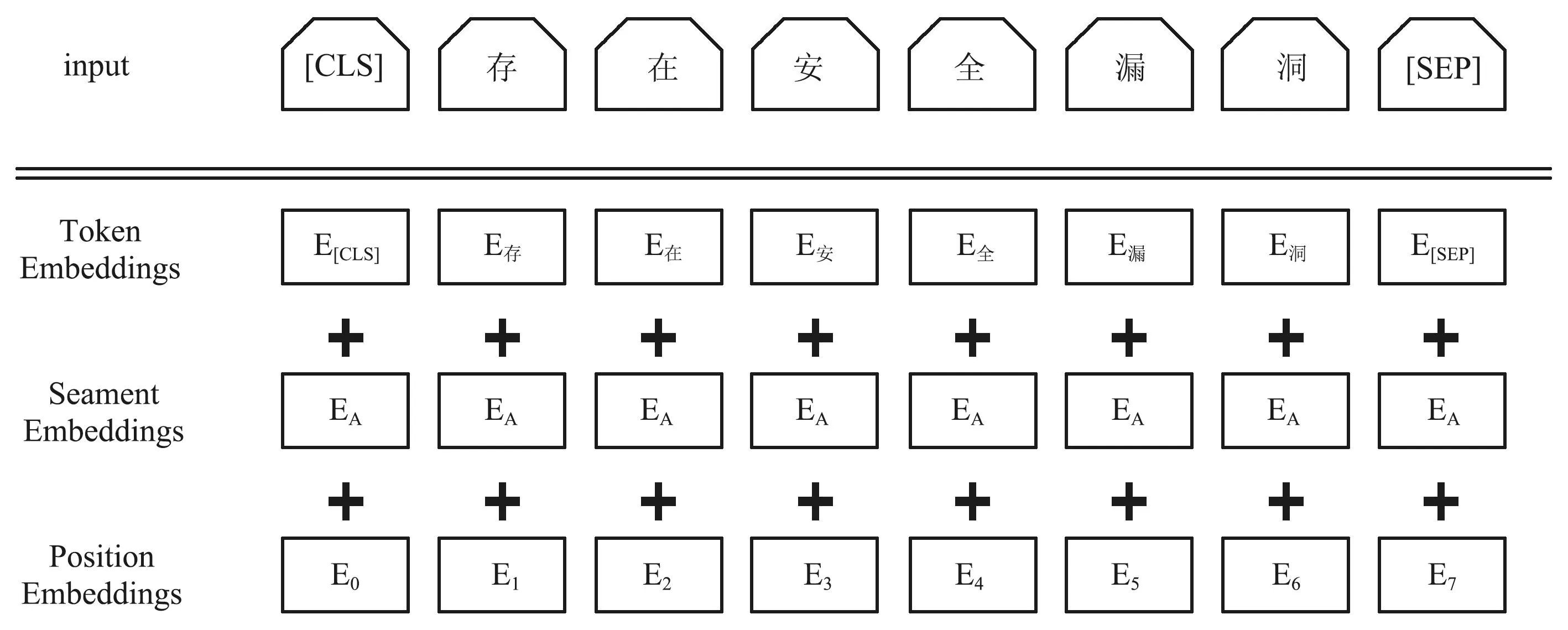
圖2 BERT輸入表示Fig.2 BERT input representation
本文以單個(gè)字符為輸入單位,所以BERT模型的輸出為字向量,為了使得試驗(yàn)最終結(jié)果相對(duì)較好且能降低字向量的維度,本文使用BERT模型最后一層隱含層獲取字向量,對(duì)于給定的輸入序列L={a1,a2,a3,…,an},利用BERT模型對(duì)序列中每個(gè)字符ai輸出它的BERT字向量Bai,即:
Bai=BERT(h(-1)),
(1)
式中:h(-1)表示隱含層最后一層,最終Bai的維度為768維。
F-FI模塊首先將訓(xùn)練集驗(yàn)證集和測(cè)試集作為統(tǒng)計(jì)數(shù)據(jù)集,計(jì)算每一個(gè)字符的F-FI值。其中F是字符字頻,FI是字符頻率指數(shù)。
(2)
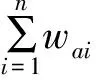
(3)
式中:N表示數(shù)據(jù)集中實(shí)例(Instance)總數(shù),nai表示含有字符ai的Instance總數(shù),加1是為了避免分母為0。
F-FIai=Fai*FIai,
(4)
式中:F-FI值為字符ai的F值乘以字符ai的FI值。F值可以很好地體現(xiàn)字符關(guān)鍵性,但數(shù)據(jù)集中常見字如:“的”的F值同樣會(huì)大,所以用FI值弱化常見字的關(guān)鍵性。利用計(jì)算得出的F-FI值對(duì)100維的word2vec靜態(tài)字向量進(jìn)行加權(quán),得到字頻向量Tai。具體求解如算法1所示。

算法1:F-FI求解算法Input: L ∥文本序列Output: word_f_fi ∥字符F-FI值begin1 defaultdict(int) doc_fre2 for word_list L do3 for i word_list do4 doc_fre [i] ←doc_fre [i]+15 declare a dictionary word_f6 for i doc_fre do7 word_f[i] ←doc_fre[i] / sum(doc_fre.values)8 declare a dictionary word_fi9 doc_num ← len(list_words)10 defaultdict(int) word_doc11 foridoc_fre do12 forjIdo13 word_doc[i] ←word_doc[i] + 114 foridoc_fre do15 word_fi← math.log(doc_num / (word_doc(i) + 1)) 16 declare a dictionaryword_f_fi17 fori doc_fredo18 word_f_if[i] ← word_f[i]?word_fi[i]19 return word_f_fiend
PianPang模塊中使用新華字典作為本地字典,以百度漢語(yǔ)作為網(wǎng)絡(luò)字典,以訓(xùn)練集驗(yàn)證集和測(cè)試集作為統(tǒng)計(jì)數(shù)據(jù)集,提取所有的字符匯集為一個(gè)字符集。針對(duì)字符集中每一個(gè)字符若本地字典中存在,則直接查詢其偏旁部首并返回結(jié)果,否則到網(wǎng)絡(luò)字典中查詢并返回結(jié)果。將偏旁部首通過(guò)Embedding的方式得到一個(gè)130維PianPang靜態(tài)向量表。對(duì)于給定的輸入序列L={a1,a2,a3,…,an},利用PianPang模塊對(duì)序列中每個(gè)字符ai輸出它的PianPang向量Pai,即:
Pai=PianPang(ai)。
(5)
把字頻向量Tai、BERT字向量Bai和PianPang向量Pai進(jìn)行拼接得到字符ai的最終向量表示Eai。最終向量Eai的維度998維,即:
Eai=Bai⊕Tai⊕Pai。
(6)
2.2 編碼層
循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)因?yàn)槟軌蚩紤]到上下文內(nèi)容而被廣泛應(yīng)用于自然語(yǔ)言處理(Natural Language Processing,NLP)方向,但是會(huì)存在梯度消失和梯度爆炸問(wèn)題,不能完美地處理具備長(zhǎng)期依賴的信息。長(zhǎng)短期記憶網(wǎng)絡(luò)(Long Short-Term Memory,LSTM)通過(guò)引入門機(jī)制控制神經(jīng)單元之間信息的傳遞,緩解梯度消失和爆炸的問(wèn)題。由于中文NER的特殊性,改進(jìn)了一種可以進(jìn)行batch并行化計(jì)算的Para-Lattice模型,模型通過(guò)word-cell對(duì)詞匯信息進(jìn)行編碼,并將其融合到char-cell的字符編碼中,使得模型可以充分地利用漢字和詞匯的信息,原模型Lattice由于在進(jìn)行詞匯融合時(shí)不能提前預(yù)知需要融入的詞匯數(shù)量,導(dǎo)致Lattice一次只能處理一條數(shù)據(jù),進(jìn)而導(dǎo)致模型的運(yùn)算速度很慢,且更新的梯度受極端值影響較大,模型損失劇烈震蕩。本文改進(jìn)了一種可以進(jìn)行并行化計(jì)算的Para-Lattice模型,在模型進(jìn)行詞匯信息融合之前,將詞匯數(shù)量提前計(jì)算構(gòu)建一個(gè)詞匯數(shù)量的列表并一同輸入到模型中,字詞融合時(shí)將一同計(jì)算的所有輸入序列的詞匯最大值定為基準(zhǔn),對(duì)其余進(jìn)行補(bǔ)零操作,進(jìn)而可以實(shí)現(xiàn)并行化計(jì)算的Para-Lattice模型。
Para-lattice對(duì)詞匯的算法為:
(7)

(8)
式中:w表示關(guān)于詞粒度的變量,c表示關(guān)于字粒度的變量
Para-Lattice通過(guò)增加一個(gè)額外的門來(lái)控制字粒度和詞粒度的選取,計(jì)算如下:
(9)
Para-Lattice對(duì)字符的算法如下:
(10)
(11)
式中:
(12)
(13)
通過(guò)式(14)得到
(14)

圖3 Lattice-LSTM結(jié)構(gòu)Fig.3 Lattice-LSTM structure
2.3 解碼層
本文網(wǎng)絡(luò)模型中編碼層負(fù)責(zé)學(xué)習(xí)上下文信息,解碼層CRF負(fù)責(zé)構(gòu)建實(shí)體間狀態(tài)轉(zhuǎn)移矩陣。給定X,則Y的概率為P(Y|X),為計(jì)算P(Y|X),CRF作出以下2點(diǎn)假設(shè):
① 假設(shè)該分布屬于指數(shù)分布簇。即存在函數(shù)f(y|x)=f(y1,y2,…,yn|x),使得:
(15)
式中:z(x)為歸一化因子,f(y|x)為打分函數(shù)。
② 假設(shè)輸出之間的關(guān)聯(lián)僅僅發(fā)生在相鄰位置,并且這種關(guān)聯(lián)是指數(shù)相加的。
(16)
式中:s(yi|xi)表示狀態(tài)分?jǐn)?shù),t(yi,yi+1)表示轉(zhuǎn)移分?jǐn)?shù)。
對(duì)CRF采用對(duì)數(shù)極大似然方法計(jì)算損失函數(shù),即:
ln(p(y1,y2,…,yn|x))=
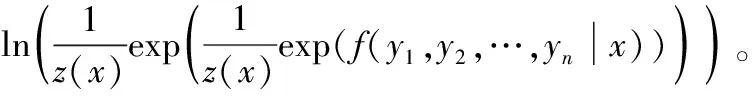
(17)
CRF損失函數(shù)的計(jì)算需要用到狀態(tài)分?jǐn)?shù)和轉(zhuǎn)移分?jǐn)?shù),其中狀態(tài)分?jǐn)?shù)是根據(jù)訓(xùn)練得到的BERT+Para-Lattice模型的輸出計(jì)算出來(lái)的,轉(zhuǎn)移分?jǐn)?shù)是從CRF層提供的轉(zhuǎn)移矩陣得到的,其解碼過(guò)程使用維特比算法得到最優(yōu)的標(biāo)簽序列。
3 實(shí)驗(yàn)與分析
3.1 數(shù)據(jù)集和評(píng)估指標(biāo)
本文收集國(guó)家信息安全漏洞庫(kù)的漏洞數(shù)據(jù)作為實(shí)驗(yàn)數(shù)據(jù)確保了實(shí)驗(yàn)數(shù)據(jù)的真實(shí)性。本次語(yǔ)料收集了近5年的漏洞數(shù)據(jù)這確保了實(shí)驗(yàn)數(shù)據(jù)的歷時(shí)性,爬取的內(nèi)容包含操作系統(tǒng)、應(yīng)用程序、數(shù)據(jù)庫(kù)、Web應(yīng)用和網(wǎng)絡(luò)設(shè)備等多個(gè)模塊的漏洞信息確保了語(yǔ)料庫(kù)文本數(shù)據(jù)的全面性,2014年12月—2019年9月共計(jì)5年的漏洞數(shù)據(jù),其中2014年18份、2015年242份、2016年328份、2017年489份、2018年422份、2019年313份,確保了語(yǔ)料庫(kù)的歷時(shí)性。按照不同的模塊進(jìn)行統(tǒng)計(jì),包含操作系統(tǒng)模塊210份、應(yīng)用程序模塊1 067份、數(shù)據(jù)庫(kù)模塊23份、Web應(yīng)用模塊334份、網(wǎng)絡(luò)設(shè)備模塊178份的漏洞信息,確保了語(yǔ)料庫(kù)文本數(shù)據(jù)的全面性。按照漏洞危害的程度分類統(tǒng)計(jì),有高級(jí)1 041份、中級(jí)636份、低級(jí)134份。圖4描述了網(wǎng)絡(luò)安全文本原始數(shù)據(jù)的分布情況。
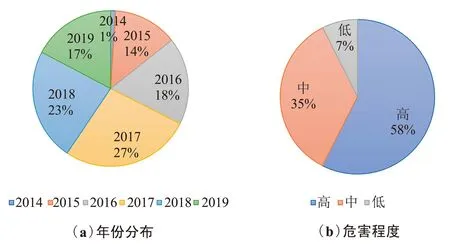
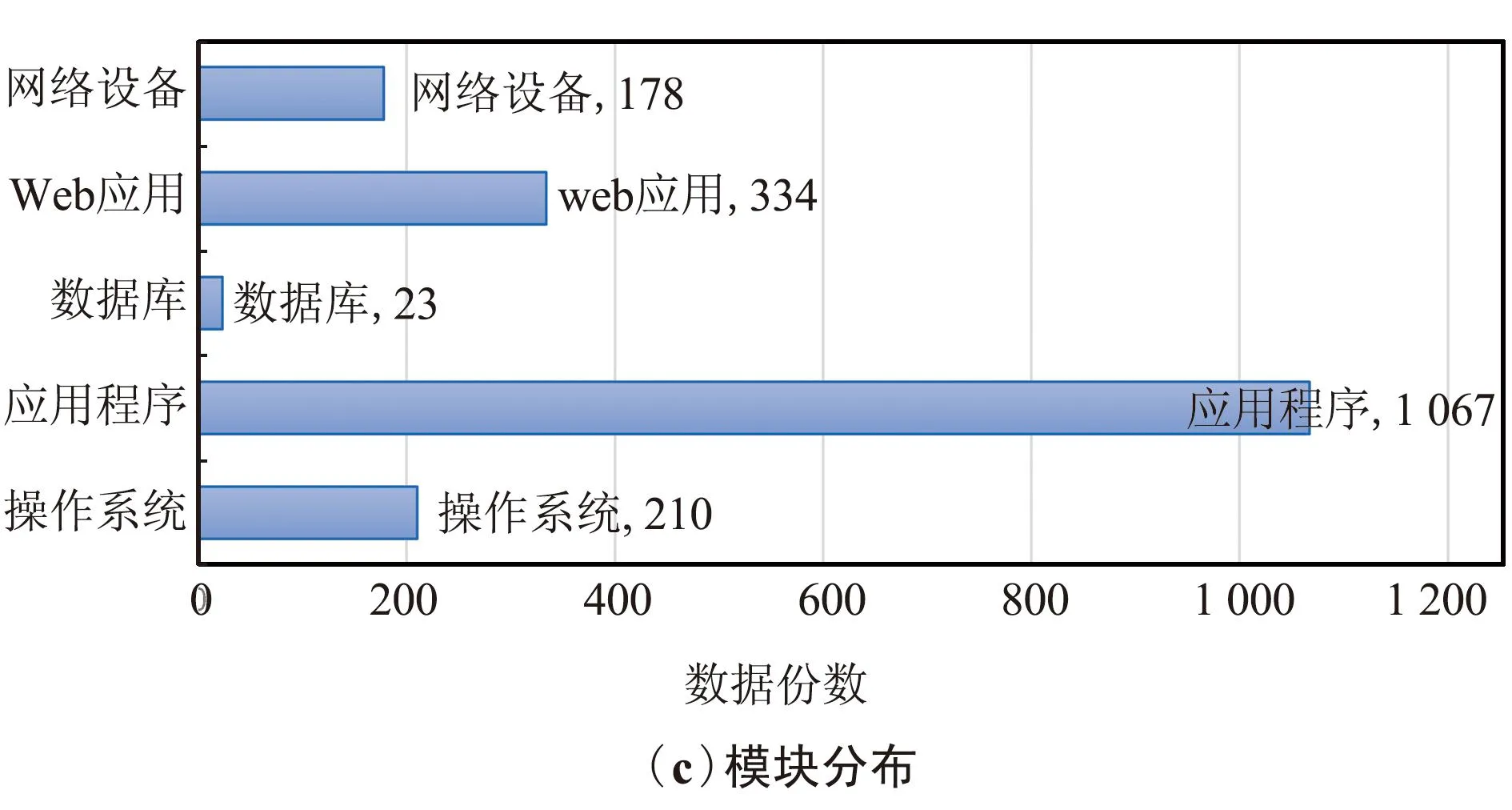
圖4 網(wǎng)絡(luò)安全數(shù)據(jù)分布情況統(tǒng)計(jì)Fig.4 Statistical chart of network security data distribution
參考了結(jié)構(gòu)化威脅信息表達(dá)對(duì)網(wǎng)絡(luò)攻擊模式12種構(gòu)件的定義,以及結(jié)合了丁兆云等[16]對(duì)網(wǎng)絡(luò)安全情報(bào)數(shù)據(jù)的分析,將語(yǔ)料庫(kù)中的實(shí)體定義為七大類,分別為漏洞編號(hào)實(shí)體(ID)、危害等級(jí)實(shí)體(CLA)、軟件名實(shí)體(SW)、組織名實(shí)體(ORG)、漏洞類型實(shí)體(TY)、地名實(shí)體(LOC)和相關(guān)術(shù)語(yǔ)實(shí)體(RT)。各實(shí)體定義如下。
① 漏洞編號(hào)實(shí)體:標(biāo)簽為ID,用來(lái)記錄漏洞在國(guó)家漏洞數(shù)據(jù)庫(kù)中的編號(hào),例如“CVE-2014-8016”。
② 危害等級(jí)實(shí)體:標(biāo)簽為CLA,用來(lái)描述該漏洞的危害等級(jí),例如“高”“中”“低”等。
③ 軟件名實(shí)體:標(biāo)簽為SW,用來(lái)描述漏洞所存在的軟件名字,例如“Cisco Meraki MS MRMX”和“Huawei USG9560”。
④ 組織名實(shí)體:標(biāo)簽為ORG,用來(lái)描述存在漏洞的軟件所屬于的組織或公司名稱,例如“華為”“思科”“谷歌”等。
⑤ 漏洞類型實(shí)體:標(biāo)簽為TY,用來(lái)描述漏洞危害的類型,如“拒絕服務(wù)漏洞”“SQL注入漏洞”“信息泄露漏洞”等。
⑥ 地名實(shí)體:標(biāo)簽為L(zhǎng)OC,用來(lái)描述存在漏洞的軟件的組織或公司所屬于的地名,如“瑞士”“美國(guó)”“英國(guó)”等。
⑦ 相關(guān)術(shù)語(yǔ)實(shí)體:標(biāo)簽為RT,用來(lái)描述網(wǎng)絡(luò)安全漏洞相關(guān)的術(shù)語(yǔ),例如“拒絕服務(wù)”“HTTP會(huì)話”“蠻力攻擊”等。
本文數(shù)據(jù)集采用BIO標(biāo)注策略,B表示實(shí)體開始的位置,I表示實(shí)體的非開始位置,O表示非實(shí)體字符。本文數(shù)據(jù)集中共計(jì)包含15種實(shí)體標(biāo)簽,標(biāo)簽統(tǒng)計(jì)情況如表1所示。
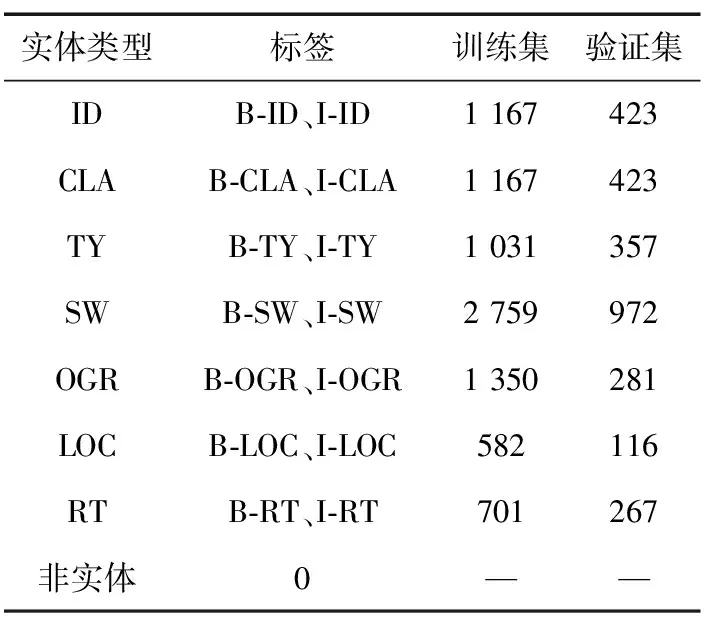
表1 網(wǎng)絡(luò)安全實(shí)體數(shù)據(jù)統(tǒng)計(jì)
標(biāo)注規(guī)則在遵循“不重疊標(biāo)注、不嵌套標(biāo)注、不包含標(biāo)點(diǎn)符號(hào)”的基本標(biāo)注原則的基礎(chǔ)上,制定適合網(wǎng)絡(luò)安全領(lǐng)域的標(biāo)注規(guī)則。
① 最大范圍標(biāo)注
例1:Microsoft XML Core Services MSXML中存在遠(yuǎn)程代碼執(zhí)行漏洞,攻擊者可借助特制的網(wǎng)站利用該漏洞運(yùn)行惡意代碼,進(jìn)而控制用戶系統(tǒng)。
例1中Microsoft為后面軟件的公司名,遵循最大范圍標(biāo)注原則,將Microsoft和XML Core Services MSXML一起標(biāo)注為軟件名實(shí)體。
② 去特殊符號(hào)標(biāo)注
例2:Cisco IOS XE是美國(guó)思科(Cisco)公司的一套為其網(wǎng)絡(luò)設(shè)備開發(fā)的操作系統(tǒng),Cisco IOS XE中的Web UI存在跨站請(qǐng)求偽造漏洞。
例2中Cisco為思科的英文名,遵循去特殊符號(hào)標(biāo)注原則,將思科和Cisco分別標(biāo)注為組織名實(shí)體。
圖5為網(wǎng)絡(luò)安全命名實(shí)體標(biāo)注實(shí)例。

圖5 網(wǎng)絡(luò)安全命名實(shí)體標(biāo)注實(shí)例Fig.5 An instance of a network security named entity annotation
表2將網(wǎng)絡(luò)安全領(lǐng)域數(shù)據(jù)集與微博NER數(shù)據(jù)集Weibo-NER、微軟亞洲研究院數(shù)據(jù)集MSRA、中國(guó)股市高管簡(jiǎn)歷數(shù)據(jù)集Resume以及人民日?qǐng)?bào)數(shù)據(jù)集PeopleDairy四種公開的常見的中文NER數(shù)據(jù)集進(jìn)行了對(duì)比。通過(guò)對(duì)比可以發(fā)現(xiàn),本文所構(gòu)建的網(wǎng)絡(luò)安全領(lǐng)域數(shù)據(jù)集相對(duì)于常見的中文語(yǔ)料庫(kù)實(shí)體的類別比較豐富,其中MSRA數(shù)據(jù)集和PeopleDairy數(shù)據(jù)集包含的實(shí)體類型最少,均包含3類實(shí)體;本文數(shù)據(jù)集NSD-NER和Weibo數(shù)據(jù)集均包含7類實(shí)體,僅次于Resume數(shù)據(jù)集中的8類實(shí)體;MSRA數(shù)據(jù)集和PeopleDairy數(shù)據(jù)集數(shù)據(jù)體量比較大,分別為14 k和9.2 k,相對(duì)來(lái)說(shuō)本文所構(gòu)建的網(wǎng)絡(luò)安全領(lǐng)域數(shù)據(jù)集NSD-NER數(shù)據(jù)體量比較小,數(shù)據(jù)大小為2.2 k,但其數(shù)據(jù)體量也大于Weibo數(shù)據(jù)集的0.8 k以及Resume數(shù)據(jù)集的1.4 k。5種數(shù)據(jù)集對(duì)比,本文數(shù)據(jù)集體量處于中游水平。
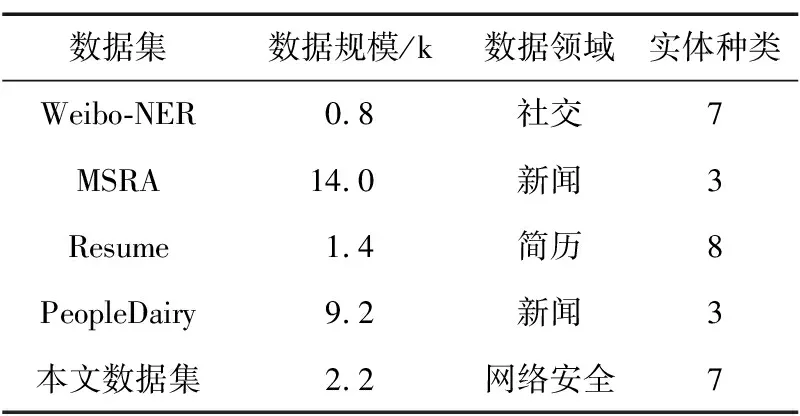
表2 不同語(yǔ)料庫(kù)對(duì)比分析
本文采用精確率(P)、召回率(R)、F1值和ACC值作為實(shí)驗(yàn)的評(píng)估指標(biāo)。其中P表示所有被預(yù)測(cè)為正的樣本中實(shí)際為正的樣本的概率,R表示實(shí)際為正的樣本中被預(yù)測(cè)為正樣本的概率,F1值是綜合P值和R值的一個(gè)F1分?jǐn)?shù),ACC值表示模型的準(zhǔn)確率。計(jì)算如下:
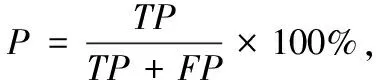
(18)
(19)
(20)
(21)
式中:TP表示正樣本被判斷為正樣本的數(shù)量,FP表示負(fù)樣本被判斷為正樣本的數(shù)量,TN表示負(fù)樣本被判斷為負(fù)樣本的數(shù)量,FN表示正樣本被判斷為負(fù)樣本的數(shù)量。
3.2 參數(shù)設(shè)置
本實(shí)驗(yàn)優(yōu)化器采用Adam[17],該優(yōu)化器集合了適應(yīng)性梯度算法和均方根傳播2種隨機(jī)梯度下降擴(kuò)展式的優(yōu)點(diǎn),可以高效地進(jìn)行計(jì)算并且所需的內(nèi)存比較少,模型使用Dropout[18]緩解過(guò)擬合的發(fā)生,在一定程度上達(dá)到正則化的效果。實(shí)驗(yàn)?zāi)P蛥?shù)設(shè)置如表3所示。

表3 參數(shù)設(shè)置
3.3 實(shí)驗(yàn)結(jié)果分析
為了確定加入偏旁的有效性以及偏旁維度對(duì)模型最終結(jié)果的影響,使用融合漢字多源信息實(shí)體識(shí)別模型(Named Entity Recognition Model Based on Multi-Source Information of Chinese Characters,Msicc-NER)在Weibo數(shù)據(jù)集上做了各維度偏旁向量對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如圖6所示。

圖6 偏旁維度對(duì)F1值影響Fig.6 Influence of radical dimension on F1 value
由圖6可以看出,隨著PiangPang向量維度的升高,F1增長(zhǎng)值呈現(xiàn)上升趨勢(shì)最后趨于平緩,綜合考慮模型運(yùn)行時(shí)間與F1值,實(shí)驗(yàn)最終選擇最優(yōu)的130維的PianPang向量與字向量進(jìn)行融合。使用F-FI對(duì)100維的word2vec向量進(jìn)行加權(quán)得到F-FI向量與字向量進(jìn)行融合。
為了驗(yàn)證本文模型Msicc-NER的有效性和普適性,將模型與常見模型在Weibo和MSRA公開數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)對(duì)比。Weibo和MSRA數(shù)據(jù)集數(shù)據(jù)統(tǒng)計(jì)結(jié)果表4所示。
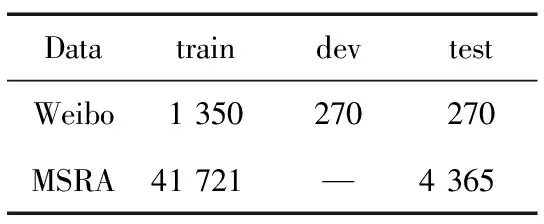
表4 公開數(shù)據(jù)集數(shù)據(jù)統(tǒng)計(jì)
圖7和圖8為各模型在公開數(shù)據(jù)集Weibo和MSRA數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果對(duì)比,通過(guò)對(duì)比結(jié)果可以看出,相對(duì)于Lattice+CRF、BiLSTM+CRF、BERT+BiLSTM+CRF等模型,本文模型Msicc-NER在公開數(shù)據(jù)集上有良好的表現(xiàn),具有普適性,更進(jìn)一步說(shuō)明了融合偏旁信息和F-FI信息的有效性。
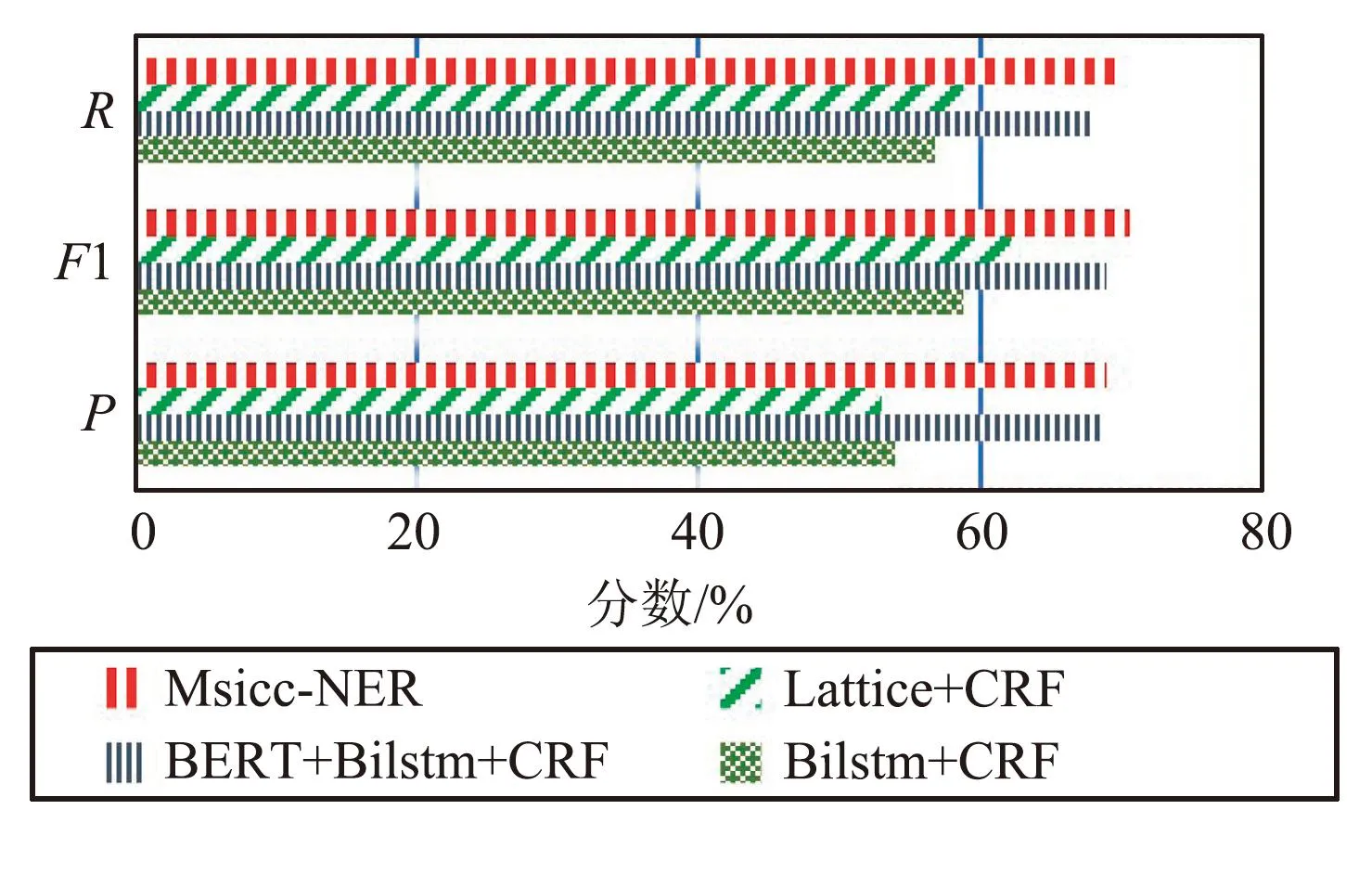
圖7 不同模型在Weibo數(shù)據(jù)集識(shí)別結(jié)果Fig.7 Recognition results of different models in the Weibo dataset
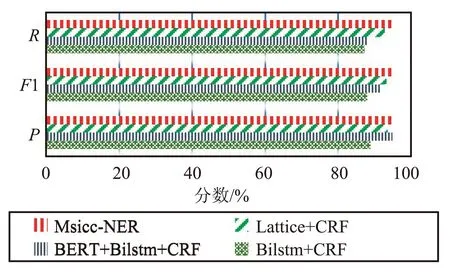
圖8 不同模型在MSRA數(shù)據(jù)集識(shí)別結(jié)果Fig.8 Recognition results of different models in MSRA dataset
使用本文模型Msicc-NER與BERT+LSTM+CRF、BERT+BiLSTM+CRF、FLAT、PLTE[19]等模型在構(gòu)建的網(wǎng)絡(luò)安全領(lǐng)域數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)對(duì)比,識(shí)別結(jié)果如表5所示。

表5 不同模型在網(wǎng)絡(luò)安全數(shù)據(jù)集上識(shí)別結(jié)果
由表5可以看出,本文模型在網(wǎng)絡(luò)安全領(lǐng)域?qū)嶓w識(shí)別任務(wù)中取得了較好的效果,精確率、召回率和F1值為0.864 9、0.840 2和0.852 3,相較其余4種模型都有一定程度的提高。Msicc-NER相比LSTM模型的F1值提升8.98%,比BiLSTM模型F1值提升4.91%,比FLAT提升2.32%,比BERT+FLAT提升了1.68%,比BERT+PLTE提升了1.88%。其中,FLAT相較于LSTM與BiLSTM模型性能提升的主要原因在于模型中引入了詞匯以及詞匯位置信息,而BERT+FLAT相較于FLAT模型性能提升的主要原因是加入了BERT預(yù)訓(xùn)練模型的字向量信息。同時(shí),本文模型的F1值是5種模型中最高的,主要原因在于本文模型同時(shí)將漢字偏旁信息和字頻信息等先驗(yàn)知識(shí)融合進(jìn)BERT字向量,又將字向量和詞向量進(jìn)行輸入,實(shí)現(xiàn)了字、詞融合進(jìn)而提高了模型的性能。
為更形象地表示模型的性能,在網(wǎng)絡(luò)安全數(shù)據(jù)集進(jìn)一步進(jìn)行模型實(shí)驗(yàn)對(duì)比,得出如表6所示的準(zhǔn)確率。通過(guò)表6可以看出,與其他模型相比較,本文模型Miscc-NER取得最高的準(zhǔn)確率96.54%,進(jìn)一步體現(xiàn)了本文模型的有效性。
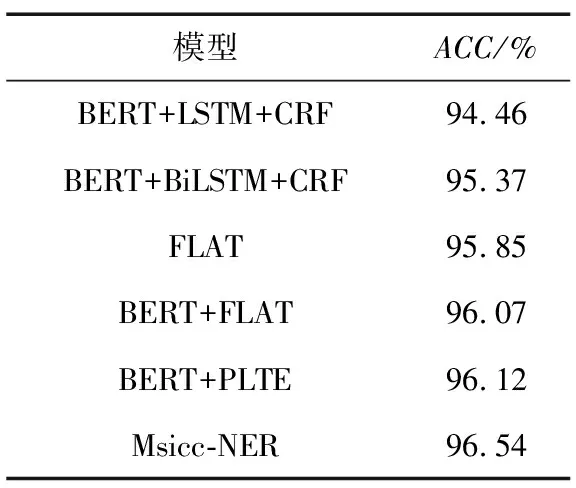
表6 不同模型在網(wǎng)絡(luò)安全數(shù)據(jù)集上ACC值對(duì)比
圖9為本文模型Msicc-NER在網(wǎng)絡(luò)安全領(lǐng)域數(shù)據(jù)集上ACC值隨著訓(xùn)練輪數(shù)的增加變化曲線,可以看出,ACC值首先快速增加,說(shuō)明本文模型隨著訓(xùn)練輪數(shù)的增加可以使神經(jīng)網(wǎng)絡(luò)有效地學(xué)習(xí)到知識(shí);然后ACC曲線在ACC=0.965處逐漸趨于平緩,說(shuō)明本文模型預(yù)測(cè)正確的概率在96.5%左右。
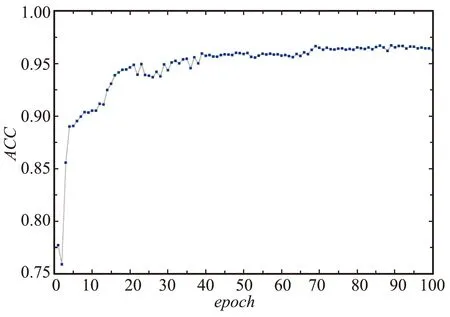
圖9 Msicc-NER模型在ACC變化曲線Fig.9 ACC variation curve of Msicc-NER model
選取漏洞類型、軟件名和相關(guān)術(shù)語(yǔ)3種類型的實(shí)體進(jìn)行精確率、召回率和F1值比較,對(duì)比結(jié)果如表7所示。
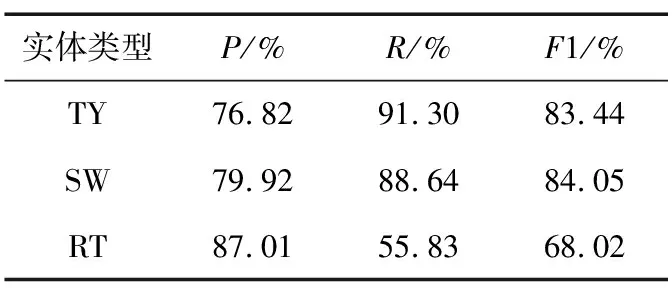
表7 Msicc-NER模型在數(shù)據(jù)集上識(shí)別效果對(duì)比
通過(guò)表7可以看出,相關(guān)術(shù)語(yǔ)實(shí)體識(shí)別性能的召回率和F1值相較于其他實(shí)體類型的識(shí)別性能比較低,主要原因是相關(guān)類型實(shí)體的定義比較寬泛,標(biāo)注時(shí)的規(guī)則不是太明確,進(jìn)而導(dǎo)致模型無(wú)法很好地學(xué)習(xí),實(shí)體識(shí)別不完全。
4 結(jié)束語(yǔ)
本文提出一種融合漢字偏旁信息、字頻信息以及詞匯信息的中文網(wǎng)絡(luò)安全命名實(shí)體方法,結(jié)合網(wǎng)絡(luò)安全領(lǐng)域的特點(diǎn)設(shè)計(jì)了7種實(shí)體類別,通過(guò)實(shí)驗(yàn)證明了本文模型的有效性,為后續(xù)網(wǎng)絡(luò)安全知識(shí)圖譜的構(gòu)建提供了幫助。在后續(xù)工作中將設(shè)計(jì)更加合適的模型算法,進(jìn)行網(wǎng)絡(luò)安全領(lǐng)域?qū)嶓w關(guān)系的抽取。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
中國(guó)生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學(xué)生必讀(中年級(jí)版)(2018年4期)2018-07-05 06:00:48
中華手工(2017年2期)2017-06-06 23:00:31
聲屏世界(2015年7期)2015-02-28 15:20:13
中外會(huì)展(2014年4期)2014-11-27 07:46:46
