基于子句抽取的文本摘要自動提取算法
2024-03-12 11:39:52朱兵兵羅勇軍丁煒超
華東理工大學學報(自然科學版) 2024年1期
關鍵詞:文本
朱兵兵, 羅 飛, 羅勇軍, 丁煒超, 黃 浩
(華東理工大學信息科學與工程學院, 上海 200237)
在如今信息數據呈指數增長時代,人們想在短時間內獲得有效數據使用自動摘要技術無疑是一個比較好的選擇;其中,如何從冗余、非結構化的長文本中提煉出關鍵信息,并且使得提煉出的信息精簡通順是一個關鍵問題。目前基于文本摘要自動抽取技術的自動摘要已經應用到社會各領域,如社交媒體綜述[1]、新聞綜述[2]、專利綜述[3]、觀點綜述[4]以及學術文獻綜述[5]等。
基于生成方式,自動摘要可分為抽取式摘要和生成式摘要[6]。抽取式摘要[7]從文本中原封不動地截取一些句子作為摘要輸出,其本質是轉換為一個排序問題,它根據每個句子的重要性賦予其不同的分數,然后選中分數排名靠前的提取單元作為摘要。提取單元可以為句子、詞組或詞語,而現有方法主要以句子作為提取單元[8]。現如今抽取式摘要中的提取算法以句子為單位已經能夠取得不錯的效果,但仍具有以下問題:一方面,抽取出的句子存在冗余;另一方面,抽取出的句子包含了一些不關鍵的信息[9]。生成式摘要是在理解原文的基礎上重新生成摘要,而不再以原文句子拼接形式生成摘要。目前對于生成式摘要想要得到理想的結果還是比較困難的,因為需要大量的創新和相應的工作來提升性能。
基于生成技術,自動摘要可分為基于主題模型、基于圖、基于特征評分和基于啟發式算法等[10]。其中,基于圖模型方法的圖排序算法充分考慮了文本圖的全局信息,同時又不需要人工標注訓練集[11]。TextRank 算法及其系列改進算法從生成方式上屬于抽取式方法,其中用到的技術為基于圖模型技術;僅僅使用文本自身的相關信息和文本自身的結構特點,就能夠實現自動摘要的提取[12]。TextRank 算法作為一種抽取式總結方法,正是由于它不需要事先學習和訓練多份文件,所以被廣泛使用。
TextRank 算法本身并沒有對摘要去除冗余的處理。為了提升TextRank 算法的性能,一系列改進算法被提出[11-16]。如為了去除冗余,Fang 等[13]提出了一種新的詞句聯合排序模型CoRank;李娜娜等[14]、汪旭祥等[15]采用余弦相似度方法;朱玉佳等[16]采用MMR 算法。為了提升摘要的準確率,徐馨韜等[11]把K-means 方法、TextRank 方法和Doc2Vec 模型相結合,提出中文文本摘要自動抽取算法(DKTextRank);黃波等[12]利用每個詞的向量,結合其他語句的向量、TextRank 算法和Word2Vec 模型,提高詞匯的維度。
然而,TextRank 及其系列改進算法并未有效地解決抽取式摘要所存在的冗余性問題。為此,本文提出基于抽取子句模型的文本摘要自動提取算法(PTextRank),以降低提取摘要的冗余度,并提高摘要的準確性。首先對文本進行預處理,以句號為標記把整個文章分割成單個句子集。然后通過Sinica Treebank[17]方法對句子進行句法成分分析,選擇子句作為抽取單元,通過BERT(Bidirectional Encoder Representation from Transformers)構建每個子句的特征向量,然后在矩陣中存儲每個子句向量的相似度。最后,將相似矩陣轉換成以子句為節點,相似度分數為邊的圖結構,一定數量排名靠前的子句構成最終的摘要,同時圖的結構中也引入標題、特殊語句等信息。本文所述的算法從比句子更細粒度的提取單元出發,將重點信息和非重點信息通過更細粒度的提取單元來區分,從而防止了冗余的內容都被抽取作為摘要的結果。
1 TextRank 及SWTextRank 算法
TextRank 算法是從PageRank 算法衍生出來的一種基于圖排序的無監督方法。PageRank 算法用來衡量網頁的重要性,以每個網頁為節點,網頁之間的聯系為邊構建網絡圖。因此,TextRank 算法將文本以句子為單位進行拆分,將每句話作為節點在網絡圖中進行劃分,同時將句子之間的相似度作為邊。通過網絡圖的迭代計算,可以得出每句話的重要性得分,最后選出分數較高的幾句話作為最終摘要。
TextRank 算法中有權的無向網絡圖可表示為G=(V,E,W),其中:V為句子表示的節點,E為節點間各個邊的非空有限集合,W為各邊上權重的集合。假設V={V1,V2,···,Vn} ,則其中Wij是節點Vi與Vj間邊的權重數值。通過余弦相似度方法可得出句子之間的相似度矩陣如式(1)所示:
每個句子的權重數值可以結合網絡圖G和矩陣Sn×n來計算,如式(2)所示任意句子的權重Vi計算公式為:
式中:Ws(Vi) 為句子Vi的權重,d是取值大小為0.85 的阻尼系數,In(Vi) 表示指向句子Vi的句子集合,Out(Vi) 表示節點Vi指向其他節點的集合,Wij表示節點Vi和節點Vj間的相似度,表示上一次迭代后節點Vj的權重值。
邊權重在TextRank 算法中的計算過程屬于Markov 過程,收斂的權重數值可以通過迭代計算最終得到。一般把句子的初始權重設為1,也就是B0=(1,···,1)T,然后迭代計算至收斂:
收斂時Bi和Bi?1會很接近,一般認為當Bi和Bi?1之間差值小于0.000 1 時收斂,最后,根據每句話的得分,以實際需要選擇排序靠前的句子作為摘要。
SWTextRank 算法[15]針對TextRank 算法在自動提取中文文本摘要時只考慮句子間的相似性,而忽略了詞語間的語義相關信息及文本的重要全局信息進行了相應改進,使得摘要的準確率得到提高。SWTextRank 算法利用Word2Vec 訓練的詞匯矢量,綜合考慮了句子權重的影響因素,如語句的位置、語句與題目是否具有相似性、重點詞語的覆蓋、重點語句與提示詞等,并通過分析句子的相似性來達到優化語句分量的目的。最后,對所獲得的候選句使用余弦相似度進行冗余處理。
2 算法設計
本文提出提取子句的方法,以避免TextRank 算法及其系列改進算法提取的摘要存在冗余的問題,從而減少含有相同語義信息的句子重復出現,使得最終獲取的摘要既具有簡約性又具有對文章總體意思的總結。本文在句子權重計算時,綜合考慮文中的子句位置,子句和題目的相似度,重點語句和提示詞等要素,使得最終獲得的摘要更準確。一般來說,每一段的首句或者尾句更能表明大意,所以這部分語句的權重也應當加大;和標題相似度很高的句子也應當加大權重;具有概括文章大意詞語的句子權重也應當加大。
2.1 基于子句的抽取
在本節中,提出一種抽取單元替代方法,對完整的句子進行截取來提取文檔的摘要。因此,使用子句提取來代替之前的整句提取方法。具體來說,提取單元基于句子的選區解析樹中的子句節點。圖1顯示了選區解析樹的兩個簡化示例(圖中S(Sentence)、ADVP( Adverb) 、 NP( Noun Phrase) 、 VP( Verb Phrase)、VBD(Verb Past Tense)、SBAR 表示從句性質、 WHNP( Wh-Noun Phrase) 、 CC( Coordinating Conjunction))。選區樹中的根節點表示整個句子,而葉節點表示其對應的詞法標記。根節點上的提取本質上是提取整個句子,而葉節點上的提取是通過提取單詞進行壓縮。對非終端節點進行抽取,既能表達相對完整的句子含義又能被人讀懂。因此,子句節點如S 和SBAR 成為一個很好的選擇。
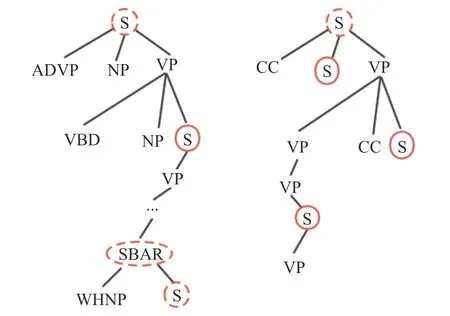
圖1 兩個簡化的選區解析樹Fig.1 Two simplified analytic trees of selected area
為了對子句單元進行提取,需要確定哪些單元可以提取。該方法基于選區解析樹,其基本思想是基于樹中的子句。在實驗中,我們采用了Sinica Treebank 中使用的語法標記集。在STB 標記集中有兩種主要類型:短語和句子。在本實驗中使用子句標簽是因為子句中的信息比短語更完整。本文實驗中主要是針對中文文本摘要的提取,因此語法標記使用的是中研院Sinica Treebank。中文和英文在句法結構上存在差異,比如英語句子的特點是句子中的每一個成分均可有修飾語,而且修飾語不止一個,每個修飾語都可以很長;一個修飾語還可被另一個修飾語修飾,因此句子結構復雜。中文句子中修飾語少而短,句子由一個一個的分句構成并逐步展開。因此,如果對英文文本進行摘要的提取,語法標記建議使用Penn Treebank。
在給定句子解析樹的情況下,遍歷它來確定提取單元的邊界。具體來說,每個子句都被視為提取單元候選項。如果它的一個祖先是子句節點,我們選擇最高級的祖先子句節點(根節點除外)作為提取單元,因為最高級的祖先子句節點包含更完整的信息。如果一個句子沒有子句,那么就用整句作為抽取單元。
表1 顯示了兩個中文句子經過本文子句抽取策略的提取結果。從結果可以看出,通過對子句提取,整個句子被分解成更細粒度的語義單元。因此,本文的子句抽取策略可以提取重要的部分,而不引入不重要的內容。

表1 子句抽取結果Table 1 Clause extraction result
2.2 子句相似度計算
TextRank 算法網絡圖中的節點間權重影響每句話的最終得分,而節點間權重即為句子間的相似度,所以計算句子相似度就變得特別重要。為了使句子相似度計算更為準確,多種相似度計算方法已經應用在TextRank 算法上,如Word2Vec、Doc2Vec 等。
BERT 是一個語言表征模型,由Google 于2018年推出。它的特點就是不同于以往的單向語言模型或者把兩個單向語言模型進行簡單拼接的方法進行預訓練,而是基于Transformer 采用深度的雙向語言表征。與Word2Vec、Doc2Vec 等方法相比,BERT 能夠更好地反映出句子之間的關系。本文正是利用BERT 訓練的詞向量來獲得子句的向量進而計算子句與子句之間的相似度。具體算法如算法1 所示,其中T為初始化的詞向量集合,S為初始化的句子向量集合,D為原始句子經過STB 抽取子句,對子句進行文本分詞、去除符號和停用詞得到的詞語集合。算法1 的具體實現流程如下所示:
利用官方中文BERT 預訓練模型對以下3 個句子進行編碼,兩種句子的相似度結果,如表2 所示。

表2 不同句子相似度結果Table 2 Similarity results of different sentences
句子A=“要重視文本摘要算法的研究”
句子B=“自動文摘是自然語言處理中的重要內容”
句子C=“今天天氣真好,風和日麗”
從所舉的例子中可以得出,A、B 兩句在語義上較A、C 兩句更為相似,但是這3 句話之間都沒有相同的詞語,每句話之間的語義相似度并未提現。A、B 和A、C 之間的余弦夾角相似度的結果,可以反映出使用BERT 對句子進行向量編碼后語義上的差異。可以看出,BERT 訓練出的詞向量更能體現出句子之間的語義不同,使得最后得出的摘要更能反映原文主旨內容。
2.3 特殊子句的權重處理
本文對特殊位置的子句、包含標題關鍵詞的子句、包含線索詞的子句和含有專有名詞的子句的權重調整為原來的k倍。在根據式(3)迭代計算收斂后,對k分別取值1.2、1.4、1.6、1.8 進行實驗對比,最后抽取前兩句作為摘要,根據式(4)~式(6)中平均準確率P、平均召回率R和平均F值最終確定k取1.4 時摘要抽取的效果最好。
其中:ai表示算法生成的第i篇文章的摘要,bi表示數據集中給定的第i篇摘要。
實驗結果對比如表3 所示。具體算法如算法2 所示,其中Bi表示句子權重值,函數isSelectCentence()是選擇符合上述條件的子句改變其權重。算法2 的具體實現流程如下所示:
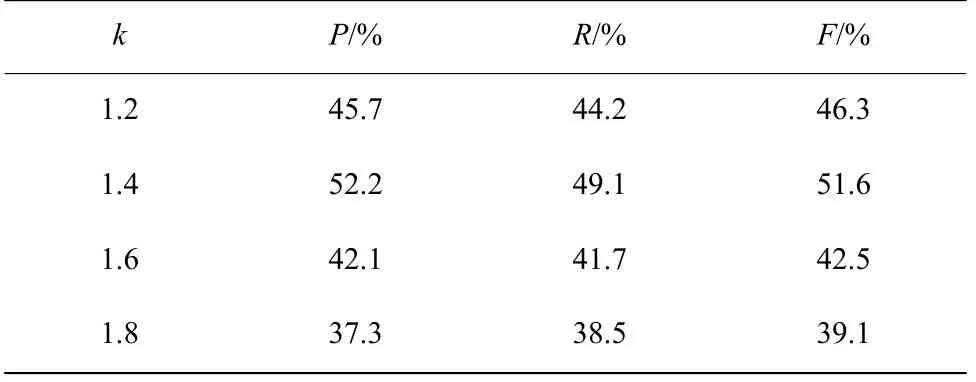
表3 不同權重結果對比Table 3 Comparison of results with different weights
2.4 算法實現
基于上述子句抽取、句子相似度計算及特殊句子的權重處理策略,改進后的PTextRank 算法的實現過程如算法3 所示。算法中對文本的處理、子句向量的計算和算法1 相同。Wij表示利用余弦相似度計算子句向量間的相似性,Sn×n是把Wij存放在如式(1)的矩陣中。然后根據式(2)計算出子句權重值Ws(Vi),選擇符合條件的子句進行權重調整,根據式(3)迭代計算至收斂得到每個子句的分數。最后根據分數排名得到最終的摘要。算法3 的具體實現流程如下所示:
3 冗余度分析
TextRank 算法迭代計算后按照句子分數從大到小的順序選擇前幾個句子形成最終的摘要,因為前幾句的語義是相近的,此時的摘要就會形成冗余。原文作者為了強調重要信息,可能會用不同形式的句子,在原文的不同位置重復原文的主旨內容。如果不同位置相似的句子都成為摘要句,那么在最終形成的摘要中就會有相似的句子造成信息冗余。
為了分析冗余問題是否存在,本文采用基于計數統計和人為判斷兩種方法進行實驗和分析。本文選取了TTNewsCorpus_NLPCC2017 數據集為樣本。在此數據集上分別進行TextRank、SWTextRank 以及PTextRank 算法的冗余度分析。首先定義一個冗余度量,即n元重疊率,計算每對句子之間的ngram 重疊。這種重疊的計算方法如式(7)所示:
根據表4 的數據顯示, TextRank 算法和SWTextRank 算法在冗余度上都遠遠高于參考摘要的冗余度。在詞匯層面的統計之外,還進行了人工評價,結果與n-gram 的重疊率相匹配,這表明TextRank 和SWTextRank 兩種算法都存在冗余的問題。

表4 各種算法和參考摘要的冗余度Table 4 Redundancy of various algorithms and reference abstracts
4 性能分析
本節進行了兩個性能分析實驗:實驗1 比較了PTextRank 算法與TextRank 算法和SWTextRank 算法的性能,實驗2 比較分析了PTextRank 算法與典型網絡在線摘要生成系統的摘要生成結果。
4.1 PTextRank 算法與TextRank、SWTextRank 算法的對比
本節以計算準確率P、召回率R和平均值F值為評價指標, 將PTextRank 與TextRank 算法和SWTextRank[15]進行比較;實驗中所采用的數據集是TTNewsCorpus_NLPCC2017。首先獲取數據集中article 和summarization 兩部分當中的article 部分,然后通過本文的PTextRank 算法和TextRank 算法、SWTextRank 算法分別生成每篇文章的摘要。
實驗結果如表5 所示。
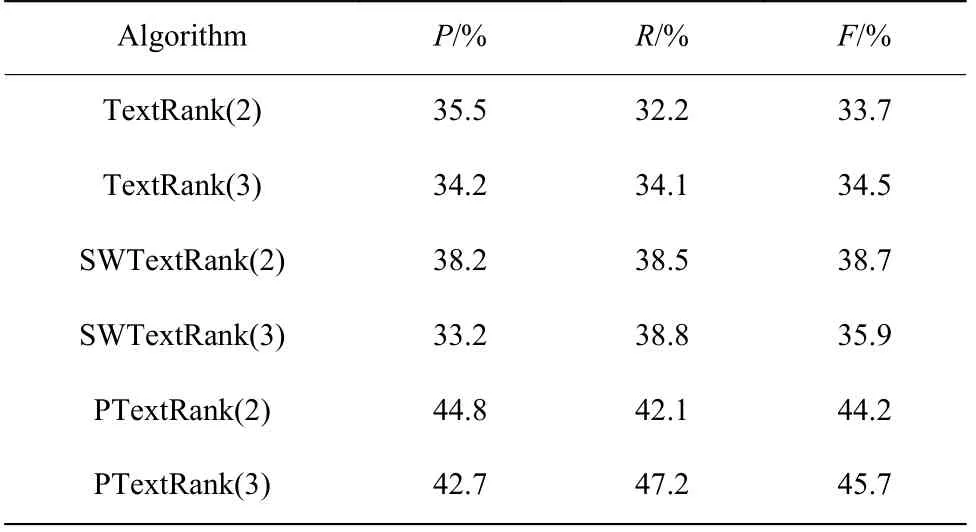
表5 各種算法的實驗結果對比Table 5 Comparison of experimental results of various algorithms
通過表5 的數據對比可以發現,從P、R、F這3 個指標來看,PTextRank 算法所產生的摘要效果要好于另外兩個算法所產生的,更加接近數據集中給定的標準摘要。其中SWTextRank 算法在生成摘要句為2 句和3 句時根據式(4)計算得出的準確率為38.5%和38.8%,而PTextRank 算法根據式(4)計算出的準確率為44.8%和42.7%。所以可以看出,PTextRank算法至少提高了6%的準確率。實驗結果說明,在提取摘要的過程中考慮了文本的整體結構信息、句子的位置以及句子與標題的相似度等因素,并結合TextRank 算法,能夠提高摘要的質量。通過表4的數據表明,在使用子句抽取模式代替原來的抽取整句后,PTextRank 算法對其進行了進一步的冗余優化處理,使得生成的摘要效果優于SWTextRank 算法。
4.2 與典型網絡摘要生成系統的摘要生成結果對比
本部分選取數據集中的兩篇文章,將PTextRank算法生成的摘要、在線自動摘要系統(http://kgb.ling join.com/nlpir/)生成的摘要與數據集中給定的摘要比較,結果如表6 所示。在線自動摘要系統所使用的算法是以TextRank 算法為基礎,首先使用Word2Vec生成詞向量并自定義Embedding,得到詞語的Embedding 后以詞向量的平均值作為句子的向量表示。其次使用余弦相似度計算句子之間的相似度并構成如式(1)的相似度矩陣。最后根據式(2)和式(3)迭代得到句子的TextRank 值,并對TextRank 值排序得到最終摘要。根據表6 的結果可知在線自動摘要系統和PTextRank 算法生成的摘要都能夠較好地表達原文的內容。因本部分只選擇兩篇文章抽取摘要數據量較小,在線自動摘要系統和PTextRank 算法生成的摘要在準確率P、召回率R和平均值F基本無差別。從摘要冗余度看,根據式(7)計算二元重疊率,可以得出在線自動摘要系統生成的摘要二元重疊率分別為22%和13%;PTextRank算法生成的兩篇摘要二元重疊率分別為10%和6%。可以看出PTextRank 算法生成摘要的冗余度遠遠小于在線自動摘要系統生成摘要的冗余度。

表6 摘要結果對比Table 6 Summary results comparsion
5 結束語
自動摘要一直是自然語言處理中的主要研究方向。本文針對目前抽取式摘要在提取中文文本摘要時存在的不足,提出了改進的PTextRank 算法。對于在抽取摘要時以句子為單位會造成抽取出的摘要存在冗余問題,本文使用STB 對每個句子進行語法標記,選擇每個句子的子句,沒有子句的就用整句作為抽取單元,進而以子句代替原來的整個句子為抽取單元。通過實驗與分析表明,與以句子為單位抽取模式相比,子句提取具有更好的效果。抽取式摘要抽取出的句子之間銜接生硬、不夠自然等問題將作為下一步待解決的工作。
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
