基于注意力機制的改進殘差網絡火焰溫度場重建
2024-03-18 08:58:58單良周榮幸洪波仰文淇孔明
化工進展 2024年2期
單良,周榮幸,洪波,仰文淇,孔明
(1 中國計量大學信息工程學院,浙江省電磁波信息技術與計量檢測重點實驗室,浙江 杭州 310018;2 中國計量大學計量測試工程學院,浙江 杭州 310018)
燃燒是工業生產和日常生活中的一種普遍現象,廣泛存在于冶金、航空航天發動機、內燃機等工業生產過程中[1]。火焰溫度監測技術有利于探究燃燒火焰的規律,推動燃燒技術理論的發展,提高燃燒效率以及降低污染排放[2]。
基于火焰輻射光場成像的測溫技術具有非侵入、響應時間短、系統設備布置簡單、精度高等優點,一直受到廣泛關注[3]。解決這類問題通常采用傳統算法,一般是基于物理問題進行求解[4-9]。常見的傳統算法有最小二乘QR 分解算法、Tikhonov正則化算法和共軛梯度法等。這些算法受限于特定的條件,求解步驟繁雜,需要更多的時間成本。近年來,隨著計算機技術的迅速發展,深度學習[10]在圖像處理、計算機視覺等領域被廣泛應用,在解決三維重建反問題方面也取得了飛速進步[11]。最新的研究結果表明,深度學習在燃燒診斷方面也有很好的應用前景。Cai 等[12]首次提出使用深度置信網絡(DBN)和遞歸神經網絡(RNN)重建溫度場,該方法展現了RNN 在噪聲抑制方面和DBN 在計算效率方面的優勢。張杰等[13]針對傳統的光場成像火焰溫度場重建計算量大、效率低等問題,提出一種基于卷積神經網絡(CNN)的火焰三維溫度場重建方法,將重建時間從傳統NNLS 算法的4759s 變為現有CNN算法的830μs。孫安泰等[14]建立了一種結合卷積神經網絡的長短期記憶網絡的模型,將CNN用于提取圖像特征、輸入LSTM預測火焰三維溫度場,并考慮了時序噪聲和圖像噪聲的影響。然而CNN 等傳統卷積神經網絡模型隨著其網絡層數的增加極易出現過擬合或者模型退化等問題,導致重建的誤差較大[15]。HE 等[16]于2016 年提出殘差網絡(ResNet),通過引入殘差連接和跳躍連接的方式,克服了梯度消失和梯度爆炸的問題。其中,ResNet18 是ResNet 系列中一種相對較淺的網絡結構,具有良好的性能和較低的計算復雜性。但是隨著網絡層數的增加,仍然面臨一些問題,如特征的重要性不均衡和冗余特征的存在。在這種情況下,加入注意力機制可以使網絡更加聚焦于關鍵特征,有效地提高網絡的表現力和泛化能力。
注意力機制[17]源自對人類視覺的研究,可以使計算機視覺系統迅速高效地關注到重點區域。Hu等[18]首次提出對卷積神經網絡中的通道信息進行注意力建模,通過學習特征的通道權重來增強有用的特征信息,其中壓縮-激勵網絡(squeeze-andexcitation network,SENet)通過特征重標定的方式自適應地調整通道間的特征響應,提升計算效率。Wang 等[19]提出了非局部注意力網絡(non-local neural network,NLNet),它融合了全局上下文信息,在目標檢測、圖像分類、實例分割等領域證明了其有效性,但會極大地增加計算量。Cao 等[20]在Wang 等[19]的基礎上提出了全局上下文網絡(global context network,GCNet),它結合了SENet和NLNet的優點,能夠在不增加過多計算負擔的情況下有效地提高模型性能和泛化能力。
另一方面,池化操作也是圖像處理中十分重要的一環。通過池化層來縮小特征圖尺寸的方法經常被現有的一些卷積神經網絡所采用,以此來獲取更大的感受野。常見池化方式有平均池化[21]、最大池化[21]和全局平均池化[22]。然而這些池化方式對特征的重要性沒有進行精確的區分,可能會丟失一些重要信息。Gao 等[23]提出了局部重要性池化(local importance-based pooling,LIP),這種池化方式可以自動學習重要性權重,根據特征的重要性對池化區域內的元素進行加權平均,從而更好地保留重要信息。
因此,本文在ResNet18 網絡中加入注意力機制GCNet和局部重要性池化LIP,對網絡進行優化。通過發光火焰正問題的數據模擬得到三維溫度場和對應火焰圖像組成數據集進行訓練,將訓練結果用于火焰三維溫度場的重建。通過消融實驗驗證本文所提出的優化方法的有效性。
1 ResNet18網絡優化
卷積神經網絡是一種特殊的多層感知機。卷積神經網絡通常由輸入層、卷積層、池化層、全連接層和輸出層組成,傳統的CNN 模型為防止過擬合現象出現一般設置為淺層網絡模型,ResNet[16]的提出讓下一層不再直接擬合成底層映射,通過近似于電路中的“短路”連接,以跳過一層或者多層的連接,最后將信息送至神經網絡的更深層。引入跳層連接能夠有效解決梯度彌散所導致的神經網絡退化以及模型難以收斂兩大問題,并減輕計算量。殘差網絡結構相較于傳統CNN 模型的優勢是其可以放大輸入中微小的擾動,因此更加靈敏。
本文采用的火焰溫度場數據集不大,為了防止出現過擬合現象,不需要多層次和多通道數的殘差網絡,因此本文使用的模型基于ResNet18 的主要框架搭建。輸入為尺寸360×360 的火焰光場圖像,經過4個殘差模塊卷積層特征提取、池化層尺寸縮減后得到大小為11×11的矩陣。ResNet18一共含有4個殘差模塊,每個殘差塊包含兩個殘差單元,每個殘差單元首先進行一次3×3卷積,其次進行批標準化和ReLU 激活,再次進行一次3×3 卷積和批標準化,最后與輸入特征圖相加后進入ReLU 激活。在模型中,加入批標準化的操作,主要是將卷積層輸出數據進行歸一化處理,加快網絡的訓練和收斂的速度,防止過擬合[24]。ReLU 激活函數是一種在神經網絡中廣泛應用且效果良好的激活函數,可以顯著提高卷積神經網絡的性能并避免模型訓練過程中梯度消失問題[13]。對ResNet18 網絡結構進行改進,在ResNet18 網絡卷積層的最后一層依次加入上述的注意力機制層(GCNet)[20]和局部重要性池化層(LIP)[23]。改進的ResNet18 網絡由輸入層、17個卷積層、1個最大池化層、1個注意力機制層、1 個局部重要性池化層、輸出層和1 個全連接層組成。過程中尺寸變化情況已在圖1中標出,在網絡末端使矩陣展平元素與目標溫度場元素一一對應。改進的ResNet18網絡結構如圖1所示,方框中為改進部分。表1給出了網絡模型的各個參數。

圖1 改進的ResNet18網絡結構

表1 ResNet18框架模型參數
1.1 注意力機制優化
當前的深度學習算法經常重復使用相同卷積操作,只關注到圖像局部的感受野,提取特征較為單一。如ResNet18網絡使用的殘差塊是由1×1卷積和3×3 卷積堆疊而成,火焰光場特征圖經過普通3×3卷積操作之后,新生成的特征圖中每一個像素點只能專注于原始特征圖中9 個緊挨一起的像素點范圍,僅學習到了局部的信息,而模型要學習更多全局而非局部信息只有通過加深網絡深度的方式提高感受野,但此方式優化難度和計算量都很大。火焰光場圖像的全局信息十分重要,注意力機制GCNet能夠幫助模型從全局視角聚焦于感興趣區域,從而分配更多的注意力給這些部分。在模型特征提取部分引入GCNet,模型可以獲得更大的感受野,使網絡能夠捕捉到更廣闊區域內的特征信息,這意味著模型可以同時考慮到遠距離的特征關系,而不僅限于局部區域。在火焰溫度場的重建任務中,神經網絡通過識別各尺度的特征,學習到灰度值信息與三維溫度場的映射關系,引入GCNet也即加大了對這種映射關系的特征信息的捕捉[11,22]。GCNet 結構圖如圖2所示。

圖2 GCNet結構
GCNet由三部分組成[20]。
(1) 建立全局上下文特征圖。特征圖X∈RC×H×W(C、H、W分別為特征圖的通道數、高度、寬度)。首先經過特征提取輸入到1 × 1的卷積層和激活函數Softmax 中,權重參數為Wk,得到的權重矩陣與大小為C×(H×W)的特征矩陣相乘,得到包含全局上下文信息的大小為C× 1 × 1的特征矩陣O1,如式(1)所示。

(2)計算每個通道的重要程度。將大小為C×1 × 1的特征矩陣O1輸入到大小為1 × 1、權重參數為Wv1的卷積層,得到的特征矩陣的大小為C/r×1 × 1。r為參數減少值,以此提高網絡的計算效率。在卷積層后加入LayerNorm 層和激活函數ReLU 防止模型過擬合。接著將特征矩陣輸入到大小為1 × 1、權重參數為Wv2的卷積層,最終得到大小為C× 1 × 1的特征矩陣O2,如式(2)所示。
式中,ReLU為非線性激活函數;LN為層歸一化;Wv1和Wv2為兩個卷積層的權重參數。
(3) 特征圖與權重相乘。將輸入特征圖X∈RC×H×W和具有不同通道權重的特征矩陣O2相乘,最終得到含有不同權重信息的特征圖O∈RC×H×W,如式(3)所示。
1.2 池化優化
常見的池化方法有平均池化、最大池化、全局平均池化等。平均池化[21]可以輸出所有激活值的平均值,但是有可能會忽略較為主要的特征,對鑒別性很小的特征有害。最大池化[21]輸出所有激活值的最大值,但當重要特征的激活值不是最大時并不適用。全局平均池化[22]可以通過減少參數的數量增加網絡的準確性和穩定性。
由于火焰不同位置的輻射值不同,如果使用上述幾種傳統池化方法,在特征圖的每個池化區域中只進行簡單的聚合操作,對特征的重要性沒有進行精確的區分,可能會丟失一些重要信息,將會影響重建精度。為了更充分地提取火焰的特征,本文采用局部重要性池化[23]對ResNet18網絡進行改進。這種池化方法通過邏輯模塊(Logit Module)中的卷積生成輸入特征圖的特征權重,邏輯模塊接著進行局部歸一化,最終在池化的過程中自動重新鑒別特征,篩選出重要的特征,減少火焰光場特征圖特征信息的丟失。池化可看作滑動窗口中激活值的線性加權過程,F表示池化函數,G表示邏輯模塊,能夠更好地學習目標特征圖的重要性,I和O分別表示池化前的輸入特征圖和池化過后的輸出特征圖,(x,y)表示輸入特征圖對應滑動窗口的位置,(x′,y′)表示對應的輸出位置,(Δx,Δy)表示滑動窗口內的相對位置,Ω表示滑動窗口內的卷積核,對應的池化表達式為式(4)。
LIP的結構圖如圖3所示,邏輯模塊由一個1×1卷積層組成,使用仿射實例歸一化(affine instance normalization)作為歸一化形式,并使用Sigmoid函數作為具有固定放大系數的函數,以保持數值的穩定性。為了使重要性權重非負且易于優化,使用exp(·)計算邏輯模塊,如式(5)。


圖3 LIP結構圖
2 仿真實驗和分析
2.1 溫度場重建流程
將改進的ResNet18 網絡模型用于火焰三維溫度場重建過程中數據集的構建以及網絡模型的訓練和測試。通過改變溫度場分布函數來構建數據集,然后將數據集分為訓練集和測試集。在訓練過程中,將數據集投入到改進的ResNet18 網絡模型的輸入層,通過模型運算最終在輸出層得到輸出數據,誤差通過火焰三維溫度與輸出數據的比較得到,將誤差代入網絡模型更新模型參數,從而完成一次迭代。當誤差不再下降或達到收斂標準的時候停止迭代,完成模型的訓練。在測試過程中,將測試集圖像數據放入網絡模型,輸出計算溫度,與真實溫度進行對比并計算誤差,評價改進的ResNet18網絡模型的性能。
2.2 數據集構建
本文使用的是單峰火焰數據集,采用式(7)所示的溫度場分布函數[7],假設為對稱圓柱形標準火焰模型。
式中,z、r分別為溫度點軸向、徑向坐標;Z表示模擬火焰的高度,為30mm;R表示模擬火焰的半徑,為12mm;f和v為2 個可調參數,改變可調參數共可獲得2000 組不同的數據集,總計2000張光場圖像,1800 組作為訓練集,200 組作為測試集。
2.3 網絡模型參數選擇
網絡優化器的主要作用是在網絡訓練時對權重更新方法等進行優化,主要的優化函數有Adagrad算法[25]、RMSprop算法[26]以及Adam算法[27]等。本文選用Adam 算法作為卷積神經網絡參數的優化算法,它繼承了Adagrad 算法和RMSprop 算法的優點,在基于一階矩均值計算適應性參數學習率的前提下,還充分利用了梯度的二階矩均值。本文網絡采用PyTorch 搭建、訓練及測試。服務器顯卡的型號為NVIDIA Geforce RTX 3090。采用式(8)所示的均方誤差函數(MSE)作為損失函數。
式中,Tp表示重建溫度;Tr表示真實值溫度。
2.4 網絡性能評價
采用改進的ResNet18 算法對火焰三維溫度場進行了重建。本文采用平均相對誤差(MRE)和最大相對誤差(MMRE)兩種評價指標,見式(9)、式(10)。
式中,N表示三維溫度場中所有溫度點的個數;Tri表示真實值中第i個溫度點;Tpi表示預測值中第i個溫度點。
圖4(a)和圖4(b)分別為火焰的原始溫度場和改進ResNet18 網絡重建出的溫度場。圖4(c)為改進ResNet18網絡重建出的溫度場的相對誤差圖。

圖4 火焰溫度場重建結果
使用改進前和改進后的ResNet18 網絡重建的平均相對誤差和最大相對誤差隨周期變化的趨勢分別如圖5(a)和圖5(b)所示。

圖5 不同周期下的相對誤差圖
本文改進的ResNet18 網絡訓練50 周期平均相對誤差為0.13%,最大相對誤差為0.75%,改進前ResNet18 網絡訓練50 周期的平均相對誤差為0.19%,最大相對誤差為1.14%,可見通過本文提出的改進ResNet18 網絡重建出的溫度場與原始溫度場在各個網格上的相對誤差總體要比改進前的ResNet18 網絡重建方法的誤差小。因此,本文提出的改進ResNet18 網絡重建火焰三維溫度場相較于原始ResNet18 網絡在重建誤差上有很大幅度減小,可以準確重建火焰三維溫度場。
2.5 消融實驗
為了驗證在ResNet18 網絡引入局部重要性池化(LIP)模塊和全局上下文網絡(GCNet)模塊的有效性,本文設計了消融實驗,下面將對進行的消融實驗的設計思路以及目的進行闡述。其中第一組為原ResNet18 網絡,第二組添加了局部重要性池化(LIP)模塊,第三組添加了全局上下文網絡(GCNet)模塊,第四組同時添加局部重要性池化(LIP)模塊和全局上下文網絡(GCNet)模塊。各個模塊的消融實驗結果如表2所示。
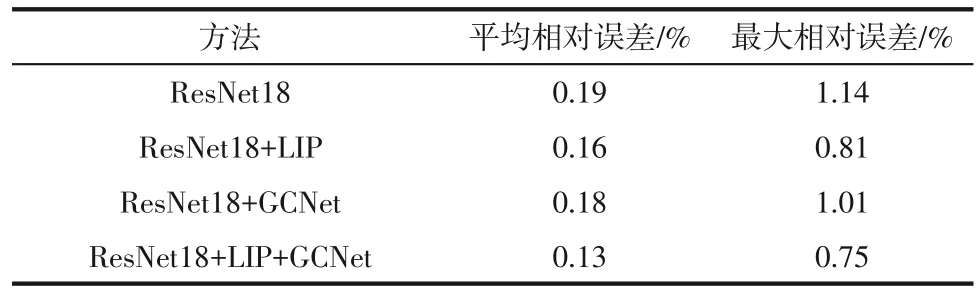
表2 不同模塊消融實驗結果
由表2可以看出,引入局部重要性池化(LIP)后,網絡的最大相對誤差為0.81%,相較于改進前的ResNet18 網絡的最大相對誤差減少了28.95%;ResNet18+LIP 能夠更好地在池化的過程中自動重新鑒別特征,減少火焰光場特征圖特征信息的丟失,充分地提取火焰的特征;引入全局上下文網絡(GCNet)后,網絡的最大相對誤差為1.01%,與改進前的ResNet18 網絡相比,最大相對誤差減少了11.4%;ResNet18+GCNet使模型在全局視角上聚焦于火焰更加需要關注的顯著區域,使得模型能夠充分利用全局信息;同時引入局部重要性池化和全局上下文網絡后,網絡的平均相對誤差為0.13%,最大相對誤差為0.75%,相較于改進前的ResNet18網絡的平均相對誤差減少了31.58%,最大相對誤差減少了34.21%,ResNet18+LIP+GCNet 集合了兩者的優點,在保證不丟失局部重要信息的情況下,增加對全局信息的把握能力。可以看出同時加入兩個改進模塊后的重建精度要優于加入單個改進模塊后的精度,局部重要性池化模塊對精度提升的作用更大。
通過兩種改進方法與原始方法進行對比,結果表明,本文所提出的方法具有更小的重建誤差,驗證了本文所提方法的有效性。圖6為消融實驗的重建結果圖。

圖6 消融實驗重建結果
3 結論
(1)本文提出了采用改進的ResNet18 網絡進行火焰溫度場重建,在ResNet18 網絡的基礎上加入注意力機制GCNet和局部重要性池化優化提取內容,實現已知信息的充分利用。
(2)本文通過消融實驗分析了注意力機制GCNet模塊和局部重要性池化模塊對重建精度的影響。結果表明,在ResNet18 網絡中同時引入注意力機制GCNet和局部重要性池化后,網絡的平均相對誤差為0.13%,最大相對誤差為0.75%;改進前ResNet18網絡的平均相對誤差為0.19%,最大相對誤差為1.14%。同時加入兩個改進模塊后的重建精度要優于加入單個改進模塊后的精度,本文所提出的方法具有更小的重建誤差。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:02
中國生殖健康(2020年4期)2021-01-18 02:58:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
甘肅教育(2020年21期)2020-04-13 08:09:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
