基于BM25 的勘察設計企業科研項目重復性檢測方法研究
2024-04-09 05:53:24曹德威王劍剛錢常運
科技管理研究 2024年4期
關鍵詞:文本
王 揚,曹德威,王劍剛,錢 鋒,錢常運
(上海勘測設計研究院有限公司,上海 200335)
0 引言
如今,中國的學術研究、技術研發蓬勃發展,多學科交叉日益相融,隨之產生交叉立項、重復立項的現象,這種現象在科研院所尤為明顯。其原因包括跨地域跨組織管控要求不一、查重信息庫范圍不足、重復性鑒定的技術壁壘等[1],這些問題在勘察設計行業仍然突出。為避免科研項目重復立項、科研成果重復產出,需大量的科研人員參與鑒定,不僅依賴科研人員的專業廣度和深度,且枯燥低效[2]。而對于國內的高新技術企業和科改示范企業,每年約投入其營收的5%在科技研發中[3],重復立項帶來的資金損失不言而喻。
從全球范圍來看,多院校、多科研機構的多方投入有助于構建良性競爭機制,孵化尖端技術[4]。伍丹等[5]認為這種作用尤其集中體現在健康信息、人機交互、機器學習等領域。然而,Schimmack[6]、Tincani 等[7]研究指出,低難度、低質量的重復研究缺乏創新性且成果缺乏實際效用,甚至滋生經費欺詐。從中國來看,各地區對于科技研究的管理存在明顯邊界[8],如路鵬等[9]、王欣等[10]的研究指出,未建立統一的儲備信息庫,導致前期工作缺乏協同、調研數據重復采集、同一課題反復申報等弊端。為杜絕科研經費的重復投入,國內各地區明確科研經費的管理機制,但仍無法杜絕“重復包裝”等現象。從勘測設計行業來看,能源規劃、工程設計、智能建造、智能運維等領域孕育了大量的科技研究課題[11],其中不乏對“建筑信息模型(BIM)+地理信息系統(GIS)+物聯網(IoT)”、人工智能、施工技術、數據挖掘技術的探索與研究,這些課題雖然有不同的聚焦場景,但研究內容存在緊密聯系,技術路線可相互借鑒,有必要加強對前期資源的整合,減少重復性投入。
基于關鍵信息和文本語義對立項材料的重復性進行自動判定,是檢測課題重復性的重要路徑。隨著企業信息化的應用深化,科研管理過程數據的結構化存儲已基本實現,企業積累的歷史科研項目數據庫是BM25(Best Matching 25)算法應用的前提。為實現科研項目重復性的自動判定,在課題申報時對項目標題、研究背景、研究目標、建設內容進行檢測,以量化結果干預立項工作。本研究在詞頻-逆文檔頻率(TF-IDF)、BM25 算法的基礎理論上,提出一種聚焦勘察設計企業特征的科研項目重復性計算方法,并以新能源、工程數字化和信息化領域的真實課題加以驗算,同時融入領域、專業、人員、部門等特征屬性。
1 文本相似性相關研究
近年來,項目重復性檢測的熱點集中在文本相似度的自動識別和判定。Salton 等[12]提出的空間向量模型將詞頻和逆文檔頻率表示成數學向量的模式來計算文本文檔相似度,該模型廣泛應用于信息檢索和文本檢索等。Kim 等[13]以國家級的科研數據為基礎建立各類課題項目的向量模型,通過計算余弦距離和歐幾里得距離(Euclidean distance)來評估文本相似度。Al Qady 等[14]在TF-IDF 算法的基礎上加入監督學習以細化聚類結果,從而提高文本相似度檢測的準確性,進而應用于課題文檔的相關度檢測。
BM25 是一種用于結構化文本的概率計算模型,在文本搜索、文本匹配、語義判定等方向應用廣泛。Liu 等[15]基于BM25 創建了基準數據集(LETOR)用于信息檢索排名;Zhang 等[16]根據BM25 的原理,擴展引入bR*-tree 的新索引,進行空間關鍵詞查詢,提升了檢索的響應時間;Singhal 等[17]在BM25模型基礎上提出的樞軸歸一化技術可用于縮小相關性概率與檢索概率之間的差距;He 等[18]在不同的TREC 數據集上,計算詞頻并進行歸一化參數調整,其調整方法在不同的 TREC 數據集上具備明顯優勢,而計算成本卻微乎其微。BM25 算法應用于勘測設計企業科研項目重復性檢測具有天然的優勢,原因在于:勘測設計企業科研項目數據以“基本信息+文本”的形式存儲,其中基本信息多為符合數據字典的固定值,且現有研究樣本中超過95%的公司文本信息小于1 000 字符。在計算項目相似度時,在BM25 算法基礎上綜合各數據權重以獲得最終值。
2 構建相似度模型
2.1 TF-IDF 相似性
使用TF-IDF 計算文本相似性,即詞頻與逆文檔頻率的乘積,計算式子如下:
式(1)~(3)中:ni,j表示詞條ti在文檔dj中出現的次數;|D|表示所有文檔的數量,|j:ti∈dj|表示擁有詞條ti的文檔數量。
計算文本Q與文本庫D中某文本d的TF-IDF相似度時,建立空間向量,以余弦距離表示,即
2.2 BM25 相似性
BM25 算法是對 TF-IDF 算法的優化,在詞頻的計算上,BM25 限制了文檔中關鍵詞的詞頻對評分的影響。與TF-IDF 相比,BM25 增加了詞語飽和度k和字段長度規約b。以BM25 算法計算文本Q與文本庫D中某文本d的相似度公式為:
式(5)中:Wi為文本Q中詞語qi的權重;R(qi·d)為詞語qi與文本d的相似度。
Wi通常取其IDF 值,即
式(6)中:N為文檔總數;n(qi)為包含該詞語的文本數目;為保證分母不為0,平滑系數取0.5。
式(7)(8)中:fi為qi在d中的頻率;qfi為qi在Q中的頻率;k根據經驗值取1.20;dl 為d的長度;avg dl 為所有文本D的平均長度;b根據經驗值取0.75。
綜上可得,BM25 相似度可表示為:
2.3 科研課題模型
勘察設計企業的科研課題關鍵信息可以通過標題、項目屬性、項目背景、建設目標和建設內容等數據來展示。根據歷年科研項目的管理經驗,分別對上述元素設置權重,分別如表1 和表2 所示。其中,標題是指科研課題標題,小于100 個字符;項目背景是指科研課題的建設意義、必要性,小于2 500 字符;建設目標是指科研課題的建設目標、考核指標,小于2 500 個字符;建設內容是指科研課題的實施方法、技術方案,小于2 500 個字符。

表1 科研課題關鍵元素權重

表2 科研課題關鍵元素數據類型
標題、項目背景、建設目標、建設內容的文本相似度由TF-IDF 算法、BM25 算法計算得出,項目屬性的相似度單獨計算。通過加權求和,獲得輸入課題P與項目庫D中某課題Di的相似度,即
項目屬性信息可進一步細分為項目領域、涉及專業、項目負責人、實施部門,各細項相似度計算方式如表3 所示。

表3 科研課題屬性信息相關度
因此,項目屬性的相似性可表示如下:
3 實驗與分析
基于BM25 算法計算科研課題相似度的方法,其實驗過程分為以下四步:(1)文本預處理;(2)建立匹配庫;(3)根據TF-IDF 算法、BM25 算法分別計算輸入課題與匹配庫中課題的相似度;(4)分析計算結果。處理及計算過程的設備環境與運行環境為:64 位Win10、intel(R)Core(TM)、Python3.7。
3.1 文本預處理
預處理的目的在于聚焦文本的有效信息,對內容進行降噪、統一同類信息。將課題編號(ProjectID)作為唯一標志,信息預處理步驟包括文本分詞、去停用詞、去標點符、英文正則化。
文本分詞:采用Krogh 等[19]提出的Jieba 分詞模型進行處理。相較于Liu等[20]使用的HanLp、Li等[21]使用的Thulac 分詞模型,Jieba 分詞模型對中文語境中未登錄詞有較強的分析能力,對專業名稱較多的科研課題具備優勢,因此適合本文的使用環境。
去停用詞:停用詞庫由虛擬詞、語氣詞、代詞等構成,覆蓋中英文。其中,包括中文停用詞843 個,英文停用詞548 個。
去標點符:去除標點符,涵蓋中英文。
文本正則化:英文單詞統一以小寫形式存儲,避免因字母編碼造成的詞義誤判。
3.2 建立匹配庫
將歷史科研課題進行批量處理,獨立存儲每個課題,建立匹配庫并動態更新。匹配庫共計803 個項目,按課題領域分類:水利有67 項,水電有91 項,新能源有242 項,輸變電有3 項,生態環境有234 項,建筑市政有28 項,數字化信息化有82 項,其他有56 項。將上述過程以偽代碼形式呈現,如圖1 所示。

圖1 建立匹配庫偽代碼
3.3 樣本相似度計算
對樣本課題P1(新能源領域)、P2(工程數字化和信息化領域)的文本進行預處理,并分別根據TF-IDF 算法及BM25 算法,將其與匹配庫中所有課題一一進行相似度計算。樣本課題的基本信息如表4所示。

表4 樣本課題的基本信息
3.4 計算結果分析
3.4.1 課題P1的計算結果分析
根據課題P1的計算結果,從匹配庫中選取3 個相似度較高的課題D1、D2、D3進行分析。具體地,課題P1涵蓋抗臺風、海上風電、海洋牧場、風機結構等細分場景,而由TF-IDF、BM25 所識別出的高相似度課題D1、D2、D3均屬于新能源領域,且重點覆蓋海上風電、基礎結構、海洋漁業等細分場景,符合預期。從表5 可以看出,對于如標題的短文本,BM25 算法得出的相似度明顯高于TF-IDF;而如課題背景的長文本,BM25 算法得出的相似度普遍低于TF-IDF。這是由于BM25 算法中對字段長度規約的設置,其值越大,在計算得分時對文檔長度差異的懲罰越大,同樣符合預期。

表5 匹配庫課題與樣本課題P1 的相似度
圖2、圖3 分別為通過TF-IDF 算法、BM25 算法計算課題P1 與匹配庫中所有課題相似度的分布,并使用不同符號區分課題領域。從空間散點分析,同為新能源領域的課題與P1整體相似度較高。相較于TF-IDF,BM25 的計算結果分布中,非新能源領域的課題的相似度較分散、區間較大,這是由于BM25 算法實現了對詞語權重的控制,擴大了課題相似性的區分度。從時間序列分析,2019 年9 月至2023 年8 月的匹配庫課題在BM25 與TF-IDF 的計算結果體現出較高的一致性,未出現極端差異。
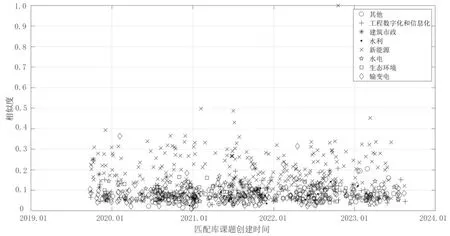
圖2 基于TF-IDF 算法的樣本課題P1 與匹配庫相似度計算結果分布
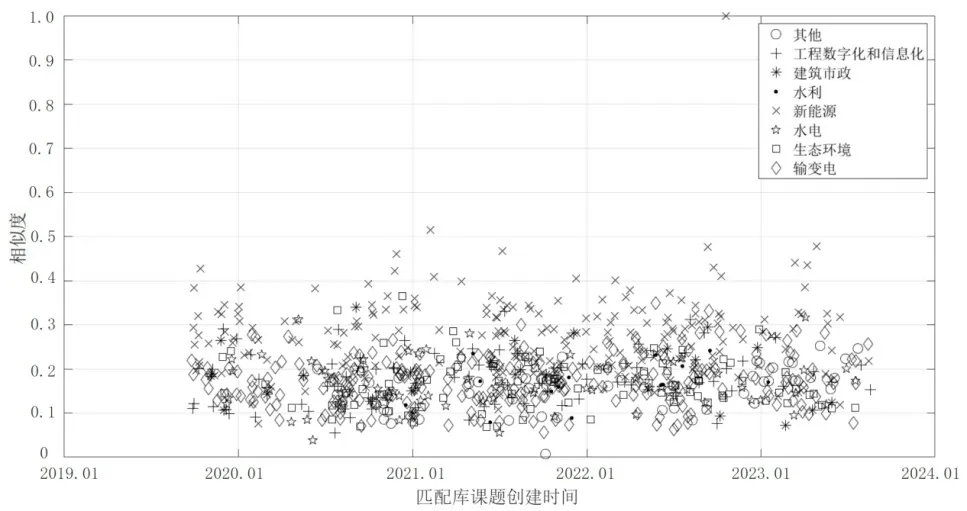
圖3 基于BM25 算法的樣本課題P1 與匹配庫相似度計算結果分布
圖4、圖5 分別為通過TF-IDF 算法、BM25 算法計算課題P1與匹配庫中各領域課題相似度的最大值、平均值、最小值。通過數據對比,BM25 算法在平均值、最大值明顯高于TF-IDF,而最小值無明顯差異,再次證明了BM25算法在區分度上的控制能力。

圖4 基于TF-IDF 算法的樣本課題P1 與匹配庫各領域課題相似度分布
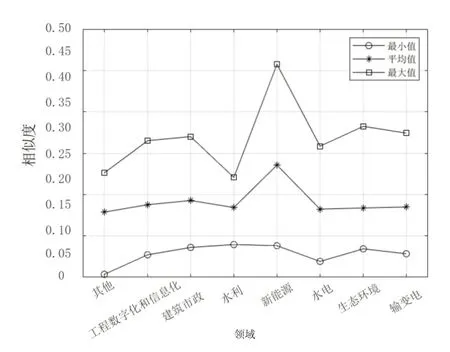
圖5 基于BM25 算法的樣本課題P1 與匹配庫各領域課題相似度分布
3.4.2 課題P2的計算結果分析
課題P2涵蓋抽蓄電站、機電設備、設備、智能管控等細分場景,如表6 所示,TF-IDF 與BM25 算法識別的高相似度課題均屬于工程數字化和信息化領域,覆蓋土方平衡、數字化施工、安全智能管理等場景。其中,課題D1’的標題文本較短,與課題P2存在“智能”“技術研究”重復關鍵詞,致使P2與D1’基于TF-IDF 和BM25 算法在標題相似度上有較高得分。通過深入研讀P2與D1’發現,兩個課題分別聚焦于抽蓄電站設備的安裝和土石方平衡計算,雖然在研究內容上均涉及人工智能(AI)、BIM 等數字技術,但經過人工復驗,認為兩者的綜合相似度過高,處于非合理范圍。這是由于TF-IDF 與BM25 算法在原理上通過詞語、詞頻計算相似度,缺乏實際語義理解,從而產生誤判。

表6 匹配庫課題與樣本課題P2 的相似度
圖6~圖9 分別展示了通過TF-IDF、BM25 算法計算課題P2與匹配庫中各課題相似度分布、各領域課題相似度的最大值、平均值、最小值。與課題P1類似,課題P2的計算結果表明,BM25 算法相較于TF-IDF 表現出較大的區分度,且其計算均值、最大值較高,最小值接近。在圖7 中,能夠看到某一課題的相似度達到0.540,但在圖6 中的相似度為0.289,并不突出,該課題標題為“海上風電數字化交付研究及應用示范”,與課題P2在建設內容(數字孿生、BIM 技術應用)上高度契合。這是BM25算法在調節平滑因子擴大區分度所帶來的優勢。
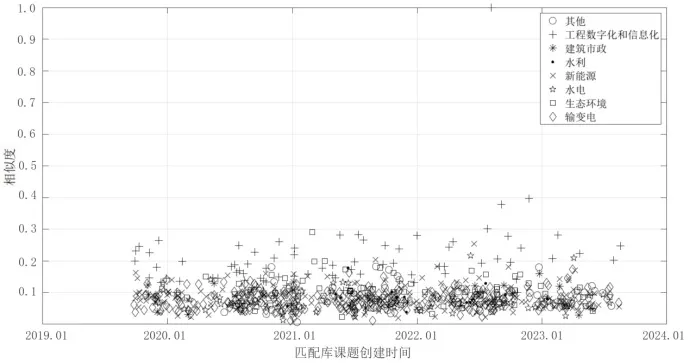
圖6 基于TF-IDF 算法的樣本課題P2 與匹配庫相似度計算結果分布
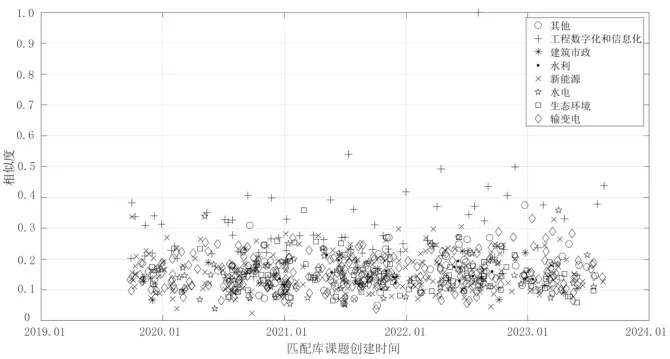
圖7 基于BM25 算法的樣本課題P2 與匹配庫相似度計算結果分布
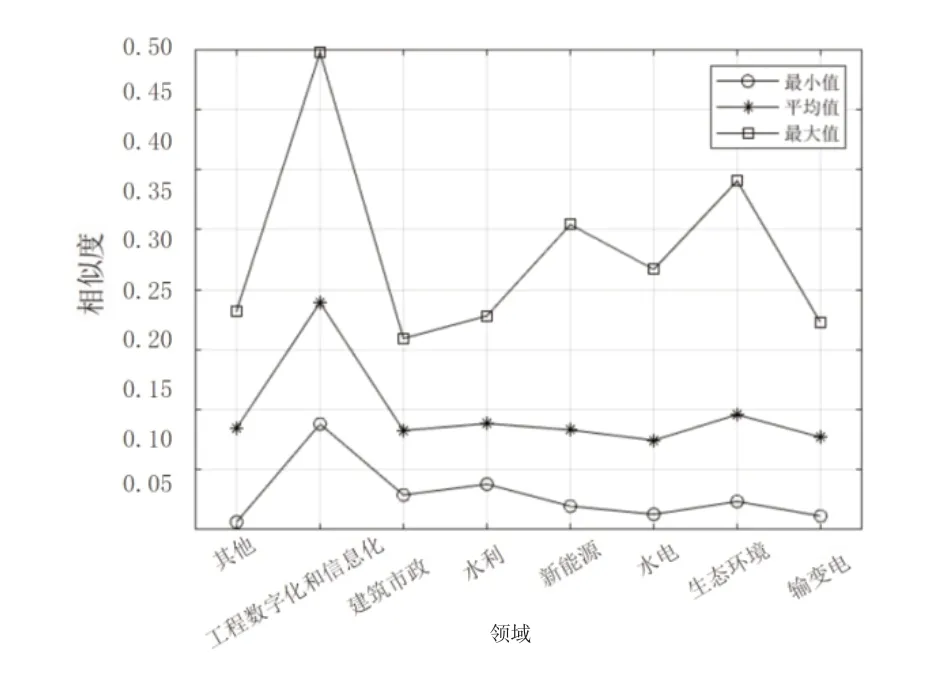
圖8 樣本課題P2 與匹配庫各領域課題相似度(TF-IDF)
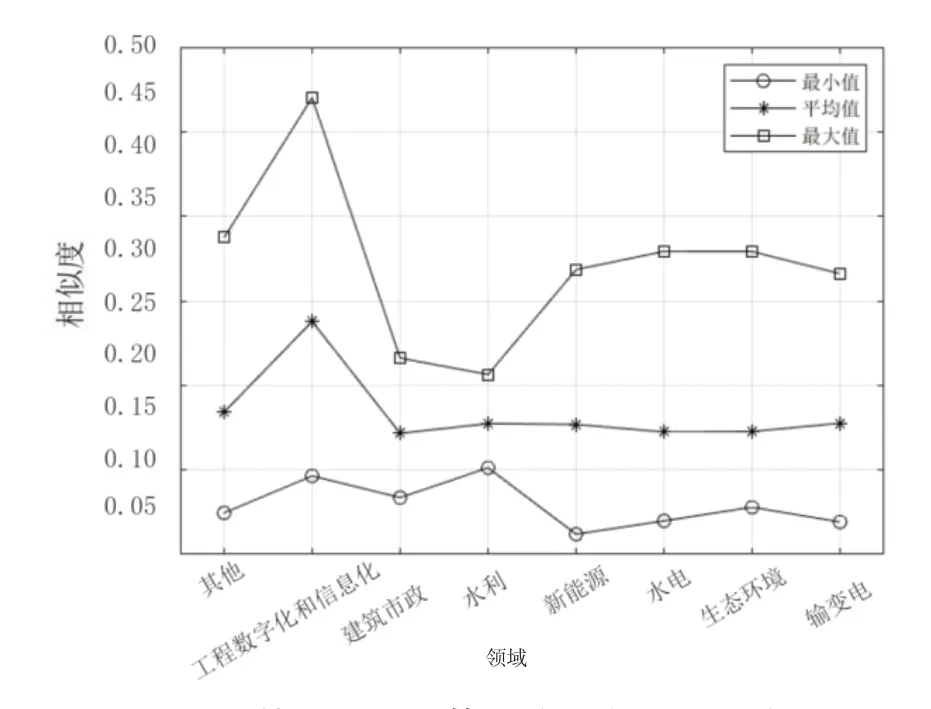
圖9 基于BM25 算法的樣本課題P2 與匹配庫各領域課題相似度分布
3.4.3 TF-IDF 與BM25 的異同點分析
TF-IDF 與BM25 在科技課題的相似度判定中,在空間分布、時序分布上具備較高的一致性,即同領域課題普遍相似度高,不同領域課題相似度較低,且未出現較大偏差,符合常規認知。相較于TFIDF,BM25 算法通過詞語飽和度和字段長度規約實現權重控制,計算結果有較高的區分度,有利于挖掘不同領域下高相似性的文本,最大程度避免了潛在重復課題的遺漏。TF-IDF 與BM25 在原理上通過詞語、詞頻計算文本相似度,在文本較短且詞語重合度較高的場景中存在局限,如TF-IDF 與BM25 均判定“智能土方平衡關鍵技術研究”與“智能吊裝平衡關鍵技術研究”兩個標題相似度得分較高,但實際語義存在較大差異。
4 結論
本研究提出了一種基于BM25 算法的勘察設計企業科研項目重復性檢測方法,聚焦BM25 算法的基本原理,融入勘察設計企業特點,引入領域、專業、人員、部門屬性值,在文本比對相似度的基礎上強化屬性值的計算權重,在判定課題重復性、輔助立項識別等工作上卓有成效。經新能源、工程數字化和信息化領域課題的實際驗證,計算時間小于0.1 s,滿足商用;計算結果經技術研發人員復驗,準確性滿足業務管理需要。除科研課題外,該相似度計算方法在工程項目、信息化項目、咨詢服務項目等亦可應用。
但是,該算法仍存在以下局限,未來研究可從以下方面進行深入探討:
(1)匹配庫所使用的科研課題共計803 個,累計中文字符小于321 萬字,在數據量上仍然不足,僅夠滿足企業內部自檢,無法對橫向課題、交叉性課題、區域性課題進行對比。如何構建跨企業、跨區域、跨行業的多源異構匹配庫,相應的技術難度、管理難度值得深思。
(2)算法的內核是TF-IDF 算法的升級,雖引入了短文本的權重參數,但仍局限于詞頻及分布。機器學習算法能大大改善該缺陷,通過數據標注、語義庫學習,理解上下文場景,強化語義理解在判定文本相似度時的作用。
(3)算法缺乏一套行之有效的評價模型,僅依靠技術研發人員的主觀判斷,而常用的檢索統計指標,諸如查全率、查準率、評價準確率均值對于企業科研課題缺乏實際意義,因此建立適用于勘察設計行業的算法評價模型十分迫切。
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
