基于改進YOLOv5的軸類零件表面缺陷檢測算法*
2024-04-12 00:29:56張昕楠郝涌汀付靖凱
組合機床與自動化加工技術 2024年3期
張昕楠,李 穎,郝涌汀,付靖凱,于 鵬
(沈陽理工大學機械工程學院,沈陽 110159)
0 引言
金屬軸類是機械設備的基礎零部件,用于轉矩傳動和承受載荷。在制造過程中,由于鋼坯原材料、加工方式、工藝流程等的改變,軸類零部件的表面不可避免地產生各類缺陷,這些缺陷將直接影響到其他機械設備的日常工業運轉和安全生產管理。傳統的檢測技術,如使用熒光磁粉進行檢查,既費時費力,又容易出現誤檢、漏檢等嚴重的錯誤。隨著基于圖像信息的缺陷檢測分析方法的發展,MENTOURI等[1]開發出一種利用二值化的統計圖像特征,結合k最近鄰分類器的缺陷檢測分析方法,可以更準確地發現熱軋過程中的鋼帶表面的缺陷。SAYED[2]提出了一個全新的紡織領域面料瑕疵點檢測方法,采用了熵濾波和最小誤差閾值分割的技術,可以更加精細地識別出紡織物瑕疵點。LI等[3]通過對卷煙標簽數據圖像的采集與標注,并完成相關檢測實驗,提出了將最小外接矩形應用于缺陷形狀的方案,該方案應用性較廣和檢測準確性良好。ZHANG等[4]利用小波多尺度分析技術,提出了一種對多紋理車輪胎圖像的缺陷測試方法,該方法通過應用缺陷邊界檢測模型,可以有效區分缺陷與背景紋理并達到實時檢測的目的。URBONAS等[5]提出一種使用快速區域卷積神經網絡(faster region-convolutional neural network,faster R-CNN)對木材表面缺陷進行定位和分類檢測系統,使木板材表面缺陷準確率達到96.1%,驗證了深度學習算法可以應用于實木板材缺陷檢測中的可行性。SHI等[6]使用多通道掩碼和掩膜區域卷積神經網絡對缺陷進行了分類和確定,分類精度超過0.987,極大提高了缺陷定位的速度和準確性。方葉祥等[7]在金屬表面的缺陷研究中使用了改進的YOLOv3算法,主要改進包括使用直方圖均衡化對圖像進行預處理﹐使用數據增強方法模擬現實工作環境以及優化損失函數來提高模型對表面缺陷分類的準確性。劉洋[8]為了提高金屬表面瑕疵檢測的速度,提出了基于Tiny-YOLOv3的R-Tiny-YOLOv3算法,該算法加入了殘差網絡以及空間金字塔池化SPP模塊最后選擇CIOU作為損失函數,該算法對金屬表面瑕疵檢測精度達到71.5%,檢測速度達到39.8 fps,能夠滿足金屬工件的實時檢測需求。
以上研究以不同的方式改進了每種缺陷檢測模型的性能,但是針對金屬軸件表面獨特的缺陷缺乏針對性的處理,特別是軸件表面小目標缺陷以及多目標缺陷和不完整軸件的識別和處理能力不足,這導致了缺陷檢測精度低和識別種類不全面,整體檢測模型不理想。針對以上問題,本文提出了一種基于改進YOLOv5的目標軸件表面缺陷的檢測算法,本實驗首先將采集到的目標軸件數據圖像進行數據增強與擴容,使用labelimg工具分類標注,再將標注好的數據圖像導入到已經優化完成的YOLOv5的網絡模型進行訓練,獲取訓練完成后的的權重數據模型,最后采集需要檢測的目標軸件圖像,并進行預測與分析。
1 數據預處理
1.1 圖像數據集獲取
在生產過程中,由于原材料缺陷、加工方式錯誤、加工人員操作不當等問題,生產完成的軸件會產生表面缺陷的問題,常見表面缺陷有劃痕、凹坑、擦傷3種。同時為解決工業生產中同時檢測多目標缺陷軸件與不完整軸件漏檢與檢測精度低。本文選用實驗軸件為12.5*71三段階梯軸、8*25二段階梯軸、8*20單頭牙軸、6*30雙頭牙軸。使用圖像采集裝置采集標準正常軸件、部分遮擋的正常軸件、具有劃痕缺陷的軸件、具有凹坑缺陷的軸件、具有擦傷缺陷的軸件和具有多種缺陷軸件的圖像,如圖1所示。

圖1 缺陷軸件圖像
圖像采集設備如表1所示。根據軸件缺陷檢測的要求,本文共采集了2417張軸件的原始圖像。

表1 采集設備
1.2 數據增強處理
工業CCD相機采集得到的軸件數據集圖像分辨率較高,而被檢測軸件的尺寸卻遠小于原始圖像,因此本文中采用了切圖的方法來處理原圖,將圖像裁切為640*640的尺寸,并將裁切后的圖像準確定位在缺陷特征的中心。為了深度學習的準確性,還需要對收集到的原始數據圖像進行多種增強處理,擴展數據集,增強模型的泛化能力[9]。其中擴容操作包括上下翻轉、左右翻轉、灰度處理、增強對比度和增大噪聲,以便更好地訓練模型,并將這些處理后的軸件數據圖像加入到數據集中,經過不同處理后的圖像如圖2所示。經過切圖與數據增強處理后的,最終獲得6557張軸件樣本數據。

圖2 數據增強后的圖像
1.3 數據標注
在開始訓練YOLOv5模型前,必須對收集到的數據圖像類型進行標注,本文使用labelimg軟件作為數據集類別標注工具,其中包括4種標注類別,如圖3所示。分別是軸體,類別為0,標簽為axle;劃痕缺陷類別為1,標簽scratch;凹坑缺陷類別為2,標簽為pit;擦傷缺陷類別為3,標簽為bruise。通過labelimg標注后,可以獲得VOC(xml格式)的標注集,但YOLOv5模型訓練必須通過代碼將VOC(xml格式)文件格式轉化為yolo(txt格式)文件格式,并且文件名與圖片名需完全一致。并利用代碼對經過標記的圖像集進行隨機的分類與劃分,將80%的標注圖像作為訓練集,剩余20%的標注圖像則作為測試集。

圖3 標注類別
2 改進的YOLOv5網絡模型
2.1 YOLOv5的網絡模型介紹
YOLOv5的網絡結構分為Input、Backbone、Neck和Prediction四部分[10]。其網絡模型結構如圖4所示。
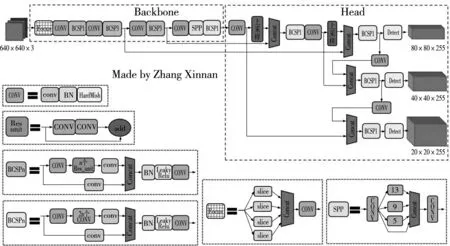
圖4 YOLOv5網絡結構
Input端包含Mosaic數據增強、自適應錨框計算和自適應圖片縮放。Mosaic技術可以實現對4張圖像的快速、準確的分割、精確的編碼,極大地豐富了數據集樣本﹐從而提升網絡魯棒性。YOLOv3、YOLOv4中模擬訓練多個的數據集時,僅依靠一個單獨的程序預測計算初始錨框的值。而YOLOv5則把預測計算原有錨框的任務融合到代碼編譯中,以便在模擬訓練多個訓練集的情況下,實現獲得最佳錨框值。自適應圖片能夠根據實際情況進行調整縮放,有效地減少了推理時計算量,從而加快目標檢測的速度與進程。
Backbone模塊的基礎架構由Focus與CSP架構組成[11]。分辨率為640*640*3的原始圖像經過Focus架構的切片和卷積處理,便可獲得320*320*32的特征圖像(圖5)。CBL模塊一種很有效的卷積計算模型,CSP結構能夠有效地從特征圖中提取出多種有用的信息。并且CSP結構能夠避免梯度信息的重復,其參量占據整個系統參量的絕大部分。YOLOv5將SPP模型改變到了Backbone模型中,擴大感受野,以便更有效的捕獲各種尺度的特征。

圖5 切片操作
在NECK結構部分中,YOLOv5網絡模型使用了Fpn+Pan結構,并采用了CSP二架構,從而達到提升網絡特征融合計算能力的目的。
Prediction還包含了Bounding box損失函數和NMS[12]。并且YOLOv5采用了GIoU_Loss損失值算法,利用非極大數抑制來減少多余的邊框,以便于確定出最終的物體檢測點。
2.2 增加小目標檢測層
鑒于軸件表面缺陷的種類繁多且形態特征復雜,在檢測過程中常有小目標缺陷被漏檢和錯檢,原始的YOLOv5模型,因為小目標缺陷相對都會很小,而YOLOv5的特點之一是下采樣倍數較大,較深的特征圖在模型訓練中往往很難學習到小目標缺陷和不明顯缺陷的特征信息,所以小目標缺陷檢測效果不佳。為了改善這一情況,因此提出增加小目標檢測層,將較淺特征圖與深特征圖拼接后進行檢測。加入小目標檢測層,可以讓網絡更加關注小目標的檢測,以提高檢測的準確性,同時增加小目標檢測頭的錨框,如圖6所示。
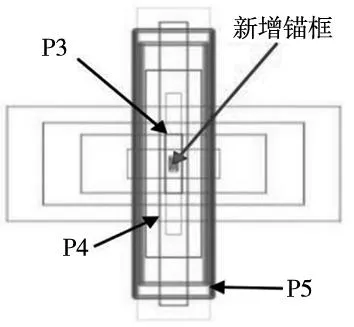
圖6 檢測層對比圖
圖中,P5應用于如輪廓、結構等信息的深層特征圖,適用于大目標的檢測,這一特征圖所用錨框尺度較大;P3應用于包含較多的低層級信息的淺層特征圖,適用于檢測小目標,錨框尺度較小;同理可得,P4則介于兩者尺度之間,應用于檢測中等大小的目標;根據軸件表面缺陷的實際情況,新增加了應用于解決圖像中更小的缺陷目標檢測問題的錨框。圖7為改進后的YOLOv5網絡結構。
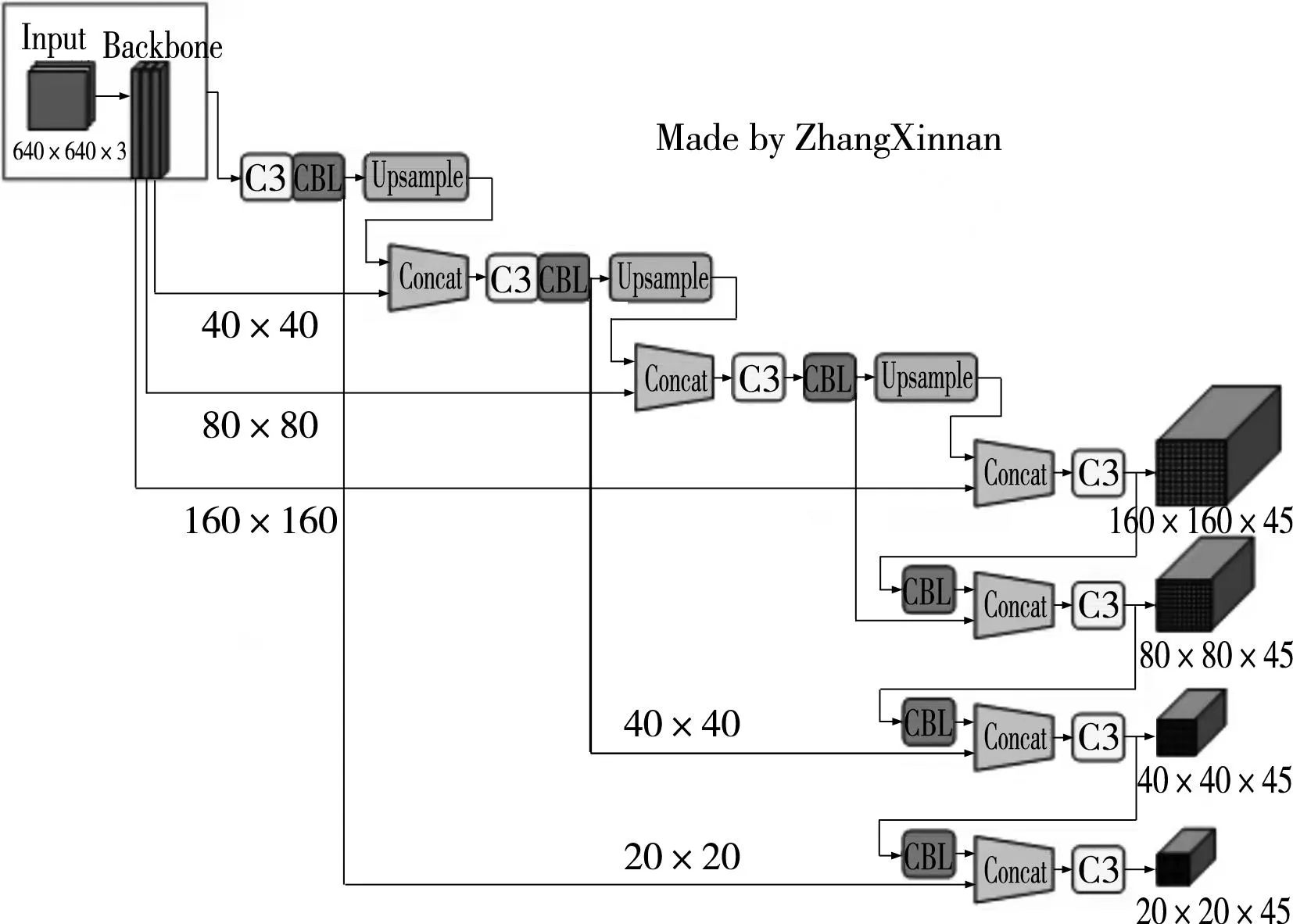
圖7 改進后的YOLOv5網絡結構
3 實驗結果與分析
3.1 實驗設置
在本文的實驗環境中,使用NVIDIA GeForce 1060 GPU進行訓練和測試,CUDA版本是11.3,Pytorch版本是1.10.0,Python版本是3.7.3,環境的詳細信息如表2所示。

表2 環境配置信息
3.2 實驗相關的評價標準
IoU[13],又稱交并比,是一種衡量邊界框準確性的重要度量指標,它反映了detection box(檢測框)與ground truth(真實標簽)的交集和并集的比值,如圖8所示。實際運算中根據IoU的大小判斷是否有效,一般當IoU≥0.5時判斷正確。
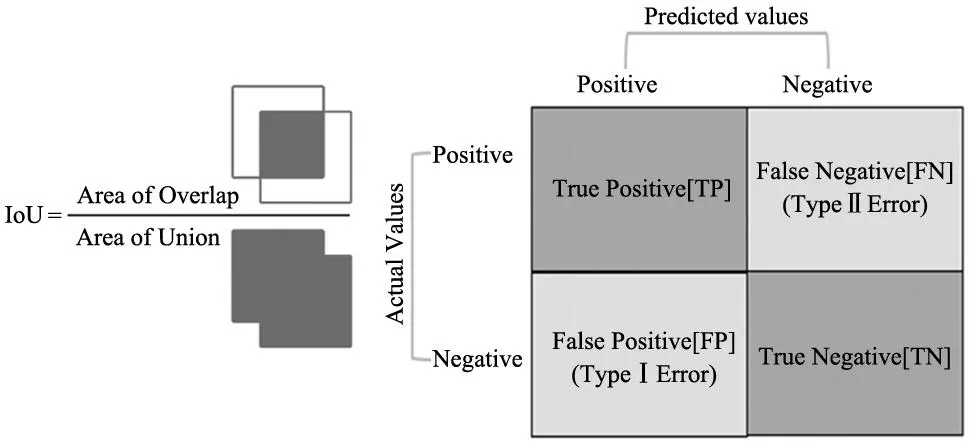
圖8 交并比(IoU)
同時,通過混淆矩陣(圖9)分析可知,可以根據預測的情況與實際結果組合將檢測結果劃分為4種不同的情況:
TP(true positive):根據模型中預測出的框,逐一的向該模型的標注框求交并比,若該標注框產生的最大交并比值超過了先前已經設定好的最大交并比閾值,以及該檢測框對應的標簽值與通過最大交并比計算得到的標注框標簽值相同時,即認定該預測框為true positive。
FP(false positive):反之,預測框與所有的框的交并比均不超過閾值,則認為這些預測框都是錯誤的預測,即視該檢測框為false postive。
TN(true negative):如果標注框的最大交并比達到了預先設置的交并比閾值,而且該預測框的類別和通過最大交并比操作所得到的標注框類別相同。則認為此預測框是true negative。
FN(false negative):反之,如果該預測框對應的標簽和通過交并比操作所得到的標注框標簽并不相同。則認為此預測框是false negative。
根據以上4種情況,可以得到以下3個指標,精度P(Precision)、召回率R(Recall)和準確率A(Accuracy)。并以此獲得綜合評價指標平均精度AP(Average Precision)和平均精度均值mAP(mean AP over calsses),其中AP表示在同一類別下所有檢測結果的平均精度[14],mAP表示所有檢測類別平均精度的均值[15]。
(1)
(2)
(3)
3.3 結果分析
為證明本文改進后的檢測效果,以及驗證具體改進措施起到的作用,本次實驗還設置原YOLOv5,SSD以及Faster-RCNN三組網絡組作為對照組,在相同的訓練環境下,分別使用3組深度學習模型在自建數據集上進行訓練和測試分析,以更加準確地評估改進后YOLOv5模型的性能。其中實驗的總體結果如表3所示,改進后的YOLOv5網絡模型相比較于Faster-RCNN網絡組maP大約有7%提升,相較于SSD網絡組提升了大約9%,與原YOLOv5網絡組的結果進行對比表明,針對于原網絡的改進措施起到了良好的效果,相對于原網絡大約提升了4%的精度。
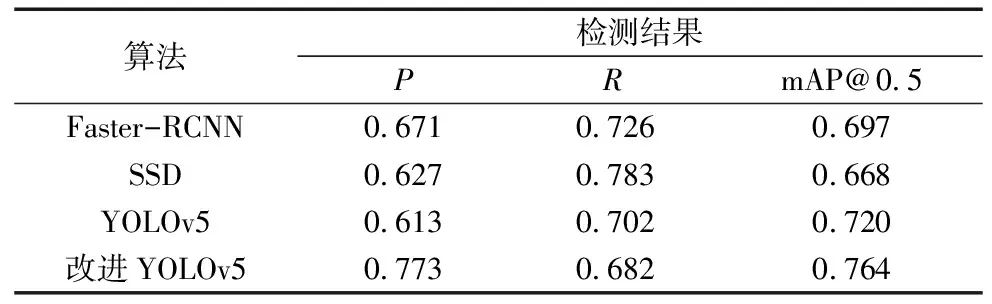
表3 各網絡檢測結果
算法的收斂情況如圖10所示,根據圖中曲線所示,最優權重在改進的YOLOv5網絡第87次迭代時產生。
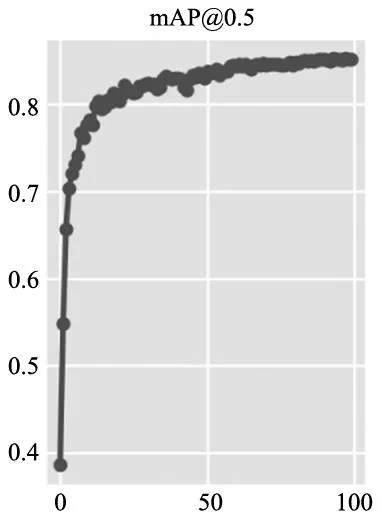
圖10 mAP隨迭代次數變化情況
圖11~圖14展示了部分檢測結果,檢測對象分別為不完整軸體和多目標缺陷的軸體、凹坑缺陷、擦傷缺陷和劃痕缺陷。該模型網絡對明顯的缺陷特征如凹坑和擦傷檢測置信度分別高于0.90和0.86、對不明顯小目標的缺陷特征如劃痕檢測置信度高于0.79,且對于鏡頭下顯示不完整軸體和多目標缺陷軸體的檢測效果較好,能夠滿足實時檢測要求。

圖11 不完整軸體和多目標缺陷的軸體

圖12 凹坑

圖13 擦傷

圖14 劃痕
4 結論
針對軸件表面缺陷檢測的問題,本文提出了一種基于改進的YOLOv5網絡模型對軸件表面缺陷進行檢測,并使用自建數據集進行實驗驗證。
通過增加小目標檢測層來增加對軸件表面小目標缺陷的檢測效果,能夠有效聚焦于目標軸件的檢測,改進的YOLOv5網絡模型相較于原YOLOv5模型在mAP上提升了7%左右;相較于SSD網絡模型,提升了9%左右;與Faster-RCNN網絡組對比,提升了4%左右。
同時通過在自建數據集中引入顯示不完整的軸件與多目標缺陷軸件的數據圖像,對于多目標缺陷軸件檢測與不完整軸件的檢測效果具有顯著提升,使網絡可以更有效完成實際生產中多目標軸件缺陷以及鏡頭下顯示不完整軸件的缺陷檢測的任務。
本文所提及的兩種改進措施,均可以在軸件表面缺陷檢測中有效的提升檢測精度,并且改進的YOLOv5網絡模型同樣適用于其他工業生產場景,特別是存在小目標以及多目標的復雜缺陷檢測領域中。同時改進后的網絡模型依然還有提升空間,需要進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
