基于Kafka的實時數據處理在銀行準時交易中的應用研究
2024-04-18 00:00:00張克
消費電子 2024年2期
【關鍵詞】實時數據處理;Kafka;銀行準時交易
引言
隨著金融行業信息化的不斷深入,銀行準時交易對于金融市場的發展,以及應用場景對于銀行發展的穩定性和信任度顯得尤為重要。然而,銀行準時交易面臨著諸多挑戰,如大量、復雜的交易數據處理、實時性、準確性要求高等。為了解決這些問題,實時數據處理技術成為銀行業的關鍵支撐之一。Kafka作為一種高性能的分布式流處理平臺,在實時數據處理中發揮著重要作用。本研究旨在探討基于Kafka的實時數據處理在銀行準時交易中的應用,并設計實現一個高效可靠的系統。通過對實時數據處理的概述、Kafka的介紹以及銀行準時交易的關鍵問題進行分析,我們將展示實時數據處理在解決銀行準時交易問題中的重要性和優勢。本研究的成果將為金融行業提供一種有效的實時數據處理解決方案,從而提升銀行準時交易的可靠性和效率。
一、 Kafka的介紹
(一)Kafka的歷史和起源
Kafka是一種分布式流處理平臺,最初由LinkedIn開發并于2011年開源。它的起源可以追溯到LinkedIn早期的架構需求,他們面臨大規模實時數據處理和消息傳遞的挑戰。在此背景下,LinkedIn團隊開發了Kafka,旨在構建一個高性能、可擴展且可靠的消息系統,以滿足其快速增長的數據處理需求[1]。Kafka的設計目標包括高吞吐量、低延遲、數據持久化和可水平擴展性。它采用了基于發布-訂閱模式的消息傳遞機制,允許多個生產者將數據寫入Kafka集群,并允許多個消費者從不同分區讀取數據。Kafka通過將消息分區存儲在多個機器上,實現了高吞吐量和可擴展性。Kafka使用日志的方式將消息持久化存儲[2],并且提供了靈活的消息保留策略,可以根據時間或大小等條件進行配置。
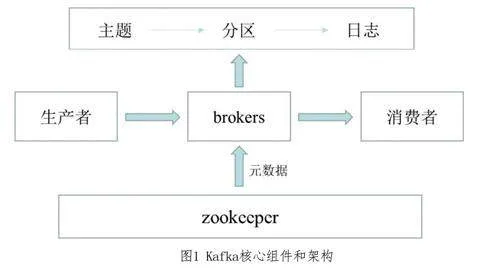
(二)Kafka的核心組件和架構
Kafka的核心組件包括Producer(生產者)、Broker(中間件)、Consumer(消費者)以及Zookeeper(協調器)。它的架構采用了分布式的設計,由多個機器組成的集群運行,實現高吞吐量和可靠性。Producer將數據分為多個主題和分區進行發布,Broker負責存儲和轉發消息,Consumer從Broker中讀取消息進行消費, Zookeeper用于管理和協調集群的配置和狀態。這種組件和架構的設計為Kafka提供了強大的性能和可伸縮性,滿足了大規模數據處理的需求。
(三)Kafka在實時數據處理中的應用案例
Kafka在實時數據處理中有廣泛的應用案例[3]。例如,金融行業可以使用Kafka來處理實時交易數據,為數據需求方提供準實時數據服務。電商行業可以利用Kafka實時處理用戶行為數據,用于個性化推薦和實時監控。物聯網領域可以使用Kafka進行實時數據流處理,對設備數據進行實時分析和響應。Kafka還可以在大數據處理中用作消息隊列和數據管道,實現實時數據集成和流式處理[4]。通過這些應用案例,Kafka為實時數據處理提供了高性能和可靠性的解決方案。
二、銀行準時交易的關鍵問題
(一) 銀行交易的流程和要求
銀行準時交易面臨著一些關鍵問題。首先,銀行交易涉及復雜的流程和要求。從客戶發起交易到最終結算,需要經過多個環節,包括交易驗證、資金轉移和賬務處理等。銀行對交易的要求包括確保交易的準確性、安全性和及時性,同時需要滿足監管要求和合規性。其次,銀行交易需要考慮交易量的增長和擴展性。隨著數字化和全球化的發展,銀行處理的交易量不斷增加,需要應對高并發和大規模交易的挑戰。銀行系統需要具備高吞吐量和可擴展性,以應對交易壓力和未來業務量的增長。此外,銀行交易還需要考慮實時性和穩定性。現代金融市場要求交易立即得到處理和確認,同時必須確保交易系統的穩定性和可靠性。任何交易延遲或系統故障都可能導致金融損失和信譽風險。針對這些問題,銀行需要建立高效的交易系統和架構,利用技術手段如分布式流處理平臺(如Kafka)來實現實時數據處理、高可靠性和可擴展性,以滿足準時交易的要求,并確保系統的穩定運行。
(二)銀行準時交易中可能遇到的問題和挑戰
銀行準時交易面臨各種問題和挑戰。其中之一是交易延遲,可能由于系統故障、網絡擁堵或處理復雜交易流程導致。另一個挑戰是交易風險,包括非法交易、欺詐風險和數據泄露等。此外,監管合規性要求也是一個挑戰,銀行需要確保交易符合相關法規和規定。為解決這些問題,銀行需要投資于高速網絡、強大的系統基礎設施和多層安全措施,同時采用智能技術如人工智能和機器學習來監測和預防潛在風險。此外,銀行還需應對不斷變化的市場需求和技術進步帶來的挑戰。新的支付方式和金融科技創新不斷涌現,銀行需要快速適應并整合這些新技術,以提供更便捷、安全和高效的數據服務體驗。同時,數據的爆炸式增長也給銀行帶來了存儲和處理的壓力,銀行需要投資和優化大數據處理能力,以實現快速的數據分析和決策。應對這些問題和挑戰,銀行需要持續創新和調整,保持競爭力和可持續發展。
(三)實時數據處理在解決準時交易問題中的作用和優勢
實時數據處理在解決銀行準時交易問題中發揮著關鍵作用和獨特優勢。首先,實時數據處理允許銀行從多個數據源(如交易系統、市場數據)獲取實時數據,以快速準確地進行交易驗證和處理。這有助于提高交易的效率和及時性。其次,實時數據處理能夠幫助銀行實時監控交易風險并采取相應措施。通過實時數據分析和監測,銀行可以及時識別和阻止潛在的欺詐活動,降低交易風險,保護客戶和銀行的利益。此外,實時數據處理還能提供數據的可追溯性和透明度,使銀行能夠更好地滿足監管合規性要求。實時數據處理能夠記錄和存儲交易數據的完整歷史,為監管機構的審查提供可信的數據來源。最后,實時數據處理還可以支持銀行進行實時決策和個性化服務。通過實時數據分析和機器學習算法,銀行可以為客戶提供個性化的金融產品和服務,并實時響應市場變化。
三、基于Kafka的實時數據處理系統設計與實現
(一)系統架構設計和工作流程
基于Kafka的實時數據處理系統采用分布式架構,包括生產者、Kafka集群和消費者。生產者發送實時數據到Kafka集群,消費者從主題中獲取數據進行實時處理。系統設計需考慮數據可靠性和容錯能力,以實現高可靠性、高吞吐量的實時數據處理。系統架構中的生產者將實時數據發送到Kafka集群,消費者從主題中獲取并實時處理數據。Kafka集群作為分布式消息隊列,確保數據的高可靠性和高吞吐量。系統設計需要考慮數據可靠性、容錯性和水平擴展,以滿足實時數據處理的需求。
(二)數據管道的構建和管理
在數據管道的構建和管理中,需要考慮數據的流動和轉換。可以使用ETL工具或自定義數據流管道進行數據的提取、轉換和加載。同時,監控和管理數據管道的運行狀態,確保數據的可靠傳輸和處理,并進行故障排查和性能優化。在構建和管理數據管道時,還需要注意數據的安全性和一致性。使用合適的數據轉換和清洗技術,確保數據質量和一致性。另外,加密和訪問控制等安全措施也需要考慮,以保護數據的機密性和完整性。定期備份和監控數據管道的運行狀態,以及及時處理異常情況,是構建可靠數據管道的重要步驟。
(三)實時數據處理的算法和模型選取
在實時數據處理中,選擇適當的算法和模型對數據進行處理至關重要。常用的實時數據處理算法包括流式聚合、滑動窗口、流式機器學習等。對于流式聚合,可以使用基于哈希的分布式聚合算法,實現快速且可擴展的數據聚合操作。對于滑動窗口,可以使用時間窗口或計數窗口,對數據進行分組和統計分析。流式機器學習算法,如在線學習和增量學習,可用于持續更新模型以適應新數據。根據具體場景需求,選擇合適的算法和模型,能有效提升實時數據處理的準確性和效率。
(四)系統性能優化和可靠性保證
在實時數據處理系統中,性能優化和可靠性保證是至關重要的。首先,需要考慮系統的水平擴展和負載均衡,以應對高并發和大規模數據處理的需求。使用分布式計算和存儲技術,如Spark、Hadoop和Kafka,可以實現數據的分布式處理和存儲,提高系統的處理能力和容錯性。其次,優化數據處理流程和算法,通過合理的并行計算、內存管理和數據壓縮等手段,提高系統的處理效率和資源利用率。同時,建立監控和告警系統,實時監測系統的運行狀態,發現問題并及時做出相應的響應和調整。對于可靠性保證,可以采用數據備份和冗余技術,確保數據的持久性和容災能力。此外,實施災備方案和自動故障轉移機制,能夠在故障發生時快速恢復系統的運行。定期進行性能測試和壓力測試,及時發現和解決系統瓶頸和性能問題,提升系統的可擴展性和穩定性。綜上所述,通過系統性能優化和可靠性保證的措施,可以提供高效、穩定和可靠的實時數據處理服務。
總結
本文基于Kafka的實時數據處理在銀行準時交易中的應用進行了深入探討。通過對實時數據處理的概念、Kafka的核心組件和架構的介紹,以及銀行準時交易面臨的問題和挑戰的分析,我們發現實時數據處理在解決準時交易問題中具有重要作用和優勢。同時,本研究還提出了基于Kafka的實時數據處理系統設計與實現的方案,包括系統架構、數據管道構建、算法和模型選取以及性能優化和可靠性保證。通過這些工作,我們為金融行業提供了一個高效可靠的實時數據處理解決方案,有望提升銀行準時交易的效率和可靠性,進一步推動金融市場的發展和穩定。
