干擾攻擊下基于MAPPO的電視頻譜資源分配研究
2024-04-28 12:28:32劉明軒
電視技術 2024年3期
趙 越,楊 亮,劉明軒
(福州大學 電氣工程與自動化學院,福建 福州 350108)
0 引言
隨著通信技術的發展,電視數量指數逐漸增長,有限的電視頻譜資源難以滿足現階段的頻譜需求。認知無線電(Cognitive Radio,CR)技術可以解決設備增長和頻譜利用率低之間的矛盾[1]。此外,許多無線網絡設備電池容量小,無法滿足設備長時間通信,傳統的電池方案不能很好地解決此類問題。射頻能量采集(Energy Harvesting,EH)技術可以從周圍的射頻信號中獲取電磁能量,并將其轉換成電能存儲到電池中,延長電池壽命[2]。因此,基于能量采集的認知無線(Energy Harvesting-Cognitive Radio,EH-CR)網絡在現階段無線通信具有很大的優勢和潛力。
但是,EH-CR網絡因其具有開放性,容易受到干擾攻擊。連續的干擾信號會使信噪比惡化,導致網絡通信中斷,因此網絡資源分配成為一個關鍵問題。WANG等[3]通過將抗干擾策略建模為馬爾可夫博弈,設計了可以避免干擾信號的最佳通信策略,但由于節點的發射功率保持固定,在資源有限的EH-CR網絡中實現該策略比較困難。CHANG等[4]研究了分布式網絡的動態頻譜接入策略,利用遞歸神經網絡和儲層計算來實現深度強化學習(Deep Reinforcement Learning,DRL),使次用戶(Secondary Users,SUs)根據當前和過去的信道感知結果,獨立做出接入信道的決策,但沒有考慮受到干擾攻擊的情況。本文研究了干擾攻擊下EH-CR網絡中SUs的聯合信道和功率分配策略,旨在最大化SUs的平均吞吐量,同時避免了SUs發射功率保持恒定的缺陷。
1 系統模型
建立一個EH-CR網絡通信模型,如圖1所示。模型中包含N個主用戶(Primary Users,PUs)和1個主用戶基站(Primary user Base Station,PBS);M對SUs包含發射機、接收機以及R個惡意用戶(Malicious Users,MUs),MUs通過一定的攻擊策略干擾SUs的通信。考慮該網絡共有N個無線信道,PUs具有信道優先使用權,但只允許在相應的信道上進行傳輸,PUs信道狀態轉換遵循兩維馬爾可夫鏈。SUs發射機采用混合方式接入空閑頻譜,定義SUi為第i個SUs,如果SUi感知到信道n空閑,則以Interwave方式接入,否則以Underlay方式接入。本文假設SUs可以完美感知,用Ii,n∈{0(空閑),1(占用)}表示SUi在t時隙感知到的信道n的狀態,Ii,n=0表示PU不存在,信道空閑,Ii,n=1表示PU存在,信道繁忙。則時隙t時SUs的頻譜感知集合S(t)={S1(t),S2(t),…,SM(t)},其中Si(t)=[Ii,1,Ii,2,…,Ii,N]。
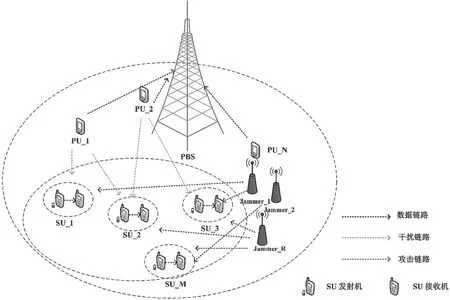
圖1 干擾攻擊下EH-CR網絡模型
1.1 信道模型
SUj表示第j個SUs,PUn表示第n個PUs,MUr表示第r個MUs,用dii表示SUi發射機和接收機之間的距離,dji表示SUj發射機對SUi接收機的干擾距離,dni和dri分別表示PUn和MUr對SUi接收機的干擾距離,其中i∈{1,2,…,M},j∈{1,2,…,M}且j≠i,n∈{1,2,…,N},r∈{1,2,…,R}。本文采用WINNER II信道模型計算傳輸過程中的路徑損耗[5],同時采用Rician模型推導出信道模型,描述為g=|h|2,因此可以得到gii、gji、gni和gki,它們分別代表SUi、SUj發射機、PUn、MUr與SUi接收機之間的信道增益,則SUs在時隙t的信道增益集合表示為G(t)={G1(t),G2(t),…,GM(t)},其中Gi(t)=[gii,gji,gni,gri]。
1.2 能量模型
每對SUs均具備EH功能,但不能同時在采集和傳輸狀態工作,當前采集到的能量存儲到電池中并在后續的時隙使用。在時隙開始階段,SUi獨立感知N個信道,由于頻譜資源的限制,每個時隙只能選擇一個信道接入且每個信道只允許接入一個SUs,當有多個SUs接入時會造成通訊失敗。用fi(t)和Pi(t)分別表示SUi發射機在時隙t選擇接入的信道及其功率,設SUi最大接入功率為Pmax,則fi(t)∈(0,N],Pi(t)∈[0,Pmax]。用Hi(t)作為SUi的工作狀態指示器,Hi(t)∈{1,0},1表示頻譜接入,0表示能量采集。感知結束后,SUi根據觀測信息調節接入動作和發射功率,若Pi(t)>0,表示SUi采取接入動作,此時Hi(t)=1;若Pi(t)=0,表示SUi采取能量采集動作,此時Hi(t)=0。
SUs的時隙結構圖如圖2所示。圖2中SUs的單個時隙長度為T,Ts為總時隙數,τ為頻譜感知時間,T-τ是數據傳輸或能量采集所消耗的時間,SUi感知時間τ和消耗的能量eτ是固定的,不存在其他消耗。在工作時,SUs可以從PUs和MUs以及其他SUs處獲取射頻能量。設PUs的發射功率為Pp,則t時隙SUi采集到的射頻能量Ei(t)表示為
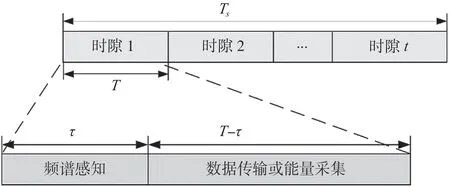
圖2 SUs的時隙結構圖
式中:η是能量轉換效率,Pi(t)是SUj的發射功率,N(t)是PUs占用信道數量,Pr(t)是MUr的干擾功率。
在電池更新階段,只有感知和傳輸階段消耗能量。設SUs電池的最大容量為Bmax,Bi(t)表示SUi的電池狀態,Bi(t)∈[0,Bmax],則SUs的電池狀態集合B(t)={B1(t),B2(t),…,BM(t)}。基于此,可以得到SUi的電池狀態更新表達式,即為
1.3 攻擊模型
MUr在時隙開始選擇一個攻擊信道,表示為lr(t),Pr(t)為其干擾功率,Pr(t)∈[0,P jmax],其中P jmax表示最大干擾功率。同時,用Jr(t)=∈{0,1}表示干擾狀態,當Jr(t)=0,表示MUr干擾失敗,信道上無SUs活動;當Jr(t)=1,表示MUr干擾成功。
本文考慮了2種干擾模式:一是隨機干擾,即MUr在時隙開始時隨機選擇一個信道進行干擾;二是反應掃描干擾。反應掃描干擾在文獻[6]中被提出,干擾機在時隙開始時選擇空閑信道進行干擾,并觀察該信道是否存在SUs活動,若存在則持續干擾直至時隙結束[6]。如果沒有檢測到SUs的活動,若當前掃描周期結束則會開始新的掃描周期,否則會繼續干擾下一個信道直至掃描周期結束。
1.4 問題陳述
基于以上模型分析,將SUi接收機在時隙t接收到的信號與干擾加噪聲比(Signal to Interference plus Noise Ratio,SINR)χi(t)的表達式為
式中:Pi(t)是SUi的發射功率,n是噪聲功率。
在時隙t處,SUs網絡瞬時總吞吐量r(t)可以用采樣公式表示,數學表達式為
式中:W是信道帶寬。
本文的目的是實現干擾攻擊下的SUs的最大平均吞吐量。優化問題可以表示為
式中:第一個條件表示接收機接收到的信號的SINR必須大于最低SINR要求,第二個條件表示電池剩余能量必須不得小于傳輸消耗的能量,第三個條件表示當PUs占用信道時,SUs的發射功率必須小于閾值Pthreshold,以防止對PUs造成干擾,第四個條件表示SUs之間不能選擇同一信道進行傳輸,以避免沖突,第五個條件表示SUs的信道和功率值不能超過限定范圍。
2 干擾攻擊下基于多智能體的資源分配
考慮到優化問題之間的耦合關系,本文設計了一種高效、簡單的基于多智能體近端策略優化(Multi-Agent Proximal Policy Optimization,MAPPO)的資源分配方法。每個SU都是一個獨立的Agent,共同目標是使干擾攻擊下SUs的平均吞吐量最大化。這種多Agent任務被稱作部分可觀測馬爾科夫決策(Partially Observable Markov Decision Process,POMDP),由{S,A,O,R,P}五元組構成。其中,S表示環境中的全局狀態空間,A={at1,at2,…,atM}表示Agents動作集合,表示Agents觀測集合,R={Rt1,Rt2,…,RtM}表示Agents獎勵集合,P表示狀態轉移概率函數。多Agent任務中基本元素的詳細解釋如下。
第一,Agents。每個SU都是一個Agent,Agents僅根據觀測信息獨立做出動作決策,與環境進行交互。
第二,狀態空間S。S由Agents的頻譜感知集合S(t)、信道增益集合G(t)以及電池狀態集合B(t)組成,表達式為
第三,局部觀測空間oti。oti表示SUi在t時隙的觀測空間,由譜感知集合Si(t)、信道增益集合Gi(t)以及自身電池水平Bi(t)組成,表達式為
第四,動作空間ati。Agent根據觀測做出信道選擇fi(t)和功率分配動作Pi(t),為了符合實際環境和方便,將發射功率平均離散為ζ個等級,即Pi(t)∈[0,Pi,1(t),Pi,2(t),…,Pi,ζ-1(t)],其中Pi,ζ-1(t)=Pmax,則動作空間ati的表達式為
第五,獎勵Rti。Rti是衡量Agents在給定狀態下采取的動作策略的影響。考慮到式(5)的優化問題,對獎勵Rti做出如下設定:當SUi傳輸成功,Rti=ri(t),即Rti為SUi獲得的吞吐量;當SUi遭受攻擊時選擇工作在能量采集模式,則Rti=C,C為固定常數;當SUi干擾PUs或與其他SUs發生沖突時,Rti=-C;其他情況下,SUi獎勵皆為0。
3 基于MAPPO的資源分配設計
MAPPO算法采用Actor-Critic架構,并引入新的裁剪替代函數,避免對目標值進行過度修改,新的裁剪替代損失函數LtCLIP(θ)為[7]
式中:θ為Actor網絡的參數,rt(θ)為新策略與舊策略的比值;為泛化優勢估計(General Advantage Estimation,GAE),clip(·)是裁剪函數,引入該函數的目的是限制rt(θ),ε為截斷因子,ε∈[0,1]。
泛化優勢估計用于估計在狀態s下采取動作a相對于平均動作的優勢,其數學表達式為
式中:δt為t時刻時間差分誤差,γ為折扣因子,λ為學習率,δt+1為t+1時刻時間差分誤差,δTs-1為Ts-1時刻時間差分誤差。
t時刻時間差分誤差的數學表達式為
式中:rt為獎勵,V?(st+1)是t+1時刻Critic網絡的價值函數,V?(st)是t時刻Critic網絡的價值函數,表達式為
Critic網絡的參數用?表示,Critic網絡通過梯度下降方式和損失函數更新,損失函數LtVF(?)的表達式為
式中,y(t)是目標值函數,表示為y(t)=rt+γV?(st+1)。
在MAPPO算法中,損失函數將策略代理項和值函數誤差項相結合,并使用熵加成來增加探索力度,因此總的目標函數LtCLIP+VF+S(θ)可以描述為
式中,c1和c2均為系數,S[πθ](st)為狀態st下策略πθ的熵。
MAPPO框架包含M個Agents,每個Agent執行近端策略優化(Proximal Policy Optimization,PPO)算法,通過可以觀測到全局信息的Critic網絡來指導Actor網絡訓練。Actor網絡的輸入為每個SU的局部觀測,輸出的是一個與動作空間中每個動作相對應的概率列表,這些概率構成了一個分布,因此可以對動作進行采樣。Critic網絡可以評估Actor網絡采取的行動是否符合預期反饋,在訓練完成后得到最優策略,在執行階段各Agents之間無須進行內部信息交換,也不需要進行隨機探索,根據自己的局部觀測即可采取最優動作,具體算法流程如下。
初始化:初始化EH-CR網絡中所有參數,初始化MAPPO參數,設置學習率lr,初始化經驗池D
4 仿真結果與分析
本節驗證所提方法的有效性。考慮到EH-CR網絡存在10個PUs、10個正交信道、4對SUs以及3個MUs,PUs的狀態轉換概率為0.6,PUs、SUs、MUs的位置隨機分布在200 m×200 m的區域內,SUs的接收機和發射機的距離為40~60 m。本文將SUs發射機功率平均離散化為8個等級,Pmax=24 mW,除特殊說明外,其余模擬參數設置如表2所示。
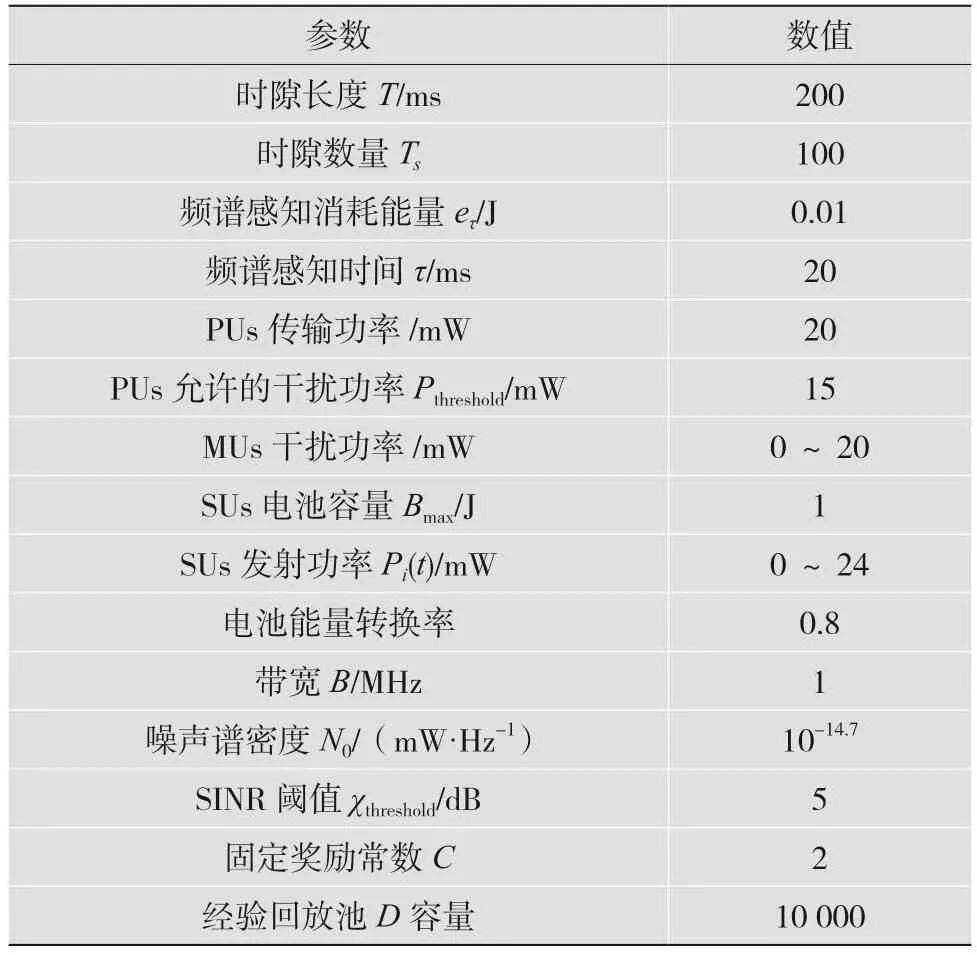
表2 模擬參數設置
為驗證提出的方法在資源分配方面的有效性,將本文方法與文獻[4]中的MADQN-RC方法進行對比。在文獻[4]中,CHANG等將儲層計算引入深度Q網絡(Deep Q-Network,DQN)算法,用RC網絡代替Q網絡,解決梯度消失和爆炸問題。其中,RC網絡的神經元數目為256,學習率為0.000 1,激活函數為ReLU(·),使用Adam優化器迭代訓練更新網絡權重,迭代次數為3 000次。
本文所提MAPPO方法使用Adam優化器迭代訓練更新網絡權重,Actor和Critic網絡學習率設置為0.000 1和0.000 5,截斷因子ε=0.2,折扣因子γ=0.9。具體仿真結果如下。
圖3為兩種方法在隨機干擾和反應掃描干擾這兩種不同干擾攻擊情況下的表現情況,時隙數量Ts=100,Bmax=1 J。在不同情況下,兩種方法的平均吞吐量雖然因受到動態環境特征和策略探索的影響而出現波動,但都隨著迭代次數的增加而趨于穩定,證明了兩種方法的收斂性,本文方法在迭代了1 000次左右進入收斂狀態,比文獻[4]方法快了2.4倍。這是因為本文方法采用近端策略優化,使得更新步幅更加平穩,有助于網絡加速收斂。相比之下,文獻[4]方法是基于Q值的更新方法,需要通過Q值的估計來更新策略,會導致訓練不穩定和慢收斂。
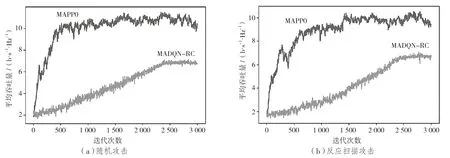
圖3 不同干擾攻擊下兩種方法的平均吞吐量
由圖3可以看出,無論哪種干擾情況,本文方法比文獻[4]方法具有更高的平均吞吐量。在隨機干擾下,本文方法的平均吞吐量比文獻[4]方法提高了62.15%;在反應掃描干擾下,盡管本文方法的平均吞吐量下降了26.19%,但仍比文獻[4]方法提高了52.66%。
通過與傳統接入模式比較來評估混合頻譜接入模式的性能,結果如圖4所示。在不存在攻擊且算法、時隙和電池容量等相同的情況下,本文采用的模式能夠獲得最高的吞吐量,比底層模式提高了14.95%,比交織模式提高了34.54%。這是因為在混合頻譜接入模式下,當PUs存在時,SUs可以以限定功率接入信道,否則就以高功率接入信道,以此實現最大的頻譜利用率,使SUs網絡的平均吐量最大。

圖4 不同信道接入模式對比(Ts=100、Bmax=1 J)
通過計算平均吞吐量與平均獎勵的差值來分析本文提出方法的性能,如圖5所示。通過圖5可以看出,在算法收斂前差值為正,表明此時處在迭代學習階段,為了對動作進行充分探索,獲取更大的獎勵,SUs會通過發生碰撞和干擾PUs的動作而遭受懲罰。在充分探索后,無攻擊模式下算法收斂至0,表明獲得的獎勵即為吞吐量,即SUs彼此可以完美避開且不對PUs產生干擾。若SUs在攻擊信道選擇能量采集,會獲得固定獎勵常數,此項是刺激算法能夠更好學習未知的干擾模式,因此在隨機和反應掃描攻擊模型下會出現差值為負的現象。這表明MAPPO算法可以學習到未知干擾模型,在攻擊信道選擇能量采集,避免遭受干擾攻擊。同時,又因為反應掃描比隨機攻擊的攻擊性更強,所以反應掃描攻擊的差值小于隨機攻擊。
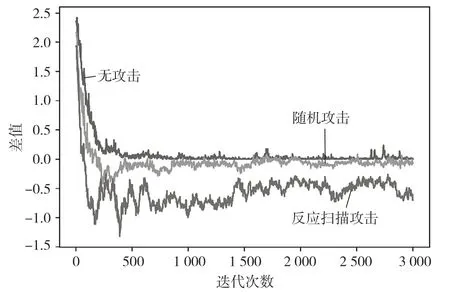
圖5 平均吞吐量與獎勵差值(Ts=100、Bmax=1 J)
5 結語
本文提出了一種干擾攻擊下聯合信道和功率分配以實現EH-CR網絡中SUs用戶平均吞吐量最大化的方法。利用馬爾科夫決策過程(Markov decision process,MDP)和DRL工具將這個NPhard問題轉化為多智能體深度強化學習問題,提出了一種基于MAPPO的聯合信道和功率的資源分配方法,并在仿真中使用平均吞吐量和迭代過程來評估所提方法的性能。模擬仿真結果表明,所提方法在隨機和反應掃描干擾情況下,可將SUs的平均吞吐量分別提高62.15%和52.66%。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
兒童故事畫報(2019年5期)2019-05-26 14:26:14
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
