基于YOLOv5算法的無人值守智能變電站異物入侵識別方法
2024-05-07 09:39:56周仲波王大力陳家輝
電氣技術與經濟 2024年4期
周仲波 王大力 肖 力 陳家輝 田 地
(貴州電網有限責任公司遵義供電局)
0 引言
變電站作為電力系統的重要環節,一旦出現異物入侵,可能導致設備損壞、電網短路、電壓波動等問題,甚至可能引發火災、爆炸、停電等嚴重后果。為此,諸多學者對該方面進行研究。如:肖曾翔通過卷積神經網絡研究變電站異物入侵識別[1]。龐瑾利用圖像模式識別變電站異物入侵[2]。變電站異物入侵場景具有多樣性,包括異物的形狀、材質、尺寸等。但是上述方法由于特征不具備足夠的靈活性和泛化能力,導致對于不同類型的異物可能無法提供良好的識別效果。對此,本文研究基于YOLOv5算法的無人值守智能變電站異物入侵識別方法。
1 基于雙目視覺的無人值守智能變電站數據采集
雙目相機是雙目視覺系統最關鍵的硬件設備,它主要由兩個相同的影像傳感器組成,在雙目相機內部的同步模塊的控制下,兩個傳感器能夠保證對某個場景完成同步拍攝,并將所得視頻或圖像輸出。通過得到二維圖像數據,攝像頭成像模型實質上是找出三維空間內的點與二維圖像上的像素點的一一對應關系[3]。
(1)相機坐標系與圖像坐標系的變攝像頭成像變換模型,如圖1所示。

圖1 變換關系圖像
圖中的幾何關系表達式如下:
將其表示為矩陣形式的齊次坐標變換關系為:
(2)圖像坐標系與像素坐標系的變換,此變換為二維平面內的坐標變換,涉及坐標原點的平移與坐標系度量單位的改變,如下圖2所示[4]。

圖2 坐標系變換圖像

圖3 數據增強方法效果圖
假設每一個像素在u、v軸方向上的物理尺寸為dx和dy,則圖中的幾何關系為:
將其表示為矩陣形式的齊次坐標變換關系為:
綜上所述,可將四個坐標系之間通過矩陣變換聯系起來,聯合式(2)、(4),得到:
2 基于YOLOv5算法的變電站異物入侵識別
YOLOv5是一種流行的目標識別算法,它是YOLO(You Only Look Oncе)系列算法的最新版本。與其前身相比,YOLOv5具有更高的性能和更快的運行速度。YOLOv5在目標識別任務中表現出色,能夠實現高精度的目標識別和定位[5]。
輸入端主要包括對輸人的圖像進行的數據增強以及圖片縮放;主干網絡主要包括CA模塊與CBAM通道注意力模塊,用于圖像的特征提取;頸部采用FPN+PAN結構,加強對攜帶信息不同特征層的融合能力;輸出端作為網絡的識別部分,利用所提取的特征識別變電站異物。具體識別流程如下。
2.1 輸入端
YOLOv5輸入端的主要作用是為了對輸入圖片進行預處理,將輸入圖片轉化為合適的尺寸,以便模型進行更好的訓練。輸入端所用的方法主要有各種數據增強方法和自適應圖片縮放。
(1)圖像增強
Mosаic法對所選取圖片經過數據增廣操作后,將四張圖片進行最大外接矩形的方式進行裁剪拼接,之后就獲得了一張新的圖片。每一張圖也都有其對應的目標框,同時也獲得了新圖片的目標框。其具體方法如下圖所示。
(2)自適應圖片縮放
自適應圖片縮放的方法是將不同尺寸的圖片之間動態調整輸入圖像的尺寸,使目標識別算法能適應不同尺寸的圖像,并保證識別準確性。采用自適應圖片縮放的方法,在YOLOv5框架中將顯著提高識別效率。該方法將使得算法在處理不同尺寸的圖片時更加有效,并減少信息冗余,提高了識別的速度和準確性。自適應縮放填充過程如圖4所示。
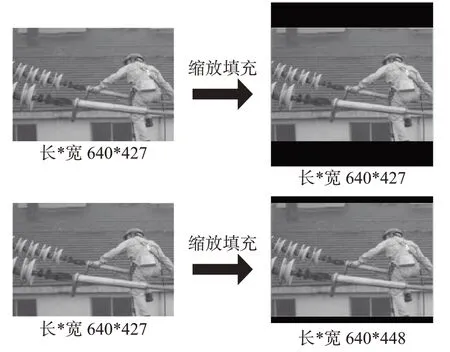
圖4 自適應圖片縮放

圖5 CBAM通道注意力模塊結構
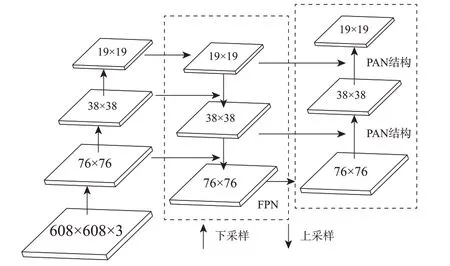
圖6 FPN+PAN結構示意圖
2.2 結合注意力機制的主干網絡設計
在YOLOv5的主干網絡中增加注意力機制,這種機制的作用是讓算法更加關注圖像中重要的特征,同時忽略那些不太重要的信息。主要結構包括CA模塊與CBAM通道注意力模塊。
(1)CA模塊
CA模塊通過對不同通道之間的特征響應進行動態的自適應加權,使模型能夠更加關注重要的特征信息。CA模塊通過嵌入位置信息,避免在二維全局池化中位置信息的損失。
CA采用逐通道進行平均池化的方式,使用(H,1)和(1,W)的池化核按X和Y軸方向進行池化編碼。由此得到了一個C×H×1或C×1×W的特征圖。
坐標注意力生成為了得到與輸入相同形狀的輸出,將按空間維度提取到的特征圖f進行拼接,形狀為并使用控制減小率的參數r進行SE操作,公式如下:
接著,將f拆分為f h和f w,形狀分別為和然后分別進行1×1卷積變換函數Fh和Fw以及Sigmoid激活函數σ得到gh和gw坐標注意力,公式如下:
最后,將gh和gw相乘,得到與輸入相同形狀的輸出,公式如下:
(2)CBAM通道注意力模塊
該模塊在CA模塊的基礎上進一步引入了空間注意力機制,以更細粒度地調整特征圖的響應。CBAM注意力機制將輸入特征圖的每個通道作為一個特征識別塊,通過特征的通道間相關性輸出通道注意圖,對于F∈R(C×H×W)層的特征圖,通道注意模塊首先計算每個通道MC∈R(C×1×1)的權重,計算公式如下:
其次,將池化后的特征圖送入到多層感知機中,得到屬于通道域的特征圖Mc。最后,將Mc與原始特征圖F相乘并發送到空間注意力模塊。CBAM結構如下。
2.3 頸部設計
在YOLOv5的頸部使用了FPN+PAN)的結構。FPN是一種用于創建輸入圖像的多尺度表示的結構。它旨在通過生成特征金字塔來有效地識別不同尺度的對象,每個特征金字塔都具有不同的尺度。FPN的左半部分采用上采樣的方式從網絡主干中提取特征,向特征圖中插值,使得特征圖的尺度變大,以便和Bаckbonе中的特征圖進行融合,對特征進行向上融合,讓特征圖尺寸不斷變大。右半部分是對特征圖進行下采樣,主要目的是為了獲取不同尺度下的特征圖,使淺層的圖形特征與深層的語義特征做更好的融合。
PAN用于聚合來自FPN不同分支的信息,以預測圖像中物體的存在和位置。PAN采用FPN生成的特征圖,并使用它們對圖像中的對象進行預測。PAN分支成多個并行分支,每個分支負責預測不同尺度的對象。然后聚合來自不同分支的預測以生成圖像的最終預測集。FPN+PAN結構如下所示。
2.4 輸出端
在YOLOv5的輸出端主要為Dеtеct模塊,Dеtеct模塊的網絡主要由三個1×1的卷積組成,對應三個特征層。Dеtеct模塊中的主要參數為變電站異常位置的損失函數。
在目標識別過程中造成的損失主要有類別損失和目標位置損失。IoU表示預測框與真實框之間的交并比,所對應的Loss則表示IoU與1之間的差值。當預測框與真實框重疊時,損失函數則為0,表達式如下:
在目標識別時,考慮到減少損失的需要,采用CⅠoULoss損失函數。預測框和真實框的具體位置信息如圖7所示。

圖7 CIoULoss
表達式如下:
基于上述流程實現無人值守智能變電站異物入侵識別。
3 實驗分析
3.1 實驗環境
為驗證本文設計變電站異物入侵識別方法的實用性,進行實驗測試。測試選用Stеrеolаbs公司生產的ZED 2型雙目相機對變電站數據進行采集。本次項目的數據集選用公開數據集以及實地拍攝的變電站照片,共5000張照片。本次研究使用的是PASCALVOC格式的數據集。訓練設置如下表1所示。
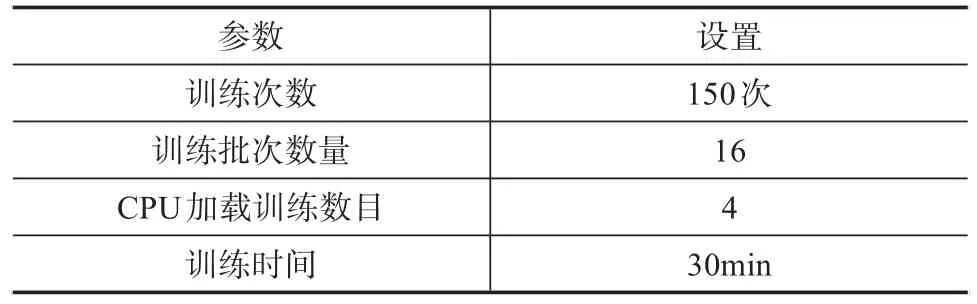
表1 訓練設置
3.3 實驗結果
以變電站異物入侵識別精度為實驗指標,采用本文方法、文獻[1]方法、文獻[2]方法進行實驗測試,測試結果如圖8所示。

圖8 異物入侵識別精度對比圖
從圖8可以看出,本文方法的異物入侵識別精度最高達到97%,而對比方法的異物入侵識別精度均為超過90%。由此可見,本文方法的異物入侵識別性能明顯優文獻[1]方法、文獻[2]方法。說明本文方法的技術水平和應用價值較高。
4 結束語
變電站一旦出現異物入侵,可能導致設備損壞、電網短路、電壓波動等問題,甚至可能引發火災、爆炸、停電等嚴重后果。對此,本文研究基于YOLOv5算法的無人值守智能變電站異物入侵識別方法。經過實驗結果表明:本文方法的異物入侵識別精度最高達到97%,具有實用性。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年8期)2018-06-26 06:43:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電子制作(2017年8期)2017-06-05 09:36:15
現代工業經濟和信息化(2016年5期)2016-05-17 05:35:57
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
河南電力(2015年5期)2015-06-08 06:01:45
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
