蜻蜓算法優選小麥粉蛋白質近紅外建模校正集
2024-05-20 07:17:00胡云超劉智健黃浩冉王紅鴻吳彩娥熊智新
食品科學 2024年9期
關鍵詞:模型
胡云超,劉智健,汪 瑩,黃浩冉,王紅鴻,吳彩娥,熊智新
(南京林業大學輕工與食品學院,江蘇 南京 210037)
小麥是世界上種植面積最廣、總產量和營養價值最高的糧食作物,提供了人類20%的能量[1]。小麥行業的發展對國家的糧食安全和社會穩定具有重要意義,2022年,國內糧食市場“麥強面弱”格局明顯,產品品質、品牌成為企業贏得小麥粉市場的關鍵[2]。小麥粉中有三大營養素,分別是蛋白質、淀粉和脂類,其中蛋白質(含量約為7%~15%)決定著小麥粉的加工品質和營養品質[3]。小麥粉可根據其蛋白質含量分為高筋粉(大于10.5%)、中筋粉(8.0%~10.5%)和低筋粉(小于8.0%)[4]。小麥粉中蛋白質含量的不同使得小麥粉具有不同的用途,例如高筋粉一般用于制作面包,而點心和菜肴一般使用低筋粉進行制作加工,所以在生產過程中對小麥粉蛋白質含量的快速精確檢測就顯得尤為重要。
近紅外光譜分析技術是21世紀發展起來的一種快速、無損、綠色、可用于在線監測的分析技術,廣泛應用于食品[5]、農業[6]、醫藥[7]、林業[8]等各個領域,隨著科學技術的發展,結合化學計量學的近紅外光譜分析技術在小麥粉蛋白質定量分析中的應用逐漸廣泛[9-11]。近紅外光譜所分析的對象大多是復雜的、未預處理的樣品體系,通常會收集大量的實驗樣本,但這些樣本可能80%以上是重復樣本或無效樣本,因此有必要從中挑選出具有一定代表性的校正樣本代替原始數據集進行建模,提高建模的效率和模型精度,減少數據庫的存儲空間。常用的樣本劃分方法有隨機采樣法、K/S(Kennard/Stone)法、SPXY(sample set partitioning based on joint X-Y distances)法等。隨機采樣法是從樣品集中隨機選擇一定數量的樣品組成校正集[12]。K/S法是以光譜變量間的歐氏距離為基礎,挑選分布范圍廣且代表性強的樣品作為校正集[13-14]。SPXY法是在K/S法的基礎上引入樣品化學值信息,用光譜間距離以及化學值濃度之間的距離選擇代表性樣品[15-16]。由于K/S法和SPXY法以樣本間的距離為標準對樣品集進行劃分,可能會將異常或者不合適的樣本挑選入校正集,進而影響所建模型性能。群智能優化算法是化學計量學方法的重要組成部分,其主要思路是基于對自然生物群體(例如狼群、蟻群、蜻蜓等)生存現象的觀察,將其生存現象量化并應用在數學模型優化中,特點為群個體之間相對獨立,通過更新策略在搜索空間中尋找最優解。群智能優化算法在光譜分析領域中已有許多成功的研究及應用案例,主要應用在特征波長優選及建模方法參數優化等方面。Guo Zhiming等[17]利用近紅外光譜分析技術結合模擬退火、蟻群優化、遺傳算法等群智能優化算法,選擇信息豐富的光譜變量,建立了準確、穩健的綠茶活性成分和抗氧化能力定量分析模型。王仲雨等[18]提出改進鯨魚優化算法并用于近紅外建模過程中的波長選擇,該算法能有效篩選出波長變量并建立玉米脂肪、蛋白質、淀粉和水的預測模型。蜻蜓算法(dragonfly algorithm,DA)作為群智能優化算法的一種,將群體行為的所有可能因素都考慮在內,使其能夠將目標函數快速地收斂在最優解附近,具有良好的全局尋優能力[19-20]。陳勇等[21]采用衰減消退蜻蜓算法優選小麥粉蛋白質近紅外特征波長,篩選出的波長數量少,所建模型穩定性高。Chen Yuanyuan等[22]提出了一種新的基于二進制蜻蜓算法(binary dragonfly algorithm,BDA)的波長選擇方法,針對汽油近紅外光譜數據集選擇有效波長,結果表明基于多BDA和集成學習BDA算法可以提高波長選擇的穩定性。蜻蜓算法在近紅外特征波長優選、建模方法參數優化等方面有著良好的應用性能,但在模型建立過程中優選校正集的應用鮮見報道。本研究采用BDA算法挑選具有代表性的校正集樣品,以迭代過程中BDA選出的校正集建模的交互驗證標準偏差(root mean square error of cross validation,RMSECV)與所建模型對驗證集預測的預測標準偏差(root mean square errors of prediction,RMSEP)之和構建適應度函數,從而在適應度函數構建中引入校正集信息,實現對校正集樣品的優選,提高模型預測的精度,并以NeoSpectra Micro型便攜式近紅外光譜儀所測的小麥粉近紅外光譜和蛋白質數據為例,與傳統的校正集優選算法(K/S法、SPXY法)的預測結果進行對比和分析,探討BDA算法優選小麥粉蛋白質近紅外建模校正集樣品的可行性。
1 材料與方法
1.1 材料
實驗所用樣品為超市購買不同品牌、不同批次的小麥粉,共計160 個樣品,包含低筋粉23 份、中筋粉82 份和高筋粉55 份,收集到的樣本置于保鮮袋內常溫儲存備用,取出小麥粉后于室溫(20~23 ℃)條件下采集光譜。
1.2 儀器與設備
NeoSpectra Micro型便攜式近紅外光譜儀 埃及Si-ware公司;D200杜馬斯定氮儀 濟南海能儀器股份有限公司。
1.3 方法
1.3.1 光譜采集
NeoSpectra Micro型便攜式近紅外光譜儀的波長范圍為1 350~2 550 nm,波數范圍為7 407~3 922 cm-1,采樣間隔為13.62 cm-1,分辨率為16 cm-1。采集小麥粉樣品的近紅外光譜時,NeoSpectra Micro型便攜式近紅外光譜儀機身采用金屬試管架夾持固定,探頭向下垂直對準深1 cm圓盤樣品池,樣品池頂部與探頭底部相距1 cm,面粉樣品鋪平深1 cm圓盤樣品池,按120°間隔采集得到3 條不同檢測點的光譜,取它們的平均作為該樣品的最終采集光譜,共得到160 個小麥粉的光譜數據。
1.3.2 蛋白質含量測定
小麥粉樣品的蛋白質含量參照GB 5009.5—2016《食品中蛋白質的測定》[23]中的燃燒法測定。
1.3.3 建模與模型評估
采用偏最小二乘回歸(partial least square regression,PLSR)法建立小麥粉蛋白質定量校正模型[24],采用留一法交互驗證,限定最大主成分數為12,選取最佳主成分數,即交叉驗證的預測殘差平方和(prediction residual error sum of square,PRESS)最小時對應的主成分數。
模型建立過程中采用RMSECV對模型的性能進行評價,建立最優的校正模型。模型建立完成后,通常采用RMSEP、決定系數(R2)[25]等指標對模型的預測性能進行綜合評價,R2越接近1,表示模型的預測效果越好;如果R2為負值,表明模型擬合效果極差。RMSECV和RMSEP值越小,所建模型的穩定性與預測精確度越高。
1.3.4 蜻蜓算法優選校正集
蜻蜓算法是Mirjalili[26]在2016年通過對自然界蜻蜓行為進行觀察、總結和抽象后,提出的一種新的智能群體優化算法,并通過對幾類典型函數優化驗證了連續DA算法、BDA算法的有效性。生物學家觀察到,蜻蜓主要通過5 種主要策略來改變其位置:分離(Separation)、對齊(Alignment)、聚集(Cohesion)、覓食(Attraction to food)、避敵(Distraction from enemy),這5 種策略的數學模型表達式分別如式(1)~(5)所示:
式中:i表示第i個蜻蜓;X表示當前蜻蜓的位置,Xj表示第j個鄰近蜻蜓的位置;N表示鄰近蜻蜓的數量;Vj表示第j個鄰近蜻蜓的速率;X+表示食物的位置;X-表示危險或敵人的位置。
通過上述5 種策略位置,在搜索范圍空間更新蜻蜓的位置并模擬它們運動,考慮了步長向量(ΔX)和位置向量(X),并在粒子群算法的框架基礎上開發了一種基于步長向量(ΔX)和位置向量(X)的人工蜻蜓搜索算法。步長向量表明了蜻蜓的運動方向,如式(6)所示:
式中:s為分離權重;a為對齊權重;c為聚集權重;f為覓食權重;e為避敵權重;w為慣性權重;t為當前迭代次數。得出步長向量后,蜻蜓的位置更新如式(7)所示:
群智能優化算法在連續空間和離散空間中的優化方式不同。在連續搜索空間中,DA的搜索代理通過在位置向量上添加步進向量更新種群的位置,而在利用蜻蜓算法優選近紅外建模校正集時,需將連續域轉換為離散域,在離散域空間中尋找最優解。Mirjalili等[27]利用傳遞函數將蜻蜓算法進行改進,提出BDA,傳遞函數接收步長值作為輸入并輸出一個0或1的數字,表示位置變化的概率。V型傳遞函數如式(8)所示:
式中:Δx為傳遞函數的輸入,即步長值。
用傳遞函數得出位置變化率后更新蜻蜓在搜索空間中的搜索位置(式(9)):
式中:r為[0,1]之間的隨機數;負號表示邏輯取反運算。
采用BDA算法優選校正集,首先使用K/S法將樣本初步劃分為初始校正集和預測集,初始校正集用于建立定量校正模型以及待優化,預測集在建模結束后用于評估優選的校正集建模的預測效果,接下來采用BDA算法,在初始校正集中進一步挑選出數量更少、更具有代表性的樣品組成新的校正集,實現對校正集樣品的優選。采用K/S法將初始校正集劃分為子校正集和驗證集,BDA的作用是在子校正集中挑選一定數量的樣品作為新的校正集,根據其全局搜索能力強的特性在子校正集樣本空間中大范圍搜索合適的校正集,適應度函數值為優選出的校正集建立PLSR模型的RMSECV與該模型預測驗證集的RMSEP之和(sum),如式(10)所示。每次實驗迭代計算時,如果本次迭代最優解優于上次,則記錄該最優解對應的sum、RMSECV和RMSEP。經過不斷的迭代更新,最終選取sum最小的樣品集作為最優校正集。BDA算法優選校正集的流程如圖1所示。
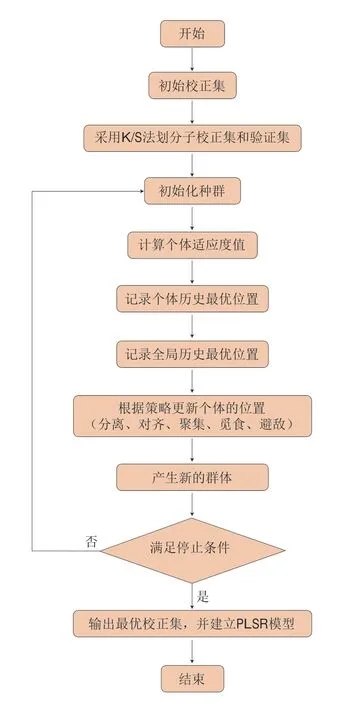
圖1 BDA算法優選校正集的流程圖Fig.1 Flow chart of calibration set optimization by BDA
1.4 數據處理與分析
采用實驗室自主研發的NIRSA 5.9.4系統[28](計算機軟件著作權登記號為2007SR06801)、Matlab 2016a等軟件平臺進行數據處理與分析。
2 結果與分析
2.1 樣品劃分
本研究所選樣品的小麥粉蛋白質含量測定結果如表1 所示,其含量基本覆蓋小麥粉蛋白質量分數(7%~15%),并且分布較為均勻,表明該樣品具有代表性。

表1 小麥粉蛋白質含量統計Table 1 Statistics of the protein content in wheat flour
在采集的所有樣品數據中,受樣品、采集環境和儀器的影響,一定程度上會存在異常樣品數據,影響所建模型的穩定性與預測能力,因此在建模之前必須將異常樣品從集合中剔除。采用主成分分析(principal component analysis,PCA)與馬氏距離相結合的方法檢測異常樣本,剔除馬氏距離大于3f/m的樣本,其中f為PCA所用主因子數,m為樣本數,共剔除20 個異常樣本。采用K/S方法將140 個正常樣品劃分為初始校正集(100 個)和預測集(40 個),其小麥粉蛋白質含量分布如表2所示,初始校正集與預測集的樣本化學值分布較寬,具有良好的代表性。
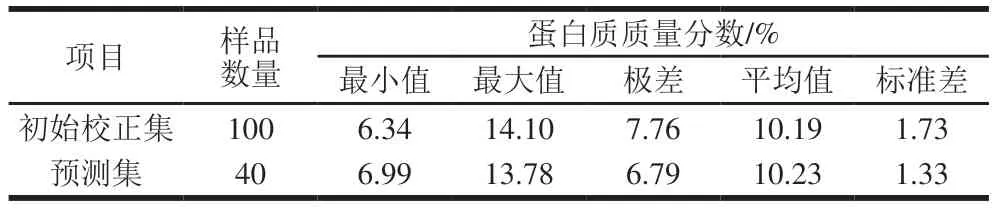
表2 初始校正集與預測集小麥粉蛋白質含量統計Table 2 Statistics of the protein content in wheat flour in initial calibration and prediction sets
2.2 初始校正集建模
以100 個初始校正集樣品的近紅外光譜及其蛋白質含量數據為研究對象,建立PLSR模型。為了消除光譜數據中無關信息和噪聲的干擾,使用移動平均平滑(moving average filter,MAF)、Savitaky-Golay卷積平滑(Savitaky-Golay filter,SGF)、標準正態量變換(standard normal variate transformation,SNV)、一階導數(1stderivative,1stD)、標準化及組合的預處理方法對樣品進行預處理[29],建立PLSR校正模型以評價預處理方法的優劣,選定最佳的預處理方法。不同預處理方法的校正模型評價結果如表3所示。
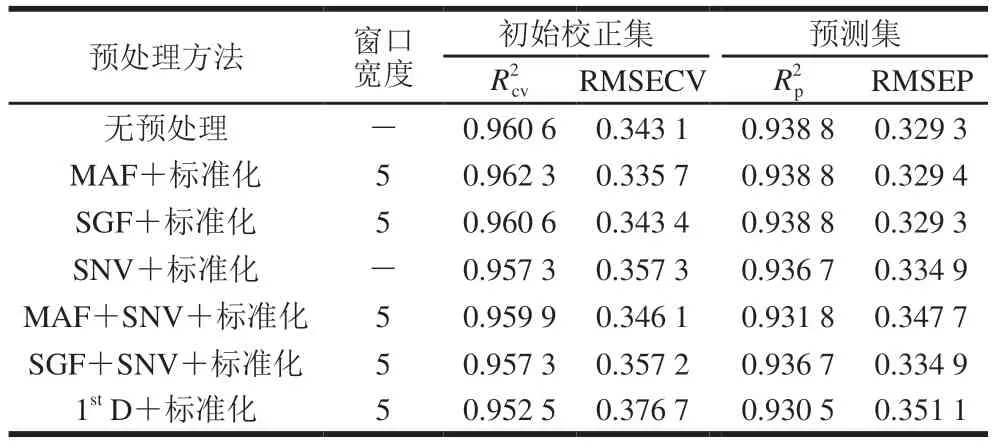
表3 不同預處理方法的樣品蛋白質PLSR校正模型評價Table 3 Evaluation of PLSR calibration models developed using different pretreatment methods
由表3可知,對比不同預處理方法的建模效果,其中MAF+標準化(MAF窗口寬度為5)的預處理方法除RMSEP略高于無預處理和SGF+標準化外,各項指標均為最優,此時PLSR模型的為0.962 3,RMSECV為0.335 7,為0.938 8,RMSEP為0.329 4,模型具有較高的預測精度,后續實驗均采用MAF+標準化(MAF窗口寬度為5)的預處理方法。
2.3 蜻蜓算法優選校正集
采用K/S方法將初始校正集劃分為子校正集和驗證集,比例為4∶1,子校正集80 個,驗證集20 個,結合BDA算法優選校正集,設置迭代次數40 次,初始種群數500,優選校正集樣品數量20~40 個。進行10 次BDA優選校正集實驗,實驗序號記為BK1~BK10,sum變化如圖2所示,隨著迭代的進行,sum越來越小,表明所挑選的校正集建模以及所建模型對驗證集的預測評價參數越來越優。優選校正集的建模及預測結果如表4所示,10 次實驗優選的校正集樣品個數平均為30.2 個,平均為0.949 5,RMSEP為0.299 0,平均預測性能提高了1.14%,RMSEP降低了9.23%,10 次優選的校正集建模預測性能均優于初始校正集,實驗BK1在10 次實驗中優選出的30 個校正集樣本建模預測效果最優(:0.956 4,RMSEP:0.278 1),與初始校正集相比,提高1.87%,RMSEP降低15.57%,實驗BK3和BK10所優選出的校正集樣品數僅24 個,且具有較好的模型穩定性和預測能力。

表4 10 次BDA優選校正集實驗的建模及預測結果Table 4 Modeling and prediction results from BDA experiments 1–10 for calibration set optimization
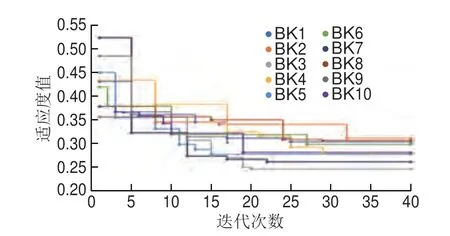
圖2 10 次BDA優選校正集實驗適應度值變化Fig.2 Changes in fitness values for BDA experiments 1–10 for calibration set optimization with the number of iterations
圖3為初始校正集、BK1優選校正集和預測集的蛋白質含量分布圖,BK1所挑選出的校正集樣本含量分布較為均勻,基本涵蓋了預測集樣品的含量分布范圍。將BK1優選的校正集和預測集取前兩個主成分作主成分分布圖,如圖4所示,30 個校正集在42 個預測集樣本中均勻分布,盡可能地用較少的樣本包含整個數據集的特征,從而使所建立的預測模型可以對預測集進行良好預測。

圖3 校正集和預測集樣本的蛋白質含量分布Fig.3 Protein content distribution of calibration set and prediction set samples
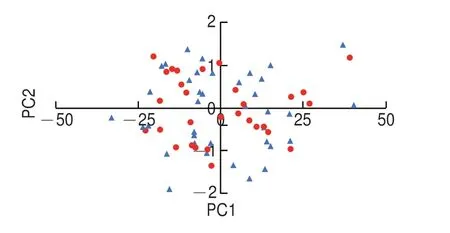
圖4 BK1優選校正集和預測集主成分分布Fig.4 Principal component analysis showing the distribution of calibration set and prediction set samples in BK1 for calibration set optimization
3 討論
在校正模型建立的過程中,選取參與校正的樣本對建立穩健的模型是十分必要的,目前最常用的方法是K/S法和SPXY法。潘國鋒[30]使用K/S算法對41 個水體中總氮光譜數據進行優選,用30 個樣本建立了較為理想的硝酸鹽定量校正模型。王世芳等[31]以小型西瓜為研究對象,校正集與預測集通過SPXY法進行劃分,建立了西瓜瓜梗、瓜臍和赤道3 個部位的可溶性固形物含量模型,預測精度較好。朱榮光等[32]采用濃度梯度法、隨機法、K/S以及SPXY法共4 種校正集劃分方法對牛肉嫩度高光譜數據進行劃分和比較,結果發現在偏最小二乘回歸和主成分回歸建模時,SPXY法所挑選出的校正集建模效果均較優。本研究將與傳統的K/S法和SPXY法優選校正集進行對比,利用傳統方法從初始校正集中分別采用K/S和SPXY法進一步挑選出k(k=20,25,…,90,95)個樣品作為新的校正集建立PLSR模型,并對預測集進行預測,結果如圖5所示。由圖5a、b可知,K/S法所挑出的校正集隨著樣品數量的增加模型穩定性整體上越來越好,當所選樣品個數為80、85以及90時所建模型穩定性最優,當所選樣品個數為35時,模型預測效果最好(:0.942 8,RMSEP:0.318 4)。由圖5c、d可知,SPXY法所挑選出的校正集隨著樣品數量的增加模型穩定性整體變好;當樣品個數為20時,所建模型穩定性較優,但預測性能差(:0.385 6,RMSEP:1.043 6);當樣品個數為85時,所建模型穩定性最優,預測性能較好(:0.933 4,RMSEP:0.343 5);當樣品個數為35時,所建模型穩定性較優,且預測性能最好(:0.938 1,RMSEP:0.331 3)。

圖5 K/S、SPXY法優選校正集建模及預測參數Fig.5 Modeling and prediction parameters of K/S and SPXY optimal calibration sets
通過K/S和SPXY法挑選出的校正集建模和預測結果可以看出,K/S法從初始校正集100 個樣品中挑選出35 個樣品作為新校正集,所建模型的預測精度相較于初始校正集而言也略有提升,從0.938 8上升到0.942 8,初步達到了優選校正集的效果;SPXY法在挑選出35 個樣品建模時預測性能最好,但預測精度略低于初始校正集建模,為0.938 1,不符合挑選出數量更少的校正集建立預測精度更高的模型的目標。而采用BDA算法從初始校正集中優選校正集,10 次實驗所選出的新校正集建模預測精度均高于初始校正集,挑選出30 個樣品進行建模時,預測高達0.956 4,樣品個數為24時,預測也可以達到0.952 5,說明采用BDA算法可以優選出數量更少的校正集建立預測精度更高的小麥粉蛋白質定量模型。
4 結論
本研究在傳統挑選校正集樣品的基礎上引入BDA算法進行優化,以所選校正集建立的模型RMSECV與其對驗證集的RMSEP之和構建適應度函數,并與傳統校正集挑選方法K/S和SPXY法進行比較。結果表明,BDA算法優選出的校正集有最優的預測性能,在10 次BDA優選實驗中,平均挑選出的校正集個數約占原校正集個數的30%(從100 個降低到30.2 個),平均預測性能提高了1.14%(從0.938 8提升至0.949 5),RMSEP降低了9.23%(從0.329 4降低至0.299 0)。采用BDA算法可以優選出數量少、具有代表性的校正集樣品,建立的小麥粉蛋白質PLSR模型穩定性好、預測精度高,可為小麥粉品質近紅外檢測分析提供一種高效、準確的校正集優選方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
