基于機器學習的游泳運動訓練方法研究
2024-06-03 00:00:00高學博楊繼宏
蘭州文理學院學報(自然科學版) 2024年3期
關鍵詞:機器學習



摘要:在體育訓練中,針對不同類型的運動員制定正確的訓練計劃和執行方案至關重要.模糊建模與免疫算法 相結合的機器學習方法可用于優化游泳運動員的訓練.綜合考慮游泳運動員的能力水平、體能狀況、技術熟練 程度以及訓練目標等多種因素,實驗中建立了12個屬性的數據集,這些屬性被分為離散型和連續型兩類.在數 據收集過程中,考慮到個體差異和訓練過程中的不確定性,對每個屬性進行了差異化和連續化處理.使用機器 學習方法對游泳訓練進行建模,可以更好地理解和指導運動員的訓練過程. 關鍵詞:機器學習;游泳訓練;水中感受預測模型
中圖分類號:G861.1
文獻標志碼:A
Research on Swimming Training Method Based on Machine Learning
GAO Xue-bo1, YANG Ji-hong2
(1. Northern Anhui Health Vocational College, Suzhou 234000, Anhui, China;
2. Anhui University of Science and Technology, Huainan 232001, Anhui, China)
Abstract:In sports training, it is very important to make correct training plans and implementation plans for different types of athletes. The machine learning method combining fuzzy modeling and immune algorithm can be used to optimize the training of swimmers. Considering the ability level, physical condition, technical proficiency and training objectives of swimmers, a data set of 12 attributes is established in the experiment, which are divided into two categories: discrete and continuous. In the process of data collection, each attribute is differentiated and continuous to consider individual differences and uncertainties in the training process. By using machine learning method to model swimming training, we can better understand and guide the training process of athletes.
Key words; machine learning; swimming training; data collection; modeling; instructing training
0 引言
在運動領域中, 制訂和執行正確的訓練計劃至關重要. 特別是在游泳這種高效率的體育運動中, 在適當時間給予每個運動員準確刺激的方法顯得尤為重要. 當訓練組涉及不同類型的運動員和專業時, 這一挑戰變得更加復雜.目前, 數字體育和智能訓練成為了國內外體育領域的研究熱點. 吳彰忠等[ 1]指出信息化時代數字與體育將會繼續相互加持, 不斷開拓中國式現代化體育新道路, 楊國慶[ 2]指出能以算法自動生成個性化訓練指導方案, 霍波等[ 3]研究了人工智能技術在體育領域的應用現狀及未來發展趨勢, 蘇宴鋒等[ 4]探討了人工智能如何提升運動表現以及構建人工智能體育化的理論支撐與政策環境的優化策略, 胡海旭等[ 5]指出機器學習為賦能個性化、 瞬時動態、 反饋等精準訓練方法提供了強力支撐. 國外的研究表明, 智能運動訓練( S S T) 領域中常用的智能數據分析方法—S S T 方法已比較成熟[ 6], 提出了一種用于適應人類運動的教學系統的機器學習方法, 利用在線分類的運動信號,以選擇適當的教學算法的自動系統的原型[ 7]. 從近年來的研究文獻來看, 機器學習在體育運動訓練中的應用將是未來體育訓練方法研究的熱點,但國內關于機器學習在游泳運動訓練中應用的研究很少.
本文旨在研究如何將模糊建模與免疫算法相結合的機器學習方法應用于游泳運動訓練中. 這種方法基于對訓練刺激和運動員反應的模糊理解, 同時考慮到個體差異和訓練過程中的不確定性. 通過將這種機器學習技術與傳統的訓練方法相結合, 希望能夠為教練做訓練決策提供一種有效的工具, 改善運動員的訓練效果.
1 實驗設計
1.1 實驗數據收集
通過調研和咨詢游泳部門的教練, 建立了1 2個獨立的屬性來模擬游泳訓練, 如表1所列. 這些屬性被分為兩類: 離散型( D) 和連續型( C) . 離散型屬性包括性別、 刺激因素、 水上訓練次數、 地面訓練次數、 體驗和感受, 而連續屬性包括年齡、 時刻、 睡眠時長、 睡眠前后脈搏數差、 時間、 距離. 其中, 刺激因素屬性又包含: 無訓練( B) 、 維持訓練( A 1) 、 有氧訓練( A 2) 、 閾訓練( T) 、 最大攝氧量訓練( VO2) 、 無氧訓練酸乳-速率訓練( AN 1) 、 無氧訓練酸乳-乳酸耐受( AN 2) 、 無氧訓練非酸乳( S) . “ 體驗和感受” 屬性分為5種: 非常差( VB) 、差( B) 、 中等( M) 、 好( G) 、 非常好( VG) .
在處理數據時, 針對每個人可能有不同的感受和體驗進行個性化處理. 例如, 男性醒來后的脈搏可能與女性的完全不同, 因此在處理這些數據時需要考慮到個體的差異[ 8]. 在處理“ 時刻” 屬性時, 例如被檢查的人會在夜里睡覺, 由于數據的連續性問題, 所以某些時刻的小時值要加上2 4, 并將以分鐘為單位的值轉換為小時的小數部分. 這樣做是為了保持數據的連續性, 并使系統能夠正確理解入睡時間. 同樣, 將“ 時刻” 屬性中的分鐘轉換為十進制值也是為了將數據轉換為計算機系統可以理解的形式. 這些預處理步驟的目的是減少數據集中的屬性數量, 提高數據的質量和一致性,以便后續的機器學習或數據分析工作能夠更有效地進行.
將數據收集以電子表格形式分發給游泳運動員, 在兩個月內完成表格的填寫. 表2中收集了各種屬性, 包括性別、 年齡、 訓練時刻、 睡眠時長、 睡眠前/后脈搏數差、 站立前/后脈搏數差、 刺激因素、 刺激持續時間、 水上訓練次數、 地面訓練次數、白天游泳距離以及在常規熱身后下午訓練中的感受. 對收集的數據進行處理, 并將特定屬性的值進行了統一. 在收集的數據中存在著一些不完整的記錄, 對于某些缺失的數據, 允許游泳運動員填寫“ -” . 在4 8 0條數據記錄中, 只有1 3 6條是合格的( 沒有任何缺失值) . 本文使用分布平衡分層交叉驗證進行實驗, 將數據集劃分為多個折時提供平衡的組內分布來提高估計質量. 然后, 利用 KL散度( K u l l b a c k - L e i b l e rd i v e r g e n c e ) 計算數據集中每個屬性的信息增益, 并利用配對t檢驗對所得結果進行統計學分析. 通過這些分析, 可以了解哪些屬性對于預測或解釋游泳運動員的訓練體驗和感受最有價值, 從而為優化訓練方案和提高運動員表現提供依據.
1.2 機器學習算法
模糊邏輯通過使用模糊集來定義重疊的類定義來改進分類任務[ 9]. 這種數據挖掘算法發現了一組形式為“ I F( 模糊條件) THEN( 類) ” 的規則,其解釋為: 如果一個實例的屬性值滿足模糊條件,則該實例屬于該規則所預測的類. 已經通過不同的技術實現了從數據中自動構造模糊分類規則,例如神經模糊方法, 基于遺傳算法的規則選擇以及模糊聚類與其他方法的組合, 例如模糊關系和遺傳算法優化. 其中的一個方法是集成人工免疫系統( A I S) 和模糊系統, 一種基于 A I S的模糊規則挖掘方法是I F RA I S( 人工免疫系統模糊規則歸納) , 使用順序覆蓋和克隆 選擇來 學習I F -THEN模糊規則. I F RA I S的速度和有效性分別通過緩沖規則, 使用初始均勻種群和模糊分區學習得到顯著提高. 基于 A I S的挖掘I F - THEN 規則的算法之一是基于用遺傳算法擴展否定選擇算法. 另一種主要集中在克隆選擇和所謂的提升機制, 以適應迭代中訓練實例的分布. 本文旨在使用改進的I F RA I S方法進行運動訓練建模.I F RA I S是一種模糊規則歸納方法, 是將人工免疫系統的進化機制應用于模糊規則的學習.該方法將訓練集視為抗原, 模糊規則視為抗體, 通過克隆選擇算法來選擇最佳的模糊規則進行學習. 在克隆選擇算法中, 首先創建一個初始的抗體群體, 然后對每個抗體進行適應度計算, 適應度計算是根據抗體與訓練集的匹配程度來確定的. 然后進行選擇、 交叉和變異操作, 以產生新的抗體群體. 這個過程反復進行, 直到滿足終止條件. 在I F RA I S中, 每個模糊規則的前件是由模糊條件的合取構成的, 每個模糊條件對應一個屬性. 在開始時, 所有屬性( 包括離散屬性和連續屬性) 都會通過隸屬函數進行模糊化處理. 在學習過程中,I F RA I S使用順序覆蓋作為主要的學習算法. 首先, 一組規則被初始化為空集; 然后, 對于每個待預測的類, 算法會使用所有訓練樣本對訓練集進行訓練, 并以當前訓練集和待預測的類為參數迭代調用克隆選擇過程, 克隆選擇過程返回一個發現的規則; 接下來將該規則添加到規則集, 并從當前訓練集中刪除已被進化規則正確覆蓋的示例,對于所有未覆蓋的示例, 分配在完整訓練集中最常見的類.
2 模型驗證實驗
為了驗證所提模型的有效性, 進行了水中感受預測模型實驗和水中感受預測與規則優化實驗.
2.1 水中感受預測模型實驗( 實驗一)
實驗主要測試模型是否能夠傳遞訓練單元、如何影響受訓者第二天在水中的感受. 為了解決這個問題, 通過設置模型的參數、 執行模糊分區的學習、 檢查接收到的規則的有效性, 并咨詢訓練員和游泳者接收到的結果. 所有實驗重復1 0次, 使用5倍交叉驗證, 運行環境為2. 8 0GH z的奔騰與2. 0 0G B的 RAM. 改進后的I F RA I S在 NE T2. 0環境下用C#語言實現. 分頻因子r=3, 抗體的初始群體大小等于5 0, 并且激活閾值L 設定為0. 1.
本實驗的目的是研究所提出的負荷訓練模型和機器學習工具是否能夠幫助游泳者找到控制他們在水中感覺的規則. 改進的I F RA I S預測的類是“ 體驗和感受” 屬性, 學習的規則集由7個規則組成, 如表3所列, 每個規則包括與合取詞和類的預測值相連接的條件列表. 在實驗中, 接收到的規則與模糊屬性完全的有效性提高了5 3. 2 1%. 這是一個相當低的結果( 接近隨機) , 但接收到的規則的可用性仍然值得考慮.
通過規則可以看到, 規則缺少 V B值, 原因是這個值從未在學習集中使用過. 另一個結論是, 類M 和G的兩個值有一個以上的規則生成. 然而,這些是來自“ 體驗和感受” 屬性的標度中心的值,并且對于受訓者來說并不那么重要. 考慮到量表中最重要值的集合的最后一條規則, 在被測游泳運動員小組中, 受訓者在以下情況下的感受最好:①游泳者在前一天晚上1 0點到凌晨2點半之間睡覺; ②訓練前一天入睡前的脈搏與醒來后的脈搏之間的差異約1. 5~2. 9; ③站立后的脈搏與醒后的脈搏之差大于5; ④訓練前一天的刺激持續時間不長于4 5m i n; ⑤訓練之前的游泳里程不大于1 1. 5k m, 在此期間游泳者具有非常好的感覺,滿足某些條件可以增加游泳者在水中的良好感覺, 但考慮到規則集的有效性, 可能存在很多例外. 這種低效率的原因是, 學員們根據自己的主觀感覺調整尺度來適應每個價值, 而且每個游泳運動員的感覺范圍可能不同, 這無疑對機器學習產生了影響. 此外, 輸入數據的3個屬性( 涉及受訓者的性別、 水中的培訓次數和地面的培訓次數) 是明確和客觀的, 但沒有出現在任何規則中.
2.2 水中感受預測與規則優化實驗( 實驗二)
水中感受預測與規則優化實驗與水中感受預測模型實驗類似, 但改變了對游泳者感受的描述方式. 最終結果是由推斷的模糊分區的屬性和學習的模糊規則集所呈現的. 這些結果可以提供關于訓練單元如何影響受訓者第二天在水中的感受的重要信息. 水中感受預測與規則優化實驗是為了驗證一個假設, 即簡化感受量表可以提高推斷規則的質量( 有效性) . 預測屬性量表的變化旨在概括感受, 并消除因受訓者的個性化感受量表而產生的差異. 對這種修改的數據集進行研究, 將先前實驗中預測屬性中相同的兩個值是否涉及到不同的感覺.
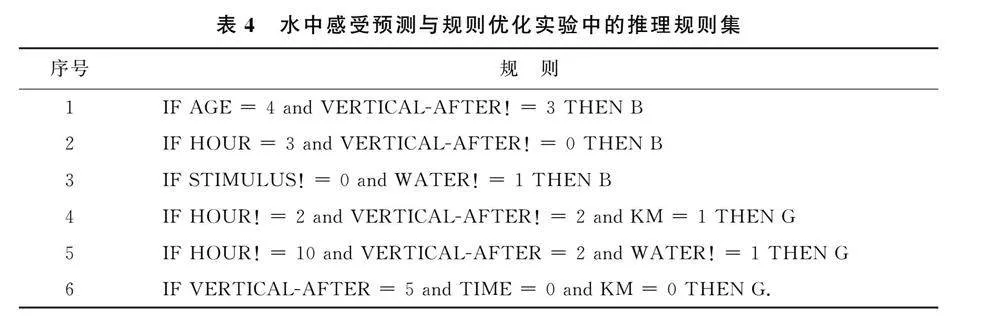
實驗后接收的規則集由6個規則組成, 如表4所列. 學習規則集的有效性提高了6 8. 5 6%. 它比之前實驗的有效性高出1 5. 3 5%. 減少預測屬性中的值減少了由多個值重疊的區域的數量, 因此增加了類別的可預測性. 此外, 規則的數量也有所減少, 從水中感受預測模型實驗中改進的I F -RA I S推斷出7條規則, 而這個實驗結束時只有6條規則.
需要注意的是, 在學習規則中忽略了4個屬性, 即性別、 睡眠時長、 站立前/后脈搏數差、 地面訓練. 兩個實驗中從未使用過兩個屬性. 這些屬性涉及受訓者的性別和在當地接受培訓的次數. 根據培訓師和參加研究的學員的意見, 似乎假設是真實的, 但假設需要進一步研究. 另外兩個屬性睡眠時長、 站立前/后脈搏數差在水中感受預測與規則優化實驗中被規則集忽略, 在水中感受預測模型實驗中學習的規則使用了這兩個屬性. 這可能是水中感受預測模型實驗中規則對學習集過度調整的結果, 這是由于缺乏預測類的給定值的語義后果造成的.
為了使受訓者在水中感覺良好( 類值 G) , 在解釋實驗結果時必須滿足以下3個規則之一: ①規則4: 在前一天午夜前或凌晨3點后睡覺; 達到訓練當天醒來后的脈搏與從床上站起來后的脈搏之間的差異, 該差異必須低于2或大于6; 在訓練前一天游泳不超過9. 5k m. ②規則5: 不遲于午夜半時入睡; 實現訓練當天醒來后的脈搏與當天從床上起床后的脈搏之間的差異, 差異必須高于2且低于6; 在水中進行兩次訓練或根本不進行水中訓練. ③規則6: 達到訓練當天醒來后的脈搏與當天起床后的脈搏之間的差值, 差值必須高于1 . 5且低于5; 參加訓練, 在此期間所進行的刺激將持續不少于3 0m i n; 在訓練前一天游泳不超過2 . 5k m.
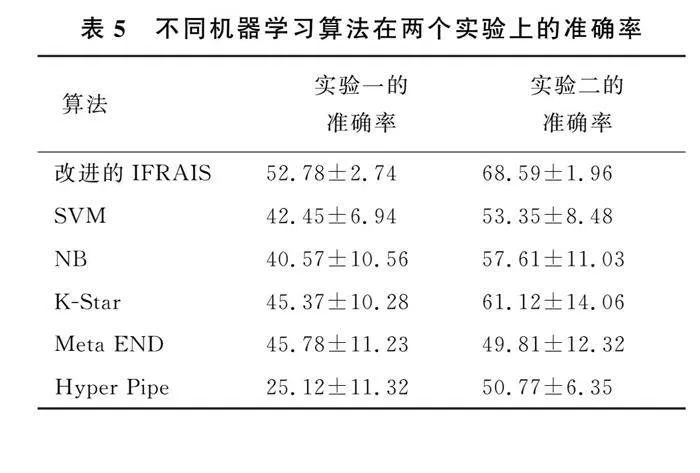
2.3 不同機器學習算法的準確性比較
不同機器學習算法在分類問題上的表現及其機理各不相同, 現將改進的I F RA I S算法與傳統分類器算法的性能進行比較. 支持向量機( s u p -p o r tv e c t o rm a c h i n e , S VM) 算法通過支持向量機進行分類, 它通過找到一個最優的超平面, 將不同類別的數據分隔開. 樸素貝葉斯( n a i v eb a y e s ,N B) 算法的原理是基于貝葉斯定理進行分類的,假設屬性之間是獨立的, 通過計算每個屬性的條件概率以及類條件概率, 來預測樣本所屬的類別[ 1 0]. K S t a r算法是一個基于實例的分類器, 通過分析數據集的特征之間的關系, 建立一棵決策樹, 并使用這棵樹對新的樣本進行分類. 元結束( M e t aEND) 算法則是將每個分類器的判斷表示為特征向量, 并再次進行分類, 由元分類器做出最終決策. 超管道( H y p e rP i p e) 算法則是通過構建超管道來進行分類的, 每個超管道包含了來自某個類中的所有屬性值, 通過比較樣本與超管道的相似度來進行分類. 不同機器學習算法在兩個數據集上的準確率如表5所列, 結果顯示改進的I F RA I S方法的結果在水中感受預測模型實驗和水中感受預測與規則優化實驗中分別是5 2. 7 8±2. 7 4、 6 8. 5 9±1. 9 6, 顯著高于其他機器學習算法,改進的I F RA I S方法在分類精度上具有優越性.
3 結語
本文提出的將模糊建模與免疫算法相結合的機器學習方法, 為游泳訓練提供了新的視角和工具. 基于 A I S的模糊規則挖掘方法I F RA I S是一種有效的數據挖掘方法, 適合處理復雜的分類問題. 比較不同的機器學習算法在兩個實驗中的效果, 可以看出, 改進的I F RA I S方法的結果在兩個實驗中的準確率分別是5 2. 7 8±2. 7 4、 6 8. 5 9±1 . 9 6, 明顯高于其他傳統算法. 說明使用機器學習方法對游泳訓練進行建模, 可以更好地指導運動員的訓練過程, 可以幫助教練根據運動員的反應和適應情況調整訓練計劃, 從而優化訓練效果. 改進的I F RA I S機器學習算法為運動科學領域的發展提供了新的思路和方法, 為提高運動員的訓練效果提供借鑒.
參考文獻:
[1]吳彰忠,鐘亞平,張立,等.中國式現代化體育新道路: 數字體育的使命與路向[J].體育科學,2023,43(6): 3-12.
[2]楊國慶.整合分期:當代運動訓練模式變革的新思維 [J].體育科學,2020,40(4):3-14.
[3]霍波,李彥鋒,高騰,等.體育人工智能領域關鍵技術 的研究現狀和發展方向[J].首都體育學院學報,2023,35(3):223-256.
[4]蘇宴鋒,趙生輝,李文浩,等.人工智能提升運動表現 的前沿進展、困境反思與優化策略[J].上海體育學院 學報,2023,47(2):104-118.
[5]胡海旭,金成平.智能化時代的個性化訓練一機器學 習應用研究進展與數字化未來[J].體育學研究,2021,35(4):9-19.
[6] RAJSP A,FISTER I. A systematic literature review of intelligent data analysis methods for smart sport training[J]. Applied Sciences,2020,10(9) :3013.
[7] WOJCIK K, PIEKARCZYK M. Machine learning method-ology in a system applying the adaptive strategy for teaching human motions[J]. Sensors,2020,20(1):105-112.
[8]李海鵬,陳小平,何衛,等.科技助力競技體育:運動訓 練中可穿戴設備的應用與發展[J].成都體育學院學 報,2020,46(3):19-25.
[9]宋群,袁青霞,王俊江.基于自動機器學習的運動過程 心電檢測算法[J].西北大學學報(自然科學版),2023,53(5):771-781.
[10]黃小杰,劉芝秀,鄧梓楊,等.基于Gauss分布和Gram-Schmidt正交化的樸素貝葉斯分類算法[J].南昌大學學報(理科版),2023,47(3):213-217.
[責任編輯:紀彩虹]
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
