基于交互注意力的紅外與可見光圖像融合算法
2024-06-07 22:56:55山子岐鄒華宇李凡刁悅欽
化工自動化及儀表 2024年3期
關鍵詞:深度學習
山子岐 鄒華宇 李凡 刁悅欽

DOI:10.20030/j.cnki.1000?3932.202403022
摘 要 為解決現有紅外與可見光圖像融合目標不夠顯著,輪廓紋理細節不夠清晰等問題,提出了一種基于交互注意力的紅外和可見光圖像融合網絡。該方法通過雙流特征提取分支提取源圖像的多尺度特征,然后經過交互融合網絡獲得注意力圖,以便從紅外與可見光圖像中自適應地選擇特征進行融合,最后通過圖像重建模塊生成高質量的融合圖像。在MSRS數據集和TNO數據集的實驗結果表明,所提方法在主觀視覺描述和客觀指標評價方面均表現出了較好的性能,融合結果包含更清晰的細節信息和更明顯的目標。
關鍵詞 圖像融合 深度學習 交互注意力 密集殘差連接
中圖分類號 TP183?? 文獻標志碼 A?? 文章編號 1000?3932(2024)03?0523?06
作者簡介:山子岐(1998-),碩士研究生,從事計算機視覺、機器學習及人工智能等的研究。
通訊作者:李凡(1986-),副教授,從事圖像處理、計算機視覺等的研究,478263823@qq.com。
引用本文:山子岐,鄒華宇,李凡,等.基于交互注意力的紅外與可見光圖像融合算法[J].化工自動化及儀表,2024,51(3):523-527;534.
由于成像設備技術的限制,僅憑單一模態的傳感器或單一攝像頭下捕獲的信息不能有效、全面地描述成像場景[1],因此,圖像融合技術應運而生。紅外傳感器通過捕獲物體散發的熱輻射信息成像,能夠有效地突出行人、車輛等顯著目標,但是缺失了大部分場景的細節信息。可見光圖像通常包含許多細節信息,但卻容易遭受極端環境的影響而丟失顯著性目標。紅外和可見光圖像融合旨在整合源圖像中的互補信息,并生成既能突出顯著目標又包含豐富紋理細節的高對比度融合圖像。目前,紅外和可見光圖像融合技術已在軍事行動、目標檢測[2]、人臉識別[3]、行人重識別[4]及語義分割[5]等領域得到了廣泛應用。
現有的融合方法主要分為兩類:傳統融合方法和基于深度學習的方法。傳統融合方法利用數學變換將源圖像轉換到變換域,并在變換域中設計融合規則以實現圖像融合。傳統的圖像融合技術主要包括基于多尺度分解的方法、基于子空間聚類的方法[6]、基于稀疏表示的方法[7]、基于優化的方法[8]和混合方法[9]。然而,傳統方法采用的變換方式越來越復雜,這無法滿足計算機實時應用的要求[10],也難以適應復雜場景。
近年來,深度學習的方法越來越多地應用到圖像融合領域。目前,基于深度學習的紅外與可見光圖像融合大致可以分為3類,即基于自編碼器(AE)的方法、基于卷積神經網絡(CNN)的方法和基于生成對抗網絡(GAN)的方法。
基于AE的方法繼承了傳統圖像融合算法,主要包括特征提取、融合和重建過程。LI H和WU X J首先提出了一種簡單的融合架構[11],由編碼器層、手工融合層和解碼器層3部分組成。之后,LI H等進一步對編碼器進行強化,引入密集連接提取深度特征,實現特征提取與重建[12]。然而,上述方法依賴手工制作的方法來制定融合規則,嚴重限制了融合性能的提高。
基于CNN的圖像融合可以在一定程度上避免手工制作的融合規則的局限性。ZHANG H等提出一種端到端的框架[13],通過強度和梯度損失來保持圖像梯度和強度的比例。JIAN L等進一步提出了一種基于殘差塊的對稱編碼器和解碼器結構的紅外和可見光圖像融合方法[14]。
基于GAN的圖像融合方法采用對抗損失來約束融合網絡。MA J等首先將基于GAN的方法用于紅外和可見圖像融合[15]。之后,MA J等進一步提出了一種雙鑒別器的生成對抗網絡,以保持不同源圖像之間的分布平衡[16]。但是,過強的約束容易將人工紋理引入到融合圖像中。
1 基于交互注意力的紅外與可見光圖像融合網絡
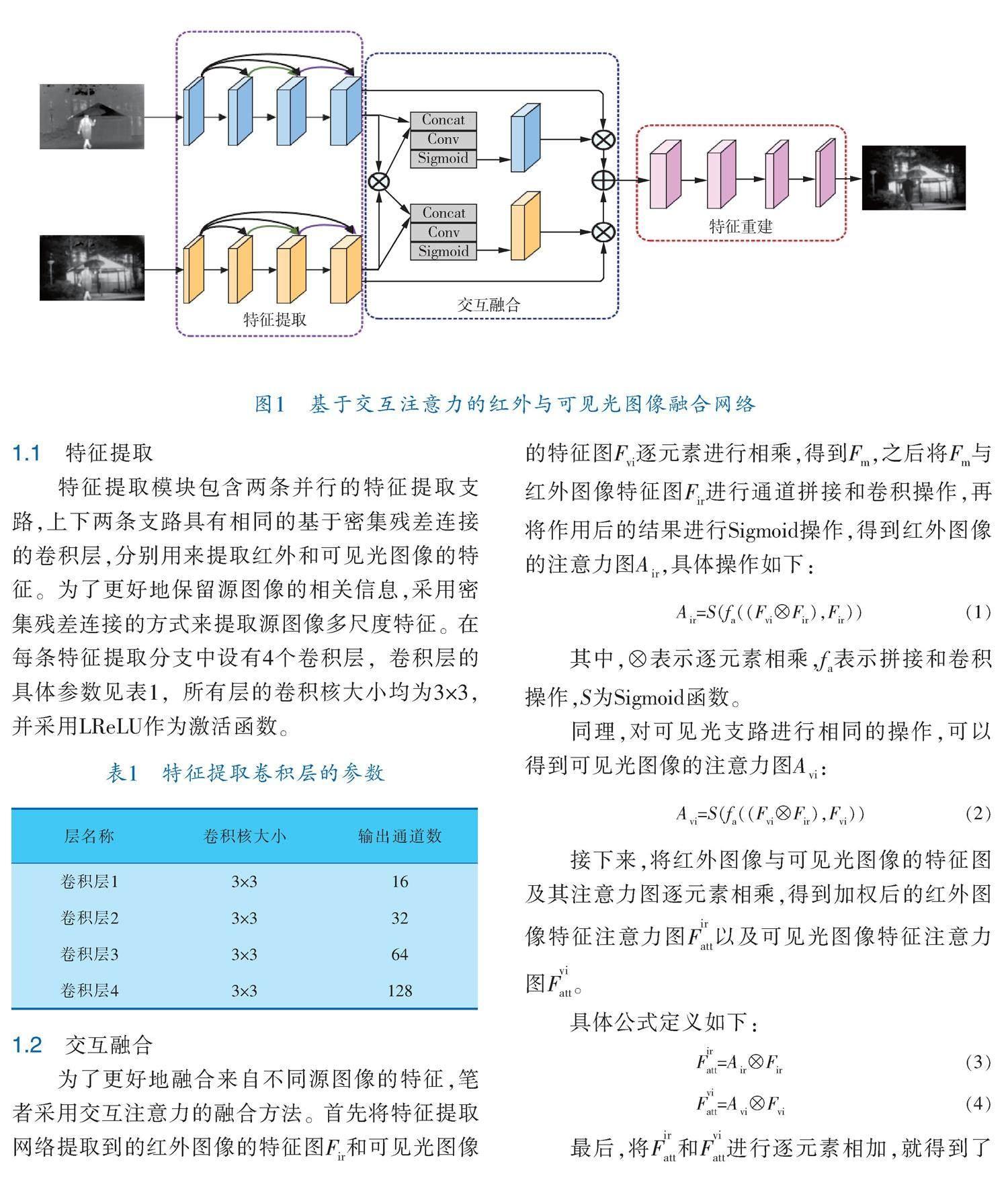
筆者提出的融合網絡總體框架如圖1所示,網絡以端到端的CNN框架作為主干,主要由特征提取模塊、交互融合模塊和特征重建模塊組成。
1.1 特征提取
特征提取模塊包含兩條并行的特征提取支路,上下兩條支路具有相同的基于密集殘差連接的卷積層,分別用來提取紅外和可見光圖像的特征。為了更好地保留源圖像的相關信息,采用密集殘差連接的方式來提取源圖像多尺度特征。在每條特征提取分支中設有4個卷積層,卷積層的具體參數見表1,所有層的卷積核大小均為3×3,并采用LReLU作為激活函數。
1.2 交互融合
為了更好地融合來自不同源圖像的特征,筆者采用交互注意力的融合方法。首先將特征提取網絡提取到的紅外圖像的特征圖F和可見光圖像的特征圖F逐元素進行相乘,得到F,之后將F與紅外圖像特征圖F進行通道拼接和卷積操作,再將作用后的結果進行Sigmoid操作,得到紅外圖像的注意力圖A,具體操作如下:
A=S(f((F?F),F)) (1)
其中,?表示逐元素相乘,f表示拼接和卷積操作,S為Sigmoid函數。
同理,對可見光支路進行相同的操作,可以得到可見光圖像的注意力圖A:
A=S(f((F?F),F))? (2)
接下來,將紅外圖像與可見光圖像的特征圖及其注意力圖逐元素相乘,得到加權后的紅外圖像特征注意力圖F以及可見光圖像特征注意力圖F。
具體公式定義如下:
F=A?F (3)
F=A?F (4)
最后,將F和F進行逐元素相加,就得到了初步融合后的特征圖。
1.3 特征重建
融合后的特征圖即為特征重建模塊的輸入,其中特征重建模塊包含4個卷積層,用于充分集合公有和互補的特征信息,并生成最終的融合圖像。特征重建模塊的具體參數見表2,除最后一層的卷積核大小為1×1外,其余層的大小均為3×3。只有最后一層的激活函數為Tanh激活函數,其余圖像重建分支中的所有卷積層均采用LReLU作為激活函數。在圖像融合領域,避免信息丟失是一個關鍵問題。因此,該網絡不引入任何下采樣,從而保證融合圖像的大小與源圖像一致。
1.4 損失函數
損失函數是優化算法的關鍵部分,在訓練過程中,通過最小化損失函數來調整模型參數,使得模型能夠不斷優化以提高結果的準確性。文中的損失函數由結構相似性損失L和紋理損失L組成。
為了使融合圖像能夠保持更多的結構信息,引入結構相似性損失Lssim:
L=(1-SSIM(I,I))+(1-SSIM(I,I)) (5)
其中,I表示融合圖像,I表示紅外圖像,I表示可見光圖像,SSIM()表示結構相似度。
為了使融合圖像能夠保留豐富的紋理細節,引入紋理損失L:
L=?I -max( ?I , ?I )? (6)
其中,max()表示選擇最大元素,?表示對圖像取梯度運算。
融合總損失由結構相似性損失和紋理損失兩部分構成:
L=L+λL (7)
其中,λ是一個超參數,用于平衡兩種損失函數間的差異。
2 實驗驗證
2.1 實驗數據集及實驗設置
筆者在MSRS數據集上訓練提出的融合模型。首先在MSRS數據集上選取1 000對紅外和可見光圖像構成訓練集,然后采用裁剪等數據擴充的方式擴充數據,以保證有足夠的訓練樣本來進行訓練。所有實驗均基于NVIDIA 2080 Ti GPU下的PyTorch框架實現。筆者采用Adam優化器對模型進行優化,初始學習率設置為0.001。測試階段,從MSRS數據集和TNO數據集中選擇部分紅外和可見光圖像對作為測試數據。
2.2 對比實驗
為了全面評估筆者所提方法的實驗性能,將其與其他5種圖像融合算法進行了定性與定量的比較,包括DenseFuse[11]、FusionGAN[14]、IFCNN[17]、PMGI[13]和U2Fusion[18]。
2.2.1 主觀評價
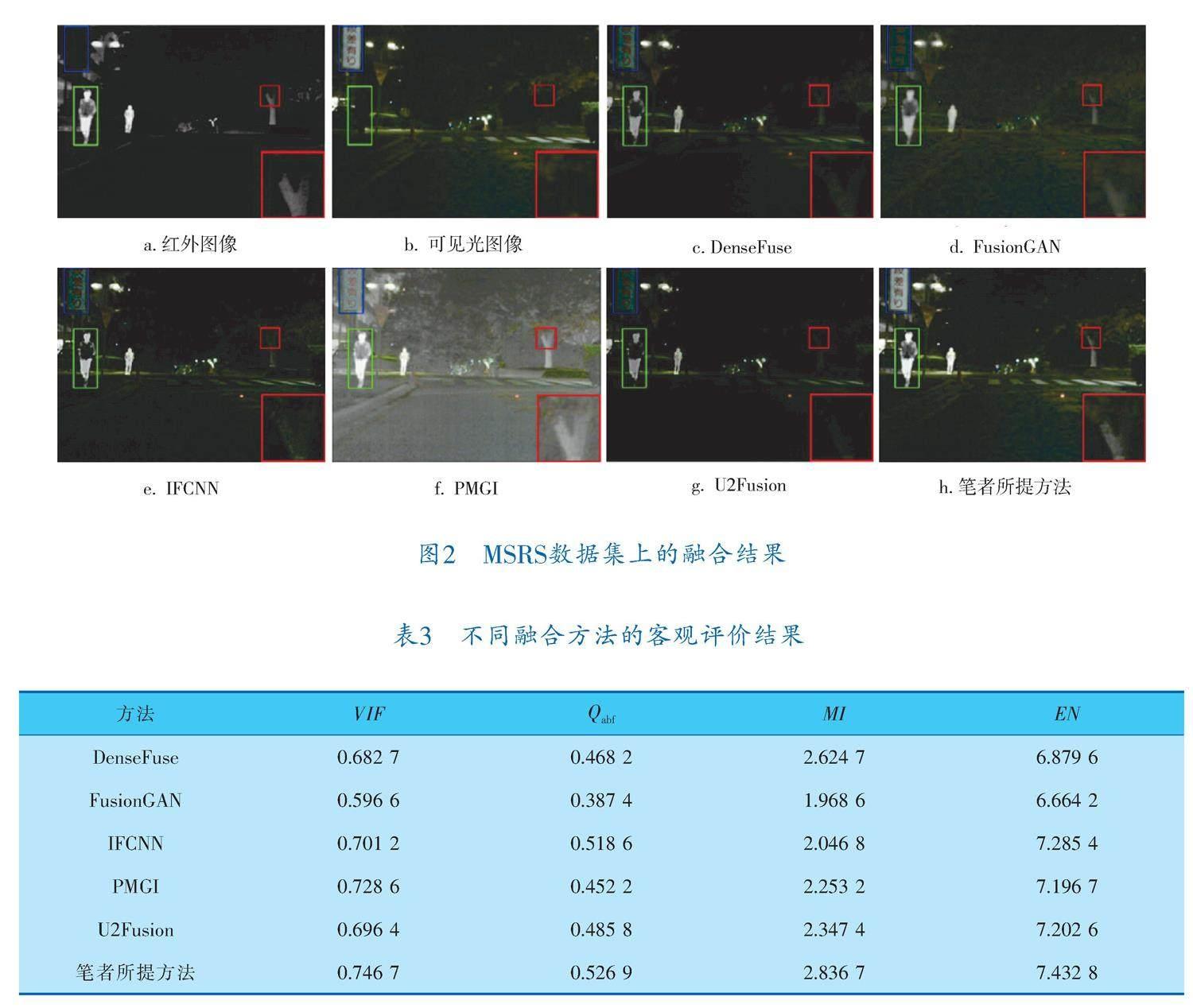
圖像融合的可視化結果如圖2所示,紅外圖像含有顯著性目標信息,可見光圖像主要包含細節信息。在每張融合圖像中劃定了一個紋理區域(紅框)、顯著目標區域(綠框)和細節區域(藍框)。在融合結果中,FusionGAN和U2Fusion在一定程度上削弱了紅外目標,PMGI在融合過程中引入了噪聲,DenseFuse、FusionGAN、IFCNN和U2Fusion未能清楚地顯示隱藏在黑暗中的樹干等信息,另外FusionGAN和PMGI模糊了圖像中的文字。與其他方法相比,筆者所提方法較好地整合了紅外和可見光圖像的互補信息。
2.2.2 客觀評價
筆者采用視覺保真度(VIF)、互信息(MI)、熵(EN)和基于邊緣信息的指標Q作為評價指標對融合效果進行客觀評價。所有評價指標的值與圖像的融合質量均成正相關。
圖像融合的定量結果見表3,筆者所提方法在4個指標中都表現出顯著優勢。其中,本文方法實現了最高的VIF,表明此方法的融合圖像具有高對比度和滿意的視覺效果。此外,本文方法的Q顯示了最好的性能,這意味著融合結果中保留了更多的邊緣細節信息。
2.3 泛化實驗
為了驗證筆者所提方法的泛化能力,將其在MSRS數據集上進行訓練,并將訓練好的模型在TNO數據集上進行測試,可視化結果如圖3所示。
在TNO數據集上的融合結果顯示,DenseFuse和U2Fusion削弱了顯著目標。此外,FusionGAN和PMGI模糊了目標的邊緣,并且在背景區域存在一定的光譜污染。與其他方法相比,筆者所提方法在顯著目標突出、紋理細節保留等方面更加具有優勢。
3 結束語
針對現有融合圖像任務中融合圖像缺乏顯著性目標、紋理細節等問題,提出了基于交互注意力的漸進式紅外與可見光圖像融合算法。該算法可以自適應地集成紅外圖像與可見光圖像中有意義的特征信息。經過大量實驗驗證,筆者提出的方法無論是在主觀還是客觀評價層面均取得了最佳的融合效果,在目標突出、紋理細節保留等方面均有一定的優勢,并且具有一定的泛化能力。
參 考 文 獻
[1] MA J,MA Y,LI C.Infrared and visible image fusion me? thods and applications:A survey[J].Information Fusion,2019,45:153-178.
[2] 寧大海,鄭晟.可見光和紅外圖像決策級融合目標檢測算法[J].紅外技術,2023,45(3):282-291.
[3] 趙云豐,尹怡欣.基于決策融合的紅外與可見光圖像人臉識別研究[J].激光與紅外,2008,38(6):622-625.
[4] LU Y,WU Y,LIU B,et al.Cross?modality person re?
identification with shared?specific feature transfer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2020:13379-13389.
[5] HA Q,WATANABE K,KARASAWA T,et al.MFNet:Towards real?time semantic segmentation for autono? mous vehicles with multi?spectral scenes[C]//2017 IEEE/RSJ International Conference on Intelligent Robo? ts and Systems(IROS).Piscataway,NJ:IEEE,2017:5108-5115.
[6] CVEJIC N,BULL D,CANAGARAJAH N.Region?based multimodal image fusion using ICA bases[J].IEEE Sensors Journal, 2007,7(5):743-751.
[7] LIU Y,CHEN X,WARD R K,et al.Image fusion with convolutional sparse representation[J].IEEE Signal Processing Letters,2016,23(12):1882-1886.
[8] MA J,CHEN C,LI C,et al.Infrared and visible image fusion via gradient transfer and total variation minimization[J].Information Fusion,2016,31:100-109.
[9] MA J,ZHOU Z,WANG B,et al.Infrared and visible image fusion based on visual saliency map and weighted least square optimization[J].Infrared Physics & Technology,2017,82:8-17.
[10] LI S,KANG X,FANG L,et al.Pixel?level image fu?
sion:A survey of the state of the art[J].Information Fusion,2017,33:100-112.
[11] LI H,WU X J.DenseFuse:A fusion approach to infra? red and visible images[J].IEEE Transactions on Image Processing,2018,28(5):2614-2623.
[12] LI H,WU X J,DURRANI T.NestFuse:An infrared
and visible image fusion architecture based on nest connection and spatial/channel attention models[J].IEEE Transactions on Instrumentation and Measurement,2020,69(12):9645-9656.
[13] ZHANG H,XU H,XIAO Y,et al.Rethinking the image fusion:A fast unified image fusion network based on proportional maintenance of gradient and intensity[C]//Proceedings of the AAAI Conference on Artificial Intelligence.AAAI,2020:12797-12804.
[14] JIAN L,YANG X,LIU Z,et al.A symmetric encoder?decoder with residual block for infrared and visible image fusion[J].arXiv Preprint,2019.DOI:10.48550/arXiv.1905.11447.
[15] MA J,XU H,JIANG J,et al.DDcGAN:A dual?discri? minator conditional generative adversarial network for multi?resolution image fusion[J].IEEE Transactions on Image Processing,2020,29:4980-4995.
[16] MA J,ZHANG H,SHAO Z,et al.GANMcC:A generative adversarial network with multiclassification constraints for infrared and visible image fusion[J].IEEE Transactions on Instrumentation and Measurement,2020,70:1-14.
[17] ZHANG Y,LIU Y,SUN P,et al.IFCNN:A general image fusion framework based on convolutional neural network[J].Information Fusion,2020,54:99-118.
[18] XU H,MA J,JIANG J,et al.U2Fusion:A unified unsupervised image fusion network[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,44(1):502-518.
(收稿日期:2023-05-22,修回日期:2024-03-15)
Interactive Attention?based Fusion Algorithm for
Infrared and Visible Images
SHAN Zi?qi, ZOU Hua?yu,? LI Fan,? DIAO? Yue?qin
(Faculty of Information Engineering and Automation, Kunming University of Science and Technology)
Abstract?? Considering insufficient remarkability and unclear? contour texture of existing? infrared and visible images,? an interactive attention?based infrared and visible image fusion network was proposed. In which, multi?scale features of the source image through a dual?stream feature extraction branch was extracted and? an attention map was obtained through the interactive fusion network to adaptively select features from the IR and visible images for fusion and finally generates a high?quality fused image through the image reconstruction module. Experiments on both the MSRS dataset and the TNO dataset show that, the algorithm proposed exhibits better performance in both subjective visual description and objective index evaluation, and the image fusion results contain clearer detail information and more obvious targets.
Key words??? image fusion, deep learning, interactive attention,? dense residual connectivity
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
