基于GPT 的本地文檔智能問答方法及應(yīng)用研究
2024-06-26 11:25:06吳曉蓉程俊杰
電腦知識(shí)與技術(shù) 2024年13期
吳曉蓉 程俊杰

摘要:隨著大模型的發(fā)展,公開通用的知識(shí)得到了廣泛的訓(xùn)練和應(yīng)用。但企業(yè)和個(gè)人的內(nèi)部文檔仍然沒有實(shí)現(xiàn)智能化。用戶查找內(nèi)部文檔內(nèi)容時(shí),仍需打開對(duì)應(yīng)文檔進(jìn)行搜索,效率低下,為了提高企業(yè)和個(gè)人內(nèi)部文檔的智能化訪問效率,減少查找時(shí)間提高工作效率。文章提出了一種基于大模型的本地文檔智能問答方法,該方法通過將本地文檔分割并調(diào)用大模型進(jìn)行智能問答,以實(shí)現(xiàn)高效的文檔檢索。研究結(jié)果表明該方法能夠在不耗費(fèi)大量計(jì)算資源的情況下,獲得與大模型相媲美的問答效果,為用戶提供更快速、智能的內(nèi)部文檔訪問體驗(yàn)。
關(guān)鍵詞:GPT;智能化問答;大模型;文檔檢索;文檔分割
中圖分類號(hào):TP311 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2024)13-0091-04 開放科學(xué)(資源服務(wù))標(biāo)識(shí)碼(OSID) :
0 引言
深度學(xué)習(xí)模型中的大模型,即擁有大量參數(shù)的模型,近年來在自然語言處理領(lǐng)域取得了巨大的進(jìn)展。特別是大語言模型(Large Language Models,LLM) ,它們通常擁有數(shù)十億甚至上百億的參數(shù),并通過大規(guī)模數(shù)據(jù)集的訓(xùn)練(如近1 TB的英文文本)來不斷提高其性能和應(yīng)用范圍[1]。這些巨型模型的出現(xiàn)引領(lǐng)了自然語言處理領(lǐng)域的發(fā)展,開創(chuàng)了新的研究方向和應(yīng)用前景,譬如OpenAI推出了ChatGPT模型,百度也推出了文心一言模型,公開通用的知識(shí)得到了廣泛的訓(xùn)練和應(yīng)用。
然而,在大模型的快速發(fā)展的同時(shí),企業(yè)和個(gè)人的內(nèi)部文檔仍然沒有實(shí)現(xiàn)智能化,這對(duì)于當(dāng)前信息爆炸的環(huán)境是一個(gè)巨大的挑戰(zhàn)。企業(yè)內(nèi)部文檔的格式通常為DOCX、XLXS、PDF、PPT、網(wǎng)頁等,數(shù)量眾多、種類復(fù)雜、內(nèi)容雜亂,這導(dǎo)致了信息檢索效率的低下。傳統(tǒng)的整理數(shù)據(jù)并訓(xùn)練企業(yè)和個(gè)人私有模型的方法相對(duì)復(fù)雜,需要大量的時(shí)間和資源。因此,研究企業(yè)內(nèi)部文檔智能化處理方法具有重要的現(xiàn)實(shí)意義和廣闊的應(yīng)用前景。
本研究旨在應(yīng)對(duì)這一挑戰(zhàn),提出了一種基于大模型的本地文檔智能問答方法。與傳統(tǒng)方法相比,這種方法既簡單又高效,能夠快速地將先進(jìn)的自然語言處理能力應(yīng)用于企業(yè)內(nèi)部文檔的處理,從而顯著提升企業(yè)的工作效率。
1 智能問答技術(shù)介紹
在今天的數(shù)字化時(shí)代,智能問答技術(shù)已經(jīng)成為人機(jī)交互的重要方式。這種技術(shù)運(yùn)用了多種方法,包括自然語言處理(NLP) 、知識(shí)圖譜、機(jī)器學(xué)習(xí)、信息檢索、文本生成、語義理解、數(shù)據(jù)匹配以及推理和邏輯,以實(shí)現(xiàn)高效、準(zhǔn)確的信息獲取和問題解答。問答系統(tǒng)技術(shù)的發(fā)展可以追溯到20世紀(jì)50年代,人們開始使用計(jì)算機(jī)來解決自然語言理解問題。隨著時(shí)間的推移,問答系統(tǒng)技術(shù)逐漸發(fā)展成為一個(gè)獨(dú)立的研究領(lǐng)域,未來的智能問答技術(shù)將更加依賴于以上各技術(shù)的深入應(yīng)用和融合,以實(shí)現(xiàn)更高水平的自動(dòng)化和智能化。當(dāng)前的智能問答技術(shù)主要有基于知識(shí)庫的問答技術(shù)、基于搜索的問答技術(shù)、基于深度學(xué)習(xí)的問答技術(shù)。
1.1 基于知識(shí)庫的問答技術(shù)
知識(shí)庫,也稱為知識(shí)圖譜,是一種表示和組織知識(shí)的方法,本質(zhì)是一種存儲(chǔ)結(jié)構(gòu)化數(shù)據(jù)的語義網(wǎng)絡(luò)。通常知識(shí)庫使用結(jié)構(gòu)化的“<主體,謂詞,客體>”三元組來存儲(chǔ)知識(shí),其中主體和客體可以視為語義網(wǎng)絡(luò)的頂點(diǎn),謂詞則為有向邊。與傳統(tǒng)關(guān)注數(shù)據(jù)間關(guān)系的數(shù)據(jù)庫不同,知識(shí)庫更關(guān)注數(shù)據(jù)內(nèi)部的結(jié)構(gòu)化關(guān)系。
知識(shí)圖譜(知識(shí)庫)可以幫助系統(tǒng)理解和檢索與問題相關(guān)的知識(shí)。近年來,隨著LSTM、注意力機(jī)制等深度學(xué)習(xí)方法的廣泛應(yīng)用,結(jié)合神經(jīng)網(wǎng)絡(luò)方法的知識(shí)庫自動(dòng)問答系統(tǒng)在性能上展現(xiàn)了令人驚艷的效果提升。這種方法通常將神經(jīng)網(wǎng)絡(luò)模型用于不同方法的子步驟上,以貪心思想在每一步驟獲得最優(yōu)解并期望獲得綜合后的最優(yōu)解。然而,這種方法也可能在一定程度上丟失不同環(huán)節(jié)之間的聯(lián)系[2]。
過去基于知識(shí)庫的問答系統(tǒng)多應(yīng)用于垂直域的專用數(shù)據(jù)庫。然而隨著開放域知識(shí)庫的拓展以及深度學(xué)習(xí)等方法的發(fā)展和應(yīng)用,基于開放域知識(shí)庫的問答系統(tǒng)研究取得了較大的進(jìn)展。相比之下,垂直域數(shù)據(jù)庫由于受限于其特殊性質(zhì),無法適配現(xiàn)有表現(xiàn)較好的問答模型,近年來進(jìn)展緩慢[3]。
1.2 基于搜索的問答技術(shù)
基于搜索的問答技術(shù)是一種利用搜索引擎進(jìn)行信息檢索和知識(shí)問答的技術(shù),搜索引擎匯集了大量的知識(shí),但它們主要通過關(guān)鍵詞檢索信息,無法準(zhǔn)確地理解用戶意圖。因此,搜索引擎返回的結(jié)果往往是一組網(wǎng)頁集合,需要用戶進(jìn)行再次篩選。相比之下,問答系統(tǒng)需要構(gòu)建一個(gè)高質(zhì)量的知識(shí)庫作為支撐,而知識(shí)庫的構(gòu)建和管理代價(jià)高昂。因此,我們可以充分發(fā)揮搜索引擎和自動(dòng)問答系統(tǒng)各自的優(yōu)點(diǎn),將二者相結(jié)合[4]。首先是問題分析,問題分析需要通過一定的算法分析,包括問題預(yù)處理、分詞、關(guān)鍵詞提取、消除停用詞、詞性標(biāo)注等[5]。
信息檢索通常采用搜索引擎檢索和數(shù)據(jù)庫檢索兩種方式。搜索引擎是廣泛使用的信息檢索工具,例如百度、Google、360搜索等。而數(shù)據(jù)庫檢索需要通過人工整理建立特定數(shù)據(jù)庫,建立索引,并選擇排序算法進(jìn)行排序,最終通過相似度計(jì)算得到最佳結(jié)果。句子相似度反映了兩個(gè)句子在語義上的匹配度,其計(jì)算方法通常基于句子中詞語的語義信息。句子相似度的取值范圍為[0,1],值越大表示句子越相似,反之則越不相似。
該方式完全依賴于搜索引擎,并且返回的結(jié)果相似度接近,很難取舍,也需要用戶二次篩選。
1.3 基于深度學(xué)習(xí)的問答技術(shù)
基于深度學(xué)習(xí)的問答技術(shù)有很多,MRC(Machine Reading Comprehension)作為自然語言處理領(lǐng)域的核心技術(shù),借助于深度學(xué)習(xí)技術(shù),也獲得了快速發(fā)展[6]。
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks, LCSNTNM)和)等長深短度記神憶經(jīng)神網(wǎng)經(jīng)絡(luò)網(wǎng)由絡(luò)于(更Lo適ng合 Sh未or標(biāo)t-T記er的m 數(shù)Me據(jù)m,or并y,能自動(dòng)學(xué)習(xí)更好的數(shù)據(jù)表征方法,逐漸成為知識(shí)問答系統(tǒng)設(shè)計(jì)的主要算法[7]。
目前,大多數(shù)生成式問答系統(tǒng)都是基于Seq2Seq 和Transformer框架。Seq2Seq最早被提于2014年,屬于encoder-decoder的一種[8],這種方法可以讓系統(tǒng)自動(dòng)從大量數(shù)據(jù)中學(xué)習(xí)自然語言處理的知識(shí),并且可以自動(dòng)生成答案,而無需使用預(yù)定義的模板。這種技術(shù)可以有效地提高答案生成的準(zhǔn)確性和自然度,因?yàn)樗梢愿玫乩斫鈫栴},更好地遵循語法和邏輯規(guī)則,同時(shí)也可以更好地應(yīng)對(duì)各種語言表達(dá)模式。
AttenTtiroann)s,f克orm服er了架傳構(gòu)統(tǒng)通模過型引的限入制自。注自意注力意機(jī)力制機(jī)(S制el允f-許模型在生成每個(gè)輸出時(shí),動(dòng)態(tài)地對(duì)輸入序列的所有位置進(jìn)行關(guān)注和加權(quán)。這樣,模型可以更好地捕捉輸入序列中的上下文依賴關(guān)系,無論距離有多遠(yuǎn)。
這種技術(shù)已經(jīng)在許多領(lǐng)域得到廣泛應(yīng)用,例如智能客服、智能搜索和智能語音助手等,OpenAI推出的商用大模型ChatGPT也采用了Transformer架構(gòu)。但也存在不足,不能完全滿足用戶的提問需求,可能生成一些無意義和錯(cuò)誤的回答,并且需要大量的計(jì)算資源,不能回答準(zhǔn)確性問題和數(shù)據(jù)隱私問題等。
2 基于GPT 的本地文檔智能問答方法
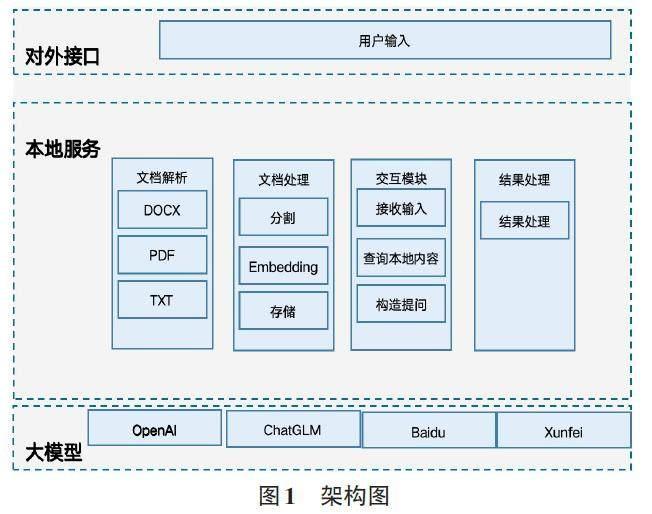
由于上述相關(guān)技術(shù)不能滿足一般企業(yè)和個(gè)人用戶的需求,本文提出一種方法,能滿足一般企業(yè)用戶和個(gè)人用戶的需求,首先獲取用戶提出的問題,在本地文檔中查找與該問題相關(guān)的文檔塊。接下來,將找到的問題和文檔塊一起傳遞給大模型。大模型結(jié)合問題和文檔塊進(jìn)行推理和分析,并生成對(duì)問題的回答。最后,我們對(duì)大模型返回的結(jié)果進(jìn)行處理并展示給用戶。通過這種方法,我們有效地利用了大模型的能力,并且成功地解決了處理本地知識(shí)不足的問題。主要架構(gòu)如下:
1) 對(duì)外接口模塊:該模塊負(fù)責(zé)處理用戶的輸入問題。
2) 文檔解析模塊:該模塊支持解析多種文檔格式,如DOCX、PDF、TXT 等,可加載指定目錄下的文檔,將其解析并讀取到內(nèi)存中進(jìn)行處理。
3) 文檔處理模塊:該模塊負(fù)責(zé)對(duì)文檔進(jìn)行處理。由于大模型的輸入有限制,需要對(duì)文檔解析的數(shù)據(jù)進(jìn)行分割,然后進(jìn)行向量化并存儲(chǔ)到向量數(shù)據(jù)庫中。
4) 交互模塊:該模塊接收用戶的輸入,當(dāng)用戶輸入查詢的問題時(shí),把問題轉(zhuǎn)為向量然后從向量數(shù)據(jù)庫中查詢相近的文本塊,并構(gòu)造問題,將問題和文本塊一起傳遞到大模型中。
5) 結(jié)果處理模塊:該模塊負(fù)責(zé)處理大模型返回的結(jié)果,并以更容易理解的方式返回給用戶。
6) 大模型模塊:該模塊主要調(diào)用各種大型語言模型API,目前支持的大模型包括OpenAI 的ChatGPT、百度的文心一言、清華大學(xué)的ChatGLM和訊飛的星火大模型。
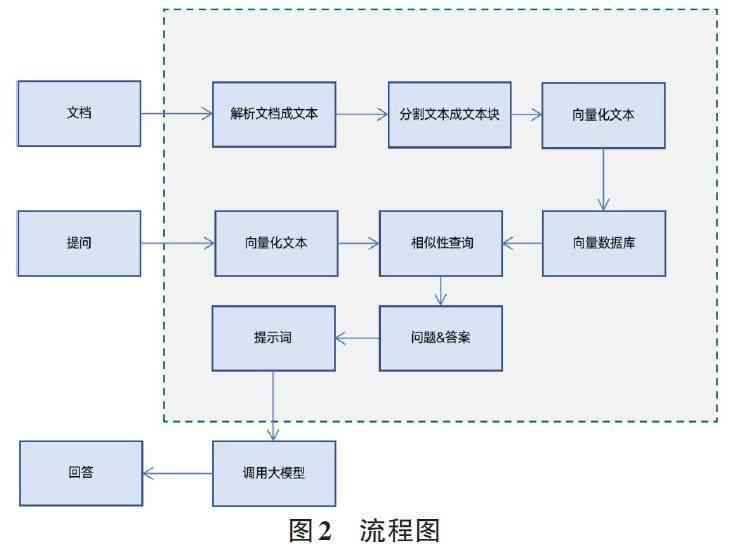
主要的流程圖如下:
整個(gè)流程主要分為三部分,第一部分:加載用戶的文檔,并將其轉(zhuǎn)化為文本形式,根據(jù)大型語言模型的最大輸入限制,將文本分割成文本塊,并使用向量化的方法將它們存儲(chǔ)在數(shù)據(jù)庫中。第二部分:當(dāng)用戶提出問題后,我們首先將用戶的問題轉(zhuǎn)化為向量形式,然后在向量數(shù)據(jù)庫中搜索,根據(jù)相似度查詢相似的文本塊。之后,將用戶的提問和相似度文本塊一起發(fā)送到大型語言模型中進(jìn)行分析。第三部分:當(dāng)大型語言模型收到用戶的提問和文本塊時(shí),會(huì)返回結(jié)果,最后對(duì)結(jié)果進(jìn)行處理,并將其返回給用戶。通過這樣的流程,就實(shí)現(xiàn)了對(duì)企業(yè)知識(shí)庫的智能化問答。
3 應(yīng)用研究
3.1 實(shí)驗(yàn)設(shè)計(jì)和數(shù)據(jù)收集
本文實(shí)驗(yàn)編程語言采用Python,Python不僅語法簡潔明了,易讀和易于學(xué)習(xí),且擁有強(qiáng)大的標(biāo)準(zhǔn)庫和第三方庫支持,使得開發(fā)人員可以快速地構(gòu)建各種應(yīng)用程序。大模型采用OpenAI的ChatGPT模型,該模型是一個(gè)基于Transformer神經(jīng)網(wǎng)絡(luò)架構(gòu)的預(yù)訓(xùn)練語言模型,是在大量的互聯(lián)網(wǎng)文本數(shù)據(jù)上訓(xùn)練得到的模型,它有1750億個(gè)參數(shù),在各種語言任務(wù)中都表現(xiàn)出了很高的性能,且提供了向量化API和提問的API。
向量數(shù)據(jù)庫采用了Chroma,向量數(shù)據(jù)庫Chroma 是一個(gè)高性能的向量檢索數(shù)據(jù)庫,它專門設(shè)計(jì)用于存儲(chǔ)和檢索大規(guī)模向量數(shù)據(jù)。Chroma的主要特點(diǎn)是能夠快速存儲(chǔ)和檢索高維向量數(shù)據(jù),而且能夠高效地處理復(fù)雜的查詢操作。
3.2 編碼實(shí)現(xiàn)(Python 偽代碼)
功能實(shí)現(xiàn)主要分為以下6個(gè)功能模塊:
1) 數(shù)據(jù)導(dǎo)入和準(zhǔn)備階段:導(dǎo)入所需的Python 模塊,包括 text_splitter、chroma、openai_embeddings 和 openai,打開文本文件 data.txt 并讀取其內(nèi)容,使用字符分割器 TextSplitter 將大文本內(nèi)容拆分為小塊文本。
2) 文本分塊處理:創(chuàng)建TextSplitter對(duì)象,并使用其 split_text 方法將文本內(nèi)容拆分成小塊(chunks) 。這些小塊將用于后續(xù)的文本處理。
3 ) 文本嵌處和相似度搜索:創(chuàng)建OpenAIEmbed?dings對(duì)象以處理文本嵌入,這有助于將文本轉(zhuǎn)換為向量形式以進(jìn)行相似度比較。使用 Chroma 對(duì)象執(zhí)行相似度搜索,將查詢字符串與分塊文本進(jìn)行比較,并返回與查詢字符串相似的文本塊。
4) 問題回答鏈:創(chuàng)建問題回答鏈,使用 OpenAI 模型用于回答問題。
5) 執(zhí)行問題回答:將相似度搜索的結(jié)果(即相似的文本塊 docs) 和查詢字符串 (query) 傳遞給問題回答鏈。問題回答鏈將使用配置的模型來生成回答。
6) 結(jié)果輸出:最后將問題回答的結(jié)果輸出。對(duì)應(yīng)功能模塊的Python偽代碼如下:
#導(dǎo)入所需庫和模塊
導(dǎo)入OpenAIEmbeddings
導(dǎo)入text_splitter
導(dǎo)入Chroma
#讀取文本文件
打開文件′./data.txt′
fcontent=f.read()
#使用字符分割器將文本拆分為小塊
text_splitter=創(chuàng)建 text_splitter(chunk_size= 1000,chunk_overlap=0)
Texts=text_splitter.拆分文本(content)
#創(chuàng)建embedding
Embedding=OpenAIEmbeddings()
#使用文本創(chuàng)建Chroma對(duì)象
docsearch=Chroma(texts,embeddings)
#設(shè)置查詢字符
Query="南京航空航天大學(xué)金城學(xué)院建立于哪一年" #使用查詢字符串進(jìn)行相似度搜索
#使用查詢字符串進(jìn)行相似度搜索
Docs=docsearch.相似度搜索(query)
#加載問題以及相關(guān)文檔塊
Chain=加載問題回答鏈(創(chuàng)建OpenAI(temperature=0,chain_type="stuff")
#運(yùn)行問題以及相關(guān)文檔塊
OpenAI.run(input_documents=docs, question=query)
3.3 實(shí)驗(yàn)結(jié)果分析
實(shí)驗(yàn)數(shù)據(jù)集采用一篇文檔,內(nèi)容如下:南京航空航天大學(xué)金城學(xué)院成立于1999年,學(xué)校位于江蘇省南京市,現(xiàn)有全日制在校本科生18 000余人,校園占地面積近千畝,建筑總面積30余萬平方米。擁有學(xué)術(shù)交流中心、科研實(shí)驗(yàn)中心、計(jì)算機(jī)中心、藝術(shù)中心及現(xiàn)代化運(yùn)動(dòng)場(chǎng)等教學(xué)生活設(shè)施。智能化圖書館能同時(shí)容納6 000人閱讀和學(xué)習(xí)。
學(xué)校秉持“高端化、國際化、個(gè)性化”的人才培養(yǎng)理念,下設(shè)7個(gè)學(xué)院和基礎(chǔ)教學(xué)部,開設(shè)33個(gè)本科專業(yè)(含方向)。其中,會(huì)計(jì)學(xué)專業(yè)是國家級(jí)一流本科專業(yè)建設(shè)點(diǎn),電氣工程及其自動(dòng)化、車輛工程和信息工程專業(yè)則是省級(jí)一流本科專業(yè)建設(shè)點(diǎn)。機(jī)械電子工程、信息工程、英語專業(yè)獲評(píng)江蘇省獨(dú)立學(xué)院“星級(jí)專業(yè)”。
學(xué)校堅(jiān)持開放辦學(xué),注重學(xué)生國際化能力的培養(yǎng),先后與美國、英國等12個(gè)國家的256所大學(xué),開設(shè)“本碩直通”“微留學(xué)”和“云游學(xué)”等項(xiàng)目,培養(yǎng)造就具有中國情懷、世界眼光的未來新型高端人才。
學(xué)校注重學(xué)生的創(chuàng)新能力培養(yǎng),促進(jìn)學(xué)生的多元化、個(gè)性化發(fā)展,全面實(shí)施“創(chuàng)意、創(chuàng)造、創(chuàng)業(yè)”創(chuàng)新人才培養(yǎng)模式,大力開展科技創(chuàng)新競賽活動(dòng)。在多項(xiàng)全國性重大競賽中接連取得突破,獲獎(jiǎng)人數(shù)和獎(jiǎng)項(xiàng)等級(jí)位居全國同類院校前列。近年來,獲國家級(jí)獎(jiǎng)1 352 項(xiàng),一等獎(jiǎng)412項(xiàng);獲省部級(jí)獎(jiǎng)2 236項(xiàng)。在全國重大競賽中表現(xiàn)突出,曾在全國大學(xué)生機(jī)器人大賽Robo? Master、全國大學(xué)生電子設(shè)計(jì)競賽、全國大學(xué)生先進(jìn)成圖技術(shù)與產(chǎn)品信息建模創(chuàng)新大賽、全國大學(xué)生嵌入式芯片與系統(tǒng)設(shè)計(jì)競賽等比賽中榮獲一等獎(jiǎng)。
為了準(zhǔn)確比較,基于文檔內(nèi)容構(gòu)造10個(gè)客觀問題如下:
1) 南京航空航天大學(xué)金城學(xué)院始建于哪一年?
2) 南京航空航天大學(xué)金城學(xué)院有全日制在校本科生多少?
3) 南京航空航天大學(xué)金城學(xué)院建筑面積多少?
4) 南京航空航天大學(xué)金城學(xué)院智能化圖書館能同時(shí)容納多少人閱讀和學(xué)習(xí)?
5) 南京航空航天大學(xué)金城學(xué)院有幾個(gè)學(xué)院?
6) 南京航空航天大學(xué)金城學(xué)院有幾個(gè)本科專業(yè)?
7) 南京航空航天大學(xué)金城學(xué)院與多少個(gè)國家開設(shè)本碩直通項(xiàng)目?
8) 南京航空航天大學(xué)金城學(xué)院與多少所大學(xué)開設(shè)本碩直通項(xiàng)目?
9) 南京航空航天大學(xué)金城學(xué)院近年來獲得國家級(jí)獎(jiǎng)項(xiàng)多少?
10) 南京航空航天大學(xué)金城學(xué)院近年來獲得省部級(jí)獎(jiǎng)項(xiàng)多少?
針對(duì)該文檔的10個(gè)客觀問題實(shí)驗(yàn)結(jié)果見表1。
通過實(shí)驗(yàn)可以發(fā)現(xiàn),本方法在回答問題的準(zhǔn)確率方面達(dá)到了100%,而其他方法,包括搜索引擎和大型語言模型,準(zhǔn)確率均較低。在本地文檔處理方面,本方法不僅可以更加準(zhǔn)確地回答問題;并且相對(duì)于搜索引擎還需要多次篩選,本方法可以更快速地找到準(zhǔn)確答案,是一種高效、準(zhǔn)確的解決方案,特別適用于本地文檔處理和回答問題。
4 結(jié)論與展望
本研究提出了一種解決企業(yè)本地知識(shí)庫不夠智能化的方法,通過對(duì)公司內(nèi)部文檔進(jìn)行智能化處理,包括公司的流程、規(guī)章制度、財(cái)務(wù)等各方面的知識(shí),并可對(duì)公司沉淀的知識(shí)進(jìn)行總結(jié),從而實(shí)現(xiàn)公司的智能化問答。相對(duì)于大型語言模型,本方法能夠提供準(zhǔn)確的知識(shí)搜索。為企業(yè)智能化的知識(shí)管理和問題解決提供了新的思路和方法。我們相信,這一方法將對(duì)企業(yè)的效率和競爭力產(chǎn)生積極影響,并在知識(shí)管理領(lǐng)域引領(lǐng)未來的研究方向。
參考文獻(xiàn):
[1] CARLINI N, TRAMER F, WALLACE E, et al. Extracting?training data from large language models[C]. Berkeley, CA:USENIX Association. 2021:2633?2650.
[2] 胡楠. 基于開放領(lǐng)域知識(shí)庫的自動(dòng)問答研究[D]. 武漢:華中科技大學(xué),2019.
[3] 李東奇,李明鑫,張瀟. 基于知識(shí)庫的開放域問答研究[J]. 電腦知識(shí)與技術(shù),2020,16(36):179-181.
[4] 石鳳貴. 基于百度網(wǎng)頁的中文自動(dòng)問答應(yīng)用研究[J]. 現(xiàn)代計(jì)算機(jī),2020(8):104-108.
[5] 姚元杰,龔毅光,劉佳,等. 基于深度學(xué)習(xí)的智能問答系統(tǒng)綜述[J]. 計(jì)算機(jī)系統(tǒng)應(yīng)用,2023,32(4):1-15.
[6] 李舟軍,王昌寶. 基于深度學(xué)習(xí)的機(jī)器閱讀理解綜述[J]. 計(jì)算機(jī)科學(xué),2019,46(7):7-12.
[7] 朱建楠,梁玉琦,顧復(fù),等. 基于深度學(xué)習(xí)的機(jī)械智能制造知識(shí)問答系統(tǒng)設(shè)計(jì)[J]. 計(jì)算機(jī)集成制造系統(tǒng),2019,25(5):1161-1168.
[8] CHO K,VAN MERRIENBOER B,GULCEHRE C,et al. Learn?ing Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. ArXiv e-Prints,2014:arXiv:1406. 1078.
【通聯(lián)編輯:王力】

- 電腦知識(shí)與技術(shù)的其它文章
- 校企三共協(xié)同培育“新工科”人才模式探索與實(shí)踐
- 基于Matlab 軟件的傅里葉級(jí)數(shù)及其應(yīng)用的教學(xué)實(shí)踐探索
- 基于EMU8086 的微機(jī)原理教學(xué)實(shí)踐探索
- 基于混合式教學(xué)模式的前端框架應(yīng)用開發(fā)課程教學(xué)改革與實(shí)踐研究
- 信息技術(shù)公共基礎(chǔ)課程思政全流程建設(shè)研究與實(shí)踐
- “項(xiàng)目實(shí)訓(xùn)”自動(dòng)評(píng)分系統(tǒng)的設(shè)計(jì)與開發(fā)