Text-to-SQL文本信息處理技術研究綜述
2024-07-20 00:00:00彭鈺寒喬少杰薛騏李江敏謝添丞徐康鐳冉黎瓊曾少北
無線電工程 2024年5期


摘 要:信號與信息處理的需求日益增加,離不開數據處理技術,數據處理需要數據庫的支持,然而沒有經過訓練的使用者會因為不熟悉數據庫操作產生諸多問題。文本轉結構化查詢語言(Text to Structured Query Language,Text-to-SQL)的出現,使用戶無需掌握結構化查詢語言(Structured Query Language,SQL) 也能夠熟練操作數據庫。介紹Text-to-SQL 的研究背景及面臨的挑戰;介紹Text-to-SQL 關鍵技術、基準數據集、模型演變及最新研究進展,關鍵技術包括Transformer 等主流技術,用于模型訓練的基準數據集包括WikiSQL 和Spider;介紹Text-to-SQL 不同階段模型的特點,詳細闡述Text-to-SQL 最新研究成果的工作原理,包括模型構建、解析器設計及數據集生成;總結Text-to-SQL 未來的發展方向及研究重點。
關鍵詞:文本轉結構化查詢語言;解析器;文本信息處理;數據庫;深度學習
中圖分類號:TP391. 1 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3106(2024)05-1053-10
0 引言
隨著信號與信息處理領域(圖像處理、文本處理、數據處理、語音處理等)研究工作的快速發展,需要考慮如何高效和準確地處理、查詢、存儲數據信息,因此數據庫成為首選工具。專業人員可以熟練使用結構化查詢語言(Structured Query Language,SQL)對數據庫中的信息進行增刪改查,但是越來越多的應用開始投入到信號與信息處理領域,并非所有使用者都擁有專業的數據庫使用技巧,所以將用戶輸入的文本自動轉換為機器可執行SQL 的文本轉結構化查詢語言(Text to Structured Query Language,TexttoSQL)文本信息處理技術產生并蓬勃發展[1]。
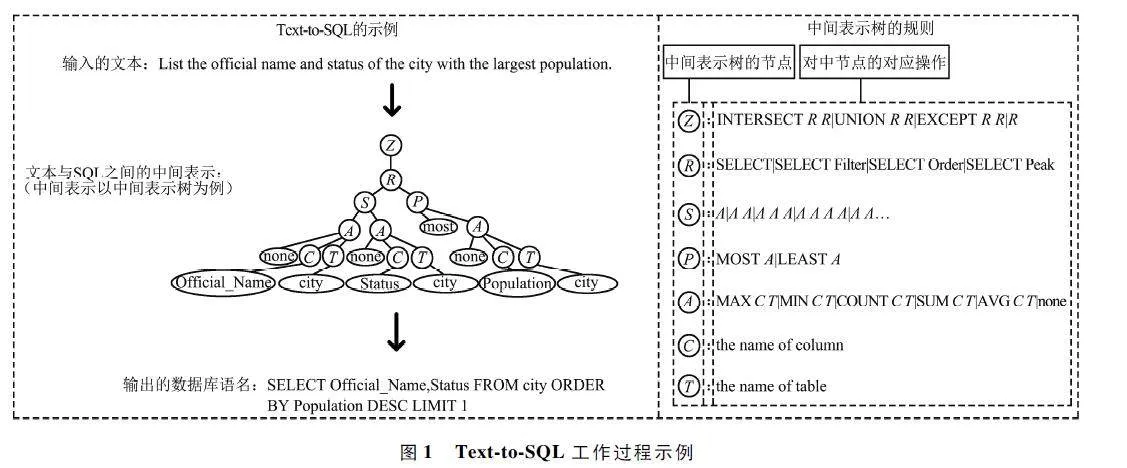
Text-to-SQL 研究面臨的挑戰主要集中在3 個方面:① 對輸入的文本進行預處理,理解輸入的自然語言的含義,提取文本涉及的數據庫關鍵字、列名和表名,減小模型訓練難度;② 將經過預處理的文本轉換成一種中間表示,SQL 的作用并非是方便閱讀,而是提高計算機處理數據庫的效率,它與文本之間存在巨大的差距,所以需要建立文本與數據庫語句之間的映射關系,提高文本轉化數據庫語句的效率;③ 將中間表示轉化為最終的SQL 語句。
傳統的Text-to-SQL 方法雖然有效,但需要耗費大量的人力,需要提前為各種場景下的SQL 設置轉換模板,過程十分繁瑣[2],并且傳統方法沒有解決上述Text-to-SQL 面臨的挑戰,轉換模板沒有設置文本與SQL 之間的中間表示,導致文本與SQL 之間的轉換效率低下。隨著近年來深度學習的崛起,深度學習逐漸運用到Text-to-SQL 中。在眾多深度學習模型中,循環神經網絡模型在這一領域的效果最佳,因為文本語言和SQL 都可以當作序列信息,需要結合前后文信息預測當前信息,所以主要用于處理序列信息(文本、視頻和音頻等)的循環神經網絡模型在Text-to-SQL 研究中效果較好。
1 關鍵技術
文本和SQL 都是序列信息,使用處理序列信息的序列模型訓練文本效果較好,本節針對常見的序列模型以及模型評判標準進行介紹。Text-to-SQL工作過程示例如圖1 所示。
長短期記憶(Long ShortTerm Memory,LSTM)[3]神經網絡是循環神經網絡的變體,通過內部的4 類門控單元:輸入門控單元、遺忘門控單元、候選記憶門控單元和輸出門控單元對序列信息進行篩選。LSTM 單元在循環神經網絡基礎上,除了隱藏狀態(對應短期記憶),還加入了記憶單元(對應長期記憶),解決了序列信息作為輸入面臨的長期信息保存和短期輸入缺失的問題。
門控循環單元(Gated Recurrent Unit,GRU)[4]是LSTM 神經網絡的簡化版本,將LSTM 神經網絡內部的4 類門控單元簡化為2 個門控單元:重置門控單元和更新門控單元。雖然GRU 針對簡易輸入的訓練速度更快、效果更好,但面對輸入文本包含復雜語法和語義信息的情況,LSTM 神經網絡是更好的選擇。
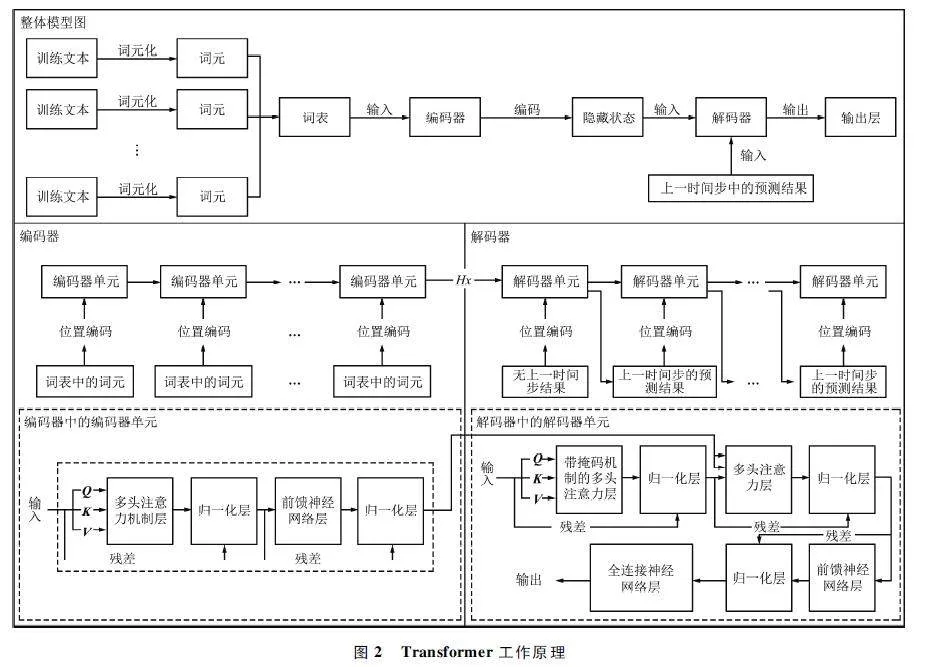
Transformer[5]模型是當前主流深度學習模型,諸多文本處理工作都是基于Transformer 完成的。Transformer 是一種基于編碼器- 解碼器的架構,編碼器用于編碼輸入序列,將輸入序列變成向量形式并添加位置編碼,然后將其編碼為隱藏狀態輸出到解碼器中。解碼器除了接收編碼器的輸出,在每一個當前時間步處理序列信息時,還會接受來自上一個時間步的輸出,解碼器也會將輸入信息轉變為向量并添加位置編碼。基于Trans-former 模型的Text-to-SQL 模型工作原理如圖2所示。
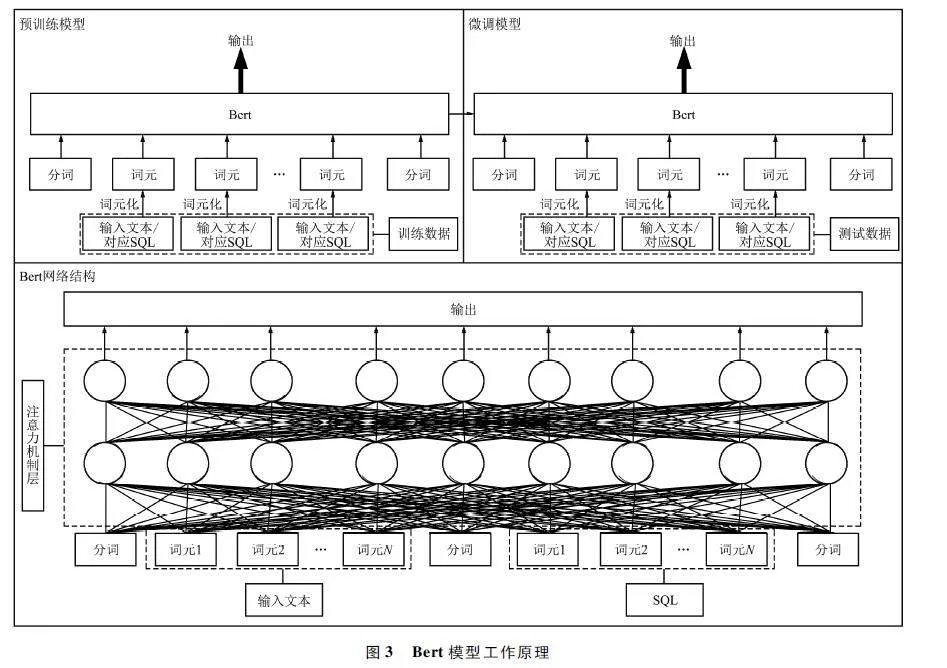
Bert[6]模型是Transformer 模型的變體,Trans-former 基于編碼器-解碼器架構,Bert 模型雖然僅有編碼器架構,但其內部的參數是Transformer 的數倍,它是一種預訓練微調模型,設置好預訓練任務對模型進行訓練,訓練后的模型僅需要針對不同的任務對輸出層進行微調。Bert 模型具有極高的泛化性,基于Bert 的Text-to-SQL 模型工作原理如圖3所示。
域外數據(Out of Domain)。數據集分為訓練集、開發集和測試集。訓練集用于訓練模型,開發集用于驗證模型,測試集用于最后測試模型。因為測試集只能測試一次,不能用于多次訓練測試模型好壞,所以在數據集比較大的情況下,可以劃分出開發集對模型訓練效果進行驗證。域外數據是指訓練集與開發集中不同的部分,過多會導致訓練難度變大。
BLEU 分數(Bilingual Evaluation UnderstudyScore)[7]用于評估序列模型語義解析的好壞,將文本解析為數據庫語句的好壞程度通常用BLEU 分數去評估。分數值介于0 ~ 1,越接近1 代表解析結果越接近參考值。除了BLEU 分數,還有METEOR、ROUGE 和PPL 等標準也可以評價解析模型的好壞,根據不同需求選擇不同的評價指標。
2 基準數據集
高質量的數據集能夠直接決定模型訓練的效果,在Text-to-SQL 領域,用于絕大多數模型檢驗常用的基準數據集為WikiSQL[8]和Spider[9]數據集,其為大規模、多領域的基準測試集,也是使用最為廣泛的基準數據集。
WikiSQL 是目前文本轉數據庫語句領域使用最頻繁的基準數據集,包含約25 000 個維基百科數據表和80 000 個由人工創建的自然語言與SQL 句子對,數據集中每一行由一個自然語言文本、一個文本對應的SQL 查詢還有SQL 查詢中涉及的列和表組成。WikiSQL 中的SQL 復雜性較低,因為其內部沒有使用復雜的SQL 子句,如:“JOIN”“GROUP BY”“ORDER BY”“UNION”“INTERSECTION”等,且在執行查詢語句時不允許在單個查詢中選擇多個列。因此在訓練模型時,WikiSQL 的訓練難度比較低,這是WikiSQL 使用率最高的原因。
Spider 是一個大規模的、復雜的跨領域數據集,包含來自138 個不同領域的200 多個關系數據庫。相較于WikiSQL,Spider 數據集具有更多復雜的嵌套查詢子句、更多的域外數據,讓訓練更加困難。經過Spider 訓練的機器學習模型可以變得更加泛化,研究人員廣泛依賴它訓練可以生成復雜SQL 查詢的模型,適應更多的任務。還有數據集針對Spider做了擴展,用于訓練指定任務。Spider-dk 擴展了Spider,用于訓練跨領域泛化模型,探索模型在面對不同領域中專業名詞的表現;Spider-syn 側重于訓練模型區分同義詞、反義詞的性能。
此外,其他數據集,例如:KaggleDBQA 是一個跨域數據集[10],雖然規模比不上WikiSQL 和Spider,但它是從Kaggle 中提取出來的,包含相當多工業界的真實數據。
3 模型演變
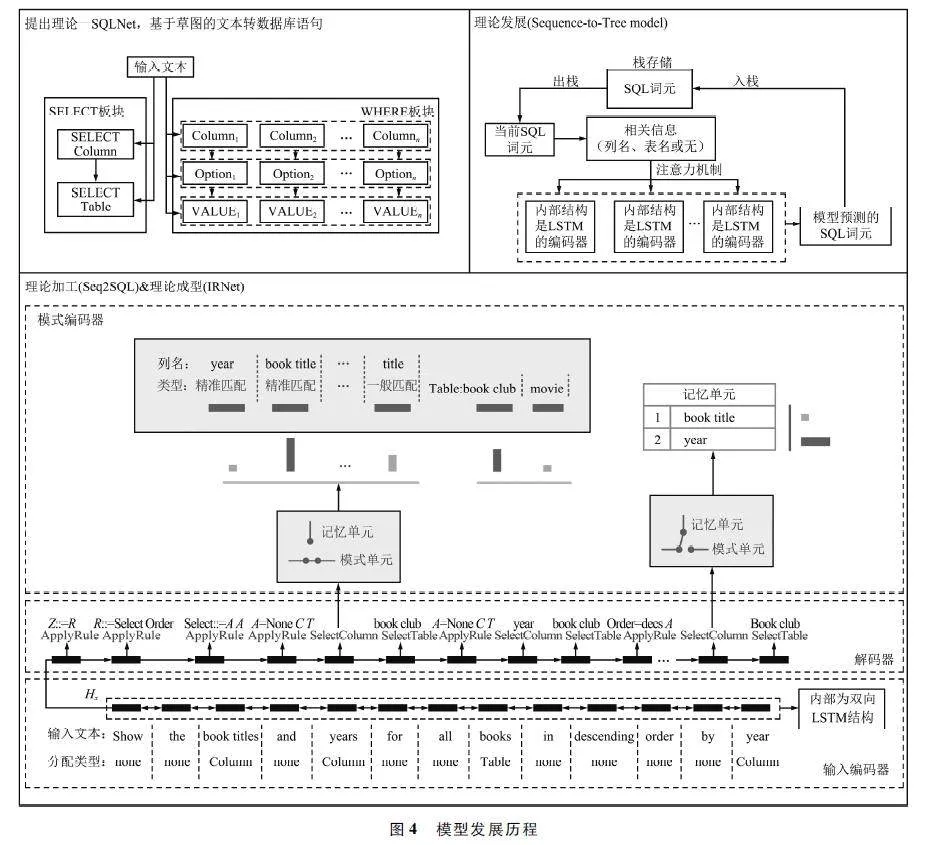
本節將按時間演變介紹文本轉數據庫領域的模型,模型發展歷程如圖4 所示。
(1)理論提出
在文本轉數據庫語句領域,Li 等[11]提出的SQLNet 是較早成理論體系的模型,該模型使用的方法基于草圖技術,草圖中包含數據庫語句的關鍵字、列名和表名,通過這個草圖,SQLNet 僅需往草圖留空處添加信息,就可以實現自然語言到數據庫語句的轉換。
(2)理論發展
基于SQLNet,Min 等[12]提出一種樹型結構返回輸出的模型———Sequence-to-Tree。該模型可以看作是序列到樹的模型,使用LSTM 網絡編碼器對輸入問題進行編碼,在編碼器處理輸入序列后,通過解碼器輸出樹型結構的SQL 查詢語句。模型通過識別單個詞元來理解輸入,并將其轉化為樹型結構,樹節點上包括關鍵字(如SELECT、WHERE)、表名和列名。
(3)理論加工
這一階段數據庫領域開始大規模使用深度神經網絡構建模型,采用中間表示生成查詢,顯著提高了計算效率。Kevin 等[13]提出Sequence-to-SQL 模型以深度學習模型為基準,引入了強化學習方法,將交叉熵損失和數據庫在運行中執行查詢的獎勵函數作為模型評價指標。該模型內部采用了一種增強指針網絡,該網絡是一種能夠改變輸出序列長度的網絡架構,相較于循環神經網絡輸入輸出的序列長度需要一一對應,增強指針網絡能使模型具有更好的性能。Sequence-to-SQL 模型由聚合分類器、SELECT組件和WHERE 組件構成。
Sequence-to-SQL 模型對查詢的聚合操作進行分類,將輸入的文本數據分類為最大最小升序降序這類約束條件。聚類分類器內部采用的是編碼器-解碼器架構,編碼器內部使用了雙向LSTM 網絡,解碼器內部采用普通的LSTM;SELECT 組件用于處理輸入文本中的列名和表名;WHERE 組件,用于確定用于轉換的數據庫語句約束條件。
(4)理論成型
這一階段文本轉數據庫語句技術趨于成熟,開始運用復雜跨域文本數據集訓練模型。大部分模型訓練選用基準數據集WikiSQL 進行訓練,但Guo等[14]提出的IRNet 選用Spider 數據集訓練模型。相較于Spider 數據集,WikiSQL 的生態更加成熟,沒有復雜的嵌套查詢語句和大量域外數據,簡化了模型的訓練過程,但Guo 等[14]的目的是訓練適用于復雜且有跨域文本的數據庫,所以選用更為復雜的Spider 對模型進行訓練。
IRNet 是基于編碼器-解碼器架構的模型,工作原理包括3 個關鍵步驟:① 編碼器,分為問題編碼器(Question Encoder)和模式編碼器(Schema En-coder)。問題編碼器內部是雙向LSTM 神經網絡,負責預處理輸入數據,將輸入的文本詞元化,并使用Ngram 算法對文本中出現的列名和表名賦予一個類,如果詞元是數據庫中的列則分配一個“Column”,如果詞元是數據庫中的表則分配一個“Table”;模式編碼器負責為N-gram 算法中識別的列名、表名的準確性匹配一個類型。其中有2 個控制單元,模式單元和記憶單元,模式單元負責為N-gram 算法識別正確的列名和表名分配一個“ExactMatch”類型,沒有正確識別的列名和表名分配一個“Partial Match”類型,分配好類型后將這些信息送入記憶單元進行存儲。② 解碼器,負責接收問題編碼器的輸出,將其作為自身的隱藏狀態,將文本數據轉化為樹型結構中間表示樹。解碼器中有一套樹型結構的轉化規則,樹中節點用字母Z 表示數據庫中的交集(intersect)、并集(union)和補集(except)操作,沒有這些操作時也用字母Z 表示;樹中結點用字母R 表示“SELECT”關鍵字;樹中結點“Select”可以分化出一個或多個節點;樹中結點“Order”對應升序(asc)和降序(desc);樹中結點“Superlative”對應最大(most)和最小(least);樹中結點“Filter”表示過濾操作,對應條件關鍵字,比如:大于、小于、等于、be-tween、not in 等;樹中結點“A”表示可以分化出列和表,列和表分別用字母C 和T 表示。③ 輸出層,遍歷解碼器輸出的樹將其轉化為最終的SQL 語句。
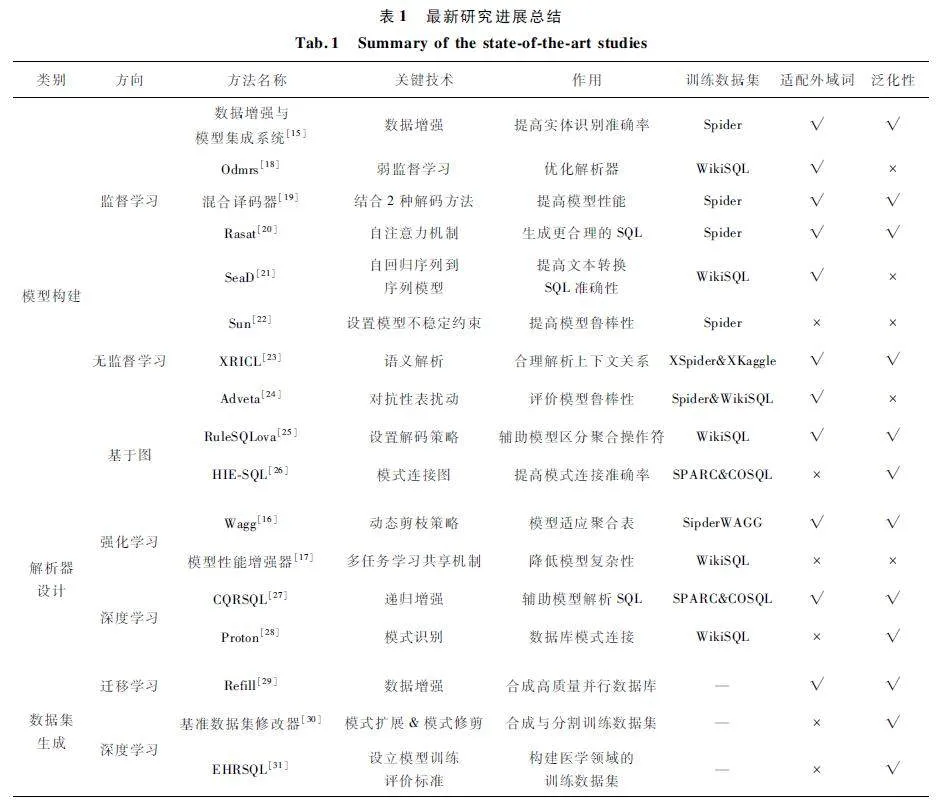
4 最新研究進展
Octavian 等[15]以編碼器-解碼器架構為原型,提出了一個結合自動訓練數據增強及多模型集成技術的系統,該系統可以處理和提取輸入問題中的特定信息,從數據庫中將詞元連接到特定的表和列。編碼器中常用的實體識別(Name Entity Recognition)模塊在該模型中被替換成消除歧義字典模塊(Dis-ambiguation Dictionary Module),用于提供模型所需要的關鍵信息。系統具有以下優勢:① 集成了種子訓練數據增強技術,基于被稱為種子的初始訓練語料庫,利用這種方法生成更大的訓練集;② 使用不同的自動生成訓練數據集,訓練不同的模型,并使用集成技術來分析組合多個模型的輸出。
Li 等[16]提出了用于聚合表內文本到數據庫語句轉換的方法———Wagg,該方法使用了一種動態修剪策略對多個聚合表中的不相關項進行修剪,大大減少模型訓練的時間成本。聚合是一種數據批處理的操作,可以將數據分組,對每組數據執行多種批處理操作。聚合表為經過聚合處理的表,常用于頻繁使用查詢操作的情況。目前針對聚合表的文本轉數據庫語句方向的研究相對較少,主要面臨2 個方面的挑戰:① 聚合表意味著更復雜的映射關系,在文本與數據庫語句進行轉換時面臨更多歧義;② 目前的深度學習模型處理聚合表會產生巨大的時間成本。Li 等[16]的方法使用動態修剪策略克服了上述困難,讓聚合表這種復雜的數據庫表可以輸入模型進行訓練。
W ei 等[17]在解碼器中引入了多任務學習的共享機制,通過不同的子任務共享同一個解碼器來實現,可以有效降低模型的復雜性,并且允許不同子任務在訓練過程中共享知識,使模型能夠更好地學習到不同子任務之間的依賴關系。文本轉數據庫語句使用基于編碼器-解碼器架構的模型時,普通解碼器學習不同子任務之間相關性的能力有限,過于復雜的解碼器會增加訓練成本。文獻[17]的方法避免了上面2 種情況,保證模型訓練效果的同時避免了過高的模型復雜性。
Tomer 等[18]提出了一種基于弱監督學習的方法———Odmrs 來訓練模型中文本轉數據庫語句的解析器,其未使用手動標記的高質量數據作為訓練標準,而是使用非專業用戶提供的數據進行訓練,證明了模型強大的泛化性。解析器中合成SQL 的算法流程,如算法1 所示。
算法1 的工作原理為:定義一個數組mapped 用于后續存儲變量(第1 行);利用啟發式函數f 將xi表達為結構化形式Mi,根據模板推斷Mi 中的具體操作(第2 行);然后通過弱監督學習模型將結構化表示Mi 映射到數組中(第3 ~ 14 行),針對每個結構化的表示Mi,提取出其中的列名和相關性強的SQL 查詢,并創建數組join(第3 ~ 7 行)。根據列與列之間的相關性和構建的結構化模板去生成SQL查詢(第8 ~ 14 行),JOINP 函數用于連接表之間的不同列,OPTYPE 函數用于從結構化模板中推斷Mi中的具體數據庫操作,MAPSQL 函數將Mi 映射到SQL 中;最后返回SQL 查詢(第15 行)。Text-to-SQL 最新研究進展總結如表1 所示。
Geunyeong 等[19]提出了一種混合譯碼器,為SQL 生成構建出基本結構,結構中包含每個查詢過程中可能需要使用的自行定義數據庫語句組件,混合解碼器依據該結構依次生成SQL 查詢。Qi 等[20]提出了一種基于Transformer 的架構,利用Transformer 中的自注意力機制識別表與表之間的關系,將模式連接和模式編碼等關系結構引入模型,讓模型生成更符合邏輯的SQL。Xu 等[21]提出一種基于循環神經網絡的方法———SeaD,將自回歸模型與序列到序列模型結合,過濾輸入文本,克服解碼過程對模型的限制,提高文本到SQL 的準確性。Qin等[22]設計了一種基于神經網絡的方法———Sun,在Sun 中使用一種啟發式的約束規則來限制模型輸出,提高模型的泛化性和穩定性。Shi 等[23]針對跨語言文本到SQL 語義解析的問題,提出一種基于遷移學習的文本解析模型———Transfer Learning inCross-Lingual(XRICL),利用基于英文數據集的訓練成果遷移到其他語言模型中。Pi 等[24]設計了一種名為Adveta 的系統,用于測試Text-to-SQL 模型魯棒性,使用Adversarial Table Perturbation(ATP)指標評估模型魯棒性,該系統內部結構主要是對抗生成框架,在監測模型魯棒性的同時也能對模型進行改進。Han 等[25]提出一種基于圖的方法———RuleSQLova,偏向于處理數據庫中的聚合操作符。Zheng 等[26]提出了一種基于模式連接圖的方法———HIESQL,該方法增強輸入文本與SQL 之間的連接,提升了模式連接的準確率。Xiao 等[27]基于上下文相關文本序列問題提出Conversation Question Reformulation(CQR)方法,該方法基于遞歸增強模式來生成文本與SQL 之間的中間表示,讓模型充分理解上下文語義,增強SQL 的解析能力。Wang 等[28]提出了一種基于大規模預訓練語言模型來誘導解析器對輸入文本進行處理的方法———Proton,該方法是無監督學習模型,無需對輸入文本進行預處理。Abhijeet等[29]提出了一種名為REFILL 的框架,用于合成高質量、多樣化的并行數據集,REFILL 框架從現有模式中檢索和添加文本查詢,提高模型訓練效率。Chen 等[30]提出了一種基準數據集修改器,用于預訓練基準數據集SQuALL 時進行分割,該解析器由模式擴展和模式修剪組成,在訓練過程中對輸入數據SQuALL 進行合成與分割。Lee 等[31]設計了一種符合醫院應用場景的數據庫———Electronic HealthRecords(EHRs),用于醫學場景下的模型訓練。
5 結束語
本文綜述了Text-to-SQL 文本處理技術最新研究成果,包括關鍵技術、基準數據集、模型演變和最新研究進展。關鍵技術包括LSTM、GRU、Transformer、Bert、域外數據和BLEU 分數等技術;基準數據集主要介紹了WikiSQL 和Spider;模型演變從4 個階段詳述了Text-to-SQL 技術,包括理論提出、理論發展、理論加工和理論成型;最新研究進展從模型構建、解析器設計和數據集生成3 個方面概述了最新研究成果。
在模型的構建上,雖然大部分是基于Transformer 的編碼器-解碼器架構模型,但是ChatGenerative Pe-trained Transformer(ChatGPT)模型的成功預示著這類架構具有很大的潛力,未來仍可以針對該結構進行改良,從不同角度提高模型性能。對于解析器而言,未來可以設計基于圖神經網絡的模型,利用圖中節點之間的關系解析上下文,增加文本與SQL 之間的轉換效率。目前常用的數據集主要包括WikiSQL 和Spider,數據集是決定模型訓練效果好壞的重要因素,未來可以針對不同業務場景構建出適合的基準數據集用于該領域模型訓練,如針對性的構建適合法律、教育和互聯網等環境的訓練數據集,讓模型在上述領域具有更好的性能。
此外,文本信息處理涉及隱私數據,隱私保護問題是不可忽視的,通常獲取的文本信息是公開的、性比較低的,不能擅自使用未公開或是私密性高的數據,未來可以制定相關規范或是制定更多的基準數據集,吸引更多的研究者投入Text-to-SQL 領域的研究。
參考文獻
[1] GEORGEK M,GEORGIA K. A Survey on Deep LearningApproaches for TexttoSQL[J]. The International Journalon Very Large Data Bases,2023,32(4):905-936.
[2] GU Z H,FAN J,TANG N,et al. Sam Madden:FewshotTexttoSQL Translation Using Structure and ContentPrompt Learning[J]. Proceedings of the ACM on Management of Data,2023,1(2):147.
[3] ZHOU S L,LI J,WANG H,et al. GRLSTM:Trajectory Similarity Computation with Graphbased Residual LSTM[C]∥Proceedings of the Thirtyseventh AAAI Conference on Artificial Intelligence. [S. l. ]:AAAI,2023:4972-4980.
[4] CHEN Y,CAO H,ZHOU Y Q,et al. A GCNGRU BasedEndtoEnd LEO Satellite Network Dynamic Topology Prediction Method[C]∥2016 IEEE Wireless Communicationsand Networking Conference. Glasgow:IEEE,2023:1-6.
[5] CHATZIANASTASIS M,LUTZEYER J F,DASOULAS G,et al. Grph Ordering Attention Networks [EB / OL ].(2022-04-11)[2023-07-10]. https:∥arxiv. org / abs /2204. 05351.
[6] ZHAO W C,HU H Z,ZHOU W G,et al. BEST:BERTPretraining for Sign Language Recognition with CouplingTokenization[C]∥Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington D. C. :AAAI,2023:3597-3605.
[7] SAMANTA D,VENKATESH V,MONIKA G,et al. Evaluating Commit Message Generation:To BLEU or Not toBLEU?[C]∥2022 IEEE / ACM 44th IEEE InternationalConference on Software Engineering:New Ideas andEmerging Results. Pittsburgh:IEEE,2023:31-35.
[8] SEMIH Y,IZZEDDIN G,SU Y,et al. What It Takes toAchieve 100% Condition Accuracy on WikiSQL [C]∥Proceedings of the Conference on Empirical Methods inNatural Language Processing. Brussels: ACL,2018:1702-1711.
[9] YU T,ZHANG R,YANG K,et al. Spider:A LargescaleHumanlabeled Dataset for Complex and CrossdomainSemantic Parsing and TexttoSQL Task[C]∥Proceedingsof the 2018 Conference on Empirical Methods in NaturalLanguage Processing. Brussels:ACL,2018:3911-3921.
[10] LEE C H,POLOZOV O P,RICHARDSON M. KaggleDBQA:Realistic Evaluation of TexttoSQL Parsers[C]∥Proceedings of the 59th Annual Meeting of the Associationfor Computational Linguistics and 11th International JointConference on Natural Language Processing. [S. l. ]:ACL,2021:2261-2273.
[11] LI D,MIRELLA L. Language to Logical Form with NeuralAttention[C]∥ Proceedings of the 54th Annual Meetingof the Association for Computational Linguistics. Berlin:ACL,2016:33-43.
[12] MIN Q K,SHI Y F,ZHANG Y. A Pilot Study for ChineseSQL Semantic Parsing [C]∥ Proceedings of the 2019Conference on Empirical Methods in Natural LanguageProcessing and the 9th International Joint Conference onNatural Language Processing (EMNLPIJCNLP ). HongKong:ACL,2019:3652-3658.
[13] KEVIN S,DIRK K. Seq2SQLEvaluating Different DeepLearning Architectures Using Word Embeddings [C]∥15th International Conference Machine Learning and DataMining in Pattern Recognition. New York:MLDB,2019:343-354.
[14] GUO J Q,ZHAN Z C,GAOY,et al. Towards ComplexTexttoSQL in Crossdomain Database with IntermediateRepresentation [C ]∥ Proceedings of the 57th AnnualMeeting of the Association for Computational Linguistics.Florence:ACL,2019:4524-4535.
[15] OCTAVIAN P,IRENE M,NGOC P A O,et al. AddressingLimitations of EncoderDecoder Based Approach to TexttoSQL[C]∥Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju:ICCL,2022:1593-1603.
[16] LI S Q,ZHOU K B,ZHUANG Z Y,et al. Towards TexttoSQL over Aggregate Tables[J]. Data Intelligence,2023,5(2):457-474.
[17] WEI C,HUANG S B,LIR S. Enhance TexttoSQL ModelPerformance with Information Sharing and Reweight Loss[J]. Multimedia Tools and Applications,2022,81 (11):15205-15217.
[18] TOMER W,DANIEL D,JONATHAN B. Weakly SupervisedTexttoSQL Parsing Through Question Decomposition[C]∥Findings of the Association for Computational Linguistics:NAACL 2022. Seattle:ACL,2022:2528-2542.
[19] GEUNYEONG J,MIRAE H,SEULGI K,et al. ImprovingTexttoSQL with a Hybrid Decoding Method [J ].Entropy,2023,25(3):513.
[20] QI J X,TANG J Y,HE Z W,et al. RASAT:IntegratingRelational Structures into Pretrained Seq2Seq Model forTexttoSQL[C]∥Proceedings of the 2022 Conference onEmpirical Methods in Natural Language Processing. AbuDhabi:ACL,2022:3215-3229.
[21] XU K,WANG Y B,WANGY L,et al. SeaD:EndtoEndTexttoSQL Generation with Schemaaware Denoising[C]∥Findings of the Association for Computational Linguistics.Seattle:ACL,2022:1845-1853.
[22] QIN B W,WANG L H,HUI B Y,et al. SUN:ExploringIntrinsic Uncertainties in TexttoSQL Parsers[C]∥Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju:ICCL,2022:5298-5308.
[23] SHI P,ZHANG R,BAI H,et al. XRICL:CrosslingualRetrievalaugmented Incontext Learning for CrosslingualTexttoSQL Semantic Parsing[C]∥Findings of the Association for Computational Linguistics. Abu Dhabi:ACL,2022:5248-5259.
[24] PI X Y,WANG B,GAO Y,et al. Towards Robustness ofTexttoSQL Models Against Natural and Realistic Adversarial Table Perturbation [C]∥ Proceedings of the 60thAnnual Meeting of the Association for Computational Linguistics. Dublin:ACL,2022:2007-2022.
[25] HAN S K,GAO N,GUO X B,et al. RuleSQLova:Improving TexttoSQL with Logic Rules[C]∥2022 International Joint Conference on Neural Networks. Padua:IEEE,2022:1-8.
[26] ZHENG Y Z,WANG H B,DONG B H,et al. HIESQL:History Information Enhanced Network for Contextdependent TexttoSQL Semantic Parsing[C]∥Findings ofthe Association for Computational Linguistics. Dublin:ACL,2022:2997-3007.
[27] XIAO D L,CHAI L Z,ZHANG Q W,et al. CQRSQL:Conversational Question Reformulation Enhanced Contextdependent TexttoSQL Parsers[C]∥Findings of the Association for Computational Linguistics. Abu Dhabi:ACL,2022:2055-2068.
[28] WANG L H,QIN B W,HUI B Y,et al. Proton:ProbingSchema Linking Information from Pretrained LanguageModels for TexttoSQL Parsing[C]∥Proceedings of the28th ACM SIGKDD Conference on Knowledge Discoveryand Data Mining. New York:ACM,2022:1889-1898.
[29] ABHIJEET A,ASHUTOSH S,SUNITA S. Diverse ParallelData Synthesis for Crossdatabase Adaptation of TexttoSQL Parsers[C]∥Proceedings of the 2022 Conference onEmpirical Methods in Natural Language Processing. AbuDhabi:ACL,2022:11548-11562.
[30] CHEN Z,SU Y,ADAM P,et al. Bridging the GeneralizationGap in TexttoSQL Parsing with Schema Expansion[C]∥Proceedings of the 60th Annual Meeting of the Associationfor Computational Linguistics. Dublin: ACL, 2022:5568-5578.
[31] LEE G,HWANG H,BAE S,et al. EHRSQL:A PracticalTexttoSQL Benchmark for Electronic Health Records[EB / OL]. (2023 - 01 - 16)[2023 - 07 - 18]. https:∥arxiv. org / abs / 2301. 07695.
作者簡介
彭鈺寒 男,(1999—),碩士研究生。主要研究方向:人工智能數據庫。
(*通信作者)喬少杰 男,(1981—),博士,教授。主要研究方向:人工智能數據庫、時空數據庫、機器學習。
薛 騏 男,(1999—),碩士研究生。主要研究方向:時空數據庫。
李江敏 男,(1997—),碩士研究生。主要研究方向:人工智能數據庫。
謝添丞 男,(1997—),碩士研究生。主要研究方向:軌跡預測。
徐康鐳 男,(1999—),碩士研究生。主要研究方向:人工智能數據庫。
冉黎瓊 女,(1998—),碩士研究生。主要研究方向:數據挖掘、云計算。
曾少北 男,(1980—),碩士。主要研究方向:數據智能應用。
基金項目:國家自然科學基金(62272066,61962006);四川省科技計劃(2021JDJQ0021,2022YFG0186,2022NSFSC0511,2023YFG0027);教育部人文社會科學研究規劃基金(22YJAZH088);宜賓市引進高層次人才項目(2022YG02);成都市“揭榜掛帥”科技項目(2022-JB00-00002-GX,2021-JB00-00025-GX);四川省教育廳人文社科重點研究基地四川網絡文化研究中心資助科研項目(WLWH22-1);成都信息工程大學國家智能社會治理實驗基地開放課題(ZNZL2023B05);成都信息工程大學科技創新能力提升計劃(KYTD202222)
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
