基于Scrapy框架的分布式網絡爬蟲系統設計
2024-08-09 00:00:00何佳知
電子產品世界 2024年6期
關鍵詞:Scrapy 框架;分布式;網絡爬蟲系統
中圖分類號:TP393.09 文獻標識碼:A
0 引言
在大數據時代背景下,各個行業產生了海量的數據,為保證萬維網數據搜索性能,市面上出現多種多樣的搜索引擎,搜索引擎在海量數據的快速搜集中發揮重要作用。同時,隨著網絡信息數據規模的不斷增加和發展,用戶對信息搜索引擎提出了更高的要求[1]。網絡爬蟲技術應運而生,該技術可以自動搜集和整理互聯網信息數據,并向指定的數據庫傳輸和存儲相關信息[2]。但是傳統單機網絡爬蟲存在抓取效率低、穩定性低、數據量不足等問題,無法滿足大數據時代對海量數據的搜索需求。為解決以上問題,本文應用Scrapy 框架,對分布式網絡爬蟲系統進行設計和應用。
1 系統設計關鍵技術
1.1 網絡爬蟲工作原理
網絡爬蟲作為一種重要的計算機程序,可以嚴格按照相關規則從互聯網中抓取相關信息數據。網絡爬蟲工作原理如下:首先,借助有序的待爬行隊列,存儲各個統一資源定位符(uniform resourcelocation,URL)隊列。其次,嚴格按照相關隊列順序,從待爬行隊列中抓取URL,將網絡請求發送至URL 地址,從而獲得所需要的網頁內容,對該網頁內容進行全面分析并提取新的URL。最后,按照一定的順序,將提取的URL 存儲至待爬行隊列中,不斷重復以上操作,當待爬行隊列滿足所設置好的爬行終止條件時,即可結束[3]。
1.2 Scrapy 框架
Scrapy 框架作為一種重要的應用框架,主要應用于結構化網絡資源的提取和通用網絡爬蟲系統的構建。Scrapy 框架包含引擎、蜘蛛中間件、調度中間件、調度器、下載器中間件、下載器、項目管道等組成部分,通過應用異步網絡庫,可以保證網絡通信處理質量和效率。目前,Scrapy 框架被廣泛應用于數據挖掘、數據監測、系統測試等領域中,并取得了良好的應用效果[4]。
2 系統總體設計
2.1 系統架構設計
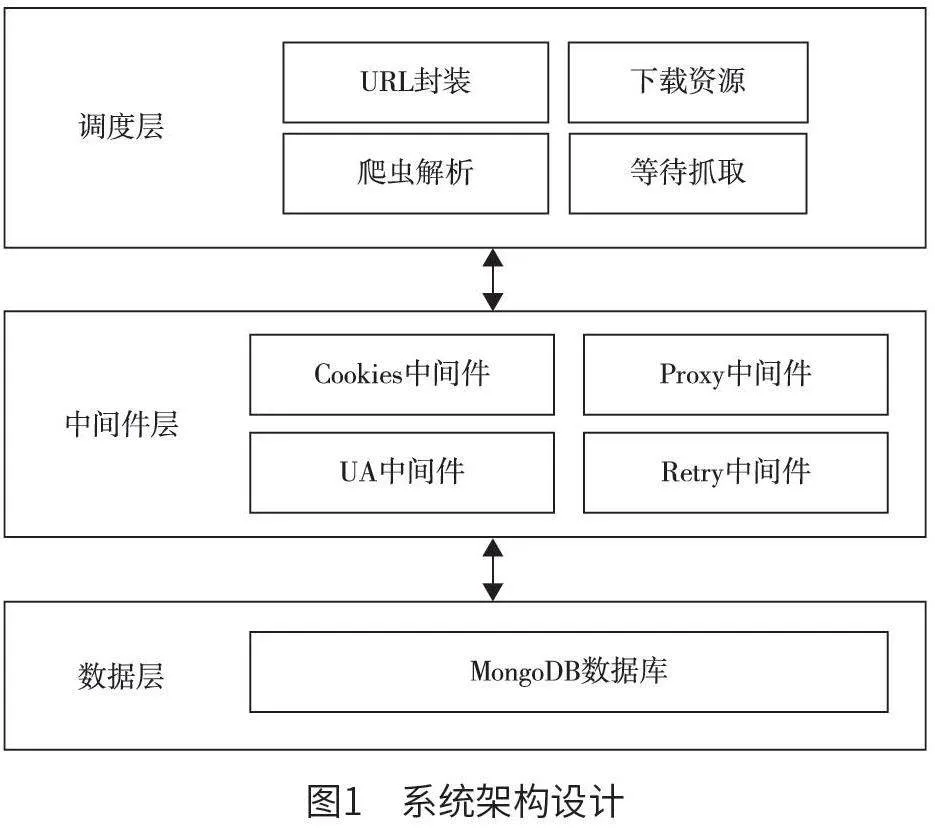
如圖1 所示,系統架構被劃分為以下3 個部分。
(1)調度層。調度層可實時接收從Scrapy 引擎中發送的請求,并將該請求直接存儲至指定隊列中,便于后期Scrapy 引擎再次請求時可快速返回和獲取。本文運用存儲調度的方式,對遠程字典服務(remote dictionary server,Redis)訪問請求進行調度,從而達到智能化調度和爬取分布式任務的目的。本文系統借助調度層,可以實現對單個URL鏈接的提取和封裝,當URL 封裝成指定的請求時,需將該請求直接發送至下載器,由下載器搜索和下載所需要的資源。在進行爬蟲解析請求時,可解析出相應的實體,并將該實體發送至實體管道,由實體管道對該實體采取進一步處理[5]。當URL 鏈接成功解析后,可向調度層發送解析后的URL 地址,由調度層等待抓取。
(2)中間件層。中間件層主要包含Cookies 中間件、Proxy 中間件、UA 中間件、Retry 中間件等組成部分。其中,Cookies 中間件主要用于對用戶本地終端數據的安全化存儲,方便后期系統快速辨別不同用戶的身份信息,保證會話跟蹤實現效果;Proxy 中間件主要用于對代理池進行對接處理,方便系統快速識別不同目標網站服務器的IP 地址;用戶代理(user agent,UA)中間件主要用于對添加錯誤UA 信息的實時修改和更新;Retry 中間件主要用于對運行異常代理的重寫和改進。
(3)數據層。數據層主要利用MongoDB 數據庫,獲取、清洗和融合處理數據。整個數據層在具體設計時,主要繼承Spider 類,該 Spider 類定義了如何爬取某個網站,應用該子類可以對請求方法進行重寫,并實時選擇和抓取數據模式和日期。
2.2 系統數據庫設計
在本文系統中,主要運用MongoDB 數據庫,從而實現長時間存儲數據。在設計MongoDB 數據庫時,需設計合理的數據表結構,保證系統數據庫的穩定性和可靠性。在網絡爬蟲期間,主要目標網站為微博和脈脈。對于微博目標網站,重點關注微博條目詳細信息、用戶詳細信息等數據;對于脈脈目標網站,重點關注匿名消息條目詳情、反饋消息等數據。因此,本文系統設計了微博條目表、微博用戶表、脈脈詳細表。其中,微博條目表主要包含微博編號、點贊量、轉發量、文本、原始文本、創建實際等屬性;微博用戶表主要包含微博編號、用戶名、頭像路徑、用戶描述、粉絲數量等屬性;脈脈詳細表主要包含數據源、評論量、插入時間、消息類型、發布時間、站點名等屬性。
3 系統功能模塊設計
本文系統主要用于對微博、脈脈目標網站相關數據進行實時爬取。整個系統功能模塊經過細化后,得到代理池服務、實體管道、網頁判重、網頁下載等模塊,各個模塊設計流程如下。
3.1 代理池服務模塊設計
代理池服務模塊主要包含以下4 個子模塊:①獲取模塊。在獲取模塊中,用戶可以借助本文系統提供的代理網站,抓取需要的代理信息。代理既可以免費使用,也可以付費使用。整個獲取模塊中,可以從多個數據來源中獲取所需要的數據,當數據被成功抓取后,可以將其直接傳輸和存儲至數據庫。②存儲模塊。存儲模塊主要用于代理信息的統一存儲和抓取,為保證代理的唯一性,需標識不同代理的處理狀態。③檢測模塊。在檢測模塊中,用戶可以借助存儲模塊,對系統數據庫中的代理信息進行統一檢測,結合最終檢測結果,標識和設置不同代理相應的分數狀態。④接口模塊。接口模塊可以直接訪問系統數據庫,快速獲取需要的數據,但是這種操作缺乏安全性,容易導致數據庫內配置信息丟失、泄露等。為解決以上問題,本文重點設計接口模塊,用戶借助接口模塊,可以安全、快速地獲取需要的代理信息,保證代理信息獲取機會的均等性,提高本文系統整體負載均衡能力。
3.2 實體管道模塊
實體管道模塊主要用于對爬取數據的清洗、驗證和存儲等相關處理。該模塊主要包含微博實體管道、脈脈實體管道等多個子模塊,各個子模塊之間既相互獨立,又相互依賴,按照流水線方式進行有序運行。其中,微博實體管道模塊主要用于實時添加爬取時間字段,當該時間字段信息添加完成后,本文系統可以自動將添加好的時間字段信息存儲至MongoDB數據庫;脈脈實體管道模塊設計目的是保證脈脈數據的獨特性和唯一性,避免脈脈數據重復,當脈脈數據經過去重、清洗處理后,可以將該數據直接存儲至MongoDB 數據庫,便于其他人員查看和調用。
3.3 網頁判重模塊
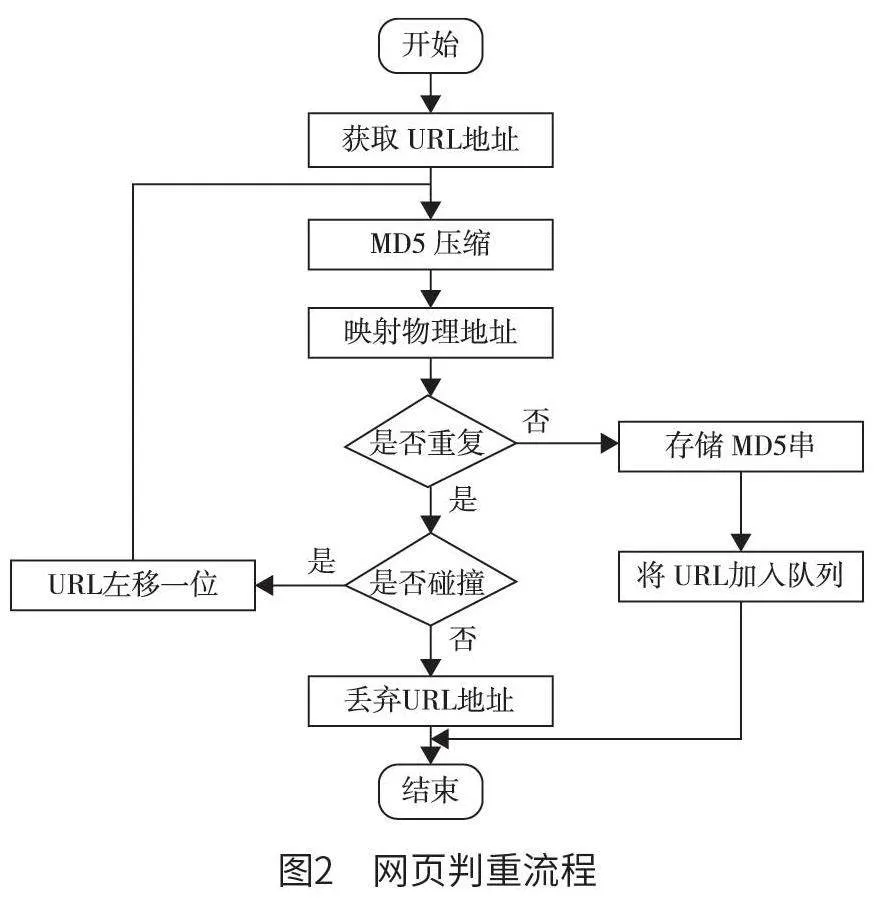
在網絡爬蟲運行期間,為避免因同一頁面被多次下載而增加系統運行時間和運行負荷的情況,本文重點設計和實現網頁判重模塊,確保URL 下載隊列含有唯一的URL 和爬取URL 的唯一性。URL網頁判重工作具體流程為:首先,利用本文系統完成對單個全局變量的構建,檢測和判斷某一URL是否被瀏覽和訪問過;其次,還要對當前待爬取URL 進行探測,探測其是否處于全局變量中。從圖2 可以看出, 運用哈希算法, 獲取所需要的URL 地址,并且對信息摘要算法(message-digestalgorithm)MD5 進行壓縮映射處理,保證URL 去重池功能的實現效果。在具體網絡爬蟲期間,運用MD5 算法,可以對任意位數的字符串進行壓縮,使其成為128 位整數,并將該整數統一映射為指定的物理地址,確保URL 去重池具有一定的獨特性和唯一性。在單次爬取期間,如果映射物理地址出現重復,需要檢驗MD5 在存儲期間是否出現碰撞,如果出現碰撞,需對URL 中的二進制數(10000)進行左移一位,得到100000;如果未出現碰撞,需丟棄URL 地址。
3.4 網頁下載模塊
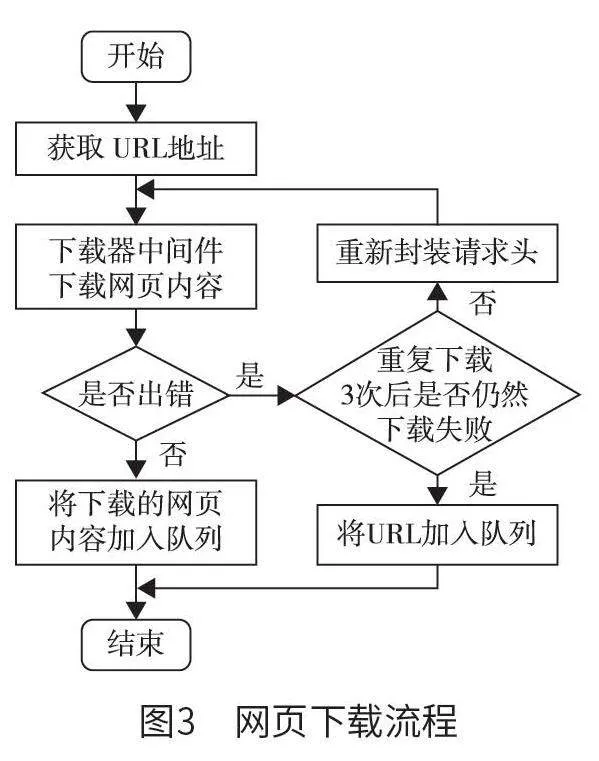
在具體設計網頁下載模塊時,技術人員需要應用Scrapy 框架內部的Downloader Middleware 類,該類定義了一個或多個方法的類,運用該類可以對process_request 方法進行重寫。本文系統從指定的請求隊列中,完成對特定URL 地址的提取,并將其發送至下載器中間件,由下載器中間件對所需要的網頁內容進行下載,如果網頁內容下載期間出現錯誤問題,需調用Rotate User Agent Middleware 類,對網頁內容進行重新下載,整個下載過程重復3 次,當重復下載3 次結束后,仍然下載失敗,則需借助失敗隊列存儲URL 地址和相關字符。網頁下載流程如圖3 所示。
4 系統測試
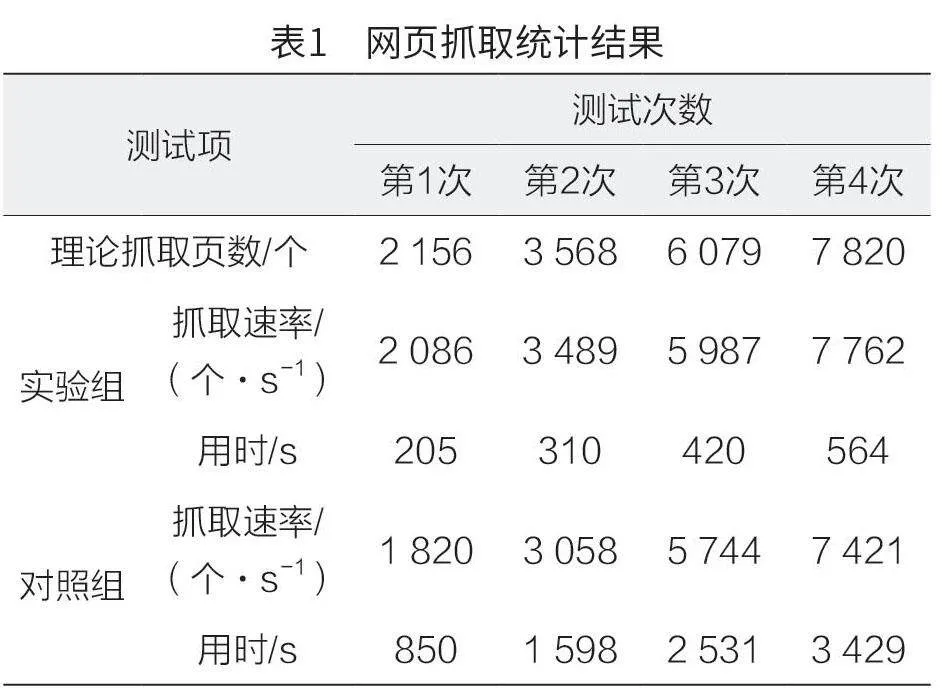
為驗證本文系統的高效性和穩定性,本文以“hao123”為測試頁面,并將本文系統和傳統單機網絡爬蟲系統分別設置為實驗組和對照組。在實驗組中,主要用到url.py 文件,該文件在具體使用中,通常產生大量的URL 隊列,此時,需利用Redis數據庫完成對以上URL 隊列的存儲;同時,應用Scrapy crawl 命令,保證分布式抓取執行效率和效果;最后應用MongoDB 數據庫,存儲相關數據。在對照組中,主要運用傳統Nutch 網絡爬蟲,抓取和存儲相關數據。在進行網頁數據抓取期間,本文分別測試實驗組、對照組成功下載保存網頁數量,網頁抓取統計結果如表1 所示。從表1 中的數據可以看出,與對照組相比,實驗組在進行網頁抓取時,網頁抓取成功率和運行效率明顯得到提升,訪問時間有效縮短,這說明本文系統在網頁抓取和運行方面具有顯著優勢。
5 結語
綜上,本文應用Scrapy 框架所設計的分布式網絡爬蟲系統在改進和優化傳統Scrapy 框架的基礎上,對Scrapy 框架分布式能力進行不斷拓展和提升,不僅保證網絡爬蟲分布式抓取效果,還能實現對相關數據的非結構化存儲。本文系統具有網頁抓取成功率高、運行效率高等特點,表現出一定的應用價值和應用前景,值得被進一步推廣和應用。
