基于深度學習的教育政策用戶評論細粒度情感分析研究
2024-08-12 00:00:00吳運明張琳胡凡剛
中國電化教育 2024年7期
摘要:智媒時代微博、抖音等網絡社交媒體平臺成為政府與公眾之間傳遞信息的重要渠道之一,公眾在平臺上對教育政策的評論影響著教育政策的實施進程、效果及后續政策的出臺。融合主題模型LDA和深度學習模型LSTM,以“雙減”政策為例,挖掘面向教育政策的網絡社交媒體用戶評論,并對其進行細粒度情感分析,剖析用戶對教育政策的多維主觀情感,為提升教育政策實施效果提供參考。研究發現,網絡社交媒體用戶對“雙減”政策的輿論焦點主要集中在四個主題下的16個評論對象上,其中在素質教育、藝術活動、學歷3個方面用戶情感偏向于正向;在校外培訓、課后服務、教育公平、貧富差距、就業等其余13個方面用戶情感偏向于負向。
關鍵詞:LSTM模型;LDA模型;情感分析;教育政策
中圖分類號:G434 文獻標識碼:A
一、引言
近年來隨著微博、抖音等網絡社交媒體的飛速發展,國家的各種教育政策一經頒布迅速引起社會廣泛網絡輿情關注,諸如《關于進一步減輕義務教育階段學生作業負擔和校外培訓負擔的意見》《校外培訓行政處罰暫行辦法》等。教育政策是由政府及其機構和官員制定的、調整教育領域社會問題和社會關系的公共政策[1],對實現教育公平,進而實現社會公平有很大助益,可以為每個人提供平等的機會,使得每個人都能夠獲得優質的教育資源,幫助他們更好地適應社會和就業市場。然而,教育政策在積極推動構建良好教育體系的同時,也引發一些現實問題,讓人們對教育政策的制定及實施產生負面輿論,這些輿論導致教育政策執行和決策的變化[2],給教育改革帶來了新的問題。因此,挖掘網絡社交媒體用戶針對教育政策的評論文本,從用戶所談及的各方面對相關評論文本做細粒度情感分析,并及時針對用戶輿論調整教育政策的決策和實施,對全面推進教育改革具有重要的價值和意義。
用戶評論細粒度情感分析是通過對用戶評論主題抽取、情感分析,實現更加精準的情感分類。目前針對教育政策產生的輿論進行情感分析的研究較少,已有研究大多關注一般領域的輿論情感分析。部分學者嘗試將主題抽取模型與情感分析模型相結合對文本內容的情感分析。如彭云等[3]構建了一種名為SWS-LDA的主題模型,以期提高對特征詞、情感詞和它們之間關系的識別能力,進而提高該主題模型的情感極性分類準確性。蘇瑩等[4]結合了樸素貝葉斯模型和隱含狄利克雷分布模型,能夠在不需要篇章和句子級別的標注信息的條件下,只需使用適當的情感詞典就可以分析網絡評論的情感傾向。另有部分學者利用基于機器學習的情感分析方法,包括深度神經網絡、卷積神經網絡、遞歸神經網絡等[5],通過在原基礎上不斷改進算法以實現對評論的細粒度情感分類。如王義等[6]提出了一種細粒度多通道卷積神經網絡模型,以詞性向量和細粒度字向量為輔助輸入,使用原始詞向量來捕獲句子間的語義信息,從而實現更加準確的文本情感分析。李慧等[7]、蔡慶平等[8]分別基于CNN構建了不同的面向產品評論的細粒度情感分析模型,從而能夠比較全面地獲得產品評論中有關多方面產品特征的情感傾向。針對教育政策用戶評論情感分析的研究,偏重于改良或融合已有的理論或技術進行情感分類。例如,李沅靜等[9]利用樸素貝葉斯、支持向量機等四種模型對“雙減”短文本評論進行情感分析。辛明遠等[10]將LDA模型中得到的主題向量與BERT詞向量模型相結合,并融入CNN卷積層處理,對“雙減”政策的輿論進行分類和提取主題詞。已有相關研究中,部分與主題抽取相結合進行情感分析,另一部分側重于從模型入手改進具體算法,仍以傳統的情感強度值為依據劃分情感,從而得到細粒度情感分析結果。上述情感分析方法雖然從整體上細化了用戶對某一教育政策的態度,但無法全面地呈現用戶在特定方面的不同情感。因此,本研究擬將深度學習模型中的LSTM(Long ShortTerm Memory,長短期記憶)模型與LDA(Latent Dirichlet Allocation,隱含狄利克雷分布)主題模型相結合,挖掘網絡社交媒體用戶對某一教育政策的用戶評論,實現在各輿論主題下多個方面的細粒度情感分類,以期助力政策制定者更深入地了解公眾的需求和關注點,為后續政策的全面落實提供參考依據,并通過情感分析獲得的數據調整政策宣傳和推廣的方式,切實增強公眾對教育政策的認同感和滿意度。
二、基于深度學習模型的教育政策用戶評論細粒度情感分析研究設計
(一)理論基礎
深度學習LSTM模型由Sepp Hochreiter和Jurgen Schmidhuber提出[11],后被Alex Graves、Haim Sak等人逐步改進并予以應用,是RNN(Recursive Neural Network,循環神經網絡)的一種特殊類型,具有記憶長短期信息能力的神經網絡。相較于RNN,LSTM解決了長期依賴問題,可以學習長期依賴信息。LSTM模型的核心是由一個記憶單元和三個門組成的重復模塊[12],通過門對記憶單元狀態進行刪除或添加信息。記憶單元能夠使LSTM模型存儲、讀取、重置和更新長距離歷史信息,輸入門控制信息是否流入記憶單元中,遺忘門控制上一時刻記憶單元中的信息是否需要積累到當前時刻的記憶單元中,輸出門則決定當前時刻記憶單元中的信息是否應該流入當前隱藏狀態中。這些機制協同工作,使LSTM具有更好的處理長時間序列數據的能力,其結構如圖1所示。
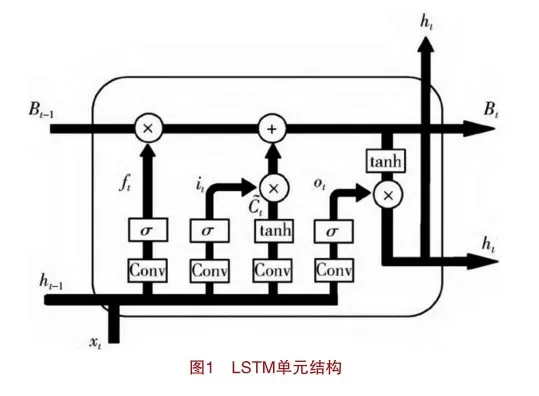
其中,Bt-1是單元狀態,表示長期記憶,可以控制信息傳遞給下一時刻;ht-1是上一次的狀態,表示短期記憶;xt指本次輸入;ft、it、ot分別為遺忘門、輸入門和輸出門。
(二)研究設計
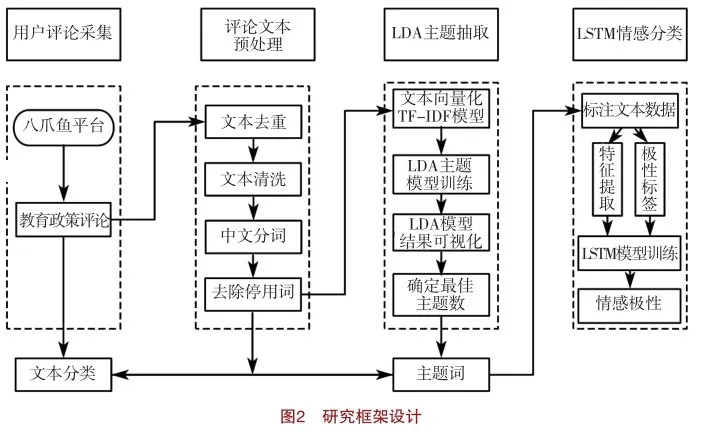
本研究構建了一個融合深度學習LSTM模型和主題抽取LDA模型的教育政策用戶評論細粒度情感分析框架,包括用戶評論采集、評論文本預處理、基于LDA模型主題抽取、基于主題詞的評論文本分類、基于LSTM模型情感分類5個模塊,具體如圖2所示。
1.教育政策用戶評論數據采集與預處理
數據收集與預處理主要包括數據采集、清洗和預處理三階段,其中數據預處理分為中文分詞和去停用詞兩個步驟,從而形成可進行情感分析和挖掘文本主題的語料庫。首先,利用文本采集工具抓取微博、抖音、嗶哩嗶哩、知乎等網絡社交媒體中用戶有關某一教育政策的生成內容;然后,對數據做如下處理:(1)去重文本數據。由于抓取的評論數據會存在重復值,需要將重復的評論數據剔除,確保數據的唯一性。此外,對于評論中存在連續重復的詞匯表達時,如“支持支持支持支持支持”,將其壓縮為“支持”。(2)清洗文本數據。部分評論可能無法采集完整,即為缺失評論;再者,部分評論文不對題,或者僅使用特殊符號、顏文字、表情包等,此視為無效評論;另有部分評論內容極為簡短,使用無意義的詞匯,如“哈哈”“無語”等,無法識別出其具體表意,本研究也將其視為無效評論。清洗數據即刪除信息缺失、無效的評論。(3)中文分詞。利用Python中的Jieba分詞包對用戶評論數據進行分詞。(4)去停用詞。停用詞是指在不同文本內容中出現頻率較高的,但不具備實質性意義的詞語或符號,例如“只是”“如果”“可以”等詞,以及各種標點符號、數字等,通常在進行文本處理任務如分類、聚類、情感分析等前,需要對文本進行去停用詞處理,減少冗余信息,提高分析的精度和效度。使用基于詞表的去除法,將分詞后的詞語與停用詞表進行比較,如果在分詞結果中有存在于停用詞表中的詞語,則將其刪除。
2.基于LDA模型的教育政策用戶評論主題抽取
LDA模型是一種文檔主題生成模型,屬于無監督學習模型,包含詞項、主題和文檔三層結構,可以用來識別大規模文檔集或語料庫中潛藏的主題信息。它采用了詞袋方法,將每一篇文檔視為一個詞頻向量,從而將文本信息轉化為易于建模的數字信息。將每篇文檔看作各種隱含主題的混合,而每個主題則表現為與該主題相關的詞項的概率分布[13]。在實際分析過程中,先通過現有的文章訓練出LDA模型,提取出相應的主題,再用模型預測新的文章所屬主題分類。
基于LDA模型進行主題聚類的主要目的是通過對網絡社交媒體用戶評論的主題挖掘,得到聚類后的主題及每個主題下的主要關鍵詞,從中得知網絡社交媒體用戶在談及某一教育政策時所關注的各個方面,為后續進行細粒度情感分析劃分多層次維度提供依據。(1)LDA模型參數及最佳主題數選擇。Dirichlet先驗α和β常按照經驗值進行設置,而主題個數的取值對于模型性能和主題挖掘效果有著重要影響。目前相關研究在確定主題數時通常基于先驗知識對文檔包含的主題數進行初步估計,再結合困惑度、一致性以及主題間相似度等質量評價方法做出選擇[14]。困惑度的大小與模型性能成反比,一致性的大小與模型性能成正比。本研究先根據經驗判斷主題個數,進而訓練LDA模型,計算一致性數值,然后使用pyLDAvis包對模型進行可視化,根據呈現的主題氣泡分布情況,確定最終主題個數。(2)LDA模型構建。使用TF-IDF算法在文本預處理后的語料中提取關鍵詞,生成詞頻矩陣;通過LdaModel函數構建LDA模型,設定合適的主題數、迭代次數等參數;為了使聚類結果更加直觀,利用pyLDAvis包對結果進行可視化,呈現各個主題在模型空間中的相互關系和重要性;為提高模型質量,可多次調整參數迭代訓練,完成LDA主題聚類。
3.基于主題詞的教育政策用戶評論文本細粒度劃分
根據得到的最佳主題數對已抽取的主題詞進行篩選,并據此對預處理后的用戶評論進行歸類,實現評論文本的細粒度劃分,為后續采用LSTM對面向教育政策的用戶評論進行細粒度情感分析做準備。(1)主題詞篩選。通過LDA主題模型算法確定最佳的主題數,抽取出與之相關的主題詞,去除重復、無關、低頻主題詞,構建更具意義的主題類別。(2)將評論切分成短句。對于每條用戶評論,根據標點符號將其拆分成若干個短句,以達到更細粒度的文本表示,提高后續細粒度情感分析的精確度。在拆分時需注意,同一句話內部出現多次標點符號,需要基于語法規則進行修正,并去除短句中的空格、制表符和回車符等不必要的空白字符。(3)短句文本分類。將切分后的評論短句按照主題詞進行歸類,將包含該類別主題詞的所有短句視為同一個類別。
4.基于深度學習模型LSTM的教育政策用戶文本情感分析
為獲取網絡社交媒體用戶對教育政策多層面的情感態度,本研究采用深度學習模型中的LSTM模型對各主題下的網絡社交媒體用戶評論文本進行正向、負向情感極性分析。首先,需要將原評論文本按主題分類,部分評論可能出現在不同的主題下;然后,按照上述預處理步驟再次對文本內容進行分詞和去停用詞;最后,構建LSTM模型,分別判斷不同主題下各類文本的情感傾向,數值趨近0為負向,趨近1為正向。
LSTM模型構建過程:
(1)使用詞向量訓練模型Word2Vec訓練語料以獲得詞向量。Word2Vec能夠將由文本轉化為的稀疏矩陣的向量維數進行縮減,從而得到每個詞所對應的低維向量,即詞嵌入過程,這種低維向量更適合深度學習模型的訓練。
(2)導入torch庫構建深度學習模型。LSTM模型的參數中有三個是必須設置的:一是輸入特征維度input_size,如果將一個句子作為輸入,每個詞都被轉換為一個向量,則該值為每個詞向量的維度;二是隱藏層狀態的維度hidden_size,即每個時間步長LSTM單元輸出的狀態向量的維度,通常會根據數據集的大小和模型的復雜度來設置該參數;三是LSTM堆疊的層數num_layers,該值越大,模型的復雜度越高,但同時也會增加訓練時間和計算資源的消耗。需要注意的是,LSTM還有其他可供設置的參數,如序列長度、Dropout率等,這些參數的設置要根據具體任務需求和數據情況進行調整。
(3)定義BCELoss損失函數和Adam優化器。nn.BCELoss()是二分類交叉熵損失函數,模型只能輸出兩種可能的結果,如正面情緒和負面情緒、垃圾郵件和非垃圾郵件等,將數據標簽定義為0和1,其中0代表第一種輸出,1代表第二種輸出。torch.optim.Adam()是Adam優化算法的實現,用于更新模型的權重和偏置等參數,在使用torch.optim.Adam()時,需要將模型的參數傳入,同時可以設置學習率、權重衰減因子、動量參數等超參數。
(4)迭代訓練LSTM模型,在每個epoch循環中,先將數據輸入模型進行前向計算,然后根據預測結果和真實標簽計算損失,并進行反向傳播更新模型參數。同時訓練過程中會輸出測驗后的loss、accuracy等信息,可根據這些信息重新定義參數,再次訓練模型。
5.結果評價
將上述研究框架應用于具體教育政策進行細粒度情感分析,并采用各類指標對分析結果進行評價,包括對LDA主題抽取結果和LSTM情感分析結果的評價。
LDA主題抽取的目的是將文本數據劃分為多個主題,并進一步了解這些主題的內容和特征。評價LDA主題抽取結果的方法和標準具體取決于分析的目的,以下為常用于評價LDA主題抽取結果的指標[15]:(1)主題的數量:主題的數量影響到了LDA模型的復雜度和解釋性,如果主題數量過多,可能會使得主題之間的界限變得模糊不清,難以解釋;反之,如果主題數量過少,則可能無法涵蓋所有關鍵信息。(2)單詞分布:主題中所包含單詞的分布也是一個重要的指標,主題內部單詞的分布應該盡量集中在某些關鍵詞上,而非分布均勻、散落不定。(3)主題一致性和可解釋性:在各個主題之間應該確保連貫性,即每個主題所包含的單詞都應該與整個主題相關聯,對于每個主題來說,需要檢查其包含的單詞是否能夠解釋該主題所代表的內容,如果主題中包含的單詞沒有明顯的共性,可能會造成解釋上的困難。
LSTM情感分類的目的是對文本數據進行情感判斷,并將其歸類為積極、消極或中性等不同類別。評價LSTM情感分類結果需要根據具體需求選取適合的評價指標進行綜合考慮,以確保分類結果的準確性和可靠性,以下是一些常見的指標[16]:(1)準確率:通過準確率可以很好地反映出模型的整體分類效果,但可能會受到數據集分布不均等問題的影響,因此需要結合其他評價指標進行綜合分析。(2)精確率和召回率:用于評估二元分類模型性能的兩個重要指標,這兩個指標結合使用可以更全面地評估分類器表現,需要根據具體情況權衡取舍。(3)F1值:F1值是精確率和召回率的調和平均值,可以對分類器的性能進行綜合評估。
三、用戶評論細粒度情感分析——以“雙減”政策為例
(一)數據采集與預處理
使用八爪魚采集器抓取來自微博、知乎、抖音、嗶哩嗶哩等網絡社交媒體有關“雙減”政策的評論,具體包括的字段有:評論內容、用戶名、發表時間、開課階段、點贊數,采集完成后將數據導出。共抓取了22876條評論數據,經過數據去重和清洗后獲得有效數據18189條,部分采集數據如表1所示。
使用jieba庫進行分詞處理。為使分詞結果更加確切有效,在詞典中添加“雙減政策”“素質教育”“培訓機構”等自定義詞匯;調用jieba.cut函數,設置分詞模式為精準模式進行分詞;由于單字詞包含信息量較少,需將單字詞過濾掉;在分詞處理后,選用百度停用詞表,剔除分詞結果中的特殊符號等無實質性意義詞匯,得到最終的分詞結果。部分評論分詞結果如圖3所示。

(二)用戶評論主題抽取
利用Python擬合LDA模型。首先根據文本內容主題分布情況粗略設定主題數為10,遍歷語料庫的次數為100,列出在線評論集合中最重要的10個主題及每個主題的若干關鍵詞,進而進行可視化處理。由于聚類出的主題交疊現象較為嚴重,為選取最佳主題數,通過計算一致性數值,并繪制主題-coherence曲線,選擇最佳主題數為4。最終抽取4類主題。
根據主題聚類結果,得到表2所示的四個主題及每個主題下最重要的10個主題特征詞。

(三)用戶評論文本分類
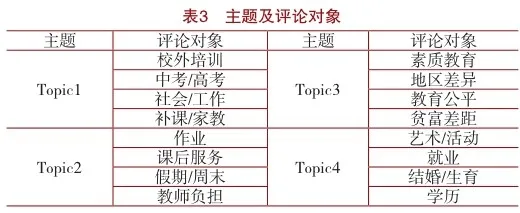
對上述抽取出的主題詞進行篩選,去除無研究意義的詞匯,將表意重復的多個主題詞聚類為一個詞語作為所要進行情感分析的層面之一,最終聚合為每個主題下的4個評論對象,如表3所示。
將評論文本切分成短句,對切分后的句子進行修正,并去除短句中的空格、制表符和回車符等不必要的空白字符,同時設定短句長度最小值為5,刪除無具體意義的過短語句,從而使每個短句語義完整且僅涉及對“雙減”政策一個方面的意見。具體切分實例如表4所示。

根據評論對象對切分后的評論文本進行篩選,包含同一評論對象的短句作為一個類別,從而完成用戶針對“雙減”政策輿論的細粒度劃分。
(四)主題文本情感分析
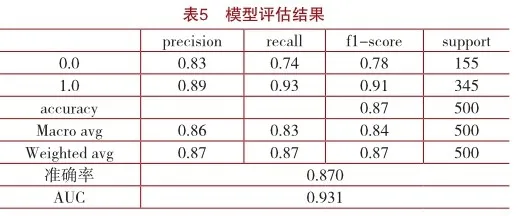
將數據集分為訓練集和測試集,占比為9:1。導入必要的torch、gensim等庫,加載數據,預訓練得到Word2Vec詞向量。在定義LSTM模型類時,傳入以下參數:learning_rate=5e-4;input_size=768;num_ epoches=5;batch_size=100;embed_size=64;hidden_ size=64;num_layers=2,迭代訓練神經網絡,并在測試集進行效果檢驗。本研究采用準確率(Precision)、召回率(Recall)和F1值(f1-score)評估分類模型性能,模型評估結果如表5所示。從表5可以看出負向情感和正項情感分別訓練模型結果在準確率上分別為0.83和0.89,總體的F1值也達到了0.87,達到良好的效果。每個主題下的準確率(Precision)、召回率(Recall)和F1值的Macro Average(宏平均)值均在0.8以上,達到良好的水平。Weighted Average(加權平均)是指對每個主題類別分別計算指標,然后取這些指標的加權平均值。從加權平均值計算結果也可以看出均為0.87,達到了良好的效果。AUC用于衡量分類器對于區分兩個類(正類和負類)的能力,介于0和1之間,其值越高表示模型的分類性能越好。從表5的計算結果看出AUC值為0.931,說明模型在進行正負類分類時,效果非常好。綜上所述,本研究構建的主題情感細粒度分類模型具有良好的分類效果。
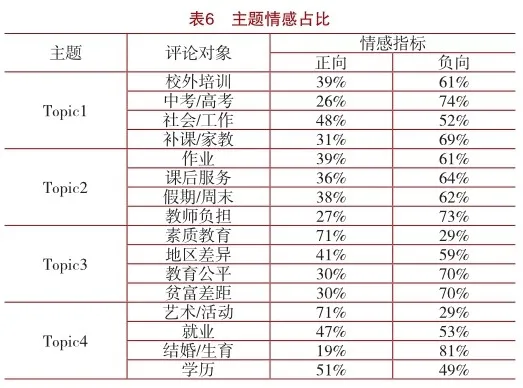
利用已訓練完成的LSTM模型,輸入各類別下的文本內容,判斷用戶評論的情感傾向,統計四類主題下相關評價對象正向、負向情感的評論比例。如表6所示,得到具體主題詞的情感量化值,例如用戶在“素質教育”的話題評論中明顯的偏向于正向,而在 “升學考試”話題中的評論情感則偏向于負向。因此,出于用戶對“雙減”政策的情感需求,相關機構在促進政策落實時,需要重點關注該政策對中考高考的消極影響,并在下一步執行計劃中實施改進措施。
(五)結果討論與分析
1.用戶對主題1下“校外培訓”“中考高考”“社會工作”“補課家教”四個方面輿論的評價情感傾向均偏向于負向
首先,“雙減”政策明確規定了義務教育階段教育質量保障機制,將禁止校外培訓機構開展與義務教育階段內容和形式相關的培訓業務,這意味著校外培訓機構無法再在中小學教育領域大肆招生,可能會導致一些校外培訓機構生存壓力增加或者面臨關閉,增加一批失業人員。“雙減”政策實施后,不僅校外培訓機構會受到沖擊,普通中學升學考試科目和升學政策也可能會有所調整,這些變化都會影響到中考和高考的錄取標準和招生政策[17]。對校外培訓有較強依賴性的學生將會面臨更大的學業困難,許多學生家長想通過讓孩子參加校外培訓提高學習成績的計劃被阻塞,這引起了眾多家長和學生的不滿,這也間接導致一批學生放棄升學,被迫早早地進入社會謀求工作,尤其是家境普通的學生。對于家境殷實的家庭,家長可能會采取較為隱蔽的方式,花較高的價錢聘請學歷高、能力強的一對一家教,這在某種程度上加劇了教育資源分配不均衡的現象[18],造成優勢學生與劣勢學生之間的差距進一步拉大。特別是在當下,學歷已然成為職業崗位的敲門磚,那些放棄升學的人也會面臨巨大的就業壓力。
2.用戶對主題2下“作業”“課后服務”“假期周末”“教師負擔”四個方面的輿論均偏向于負向情感
據現有調查研究顯示,該政策實施后中小學生作業量明顯減少。這在一定程度上緩解了學生焦慮情緒[19]。但研究結果顯示,61%的家長和學生表示政策實施后在作業減負方面并沒有起到一定的效果。有許多學校將超負的部分作業轉化為各種形式發布給學生,從表面看學生的書面作業確實減少了,但學生的作業壓力并沒有減少。在“課后服務”方面,根據孟晶等[20]對小學教師課后服務認同現狀的調查,存在教師對學校課后服務的執行方式認同偏低、學校課后服務的執行主體單一、學校課后服務的內容脫離教師實踐等一系列問題。部分人認為課后服務是形存實亡,例如,學校利用課后服務時間并不是在幫助學生鞏固復習、輔導作業,而是強制要求學生參加以便于老師講解新課,而且有很多學生抱怨課后服務的時間過長。張妍等[21]也認為義務教育學校課后服務仍面臨課后服務制度規范亟待完善、課后服務人員權責有待厘清、課后服務保障體系有待健全等現實難題。若不抓緊解決這些問題,不僅不會減壓,反而會增加學生的學業壓力。不僅如此,“雙減”政策在某些方面也加重了教師的負擔,教師在完成日常的教學任務之后,會以監督學生完成作業的方式參與課后服務工作,這種延時工作難免會讓教師感到時間緊張,難以合理分配精力。在“假期周末”方面,部分人表示由于早已習慣了在假期、周末補課,在取消校外培訓后自己在放假期間無所事事;部分人表示原本計劃在周末的補課被迫調整到了學周中,或者有的直接沒有做任何調整,仍然利用周末假期進行補課,并沒有達到減負的效果。
3.用戶對主題3下的輿論在“地區差異”“教育公平”“貧富差距”方面為負向情感,在“素質教育”方面偏向于正向情感
用戶輿論在“地區差異”“教育公平”“貧富差距”方面的情感偏向于負面,反映了現有教育資源不均衡、教育不公平等缺陷,引起該現象產生的因素即為地區差異、貧富差距,而這兩個因素同時也是導致用戶負面情感出現的具體原因。
首先,在一些較為發達的一線城市,如北京、上海等地作為政策試點地區,“雙減”政策相對落實到位,相關部門對政策實施過程進行全面監管,同時創新各種舉措,不斷探索政策落地途徑。而在其他不同的地區,政策的落實情況及面對的難題也各有不同,例如根據江西省教研室的調查顯示,97.8%的學生學習及整體狀況呈現出良好的態勢,但65.31%的教師表示工作負擔加重,也要求學校整體改進教育教學制度[22];據昆明市相關部門的調研,雖然有超過95%的學生和家長對昆明市“雙減”工作滿意,但僅有29.59%的學生認為沒有作業負擔,47.28%的學生不參加校外培訓[23]。同時,由于城鄉教育發展的不均衡以及農村優質教學資源的短缺,使得“雙減”政策在農村與城市的實施無法一概而論[24],“雙減”工作在鄉鎮學校的推進仍存在問題。陸芳等對比城市和鄉鎮教師就“雙減”政策落實情況的評估,采用卡方檢驗獲得的結果表明,城市學校實施課后服務的比例顯著高于鄉鎮,而更多的鄉鎮教師認為“雙減”實施后“基本沒有變化”[25]。由此可知,“雙減”工作的開展情況存在一定的城鄉差異。
此外,貧富差距影響著教育資源的獲得。自“雙減”政策發布以來,我國對校外培訓機構進行了大力壓縮,有證機構積極轉型調整,而無證機構則完全停止了培訓行為,扭轉了校外培訓過多過濫的局面,學科類培訓機構大幅壓減[26]。這就導致大部分平價且小有成效的校外教育機構要接受改制調整,同時引起家長焦慮,在這種局面的刺激下較為富裕的家庭爭先招聘學歷高、能力強的私人家教,而一對一輔導所要花費的金額遠遠超過之前的大班授課,大部分普通家庭難以承擔這筆支出,因此會在一定程度上拉大貧富兩類家庭孩子的教育水平,引發了新的教育公平問題。
在“素質教育”方面用戶評論的情感傾向偏向于正向,雖然“雙減”政策會對素質教育的發展帶來挑戰,但大部分群眾都認為“雙減”政策對于推進素質教育具有積極的促進作用,例如,學校能夠通過優化課程設置、增加運動場地和基礎設施等方式,開展多元化的課外活動、設計并組織各種形式的文體娛樂項目以及提供豐富的實踐機會等,以充分發掘學生的個性和特長,培養學生的創新精神和實踐能力,從而促進學生的全面發展。“雙減”政策還會協調家校社共同推進素質教育發展。不少學校為落實好“雙減”政策進行教育教學改革的實踐探索。讓“學校回歸教育主陣地”是家校社協同育人的根本前提,因此該政策能夠密切家校社合作關系,實現家校社協同育人功能[27]。此外,也有利于轉變教育觀念、改進教學模式,最重要的是遏制了私立教育的無限發展,縮小了教育差距。由此看來“雙減”政策在義務教育階段的中小學取得了一定的成效。正基于此,大眾也寄望將該政策推廣到高中階段。
4.用戶對主題4中 “藝術體育”“學歷”方面輿論偏向于正向情感,對“就業”“結婚生育”方面偏向于負向情感
“雙減”政策的一個重要目標是減輕學生校外培訓的負擔,為此,該政策規定在一年內有效減輕中小學生的課外負擔,并關閉不合規的校外學科類培訓機構,同時規范和完善校內教育體系。一方面,這有利于優化教育體系結構、促進教育改革、全面開展素質教育,有助于減少青少年兒童的學業負擔,釋放他們活潑好動的天性,保護他們健康成長,這也是部分大眾支持該政策的原因。另一方面,許多人持反對意見,在家長層面,“讓孩子贏在起跑線上”這句話深入人心,激發了家長之間的競爭心,又由于各個家庭的收入水平不同,管制校外輔導機構對他們來說自然不是一件值得歡喜的事情;在社會層面,管制校外輔導機構導致一大批從業者失業[28],其中師范類專業畢業者居多,對即將畢業的大學生來說失去了一條就業之路,在教師編制門檻十分難過的現狀下,唯有選擇考研是一個延緩就業的最佳道路,然近年考研人數急劇增長、考研難度升級,使得這些人群對“雙減”持有負面情緒。另外,該政策引起了家長甚至一個家庭內部的焦慮。一方面,由于家長對升學率高度關注和家長間的不斷競爭,加之人們歷來對職業學校的不重視,而在就業時招聘公司又格外注重應聘人員的學歷,因此人們對該政策產生了抱怨情緒,認為國家推行“雙減”政策的目的是補給社會勞動力,讓部分大學生甚至是中學生直接選擇就業,而非升學。然而就業市場競爭激烈,許多年輕人需要更長的時間來找到穩定的工作,這可能迫使他們推遲結婚和生育的計劃。隨著“雙減”政策的推進,義務教育質量得到提升,家長更注重子女教育,因此一些家長希望在子女教育上投入更多的時間和精力,這也可能導致他們在較晚的時候才考慮結婚和生育的問題,以保證能夠承擔高額的教育花費。
綜上,網絡社交媒體用戶對“雙減”政策的輿論焦點主要集中在4個主題、16個評論對象上,在“素質教育”“藝術活動”“學歷”3個方面用戶情感偏向于正向;在“校外培訓”“課后服務”“補課家教”“作業”“假期周末”“教師負擔”“中考高考”“社會工作”“地區差異”“教育公平”“貧富差距”13個方面用戶情感偏向于負向。
四、結語
針對教育政策用戶評論文本的情感分析,本研究提出了融合LSTM深度學習情感分析與 LDA主題挖掘的細粒度情感分析框架,對從微博、知乎以及抖音等平臺抓取的教育政策用戶評論文本數據進行情感分析。借助LDA模型對用戶評論文本進行主題分類,為下一步細粒度情感分析劃分層面提供依據,進而利用LSTM模型分析各層面用戶評論的情感態度。LSTM模型需要在人工標注相關數據的前提下進行構建才能細粒度地識別用戶評論中的情感傾向,未來將對深度學習模型進行優化,利用半監督和無監督學習方法,進一步提高情感分類的速度和準確度。
目前,我國正在大力推動“雙減”政策的落實,本研究有助于指明進一步推動“雙減”政策實施的方向、有針對性的強化政策操作與執行力度。根據上述分析,筆者提出以下幾點建議:
(1)關注公眾輿論方向,及時調整教育政策實施重點和方向。政府機構應當密切關注社會各界對于教育政策執行效果和社會影響的反饋意見和輿情動態,及時收集、分析和應對各種聲音和反饋,以更好地傾聽民意,保障教育政策實施的公正性和透明度。同時,根據實際情況和社會反饋及時調整和優化教育政策的執行重點和方向。在教育政策實施過程中不斷完善政策措施,加強督導檢查,并能夠靈活地進行調整,避免產生不利影響,確保教育政策目標的順利實現。
(2)加強教育政策執行監管、督導力度,保證不同地區以及同一地區的城鄉學校齊頭并進。政府機構應當建立科學有效的管理制度和監管體系,從制定、實施到評估各個環節都要健全規范,落實責任制,加強數據統計與分析,確保教育政策執行的科學性、公正性和可行性。增強信息公開和溝通機制,加強與社會各界的溝通,提高透明度,及時發布教育政策信息和執行情況,并注重對“雙減”政策和后續政策的宣傳和普及,為公眾了解政策目標、內容和效果提供便利,樹立政府公信力和形象。有關部門也應該加大對“雙減”政策的解讀和宣傳力度,提高社會各界對政策的認知度和支持度。其次,學校之間的資源配置應按照實際需求和情況進行調整,確保各個地區、各個學校的教育資源均衡配置。政府要給予學校更多的自主權和管理權限,讓學校自主管理,依法依規治理,詳細制定必要的工作計劃和標準,以規范化、科學化的方式推進教育政策的實施。
(3)發展社會經濟,縮小貧富差距,促進教育資源合理分配。實施“雙減”政策需要配合發展社會經濟,通過發展經濟來縮小貧富差距,進而促進教育資源合理分配。政府應該制定明確的政策措施,通過財政補貼、資源配置等方式,加強教育資源的公平性,確保資源的合理分配,讓每個學生都能夠享受到公平的教育機會,同時加大對于貧困地區的教育投入,提升貧困地區的教育資源質量,讓貧困地區的學生也能夠享受到優質的教育資源。
參考文獻:
[1] 劉復興.教育政策的邊界與價值向度[J].清華大學教育研究,2002,(1):70-77.
[2] 蔣建華,崔彥琨,王鐘.輿論、教育政策與教育治理現代化[J].教育研究,2021,42(11):132-137.
[3] 彭云,萬紅新,鐘林輝.一種語義弱監督LDA的商品評論細粒度情感分析算法[J].小型微型計算機系統,2018,39(5):978-985.
[4] 蘇瑩,張勇等.基于樸素貝葉斯與潛在狄利克雷分布相結合的情感分析[J].計算機應用,2016,36(6):1613-1618.
[5] 譚翠萍.文本細粒度情感分析研究綜述[J].大學圖書館學報,2022,40(4):85-99+119.
[6] 王義,沈洋,戴月明.基于細粒度多通道卷積神經網絡的文本情感分析[J].計算機工程,2020,46(5):102-108.
[7] 李慧,柴亞青.基于卷積神經網絡的細粒度情感分析方法[J].數據分析與知識發現,2019,3(1):95-103.
[8] 蔡慶平,馬海群.基于Word2Vec和CNN的產品評論細粒度情感分析模型[J].圖書情報工作,2020,64(6):49-58.
[9] 李沅靜.基于二階隱馬爾可夫模型的文本情感分析及其在“雙減”政策中的應用[D].安慶:安慶師范大學,2023.
[10] 辛明遠,劉繼山.基于BERTCNN-LDA模型的輿情檢測方法——以雙減政策為例[J].信息與電腦(理論版),2022,34(2):59-6m9uRuPBbEDk6W9AbU1UUUQ==3.
[11] Sepp H.Jurgen S.Long Short-Term Memory.Neural Computation,1997,9 (8):1735-1780.
[12] 朱光,劉蕾,李鳳景.基于LDA和LSTM模型的研究主題關聯與預測研究——以隱私研究為例[J].現代情報,2020,40(8):38-50.
[13] Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation [J].Journal of Machine Learning Research,2003,3:993-1022.
[14] 張東鑫,張敏.圖情領域LDA主題模型應用研究進展述評[J].圖書情報知識,2022,39(6):143-157.
[15] 關鵬,王曰芬,傅柱.不同語料下基于LDA主題模型的科學文獻主題抽取效果分析[J].圖書情報工作,2016,60(2):112-121.
[16] 馮興杰,張志偉,史金釧.基于卷積神經網絡和注意力模型的文本情感分析[J].計算機應用研究,2018,35(5):1434-1436.
[17] 賈偉,屈宸羽,蔡其勇.“雙減”背景下家長作業焦慮問題還存在嗎——基于扎根理論對C市9區1648名家長的實證研究[J].中國電化教育,2023,(5):95-104.
[18] 朱新卓,駱婧雅.“雙減”背景下初中生家長教育焦慮的現狀、特征及紓解之道——基于我國8省市初中生家庭教育狀況的實證調查[J].中國電化教育,2023,(4):49-56.
[19] 寧本濤,楊柳.中小學生“作業減負”政策實施成效及協同機制分析——基于全國30個省(市、區)137個地級市的調查[J].中國電化教育,2022,(1):9-16+23.
[20] 孟晶,楊寶忠.小學教師對課后服務的認同困境與路徑[J].教育理論與實踐,2023,43(11):28-32.
[21] 張妍,曲鐵華.義務教育學校課后服務:功能議題、現實審思與未來進路[J].當代教育科學,2023,(2):73-80.
[22] 徐承蕓,林通.“雙減”政策實施后師生現實狀況審思——基于對江西省部分小學師生的調研分析[J].基礎教育課程,2022,(7):14-20.
[23] 杜仲瑩.學生和家長對“雙減”工作滿意度超95%[N].昆明日報,2022-04-17(01).
[24] 薛海平,師歡歡.起跑線競爭:我國中小學生首次參與課外補習時間分析——支持“雙減”政策落實的一項實證研究[J].華東師范大學學報(教育科學版),2022,40(2):71-89.
[25] 陸芳,張莉等.中小學校“雙減”實施情況、存在問題及對策——基于江蘇省的實證分析[J].天津師范大學學報(基礎教育版),2022,23(4):25-30.
[26] 梁凱麗,辛濤等.落實“雙減”與校外培訓機構治理[J].中國遠程教育,2022,(4):27-35.
[27] 陳曉慧.“雙減”時代智能技術的可為與能為——基于“家—校—社”協同育人視角[J].中國電化教育,2022,(4):40-47.
[28] 薛二勇,李健,劉暢.“雙減”政策執行的輿情監測、關鍵問題與路徑調適[J].中國電化教育,2022,(4):16-25.
作者簡介:
吳運明:副教授,在讀博士,研究方向為教育數據挖掘與應用。
張琳:在讀碩士,研究方向為教育數據挖掘與應用。
胡凡剛:教授,博士后,博士生導師,副校長,研究方向為教育虛擬社區理論與實踐、教育大數據應用。
Fine-Grained Sentiment Analysis of User Comments on Educational Policies Based on Deep Learning
Wu Yunming1,2, Zhang Lin3, Hu Fangang2
1.School of Education, Qufu Normal University, Qufu 273165, Shandong 2.School of Communication, Qufu Normal University, Rizhao 276826, Shandong 3.School of Information Science and Technology, Northeast Normal University, Changchun 130117, Jilin
Abstract: In the era of smart media, online social media platforms such as Weibo and Tiktok have become one of the most important channels to transmit information between the government and the public, and the public’s comments on education policies on these platforms influence the implementation process, effect and subsequent policies. By integrating the LDA model and the LSTM model, and taking the“double reduction” policy as an example, the study mines the users’ comments on education policies on online social medias and finegrainedly analyzes the users’ multidimensional subjective emotions towards education policies, so as to provide a reference for improving the implementation effect of education policies. It is found that the focus of online social media users’ opinions on the “double reduction” policy is mainly concentrated on 16 comment objects under four themes, among which the users’ emotions are positive in three aspects, including quality education, art activities, and academic qualifications; and the remaining 13 aspects are negative, such as out-of-school training, afterschool service, education fairness, rich-poor gap, and employment.
Keywords: LSTM model; LDA model; sentiment analysis; educational policy
責任編輯:李雅瑄
