新文科視域下口譯教學自動測評系統建構的可解釋研究
2024-08-12 00:00:00韓彩虹許文勝
中國電化教育 2024年7期
摘要:隨著全球化進程的不斷推進,口譯教學在新文科視域下扮演著越來越重要的角色。為了提高口譯教學的效率和質量,自動測評系統被引入口譯教學之中。然而,目前大多數口譯教學自動測評系統在其工作原理和結果的解釋方面出現了諸如模型的黑盒化、評估結果的不透明及評分標準的不明確等問題。該研究以新文科翻譯學視角,通過對口譯任務的要素進行分析,設計了一種可解釋的口譯教學自動測評系統,并基于人工智能的可解釋理論分析,提出了相應的可持續性優化路徑,以提高系統的透明度、可信度和準確度。
關鍵詞:可解釋人工智能;新文科翻譯學;口譯教學;自動測評系統
中圖分類號:G434 文獻標識碼:A
* 本文系2022年度河南省哲學社會科學項目“可解釋人工智能在口譯自動測評系統建構中的應用研究”(項目編號:2022BYY023)、2022年度上海市社科規劃課題“面向突發公共事件的應急語言服務研究”(課題編號:2022BYY009)階段性研究成果。
一、引言
在全球化的浪潮中,口譯作為一種高度專業化的語言技能,其教學與評估在新文科視域下的地位和作用日益凸顯。然而,與傳統的書面翻譯相比,口譯教學與評估面臨著更為復雜的挑戰。口譯不僅要求即時性和準確性,還涉及到非語言因素,如語調、停頓、表達的自然流暢度等,這些因素都給傳統的人工評估帶來了難度。為了應對這些挑戰,自動測評系統應運而生,并迅速成為輔助口譯教學和評估的有力工具。自動測評系統利用先進的語音識別技能和自然語言處理算法,能夠對口譯的內容和形式進行快速而準確的評分,可以節省大量的人力成本。因此,引入自動測評系統成為提高口譯教學效率和質量的必然選擇。
然而,盡管自動測評系統在實踐中展現出了一定的潛力,但其在可解釋性方面的不足卻制約了其進一步應用和發展。在傳統的口譯教學中,教師通過與學生的面對面交流和個性化指導來提升其口譯水平。而自動測評系統作為一種人工智能技術工具,其評估結果往往難以被教師和學生所理解,導致了一定程度上的信任缺失和效果降低,并具有不透明性,常被詬病為黑盒子。2009年保羅˙漢弗萊斯(Paul Humphreys)對人工智能的不透明性進行了分析,認為“計算系統在t時刻相對于認知主體X不透明,以防X在t時刻不知道(系統)的所有認知相關元素”[1]。據此可推知,計算機系統本身從來都不是不透明的,只是對于某個特定主體而言是不透明的。為了增強用戶對機器翻譯的信任度和認可度,讓不透明的計算系統變得透明,需要對相應的算法和原理進行合理的解釋和闡釋。由此,可解釋人工智能(Explainable Artificial Intelligence)的概念也在國內外學者們持續關注中開始浮出水面。斯沃圖特(William R.Swartout)率先以解決代碼合理性問題建議充分解釋人工智能系統行為[2]。米勒(Tim Miller)等將“可解釋性”定義為“展示自己或其他主體做出的決定所依賴的原因”[3]。對于自動測評系統可解釋性的研究旨在洞悉深度網絡內部工作機制、理解模型的決策,扮演人類與深度網絡模型間的接口角色,幫助人們如何構建一個可解釋的網絡模型以及模型的輸出是否合理與可靠。針對口譯教學自動測評系統的可解釋性研究還處于早期階段,主要聚焦自動測評系統的深度網絡方面研究。深度網絡主要是由卷積核、池化層、線性層以及激活算子堆疊而成,其中包含了大量非線性運算,難以厘清其中邏輯理路。在已有的可解釋方法中,大致研究角度主要涵蓋事前解釋方法(Intrinsic Explanation)和事后解釋方法(Post-hocExplanation)。事前角度的可解釋性研究主要通過更改網絡結構或調整訓練過程,使網絡本身具有一定的可解釋性。諸如,Plumb等人在網絡中加入一個可解釋的正則器[4],來提高對網絡輸出進行歸因的質量。Zhang等人在網絡層次中每個神經元添加一個損失項來引導每個神經元學習的不同視覺概念[5]。Li等人在系統的神經網絡中加入一個原型層[6],收集某一類別中共有的特征原型,測試圖像的前向傳播過程類似于人類的推理過程,若圖中的特征與某一類別的原型的整體相似度高,則該圖像屬于這一類。Huang等人引入塊分割和注意力機制,設計了一種細粒度分類的可解釋性框架[7],該模型的可解釋性體現在可以給出塊分割圖與顯著性圖。而事后角度的可解釋性研究主要從訓練好的模型出發,觀測網絡的行為規律、抽取網絡邏輯規則或提取其他人類可解釋的模式。諸如,Zeiler等人通過反卷積、反池化的方式將網絡神經元輸出的激活至反向映射再至輸入空間,觀測每個神經元在關注的圖像中的特征,網絡的淺層更關注圖像的角、邊緣等特征,而高層次更關注于更具有區分性的全局特征[8]。
綜上可見,自動測評系統的出現,為口譯教學帶來了革命性的變革。然而,如何確保自動測評系統在評估過程中的透明度和公正性,成為了研究者關注的焦點。為厘清人工智能技術與口譯教學測評手段跨學科交叉融合的理路,本研究以新文科翻譯學的視角研究口譯教學自動測評系統的可解釋性問題,旨在通過深入分析系統構建的各個環節以及評估結果的表現形式,力求找到解決方案,以提高系統的可用性和可信度。
二、新文科視域下口譯教學自動測評系統的可解釋性問題
人工智能技術的突飛猛進極大推動了翻譯行業的發展,催生了翻譯記憶、術語管理、神經網絡機器翻譯等一大批新技術,引發了翻譯生產模式的劃時代變革[9]。新文科視域下翻譯學科的創新發展可以稱之為“新文科翻譯學”(New Liberal Arts Translation Studies),其概念主要源于王立非等于2022年提出的“新文科語言學”(New Liberal Arts Linguistics)發展構想[10],是立足于中國維度、聚焦當前新時代國際傳播語言服務問題而提出的中國模式解決方案。傳統翻譯學的研究主要關注人類語言的詞匯、語法、語用等基礎語言單元和規則,而新文科翻譯學則更注重現代科技環境下的翻譯問題,例如機器翻譯、自然語言處理等方面的翻譯問題,其內容涵蓋了語言學、計算機科學、人工智能、心理學等多個領域的知識、前沿技術與方法。可以說,新文科翻譯學的構想具有深刻的歷史和時代背景,并隨著人工智能技術的發展和應用,在很大程度上引領了翻譯學邁向智能化時代,已經日益覆蓋到外語學術體系建設、翻譯教學和翻譯測評領域,涵蓋了不同領域中有關機器學習算法可解釋性的研究,具有“文化性、生成性、跨學科性及社會性特征”[11]。由此推知,新文科翻譯學要求口譯教學自動測評系統的建構應考慮語言學、自然語言處理、機器學習、評估標準等多個方面的要求,以實現口譯教學質量的自動評估和可解釋反饋。因為其可解釋性不足不僅會影響系統的應用效果,也限制了對口譯教學過程的深入理解和改進,具體表現為如下幾個方面:
(一)模型的黑盒化問題
口譯教學自動測評系統的算法往往被視為黑盒,即用戶無法了解系統內部的工作原理和決策過程。這種算法黑盒化使得教師和學生難以對系統的評估過程進行監督和驗證,無法確定評分是否合理和可信。算法黑盒化也增加了系統的不可解釋性和不可信度。在口譯教學自動測評系統的運作過程中,首先需要對學生的口譯錄音進行語音識別,將其轉換為文本數據。隨后,系統會分析這些文本數據中的多種語言特征,如詞匯的準確性、語法結構的復雜性、句子的連貫性等。此外,一些高級的自動測評系統還能夠評價非語言特征,例如語調、停頓的適當性以及表達的自然流暢度等。通過這些分析,系統能夠給出一個綜合評分,以此來反映學生的口譯能力。盡管自動測評系統在技術上取得了顯著的進步,但它們在實際運用中仍面臨著一系列的挑戰。其中最為關鍵的挑戰之一便是如何確保評分的公正性和透明性。由于當前大多數口譯自動測評系統所采用的機器學習算法往往是黑箱模型,難以解釋其內部的決策邏輯和評估過程,直接導致了師生對系統的信任度降低,影響其使用體驗和接受程度。
(二)評估結果的不透明問題
口譯教學自動評分系統的評分過程往往被認為缺乏透明度,即用戶難以理解系統是如何得出評分結果的。這主要源于系統內部算法和模型的復雜性,用戶往往無法準確把握評分的具體依據。另外,數據質量和標注偏差也會影響口譯教學評估結果的可解性。如果系統訓練數據的質量不高或存在標注偏差,那么系統學習到的模式和規律可能不準確或不全面,導致評分結果的不確定性和不可信度。口譯教學自動測評系統的評估結果通常以分數或等級的形式呈現,但系統很少提供詳細的解釋或反饋,使得教師和學生難以理解評估結果的具體含義和背后的原因。這給教學和學習過程中的改進提出了挑戰。
(三)評估標準的不明確問題
口譯教學自動測評系統的評估標準往往是模糊的,反饋過于晦澀或抽象,缺乏明確的定義和解釋。學生難以理解口譯表現的“優秀”“良好”和“不足”,無法根據評估標準來有針對性地改進口譯技能。另外,口譯教學自動測評系統在評分過程中往往忽略了文化和語境因素的影響,導致評分結果缺乏準確性和客觀性。口譯涉及到不同語言和文化之間的轉換,而不同文化背景下的表達方式和習慣可能存在差異,這些差異沒有被充分考慮可能導致評分偏頗或不公正。
以上這些可解釋性問題嚴重影響了口譯教學自動測評系統的應用和推廣。缺乏對評估過程和結果的清晰解釋,使得教師和學生難以接受系統的評估結果,也無法根據評估結果進行有效的教學和學習。由此,基于新文科翻譯學的理論框架,嘗試構建具有可解釋性的口譯教學自動測評系統是當前研究和實踐中的重要任務之一。
三、可解釋口譯教學自動測評系統的建構
新文科視域的涌現為口譯教學帶來了新的理論和方法,強調跨學科的整合和創新。這意味著口譯自動測評系統的建構不僅需要考慮評估模型的準確性和效率,還需要關注其可解釋性問題。口譯教學自動測評系統不僅是一個技術工具,更是一個教學輔助平臺,應該與口譯教學的理論和實踐密切結合,為教師和學生提供個性化的支持和指導。因此,在構建口譯教學自動測評系統時,必須充分考慮新文科視域的要求,注重跨學科的整合和創新,以實現口譯教學的現代化和智能化。
(一)口譯教學自動測評系統的理論框架
口譯教學自動測評系統的建構是一個復雜而系統的過程,涉及到測評每個環節和技術手段的綜合運用。在新文科視域下,構建一個具有可解釋性的口譯教學自動評分映射模型至關重要,需要充分考慮到語言學、計算機科學以及教育學等領域的理論與實踐結合,同時關注人工智能技術與口譯測評手段融合過程的透明度和可解釋性,進而形成基于人工智能的口譯自動評分系統構念圖。整體設計思路如圖1所示。
首先,參照相關研究成果及標準確定口譯測評系統的評分參數,包括詞匯、句法和邏輯、音段和超音段層面特征。針對音段和超音段層面,采用語音自動測評方法以及HMM技術獲得考生的語音特征值;針對詞匯層面,采用關鍵詞覆蓋率、N元組提取、PageRank算法、文本覆蓋率等方式獲取考生譯文的關鍵詞、術語、語義相似度、銜接性情況;針對句法和邏輯層面,采用FDG、Chart-based parser等語法分析工具對考生譯文的語法完整性進行分析;借助LISP等邏輯編程語言,對譯文中的命題邏輯及謂詞邏輯情況進行考察。其次,借助人工神經網絡技術以及深度學習對機器進行訓練。最后,采用描述性分析和相關性分析方法測試并修正口譯測評系統。尤其在確定口譯教學自動測評系統參數方面,包括如下兩個層面特征:
(1)音段和超音段層面特征。構建由多名專業譯員錄制的參考答案語音語料庫。交傳、同傳語料分別采用單聲道和雙聲道錄制,以mp3格式保存,能夠體現專業譯員對流利度、重音、節奏等音段和超音段、同步性等層面的準確把握。此外,收集由考生考試現場錄音組成的語料,并統計考生的成績分布情況。提取語音特征并構建語音模型。采用MFCC(Mel-Frequency Ceptral Coefficients)特征參數與PLP(Perceptual Linear Predictive)特征參數,分別用在考生的語音識別以及評估模型的構建方面。基于HMM模型(Hidden Markov Model)的概率統計法構建讀音模型,作為口譯評分映射指標之一,旨在判斷不同考生的語音在音段和超音段層面的差異,以此來評價考生的語音情況。此外,采用音素后驗概率法內置標準語音庫(基于標準語音數據訓練獲得的標準語音模型)。根據范文裁剪后的定制語言模型進行連續語音識別,利用二元語言模型對識別結果予以解碼,得到最大似然序列。
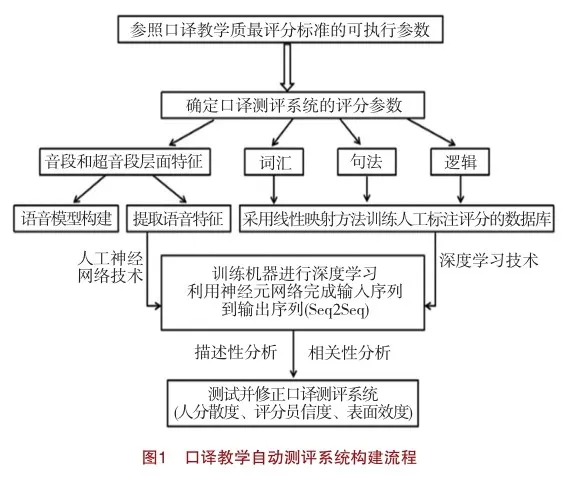
(2)詞匯、語義、句法和邏輯層面特征。將關鍵詞、術語和銜接詞等的覆蓋率、語義相似度、句法和邏輯結構等維度評分特征,輸入到專家評分映射模型中作為技術模型,采用線性映射方法,對人工標注評分的數據庫訓練,以便為最終自動評分提供準備。關鍵詞、語義相似度、術語和銜接詞等維度評分特征輸入,由專業譯員標注參考答案中涉及的關鍵詞集以及術語的多種表達方式,并生成詞圖。同時,將原文各句劃分為2—3個語義單位,對照多篇最佳譯文中的N元組提取(N元組匹配數量及其百分比),考察譯文語義質量。關鍵詞對齊數量,可借助詞典的詞對齊及模糊匹配的方法;對于考生出現的用自己的語言繞過關鍵詞進行表達的情況,可通過文本覆蓋率的方法處理,以便對關鍵詞等覆蓋率進行考察。針對銜接詞,構建考生譯文的詞圖,借助PageRank算法計算基于權重的詞匯銜接,形成WLC以及依賴詞性的PWLC(post-WLC)詞匯銜接評價方法。針對句法和邏輯結構評分特征輸入,則主要對譯文進行完整的語法分析,并借助于FDG、Chart-based parser等語法分析工具對此進行處理。而邏輯編程語言,如LISP則通過命題邏輯以及謂詞邏輯的方法對自然語言予以分析處理。
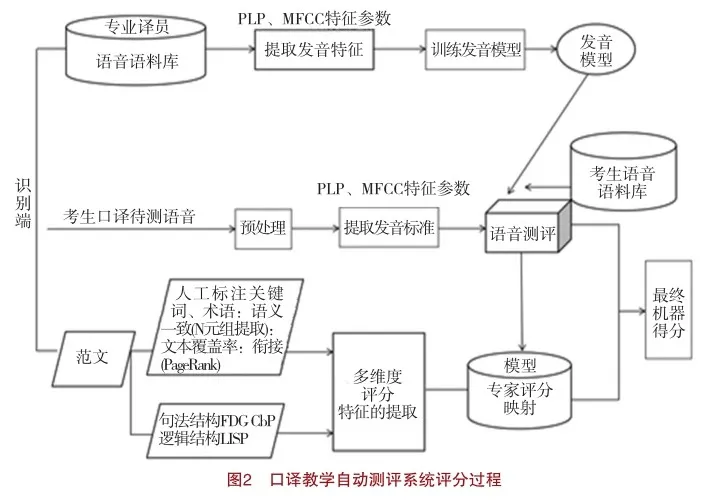
(二)口譯教學自動測評系統的評分理據
口譯教學自動測評系統的評分過程是基于口譯的準確性、完整性、流暢性、文化適應性等多方面進行綜合評估的。通過這些準則,系統主要采用語音自動測評方法以及HMM技術獲得考生的語音特征值,與專業譯員的語音進行聲學差距對比。同時,基于人工智能相關技術構建口譯評分映射模型,并不斷訓練,從多維層面全面、客觀評價考生的口譯水平。如圖2所示。
首先,構建專業譯員語料庫,并通過PLP、MFCC特征參數提取其發音特征,以便訓練發音模型。隨后,通過識別端導入考生口譯待測語音,并進行預處理,形成考生語音語料庫。提取相關特征并預處理后,計算機能夠自動分析出考生與專業譯員發音的聲學差距。同時,提取關鍵詞、術語和銜接詞等的覆蓋率、語義相似度、句法和邏輯結構等維度特征,形成專家評分映射模型,不斷訓練人工標注評分數據庫,自動獲得最終得分(詞匯、句法和邏輯、音段和超音段層面的分數合計)。
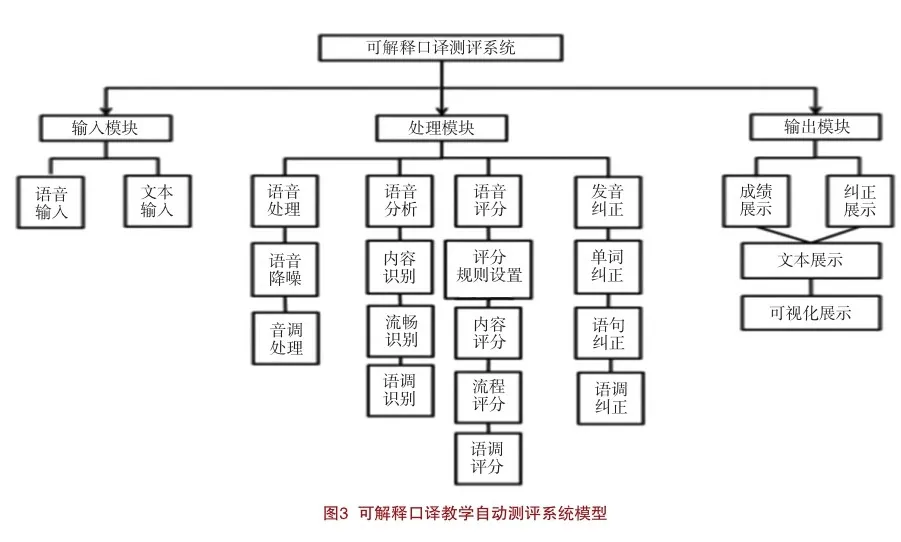
(三)可解釋口譯教學自動測評系統的構建
1.模型構建
設計一個可解釋的口譯教學自動測評系統模型,需要考慮到口譯的核心要素和評估標準,同時確保系統的可解釋性。主要針對上述關于自動測評系統的模型黑盒化、評估結果不透明及評估標準不明確問題構建了可解釋口譯教學自動測評系統。如下頁圖3所示:可解釋口譯教學自動測評模型主要涵蓋輸入、處理及輸出三個模塊。其中,在輸入模塊選用了語音和文本同步輸入的正則器嵌入技術,便于追溯到評估結果的產生過程,包括使用了哪些數據、哪些特征、哪些模型和算法等。在處理模塊主要添加一個損失項來引導神經元學習的不同視覺概念,考慮多個方面的口譯表現評估,包括語音語調、詞匯運用、語法準確性等,以全面評估學習者的口譯能力,尤其是語音降噪技術與口譯測評手段的結合,使得評估過程能夠成為口譯教學的一部分,促進學習者的有效學習和提高口譯能力。在輸出模塊主要嵌入了反卷積、反池化的可解釋技術,以成績展示和糾正展示提供及時有效的反饋機制,便于幫助學習者了解自己的口譯表現,指出表現中存在的問題,并提供改進建議。
2.數據集構建
在英語基礎口譯教學成績單中,選出1 5 8條記錄,每條記錄中選擇ECSentence Interpretation1—5的音頻文件作為訓練數據,共有158*5=790條音頻數據。在成績單中得分呈現離散分布:0,0.25, 0.5,0.75,1,1.25,1.75,2,2.25,2.5,2.75,3共13個類別。接著,將音頻轉換成聲波圖形,圖像分辨率統一為640*640。為了能夠更加準確提取波形特征,使用OPENCV(這是一個常用圖像處理模塊)對圖像進一步處理提取邊界特征,然后生成數據標簽。每行標簽記錄分為兩部分組成:第一部分為圖片文件名,文件命名由記錄序號和題目序號組成,這里得分是類別序號,從0—12分別對應實際得分0—3,每個臨近類型相差0.25分。標簽數據記錄保存到train.txt中,從原始數據抽取100個數據作為驗證數據,保存驗證標簽數據到valid.txt中。
3.模型訓練
在訓練模型前,首先需要打亂標簽記錄順序,從中一次取出8個記錄,輸入模型,模型通過運算后得到預測值,直到790個數據全部計算完成,使用損失函數計算預測值與真實值之間的誤差,則模型會自動朝著使誤差較小的方向進行調整,最終實現盡可能多地滿足預測值,這個過程就是模型反向傳播。模型經過第一次自動調整后,再去在驗證數據集上使用,可以等到一個預測正確的概率。這樣就完成一輪數據運算,也叫一個epoch。整個訓練過程進行了90個epoch運算,每經過20個epoch,模型反向傳播的幅度(也叫學習率)變成原來的1/10,這就是朝著正確方向更新的幅度減小,之所以這樣,是因為隨著計算的進行,模型會逐漸朝著最正確的方向進行,在越接近正確值時,速度要降低一些,否則就容易更新趨于絕對化,會相應得出一個效果不理想的值。在每個epoch運算完成后,就用驗證值檢查一個正確率,如果正確率比上次高,就把模型記錄到一個best.pt文件中,如果正確率下降,就直接略過,依此循環反復,經過90個epoch之后,把正確率最高的模型保存下來,由此,可以初步獲得一種可解釋口譯教學自動測評映射模型。
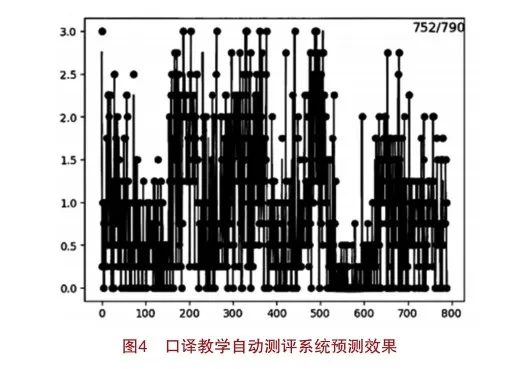
4.實驗結果與分析
如圖4所示,通過使用best.pt模型文件,對整個數據集中790數據進行預測,其中,有752個圓點與曲線重合,表明模型的預測正確率達到了95.18%,具有較高的準確度,同時又以文本可視化進行了解釋反饋,與預期構建目標基本達成了一致性。
實驗結果表明:(1)該系統基于新文科翻譯學的理論框架,能夠對口譯表現進行解釋,包括口譯中的語法結構、語義表達、語用特點等情況給予反饋,通過解釋系統對這些語言現象的識別和分析過程,可以較好解決模型的黑盒化問題,增加系統評估結果的可信度和可理解性;(2)系統能夠利用語言知識和自然語言處理技術對口譯文本進行分析,并將分析結果轉化為最終的評分和反饋,通過透明的評估過程能夠較好解決評估結果的不透明問題,便于更好地理解系統的工作原理和評估結果的可信度;(3)系統的評分標準能夠被解釋和理解,反映新文科翻譯學的觀點和原則,已經包括評估口譯質量所考慮的準確度、流暢度、表達能力等關鍵因素,能夠較好解決評分標準的不明確問題。
四、口譯教學自動測評系統的可解釋理論分析
在新文科翻譯學視域下,對口譯教學自動測評系統的可解釋性分析需要更加注重系統的理論框架與語言現象解釋、評分標準的解釋與建構、評估過程的透明性以及反饋信息的解釋和指導等方面,以適應復雜多變的社會需求和跨文化交流挑戰,也相應形成了多學科融合、符號主義與連接主義結合及多模態數據處理技術整合的可解釋分析理論依據。
(一)多學科融合的可解釋分析
基于算法的復雜度導致的模型黑盒化問題,上述系統考慮到利用語言學知識、自然語言處理技術及學習者的認知心理對口譯文本進行分析,基于新文科翻譯學的學科交叉融合特征,主要是借鑒解釋學理論和方法,深入探討可解釋性在口譯教學自動測評系統模型中的應用,提高其模型的解釋性和可理解性,使可解釋人工智能技術更加接近人類表達和思考方式。口譯教學自動測評系統的解釋性可以分別從認知心理學、哲學和計算機科學的多學科融合視角進行闡釋。諸如:解釋性的理論基礎起源于認知心理學。其中,人類的認知系統是一個有機的整體,單獨的思考方面難以對整個人類認知系統做出有效的描述。人類認知過程中,通過感知到的信息和知識體系進行思考、發現和理解新信息。因此,了解人類認知心理學對于設計并使口譯教學自動測評系統有較好的可解釋性是至關重要的。而解釋學作為哲學范疇,強調了解和表達人類理解力和創造力、思考人類認為是真理和價值觀的方式。從傳統的哲學思考到現代哲學研究,解釋學對于文化、社會、自然科學等領域均有深刻的影響。另外,以機器學習和人工智能為代表的計算機科學,也為口譯教學自動測評系統的可解釋性研究與應用提供了理論基礎和技術支持。機器學習和人工智能通過把具有經驗性質的信息數據提供給計算Fw3i3aKcEvc7a7fanENSSRM8lBvjPcOJouxowhbhLcU=機來實現模式的識別和處理。這些技術研究的結果可應用于解釋模型決策過程中的不透明性。同時,計算機科學中的交互式技術,如可視化和對話機制,也允許用戶更好地理解和控制口譯教學自動測評系統。
(二)符號主義與連接主義相結合的可解釋分析
基于標注偏差和數據質量導致的評分結果不透明問題,上述口譯教學自動測評系統主要利用符號主義與連接主義相結合的自然語言處理技術,以處理口譯文本的語言特征、語法結構和語義信息。包括分詞、詞性標注、句法分析、語義分析等技術,以便能夠準確理解口譯文本的含義和表達方式,從而進行評估和反饋。基于新文科翻譯學的生成性特征,重視自然語言處理中語境和語義的復雜性,從而在開發可解釋的AI算法時主動考慮語言和文化的多元性,符號主義(Symbolism)與連接主義(Connectionism)相結合的技術語言識別性,這樣可以提高人工智能技術在各種不同地理、社會和文化背景下的應用效果,更好地服務于不同用戶群體。其中,符號主義認為語言是由離散的符號組成的,這些符號具有固定的意義和組合規則。利用形式語言學和邏輯學方法來研究語言的本質,從而實現人工智能在自然語言處理方面的應用。符號主義的一大優點是可以理解和解釋人類語言使用的規則,但它也存在一個難題,就是難以處理語言的模糊性和多義性。而連接主義則認為語言是由神經元之間的連接關系組成的。神經網絡可以通過海量的語料庫學得語言規律和語義聯想,從而實現自然語言處理。連接主義的優點在于能夠處理多義性和模糊性等語言特征,但它也很難解釋語言內部的規則和邏輯。
(三)多模態數據處理技術整合的可解釋分析
基于語言文化差異性導致的評分標準不明確問題,上述口譯教學自動測評系統主要通過整合多模態數據處理技術,對口譯學習者的口譯表現進行全面評估,同時提升系統的透明度。事實上,可解釋的多模態處理技術法已在多個領域的研究和應用中得到了佐證。諸如,學者朱富坤等探討了關鍵數據路由路徑(Critical Data Routing Path,CDRP)這一面向網絡路徑的可解釋方法,實驗結果從路徑熱力圖可視化以及相應的預測與定位精度等角度驗證了Score-CDRP方法相較于CDRP的合理性、有效性和魯棒性[12]。盧宇等研究梳理和提出了可解釋人工智能在微觀、中觀和宏觀三個層面的教育應用模式,即檢驗教育模型、輔助理解系統與支持教育決策[13]。王文杰等提出了一種基于理性情感的評論情感分析算法及可解釋性研究[14]。該方法利用情感理性分析和多標簽學習的思想,構建了一個基于規則的理性情感分析模型,從多種角度解釋了該方法分析情感的過程,提高了情感分析模型的可解釋性。學者吳文梅以釋意派的口譯三角模式為基礎,以“口譯過程兩階段解讀”為參照,借鑒認知心理學與心理語言學關于語言與語言表達過程的研究成果,分析口譯過程的各階段及其關系,以及其間運用的信息加工方法,構建并闡釋了口譯三角模型(細化版)(Interpreting Triangle Model,即IT Model[15],幫助口譯教學和測評的可解釋性。
總之,該可解釋口譯教學自動測評系統基于新文科翻譯學的視角,形成了多學科融合、符號主義與連接主義結合、多模態技術融合的理論依據,關注模型可解釋性、透明度和可追溯性、反饋機制、教學與評估融合等方面的要求,便于實現對口譯教學的有效支持和促進。據此,通過不斷的技術創新和方法改進,可以期待未來的可解釋口譯教學自動測評系統能夠不斷優化升級,不僅能夠提供準確的評分,還能夠向用戶提供清晰的評分依據,從而在口譯教學領域發揮更大的作用,不斷拓展新文科翻譯學的研究邊界。
五、可解釋口譯教學自動測評系統的優化路徑
新文科翻譯學視域下口譯中的多樣性和主觀性則是自動測評系統的挑戰。可解釋性指的是系統的決策過程能夠被用戶理解和信任的程度。這意味著要增強系統的透明度、可信度及準確度,需要具備持續改進的機制,根據用戶反饋和實際應用情況,不斷優化和更新系統的評估模型、算法和界面設計,發掘相應的優化路徑。
(一)基于增強系統透明度的可解釋模型嵌入路徑
構建一個可解釋的自動測評系統是一個多方面的工程,它需要技術的創新、教育專家的深入參與以及用戶的積極反饋。尤其在訓練口譯教學自動測評系統進行深度學習環節,需要嵌入相應的可解釋模型,便于自動測評系統不僅能夠提供準確的評分,還能夠向用戶提供清晰的評分依據,使測評系統由黑盒化轉向白盒化。
1.詞向量構建的可解釋性模型
在基于深度學習的機器翻譯技術中,詞向量是一種用于表示自然語言文本中單詞的一種向量化表達方法。機器翻譯模型通常會將源語言和目標語言中的單詞映射到一個高維空間中的向量表示。這些向量可以被看作是單詞的詞向量,每個維度代表著某種語義特征。詞向量在機器翻譯中起到非常關鍵的作用,它可以幫助模型更好地理解和表達單詞之間的語義關系,從而提高翻譯質量。詞向量的構建通常采用詞嵌入技術,它將每個單詞映射到一個固定長度的實數向量中。唐明等提出,Word2vec是一種通過預測單詞出現上下文來學習單詞向量的工具,它是一種用于實現分布式詞向量學習的一種算法。它的目的就是將訓練數據中的每個單詞表示為向量,然后對這些單詞向量進行聚類,并在聚類之間定義單詞之間的相似度[16]。
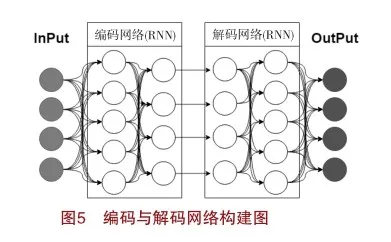
2.編碼與解碼網絡構建的可解釋性模型
基于編碼解碼機器翻譯思想:在編碼網絡將源語言句子進行編碼,獲得分布式語義表示,解碼網絡從源語言分布式語義表示出發解碼出目標語言句子。如圖5所示,實現的是一種端到端的網絡模型結構。
在輸入層,把源語言中的語句轉換成詞向量序列輸入到編碼網絡中。在編碼網絡中把輸入的詞向量序列轉換一個特定的向量值,這個向量包含了源語言句子中的信息,包括語義、詞序等所有的特征。為能夠同時提取到從左向右的語句上下文信息,需要使用循環神經網絡(RNN)進行計算,RNN能夠很好地將語義信息在網絡層之間進行傳遞和積累,在處理語句序列的任務中表現出較好的效果。在解碼網絡中,通過包含多個RNN隱層和一個全連接層,在RNN隱層中,以編碼網絡中傳遞的值為起點,進行計算目標語句生成所需的信息,經過多輪計算后,使用全連接層預測出目標語言詞語的可能出現概率。選出最大概率的詞語來組成語句,進而完成翻譯任務。
3.注意力機制構建的可解釋性模型
在機器翻譯技術中,最大的難點是如何解決自然語言的多義性。一句話往往有不同的解釋和含義,而且同一個單詞在不同的上下文中也可能有不同的詞義,這給機器翻譯帶來了巨大的挑戰。注意力機制可以很好地解決一詞多義性問題。通過引入對齊權重,注意力機制使得模型可以根據源語言和目標語言之間的對齊關系,選擇性地聚焦于源語言和目標語言之間的特定區域,從而能夠更好地識別句子中的重要信息。注意力機制還可以實現動態選擇性關注,即讓模型根據輸入的源語言和目標語言,動態地調整對不同詞匯的關注程度。比如,使用Transformer注意力機制編碼與解碼網絡結構模型,在WMT2014英語到德語的翻譯任務上,取得明顯的性能提升[17]。
(二)基于增強系統可信度的用戶全過程追蹤路徑
在實踐口譯教學自動測評系統過程中,針對系統評分結果的不透明性問題,主要通過提供用戶友好的反饋和解釋以及強化參與反饋機制等方法進行精準施策。
1.提供用戶友好的反饋和解釋
為提高用戶對口譯教學自動測評系統的理解和接受度,主要從如下幾個方面找到解決問題的突破口:一是引入多樣化的反饋形式,如語音、圖像、視頻等,以滿足不同用戶的學習偏好和需求。二是利用機器學習和個性化推薦技術,為用戶提供智能化的個性化建議。系統根據用戶的口譯表現和學習歷史,針對性地給出改進建議,幫助用戶更加有效地提升口譯能力。三是采用實例引導式解釋,在解釋評價和建議時,采用實例引導式的方法,通過具體案例和示范,幫助用戶理解評價標準和改進方向。例如,提供優秀口譯案例的分析和比較,指導用戶如何改進自己的口譯表現。四是針對不同用戶群體,主要進行語言普及和文化適應,確保反饋信息易于理解和接收。例如,針對非母語用戶,提供簡明易懂的解釋,避免使用復雜的語言結構和專業術語。五是建立反饋循環閉環機制,鼓勵用戶根據系統反饋進行自我調整和改進,并及時反饋使用體驗和需求。主要通過建立用戶參與的反饋循環,不斷優化系統的反饋機制和內容,提高用戶的滿意度和學習效果。
2.強化用戶參與和反饋機制
強化口譯教學自動測評系統的用戶參與和反饋機制是提升系統質量和用戶體驗的重要途徑。在提升口譯自動測評系統可解釋性實踐中,主要采用如下方法開展:一是定期向用戶發送調查問卷或反饋表,了解他們的意見和建議。主要涵蓋系統的易用性、功能改進、內容更新等內容。二是創建一個在線論壇或社區,讓用戶分享他們的體驗、提出問題并與其他用戶交流,便于鼓勵用戶參與討論,并提供及時的反饋。三是定期更新和溝通,及時向用戶通報系統的更新內容和改進計劃,讓他們了解系統的發展方向,并鼓勵他們繼續參與反饋。四是不僅關注用戶提出的建議,還要密切關注他們的實際體驗。通過分析用戶行為和使用數據,發現潛在問題并及時改進,并將用戶反饋作為持續改進的動力,不斷優化系統功能和性能,以滿足用戶的需求和期待。
(三)基于增強系統準確性的多源信息融合路徑
口譯教學自動測評系統的準確性是其核心競爭力之一。為了持續解決系統評分標準的不明確問題,主要采用多源信息融合策略,綜合利用不同的信息源,提高系統評估的準確性。主要涵蓋語音識別技術、文本語義分析、語境理解、專家評估與反饋、實時反饋與調整、持續學習與優化的多源信息融合。其中,語音識別技術將口譯員的口語輸入轉換為圖片形式,可以作為系統評估的基礎。通過文本語義分析技術,理解口譯員的表達含義和意圖,便于系統更準確地評估口譯員的表達是否準確、清晰。通過模擬口譯不同語境的場景來提高口譯準確性的評估。通過邀請口譯領域的專家參與評估,提供專業意見和反饋,幫助系統發現并糾正可能存在的錯誤。通過提供實時的反饋,告知口譯員在表達或翻譯中可能存在的問題,并提供改進建議。通過深度學習技術不斷學習和優化口譯教學自動測評系統,結合歷史數據和用戶反饋,進行模型更新和參數調整,以適應不斷變化的口譯環境和需求。
六、結論與展望
口譯教學自動測評系統的可解釋性問題是當前研究和實踐中的重要挑戰之一。在新文科視域下,構建一個具有可解釋性的口譯教學自動測評系統對于提高口譯教學效率和質量具有重要意義。本文該研究以新文科翻譯學視角,通過對口譯教學自動測評系統建構的各個方面以及可解釋性問題的深入探討,提出了一系列解決方案和實現優化路徑。首先,口譯教學自動測評系統的建構需要充分考慮數據采集、特征提取、模型訓練和評估指標設計等方面,以確保系統的基礎和功能完備。其次,口譯教學自動測評系統的可解釋性問題主要表現為模型黑箱化、評估結果不透明和評估標準不明確等方面,需要通過透明數據處理、特征解釋性、模型可解釋性、評估標準明確化、結果反饋機制以及用戶參與設計等途徑來解決。通過對口譯教學自動測評系統的可解釋性問題進行深入分析和探討,可以為口譯教學自動測評系統的設計、開發和應用提供重要參考,促進口譯教學的現代化和智能化進程系統的透明度、可信度和準確度。未來,我們需要將繼續關注口譯教學自動測評系統的研究和實踐,不斷探索更加有效和可解釋的方法,為口譯教學的發展貢獻更多的思想和力量。
參考文獻:
[1] Paul Humphreys.The Philosophical Novelty of Computer Simulation Methods [J].Synthese,2009,169(3):615-626.
[2] William R.Swartout.XPLAIN:A System for Creating and Explaining Expert Consulting Programs [J].Artificial intelligence,1993,21(3):285-325.
[3] Tim Miller.Explanation in artificial intelligence:Insights from the social sciences [J].Artificial Intelligence,2018,267:1-38.
[4] Plumb G,Al-Shedivat M,et al.Regularizing black-box models for improved in terpretability [J].Advances in Neural Information Processing Systems,2020,33:10526-10536.
[5] Zhang Q,Wang X,et al.Interpretable cnns for object classification [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2021,43(10): 3416-3431.
[6] Li O,Liu H,et al.Deep learning for case-based reasoning through prototypes:A neural network that explains its predictions [C]. New Orleans:Proceedings of the AAAI Conference on Artificial Intelligence,2018.
[7] Huang Z,Li Y.Interpretable and accurate fine-grained recognition via region grouping [C].Paris:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2020.8662-8672.
[8] Zeiler M D,Fergus R.Visualizing and understanding convolutional networks [C].Beijing:European Conference on Computer Vision,2014.818-833.
[9] 王均松,肖維青等.人工智能時代技術驅動的翻譯模式:嬗變、動因及啟示[J].上海翻譯,2023,(4):14-19.
[10] 王立非,栗潔歆.主動服務高質量發展,加快建設中國特色“新文科語言學”[J].北京第二外國語學院學報,2022,44(1):3-10.
[11] 韓彩虹,許文勝.新文科語言學視域下的外貿口譯職業能力調查及智能對策——基于中國邊境區域外貿從業人員的調研分析[J].外語電化教學,2023,(5):25-31+105.
[12] 朱富坤,滕臻等.一種語義引導的神經網絡關鍵數據路由路徑算法[J].計算機科學,2024,(4):1-11.
[13] 盧宇,章志等.可解釋人工智能在教育中的應用模式研究[J].中國電化教育,2022,(8):9-15+23.
[14] 王文杰,張柯等.基于理性情感的評論情感分析算法及可解釋性研究[J].計算機應用研究,2021,38(2):358-362+367.
[15] 吳文梅.口譯三角模型(細化版)IT Model:構建與闡釋[J].上海翻譯,2023,(1):66-72.
[16] 唐明,朱磊等.基于Word2Vec的一種文檔向量表示[J].計算機科學,2016,43(6):214-217+269.
[17] 馮洋,邵晨澤.神經機器翻譯前沿綜述[J].中文信息學報,2020,34(7):1-18.
作者簡介:
韓彩虹:教授,在讀博士,研究方向為口譯理論與實踐。
許文勝:教授,博士,博士生導師,研究方向為口譯理論與實踐。
Interpretability Research on the Construction of an Automatic Evaluation System for Interpreting Teaching from the Perspective of New Liberal Arts
Han Caihong1,2, Xu Wensheng1
1.School of Foreign Languages, Tongji University, Shanghai 200092 2.Zhengzhou University of Science and Technology, Zhengzhou 450064, Henan
Abstract: With the continuous advancement of globalization, interpretation teaching is playing an increasingly important role in the field of new humanities. In order to improve the efficiency and quality of interpreting teaching, an automatic evaluation system has been introduced into interpreting teaching. However, currently most automated evaluation systems have encountered issues such as black box modeling, opaque evaluation results, and unclear scoring criteria in their working principles and interpretation of results. This study, from the perspective of new liberal arts translation studies, analyzes the elements of interpreting tasks and designs an interpretable automatic evaluation system for interpreting teaching. Based on the interpretable theory of artificial intelligence, corresponding optimization strategies are proposed to improve the transparency, credibility, and accuracy of the system.
Keywords: explainable Artificial Intelligence; new liberal arts translation studies; interpretation teaching; automatic evaluation system
責任編輯:李雅瑄
