基于多軸自注意力的無人機避障模型
2024-08-28 00:00:00王新趙偉杰
機械制造與自動化 2024年4期
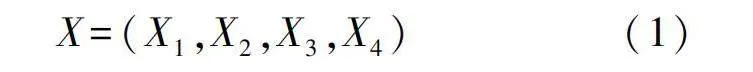

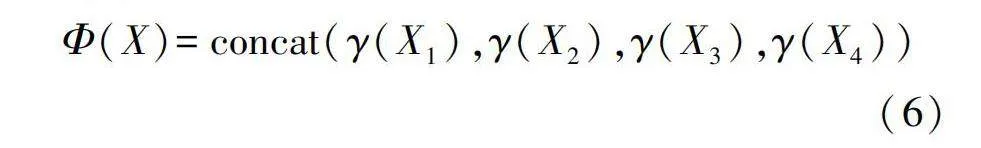
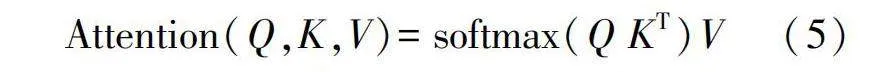
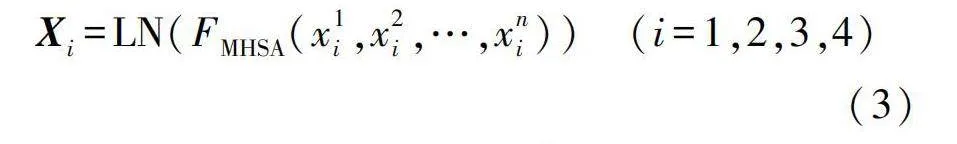

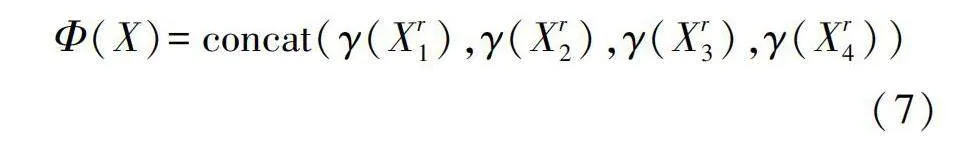
摘 要:針對無人機在飛行過程中容易因旋翼碰撞而墜毀的問題,提出利用改進的圖像識別模型實現自動預警。將瓶頸多軸自注意力模塊(BMSA)嵌入到圖像識別模型中進行改進,提升模型對細小物體的識別準確率。多軸自注意力層在低分辨率階段替換原本卷積層,使得模型能夠兼顧局部自注意力和全局自注意力。實驗結果表明:改進得到的多軸自注意力的殘差網絡(MS-ResNet)具有較高的障礙物識別準確率,能實現較好的預警效果。
關鍵詞:圖像識別;深度學習;自注意力機制;卷積神經網絡;避障模型;無人機
中圖分類號:TP391.4 文獻標志碼:A 文章編號:1671-5276(2024)04-0124-05
UAV Obstacle Avoidance Model Based on Multi-axis Self-attention
WANG Xinwen1, ZHAO Weijie2
(1. School of Advanced Manufacturing, Fuzhou University, Quanzhou 362251, China;2. Quanzhou Reserch Center of Equipment Manufacturing of Haixi Institute, Chinese Academy of Science, Quanzhou 362216, China)
Abstract:To address the proneness of UAV crash due to rotor collision during flight, an improved image recognition model is proposed to achieve automatic warning. A bottleneck multi-axis self-attention module (BMSA) is embedded into the image recognition model for improvement, enabling the model to improve the recognition accuracy of the model for fine objects. The multi-axis self-attentive layer replaces the original convolutional layer in the low-resolution stage, enabling the model to obtain both local self-attention and global self-attention. The experiments show that the improved multi-axis self-attentive residual network (MS-ResNet) has high accuracy of obstacle recognition and achieve a better early warning effect.
Keywords:image recognition; deep learning; self-attention mechanism; convolutional neural network; obstacle avoidance model; UAV
0 引言
基于視覺系統的障礙物預警系統是實現無人機安全飛行的重要研究內容。在無人機飛行過程中,航拍攝像頭通常無法采集到無人機旋翼上方圖像,導致無人機有旋翼撞擊障礙物而墜毀的風險。為了解決這個問題,通過圖像識別算法對無人機的飛行路徑進行實時避障預警。相比無人機上的單目避障系統[1]和SIFT圖像匹配避障方法[2],采用圖像識別網絡來實現避障系統計算量較低、精度較高,能夠較好地平衡計算耗時和準確率。
圖片識別算法在各個領域已經實現廣泛的應用,2012年,深度卷積結構的AlexNet[3]在ILSVRC[4]分類挑戰大賽中取得讓人印象深刻的成績。GoogLeNet[5]在ILSVRC大賽上實現了74.8%的top-1準確率,后來提出的ResNet[6]相比其他模型實現了非常顯著的準確率提升。
近幾年來,研究人員開始研究計算機視覺任務中的Transformer[7]結構,BoT[8]基于ResNet提出帶有多頭自注意力模塊的基本組成結構,同樣可以堆疊得到類ResNet的網絡模型。TU等[9]提出結合局部自注意力和全局自注意力的方法,基于此,本文對BoT進行改進,提出多軸自注意力的殘差網絡(deep residual network of multi-axis self-attention, MS-ResNet)模型。
主要創新和工作如下所述。
1)通過視覺系統實現無人機飛行避障預警,以降低旋翼碰撞的風險。在公開數據集中搜集大量無人機飛行障礙物的數據,對相關圖像識別網絡進行訓練和對比。
2)根據Max-ViT中提出的多注意力融合方法,提出一種嵌入卷積網絡中的多軸自注意力模塊對圖像識別模型進行改進,以增強模型對障礙物的識別準確率。
3)為驗證所提方法對圖像識別模型的有效性,在CIFAR、FLOWER-102和ImageNet等圖片識別數據集上進行了大量的對比實驗,充分驗證預警模型的先進性。
1 視覺避障模型
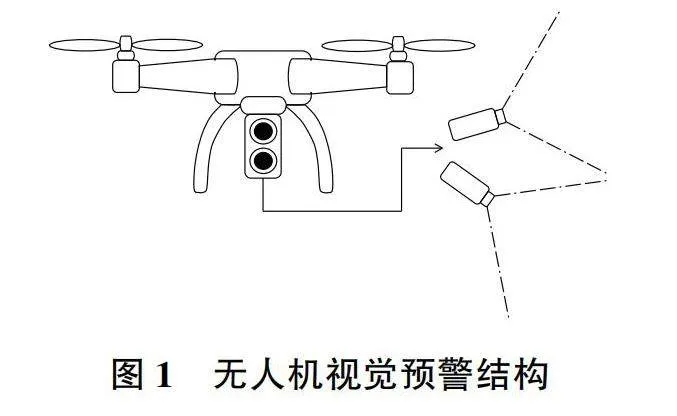
通常無人機的航拍攝像頭是向下傾斜的,這樣會導致操縱無人機時無法注意到前方或者上方的微小障礙物,以至于無人機的旋翼發生碰撞而墜機。本文提出的無人機視覺預警系統如圖1所示,在無人機的前方添加一個向上傾斜的攝像頭,對前上方的場景進行自動拍攝,再由圖像識別系統對危險物體進行實時預警,從而避免無人機的旋翼發生碰撞。圖像識別模型在無人機嵌入式設備或者云計算終端上對上傾角攝像頭的拍攝圖像進行實時分析,達到對障礙物預警的目的。
無人機避障系統的預警效果由圖像識別模型的準確率來體現。基于視覺系統的避障系統,要求對大尺寸物體和小尺寸物體識別準確率足夠高,因此,下面對圖像識別網絡進行改進。
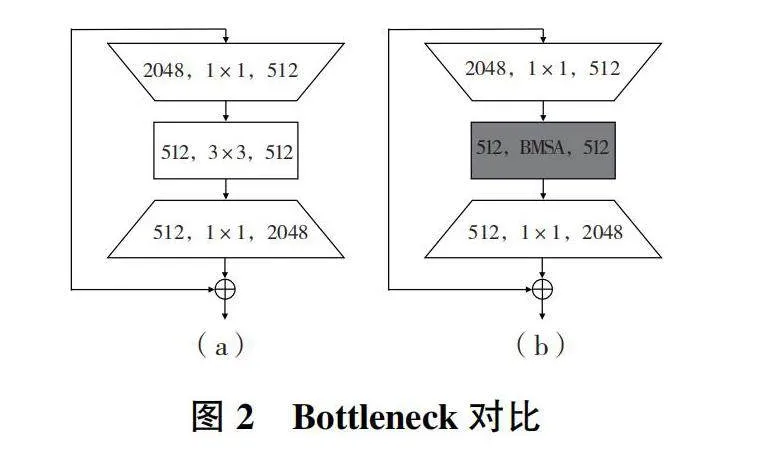
圖2(a)是深度殘差網絡的Bottleneck,其中包含1個1×1卷積層、1個3×3卷積層再加上1個1×1卷積層。圖2(b)為所提方法,將1個多軸自注意力模塊嵌入到深度殘差網絡的Bottleneck中,對特征圖進行空間上的局部建模和全局建模。
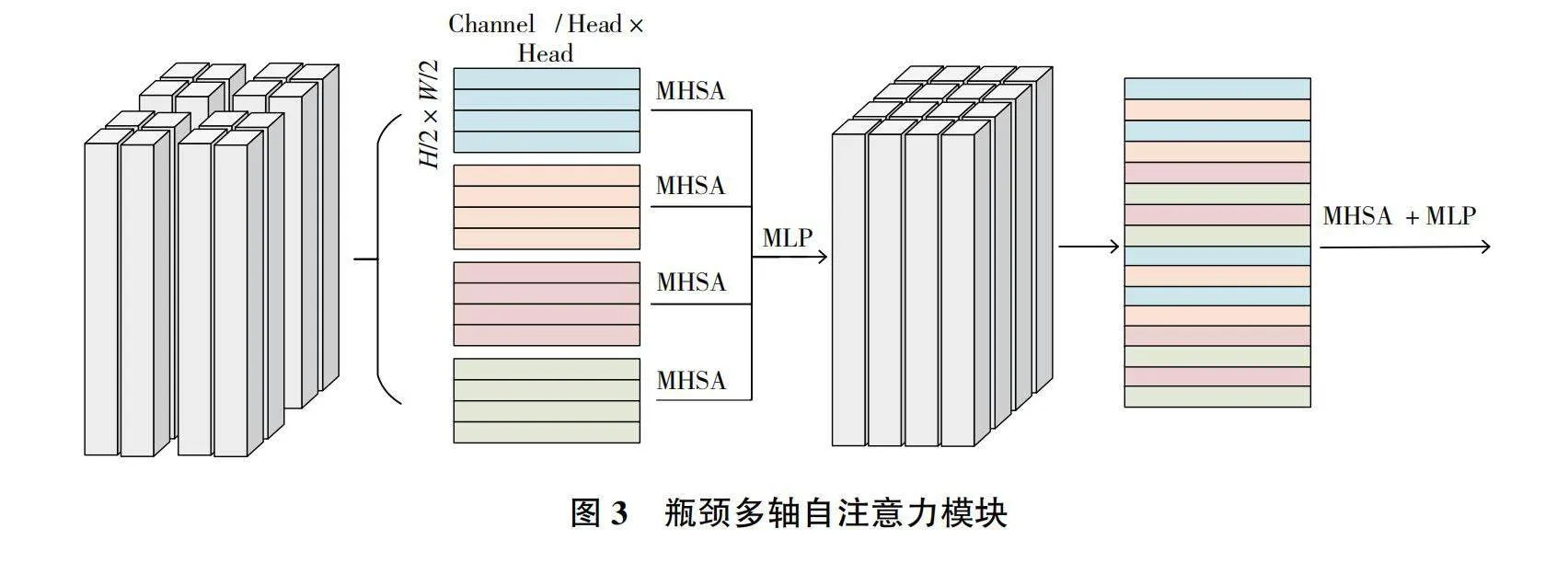
具體計算過程如圖3所示。BMSA的計算方式分為兩步,第一步將特征圖分成多個子塊(本文中默認是4塊),被分割的特征子圖分別通過多頭自注意力層,實現對特征圖中局部特征的交互。第二步將前面分割得到的多個特征子圖進行錯位拼接,再經過全局自注意力層得到結果。錯位拼接可以使BMSA模塊關注到更遠距離的交互信息,有利于模型捕捉更加多樣化的特征關系。
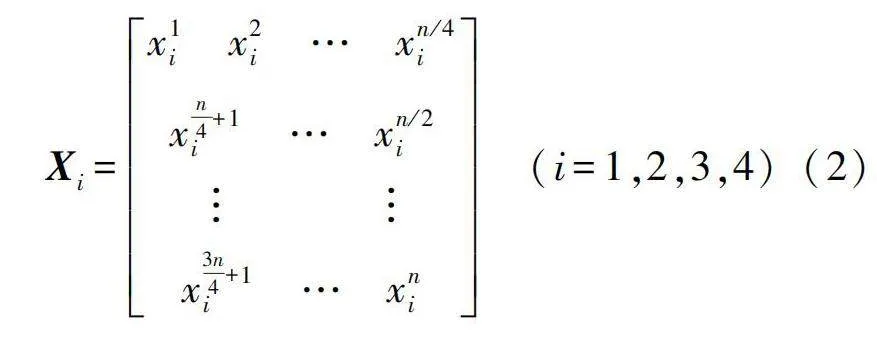
接下來是方法的數學描述。X是每個Bottleneck的輸入特征圖,X1、X2、X3、X4分別是第1、2、3、4塊特征子圖,而x1i,x2i,…,xni(i=1,2,3,4)則是每個特征子圖變換成向量后的組成元素,其中n為特征圖的元素個數。首先進行特征圖分割,將輸入特征圖分割成多個子圖(這里默認分為4塊):
X=(X1,X2,X3,X4)(1)
計算過程中,每個特征圖子圖可由式(2)表示。
分割后的特征圖進入多頭自注意力層(Multi-Head Self-Attention,MHSA),如式(3)所示。
經過局部自注意力模塊后,會再經過LayerNormalization(LN)層。LayerNormalization層的作用是防止多次的特征圖重塑操作。
特征圖X1、X2、X3、X4經錯位拼接得到和輸入特征圖同維度的X*,X*經過全局自注意力層,如式(4)所示。
經過全局自注意力部分的計算,同樣再經過一個LayerNormalization層,得到一個BMSA模塊的輸出結果Ooutput。式(4)中FMHSA的計算過程如式(5)所示。
式中Q、K、V均由[x1i,x2i,…,xni]得到。將自注意力建模過程抽象為Φ(X),局部自注意力過程如式(6)所示。
經過當前層BMSA的錯位拼接后,下一個BMSA模塊中的局部自注意力過程則可以表示為
Xri(i=1,2,3,4)表示經過變形重組得到的特征子圖,局部自注意力能捕捉特征圖上遠距離的特征交互信息,這是BMSA表現優于MHSA的主要原因。模型中的局部注意力模塊能夠增加無人機在飛行過程中識別細小的電線、樹枝等物體的準確率。
2 實驗
2.1 數據集
為了提高模型對無人機飛行障礙物識別的有效性,制作障礙物數據集。從各公開數據集中挑選飛行障礙物的圖片,主要有電線、樹木、飛行物(鳥類等)和大型障礙物(山體等)4個類別,每個類別大約1 500張訓練圖片和50張驗證圖片。為了驗證避障模型對多種物體的識別能力和泛化能力,還在CIFAR、FLOWER-102、Tiny-ImageNet和ImageNet上進行對比試驗。
2.2 訓練細節
對比實驗中模型使用weight decay為0.000 1,momentum為0.9的SGD優化器進行訓練。Batchsize設置為128,初始學習率固定為0.1,隨著實驗進行學習率逐漸衰退。在實驗的訓練過程中,對所有訓練數據運用隨機裁剪和隨機水平翻轉進行數據增強。
1)障礙物數據集實驗
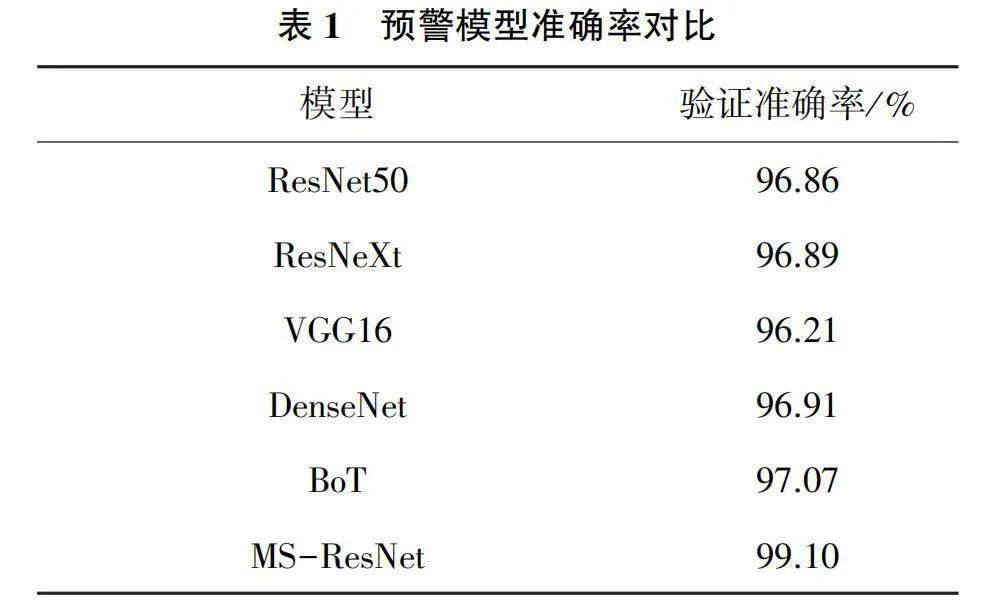
主流的圖像識別模型在障礙物數據集上進行對比實驗,實驗結果如表1所示,改進后的MS-ResNet實現99.10%的準確率,能夠準確地識別無人機在飛行過程中可能遇到的障礙物,從而對場景中的障礙物實時監測,對有危險的飛行路徑進行提前預警,并且MS-ResNet相比ResNet、VGG以及BoT等模型可實現更高的準確率。這表明采用MS-ResNet作為避障系統的圖像識別模型能達到最好的效果,能最準確地對無人機飛行路徑進行實時預警,以保障避障系統效果最大化。
隨機選擇無人機飛行過程中拍攝的圖片對預警模型進行測試,以驗證避障模型對實際障礙物的識別置信度。效果圖如圖4所示,圖4中(a)、(b)、(c)、(e)、(f)和(g)識別置信度都在90%以上,其中圖4(d)和圖4(h)對電線和樹木的識別置信度分別為73%和77%,能夠準確判斷出無人機在飛行過程中是否遇到障礙物,達到預警的目的。
2)公開數據集實驗
為了進一步驗證預警模型的效果,分別在不同分辨率的公開數據集上進行實驗。MS-ResNet、BoT、ResNet-50、ResNeXt-50[10]、ResNet101、VGG16和DenseNet在CIFAR[11]、FLOWER-102[12]、Tiny-ImageNet[13]和ImageNet數據集上進行訓練。為了適應小分辨率數據的尺寸,將網絡都進行相同的修改,將下采樣次數減少為3次。
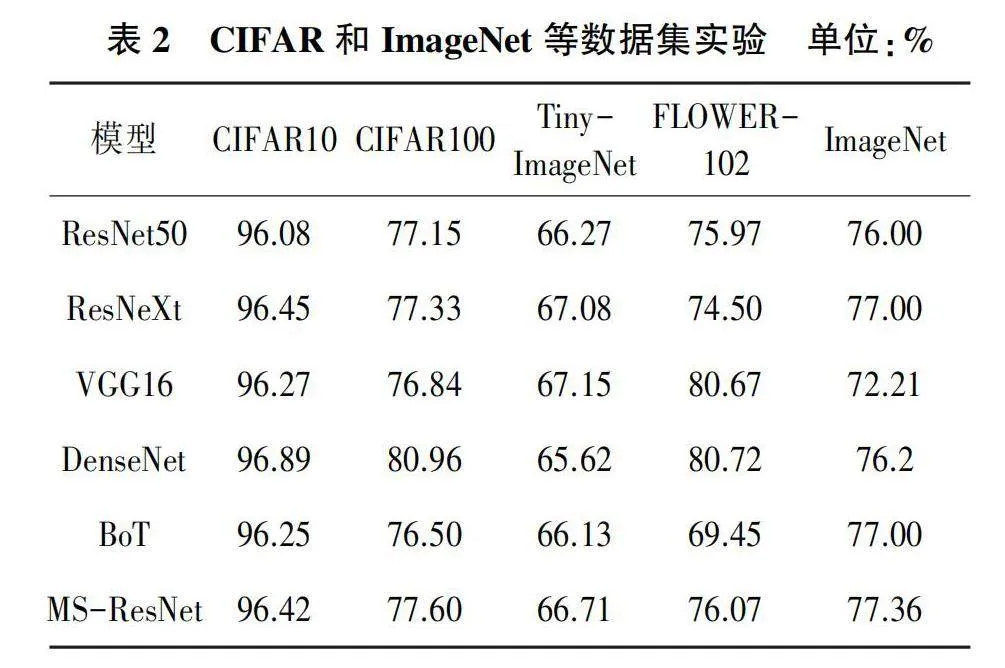
實驗結果如表2所示,無論是在CIFAR和Tiny-ImageNet等小分辨率數據集上,還是在FLOWER-102和ImageNet等大分辨率數據集上,MS-ResNet相比同類型的BoT實現更好地驗證準確率。MS-ResNet在CIFAR10、CIFAR100、Tiny-ImageNet和ImageNet上的準確率分別比BoT高0.17、1.1、0.58和0.36個百分點。在數據量較少的FLOWER-102上,MS-ResNet的準確率比BoT高5.62個百分點。
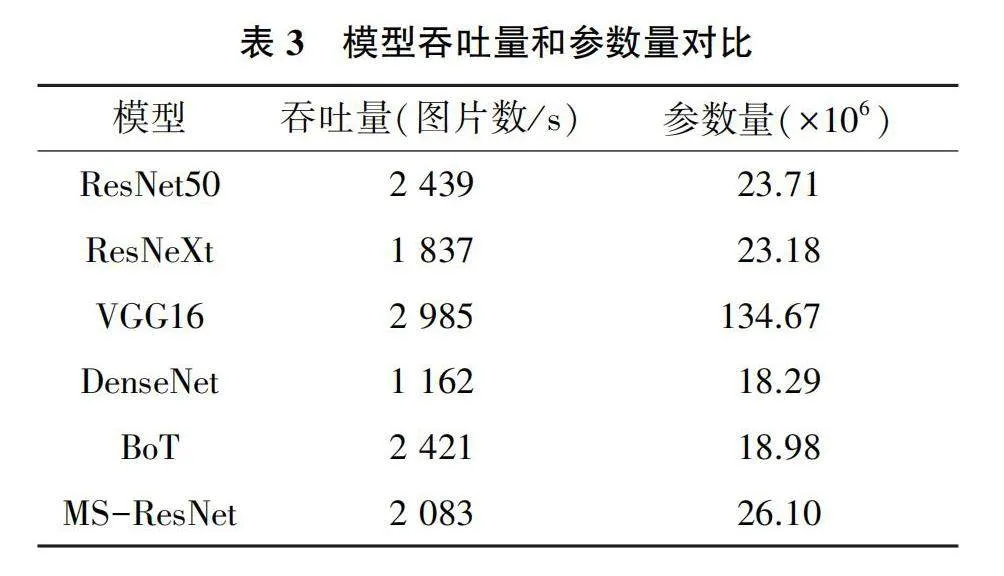
考慮到預警系統要求實時性,預警模型的計算效率和準確率同樣重要。為了對比模型的計算資源消耗,采集部分模型在CIFAR100數據集上的吞吐量(單張NVIDIA V100上每秒計算圖片數),同時得到模型的參數量對比。如表3所示,MS-ResNet的參數量要稍高于BoT和ResNet50,但是MS-ResNet在上述3個數據集上得到的驗證準確率都高于BoT和ResNet50。這表明MS-ResNet的泛化能力要優于BoT和ResNet50,并且MS-ResNet的吞吐量僅僅稍低于BoT和ResNet50。
表2和表3數據表明,DenseNet在上述3個數據集上的表現都稍優于MS-ResNet,但是DenseNet的吞吐量遠遠低于MS-ResNet。BMSA在提升模型準確率的同時,沒有大幅降低模型的計算效率,也能保證預警系統的實時性,可見BMSA嵌入卷積網絡的方案是可行的。
3 結語
本文論述了基于圖像識別模型對無人機的飛行路徑進行實時監測,以達到避障的目的。對ResNet和BoT進行改進,實驗表明改進圖像識別模型能夠對障礙物實現更準確的識別。將多軸自注意力模塊BMSA嵌入到原本模型中,引入局部自注意力單元和全局自注意力單元,解決了模型在識別細小物體方面表現不佳的問題,提升了系統的避障準確率。大量實驗結果表明,深度卷積網絡結合BMSA能在圖像識別任務中實現更高的驗證準確率,同時并沒有大幅降低模型的吞吐率。此外,BMSA相比于同類型的結構表現出了更好的泛化性能,在數據量較少的情況下,BMSA能幫助深度卷積網絡獲得巨大的準確率提升。
參考文獻:
[1] 張香竹,張立家,宋逸凡,等. 基于深度學習的無人機單目視覺避障算法[J]. 華南理工大學學報(自然科學版),2022,50(1): 101-108,131.
[2] 肖英楠,孫抒雨. 基于改進SIFT圖像匹配的無人機高精度避障算法設計[J]. 機械制造與自動化,2022,51(1): 237-240.
[3] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM,2017,60(6):84-90.
[4] RUSSAKOVSKY O,DENG J,SU H,et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision,2015,115(3):211-252.
[5] SZEGEDY C,LIU W,JIA Y Q,et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,MA,USA:IEEE,2015:1-9.
[6] HE K M,ZHANG X Y,REN S Q,et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). LasVegas,NV,USA:IEEE,2016:770-778.
[7] DOSOVITSKIY A,BEYER L,KOLESNIKOV A, et al. An image is worth 16x16 words:transformers for image recognition at scale[C]//International Conference on Learning Representations, Vienna, Austria:[s.n.] ,2021.
[8] SRINIVAS A,LIN T Y,PARMAR N,et al. Bottleneck transformers for visual recognition[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville,TN,USA:IEEE,2021:16514-16524.
[9] TU Z Z,TALEBI H,ZHANG H,et al. MaxViT:multi-axis vision transformer[M]//Lecture Notesin Computer Science. Cham:Springer Nature Switzerland,2022:459-479.
[10] XIE S N,GIRSHICK R,DOLLRP,et al. Aggregated residual transformations for deep neural networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu,HI,USA:IEEE,2017:5987-5995.
[11]KRIZHEVSKY A,HINTON G. Learning Multiple Layers of Features from Tiny Images[R].Technical Report TR-2009. Toronto: University of Toronto, 2009: 32-33.
[12] NILSBACK M E,ZISSERMAN A. Automated flower classification over a large number of classes[C]//2008 Sixth Indian Conference on Computer Vision,Graphics amp; Image Processing. Bhubaneswar,India:IEEE,2008:722-729.
[13] LE Y,YANG X S. Tiny imagenet visual recognition challenge[J]. Computer Science,2015,7(7): 3-6.
收稿日期:2023-02-01
猜你喜歡
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
人間(2016年26期)2016-11-03 17:52:40
中國科技博覽(2016年22期)2016-11-01 18:10:31
軟件工程(2016年8期)2016-10-25 15:47:34
科技視界(2016年22期)2016-10-18 14:30:27
企業導報(2016年9期)2016-05-26 20:58:26
