基于改進YOLOv5的兩階段抓取檢測算法
2024-10-25 00:00:00朱文磊董淑宏張洪于培師徐穩
機械制造與自動化 2024年5期



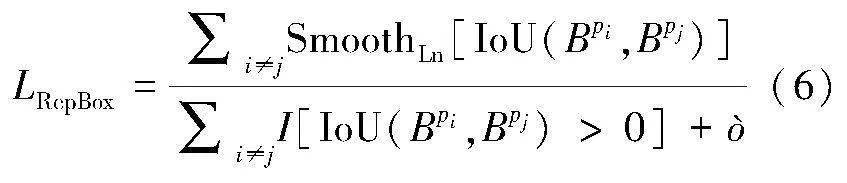



摘 要:針對復雜場景中機器人的無序抓取需要,提出一種兩階段的抓取檢測算法。改進YOLOv5的網絡模型,在多尺度特征融合上將淺層位置信息和深層語義信息進行注意力融合,提高多尺度目標的檢測能力;將排斥因子引入損失函數中,提高了模型在遮擋環境下的魯棒性;在目標檢測后對抓取目標邊界框進行裁切處理,避免了抓取檢測過程中其余目標的干擾;改進抓取檢測算法,引入CSP結構和注意力機制,提高了模型的特征提取能力。在真實環境下針對隨意擺放的多目標遮擋物體進行抓取實驗,結果表明:機器人抓取成功率為95%。
關鍵詞:調壓閥;目標檢測算法;輕量化;重參數化;特征融合
中圖分類號:TP391.41" 文獻標志碼:A" 文章編號:1671-5276(2024)05-0218-06
A Two-stage Grasp Detection Algorithm Based on Improved YOLOv5
Abstract:A two-stage grasp detection algorithm is proposed for the disorderly grasping needs of robots in complex scenes. The network model of YOLOv5 is improved by attention fusion of shallow location information and deep semantic information on multi-scale feature fusion to improve the detection of multi-scale targets. The rejection factor is introduced into the loss function to enhance the robustness of the model in occlusion environment. The grasp target bounding box is cropped after the target detection to avoid the interference from the rest of the targets during the grasp detection process. The grasp detection algorithm is improved by introducing the CSP structure and attention mechanism to improve the feature extraction ability of the model. In grasping multi-target obscured objects randomly placed in a real environment, the results show that the robot has a 95% success rate.
Keywords:pressure regulating valve;target detection algorithm;lightweight;re-parameterization;feature fusion
0 引言
伴隨著人工智能的快速崛起,智能制造業中機器人的應用深度和廣度得到了顯著提升。機械手抓取作為智能機器人最重要的技能之一,被廣泛應用在工業領域中替代人工進行工件抓取分類、產品包裝等工作[1]。目前,在復雜環境下的多目標抓取檢測仍具有較大挑戰,獲取更高精度的抓取姿態成為了抓取控制領域的研究熱點[2]。
近年來,基于深度學習的經驗法抓取取得了一定的研究成果。LENZ等[3]首次采用滑動窗口檢測框架搭建神經網絡,達到了73.9%的準確率,但是其模型計算量過大,無法進行實時檢測;REDMON等[4]舍棄滑動窗口的檢測方法,利用AlexNet網絡直接回歸獲得檢測結果,達到了88%的準確率,且可以實時運行;MORRISON等[5]借鑒語義分割的算法思想,提出了基于像素點檢測的輕量化抓取模型GGCNN,模型運行速度快,但準確率不高;KUMRA等[6]在其基礎上將殘差模塊添加到特征提取骨干網絡,以RGB-D融合圖像作為輸入,提高了模型的準確率;張志康等[7]提出了基于語義分割分階段特征融合的抓取檢測算法,具有較高的檢測精度,但網絡結構復雜;金歡[8]采用級聯式的網絡結構,將原始圖像先分割后檢測,實現了多目標抓取檢測。
綜上所述,已知的抓取檢測算法僅利用特征提取網絡中的最后一層輸出特征圖進行特征預測,對于尺寸多變、形狀不同、姿態未知的目標,往往傾向于生成大目標的抓取框,而對小目標的檢測性能較差,同時大部分的抓取模型為單目標場景抓取,沒有考慮實際工業環境中背景復雜、目標間存在相互遮擋等問題。針對以上問題,本文提出了一種兩階段的抓取檢測算法。
1 兩階段抓取檢測算法
為了滿足抓取檢測中無序抓取的任務需求,除了生成最優的抓取檢測框外,還需要識別出目標種類,本文通過設計并聯式的兩階段抓取檢測算法,實現在復雜環境中雜亂物體的抓取。整個抓取檢測流程如圖1所示。
2 目標檢測網絡
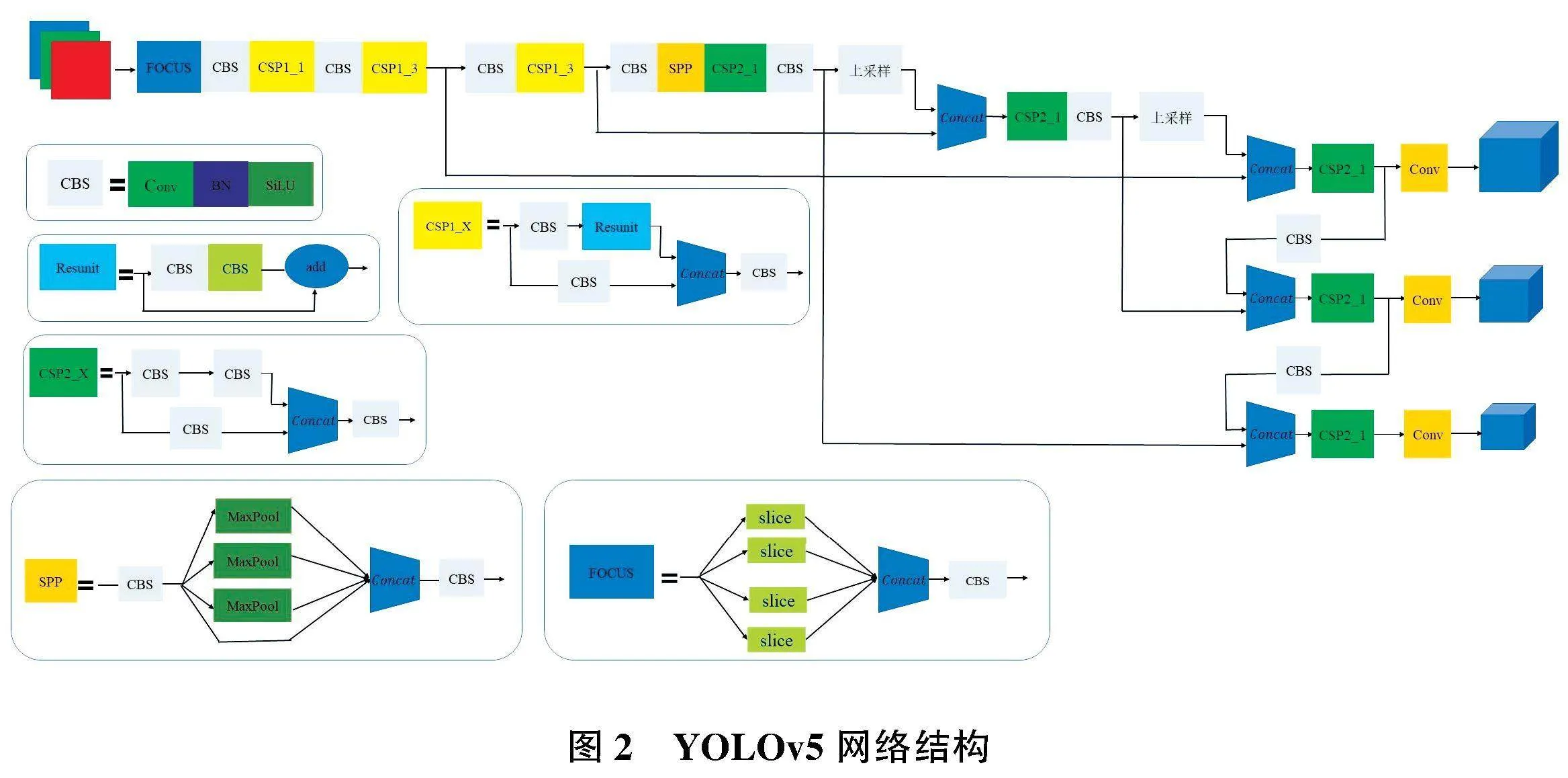
YOLOv5在目標檢測領域具有了較好的檢測精度和檢測效率,其網絡框架如圖2所示。但是在實際應用環境中,機器人檢測的目標多樣復雜、抓取環境雜亂、物體密集堆疊。針對以上問題,本文在數據預處理、網絡結構以及損失函數部分做出改進。
2.1 數據預處理
在訓練的過程中,通過模擬物體遮擋,可以提高模型被遮擋時的抗干擾性,同時對于整體數據集而言是一種正則化處理方式,避免了網絡過擬合,對模型的學習能力有所提升。
本文采用多種數據增強方法來模擬物體遮擋的效果,具體效果如圖3所示。Cutout和Random erasing均通過在圖像中隨機裁切一個矩形區域,前者直接在此區域內填充0,后者賦值隨機像素值;Hide-and-Seek 為解決弱監督問題中目標定位的精度問題,采用隨機裁切若干個區域,從而讓模型學習物體的全局信息;GridMask在 HaS的基礎上采用了等間隔裁切區域的方式,并且對該區域實現一定的旋轉。
2.2 網絡結構優化
在卷積神經網絡中,通過上下采樣可以獲得不同尺寸的特征圖。低緯特征圖能夠包含目標物體的空間特征信息,有利于確定目標的空間位置,而高緯特征圖包含更豐富的語義特征信息,具有圖像的概括能力,有利于分類任務的完成。
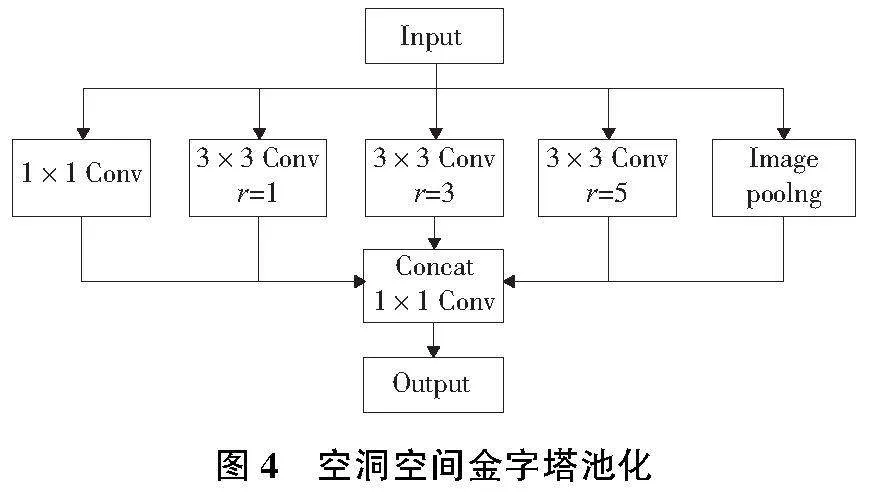
原有的YOLOv5采用SPP(空間金字塔池化)來獲取不同感受野的大小,采用統一步長,不同大小卷積核對輸入特征圖進行卷積操作,沒有綜合局部信息與全面信息的語義關系。本文結合深度可分離卷積實現ASPP(空洞空間金字塔池化),降低參數計算量,無需通過減小圖片和多個卷積核串聯來增加感受野。如圖4所示, 第1個分支采用1×1卷積,保留輸入特征的感受野;中間3個分支分別采用擴張系數為1、3、5的空洞卷積,獲得不同大小的感受野;第5個分支采用全局池化得到全局感受野;最后將各個特征輸出Concat拼接后經過一個1×1卷積,實現多尺度特征提取。經過ASPP后的多尺度特征信息包含了大量的冗余信息,可通過添加注意力機制提高其特征提取效率。
YOLOv5原有的FPN+PAN在多尺度特征融合上對不同的輸入特征圖采用了平等的處理方式,而不同尺寸的特征圖擁有不同的信息密度,在特征融合過程中所提供的有效特征是不相等的。為了提高多尺度融合中特征復用效率,本文采用BiFPN[9](加權雙向特征金字塔網絡),在不同尺度的特征通道上引入了可學習的權重,重復利用自頂向下和自下而上的多尺度特征融合,充分利用不同分辨率中的特征信息。
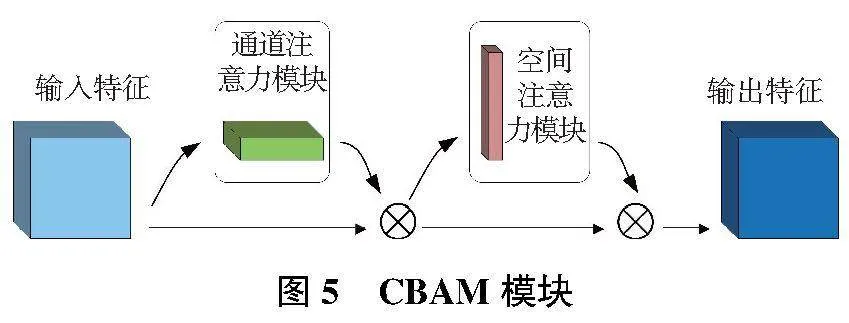
CBAM[10]作為混合注意力機制,包含兩個獨立的子模塊:通道注意力模塊(channel attention module,CAM)和空間注意力模塊(spatial attention module,SAM),分別將注意力映射到特征圖的通道和空間兩個維度,實現自適應特征提取,其網絡結構如圖5所示。
本文將CBAM嵌入到ASPP和CSP模塊后, 在特征融合之前,對特征圖進行加權處理,提升關鍵特征,并抑制無關特征,使得網絡能將重要信息加以融合。這樣不僅使融合后的特征圖包含更有效的目標信息,提升遮擋目標的定位精度,還達到降低模型的計算量,提升檢測速度的目的。
2.3 損失函數改進
為了提高模型的遮擋檢測性能,本文在CIoU的基礎上引入新的損失函數Repulsion loss[11],通過調整目標預測框與真實框、重疊目標預測框和真實框之間的關系,盡可能讓預測框靠近真實框,遠離其他目標框,降低NMS對閾值的敏感度。Repulsion loss損失函數如下所示。
L=LAttr+α×LRepGT+β×LRepBox(1)
式中:LAttr表示目標預測框與真實框之間的損失,本文采用CIoU替換原有的SmoothL1損失;LRepGT表示目標預測框與周圍其他目標真實框之間的損失;LRepBox表示目標預測框與周圍其他目標預測框之間的距離;α、β為權重調節系數。
LRepGT是所有正樣本預測框與其最大CIoU值的真實框的IoG均值,公式如下所示。
式中:G表示真實框;g為所有真實框的集合;P表示預測框;p為IoU大于閾值的正樣本預測框的集合;BP是根據預測框P調整后獲得;GPRep是目標預測框p除與之匹配的最大CIoU值的真實框;GPAttr是與目標預測框p相對應具有最大CIoU值的真實框。
LRepBox作為相鄰但不同目標預測框之間的排斥項,使得預測框和周圍的其他預測框盡可能遠離,公式如下所示。
3 抓取檢測網絡
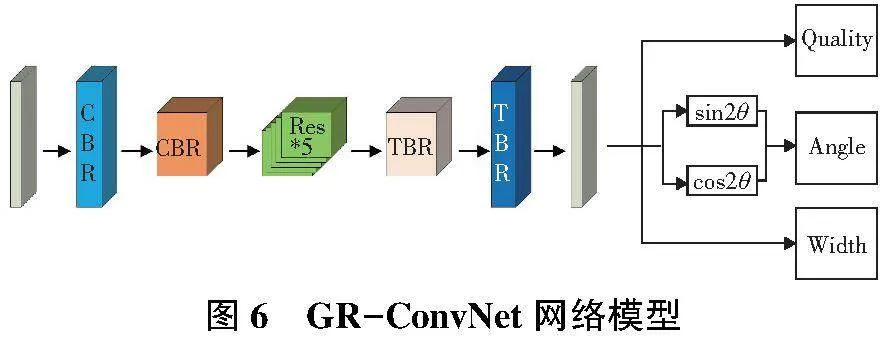
GR-ConvNet是基于抓取點的抓取位姿檢測算法模型。通過RGB-D的像素點信息預測出抓取目標的最佳抓取姿態以及每一個抓取點的質量分數,其網絡模型如圖6所示。
該算法主要應用于單目標的抓取位姿檢測,無法對目標對象進行分類處理,抓取受到環境干擾大,同時在多尺度檢測上容易忽視小目標的抓取。針對以上問題,本文在數據預處理和網絡結構部分做出改進。
3.1 數據預處理
在多目標復雜場景以及目標之間存在堆疊時,輸入圖片中的背景和其他物體所包含的像素信息對GR-ConvNet算法具有一定的干擾性,主要是由于檢測過程中只生成一個最佳的抓取框,抓取框選取的是全局圖像中抓取置信度最高的點,而部分噪聲點會干擾抓取框的選取,導致誤檢現象的發生。本文采用目標檢測算法對抓取檢測輸入的圖像進行預處理,只保留目標物體的邊界框,將其余部分填充0。
3.2 模型結構優化
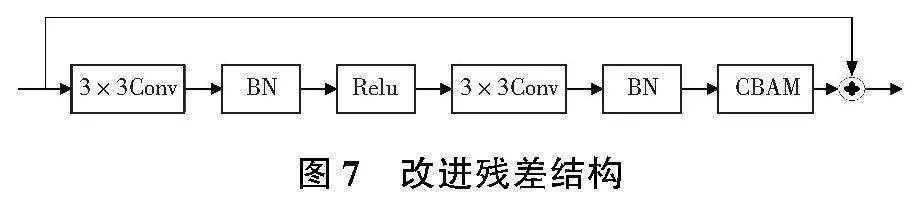
針對原有模型中的殘差模塊,本文引進注意力機制CBAM,如圖7所示,嵌入在殘差模塊中的BN層后,提高模型的特征提取能力。同時借鑒CSP模塊對其進行優化,通過采用CSP模塊將輸入特征分為兩個分支使得通道數減半,其中一部分通過5個改進的殘差模塊后與另一部分進行通道相加,減少了計算量;在梯度反向傳播過程中,同一個梯度在不同的模塊中被反復計算,會導致大量的梯度冗余,通過對特征通道的裁剪,使得梯度在不同的分支中獨自進行梯度回傳,沒有重復計算,有效地降低了梯度冗余,提高了模型的運行速度。
4 實驗及結果分析
4.1 目標檢測
本實驗采用自制工件數據集進行模型訓練,如圖8所示,對自動化裝備生產中所需的氣動工件采用Kinect V2深度相機采集。一共選取4種工件,采集了1 200張圖像,以VOC格式對其進行標注,按照8∶1∶1的比例劃分為訓練集、驗證集和測試集。
為充分驗證模型改進的有效性,設置消融實驗和對比實驗探究不同改進策略對檢測算法的性能影響。本文采用mAP(均值平均精度)和FPS(幀率)作為評價指標,表示檢測算法對目標的平均檢測精度和速度。
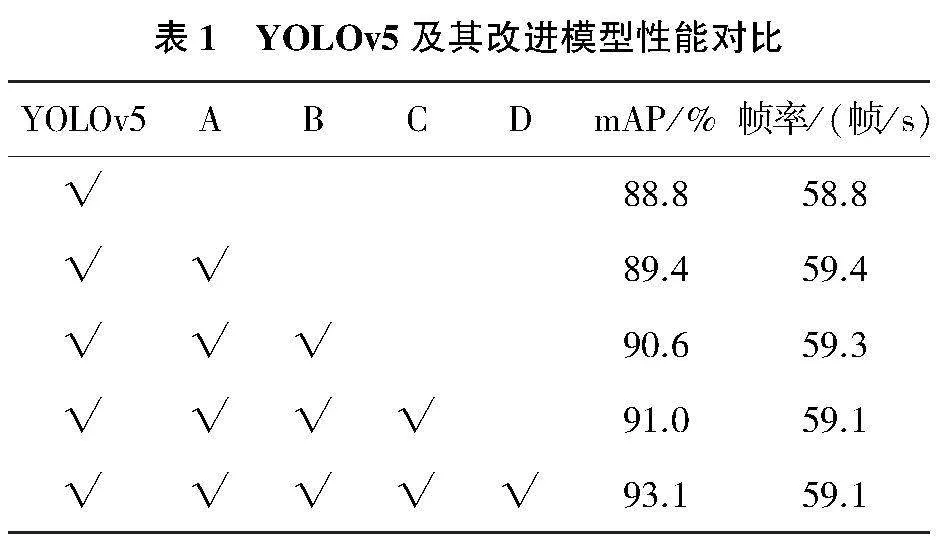
消融實驗如表1所示,A表示替換ASPP模塊后模型在不增加計算量的前提下,擴大了感受野,增強了模型識別不同尺寸目標的能力,檢測速度和檢測精度均有所提升;B表示增加注意力機制CBAM,加強了目標對象的關注度,有效降低了背景的干擾,增強了模型的魯棒性,提高了模型的檢測精度;C表示在特征融合階段采用了BiFPN,在不同深度的特征圖中采用不同的權重進行特征裁切,檢測速度有小幅度降低但精度有所提升;D表示在損失函數中引入排斥因子,使得模型在復雜環境中對遮擋物體的檢測能力和精度得到了提升。相比原有模型,改進后的YOLOV5檢測算法mAP提高了4.3個百分點,而檢測速度基本沒有受到影響。
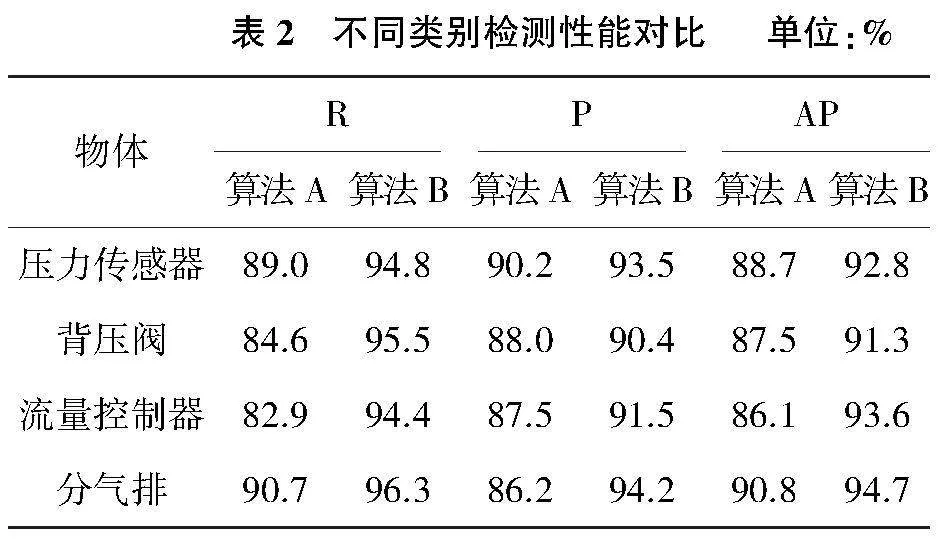
為探究改進算法在各類別檢測上的影響,本文將原算法A與改進算法B進行類別性能測試實驗,如表2所示。
由表2可知,改進模型在準確率、召回率和平均精度上均有所提升。在多目標遮擋環境下,流量控制器的模型較小,且表面特征不明顯,部分特征與壓力傳感器相似,當遮擋情況嚴重時便會導致誤檢或漏檢,而改進后的模型顯著提高了對流量控制器的特征提取能力以及遮擋情況下的召回率。
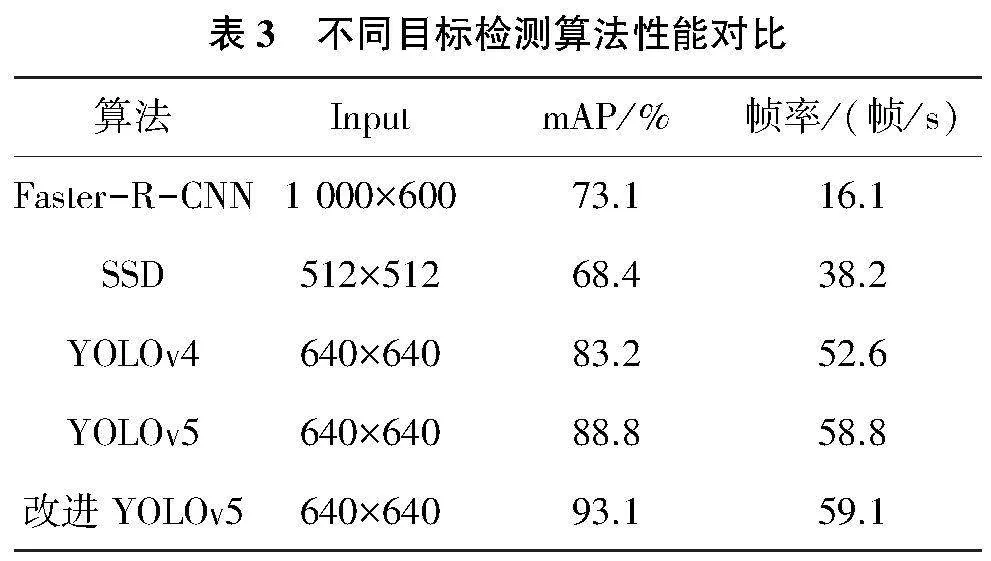
將改進后的YOLOv5算法與目前主流的目標檢測算法進行性能對比(表3),檢測速度和檢測精度均有了提升。在背景環境復雜、檢測目標存在遮擋的情況下依然可以識別出目標并精準定位,減少了漏檢、誤檢的概率。
4.2 抓取位姿檢測
由于cornell數據集全部為單目標場景,缺少多目標堆疊場景下的數據集,本文選用cornell數據集和自制單目標工件數據集作為訓練集和驗證集,自制多目標工件數據集作為測試集,驗證不同遮擋程度下抓取檢測算法的性能。
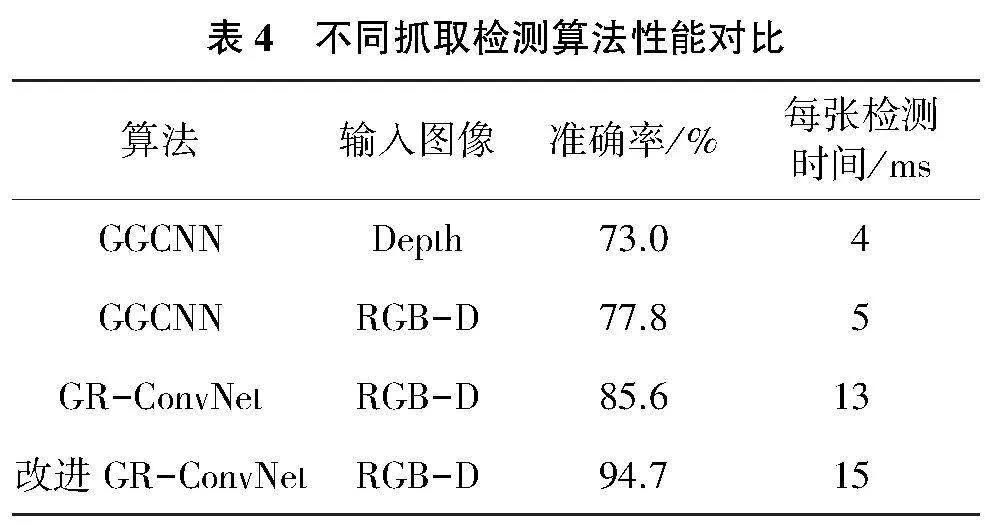
測試數據集首先通過目標檢測算法進行圖像預處理,裁切出抓取目標區域并將其余背景部分進行填0處理,再輸入到抓取位姿檢測模型中。不同的檢測算法實驗結果如表4所示。
由表4可知,在抓取位姿檢測模型中,采用輕量化設計的GGCNN在檢測速度上優勢較大,但是檢測準確率較低,通過將彩色圖像和深度圖像融合進行多模態輸入,模型的檢測精度有所提升;本文改進的GR-ConvNet采用RGB-D圖像作為輸入,引入CSP模塊和CBAM注意力機制對殘差結構進行優化,減少了梯度冗余,提高了模型的特征提取能力,解決了模型推理速度和檢測精度不平衡的問題,在增加少量推理時間前提下獲取了較高的準確率,相比原有模型提高了9.1個百分點。
4.3 真實機械臂抓取實驗
本文采用UR5機械臂、Robotiq機械夾爪和Kinect V2深度相機搭建抓取實驗平臺,采用眼在手外的方式固定相機,如圖9所示。
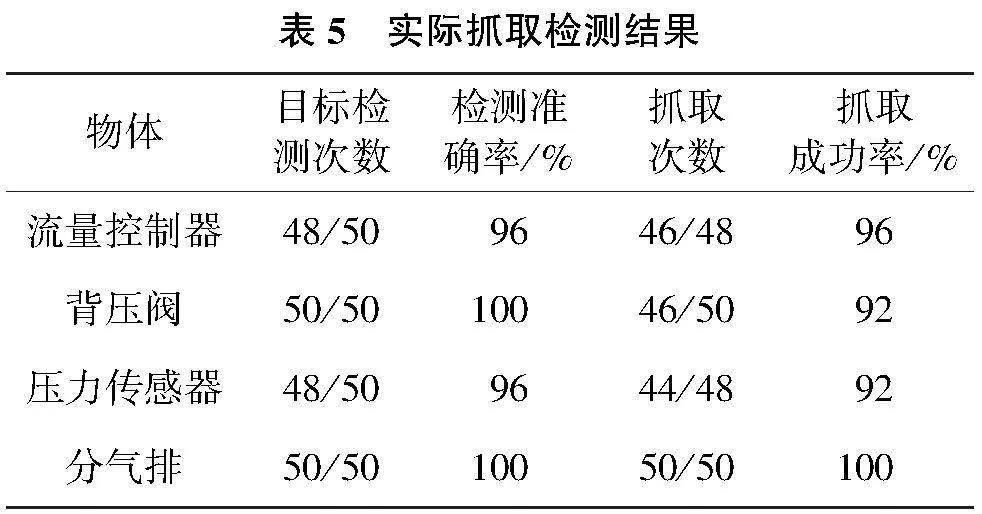
實驗采用多目標場景,在平臺上隨機擺放工件,部分工件之間存在遮擋現象,重復實驗50次,以實際抓取的成功率作為評價指標。抓取效果如表5所示。
由表5可知,本文提出的雙階段抓取檢測算法在遮擋條件下具有較高的抓取成功率,通過目標檢測算法獲取遮擋目標的局部信息,提高了模型的抗干擾性,但依然存在檢測失敗和抓取失敗的案例。高度遮擋環境下,目標間重疊面積過高,導致檢測對象的特征不明顯,對后續的抓取檢測也有著較大的挑戰。分氣排模型較大且形狀簡單,在抓取過程中具有最佳的抓取表現;壓力傳感器由于其表面存在金屬光澤,在圖像中有效像素較少,抓取成功率相比其他種類較低;背壓閥的最佳抓取位姿較少且表面光滑,使用二指夾爪在抓取過程中容易脫落導致抓取失敗。
5 結語
為實現工業環境中工件無序分揀,針對環境中背景復雜和目標間存在堆疊,難以實現高效分類抓取的問題,提出了一種兩階段抓取檢測算法對工件進行抓取位姿估計。在第一階段采用了目標檢測算法,通過修改網絡結構和損失函數,增強了對遮擋目標的檢測能力,在多目標密集遮擋環境下獲得了良好的性能,降低了模型漏檢、誤檢的概率。第二階段中,算法利用第一階段生成的目標檢測結果,對最佳抓取范圍進行裁切,抑制甚至消除了環境背景對檢測的干擾,再對目標物體進行細粒度的姿態估計和抓取框生成,實現了最佳的抓取效果。該算法在實際的機器人抓取場景中得到了廣泛應用和驗證,具有較強的通用性和魯棒性,能夠適應各種不同形態和大小的物體,并實現高效、精確的抓取操作。今后將進一步研究多個目標之間的順序抓取問題以及被遮擋物體的信息補全,進一步提升抓取成功率。
參考文獻:
[1] 陳苗苗,葉文華,馬庭田,等. 不規則金屬物料的抓取位姿實時檢測方法研究[J]. 機械制造與自動化,2022,51(1):177-180,191.
[2] DU GG,WANG K,LIAN S G,et al. Vision-based robotic grasping from object localization,object pose estimation to grasp estimation for parallel grippers:a review[J]. Artificial Intelligence Review,2021,54(3):1677-1734.
[3] LENZ I,LEE H,SAXENA A. Deep learning for detecting robotic grasps[J]. The International Journal of Robotics Research,2015,34(4/5):705-724.
[4] REDMON J,ANGELOVA A. Real-time grasp detection using convolutional neural networks[C]//2015 IEEE International Conference on Robotics and Automation. Seattle,WA,USA: IEEE,2015:1316-1322.
[5] MORRISON D,CORKE P,LEITNER J. Learning robust,real-time,reactive robotic grasping[J]. The International Journal of Robotics Research,2020,39(2/3):183-201.
[6] KUMRA S,JOSHI S,SAHIN F. Antipodal robotic grasping using generative residual convolutional neural network[C]//2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Las Vegas,NV,USA: IEEE,2021:9626-9633.
[7] 張志康,魏赟. 基于語義分割的兩階段抓取檢測算法[J/OL]. 計算機集成制造系統.(2022-05-11)[2022-12-11]. http:/lkns.cnki.net/kcms/detail/11.5946.TP.20220517.1009.008.html.
[8] 金歡. 基于卷積神經網絡的機器人抓取檢測研究[D]. 哈爾濱:哈爾濱工業大學,2019.
[9] TAN MX,PANG R M,LE Q V. EfficientDet:scalable and efficient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,WA,USA: IEEE,2020:10778-10787.
[10] WOO S,PARK J,LEE J Y,et al. CBAM:convolutional block attention module[M]//Computer Vision - ECCV 2018. Cham:Springer International Publishing,2018:3-19.
[11] WANG X L,XIAO T T,JIANG Y N,et al. Repulsion loss:detecting pedestrians in a crowd[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA: IEEE,2018:7774-7783.
