基于改進卷積網絡的鑄件視覺檢測
2024-10-25 00:00:00顏夢玫楊冬平
機械制造與自動化 2024年5期
關鍵詞:深度學習



摘 要:為實現對鑄件各種不同缺陷的自動診斷,設計一種視覺檢測系統對鑄造產品進行外觀檢測。利用多頭自注意力模塊對圖像識別網絡的下采樣過程進行增強,使得經典圖像分類網絡能夠獲得全局特征信息,以提升模型對鑄件體外觀上細小裂紋和大范圍毛刺的識別能力。實驗結果表明:改進得到的卷積網絡對鑄件缺陷具有較高的識別準確率,能夠較準確地判斷鑄件缺陷類型。
關鍵詞:缺陷檢測;圖像識別;卷積神經網絡;深度學習;自注意力機制
中圖分類號:TP391.4" 文獻標志碼:A" 文章編號:1671-5276(2024)05-0229-05
Casting Visual Detection Based on improved Convolutional Network
Abstract:For automatical diagnosing different defects in castings, a visual inspection system is designed to inspect the appearance of casting products. The multi-head self-attention module is used to enhance the downsampling process of the image recognition network, enabling the classic image classification network to obtain global feature information and promote the model's ability to identify small cracks and large-scale burrs on the appearance of castings. The experimental results show that the improved convolutional network has a higher recognition accuracy for casting defects, and can more accurately determine the type of casting defects.
Keywords:defect detection;image recognition;convolutional neural network;deep learning;self-attention mechanism
0 引言
鑄件是用各種鑄造方法獲得的金屬或者合金材料成型零件,常用作機械、建筑、航空航天和汽車等領域的主要零部件。由于鑄件的特殊成型方式,在制造過程中常出現氣孔、裂紋和夾渣等質量問題。這些問題不僅影響機械零件的性能,還可能導致它的使用壽命大大縮短。為及時發現鑄件的缺陷,基于X射線的無損檢測[1]廣泛應用于鑄件檢測中,能夠準確診斷鑄件內部缺陷。但是由于X射線的無損檢測效率較低、成本較高,通常會采用外觀檢查等人工方式進行初步篩選。為了高效、準確地篩選出有缺陷的鑄件,可通過圖像分類網絡對所有鑄件進行分類,實現對氣孔、細小裂紋和毛刺等缺陷的初步篩選。相比人工外觀檢查等低效的篩選方式,圖像檢測系統[2]能夠更加高效、準確地檢測鑄件的外觀缺陷。
隨著計算機視覺技術和深度學習方法的快速發展,通過圖像數據對物體進行準確分類已成為可能。2012年ILSVRC圖像分類大賽中,深度卷積結構實現的AlexNet[3]一舉奪冠,2014年GoogLeNet[4]實現了74.8%的top-1準確率,并且VGGNet[5]也實現了相同的精度。此外,ResNet[6]提出的殘差連接使得訓練這些極深的網絡更加容易,表現也更好。
近幾年來,研究者們利用不同的改進方法來提升圖像分類網絡的準確率。Transformer[7]是一種與卷積結構不同的模型,最開始用于解決自然語言處理(NLP)任務,因其表現出的卓越性能而迅速成為主流架構。ViT[8]是視覺任務中應用Transformer結構的先驅,它通過直接堆疊的方式,在不重疊圖像塊上運行Transformer塊來實現圖像識別的卓越性能。BoTNet[9]則將Transformer引入卷積結構中,提出帶有MHSA層的ResNet瓶頸結構的Transformer塊。Conformer[10]是CNN和Transformer并行的混合網絡,通過特征耦合模塊對每個階段的局部特征和全局特征之間進行信息交互,使得Conformer同時兼具兩者的優勢。在分類任務中,Conformer以更小的參數取得更高的準確率。
基于此,本文對Conformer結構中的Transformer分支進行簡化和改進,提出增強型Transformer(enhance transformer, ET)架構,并將其插入到ResNet和其他深度卷積網絡中,實現對網絡性能的增強以及網絡準確率的提升。
本文主要工作有:
1)使用深度卷積網絡對鑄件的外觀缺陷進行識別,搜集鑄件圖像數據集,對孔狀缺陷、毛刺和細小裂紋等圖像進行分類處理;細化缺陷數據類別,使得缺陷診斷網絡能夠更加準確地判斷缺陷種類,以便后期對鑄造方法進行分析和改進;
2)為提升深度卷積網絡對細小裂紋的識別準確率,將Conformer中的方法加以簡化和改進,提出增強Transformer結構,將該結構插入ResNet的下采樣模塊中能夠顯著提升準確率;并對此方法進行對比試驗,以找到最佳融合方式。
1 缺陷診斷模型
視覺診斷系統能夠自動地對鑄件進行外觀缺陷檢測,檢測的精度由圖像分類網絡的準確率決定。通過比對大量缺陷圖片發現,鑄件毛刺特征和細小裂紋表現出的尺寸相差較大,這要求圖像分類網絡能夠捕捉到圖像中的全局特征和局部特征。因此,將能夠捕捉全局特征的Transformer結構對深度卷積結構進行增強,使得網絡模型的局部特征和全局特征都能進行信息交互。
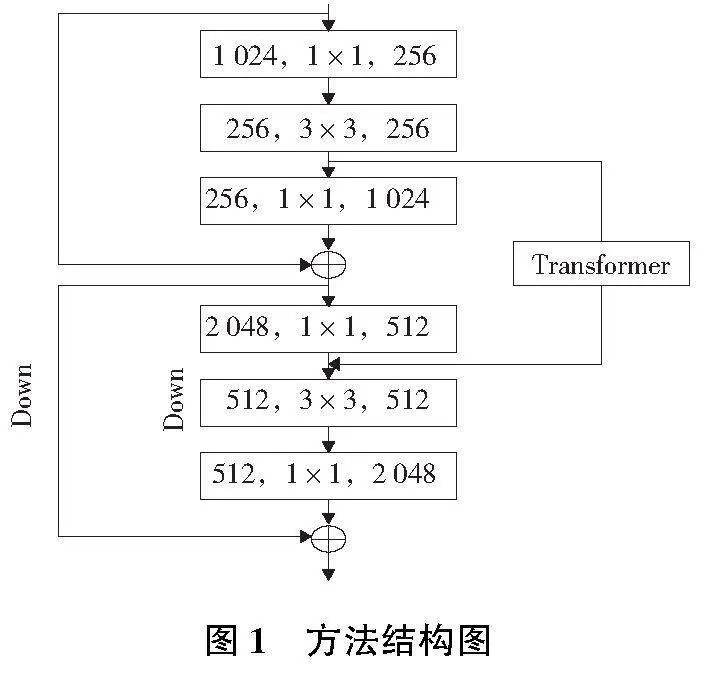
如圖1所示,在一般的深度卷積結構中插入一個Transformer模塊,與卷積計算分支組成并行的結構,使得網絡模型能夠利用卷積實現局部特征交互,也能通過Transformer進行全局特征信息交互。實驗結果表明: 增強Transformer放在下采樣層的前面會獲得更好的表現。因為這種方法還能增強特征信息,使得網絡在下采樣過程中保留更多的特征信息。
詳細計算過程如圖2所示。在第3個Stage和第4個Stage中間加上一個Transformer模塊。從第4個Stage開始,進行特征圖下采樣,Transformer模塊通過捕捉全局特征后合并信息流實現對特征信息進行增強。
將第3個Stage最后一個3×3卷積的輸出特征圖分別經過主干卷積層和增強Transformer結構。該特征圖X首先經過一個1×1卷積層,再進行重組,變成一個B×C×H×W尺寸的特征圖X。特征圖X依次經過多頭自注意力層(multi head self-attention, MHSA)、layer normalization(LN)層和多層感知機(multi layer perceptron, MLP),計算過程如式(1)所示。
XT=MLP(LN(MHSA(X)))(1)
多頭自注意力層中的特征圖X分別生成query、key和value,再經過計算得到同維度的輸出結果,計算過程如式(2)所示。這個過程中,特征圖上的全局特征會進行信息交互,并對感興趣的特征進行加權,從而捕捉到特征圖上的全局關鍵信息。
Attention(Q,K,V)=softmax(QKT)V(2)
特征圖XT重新變形重組為B×C×H×W的特征圖,再經過一個3×3卷積層后和主干特征圖相加。這個卷積層的作用是將特征圖XT的維度變為和主干特征圖的維度一致。整個計算過程可以由式(3)表示,其中C(·)表示卷積操作,Xl和Xl-1分別表示當前卷積層的輸出特征圖和前一個卷積層的輸出特征圖,Y表示雙分支的合并結果。
Y=XT+C1×1(Xl+C1×1(Xl-1))(3)
通過這種雙分支的方式,網絡模型在第4個Stage能夠感受到圖片上的局部特征和全局特征,因此對大范圍的毛刺和小尺寸的裂紋都能有較好的識別效果。并且,增強Transformer結構只在低分辨率階段與卷積進行融合,不會導致計算速度大幅下降。實驗結果表明:增強Transformer帶來準確率提升的同時,并沒有大幅度降低吞吐率,這種方法可以為圖像缺陷診斷系統帶來更好的檢測性能。
2 實驗
2.1 實驗設置
實驗中每個網絡均使用SGD優化器進行訓練,優化器的weight decay和momentum分別設置為0.000 1和0.9。在訓練過程中,Batchsize設置為128,初始學習率固定為0.1,隨著實驗進行,學習率逐漸衰退。
在各種網絡的訓練過程中,對所有訓練圖像運用相同的數據增強方法。這里用到的數據增強方法為隨機裁剪和隨機水平翻轉。所有實驗代碼基于pytorch框架實現,訓練和測試過程在多張NVIDIA GeForce RTX 3090上采用并行計算完成。
2.2 對比實驗
1)診斷模型對比實驗
為了讓診斷模型能夠準確判斷出鑄件缺陷的類型,以便后期能針對性地加以改進,需制作包含不同類型缺陷的訓練數據集。從各相關數據集中挑選各種不良鑄造軸承圖片,將其鑄造缺陷類別主要分為孔狀缺陷、毛刺和細微劃痕等3類,加上正常鑄件類別組成一共4個類別的數據集。其中,每個類別的訓練圖片為190張,驗證圖片都是10張,另外準備少量跨域場景圖片對診斷模型進行泛化能力測試。
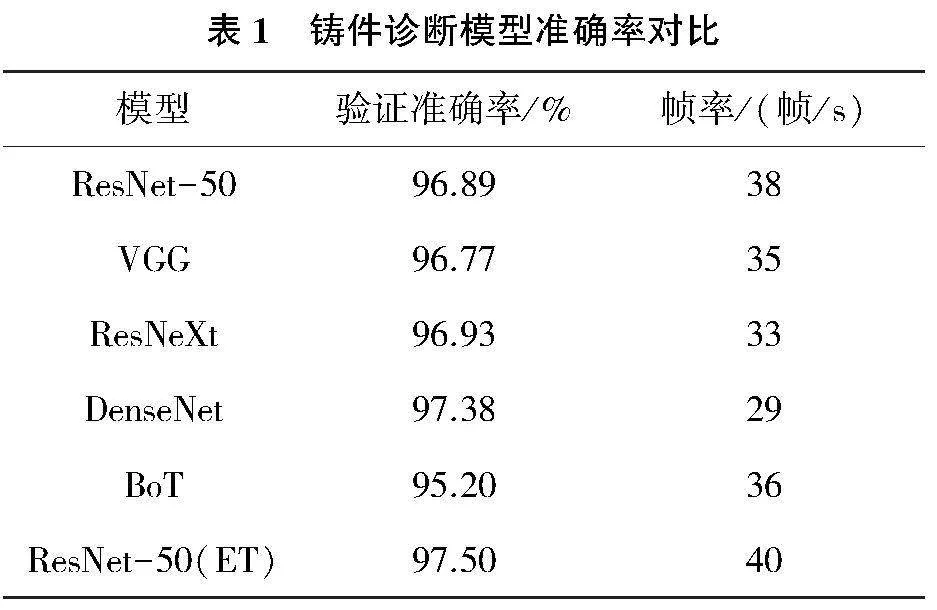
采用2.1節中的實驗參數設置,將ResNet、VGG、ResNeXt[11]、DenseNet[12]等主流分類網絡和這里的ResNet(ET)在鑄件診斷訓練數據集上進行訓練和驗證,其中BoT為CNN和Transformer結合網絡,主要特點為精度和計算速度表現都較好,實驗結果如表1所示。相比ResNet和VGG等分類網絡,具有ET結構的ResNet網絡實現了更高的準確率和更快的計算速度,表明ET結構可以作為缺陷檢測系統的增強方法,能使模型準確、快速地對鑄件缺陷類型進行分類判斷。
此外,為了驗證本文方法對細小劃痕缺陷識別的增強效果,隨機選擇包含細小劃痕的鑄件圖片進行驗證和分析。將缺陷鑄件圖片輸入改進診斷模型計算,并得到計算時的熱力圖,如圖3所示。圖3(a)為原圖,圖3(b)是網絡發現毛刺和細小氣孔缺陷區域的熱力圖,這正說明它依賴于這些特征進行缺陷分類。
2)公開數據集對比實驗
為進一步驗證改進方法對分類網絡的有效性,讓ResNet、VGG、ResNeXt、DenseNet等分類網絡和ResNet(ET)分別在公開分類數據集上進行對比實驗。實驗數據集主要包括:CIFAR[13]和Tiny-ImageNet。訓練參數與2.1節中的一致,為了讓分類網絡適應小分辨率數據的尺寸,將深度卷積模型都進行相同的修改,將下采樣次數由原本的5次減少為3次。
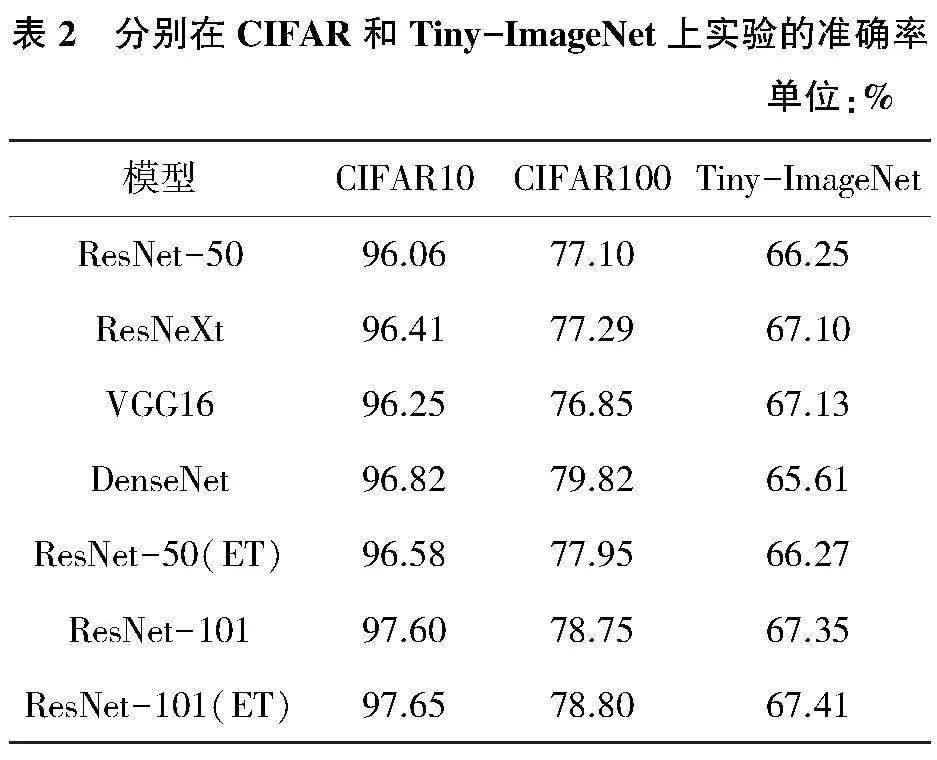
實驗結果如表2所示,提出的ResNet-50(ET)在CIFAR10、CIFAR100和Tiny-ImageNet上分別比ResNet-50高0.52個百分點、0.85個百分點和0.02個百分點。并且在一系列公開數據集中,ResNet-101(ET)也比ResNet-101表現出更高的準確率。此外,DenseNet在CIFAR10和CIFAR100兩個數據集上的表現都稍優于ResNet(ET),但是在Tiny-ImageNet數據集上的準確率表現較差,并且從表1可以看出它的計算速度較慢。
改進方法能夠提升分類網絡的準確率,但是也會引入更多參數量和計算量,因此只在第4個Stage使用改進方法。為了對比改進方法在網絡不同層插入帶來的改變,將改進方法分別插入ResNet-50第4個Stage的第1、第2、第3個Bottleneck中,并在CIFAR100和Tiny-ImageNet上訓練和驗證。實驗結果如表3所示。增強Transformer的位置放在下采樣Bottleneck的前面能得到較好的準確率,并且插入位置越靠近頂部,模型的準確率會越低。
3 結語
通過在ResNet下采樣過程中添加增強Transformer得到改進模型,利用圖像識別對鑄件外觀缺陷檢測。實驗表明改進后的圖像識別模型能夠更精確地對缺陷圖像進行分類。在深度卷積結構中插入Transformer模塊,使得網絡可以進行局部或全局特征信息交互,從而增強特征信息,對大范圍毛刺和細小劃痕缺陷都能準確識別。ResNet(ET)不僅能夠在圖像識別任務中獲得較高的準確率,同時它的計算速度并未下降,ResNet(ET)相比同類型的網絡架構表現出更好的泛化性能。
參考文獻:
[1] 張國寶,楊為,趙恒陽,等. 基于X射線三維成像技術的在役GIS盆式絕緣子缺陷檢測[J]. 高壓電器,2022,58(10):230-236.
[2] 周祺智,馬萬太. 基于局部分類的鋁合金低倍組織圖像分割[J]. 機械制造與自動化,2022,51(4):129-132.
[3] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM,2017,60(6):84-90.
[4] SZEGEDY C,LIU W,JIA Y Q,et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,MA,USA: IEEE,2015:1-9.
[5] SIMONYAN K,ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10)[2022-10-20]. http://arxiv. org/abs/1409.1556.
[6] HE K M,ZHANG X Y,REN S Q,et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas,NV,USA: IEEE,2016:770-778.
[7] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all You need[EB/OL]. (2017-06-12)[2022-10-20]. https://arxiv.org/abs/1706.03762.
[8] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An image is worth 16x16 words:transformers for image recognition at scale[EB/OL]. (2020-10-22)[2022-10-20]. https://arxiv.org/abs/2010.11929.
[9] SRINIVAS A,LIN T Y,PARMAR N,et al. Bottleneck transformers for visual recognition[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville,TN,USA: IEEE,2021:16514-16524.
[10] PENG Z L,HUANG W,GU S Z,et al. Conformer:local features coupling global representations for visual recognition[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal,QC,Canada: IEEE,2022:357-366.
[11] XIE S N,GIRSHICK R,DOLLR P,et al. Aggregated residual transformations for deep neural networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu,HI,USA: IEEE,2017:5987-5995.
[12] HUANG G,LIU Z,VAN DER MAATEN L,et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu,HI,USA: IEEE,2017:2261-2269.
[13] KRIZHEVSKY A. Learning multiple layers of features from tiny images[R].Toronto, Canada: University of Toronto,2009.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
