科學數據分類分級保護探索:框架與模式
2024-12-01 00:00:00王健周國民張建華許哲平劉婷婷
農業大數據學報 2024年3期





摘要:近年來,隨著數據安全監管的日益收緊,科學數據管理面臨越來越嚴峻的“安全合規”挑戰,數據分類分級保護逐漸成為學術界、數據管理實踐者和監管機構共同關注的議題。然而,現有的研究和實踐大多局限于對數據合規的解釋與反應性應對,缺乏對科學數據分類分級保護的系統性和理論性討論。這種認知不足限制了科學數據安全管理領域理論框架和實用模型的發展。為形成對科學數據分類分級保護的系統性理解,本研究基于對現有實踐的廣泛調查,提煉出科學數據的六項關鍵安全特征:多重規制、倫理強規制、學科領域差異性、“規模-風險”帕累托分布、公益性和動態敏感性,以此六項特征為基礎,構建了科學數據安全分類和分級框架,并提出了全面、平衡與精簡三種保護模式。研究提出了“數據合規-合規成本-數據收益”三角平衡觀點,合理解釋了三者之間的權衡關系。文中還詳細討論了數據安全分類與安全分級的區別及其相互作用,澄清了科學數據安全分類的復雜性。該研究提出的針對科學數據分類分級保護的理論框架為分析科學數據安全管理中的復雜問題提供了框架性工具,可為相關研究提供有價值的參考,有助于推動科學數據安全保護實踐。
關鍵詞:科學數據;數據安全;數據保護;數據分類;數據分級;數據倫理
1 "引言
1.1 "背景
科學數據管理正面臨數據安全監管收緊引發的“安全合規”挑戰。僅就個人數據而言,歐盟、美國、中國等主要創新型國家或區域先后發布了《通用數據保護條例(GDPR)》、《加州消費者隱私法案(CCPA)》和《個人信息保護法(PIPL)》等法規,對個人數據的采集、存儲、傳輸、利用和再利用等進行了更加嚴格的規制。這些法規顯著增加了生物醫學、人文社科等領域的研究成本[1–5],并影響了涉及歐盟的國際合作研究[6]。
作為管理層面的應對措施,許多科學中心和數據管理機構已引入GDPR等法規,并在機構政策和業務流程等方面進行了相應調整,以滿足數據合規的要求。在中國,此類事件驅動性質的研究與管理實踐日益受到重視,尤其是在《科學數據管理辦法》 和《數據安全法》 先后提出“數據分類分級保護”要求后。目前,科學數據分類分級保護已經成為學術界、科學數據管理實踐領域和數據安全管理當局的共識,成為緊監管環境下應對“安全合規”挑戰的基本路徑。
與實踐需求形成鮮明對照的是相關研究的不足。首先是缺乏對安全視角下科學數據及其保護的復雜性關注不足。科學數據包含個人隱私、知識產權以及對公共健康、社會政策和環境具有廣泛影響的多類敏感信息,是一個復雜、綜合但同時缺乏明確法律邊界的數據大類,其保護不僅需要遵守多重法律規制,而且還涉及倫理考量[7-8],需要維護科學研究的完整性(Integrity)和可重復性。其次是對科學數據保護的系統性理解及實踐指導作用相對不足。部分學者關注科學數據分類分級保護的意義或策略等宏觀議題[9-13],其目的顯然是希望引起學術界和政策制定者的討論;部分學者關注數據安全分類分級方法[14-16]、標準規范[17-18]等實踐議題,以及空間科學[19]、高能物理[20]、冰川凍土[21]、醫學[14,22]、計量科學[23]等學科領域實踐,嘗試為相關實踐提供參考。然而整體上,科學數據分類分級保護的內在邏輯和實現模式仍然缺乏系統性討論。這種研究現狀在一定程度上解釋了當前實踐中存在的平凡引用通用或其他領域數據分類分級保護方案的做法,以及由此帶來的可行性和有效性問題。
科學數據保護實踐需求與研究供給之間的空白已經成為前者發展的重要障礙。論文旨在通過提出一個分類框架和三種數據保護模式來填補這一空白。這些發現基于對相關機構的數據保護實踐調查,其目的是建立科學數據分類分級保護的系統思維框架,為學術界、科學數據管理實踐和數據安全管理當局的政策溝通提供理論基礎,為相關機構的實踐提供實用工具。
1.2 "目標
本研究的主要目標是提供一個科學數據安全分類分級框架及與之配套的三種數據保護模式,為應對科學數據保護相關的復雜性和挑戰提供理論和實踐參考,具體的目標包括:
(1)闡明科學數據安全分類的復雜性
基于科學數據的六項數據安全特征對復雜性做出解釋,特別是多重規制和倫理因素的影響。這些影響導致許多實踐困惑,例如難以確定數據的法律或倫理規制,或者無法明確數據安全分類與安全分級的邊界。
(2)開發科學數據安全分類分級框架
基于通用的數據安全分類分級框架和科學數據的六項安全特征,以擴展和細化的方式建立科學數據專用的分類分級框架,同時為各科學數據相關機構形成更具個性化的框架提供一個系統性、結構化的思考路徑。
(3)提出科學數據保護的模式
研究提出了三個科學數據保護模式:全面模式、平衡模型和簡化模型。這些模式是不同機構對數據保護平衡三要素——數據合規、合規成本和數據收益——進行綜合權衡的結果。具有不同功能定位和不同資源投入的數據管理主體可以分別采用相應的模式對所管理數據實施保護。
1.3 "研究意義
本研究嘗試增加學術界、科學數據管理群體和數據安全管理部門對科學數據分類分級保護的理解,為相關數據保護實踐提供參考。在科學數據對科學發展和政策制定日益重要、數據安全監管持續收緊的情況下,本研究對相關理論的發展和具體實踐有指導意義。
1.3.1 "研究方面
在科學數據安全管理方面有兩項貢獻。首先,提取出科學數據的六項數據安全特征,在此基礎上提出了科學數據安全分類分級框架。這一系統性的科學數據安全分類分級思考框架,在一定程度上補充了現有研究的不足。其次,提出了科學數據保護的三種模式,同時給出了如下兩項相關發現:
(1)數據管理機構在數據生態系統中的功能定位決定了其最適宜的數據保護模式;
(2)數據保護模式的選擇是數據管理主體對數據合規、合規成本和數據收益三個要素進行綜合權衡的結果。
上述發現為相關研究提供了具有理論支撐的分析框架,同時促進了研究人員、實踐者和政策制定者之間的持續對話。
1.3.2 "實踐方面
該研究將在如下兩方面對科學數據保護實踐做出貢獻。一是提出了一個科學數據安全分類和分級框架,作為系統性的參考和指導;其二介紹了三種數據保護模式以及選擇或調整這些模式的原則,可指導機構在數據合規、合規成本和數據收益最佳平衡的基礎上制定與優化數據保護策略及其落地實施,這對于確保高效、合理的數據保護至關重要。
1.4 "論文結構
本文共分為七個部分。第一部分概述了研究的背景、目標及其重要性。第二部介紹了研究所采用的方法。第三部分探討了科學數據的本質,提出了六個具有數據安全意義的關鍵特征,為隨后的分類與保護模式研究奠定了基礎。第四部分深入分析了科學數據安全分類與分級的實踐及基本思想,構建了相應的框架。第五部分提出了三種科學數據保護模式,并對其理論依據與優化策略進行了詳細論述。第六部分闡述了本文觀點及應用場景。第七部分總結了研究發現,并指出了未來的研究方向。
2 "研究方法
研究采用網絡調查的方法搜集必要的資料,具體
包括調查設計、樣本機構遴選、數據收集過程和數據分析四個環節。
2.1 "調查設計
調查的目的是理解樣本機構的科學數據分類分級保護實踐,調研內容包括機構政策、工作報告、標準規范以及其他反映數據管理實踐的網絡公開信息。必要情況下,調查還將擴充至樣本機構所屬監管機構的政策與制度。
數據收集的主要方法是人工遍歷樣本機構的網站,以獲取樣本機構的如下資料:
(1)數據安全分類信息:樣本機構如何根據敏感性和法規要求對科學數據進行分類。
(2)數據分級信息:樣本機構如何為不同類型的數據分配敏感性或風險等級。
(3)數據保護實踐:為保護數據而實施的措施、政策(包括遵守法規和遵循倫理標準)、規范、流程、組織、技術工具以及軟硬件基礎設施。
(4)數據監管信息:樣本機構所受數據監管相關的政策、法律法規、標準規范、行業政策等。
2.2 "樣本機構遴選
樣本機構遴選力求實現機構類型和地理區域的雙重代表性。在機構類型上,調查以目標機構在科學數據生態系統中的功能定位為遴選標準選定如下三類樣本機構:
(1)數據管理者:開展科學數據生產、管理、共享和利用的大型綜合性研究機構,典型樣本為哈佛大學。
(2)數據托管者:為數據所有者提供數據托管及開放共享服務的各類機構,典型樣本為美國校際社會科學數據共享聯盟存儲庫(Inter-university Consortium for Political and Social Research,ICPSR) 等大型科學數據存儲庫。
(3)數據共享服務提供者:為數據所有者提供數據共享服務的各類機構,這些機構很少或不會提供數據管護服務,典型樣本為DRYAD 或Figshare 等數據共享機構或平臺。
(4)政府監管部門:對樣本機構及其政策或實踐實施監管或指導的政府部門,其政策構成了樣本機構數據保護實踐的制度環境和監管背景。例如,美國國
家衛生研究院 或中華人民共和國科學技術部 。
樣本機構需同時符合如下三條標準:
(1)高學術影響力:除政府監管部門外,入選的樣本機構均須在所管理數據的規模、機構規模以及機構的學術影響力方面具有前列(top20)。
(2)區域覆蓋:除政府監管部門外,入選的樣本機構需覆蓋歐洲、美國、中國和其他地域,由此實現區域代表性。
(3)同等條件替補:若樣本機構缺乏足夠的公開可用信息,則根據標準1、2遴選新機構作為替代,確保樣本的規模和代表性。
基于上述標準共遴選了80個機構,篩除17家資料不完整的機構,最終得到了63個樣本(附表1),同時納入了相關的10個監管部門或有影響力學協會。
2.3 "數據收集過程
(1)網站審查:對所選組織和相關政府部門的網站進行詳細瀏覽,以收集有關數據分類、分級和保護實踐的信息,具體包括公開的文件、政策、標準規范、工作報告和其他在線可訪問的相關材料。
(2)信息采集:從所收集的資料中提取關鍵信息,重點是樣本機構如何分類和分級科學數據及其采取的保護措施。此外,調查還將記錄影響這些實踐的政府政策和法規。
(3)數據驗證:為了確保收集信息的準確性,在可能的情況下進行多方交叉驗證。記錄下不一致或含糊之處,并在必要時進行核查等澄清操作。
2.4 "數據分析
數據分析過程包括以下步驟:
(1)數據整理:收集的信息根據主題進行整理和分類:數據分類、分級、保護實踐和監管合規性。該整理有助于對不同組織的實踐進行結構化分析。
(2)比較分析:對三組樣本機構及相關管理部門的數據保護實踐進行比較分析,確定其中的異同點,以此揭示不同類型組織和政府實體在數據管理方面的模式和趨勢。
(3)主題分析:運用主題分析來識別調查資料中的常見主題和見解。主題是基于公開信息中反復出現的概念和問題發展而來的。
(4)結果整合:將比較分析和主題分析的結果整合起來,以提供對數據保護實踐的全面理解。這一整合為本文所提出的分類框架和管理模型的發展提供了信息。
3 科學數據的數據安全特征
科學數據是研究的基礎,涵蓋了研究過程中生成的廣泛材料,包括原始數據、處理后數據和分析結果[24]。不同于商業或政府數據,科學數據與知識生產和科學進步緊密相關,這賦予其多樣性和復雜性,給管理和保護帶來挑戰[25]。科學數據源自不同學科,并應用于各種研究背景、公共管理或企業開發等場景,每個生產和應用環節都有特定的標準、倫理考量和監管要求[26]。這種多樣性和復雜性決定了科學數據的安全特征,以及需要專門針對這些特征的精細化數據保護方法[27]。
3.1 "多重監管
現代研究的全球性和跨學科性[28]使得科學數據必然受到多個監管框架(包括倫理規范)的約束,每個司法管轄區和研究領域可能對數據保護提出各自的特定要求,導致研究人員需要應對復雜的合規環境[29]。例如,在歐洲收集的個人數據必須遵守《通用數據保護條例》(GDPR)[30],而與健康相關的數據可能需要遵守美國的《健康保險流通與責任法》(HIPAA) 。此外,涉及瀕危物種的研究可能受《瀕危野生動植物種國際貿易公約》(CITES)[31]的監管。
多重規制特征還存在另一個操作性原因,即科學數據缺乏明確的法律界定。從法律規制的角度看,科學數據是個人數據、商業數據等多個法定類型以及公共數據等非法定類型的混合,同時不同類型之間不存在互斥關系。這種具有交叉關系的類型混合必然導致多重規制,并在實踐中表現為數據歸類的模糊性和復雜性。
3.2 "倫理強規制
各類數據均同時接受法律和倫理的雙重規制,并且前者往往居于主導地位。然而,不同于商業數據、公共管理等數據大類,科學數據受到了嚴格且有力的倫理約束。尤其是在生物醫學研究或涉及兒童等弱勢群體的研究領域中,相關的倫理考量往往超出了法律要求[32-33]。例如,雖然法律法規可能允許某些數據處理活動,但倫理準則可能會施加額外的限制,以保護參與者的權利和福祉[34]。
倫理強規制源于研究人員對確保其工作完好性(research integrity)以及保護其人類參與者和學術共同體的道德義務[35],其強制力遠超商業倫理和公共數據倫理對相關數據行為的約束。對于研究人員而言,在絕大多數情況下,遵守倫理標準與遵守法律要求同等重要,甚至更為重要[36]。
3.3 "學科領域差異性
研究內容、研究方法、固有風險以及監管環境存在學科、領域差異[37],科學數據的敏感性和保護需求在不同學科、領域之間必然存在顯著不同[38]。例如,涉及基因信息的生物醫學數據比涉及消費者行為的社會科學調查數據需要更高水平的保護[39]。學科領域差異性強調了需要根據各研究領域的獨特風險和監管要求制定專門的數據保護策略,凸顯了理解科學數據生成和使用的特定背景的重要性[27]。
3.4 “規模-風險”帕累托分布
科學數據在規模與其風險上呈現帕累托分布特征。盡管缺乏統計證據量化證明20%的數據帶來了80%的風險,但長期科學數據管理實踐可定性表明,規模占比最大的開放數據具有最小的數據風險,風險較高的敏感數據規模占比遠小于開放數據,風險更高的重要數據和核心數據占比規模又遠遠小于敏感數據。
“規模-風險”帕累托分布是風險管理的基本理論[40],是科學數據分類分級保護的理論立足點,也是下文所述三類數據保護模式的基本出發點。
3.5 "公益性
科學數據往往對公共利益產生重大影響[41]。例如,促進醫學進步、環境保護或社會政策的數據可以為社會帶來深遠的利益[42]。因此,確保此類數據得到保護并負責任地使用符合社會公眾的利益[36]。這種對公共利益的關注解釋了科學數據保護不僅是為了實現數據的法律合規,還是為了推動數據持續為公共利益做出貢獻[43]。科學數據保護在很多時候是為了保護從科學探究中產生的公共利益。
3.6 "動態的敏感性
科學數據的敏感性隨著時間的推移而變化[25]。曾
經非敏感的數據可能由于新的科學發現、社會規范的變化或不斷發展的監管標準而變得敏感[24]。例如,當前匿名化的基因數據可能隨著大數據分析技術的進步而再次關聯到特定人員,或者生命科學研究的發展使得靜脈紋理圖像[44]、心音[45]或者腦電波[46]都成為了可識別個人身份的敏感信息。
數據敏感性的動態性要求靈活和適應性強的數據保護策略[26]。研究人員和數據管理者必須準備好隨著數據敏感性的變化不斷重新評估和調整其保護措施[47]。
科學數據的六個特征源于其全球性、跨學科和受倫理約束的研究本質[24],體現為多重監管、強倫理規制、學科差異性、公益性和動態敏感性。這些特征相互關聯,構成復雜的數據保護環境,例如,法規合規可能受到倫理的影響[27],而動態敏感性可能與公益性相關。理解這些特征對于制定能夠滿足科學數據獨特需求的有效數據保護策略至關重要[32]。
4 "科學數據安全分類分級
數據的安全分類與安全分級具有不同的管理意義:前者確定數據的適用規制[48],是數據安全管理專業性的體現;后者確定數據的風險程度,是匹配數據保護措施的依據;二者共同確定了給定機構的適管數據范圍,是“數據合規、合規成本、數據收益”三角平衡的支點。科學數據是通用數據安全分類分級框架的具體實現與擴展。
4.1 "數據的安全分類分級
數據的安全分類分級是從安全角度對數據進行的水平或垂直劃分。水平分類針對數據所含信息的敏感性,其依據是相關法律、倫理、標準規范和行業或機構政策對敏感信息的界定,其意義在于明確數據的適用規制系統(例如,個人數據由《中華人民共和國個人信息保護法》9規制),最終實現敏感信息的專業化處理,即由最理解數據內容和規制要求的專業人員識別與界定敏感信息。垂直分級針對數據相關風險的性質和影響程度(包括數據本身的風險及數據相關行為的負外部性),其管理意義是籍由等級化的風險界定(例如,重要數據或核心數據)確定必要的安全保護措施,最終實現“數據合規、合規成本、數據收益”三角平衡。
數據的安全分類與安全分級均由數據安全規則體系決定。其中,法律規制和倫理規制提出要求或原則,標準規范和機構政策將之映射為各具體機構的操作性政策或規則,同時融入機構級數據訴求。觀察具體實踐可以發現,盡管國內外的數據安全制度存在較大差異,但我國和美歐等主要國家均采用了國家秘密數據、非國家秘密但受到控制的數據(以下簡稱受控非密數據,Unclassed controlled data, UCD)以及一般數據的三元框架(表1)。
9 https://www.gov.cn/xinwen/2021-08/20/content_5632486.htm
10 http://gongbao.court.gov.cn/Details/a1c97149796e14f585c1662b0f9099.html
11 http://www.npc.gov.cn/c2/c30834/202106/t20210610_311888.html
國家秘密數據(或者說,含有國家秘密信息的數據)的規制依據是《中華人民共和國保守國家秘密法》,是指關系國家的安全和利益,依照法定程序確定,在一定時間內只限一定范圍的人員知悉的事項。國家秘密在類型上包括國家事務重大決策中的秘密事項、國防建設和武裝力量活動中的秘密事項、外交和外事活動中的秘密事項以及對外承擔保密義務的秘密事項、國民經濟和社會發展中的秘密事項、科學技術中的秘密事項等7個細分子類,在等級上包括絕密、機密和秘密3個等級。與我國不同,美國沒有單一的國家秘密法,而是由《信息自由法》等一系列相關的法律、法規形成的綜合性規制依據,由此形成的國家秘密(Classified Information)在類型上包括軍事計劃、外國政府信息、情報活動、外交活動、與國家安全有關的科技事項等8個細分子類,同樣分為頂級機密(Top secret)、機密(secret)和秘密(confidential)3個等級。
受控非密數據是指不屬于國家秘密但需要在國家層面施予特別保護措施的數據。該類名和內涵均借用自美國的同名數據安全類型。我國法律規制中沒有單設這一類型,但借助重要數據和核心數據形成了枚舉性界定[49]。借用UCD概念的主要考量是其在中美兩個異質規制系統中的定位相似性:二者均居于國家秘密數據和一般數據之間,且三者在內涵、外延與規制力度三方面均表現出梯度銜接關系。美國的受控非密數據包含了20個公共事項主類(包括關鍵基礎設施、防御、執法、核、專利等)和125個子類。相對而言,我國沒有明確給出重要數據和核心數據的細分子類,這意味著我國的UCD在理論上可以覆蓋除國家秘密外所有的數據。此外還需要注意到,核心數據相對于重要數據而言更多體現了風險水平的提升而非風險內容的差異,即二者構成了風險高低的等級關系而非平行的類型關系。
一般數據囊括了國家秘密和受控非密數據之外的全部數據,是一個兜底性質的數據類型。歐美數據安全體系中沒有對應類型,其在實踐中往往以“敏感數據+開放數據”的形式表達類似的含義。其中,敏感數據是含有敏感信息因而需要采取合規措施予以保護的數據,其識別和規制依據包括《中華人民共和國個人信息保護法》《通用數據保護條例》《健康保險可攜性與責任法案》等專業硬法,也包括《科學數據管理辦法》《紐倫堡法典》《西蒙報告》《赫爾辛基宣言》等軟法或科學倫理,以及《數據安全技術 數據分類分級規則》[49]等標準規范。國內外一般數據的細分子類差別很大:我國的規制系統將一般數據分為個人數據、商業秘密數據、公共利益/秩序與公共安全相關數據和其他數據四個大類,其中個人數據具體分為26個子類[49];歐盟各成員國則不在此類型中顯式納入公共利益、秩序與安全數據和其他數據等類型。同時,個人數據具體分為基本個人信息等8個大類12小類12。
整體觀察三個大的安全類型可以發現,國家秘密數據、受控非密數據和一般數據的規制依據在多樣性和擴展性上逐漸增加。以我國為例。國家秘密由《中華人民共和國保守國家秘密法》單一規制,具有明顯的封閉性;受控非密數據由《數據安全法》等數據安全主法及一系列相關法律和標準規范進行規制,類型和數量較之國家秘密數據有所增多,呈現了一定的擴展性;一般數據則由《個人信息保護法》等數量眾多的專業法所規制,并且隨著人類科技探索和司法實踐的發展,新的法條或倫理規則不斷加入,呈現了顯著的擴展性。相對而言,由于科學研究領域的探索性,科學數據在“一般數據”類型中的多樣性和擴展性更加突出。
4.2 "科學數據的安全分類
科學數據最寬泛的定義是具有科學價值的數據,這一功能導向的界定意味著科學數據在理論上覆蓋了表1中的全部數據安全類型。畢竟僅就數據本身而言,無論是國家秘密還是受控非密數據都可以成為研究證據。然而在具體實踐中,國家秘密數據因其特殊的保護措施而不被視為科學數據的保護范圍,受控非密數據也僅僅在特殊情況下(例如,由研究活動所收集)極小部分地被納入科學數據保護范圍。換言之,科學數據安全保護的對象基本上是表1中的一般數據。
然而,即使僅僅集中于一般數據類型,科學數據本質及其六個安全特性也形成了數量較多的子類型,并籍由這種擴充形成了科學數據的安全分類(表2)。
科學數據安全分類的復雜性在不同的組織機構具有不同的表現,主要取決于相關機構涉及學科領
12 https://gdpr-info.eu/
域的全面程度。對于哈佛大學等綜合性大學而言,多學科乃至全學科覆蓋的特點決定了其所管理數據的分類必然是復雜的,因而很少制定全局統一的分類標準,基本上通過不同的專業倫理委員會實施數據敏感性內容的專業判斷。另一方面,對于大部分專業性學科領域數據倉儲而言,由于所涉及學科領域數量較少且相對集中,敏感信息的類型較少,因而往往制定并執行全局統一的分類標準。然而整體上,科學數據所含敏感信息基本上可歸入表2所示的類型框架。
13 部分個人生物數據歸屬個人數據類別
4.3 "科學數據的分級
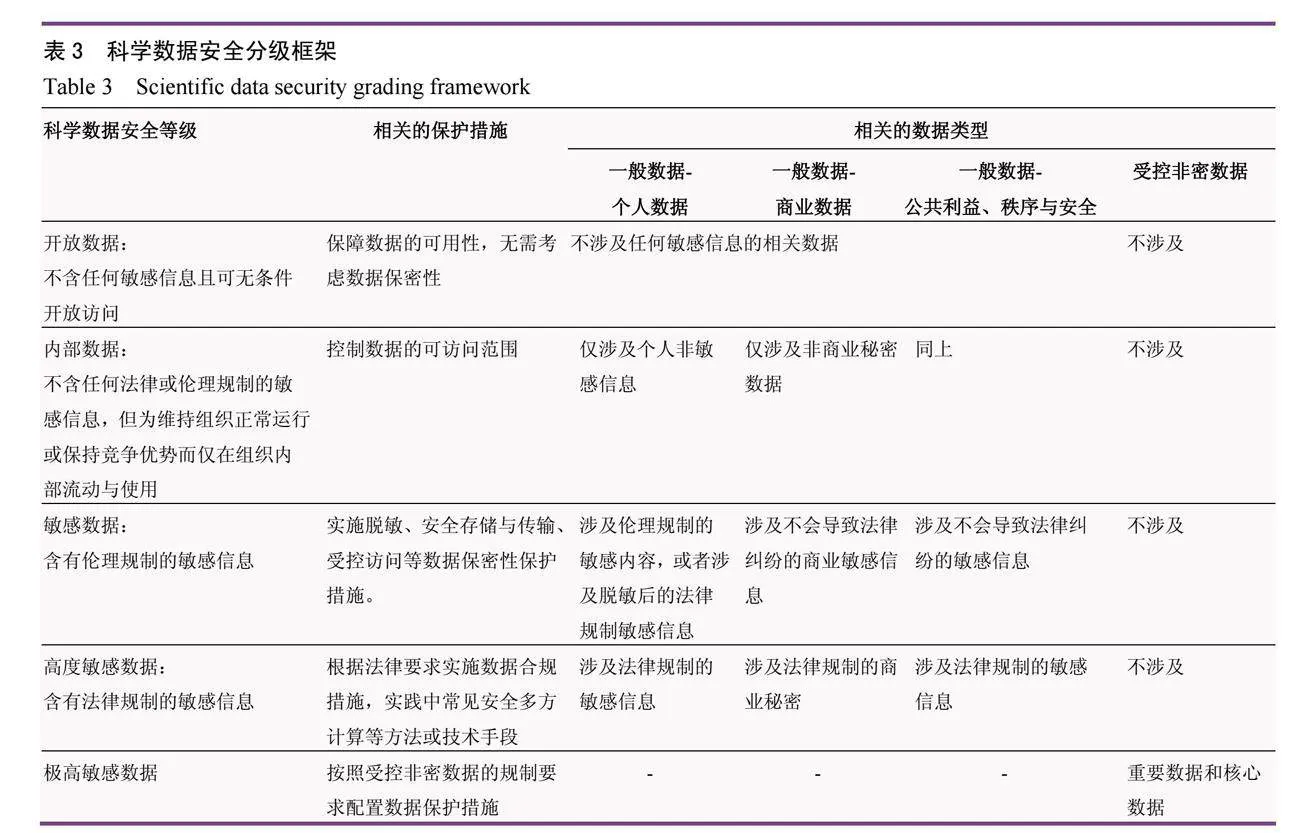
科學數據分級直接關聯數據保護措施,是通用數據分級框架與方法在科學數據上的具體應用。與此同時,在科學數據盡可能開放的原則下,學術界和科學數據管理部門在合規的前提下,借助數據安全訪問模型[50]14等理論,基于數據敏感內容的規制類型和風險程度,發展形成了多種力度不同的數據保護方法,形成了事實上的安全等級細分框架(表3)。
表3表明,實踐中的科學數據分級主要覆蓋了一般數據,除極少數數據生產管理單位(例如,哈佛大學)外,絕大部分數據管理機構僅處理一般數據類型。從規模的角度,絕大部分數據在等級上隸屬開放數據、內部數據和一般敏感數據,高度和極高敏感數據占比很少。
5 "科學數據分類分級保護模式
科學數據分類分級保護具有不同于其他領域數據的管理流程與組織結構,這些管理要素的穩定組合形成了全面、平衡和精簡三個模式,其決定性因素是科學數據管理主體在科學數據生態系統中的功能定位。
5.1 "科學數據管理者的生態功能定位
開放科學和科學數據的大數據化正在推動科學數
14 http://fivesafes.org/
據生態系統[51-52]的形成。貫穿這一生態系統的主干是數據“生產-存檔-共享-利用”的生存周期,不同的生態系統參與者涉及了不同周期階段或其組合,形成了各自不同的功能定位。從數據安全管理的角度,除數據用戶群體外,具有明確功能定位的主要參與者還包括科學數據生產管理者、科學數據受托管理者和科學數據共享服務提供者三個群體。
科學數據生產管理者在功能上覆蓋了數據生存周期的全部環節,其數據管理的首要目的是保護并最大化自身數據的價值,其典型代表是研究型大學或中國科學院等大型綜合性研究機構。科學數據生產管理者需要同時管理自身生產和外部托管的數據,這意味著它需要囊括自身生產的所有類型的數據,同時還要覆蓋從數據生產環節開始的全部數據安全域[53],這種功能定位客觀上決定了其數據安全管理對數據安全類型、風險和數據保護的全面覆蓋。
科學數據受托管理者在功能上覆蓋了除數據生產之外的數據生存周期環節,同時具有兩個突出特點:其一,所管理數據均來自機構外部委托者(主要是數據生產者或實際控制者),管理者與委托者簽訂托管協議并據此為后者提供數據管護與共享服務;其二,數據管理的主要目的是在數據合規的前提下,實現數據共享以促進數據價值發揮。典型的受托管理者包括ICPSR、Zenodo15、國家農業科學數據中心16等學科領域或綜合性科學數據中心,以及Scientific Data17等開展數據出版的學術出版機構。從數據安全管理的角度,受托管理者采用了一種平衡策略——即通過排除部分高規制數據(例如,通過拒稿或拒絕接收等方式排除重要數據或核心數據等需要更高數據保護措施的數據),實現數據合規、管理成本和數據收益的最佳平衡。
科學數據共享服務提供者僅提供數據共享功能,很多機構甚至借助將數據存儲于第三方倉儲的方式進一步縮減其在生態系統中的功能覆蓋。典型的科學數據共享服務提供者包括Figshare、DYARD等科學數據共享中心。在實踐中,共享服務提供者普遍要求托管者基于CC BY 4.0等制式協議18——通常由數據提交者聲明承擔數據的質量和安全責任——自助提交與發布數據。借助這種“協議+自助”的方式,數據共享服務者事實上僅接收開放數據而排除了所有需要特別保護措施的數據,由此以最少投入的形式實現了數據合規、數據管理成本和數據共享的精簡式平衡。
5.2 "全面模式:哈佛大學
全面模式覆蓋了科學數據生存周期全程及數據安全管理的全部過程域,涉及了全部的數據安全類型和等級,主要由各類科學數據生產管理者采用。這些機構的研究活動規模大、類型多且覆蓋了眾多學科領域,涉及到大量數據的生產和流動、復雜多樣的數據安全場景和幾乎全部的數據安全類型,使得數據合規成為其數據安全管理的嚴峻挑戰和首要目標,科學數據存檔與復用成為了相對次要的目標。在三種數據保護模式中,全面模式的數據規制范圍最大、規制力度最強且規制成本最高。
哈佛大學的全面數據保護主要體現在分類分級和數據保護流程兩個方面。
15 https://zenodo.org/
16 https://www.agridata.cn/#/home
17 https://www.nature.com/sdata/
18 https://creativecommons.org/licenses/by/4.0/legalcode.zh-hans
(1)全面的數據安全分類分級方案
哈佛大學的教學研究涉及了自然科學、社會科學、人文學科等五十余個學科門類,這決定了其所管理數據(包括大學研究人員生產和托管的數據)的內容多樣性,形成了其復雜、全面的數據安全分類分級方案(表4、表5)。
這一方案體現了“管理分類、風險定級”的思想:首先根據數據所含敏感信息的專業或管理屬性確定其類型,以此實現數據與其處理人員的專業或管理匹配;其次,根據數據風險的性質、發生的可能性以及相應后果的嚴重程度,確定各類數據的安全等級并匹配以相應的安全保護措施。
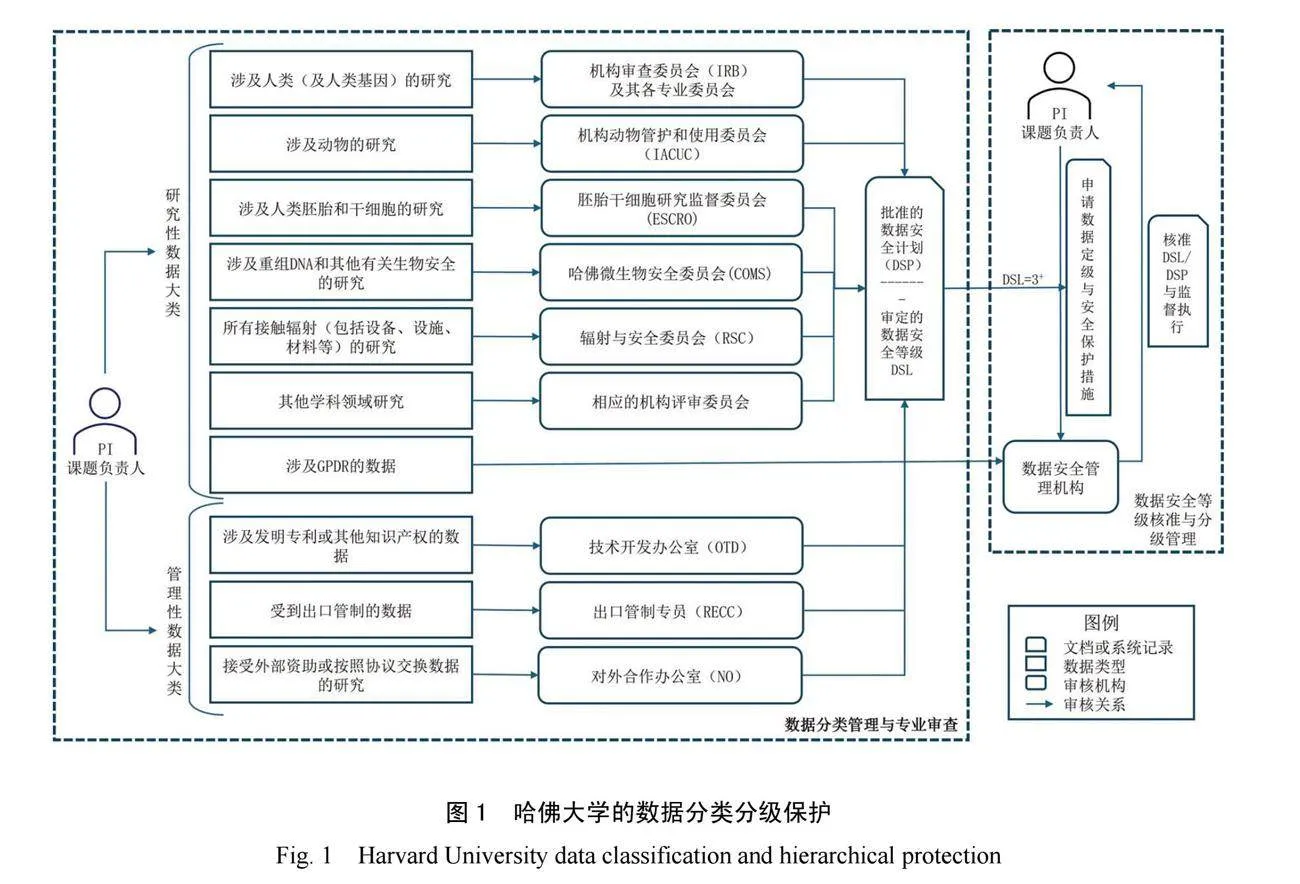
哈佛大學并未給出數據安全類型的統一說明——可能與敏感信息的學科領域差異有關——而是在數據安全分類分級管理流程(圖1)中提及了7種不同的類型。這些類型分別歸屬研究視角和管理視角兩個維度(表4)。其中,研究視角關注法律規制和倫理規范的敏感內容,管理視角關注政策和管理層面的敏感內容。整體上,個人數據是體量最大且最受關注的數據安全類型。
哈佛大學通過數據安全管理部門發布了具有5級數據安全等級標準(表5)。該標準覆蓋了大學自身生產的數據和因托管或合作等納入管理范圍的數據。數據專業機構和校信息數據管理部門共同確定特定數據的安全等級。
(2)“學術評審+信息安全批準”的兩階段數據保護流程
哈佛大學設置了兩階段的數據分類分級保護流程,并發展了配套的組織機構與技術、工具和軟硬件基礎設施(圖1)。第一個階段是各類學術機構主導的數據安全類型判斷與等級審定。研究項目負責人(PI)在研究啟動前需要根據數據合規和科學倫理的要求及相應標準規范,初步判斷所收集數據的安全類型及等級,進而根據數據類型,借助相應的數據安全評審系統(例如,ESTR-IRB)向負責該類數據倫理審批的學術機構(例如,IRB或COMS)報送數據安全等級(Data security level, DSL)及相應的數據安全保護計劃(Data security plan, DSP)。審批機構根據學校的數據安全管理政策和倫理規范審定DSL并判斷DSP的合理性與有效性。第二個階段是信息安全部門主導(ISR)的數據安全等級核準與分級保護。在這一階段,當數據的DSL大于三級時(表5),
19 《關于防止受關注國家獲取美國人大量敏感個人數據和美國政府相關數據的行政命令》(Executive Order on Preventing Access to Americans\" Bulk Sensitive Personal Data and United States Government-Related Data by Countries of Concern),https://www.federalregister.gov/documents/2024/03/01/2024- 04573/preventing-access-to-americans-bulk-sensitive-personal-data-and-united-states-government-related.
20 https://privsec.harvard.edu/data-classification-table
項目負責人需通過專有系統向ISR呈報第一階段已批復的DSP和DSL。只有得到ISR的最終核準后,PI才能啟動數據采集等研究工作。ISR主要由信息安全技術、管理和數據安全法務人員組成,其職責是開展數據安全合規審查與監管。完成審批后,PI在項目全程均需嚴格遵循批復的DSP開展數據活動——例如,通過與DSL等級相匹配的安全設施或系統進行數據加工、傳輸、存儲與共享——并及時向ISR報告數據安全事項以接受其監督。
在流程之外,學校還配套了ESTR-IRB、安全終端、云安全存儲等數據安全軟硬件系統,以及專業性或綜合性機構審查委員會、對外合作辦公室、數據安全審查專員等角色與責任機構,從技術和組織上保障了敏感數據(L3以上)始終流動在受控“管道”中。
5.3 "平衡模式:ICPSR
數據分類分級保護的平衡模式是指數據管理主體采用排除高規制數據(主要是國家秘密數據和受控非密數據)的方式,構造適配自身數據管理目標的數據類型和等級并配置必要保護措施,從而在有限投入的情況下兼顧數據合規與數據利用的管理模式。這一模式的實踐者是各類數據受托管理者:早期主要是ICPSR等學科領域數據中心;隨著學術出版界開始要求作者提供研究支撐性數據或直接出版數據,很多學術期刊(特別是開展數據出版的期刊)也從成本和收益平衡的角度采用這一模式。
ICPSR實踐了典型的平衡模式。該數據中心面向人文社科領域中的教育、老齡化、刑事司法、恐怖主義等21個主題,收錄數據檔案50萬份以上,是全球最大的社科類科學數據中心,也因其數據管護的規范性和共享的廣泛性躋身于世界級的科學數據中心。ICPSR的主要做法包括數據安全分類分級方案以及分類分級保護流程兩方面。
5.3.1 "平衡性的數據安全分類分級方案
數據托管者管理的數據均來自外部,這意味著此類機構可以根據自身的專業范圍和財務資源等因素,確定可納入管理范圍的數據安全類型與等級。例如,ICPSR主要服務人文社科領域研究,因此其以個人數據作為主要的數據安全類型;GBIF面向生物多樣性,因而更重視珍稀物種棲息地位置等敏感信息。需要注意的是,大多數托管者涉及的學科領域相對有限,數據安全類型數量少,因此往往不會給出明確的數據安全分類標準。
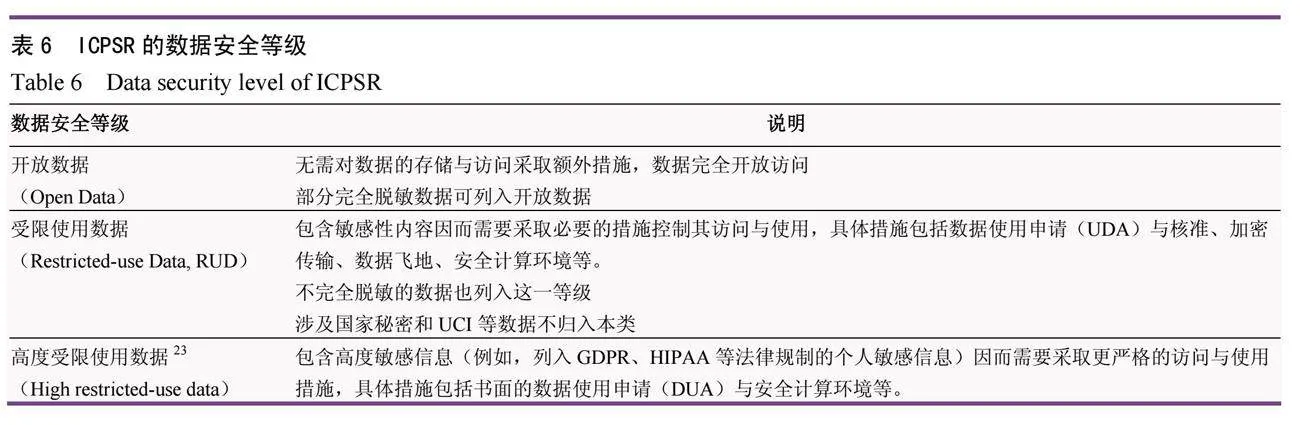
數據類型的縮小必然帶來安全等級的簡化。大部分托管者僅設置了敏感數據(或受限訪問數據21等類似名稱)與開放數據兩個大的等級,部分機構會將歸屬法律規制的敏感數據單列為一個高度敏感數據等級22。ICPSR在其數據管理政策中明確排除了任何涉及國家秘密和國家安全相關的數據,意味著其事實上僅處理一般數據(包括敏感數據和開放數據)中的3個安全等級(表6)。
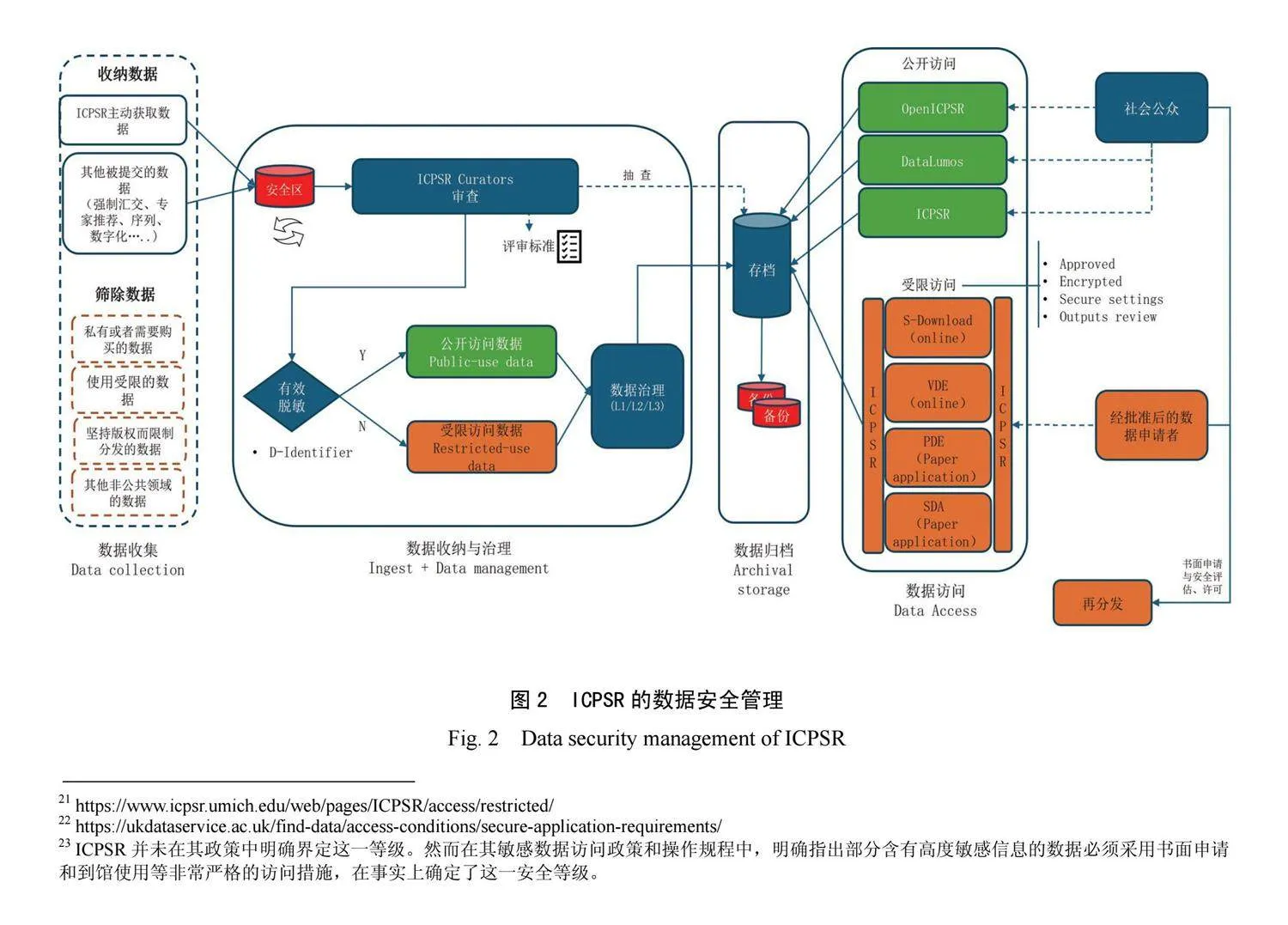
5.3.2 “選擇性納入與技術性定級+分級訪問”的三階段分類分級保護流程
ICPSR采用“選擇性納入+非學術定級+分級訪問”
3階段流程(圖2)。“選擇性納入與技術性定級”發生在數據收集環節。ICPSR在該環節設置了數據存檔適宜性評審,對數據的學術價值、存檔價值和安全風
21 https://www.icpsr.umich.edu/web/pages/ICPSR/access/restricted/
22 https://ukdataservice.ac.uk/find-data/access-conditions/secure-application-requirements/
23 ICPSR并未在其政策中明確界定這一等級。然而在其敏感數據訪問政策和操作規程中,明確指出部分含有高度敏感信息的數據必須采用書面申請和到館使用等非常嚴格的訪問措施,在事實上確定了這一安全等級。
險進行評審,其中安全評審的目的是排除高規制數據,同時根據數據敏感內容的類型(主要為個人身份信息和商業秘密)和程度將其標定為開放數據、受限使用數據和高度受限使用數據。該評審由數據管護人員而非學科領域專家實施。在“分級訪問”環節,ICPSR的數據服務團隊采用“請求-批準”方式保護敏感數據,具體措施包括RUD數據的安全下載、遠程安全訪問終端、數據飛地24,以及專門用于高度受限使用數據的數據安全實驗室25等。
5.4 "精簡模式:DRYAD
精簡模式在某種程度上是平衡模式的進一步簡化,即管理者排除了開放數據之外的所有數據,意味著管理者無需進行數據安全分類分級及其他與數據保密性有關的工作,實現了最小的數據合規成本。
精簡模式的采用者基本上是DRYAD、Figshare等公益性或非盈利數據共享中心。DRYAD是由美國國家生態分析與合成中心和美國國家進化合成中心主辦的科學數據倉儲機構,專注于進化生物學領域科學數據的管護與共享,主要借助亞馬遜云服務實現實驗數據、觀測數據、模擬數據等多種生態學和進化生物學數據的存儲。
DRYAD的數據保護措施集中在數據收納階段的數據篩除操作。數據管護人員對所提交的數據進行審議以判斷其數據作者身份和數據的真實性、可靠性與可用性,同時判斷數據是否含有個人身份信息等敏感內容,以此回避所有高規制數據。
6 "本文觀點及其應用場景
6.1 "觀點
科學數據與商業數據、公共數據在分類分級保護實踐上的差異是論文的起點。科學數據的分類分級與其他數據類型有何異同?為何大部分科學數據管理機構都提出了統一的數據安全分級方案但缺乏數據安全分類方案?為何大型學術機構普遍借助IRB(或類似的學術機構)與信息安全管理部門共同執行數據安全類型和等級的劃分?為何學術界發展了相對更多的敏感數據安全訪問方法與技術?這一系列源于實踐觀察的問題及其答案形成了本文的基本觀點:
(1)科學數據安全分類分級是通用數據安全分類
24 https://www.icpsr.umich.edu/web/pages/ICPSR/access/restricted/
25 https://www.icpsr.umich.edu/web/pages/datamanagement/lifecycle/services. html
分級框架的細化與擴展。類型細化與擴展集中在“一般數據”,擴展依據是科學倫理對更多敏感內容的關注;等級細化與擴展集中在“敏感數據”區域,體現了數據共享最大化、數據合規成本與數據合規要求的權衡。
(2)科學數據安全分類是基于法律規制和倫理要求對數據所含敏感內容進行辨識與劃分的過程。數據安全法律界定了法律規制敏感內容,科學倫理決定了倫理規制敏感內容。科學研究的廣泛性和科學倫理的學科領域性決定了科學數據的安全特征,進而決定了其分類與分級,以及IRB等學術機構參與數據保護的必要性。
(3)科學數據安全分級是合規導向的風險判斷及其等級化表示的過程。數據安全法律規制是決定性依據,科學倫理的作用相對較少。這一點決定了信息安全或數據安全部門主導或獨立進行安全分級的必然性。
(4)科學數據安全分類分級保護模式是特定機構追求“數據合規-合規成本-數據收益”三角平衡的結果。不同機構在數據生態系統中具有不同的功能定位和管理目標,決定了在三角平衡中的取舍,形成了全面、平衡和精簡三種模式。
6.2 "應用場景
論文形成的上述觀點有助于回答如下一些實踐中存在的爭議或困惑。
(1)科學數據安全分類的復雜性
科學數據的安全分類表現出較高的復雜程度,既關乎科技倫理的學科領域性或專業性,更與其缺乏明確法律界定直接相關。數據安全的主干是合規性,具有明確的法律界定和相應規制是降低模糊性及復雜性的前提。然而,不同于具有明確法律界定的個人數據26、商業數據27,科學數據缺乏明確的法律界定,或者說,在法律意義上,科學數據是多種類型數據的混合體——其外延既包括個人數據、商業數據,同時還包括同樣缺乏明確法律界定的公共數據[54,55],并且這些數據之間不存在互斥關系。顯然,從法律層面明確界定科學數據及其重要屬性是簡化其安全分類分級的可行舉措。目前,歐盟數據安全辦公室已經從公益性科學研究的界定著手逐步明確科學數據的法律界
26 依據《個人信息保護法》以及《通用數據保護條例》中的個人數據(persona data)的界定
27 依據《中華人民共和國反不正當競爭法》的界定
定,這無疑是解決科學數據安全分類分級管理乃至數據安全保護的重要舉措。
(2)科學數據安全分類與安全分級的區別和聯系
科學數據安全的分類與分級具有不同的專業性和管理意義。安全分類是根據數據安全規則(法律、倫理、標準規范與機構政策)識別數據所含敏感信息的過程。敏感信息的學科領域差異決定了科學數據安全分類的專業性,客觀上決定了科技倫理以及領域專家或專業性機構審查委員會(IRB)在數據安全分類中的核心作用。由此,學科領域的綜合性成為數據安全分類必要性的決定性因素,綜合性越高則必要性越大。相對而言,安全分級主要評估數據風險及其后果,需要由信息安全管理專業人員而非研究人員進行,這也是哈佛大學等機構單獨設立信息安全部門的原因。需要說明的是,在科學數據管理實踐中,部分單位會將數據的價值、珍稀程度等也作為安全分類指標,從而將安全分類擴展為管理性的數據分類,使得數據分類和相關管理更加復雜。
科學數據的安全分類與安全分級具有不同的作用。數據安全的基本原則是“分類管理、分級保護”,即數據安全分類的目的是實現數據內容與相應專業人員的匹配,其目的是提高管理效率;數據安全分級的目的是實現風險的控制與應對。顯然,如果不考慮數據敏感內容的專業性,則數據安全分類并不一定是必要的。事實上,很多學科領域數據中心往往不設置專門的數據安全分類標準及相應的崗位或團隊。另一方面,數據安全分類往往是數據安全分級的可選前序,后者又是后續保護措施配置的必要依據與必選前序。在這一意義上,數據安全分級顯然具有更高的必要性。
(3)科學數據安全分類分級的杠桿作用
數據安全分類分級對“數據合規-合規成本-數據收益”的平衡具有杠桿作用:寬松的分類分級標準代表著更多的開放數據與更少的規制數據,意味著機構可以在較少合規投入的情況下提供更多可共享數據,實現更大的數據價值和學術影響力。這種杠桿作用在國家層面同樣存在:更多開放數據必然提高該國對國際科學研究的數據貢獻,在“貢獻-收益”掛鉤的國際數據治理原則下[56],更高的貢獻無疑將鞏固、提升國家科學數據影響力和高質量數據的吸聚能力,最終實現“更多開放、更好安全”的積極性科學數據安全路徑。
(4)科學數據分類分級保護模式的內在邏輯
科學數據安全分類分級管理實踐中涌現了全面、選擇性和簡化三種模式,它們構成了數據安全保護的連續統一,呈現了數據安全保護范圍、保護水平和數據合規成本三者組合的階梯型變化。這些模式背后是一個共性的管理思考:在少數高規制數據消耗大部分合規成本的情況下,如何借助限定數據安全類型和等級范圍,實現數據合規、合規成本和數據收益的動態平衡。顯然,如果進一步考慮到更先進的管理、技術手段對整體效率提升的作用,則就模式設計、比選和優化而言,其內在邏輯是對兩個要素及其作用的把握:數據安全分類分級是這一平衡的關鍵支點,更先進的管理、技術措施是推動三角平衡體水平提升的重要推動力量。
7 "總結
全球性數據安全緊監管制度環境對傳統科學數據管理形成了“合規沖擊”,促使學術界、科學數據管理實踐群體和數據安全管理當局共同關注科學數據的分類分級保護。然而,相關實踐及研究整體上仍然局限于對“合規沖擊”的解讀和被動應對,其原因主要在于缺乏對科學數據安全分類分級及分級保護的整體性理解。
本研究在實踐調查和案例分析的基礎上,從科學數據本質及其六個安全特征出發,同時考慮到科學數據管理主體在數據生態系統中的功能定位,提出了科學數據安全分類分級框架及全面、平衡和精簡三種數據安全保護模式,指出了支撐模式的數據合規、合規成本與數據收益三元平衡思想。這在一定程度上補充了科學數據安全分類分級保護理論與實踐之間的空白,同時為相關實踐和政策制定提供了工具與參考。
科學數據規模增長、價值提升、復雜度升高和外部性增強是其安全保護工作日益受到重視的內在因素。在社會經濟和科學研究持續數字化且數據安全監管收緊的大趨勢下,這些因素將長期存在并發揮作用,這使得科學數據的保護成為比肩利用的重要管理議題。由此,研究并形成系統性和結構化的分類分級保護思想,探索契合開放科學精神的數據安全分類分級保護理論、方法與技術,加快科學數據管理從傳統環境向緊監管環境轉變,是相關實踐的需求,也是相關研究進一步發展的動力。
參考文獻
[1] PELOQUIN D, DIMAIO M, BIERER B, et al. Disruptive and avoidable: GDPR challenges to secondary research uses of data[J]. European Journal of Human Genetics, 2020, 28(6): 697-705. DOI:10.1038/ s41431-020-0596-x.
[2] CLARKE N, VALE G, REEVES E P, et al. GDPR: an impediment to research?[J]. Irish Journal of Medical Science, 2019,188(4): 1129-1135. DOI:10.1007/s11845-019-01980-2.
[3] KNOPPERS B M, BERNIER A, BOWERS S, et al. Open Data in the Era of the GDPR: Lessons from the Human Cell Atlas[J]. Annual Review of Genomics and Human Genetics, 2023, 24(1): 369-391. DOI:10.1146/annurev-genom-101322-113255.
[4] QUINN P. Research under the GDPR – a level playing field for public and private sector research?[J/OL]. Life Sciences, Society and Policy, 2021, 17(1): 4. DOI:10.1186/s40504-021-00111-z.
[5] STAUNTON C, SLOKENBERGA S, MASCALZONI D. The GDPR and the research exemption: Considerations on the necessary safeguards for research biobanks[J]. European Journal of Human Genetics, 2019, 27(8): 1159-1167. DOI:10.1038/s41431- 019-0386-5.
[6] National Research Council. Improving Access to and Confidentiality of Research Data: Report of a Workshop[M/OL]. Washington, DC: The National Academies Press,2000. https://doi.org/10.17226/9958.
[7] 胡良霖,朱艷華. 科學數據倫理關鍵問題研究[J]. 中國科技資源導刊, 2022(1): 11-20.
[8] 溫亮明,張麗麗,黎建輝.大數據時代科學數據共享倫理問題研究[J]. 情報資料工作, 2019, 40(2): 38-44.
[9] 廖方宇,李婧. 開放科學背景下科學數據開放共享安全挑戰及我國對策思考[J/OL]. 農業大數據學報, 2024, 6(2): 146-155. DOI:10. 19788/j.issn.2096-6369.000027.
[10] 嚴煒煒,謝順欣,潘靜,等. 數據分類分級:研究趨勢、政策標準與實踐進展[J]. 數字圖書館論壇, 2022(9): 2-12.
[11] 袁康,鄢浩宇.數據分類分級保護的邏輯厘定與制度構建——以重要數據識別和管控為中心[J]. 中國科技論壇, 2022(7): 167-177.
[12] 張敏,魏偉,譚天怡,等. 數據分類分級及其發展路徑研究[J]. 網絡安全與數據治理, 2022, 41(7): 18-22+29.
[13] 陳兵,郭光坤. 數據分類分級制度的定位與定則——以《數據安全法》為中心的展開[J]. 中國特色社會主義研究, 2022(3): 50-60.
[14] 陳燁,王陽,徐亞蘭,等. 電子健康檔案數據分類分級研究[J]. 檔案學研究, 2024(3): 119-128.
[15] 王暢,曾亞. 煙草行業數據的分類分級及安全防護方法探討[J]. 內蒙古科技與經濟, 2020(1): 31-32+57.
[16] 高磊,趙章界,林野麗,等. 基于《數據安全法》的數據分類分級方法研究[J]. 信息安全研究, 2021,7(10):933-940.
[17] 朱艷華,廖方宇,胡良霖,等. 科學數據安全標準規范關鍵問題探索[J]. 信息網絡安全, 2021, 21(11): 1-8.
[18] 廖方宇,胡良霖,王健,等. 科學數據安全標準研究與工作建議[J]. 科學通報, 2024, 69(9): 1142-1148.
[19] 許琦,胡曉彥,鄒自明,等. 空間環境科學數據安全分級概念框架研究[J]. 農業大數據學報,2024, 6(2): 259-268.
[20] 王佳榮,周彩秋,苑新陽,等. 國家高能物理科學數據安全保障體系[J]. 農業大數據學報,2024,6(2): 269-277.
[21] 張耀南,張名成,康建芳. 科學數據中心安全工作實踐——以國家冰川凍土沙漠科學數據中心為例[J]. 農業大數據學報,2024,6(2): 278-285.
[22] 關健. 醫學科學數據共享與使用的倫理要求和管理規范(五)隱私分類分級的初步建議及其依據的確認[J]. 中國醫學倫理學, 2020, 33(8): 915-920.
[23] 智峰,田鋒,趙若凡. 計量科學大數據分級分類[J]. 大數據, 2022, 8(1): 60-72.
[24] CHRISTINE L. BORGMAN. Big Data, Little Data, No Data: Scholarship in the Networked World[M/OL]. The MIT Press, 2015. https://doi.org/10.7551/mitpress/9963.001.0001.
[25] WILKINSON M D, DUMONTIER M, AALBERSBERG I J, et al. The FAIR Guiding Principles for scientific data management and stewardship[J]. Scientific Data, 2016, 3(1): 160018. DOI:10.1038/ sdata.2016.18.
[26] TENOPIR C, ALLARD S, DOUGLASS K, et al. Data Sharing by Scientists: Practices and Perceptions[J]. PLOS ONE, 2011, 6(6): 1-21. DOI:10.1371/journal.pone.0021101.
[27] PIWOWAR H A, VISION T J, WHITLOCK M C. Data archiving is a good investment[J]. Nature, 2011, 473(7347): 285-285. DOI:10. 1038/473285a.
[28] OECD. OECD Principles and Guidelines for Access to Research Data from Public Funding[M/OL]. OECD, 2007[2024-08-28]. https://www. oecd-ilibrary.org/science-and-technology/oecd-principles-and-guidelines-for-access-to-research-data-from-public-funding_9789264034020-en-fr. DOI:10.1787/9789264034020-en-fr.
[29] GARETT R, YOUNG S D. Ethical views on sharing digital data for public health surveillance: Analysis of survey data among patients[J/OL]. Frontiers in Big Data, 2022, 5: 871236. DOI:10.3389/ fdata.2022.871236.
[30] Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance)[A/OL]//Official Journal of the European Union, 2016. http://data.europa.eu/eli/reg/2016/679/oj/eng.
[31] Secretariat of the Convention on International Trade in Endangered Species of Wild Fauna and Flora (CITES). Notification to the Parties No. 2016/007[EB/OL]. https://cites.org/sites/default/files/notif/E- Notif-2016-057.pdf.
[32] RESNIK D B. The Ethics of Research with Human Subjects: Protecting People, Advancing Science, Promoting Trust[M/OL]. Springer International Publishing, 2018. http://link.springer.com/ 10.1007/978-3-319-68756-8.
[33] The World Medical Association. WMA Declaration of Helsinki-Ethical Principles for Medical Research Involving Human Subjects[EB/OL]. 2018. https://www.wma.net/policies-post/wma- declaration-of-helsinki-ethical-principles-for-medical-research-involving-human-subjects/.
[34] EMANUEL E J. What makes clinical research ethical?[J/OL]. JAMA, 2000, 283(20): 2701. DOI:10.1001/jama.283.20.2701.
[35] VARKEY B. Principles of clinical ethics and their application to practice[J]. Medical Principles and Practice, 2021, 30(1): 17-28. DOI:10.1159/000509119.
[36] Sharing publication-related data and materials: responsibilities of authorship in the life sciences[J/OL]. Plant Physiology, 2003, 132(1): 19-24. DOI:10.1104/pp.900068.
[37] STODDEN V, LEISCH F, PENG R D. Implementing Reproducible Research[M/OL]. New York: Chapman and Hall/CRC, 2018. https://www.taylorfrancis.com/books/9781315362762.DOI:10.1201/9781315373461.
[38] BORGMAN C L. The conundrum of sharing research data[J/OL]. Journal of the American Society for Information Science and Technology,2012. https://onlinelibrary.wiley.com/doi/full/10.1002/asi. 22634.
[39] TENOPIR C, TALJA S, HORSTMANN W, et al. Research data services in European Academic Research Libraries[J/OL]. Liber Quarterly, 2017, 27(1): 23-44. DOI:10.18352/lq.10180.
[40] CHARPENTIER A, FLACHAIRE E. Pareto Models for Risk Management// DUFRéNOT G, MATSUKI T. (eds) Recent Econometric Techniques for Macroeconomic and Financial Data. Dynamic Modeling and Econometrics in Economics and Finance, vol 27[M/OL]. Cham: Springer International Publishing, 2021: 355-387. https://doi.org/10.1007/ 978-3-030-54252-8_14.
[41] BORGMAN C L. Scholarship in the Digital Age: Information, Infrastructure, and the Internet[M/OL]. The MIT Press, 2007. https://www.jstor.org/stable/j.ctt5hhbk7.
[42] NIELSEN M. Reinventing Discovery: The New Era of Networked Science[M]. Princeton University Press, 2011.
[43] BEZUIDENHOUT L M, LEONELLI S, KELLY A H, et al. Beyond the digital divide: Towards a situated approach to open data[J]. Science and Public Policy, 2017, 44(4): 464-475. DOI:10.1093/scipol/ scw036.
[44] KOLIVAND H, ASADIANFAM S, AKINTOYE K A, et al. Finger vein recognition techniques: a comprehensive review[J]. Multimedia Tools and Applications, 2023, 82(22): 33541-33575. DOI:10.1007/ s11042-023-14463-5.
[45] ABBAS S N, ABO-ZAHHAD M, AHMED S M, et al. Heart-ID: human identity recognition using heart sounds based on modifying mel-frequency cepstral features[J]. IET Biometrics, 2016, 5(4): 284-296. DOI:10.1049/iet-bmt.2015.0033.
[46] DU Y, XU Y, WANG X, et al. EEG temporal–spatial transformer for person identification[J/OL]. Scientific Reports, 2022, 12(1): 14378. DOI:10.1038/s41598-022-18502-3.
[47] BORGMAN C L. The conundrum of sharing research data[J/OL]. Journal of the American Society for Information Science and Technology,2012,63(6):1059-1078. https://doi.org/10.1002/asi. 22634.
[48] CAI P, CHEN L. Demystifying data law in China: A unified regime of tomorrow[J]. International Data Privacy Law, 2022, 12(2): 75-92. DOI:10.1093/idpl/ipac004.
[49] 數據安全技術 數據分類分級規則: GB/T 43697-2024[S]. 2024.
[50] RITCHIE F. Five Safes: designing data access for research[M/OL]. 2016. DOI:10.13140/RG.2.1.3661.1604.
[51] 夏義堃,管茜. 科學研究的數據生態及其模式演進研究[J].科學學研究,2024,42(4): 673-682.
[52] 尹海清, 王永偉, 張曉彤, 等. 材料基因工程數據生態系統[J]. 中國材料進展, 2023, 42(02): 135-143.
[53] 信息安全技術 數據安全能力成熟度模型: GB/T 37988-2019[S]. 2015.
[54] 賀欣然. 公共數據開放共享法律問題研究[J/OL]. 爭議解決,2023, 9(6): 3269-3276. DOI:10.12677/ DS.2023.96446.
[55] 程雁雷,張林軒,張旭. 公共數據開放的邏輯意蘊:現狀考察、問題檢視與法治進路[J]. 科技情報研究, 2024,6(3): 26-40.
[56] 李宜展,董璐,王東瑤,等. 國際科技組織與國際科技合作計劃中的科學數據安全治理[J]. 農業大數據學報, 2024, 6(2): 161-169. DOI:10.19788/ j.issn.2096-6369.000031.
引用格式:王健,周國民,張建華,許哲平,劉婷婷. 科學數據分類分級保護探索:框架與模式[J].農業大數據學報,2024,6(3): 307-324. DOI:10.19788/j.issn. 2096-6369.000069.
CITATION: WANG Jian, ZHOU GuoMin, ZHANG JianHua, XU ZhePing, LIU TingTing. Navigating the Distinctiveness of Research Data Protection: Framework and Mode[J]. Journal of Agricultural Big Data,2024,6(3): 307-324. DOI:10.19788/j.issn.2096-6369.000069.
Navigating the Distinctiveness of Research Data Protection: Framework and Mode
WANG Jian1,3,4, ZHOU GuoMin2,3,4, ZHANG JianHua1,3,4*, XU ZhePing5,6, LIU TingTing1,3
1. Agricultural Information Institute of Chinese Academy of Agricultural Sciences, Beijing 100081, China; 2. Nanjing Institute of Agricultural Mechanization, Ministry of Agriculture and Rural Affairs,Nanjing 210014, China; 3. National Agricultural Scientific Data Center, Beijing 100081, China; 4. Hainan National Breeding and Multiplication Institute at Sanya, Chinese Academy of Agricultural Sciences, Sanya 572024, Hainan, China; 5. National Sciences Library of Chinese Academy of Science, Beijing 100190, China; 6. School of Economics and Management, University of Chinese Academy of Sciences, Beijing 100190, China
Abstract:In recent years, increasing data security regulations have posed significant compliance challenges for scientific data management. Data classification and grading for protection has become a focal point for academia, practitioners, and regulatory bodies. However, existing research mostly focuses on compliance interpretation and reactive measures, lacking a systematic theoretical analysis of scientific data protection. This gap limits the development of frameworks and models in the field. To address this, based on an extensive survey of current practices, this paper identifies six key security characteristics of scientific data: multi-regulation, strict ethical regulation, disciplinary differences, Pareto distribution of \"scale-risk,\" public interest, and dynamic sensitivity. It proposes a classification and grading framework, along with three protection models: comprehensive, balanced, and streamlined. Additionally, the paper introduces a \"compliance-cost-benefit\" triangle to explain the trade-offs among these factors. The proposed framework clarifies the complexity of classifying scientific data, distinguishing between data classification and grading, and offering insights into their interaction. This theoretical model provides valuable reference for future research and practical tools for addressing challenges in scientific data security management.
Keywords: scientific data; data security; data protection; data classification; data grading; data ethic
