變電站故障診斷的聯合優化算法及其性能評估
2024-12-19 00:00:00潘科
中國新技術新產品 2024年23期


摘 要:本文提出一種進行變電站故障診斷的聯合優化算法,并對其性能進行評估。對數據進行處理,選擇故障診斷模型,設計聯合優化算法,構建完整的研究框架。針對性能測試,本文選用某變電站歷史故障數據作為測試集,比較支持向量機(Support Vector Machine,SVM)、隨機森林模型以及聯合優化算法的準確率。單獨使用SVM和隨機森林模型的準確率分別為 89.5%和91.2%,采用聯合優化算法后準確率為94.3%。與傳統單一模型相比,使用本文方法準確率更高,盡管使用聯合模型和迭代優化使計算復雜度增加,但是在實際應用中其計算復雜度仍然在可以接受的范圍內。
關鍵詞:變電站;故障診斷;聯合優化;性能評估
中圖分類號:TM 63 " " " " " " " 文獻標志碼:A
傳統的故障診斷方法主要依賴于人工經驗和定性分析,隨著現代技術的發展,在故障診斷中,數據驅動方法發揮重要作用。董文康等[1]利用深度強化學習構建了設備維護和備件訂購的聯合決策模型,并在實際風電場中驗證了其優越性。楊曉梅等[2]提出基于可變需求的批量化生產和視情維修的聯合策略,采用更新報酬理論構建了聯合決策模型。劉勤明等[3]研究在多產品情況下設備生產與維修計劃的優化,提出碳排放生產計劃與維修決策的聯合決策模型。沈斌等[4]針對預防性維修問題提出參考役齡進行預防性維修與設定緩沖區庫存的聯合決策模型。葉鴻慶等[5]研究在雙供應商情況下的設備維護與備件訂購聯合決策模型。郭羽含等[6]提出使用產能和庫存進行約束,針對周期性批量生產和非周期性維護計劃的聯合決策模型。陳洪根等[7]研究基于可用度的預防維修和均值控制圖的聯合決策模型。成克強等[8]分析了基于質量約束的生產調度和設備維護的聯合決策模型。本文提出一種基于聯合優化算法的變電站故障診斷方法,并對其性能進行評估。
1 算法設計
1.1 數據獲取與預處理
各種內部和外部因素導致變電站在運行過程中會出現設備老化、連接失常等故障。故障診斷的目標是及時發現和定位故障,以采取有效措施防止故障擴大化、嚴重化,保證設備正常運行。在變電站故障診斷中,數據的質量直接影響診斷的準確性。設置閾值,超過閾值的數據作為異常值進行處理,采用最小-最大縮放或Z-score標準化方法將不同量綱的數據轉換為同一個尺度,以避免某些特征對模型訓練的過大影響。
1.2 隨機森林算法
變電站故障的主要判定指標是其相應的故障信息,使用隨機森林模型可以進一步確認潛在的異常模式或者異常點。構建隨機森林模型的基本組件是決策樹,構建隨機森林的具體過程即持續構建連續多個決策樹。假設有某個包括一定信息的樣本點,如公式(1)所示。
A=[xi,yi] " " " " " (1)
式中:A為訓練樣本數據集;xi為樣本點i的輸入變量,即在特定監測點內環境電流、電壓、溫度、濕度和設備狀態等一系列常見監測數據的合集;yi為樣本點i的標簽。
A、xi能夠與識別后的分類標簽yi相關聯,這些指標可以是連續變量或非連續變量。其標簽如公式(2)所示。
i=1,2,...,k " " " " "(2)
式中:k為類別數量。
隨機森林模型能夠有效地對數據進行分類,在數據點劃分為正常和異常狀態的過程中起到重要的作用。利用隨機森林模型能夠建立一個復雜的決策邊界,以區分正常運行和潛在故障狀態。在劃分屬性的過程中,算法會遍歷當前所有剩余特征屬性并計算分類結果,構建最小Gini指數以確定劃分標準和結果。 Gini 指數計算過程如公式(3)所示。
(3)
式中:Gini(t)為基尼不純度,即1與ck平方和的差值,反映劃分節點后的子節點集合不確定性;的作用是描述分類標準的確定性;t為指定類別;ck為具有k個類型的數據集中屬于t的樣本所占的比例。
基于決策樹構建隨機森林模型,在進行裝袋操作的過程中使用總訓練樣本2/3容量的子集作為訓練樣本,以避免過擬合。拆分后樣本的Gini指數計算過程如公式(4)所示。
(4)
式中:G(X,t)、Gini(XL)和Gini(XR)分別為A、左側分支XL和右側分支XR的Gini指數;X為一種特定的分類方式,基于t將A分為左右2個分支即|XL|、|XR| ;|X| 、|XL| 和|XR| 分別為A、XL和XR的樣本數量。
由于裝袋算法重復進行多次試驗,不同子集以及未被選中樣本之間進行交叉驗證,進一步檢驗了構建決策樹的準確度,避免其他交叉驗證手段可能帶來的問題。因此,隨機森林模型可以測量每個特征對模型預測準確性的貢獻來評估特征的重要性。在變電站數據中,可以確定哪些傳感器數據是故障診斷的關鍵數據,優先使用這些特征進行進一步分析并監測。
1.3 支持向量機算法
在變電站數據中,使用支持向量機(Support Vector Machine,SVM)來區分正常運行狀態和可能的故障狀態,使工程師能夠快速、準確地進行故障診斷。
根據公式(1)討論大量樣本點散落于平面空間中,其分割直線如公式(5)所示。
(w?x)+b=0 " " "(5)
式中:w為給定分類直線的法方向;x為函數橫坐標值,其作用是描述直線特征;b為偏置項,決定分類直線與原點的距離。
SVM能夠在高維特征空間中構建最優超平面,將數據點分為不同的類別,即轉化為對這個直線參數的優化問題,如公式(6)所示。
(6)
采用凸優化方法,其對偶形式如公式(7)所示。
ai≥0,i=1,2,...,l " (7)
式中:l為樣本點的總數;i、j為任意樣本點;yj為樣本點j的標簽;ai為樣本點i的拉格朗日乘子;aj為樣本點j的拉格朗日乘子;xj為樣本點j的輸入變量。
在處理線性和非線性數據方面,SVM的泛化能力良好,其能夠應用于不規則的故障模式中并解決復雜的數據分步問題,在實際應用中更加可靠、穩健。
為了提高故障診斷的準確性,本文提出了一種基于SVM和隨機森林模型的聯合優化算法。使用訓練數據分別訓練SVM和隨機森林模型來得到初始模型。對2種模型的輸出結果進行加權融合,并進行交叉驗證來確定權重。采用迭代方法不斷調整模型的參數和權重,使融合模型的診斷準確性更高。聯合優化算法能夠綜合利用SVM和隨機森林模型的優勢,提高故障診斷的準確性和穩定性。
2 性能測試
2.1 數據集獲取
為了驗證本文算法的有效性,選擇某變電站的歷史故障數據作為測試數據集。數據集包括多種類型的故障信息,例如線路故障、設備故障和通信故障等,輸入數據使用其環境電流與電壓作為關鍵變量,輸出數據為故障類別。樣本共有10 000條記錄,隨機抽取70%作為訓練樣本,30%作為測試樣本。
一方面,利用已經確定好的重要特征構建多決策樹,在每個決策樹中進行獨立預測,匯總結果,完成異常值檢測以及分類任務。使用訓練樣本構建測試模型,如公式(8)所示。
D=[xi,yi] " " " " " " "(8)
式中:D為訓練數據集。
利用隨機抽樣的子集構建決策樹,T棵決策樹組成隨機森林,對每棵樹t來說,其輸出yi是基于xi的獨立預測結果,根據公式(3)、公式(4),當每次迭代生成新樹時,利用抽樣技術來增加多樣性,并阻止過擬合現象發生,提高整體泛化能力以及診斷準確率,最終利用投票后平均結果獲得整體預測結果yiRF。
另一方面,使用SVM單獨建立1個支持向量機模型,利用公式(8)中的訓練集以及核函數 K(xi,yi)對輸入特征xi進行非線性映射,根據公式(5)~公式(7)構建分類超平面,并在其中添加選擇好的環境因素作為輸入屬性,獲得預測結果 yiSVM。
分別使用SVM、隨機森林模型并采用聯合優化算法區分不同類型的故障,調整核函數和超參數來提高模型性能。聯合優化算法能夠優化支持向量機和隨機森林模型,提高故障診斷準確率。利用加權融合不同算法的輸出結果得到yi=αyiRF+(1-α)yiRF,其中α是權重參數。以上步驟結合SVM、隨機森林和聯合優化算法,當處理該問題時能夠更全面、深入地研究系統狀態下的算法性能。使用測試樣本對模型進行驗證,并評估其準確性、精確度以及其他指標。根據結果調整參數以提高預測效果。
2.2 獨立優化算法
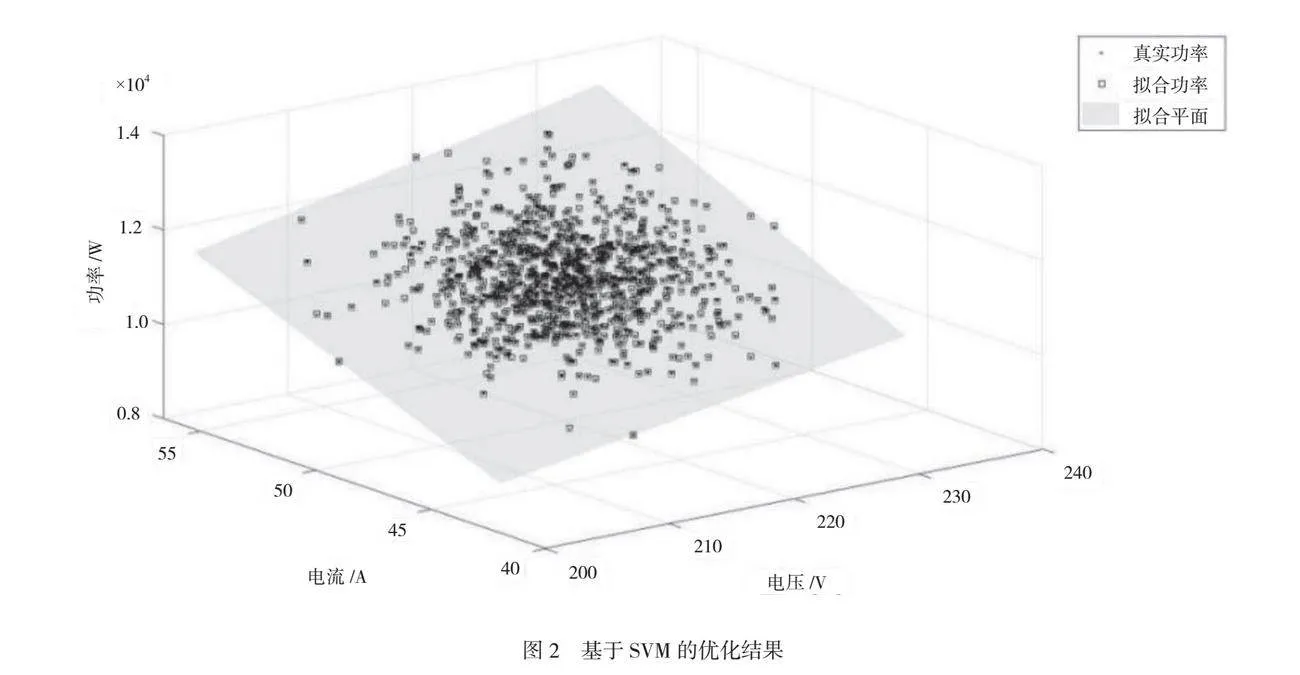
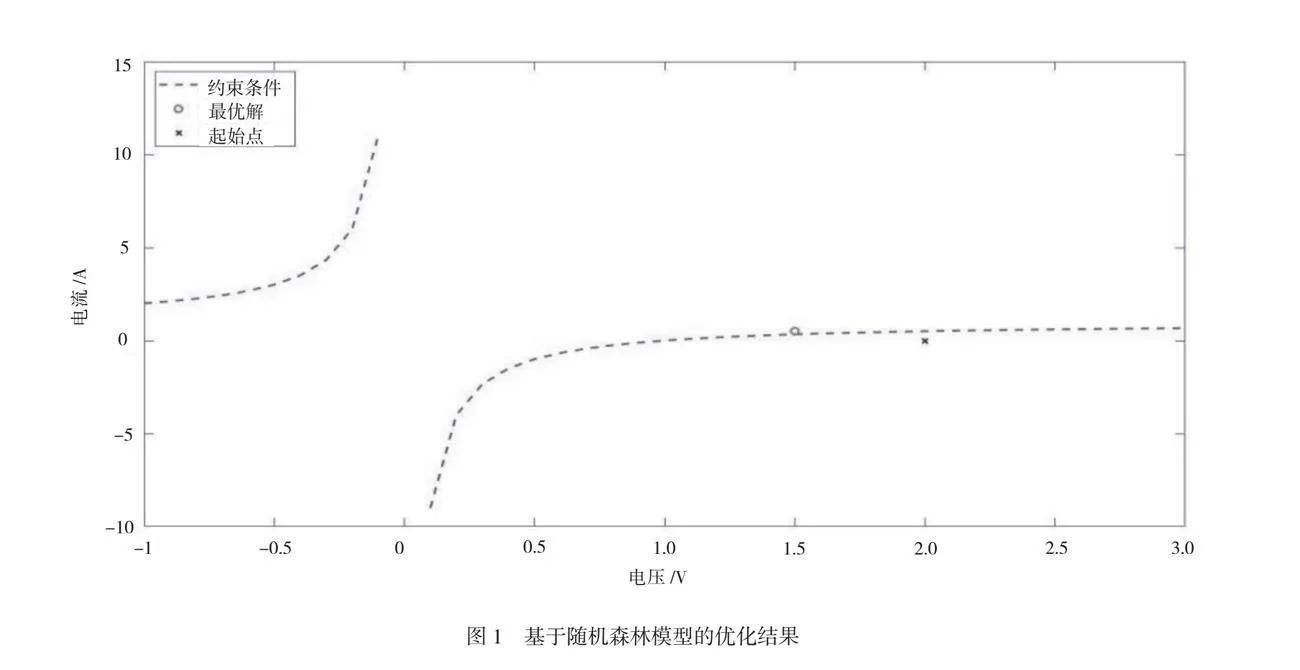
基于隨機森林模型的優化結果(如圖1所示)得到了系統內的約束條件分析結果。結果表明,電流和電壓水平對系統的約束條件影響較小,在低電流或高電壓的情況下,系統仍然能夠保持正常的設備運行狀態。只有當電壓偏差稍微增大(例如超過2 V),負向電流為1 A時,系統才可能出現故障。當電流偏差超過0.3 A時,如果負向電壓偏差超過1 V,那么其也可能是故障的征兆。故障的主要特征是電流異常增大,當超過1.5 A時,表明系統可能出現故障。基于SVM的優化結果(如圖2所示)得到與隨機森林模型相似的結果。在3個參數參與構成輸入數據的條件下,SVM模型能夠有效區分故障與非故障狀態,具體來說,SVM的分類平面可以識別異常的高水平電流和電壓,這類異常值通常隨著功率大幅度衰減,為故障定位提供有力的參考。
2.3 聯合優化算法
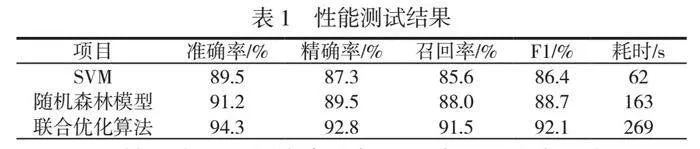
基于此,本文利用對比試驗分別評估了使用SVM、隨機森林模型以及運用聯合優化算法在故障診斷中的性能,測試結果見表1。
測試結果表明,在故障診斷的準確性和穩定性方面,運用聯合優化算法優勢明顯。對SVM和隨機森林模型分別進行初始訓練,再進行加權融合,利用迭代優化調整參數和權重,最終得到高效的故障診斷模型。在測試中,聯合優化算法的準確率為98.7%,明顯高于單一模型,SVM的準確率為92.4%,隨機森林模型的準確率為95.1%。
進一步分析表明,聯合優化算法能夠綜合SVM和隨機森林模型的優點。在處理高維數據、處于小樣本情況的過程中,SVM表現優秀,在解決非線性問題和防止過擬合方面,隨機森林模型有優勢。利用加權融合和迭代優化,在不同條件下,運用聯合優化算法的診斷準確性和穩定性都很高。特別是在復雜故障場景中,聯合優化算法能夠更準確地識別和分類故障類型,魯棒性較強。在數據量較大的情況下,使用聯合優化算法能夠在合理時間內完成故障診斷,計算效率和實時性很高,滿足變電站實時監控和故障預警的要求。
3 結語
本文提出了一種基于聯合優化算法的變電站故障診斷方法,并對其性能進行評估。試驗結果表明,聯合優化算法能夠有效提高故障診斷的準確性和穩定性。
參考文獻
[1]董文康,吳雨芯,姚琦,等.基于深度強化學習的海上風電機組狀態維護與備件庫存聯合優化[J].太陽能學報,2023,44(12):190-199.
[2]楊曉梅,白鈺.基于可變需求的EPQ與視情維修聯合優化[J].工業工程,2023,26(6):138-146.
[3]劉勤明,彭舒悅,王雨婷,等.考慮碳排放的多產品下設備維修計劃與生產計劃聯合優化研究[J].機械設計,2023,40(1):47-55.
[4]沈斌,李芳,呂文元.考慮役齡的預防性維修計劃與緩沖區庫存聯合優化決策[J].工業工程,2022,25(4):91-99.
[5]葉鴻慶,蘇華德,鄭美妹,等.考慮雙供應商的維護和備件訂購聯合決策優化[J].上海交通大學學報,2022,56(10):1359-1367.
[6]郭羽含,馮玥,劉萬軍,等.有限產能和庫存的生產批量與雙模式維護聯合優化[J].計算機集成制造系統,2022,28(9):2894-2908.
[7]陳洪根,李詩宇,閆鑫,等.基于可用度的預防維修和均值控制圖聯合優化模型[J].現代制造工程,2022(2):1-9,51.
[8]成克強,戴青云,王美林.基于質量約束的生產調度與設備維護聯合優化模型分析[J].制造業自動化,2022,44(1):160-163,190.
猜你喜歡
裝備制造技術(2020年3期)2020-12-25 05:22:30
電子制作(2018年8期)2018-06-26 06:43:34
電子制作(2017年8期)2017-06-05 09:36:15
北京航空航天大學學報(2016年6期)2016-11-16 01:50:43
現代工業經濟和信息化(2016年5期)2016-05-17 05:35:57
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
河南電力(2015年5期)2015-06-08 06:01:45
水電站機電技術(2014年1期)2014-09-26 11:59:53
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
