智能駕駛中的關鍵點檢測技術
2024-12-20 00:00:00呂纖纖
專用汽車 2024年12期




摘要:智能交通系統和智能駕駛技術的快速發展對車輛姿態信息及三維屬性的獲取提出了新的要求。探討了兩種主流的多目標關鍵點檢測方法,即基于自頂向下和自底向上方法,并分析了兩者在精度和速度方面的表現。然后搭建了一種基于自頂向下的、使用Heatmap+Offsets方法的卷積神經網絡車輛關鍵點檢測模型,該模型具有很高的平均精度,且誤差較小,在處理角度信息時也具有較高的精確度。
關鍵詞:智能駕駛;關鍵點檢測;姿態估計;車輪關鍵點;深度學習
中圖分類號:U467.4 收稿日期:2024-10-18
DOI:10.19999/j.cnki.1004-0226.2024.12.026
1 前言
智慧交通和智能駕駛有良好的應用前景,成為近年來的研究熱點,其中,機器視覺在智能駕駛研發中發揮著重要作用,主要包括場景識別、動靜態目標檢測、軌跡預測等。機器視覺顧名思義是通過機器來模擬生物視覺,代替人眼實現對目標的分類、識別、跟蹤等。但隨著智駕技術的發展,機器視覺感知的需求也逐步擴大,在智能感知系統中,準確獲取動態目標的三維屬性及姿態信息對于提高交通效率和安全性至關重要。
通常,目標檢測算法只能輸出當前圖像中車輛目標的外接2D矩形框、置信度和類別信息,但是無法獲取到其朝向和姿態信息,如圖1所示。但當智駕感知有更高的要求時,就希望不僅要識別出目標,還要獲悉其姿態和三維信息,以便下游做出進一步的判斷。
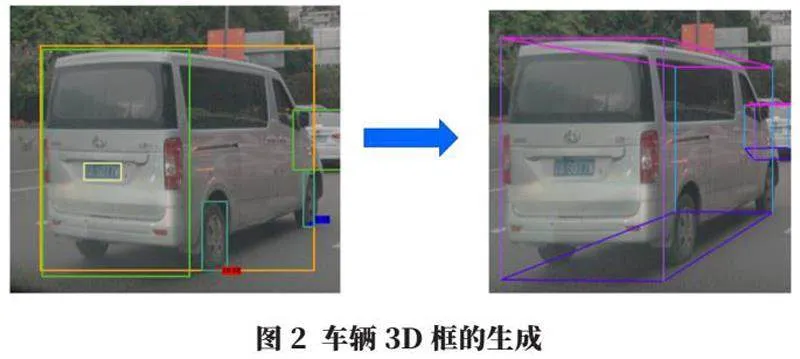
目前的3D檢測技術依賴高精度的激光雷達獲取真值信息,但由于其成本高昂,限制了其應用普及。另一個思路是通過單目攝像頭獲取圖像,通過檢測圖像中每輛車近側前后車輪接地點(車輪與地面相切的切點),再結合全車框、車尾框,生成車輛3D框,從而比較準確地獲得車輛當前的朝向和姿態信息,如圖2所示。因此關鍵點檢測技術是一個生成3D框和獲取目標姿態的折中方法。另外智駕系統中也經常檢測騎車人關鍵點,用于提供騎車人的姿態以及測距測速信息,圖3分別展示了車輪角點和騎車人角點,其中序號1表示前輪,序號0表示后輪。
2 關鍵點檢測技術
關鍵點本質上就是在圖像中用一個點表示物體上特定的部位,它不僅是一個點信息或代表一個位置,更代表著上下文與周圍鄰域的組合關系。常見的關鍵點有車輛關鍵點、人體關鍵點和人臉關鍵點等,車輛關鍵點一般用于車輛模型建模、智能駕駛領域等[1];人體關鍵點可以應用于分析人體的行為動作,還可以應用于VR、AR等[2];人臉關鍵點則應用于涉及人臉識別的相關應用[3]。
關鍵點檢測技術按照問題場景,可分為“單目標關鍵點檢測”和“多目標關鍵點檢測”[4]。在“單目標關鍵點檢測”中,其研究關鍵在于如何設計關鍵點檢測算法或模型結構,從而實現準確的關鍵點檢測。而在“多目標關鍵點檢測”中,研究重點不再是具體的關鍵點檢測,而是如何對檢測的關鍵點進行實例化分組,該領域由此也分為基于自頂向下和自底向上的兩種解決范式,下面分別介紹這兩種方法及優缺點。
2.1 基于自頂向下的多目標關鍵點檢測方法
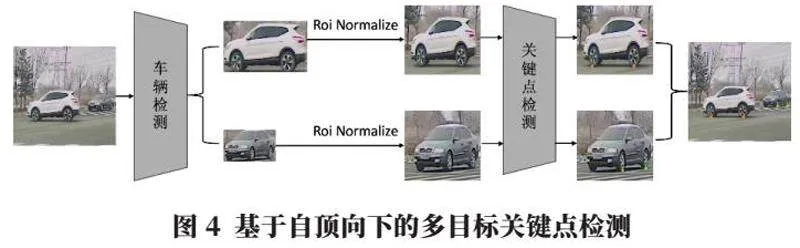
在多目標關鍵點檢測任務中,最自然想到的做法就是先檢測出圖中所有目標,然后再將目標2D框摳出來,對每一個2D框候選區域內進行關鍵點檢測,這就是自頂向下的方法,即通過先進行全圖目標檢測,而后進行單目標關鍵點檢測的兩階段網絡,將多目標任務轉換為單目標任務。
該方法如圖4所示,其中包含“車輛檢測”和“關鍵點檢測”兩個不同的卷積神經網絡,前者對車輛目標進行檢測提取并將其裁剪成單個車輛目標候選框,之后再通過Roi Normalize方法進行外擴一定區域,包含背景信息,且歸一化到相同尺寸下,作為后面“關鍵點檢測”網絡的輸入,通過兩步走實現了多目標關鍵點檢測。
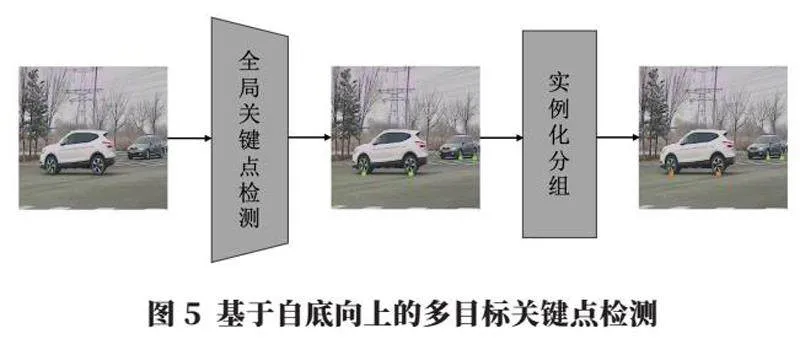
2.2 基于自底向上的多目標關鍵點檢測方法
自底向上的方法與自頂向下相反,其網絡設計只有一個網絡,直接對整張圖進行全局關鍵點的檢測。對于圖像中含有多個目標,存在無法區分哪些點屬于目標A,哪些點屬于目標B的問題,因此還需要在后面接一個實例化分組模塊,利用其他輔助信息和后處理將這些關鍵點按照策略進行實例化分組和匹配。
該方法如圖5所示,其中只有“全局關鍵點檢測”一個卷積神經網絡,進行不限制實例數量的全局關鍵點檢測,另外會輸出額外如分割或實例化編碼等輔助信息,最后通過后處理進行實例化分組。
2.3 兩種方法的優缺點分析
基于自頂向下和自底向上的兩種方法,雖然各有千秋,但總體上可以從精度和速度兩方面闡述它們各自的特點。其中,自頂向下的方法思路直觀,檢測過程易于理解,被大部分人所接受。
由于分兩階段地將多目標場景轉換為單目標問題,同時能夠利用業界先進的通用目標檢測網絡,從而能達到更高的精度和更廣的應用范圍;但相應地,兩階段的流程較為冗余且分階段訓練的成本較大,并且會因為人物數量變多而計算量增大,耗時增加,前序的目標檢測效果將會影響后續的關鍵點檢測。
基于“自底向上”的方法過程比較簡單,其無論目標多少,都只需要對整張圖片進行一次處理,且檢測速度不會隨著目標的增加而明顯降低,但缺點則是會犧牲一些精度。
3 實驗內容及結果分析
本文搭建了一種基于普通攝像頭的車輪關鍵點檢測模型,通過檢測圖像內車近側車輪接地點,進而獲取車輛的姿態信息,為智能駕駛提供了一種成本效益更高的解決方案。
3.1 實驗內容
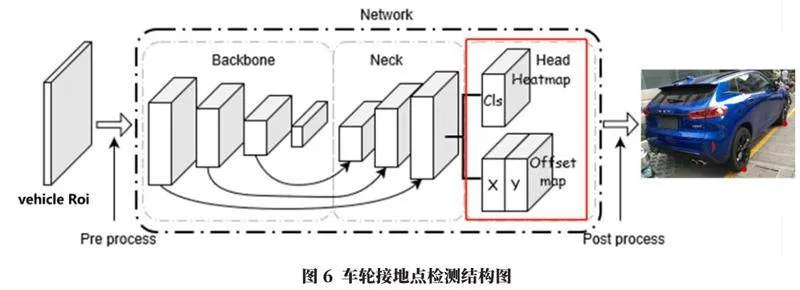
本文基于自頂向下的方法,通過使用Heatmap+Offsets的方式,用卷積神經網絡來實現車輪接地點的檢測。
Heatmap是指將每一類坐標用一個概率圖來表示,對圖片中的每個像素位置都給一個概率,表示該點屬于對應類別關鍵點的概率,距離關鍵點位置越近的像素點的概率越接近1,距離關鍵點越遠的像素點的概率越接近0,具體可以通過函數進行模擬。Heatmap網絡在一定程度上給每一個點都提供了監督信息,網絡能夠較快收斂,同時對每一個像素位置進行預測能夠提高關鍵點的定位精度,典型網絡有hourglass[5]、openpose[6]等。
Heatmap + Offsets的方法與上述Heatmap方法不同的是,這里將距離目標關鍵點一定范圍內所有像素點的概率值都賦為1,另外使用offsets(即偏移量)來表示距離目標關鍵點一定范圍內的像素位置與目標關鍵點之間的關系。
網絡整體結構如圖6所示,流程如下:
a.模型前處理。先通過目標檢測方法預測出車輛2D框的位置,然后外擴一定區域,形成車輛ROI,再對ROI做歸一化處理。
b.label生成。heatmap是一個以關鍵點為中心的圓,半徑r為用戶指定,heatmap上位于該圓上的值為1,其余值為0;offset是圓上當前點指向關鍵點的向量。
c.模型輸出。將處理后的ROI輸入到卷積神經網絡中,經過網絡提取特征,最后輸出heatmap與offset兩個head。heatmap的shape為(n,num_kps,h,w),offset的shape為(n,2*num_kps,h,w),其中n為batch_size;num_kps為角點數量(這里取2);h、w為輸出feature map的尺寸。
d.模型后處理:先找到heatmap輸出的最大值的位置(x,y),并根據這個位置找到offset相對應點處的向量(x_offset,y_offset),預測出最終的輸出點位置(x+x_offset,y+y_offset)。
e.根據label值和預測值,計算損失函數,反向傳播更新模型參數,直至模型收斂。
本文采用的訓練集總共有125 000張圖像,訓練采用迭代訓練策略來優化模型,本文設置總訓練步數為float_steps=13 800步,以確保模型能夠充分學習訓練集的特征;此外,hyqDUABiq767NbxsWN0x7A==為了穩定訓練過程并避免過擬合,使用freeze_bn_steps=7 500步凍結了批量歸一化(Batch Normalization)層的參數,這意味著在訓練的前7 500步中,BN層的參數不會更新,這一策略有助于在訓練初期快速收斂,同時在訓練后期允許模型參數自由調整以捕捉更復雜的信息。
3.2 實驗結果分析
本文采用的評測指標如下:
a.平均精度(AP)。AP是Average Precision的縮寫,這一指標衡量了模型在不同置信度閾值下的平均精度,AP值越高,表示模型的整體性能越好。
b.歸一化誤差(NormError)。該指標通常指的是模型預測值與實際值之間差異的歸一化化誤差,是衡量模型性能的關鍵指標之一。
c.角度誤差(AngleError)。該指標衡量模型在預測角度方面的準確性。
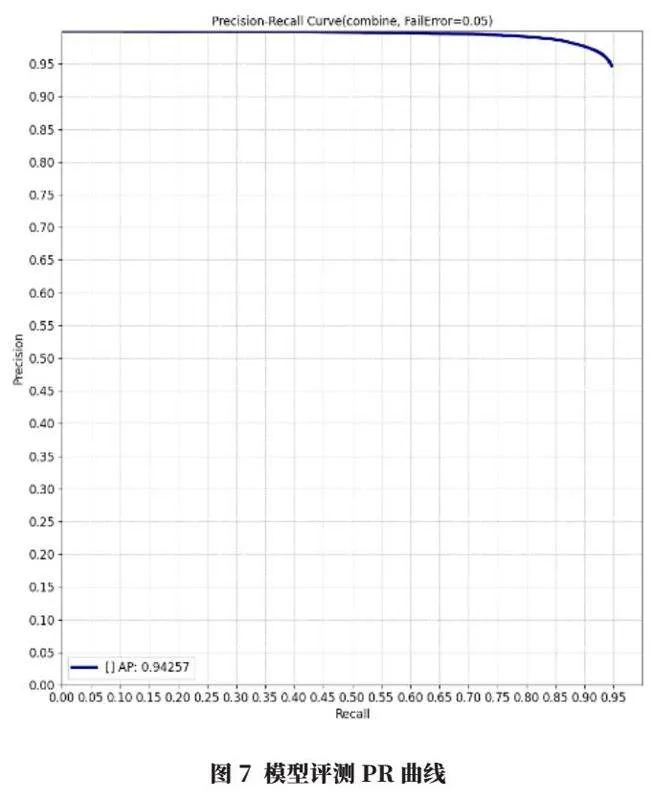
d.PR曲線(Precision-Recall)。該曲線通過繪制不同閾值設置下的精確度(Precision)與召回率(Recall)之間的關系,曲線下的面積能夠量化模型的整體性能,值越高表示模型的性能越好。
訓練完成后,在4 770張圖像評測集上進行評測,評測結果為AP值為0.955,NormError值為0.017,AngleError值為4.75,PR曲線如圖7所示。該評測結果表明模型具有很高的平均精度,且誤差較小,模型在處理角度信息時也具有較高的精確度。
同時為了獲得更直觀的視覺感受,本文選取了一些測試圖像可視化地來分析車輪接地點檢測模型的性能,圖8顯示了該模型在車輛兩點關鍵點上的檢測效果。可以看出,該模型在檢測車輪關鍵點方面效果良好,能夠準確識別車輛目標的同時檢測出車近側車輪前后兩點接地點。
4 未來工作
對于一些復雜場景和corner case,車輪關鍵點檢測方法還是會有一定局限性,可能出現接地點漏檢或位置不準等情況,未來的研究可以集中在解決這些corner case和提高關鍵點檢測的魯棒性。
下面列舉了一些車輪關鍵點檢測的corner case:
a.目標存在遮擋情況造成關鍵點位置不明顯,會導致接地點漏檢、檢測位置不準。
b.對于一些cut-in場景,會導致目標不完整、車輪缺失,可能造成模型腦補的關鍵點預測不準。
c.對于大小車車輛重疊的場景,會導致關鍵點位置檢測不準,如圖9所示。
5 結語
本文搭建了一種基于自頂向下的、使用Heatmap + Offsets方法的車輛關鍵點檢測模型,通過模型評測定量和定性結果可以看出,其具有很高的精度效果,且誤差較小,在處理角度信息時也具有較高的精確度。未來的研究可以集中在解決道路復雜場景和corner case上,需要不斷提高關鍵點檢測算法的魯棒性。
參考文獻:
[1].劉軍,后士浩,張凱,等.基于單目視覺車輛姿態角估計和逆透視變換的車距測量[J].農業工程學報,2018,34(13):70-76.
[2].汪檢兵,李俊.基于OpenPose-slim模型的人體骨骼關鍵點檢測方法[J].計算機應用,2019,39(12):3503-3509.
[3].石高輝,陳曉榮,劉亞茹,等.基于卷積神經網絡的人臉關鍵點檢測算法設計[J].電子測量技術,2019,42(24):125-130.
[4].馬雙雙,王佳,曹少中,等.基于深度學習的二維人體姿態估計算法綜述[J].計算機系統應用,2022,31(10):36-43.
[5].Newell A,Yang K,Deng J.Stacked hourglass networks for human pose estimation[C]//European Conference on Computer Vision. Springer,Cham,2016:483-499.
[6]Cao Zhe,Tomas S,Shih-En W,et al.Realtime multi-person 2D pose estimation using part affinity fields[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2017:130-138.
作者簡介:
呂纖纖,女,1996年生,助理工程師,研究方向為智能駕駛算法。
