復雜裝備全生命周期多源異構數據融合技術研究
2024-12-28 00:00:00曾文驅王淑營
機械制造與自動化 2024年6期
關鍵詞:全生命周期
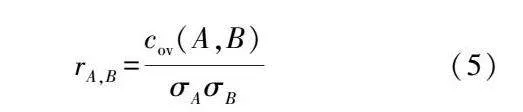




摘要:提出一種融合框架和方法,用于解決復雜裝備全生命周期數據的多源異構性帶來的數據冗余、不一致和索引困難問題。該框架包括自上而下的數據模式融合、自下而上的數據實體模式生成和動態融合全生命周期數據層3個步驟。通過建立頂層數據模式、生成數據實體模式并配置主碼轉換規則和數據對象屬性補全規則,實現全生命周期數據層的動態融合。經工程實踐驗證,該方法能夠有效處理復雜裝備全生命周期數據的多源異構性,優化數據融合過程。
關鍵詞:復雜裝備;全生命周期;融合框架;模式融合;數據融合
中圖分類號:TP391文獻標志碼:A文章編號:1671-5276(2024)06-0107-06
Abstract:A fusion framework and method are proposed in this study to address the challenges of data redundancy, inconsistency, and indexing difficulties caused by the heterogeneity of multi-source data in the entire lifecycle of complex equipment. The framework includes three steps: top-down data schema fusion, bottom-up data entity schema generation, and dynamic fusion of the entire lifecycle data layer. With the establishment of a top-level data schema, generating data entity schemas and configuring rules for primary key transformation and data object attribute completion, the dynamic fusion of the entire lifecycle data layer is achieved. Engineering practices prove that the proposed method is effective in handling the heterogeneity of multi-source data in the entire lifecycle of complex equipment and optimizing the data fusion process.
Keywords:complex equipment; full life cycle; fusion framework; pattern fusion; data fusion
0引言
復雜裝備是指在重要工業、交通、能源、通信等領域應用的具有復雜結構、高度自動化和智能化的裝備,例如高速列車、盾構機、核電裝備等。這類裝備的特點包括:1)包含大量組件和子系統,需要高度集成;2)結構設計和制造要求復雜;3)研發、制造和維護周期長。
復雜裝備涉及眾多物理信息系統,導致多維異構信息難以在系統層面上得到統一表達[1],全生命周期數據關聯映射和閉環反饋是復雜裝備數字孿生的基石[2-3]。目前,裝備數據融合的研究主要集中在多源異構感知數據融合[4-5]方法上,包括基于機器學習[6-7]、深度學習[8-9]的方法等。這些成果為關鍵零部件數字孿生研究奠定了基礎,但缺乏對復雜裝備結構間關聯和履歷數據關聯的分析。
在全生命周期數據融合研究方面,基于本體的數據集成方法[10-12]和知識圖譜的數據集成框架[13]已被提出并應用于復雜裝備領域。這些方法通過描述全局模式和利用本體知識庫來高效地訪問多個數據源中的數據。但這些方法缺乏對復雜裝備的骨架結構特征和基于產品族配置特征的充分融入。
因此,本文針對復雜裝備全生命周期數據的產品結構歸屬和基于產品族配置設計制造特征,提出復雜裝備全生命周期數據集成框架,設計了既有多源異構數據計算的數據實體模式又參照模式自動構建算法,從而實現復雜裝備全生命周期數據的一致性融合。
1復雜裝備全生命周期數據模式融合框架
1.1基于BOM的數據關聯映射方法
1)定義BOM:描述產品組成關系的數據結構,通常使用四元組BOM=(P,C,R,Q)表示。其中:P表示產品族或產品;C表示組件或零部件,是產品或產品族子部分,可包含更低層級的子組件或零部件;R表示組件之間的關聯關系;Q表示組件間的數量關系。
基于BOM的復雜裝備全生命周期數據關聯映射方法:a)定義BOM節點;b)定義BOM節點間關聯關系;c)定義BOM節點與實體、各實體間的關聯關系。
由于數據的完整性和一致性對復雜裝備數字孿生具有重要的意義,因此采用關系模型,通過參照完整性來建立實體間的關聯約束。
2)定義參照完整性約束:設Dx和Dy代表兩類不同對象的數據實體,其間可建立參照完整性約束:
式中:f(Dx,Dy)表示Dx和Dy間的關聯映射函數;Dx×Dy表示Dx和Dy兩個數據集做笛卡兒積運算;σDx.A=Dy.A′表示在Dx數據模式的A屬性和Dy數據模式的A′屬性值相等下的條件選擇運算。在上述映射關系中,Dx稱為參照數據關系實體,Dx.A為Dx的參照屬性;Dy稱為被參照關系實體,Dy.A′為Dy的主屬性集。
1.2全生命周期數據模式融合框架及實施路徑
1)基于GBOM的知識數據模式框架構建
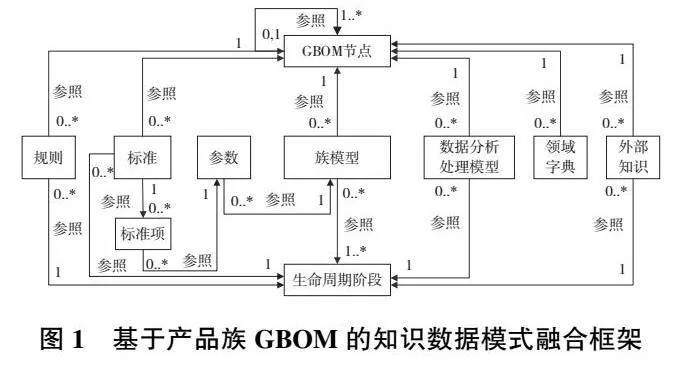
基于產品族的設計制造是一種在多個產品間共享設計和制造資源、知識和經驗的方法,這種方法可以實現產品間的設計和制造的共享及重用,如圖1所示。通過建立GBOM節點間參照、GBOM和專業族庫、設計規則、維護方法、數據驅動的分析處理模型等可重用的知識類實體間的參照完整性映射,實現產品族知識模型和數據的關聯和一致性約束。
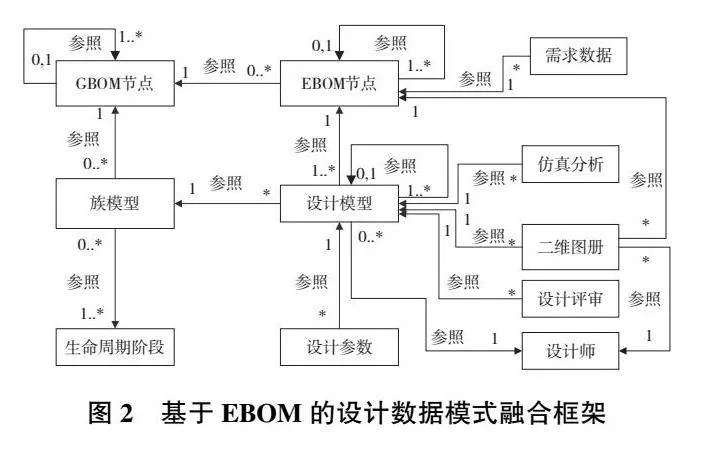
2)基于EBOM的設計數據模式框架構建
設計階段數據模式融合框架如圖2所示。在基于產品族的配置設計過程中,EBOM通常是基于GBOM節點選配實例化自動生成,設計模型和設計參數是在配置設計過程中通過族模型和參數實例化生成,因此要先建立EBOM與GBOM節點、模型及參數間參照完整性約束,其次建立EBOM節點與設計階段零部件模型、二維圖冊、仿真分析、強度分析等數據的映射。
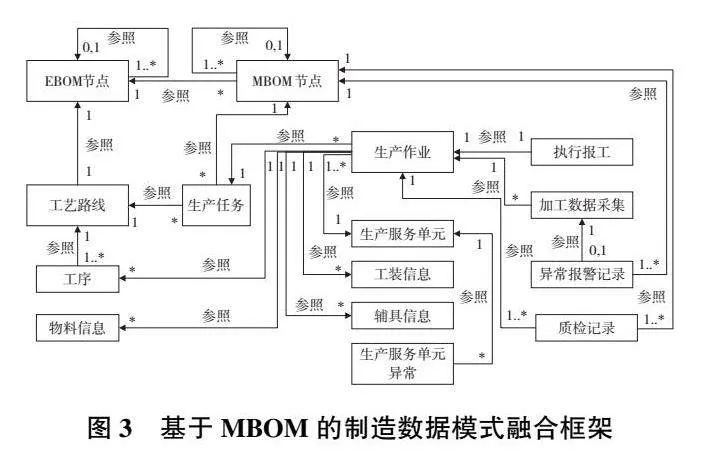
3)基于MBOM的制造數據模式框架構建
制造階段數據模式融合框架如圖3所示。對于EBOM中的自制件需要設計產品工藝和工序,每個自制件按工藝排程生產后會按數量形成多個零部件,基于此可構建EBOM節點與MBOM節點、工藝和生產任務之間的完整性約束;其次制造階段的生產任務、任務排程、生產報工、質檢等數據與EBOM節點的每個零部件相關,從而將制造和設計階段的數據關聯。
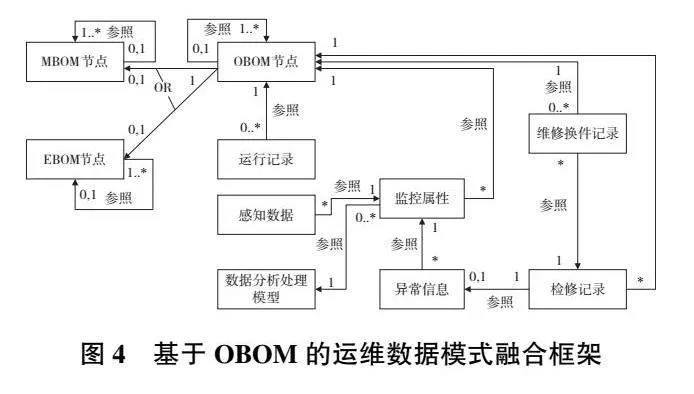
4)基于OBOM的運維數據模式框架構建
OBOM是針對運維階段需求,在MBOM的基礎上,結合某些外購件運維需求而構建的,因此OBOM節點基于MBOM或EBOM實例化生成。基于OBOM的運維數據模式融合框架如圖4所示。建立OBOM節點與運維階段裝機檔案、運維記錄、感知數據、故障報警、維修環境等數據間的關聯映射。
2基于數據計算的實體數據模式補全
2.1多源異構數據冗余屬性識別與約簡方法
不同源系統對同一類數據的同一特征,其屬性命名存在差異,按屬性數據類型分類設計算法如下。
1)標稱屬性約簡
設屬性A和屬性B是來自不同系統Dx1和Dx2的兩個屬性,屬性A有c個值,A(a1,a2,…, ac),屬性B有r個值,B(b1,b2,…,br),則屬性A和屬性B是否描述同一特征做如下計算:
式中:x2為卡方檢測值;oij為觀測頻度;eij為期望頻度。
式中:count(A=ai)表示取ai值的數據樣本個數;count(B=bj)為取值為bj的樣本個數;n為數據樣本總數。對計算出的x2通過卡方表對比,如果相關,則比較屬性A和屬性B的數據類型定義長度,保留數據類型定義長度大的屬性,另一個屬性標記為冗余。
2)數值屬性約簡
設屬性A和屬性B是來自不同系統兩個屬性,通過計算協方差來衡量屬性A和屬性B的相關度,即
式中:ai∈(a1,a2,…,an)為屬性A的n個樣本的值;bi∈(b1,b2,…,bn)為屬性B的n個樣本的值;A-和B-分別為屬性A和屬性B的均值。
由協方差進一步計算屬性A和屬性B的相關系數:
計算結果rA,B與設定的閾值比對,若超過閾值,則比較屬性A和屬性B的數據類型定義長度,保留數據類型定義長度大的屬性,另一個屬性標記為冗余。
2.2基于多源異構數據計算的數據實體屬性自動補全
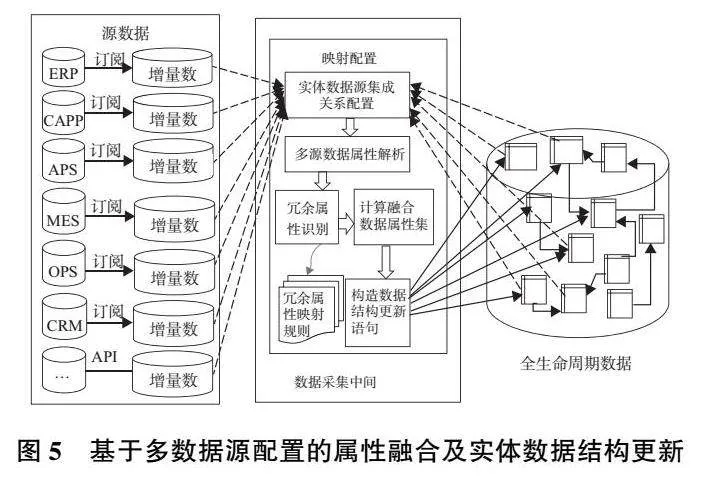
對集成框架中的每一個實體,應用數據采集中間件配置其多源異構數據源,提取數據源中數據的屬性和數據值,按2.1節算法進行冗余屬性的約簡,用約簡后的屬性集更新數據實體模式,實現實體屬性的自動補全。如圖5所示,虛線代表右側數據實體和左側數據源之間的配置,實線代表通過計算的融合屬性集更新實體數據結構,中間部分表示屬性計算融合過程。
3多源異構數據采集及融合存儲
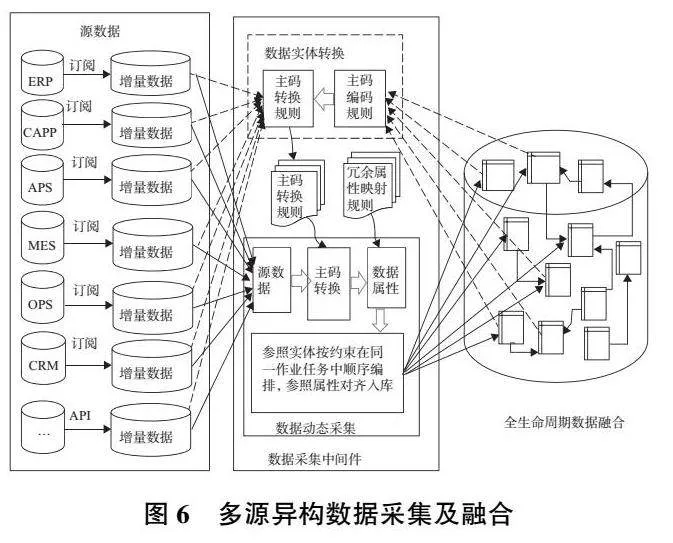
在對數據屬性進行約簡和補全之后,就需要將多源異構數據進行收集和融合,再將對齊后的數據和屬性存儲入庫。該過程如圖6所示,在圖5的基礎上,基于數據集成中間件進一步配置各實體主碼的編碼規則,設置源主碼與目標實體主碼轉換規則,然后配置源數據提取、主碼轉換和數據屬性對齊方法;同時將具有參照關聯的實體在同一作業中進行編排,以解決實體間存在參照完整性約束的問題。在數據集成中間件中設置任務執行策略,可定期將多源異構數據采集、轉換并存儲到具有統一模式的數據倉庫中,為后續復雜裝備數字孿生提供數據支撐。
4實驗驗證與分析
以某高速列車產品數據為例,從全生命周期數據融合框架構建、基于多源異構數據解析計算的數據實體屬性自動補全和基于BOM的全生命周期數據索引3個方面進行案例分析以驗證方法的有效性。
1)全生命周期數據融合框架構建
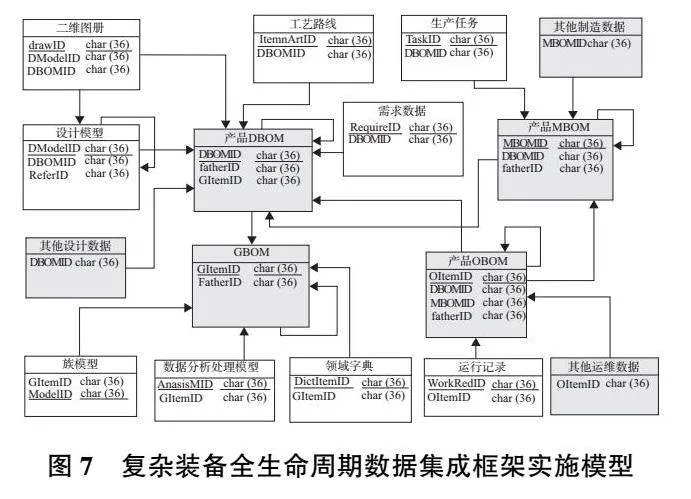
采用1.2節介紹的全生命周期數據融合框架構建方法來構建數據實體及參照模式的頂層框架。本實驗采用PowerDesigner16.5作為框架建模工具,按照圖1—圖4構建全生命周期數據模式,結果如圖7所示。
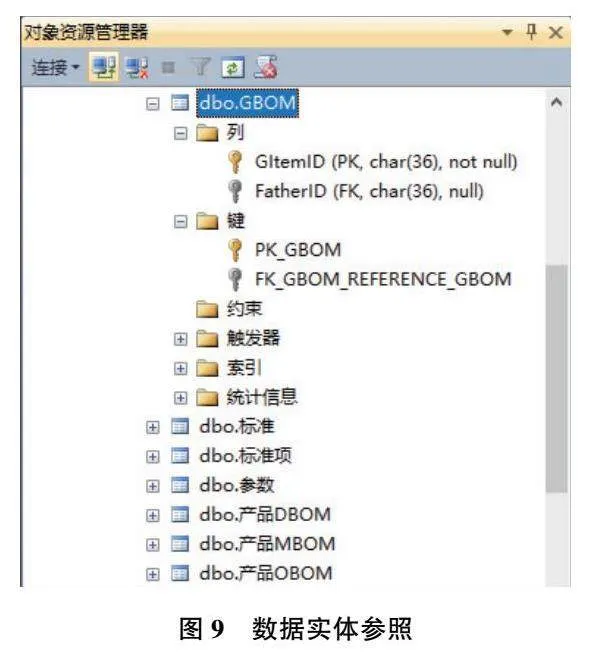
利用PowerDesigner導出工具將框架模型導出為如圖8所示的數據庫SQL文件,并在數據庫管理系統中執行生成如圖9所示的實體骨架結構和參照約束。以圖中展開的GBOM節點為例,其僅包含主碼和外碼兩個屬性。
2)基于數據計算的數據實體屬性自動補全
對圖7中的數據實體按照2.2節的方法配置要融合的數據源。本實驗采用Kettle數據集成中間件,配置完成后一次性執行;采集各數據源數據,解析數據屬性的數據類型,調用算法1,生成數據模式更新的SQL語句,用融合計算的屬性集更新實體數據模式,從而實現補全。
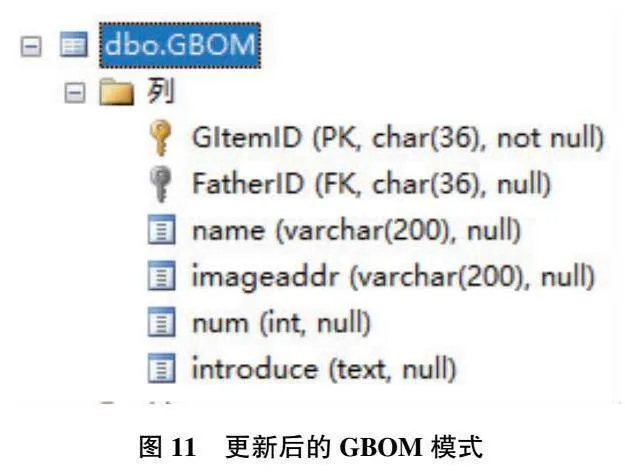
以GBOM為例,對基于多源異構數據解析計算的數據實體屬性自動補全進行案例分析,所用數據來源于知識庫系統和產品設計平臺系統。知識庫系統GBOM模式為:GBOM(id,name,imageaddr,num, introduce,prientid)包含節點編碼、名稱、圖片、數量、簡介和父節點編碼6個屬性,其中非主屬性和非參照屬性有{name,image,num,introduce};產品設計平臺系統GBOM模式為GBOM(code, name),非主屬性和非參照屬性有{name}。將數據輸入算法1,得到GBOM屬性更新表的SQL語句如圖10所示。在數據庫管理系統中執行該SQL語句,得到如圖11所示的更新后的GBOM。
3)基于BOM的全生命周期數據索引
在完成數據模式融合后,按照第3節的方案配置Kettle數據采集任務(定時執行),將多源異構數據集成到統一的數據倉庫。通過數據中臺的可視化界面可查看全生命周期數據。
5結語
復雜裝備全生命周期各個階段產生的數據無法統一表達,會造成信息孤島問題,導致資源浪費和數據共享效率低下。為有效解決這些問題,本文提出了復雜裝備全生命周期多源異構數據融合框架。該模式的主要貢獻在于數據關聯映射和數據融合兩個方面,研究了面向復雜裝備的全生命周期多源異構數據關聯映射方法和數據特征統一建模及數據轉換方法。
參考文獻:
[1] TAO F,CHENG J F,QI Q L,et al. Digital twin-driven product design,manufacturing and service with big data[J]. The International Journal of Advanced Manufacturing Technology,2018,94(9):3563-3576.
[2] CHEN L L,ZHANG Y Y,WANG Z P. Logistics service supply chain model applying artificial intelligence and big data analysis[J]. Security and Communication Networks,2022,2022:1575813.
[3] ZHANG L. Design of a sports culture data fusion system based on a data mining algorithm[J]. Personal and Ubiquitous Computing,2020,24(1):75-86.
[4] DING W X,JING X Y,YAN Z,et al. A survey on data fusion in Internet of Things:towards secure and privacy-preserving fusion[J]. Information Fusion,2019,51(C):129-144.
[5] ALAM F,MEHMOOD R,KATIB I,et al. Data fusion and IoT for smart ubiquitous environments:asurvey[J]. IEEE Access,2017,5:9533-9554.
[6] MENG T,JING X Y,YAN Z,et al. A survey on machine learning for data fusion[J]. Information Fusion,2020,57(c):115-129.
[7] CHEN H P,HU N Q,CHENG Z,et al. A deep convolutional neural network based fusion method of two-directionvibrationsignal data for health state identification of planetarygearboxes[J]. Measurement,2019,146:268-278.
[8] WU J,HU K,CHENG Y W,et al. Data-driven remaining useful life prediction via multiple sensor signals and deep longshort-term memory neural network[J]. ISA Transactions,2020,97:241-250.
[9] 何逸茹,劉晨,楊中國. 面向多源傳感器時間序列的時序依賴關聯挖掘方法[J]. 小型微型計算機系統,2021.42(11):2307-2311.
[10] NIANG C,MARKHOFF B B,SAM Y,et al. A semi-automatic approach for global-schema construction in data integration systems[J]. International Journal of Adaptive,Resilient and Autonomic Systems,2013,4(2):35-53.
[11] 張春,袁天寧. 針對動車組全生命周期集成管理的多源異構數據融合框架設計[J]. 計算機與現代化,2017(10):36-41.
[12] YU Y,SUN L F,WANG S H. Multiparty dynamic data integration scheme of industrial chain collaboration platform in mobile computing environment[J]. Wireless Communications and Mobile Computing,2022,2022:1550668.
[13] KALAYC T E,BRICELJ B,LAH M,et al. A knowledge graph-based data integration framework applied to battery data management[J]. Sustainability,2021,13(3):1583.
收稿日期:20230420
基金項目:國家重點研發計劃項目(2020YFB1708000);四川省重大科技專項 (2022ZDZX0003)
第一作者簡介:曾文驅 (1980—),男,廣東陽春人,博士研究生,研究方向為智能制造、數據孿生,2464882541@qq.com。
DOI:10.19344/j.cnki.issn1671-5276.2024.06.021
猜你喜歡
價值工程(2016年35期)2017-01-23 20:27:52
居業(2016年5期)2017-01-11 23:32:11
中國集體經濟(2017年1期)2017-01-04 08:21:06
科技視界(2016年18期)2016-11-03 23:54:06
中國科技博覽(2016年13期)2016-07-13 02:37:31
科技視界(2016年16期)2016-06-29 20:55:36
現代經濟信息(2016年9期)2016-05-24 15:28:26
中國科技博覽(2016年5期)2016-04-23 16:21:20
中國市場(2016年4期)2016-01-15 10:07:56
