基于跨模態特征融合的RGB-D花椒圖像顯著性檢測
2024-12-28 00:00:00李節孫成龍王逸涵楊前李柏林
機械制造與自動化 2024年6期










摘要:針對現有顯著性檢測模型無法有效地協同花椒枝干彩色圖像和深度圖像特征,建立基于注意力的RGB-D圖像花椒枝干顯著性檢測模型。由兩個單流卷積網絡分別提取彩色和深度圖像特征;設計基于空間和通道注意力機制的跨模態融合模塊,用于融合多尺度的彩色流和深度流特征;研發多尺度監督機制,用于緩解由于采用最近鄰域上采樣的解碼方式導致邊緣預測不準確的問題。實驗結果表明:該方法的平均精確度、平均召回率、綜合評價指標和平均絕對誤差均優于對比顯著性目標檢測方法。
關鍵詞:花椒自動化采摘;圖像處理;RGB-D顯著性目標檢測;跨模態融合;注意力機制;多尺寸監督
中圖分類號:TP391.41文獻標志碼: A文章編號:1671-5276(2024)06-0211-07
Abstract:To address the inability of existing saliency detection models to utilize the features of pepper branch color images and depth images effectively, an attention-based RGB-D image pepper branch saliency detection model is proposed. Color and depth image features are extracted separately by two single-stream convolutional networks. A cross-modal fusion module based on spatial and channel attention mechanisms is designed to fuse multi-scale color stream and depth stream features. A multi-scale supervision mechanism is developed to alleviate the inaccurate edge prediction caused by the use of nearest-neighbor upsampling decoding. Experimental results show that the average accuracy, average recall rate, comprehensive evaluation index and average absolute error of the proposed method are all superior to the compared salient object detection methods.
Keywords:automated pepper harvesting; picture processing; RGB-D significance target detection; cross-mode fusion; attention mechanism; multi-dimension supervision
0引言
花椒是四川省重要經濟作物,提升花椒采摘的自動化水平對于我國西部鄉村振興具有重要意義。得益于近些年來計算機軟硬件的發展,基于視覺的采摘機器人被廣泛地應用于蘋果、柑橘和葡萄的自動化采摘。作為智能采摘機器人[1]的重要組成部分,視覺系統通常被設計用于識別并定位果實位置,從而引導機械部分完成采摘。不同于蘋果、柑橘等的采摘,簇狀花椒的采摘點無法直接被觀測到,而采摘點的估計需要利用枝干和花椒簇的交點來確定。
如圖1所示,考慮到機械臂的運動空間及復雜采摘場景中的干擾物(枝條、葉子等),合理的花椒采摘規劃應為采摘明顯的近景花椒,忽略遠景花椒。由于近景花椒一般位于前景中較粗的主枝干上,因此前景主枝干的提取是花椒采摘點估計的重要前提。
花椒前景的主枝干提取任務是一種顯著性目標檢測[2](salient object detection, SOD)問題,旨在實現圖像場景中感興趣區域的快速提取并過濾背景噪聲的干擾。文獻[3]提出了一種RGB-SOD算法用于農田中的昆蟲檢測并取得了良好的效果,但易受到復雜環境的干擾,無法有效用于具有低對比度、相似前景與背景、復雜背景等特點的花椒主枝干提取。為了實現復雜農業場景中SOD,文獻[4]提出了雙流主干網絡用于同時提取柑橘圖像的彩色和深度特征,提供具有魯棒性的顯著性線索。文獻[5]以跳層結構為基礎提取跨模態間的多層次互補信息。為了更好地獲取跨模態間的互補信息用于顯著性推理,文獻[6]提出了一種流體金字塔結構用于引導深度圖像和彩色圖像的信息融合。復雜的農作環境中采集到的彩色圖像和深度圖像中跨模態信息往往是非耦合的(圖1),采集到的花椒深度圖像中還包含了與前景相似的噪聲,而現有的一些研究表明線性的跨模態融合方法無法有效地抑制相似噪聲的干擾,從而影響最終的識別結果。為了抑制深度圖像中的噪聲對顯著推理造成的影響,文獻[7]利用邊緣一致性、區域不確定性和模型方差來評估深度圖質量,并以此指導深度圖與彩色圖的選擇性融合。然而,該方法依賴手動設計的質量評價標準,無法應對花椒采摘場景中的各種復雜背景的干擾。
針對相似前景與背景、復雜背景中的花椒枝干提取問題,本文提出基于注意力機制[8]和多尺度監督[9]的花椒主枝干顯著性檢測模型。模型的編碼器采用主流的雙分支主干網絡來提取彩色圖像特征和深度圖像特征。此外,在多個尺度上,本文提出特征融合增強模塊(feature fusion enhancement module,FFEM)并將其嵌入到兩個分支網絡中,利用空間與通道注意力模式來實現跨模態特征的判別融合。在多尺度分割標簽的監督下,特征融合增強模塊能夠自動學習空間權值圖和通道權值向量。本文方法如下。
1)針對復雜的農作環境中花椒主枝干的檢測問題,提出一種基于跨模態特征融合的RGB-D花椒枝干圖像顯著性檢測模型。
2)所提模型在多個編碼層級采用通道權值向量調整彩色和深度圖像的串聯特征,并計算調整后特征的空間權值圖,提取主枝干的形狀特征并抑制背景噪聲。
3)采用多尺度監督的方式來緩解上采樣過程中的邊緣信息丟失,提高模型對主枝干的分割效果。
1所提模型
1.1網絡結構
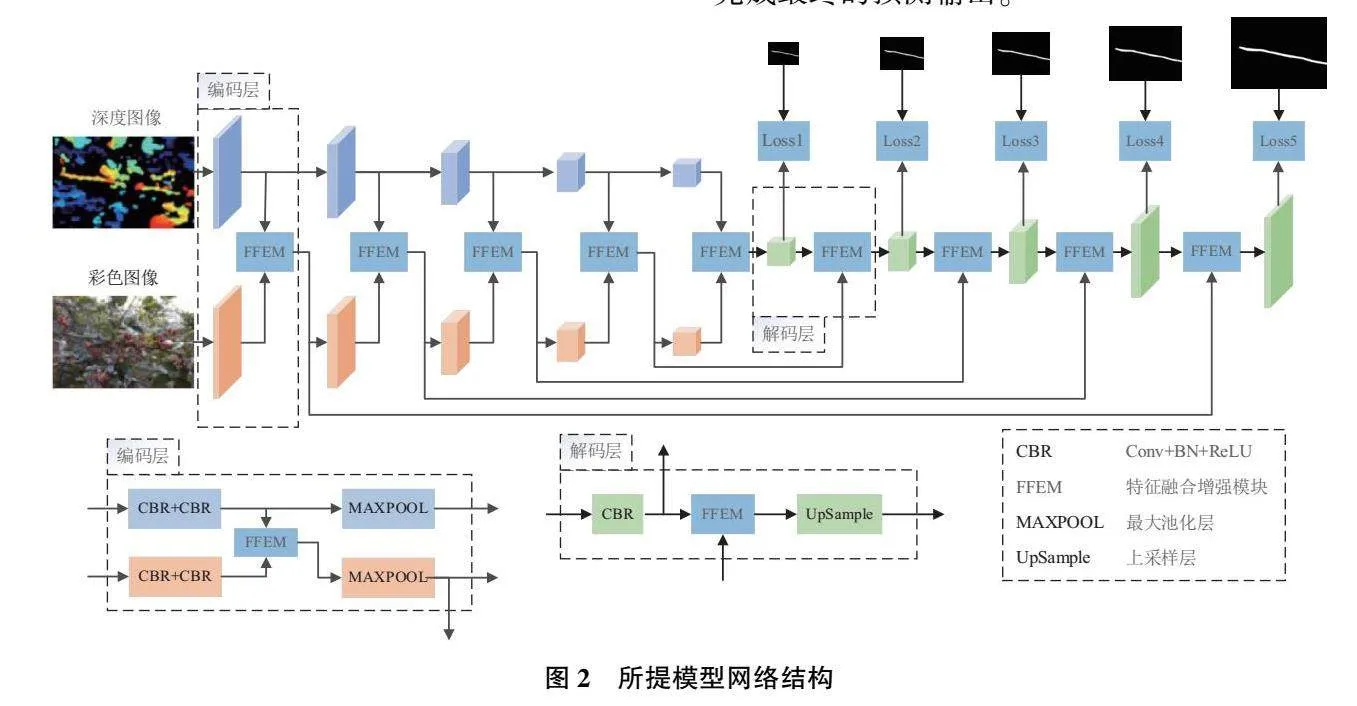
花椒主枝干的精確提取是預測花椒采摘點的重要前提。為了在復雜農作環境下完成花椒主枝干的精確提取,本文提出了一種跨模態的枝干顯著性檢測模型,如圖2所示。模型采用花椒彩色和深度圖像兩種輸入信息,由兩個單流卷積網絡獲取多尺度的編碼特征。單流卷積網絡采用類似Unet編碼器架構,通過連續地組合卷積編碼層(包括卷積層、批歸一化層、線性整流層和最大池化層)來編碼彩色圖像和深度圖像特征。為了有效地利用彩色和深度編碼特征,提出特征融合增強模塊用于實現跨模態特征的判別融合并剔除特征中相似背景的噪聲干擾。該模塊借鑒了注意力機制聚焦于感興趣區域的特性,通過在線性融合過程中嵌入非線性注意力單元來改善融合后特征的顯著性表達。在上采樣過程中,一個反向的解碼網絡被用于解碼圖像特征,非線性注意力單元被嵌入到網絡的每一層級來進一步精煉特征表示。最終,通過多級監督的方式,顯著性推理模塊完成最終的預測輸出。
1.2基于注意力的跨模態融合模塊
彩色花椒圖像中主枝干的提取會受到相似前景枝干的干擾。因此,為準確地區分主枝干還需要深度圖像提供額外的顯著性線索。然而,復雜的農作環境易導致深度圖的深度線索缺失,使得深度圖像中枝干與附近葉子、花椒等對象融為一體。從低質量的深度圖像中分辨出目標枝干仍然需要借助顏色、紋理等外觀信息。因此,本文設計了跨模態融合模塊來同時提取彩色模態和深度模態中包含的與主枝干相關的編碼信息。為了減少彩色模態和深度模態中與顯著性目標相似的背景信息對主枝干提取的干擾,本文在融合模塊中嵌入注意力機制來精煉融合后的編碼特征。
單一層級跨模態融合模塊的結構如圖3所示。該模塊首先接收來自同層級的彩色模態和深度模態特征XRGBi∈RCi×(H/2i)×(W/2i)和XDEPi∈RCi×(H/2i)×(W/2i),其中參數C、H、W和i分別表示編碼特征的通道數量、尺度和層級系數,R表示實數空間。
針對雙模態的特征,首先采用拼接操作聚合跨模態特征,并采用卷積操作對聚合特征進行非線性映射:
式中:Conv3×3表示采用3×3尺寸的卷積核進行步長為1的標準卷積操作;BN(·)和ReLU(·)分別代表批歸一化和線性整流操作。
對于聚合后的跨模態特征Ffusion,分別采用通道注意模塊和空間激活模塊來計算該特征的通道權值圖和空間權值圖。最終,融合模塊的編碼輸出將表示為輸入編碼在權值圖上的加權映射。具體的計算過程如下:
式中:CAM表示通道注意力模塊;表示對應元素相乘;通道權值圖FCAM∈RCi×(H/2i)×(W/2i)。
式中:SAM表示空間注意力模塊;空間權值圖FSAM∈RCi×(H/2i)×(W/2i);模塊最終輸出的編碼特征XRGB′i∈RCi×(H/2i)×(W/2i)。
通道注意力通過自適應地計算輸入特征通道權值圖來為判別力強的重要通道賦予較高權值,從高維冗余的特征圖中選擇對顯著性表達更加有利的特征表示。空間注意力機制通過自適應計算來增強顯著性區域的特征表示。由于顯著性區域被賦予更高的空間權值,多模態特征中與主枝干相似的背景噪聲能夠被更好地抑制。
1.3通道注意機制和空間激活機制
卷積網絡輸出的中間層特征中包含反映不同內容的通道,例如彩色模態中枝干的主要形狀、細節輪廓、語義信息,深度模態中主枝干與背景的深度差異性、目標的深度輪廓等。在主枝干的顯著性檢測中,特征圖中背景的細節輪廓信息會干擾顯著性目標的檢測,造成分割結果中出現與主枝干結構相似的背景枝干,甚至花椒和葉子等背景對象。因此,對多通道編碼特征進行差異化關注,可以增強其中與顯著性預測相關的特征表達,起到抑制多模態特征中背景信息的干擾作用,有利于前景主枝干提取。因此在跨模態融合模塊每個層級中,通道注意機制被嵌入用于引導網絡對融合后的跨模態編碼特征中與顯著性預測相關的通道,進行重點關注,其結構如圖4所示。
首先,對輸入的串聯特征Ffusion進行轉置:
式中Permute(·)表示轉置操作,轉置后的編碼特征FTfusion∈R(H/2i)×(W/2i)×Ci。
然后,采用包含一個隱含層的多層感知機對轉置特征進行非線性映射:
式中MLP由兩個全連接層與一個ReLU激活函數層組成。與CBAM[10]類似,本文在MLP進行特征映射時,采用reduction為r的調節通道衰減系數。MLP輸出的編碼FT∈R(H/2i)×(W/2i)×Ci。
隨后,采用轉置操作還原編碼特征的維度,同時采用Sigmoid激活函數將還原后的特征映射到[0,1]并獲得最終的通道權值圖FCAM:
式中σ表示Sigmoid函數。
編碼特征中的二維圖反映了不同內容的語義激活,二維圖特定的權值圖能夠引導網絡增強相應區域的語義響應,從而抑制非感興趣區域特征的表達。本文進一步嵌入空間激活機制到模態融合模塊中。空間注意力機制依據顯著性監督來自適應計算有利于枝干預測的二維權值圖,從而引導枝干顯著性特征的表達。
在空間激活機制中(圖5),對輸入的編碼特征采用7×7的卷積操作,獲取更大的感受野,使網絡能夠更加有效地利用上下文空間信息。同時,為減少較大卷積核帶來的計算負擔,上述卷積操作采用了reduction為r的可調節通道衰減系數:
式中:FM為卷積后的編碼特征;Convr7×7表示采用7×7卷積核和通道衰減系數r的卷積操作。
隨后采用7×7卷積核和通道衰減系數1/r的卷積操作將該特征映射到與輸入特征相同的特征空間:
最后采用Sigmoid激活函數將編碼特征中的特征值映射到[0,1]以得到最終的空間權值圖FSAM:
FSAM中每個特征點的取值范圍是[0,1],某個位置的權值較大則表明此處的特征被增強,否則被削弱。通過訓練階段優化卷積核參數,FSAM能夠自適應地根據彩色特征XRGBi和深度特征XDEPi為分割目標區域賦予較大特征權值,增強前景主枝干區域的特征,抑制遠景枝干的干擾。因此,融合跨模態特征的空間權值圖FSAM能夠引導模型更加關注特征圖中的局部重要區域。
1.4顯著性推理
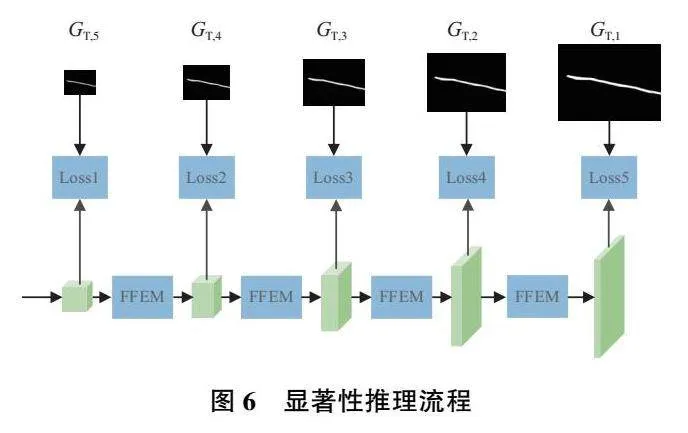
特征解碼階段采用鄰域插值的上采樣操作會丟失目標邊緣輪廓的部分特征,使得分割結果中物體的邊緣較為粗糙[11]。然而花椒采摘點的估計需要精確的枝干邊緣作為依據。因此,采用多尺度監督的方式來減少上采樣過程中邊緣信息的丟失,如圖6所示。在特征解碼階段,本文采用與Skip-Unet類似的解碼網絡,通過采用階梯式的最近鄰域上采樣層和卷積激活操作來對融合后的跨模態特征編碼進行最終的解碼映射。在上采樣過程中,跳躍連接被用于從編碼器中獲取部分特征映射來提升解碼器的特征豐度,緩解因注意力機制而丟失的部分編碼特征。
在上采樣過程中的每一個層級,對應尺度的真實標簽值GT,i被依次用于監督特征解碼過程,以損失計算的方法來引導枝干特征的顯著表達。其中,不同尺度的真實標簽值通過下采樣真實標簽圖獲得。
2實驗結果與分析
2.1實驗設置
1)數據集
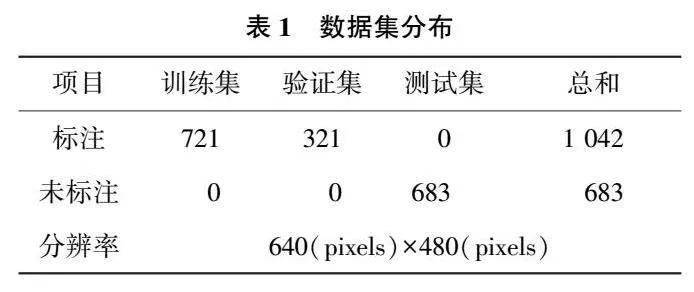
實驗采用的花椒圖像采集于四川省冕寧縣,品種為紅花椒,處于盛果采摘期(2021年7月2日—7月6日),果實的顏色以紅色為主。采用Intel RealSence D435i深度相機采集花椒的彩色和深度圖像,并將二者尺寸進行對齊。表1詳細地列出了圖像數據集的信息。為了保證數據的多樣性,采集的圖像涵蓋了3種天氣條件(晴天、多云、雨后)和一天中的兩個時間段(上午和下午),如圖7所示。從5棵不同大小的花椒樹上總共收集了1 725張彩色圖像和對應的深度圖,其中1 042張彩色圖像被標記用于識別算法的訓練和驗證。其中,70%(721)的標記圖像被用作訓練數據,剩余30%(321)的標記圖像被用于實驗驗證,以測試識別算法的擬合性能。此外,剩余683張未標記的圖像則被用來測試算法的識別效果。在數據標注方面,LabelMe軟件被用于手動標注主枝干的分割掩碼。
2)模型參數
實驗框架基于PyTorch1.2框架搭建,訓練階段采用Adam優化器來訓練網絡,選取學習率、批量、迭代次數和通道衰減系數r分別設置為0.001、6、800和16。測試階段,將模型預測概率大于0.7的像素作為分割目標。所有實驗環境均采用Ubantu 18.04的設備環境,顯卡為NVIDIA GeForce RTX 3090。
3)評價指標
為更好地評估模型的綜合性能,采用平均精確度P、平均召回率R、Fmeasure和平均絕對誤差(mean absolute error,MAE)作為評價指標。如表2所示,模型檢測結果的定義主要分為真陽性(true positive,TP)、假陽性(1 positive,FP)、真陰性(true negative,TN)、假陰性(1 negative,FN)4種情況。
Fmeasure是對精確度和召回率的整體表現評估,計算公式如下:
式中β2是一個超參數,通常取0.3。P、R、Fmeasure數值越大,顯著性目標檢測效果越好。
MAE值用于評估顯著預測圖和真值圖之間的平均絕對差值,代表顯著性檢測的整體效果:
式中:N和M分別為圖像的長和寬;S(x,y)和G(x,y)分別為(x,y)處的顯著預測值和真值。MAE值越小,表明模型預測的結果與真實標注圖間差異越小,因此枝干的分割性能越好。
2.2對比實驗
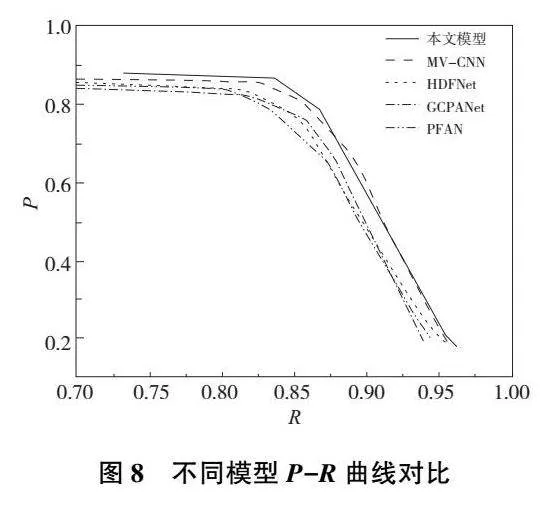
為測試本文模型的性能,本文采用主流的顯著性模型進行對比,包括全局上下文感知漸進聚合顯著性目標檢測網絡(global context-aware progressive aggregation network for salient object detection,GCPANet)[12]、金字塔特征注意力顯著性檢測網絡(pyramid feature attention network for saliency detection,PFAN)[13]、基于CNN的跨視圖轉移和多視圖融合RGB-D顯著性檢測網絡(CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion,MV-CNN)[14]、基于分層動態濾波RGB-D顯著性檢測網絡(hierarchical dynamic filtering network for RGB-D salient object detection,HDFNet)[15]。指標結果定量比較如表3所示。
從表3中可以看出:本文模型取得了最佳的顯著性檢測效果,其中P、R、Fmeasure和MAE指標分別為0.852 3、0.862 5、0.854 6和0.041 2。與MV-CNN網絡相比,指標性能分別提升了0.95、1.79、1.14和0.14個百分點。相比于其他的3種網絡,指標性能分別有1.53~3.51、1.89~3.93、1.94~3.61和1.16~2.15個百分點的提升。此外,為了清晰地觀察實驗結果,本文繪制了各個模型的P-R曲線。如圖8所示,P-R曲線表明本文模型優于MV-CNN模型,同時明顯優于HDFNet、GCPANet和PFAN模型。
為了更直觀地分析結果,本文進一步展示了各個模型檢測的可視化結果,如圖9所示。
從圖9中可以看出,本文模型能夠在雜亂背景、前景和不易區分背景、多個對象等復雜場景中,準確檢測到顯著花椒枝干區域。如第一、第二行圖片中存在較多與前景主枝干類似的背景枝干,但本文模型能夠充分抑制背景枝干噪聲,將前景主枝干識別出來。第三行圖片中前景區域存在多個枝干對象,本文模型仍能夠將前景主枝干識別出來。這表明本文模型能夠有效過濾冗余信息,準確地輸出識別結果。
2.3消融實驗
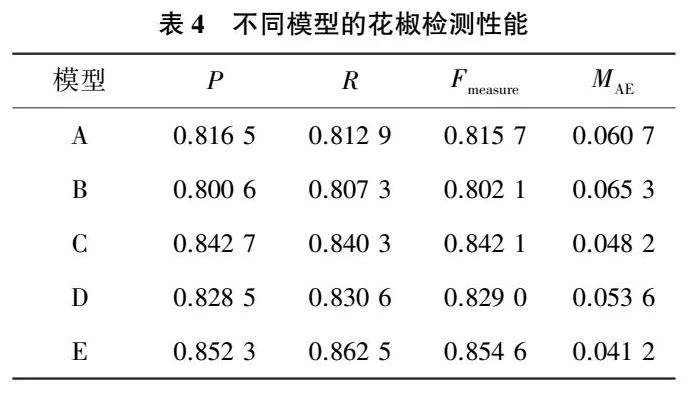
為測試本文所提不同模塊對模型顯著性檢測的影響,設置以下模型進行對比實驗:A,基礎模型,經典的U-Net單模態骨干網絡模型;B,雙編碼器模型,在U-Net模型的基礎上,增加另一編碼器通道提取深度圖像特征,兩通道在編碼階段結束后特征直接拼接進入解碼階段;C,跨模態多尺度特征融合模型,該模型同樣采用雙通道提取圖像特征,并在編碼階段的5個層次分別加入特征融合模塊進行特征融合,融合后的特征進入彩色圖像通道繼續編碼;D,多尺度監督模型,在U-Net模型的基礎上,在解碼階段進行多尺度監督;E,本文模型,同時采用跨模態多尺度特征融合模塊和多尺度監督模塊。上述模型的檢測性能如表4所示。
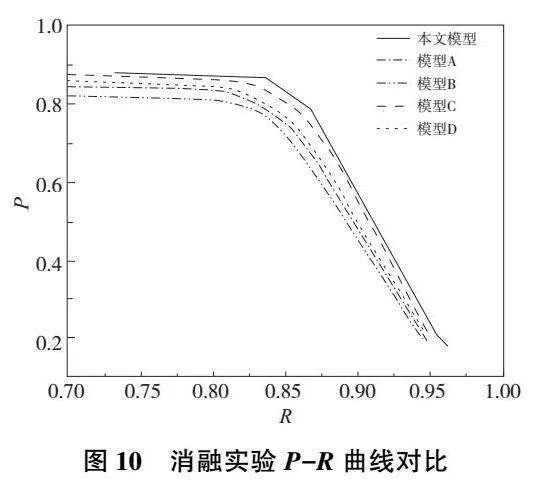
從表4中可以看出:模型B由于未采用特征融合模塊對深度圖像和彩色圖像進行特征融合,導致被冗余的深度信息干擾,評價指標反而差于基礎模型;模型C在引入多尺度特征融合增強模塊后,評價指標得到了明顯的提升;模型D的多尺度監督模塊也促進了模型的評估性能。多尺度特征融合增強模塊和多尺度監督模塊的聯合使用和僅使用單個模塊相比,指標性能分別有0.96~2.38、2.22~3.19、1.25~2.56和0.70~1.24個百分點的提升。此外,本文繪制了5種模型檢測的P-R曲線,如圖10所示。從中可以看出,使用多尺度特征融合增強模塊和多尺度監督模塊后模型的檢測曲線能夠將其他曲線完全包住,這證明了其性能優于其他幾種檢測模型。
為了更加直觀地反映出多尺度特征融合增強模塊和多尺度監督模塊對顯著性檢測的影響,本文對這幾個模型的部分檢測結果進行了可視化,如圖11所示。從圖11中可以看出:模型B增加了預測圖的噪聲數量,帶來了負面效果;模型C又極大程度上抑制了噪聲,這定性地證明了多尺度特征融合增強模塊的作用;使用模型D的多尺度監督模塊后,模型提取邊緣信息的能力更強;同時本文模型使用了多尺度特征融合增強模塊和多尺度監督模塊,可以得到輪廓清晰且無噪聲的前景主枝干預測圖。
3結語
針對現有顯著性目標檢測模型難以準確定位復雜場景下花椒枝干的問題,本文提出跨模態特征融合的RGB-D花椒圖像顯著性檢測模型。本文方法首先采用雙分支主干網絡來提取彩色圖像特征和深度圖像特征,并利用注意力機制來引導這兩個模態特征的融合;最后引入多尺度監督方法用于提升模型對于顯著性枝干邊緣的檢測性能。實驗結果表明:本文模型的各項評估指標均優于其他顯著性目標檢測模型,能夠得到更加精確的枝干檢測結果。
參考文獻:
[1] 楊前,劉興科,羅建橋,等. 基于多任務上下文增強的花椒檢測模型[J]. 機械制造與自動化,2023,52(1):113-118,149.
[2] LIU J J,HOU Q B,LIU Z A,et al. PoolNet+:exploring the potential of pooling for salient object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(1):887-904.
[3] 黃世國,洪銘淋,張飛萍,等. 基于F~3Net顯著性目標檢測的蝴蝶圖像前背景自動分割[J]. 昆蟲學報,2021,64(5):611-617.
[4] SUN Q X,CHAI X J,ZENG Z K,et al. Noise-tolerant RGB-D feature fusion network for outdoor fruit detection[J]. Computers and Electronics in Agriculture,2022,198:107034.
[5] 陳曦濤,訾玲玲,張雪曼. 采用跳層卷積神經網絡的RGB-D圖像顯著性檢測[J]. 計算機工程與應用,2022,58(2):252-258.
[6] LIU Z Y,LIU J W,ZUO X,et al. Multi-scale iterative refinement network for RGB-D salient object detection[J]. Engineering Applications of Artificial Intelligence,2021,106:104473.
[7] WANG X H,LI S,CHEN C,et al. Depth quality-aware selective saliency fusion for RGB-D image salient object detection[J]. Neurocomputing,2021,432:44-56.
[8] NIU Z Y,ZHONG G Q,YU H. A review on the attention mechanism of deep learning[J]. Neurocomputing,2021,452:48-62.
[9] WANG N,CUI Z G,SU Y Z,et al. Multiscale supervision-guided context aggregation network for single image dehazing[J]. IEEE Signal Processing Letters,2021,29:70-74.
[10] WOO S,PARK J,LEE J Y,et al. CBAM:convolutional block attention module[C]//European Conference on Computer Vision. Cham:Springer,2018:3-19.
[11] YU J,YAO J H,ZHANG J,et al. SPRNet:single-pixel reconstruction for one-stage instance segmentation[J]. IEEE Transactions on Cybernetics,2021,51(4):1731-1742.
[12] CHEN Z Y,XU Q Q,CONG R M,et al. Global context-aware progressive aggregation network for salient object detection[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):10599-10606.
[13] ZHAO T,WU X Q. Pyramid feature attention network for saliency detection[C]//2019IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach,CA,USA: IEEE,2019:3080-3089.
[14] HAN J W,CHEN H,LIU N,et al. CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion[J]. IEEE Transactions on Cybernetics,2018,48(11):3171-3183.
[15] PANG Y W,ZHANG L H,ZHAO X Q,et al. Hierarchical dynamic filtering network for RGB-D salient object detection[C]//Vedaldi A,Bischof H,Brox T,et al. European Conference on Computer Vision. Cham:Springer,2020:235-252.
收稿日期:20230407
基金項目:四川省科技計劃重點研發項目(2021YFN0020)
第一作者簡介:李節(1997—),男,四川達州人,碩士研究生,研究方向為圖像處理、機器視覺,lijie295195@163.com。
DOI:10.19344/j.cnki.issn1671-5276.2024.06.042
