Raft存儲集群中的日志分發機制優化
2024-12-30 00:00:00徐輝高輝
計算機應用研究 2024年12期




摘 要:在分布式存儲系統中,Raft(replicated and fault tolerant)算法的強領導特性在節點數量增多時會帶來巨大的日志分發開銷,限制了系統性能和水平擴展能力。針對系統性能和擴展性瓶頸,提出了兩種新的日志機制來優化一致性哈希集群分布式存儲方案。第一種是基于動態優先級的日志分發機制,日志分發順序由領導者與跟隨者節點日志的同步程度決定,加快了日志項的提交速度;第二種是基于窗口流水線的日志分發機制,領導者節點指派日志同步程度較高的跟隨者節點對同步程度較低的跟隨者節點進行日志分發,縮短了系統中節點日志趨向一致的時間。相比于未優化方法,吞吐量和日志同步時間在多節點集群上有顯著提升,證明了兩種日志機制在改進系統性能上的有效性。
關鍵詞:分布式存儲;一致性哈希;日志分發;動態優先級分配;窗口流水線
中圖分類號:TP311.13"" 文獻標志碼:A
文章編號:1001-3695(2024)12-031-3755-08
doi: 10.19734/j.issn.1001-3695.2024.05.0155
Optimization of log distribution mechanisms in Raft storage clusters
Xu Hui1, Gao Hui1, 2
(1.School of Computer Science amp; Engineering, University of Electronic Science amp; Technology of China, Chengdu 611731, China; 2. Kash Institute of Electronics amp; Information Industry, Kashgar Xinjiang 844000, China)
Abstract:In distributed storage systems, the Raft algorithm’s strong leadership characteristics introduce substantial log distribution overhead as the number of nodes increases, impacting performance and scalability. This paper proposed two innovative mechanisms to overcome these challenges. First algorithm was a dynamic priority based log distribution mechanism. It assigned log entries based on the synchronization levels between leader and follower nodes, thereby expediting log submission. Second algorithm was a window pipeline based log distribution delegation mechanism. Its leader node assigned more synchronized followers to disseminate logs to less synchronized ones, diminishing the time required to achieve system-wide log consistency. The experimental results demonstrate substantial enhancements in throughput and log synchronization time within multi-node clusters. This improvement shows the efficacy of these mechanisms in bolstering system perfor-mance.
Key words:distributed storage; consistent hashing; log replication; dynamic priority assignment; windowed pipelining
0 引言
根據國際調研機構IDC發布的《Data Age 2025》[1]預測,全球數據總量從2016年的16.1 ZB增長至2025年的163 ZB。傳統的單機存儲或集中式存儲已經觸及存儲性能和容量方面的瓶頸,無法滿足數據快速增長背景下對數據存儲的需求。
分布式存儲技術在這一背景下應運而生。相較于集中式存儲,分布式存儲可以通過水平擴展的方式增加系統容量,滿足存儲海量數據的需求。同時,分布式存儲將用戶的讀寫請求分散到系統不同節點,提高整體性能,實現系統的負載均衡。此外,分布式存儲還可以通過將數據備份到不同節點實現異地容災備份,提升數據安全性、系統可靠性和可用性。然而,盡管分布式存儲帶來了上述優勢,但也存在一些缺陷,如數據一致性、數據分布不均衡等問題,這些都是需要解決的關鍵問題。
在分布式一致性算法中,Raft算法以其強領導特性、易理解性和良好的性能在業界受到廣泛關注。然而,隨著分布式存儲系統節點數量的增加,Raft算法中的領導者節點在日志分發過程中會面臨巨大的開銷,這不僅影響了日志項的提交速度,還限制了系統的水平擴展能力。
在Raft算法中以領導者節點為中心進行日志復制會產生以下三個問題:a)如果領導者節點為慢節點會產生長尾效應導致性能瓶頸;b)日志的同步必須是有序提交的;c)切換領導者節點時有一段時間系統不可用。
當 Raft 存儲集群進行節點變更時,新加入的節點可能會因為需要花費很長時間同步日志而降低集群的可用性,導致集群無法提交新的請求。在目前存儲數據的飛速增長的背景中,越大規模的分布式系統,日志復制越有可能會成為性能瓶頸。此外,隨著節點的增加,領導選舉和成員變更的開銷也會劇增。為了維護一個高可用、高擴展性的分布式存儲系統,集群節點成員變更時的性能瓶頸亟待解決。
受到計算機網絡中的TCP滑動窗口和操作系統中的動態優先級的進程調度等相關算法的啟發,對Raft算法中的日志分發機制作出優化改進。研究主要解決Raft算法在分布式存儲系統中水平擴展的限制,通過優化日志分發機制來提高系統的性能和可靠性。
a)基于動態優先級分配的日志分發機制中,領導者會根據系統中跟隨者節點中日志與自己日志的同步程度來決定日志分發到不同跟隨者節點的先后順序,從而更快地將日志項復制到集群一半以上節點中,加快日志項的提交速度并提高系統對寫請求的吞吐量。
b)基于窗口流水線的日志分發委托機制中,領導者節點為每個跟隨者節點維護了一個具有容量上限的委托復制窗口,窗口中存儲了領導者在之前心跳函數觸發時日志分發過程中產生的日志分發委托的記錄,窗口中的記錄會在一定時間內得不到跟隨者的響應而過期,在窗口內記錄數量未滿或窗口內有記錄過期的情況下,領導者節點在日志分發過程中為日志落后程度較高的節點指派跟隨者節點對其進行指定區間的日志分發并在跟隨者的委托復制窗口中更新相關記錄信息,將領導者部分日志分發的壓力轉移到跟隨者中,縮短了系統中節點數據趨向一致的時間。
1 相關研究介紹
分布式系統中的一致性問題涉及同一集群中節點在初始狀態一致的情況下,執行相同指令序列直至達到一致狀態的過程。Lamport提出的Paxos算法是基于消息傳遞的代表性一致性算法,將節點分為proposers、acceptors和learners。proposers提出指令,acceptors批準或拒絕,最終由learners執行。盡管Paxos理論描述詳盡,但在工程實踐中仍面臨挑戰。Google的Chubby[2]項目將Paxos引入工程實踐,解決了節點故障恢復等問題。
隨著Paxos廣泛應用于分布式系統,出現了多種優化方案如Multi Paxos、Cheap Paxos、Fast Paxos、Ring Paxos、HT Paxos、Adv Paxos、Pig Paxos等[3~15],以提升性能和容錯性。Raft分布式一致性算法由斯坦福大學提出,相較Paxos更易理解且具備工程實踐基礎。其在區塊鏈共識算法中得到廣泛應用,包括hhRaft、CRaft、KRaft等變體,優化了在不同環境下的性能和容錯能力。
1.1 Raft一致性算法
針對Paxos算法難以理解以及不易用于工程實踐等問題, Ongaro等人[16]發表了基于復制狀態機的Raft算法。復制狀態機通常是通過復制日志的方式來實現的。用戶向基于復制狀態機的分布式系統發起請求到收到響應的流程一般分為以下幾個步驟:a)客戶端向集群中的某個服務節點發起修改狀態機中某些值的操作請求;b)該服務節點將該操作記錄在本地日志中,同時將該操作復制到系統中的其他服務器節點的日志中;c)操作在所有節點中都被記錄到日志后,狀態機執行該操作,完成對某些值的修改;d)該服務節點返回對狀態機某些值修改的結果給客戶端。
Raft算法定義leader(領導者)、candidate(候選者)、follower(跟隨者) 三種節點狀態。通常僅一個領導者,其余為跟隨者。跟隨者不發起請求,僅響應領導者和候選者。領導者處理客戶端請求,維持與跟隨者心跳,同步集群日志。候選者用于選舉領導者,自增任期、投票并請求其他節點投票。若獲多數票則成領導者,遇到現有領導者或任期更大者則回歸跟隨者。跟隨者初始化時均為此狀態,維護選舉超時計時器,超時則轉變為候選者并發起選舉。
Raft算法中,節點日志由序號標記的條目構成,含任期、索引及狀態機指令。日志條目復制到集群多數節點時可提交至狀態機執行,確保節點間日志高一致性,簡化系統行為,保障安全性。Raft日志特性如下:
a)若兩個日志條目分別來自兩個節點的日志,且存儲了相同的索引值和任期,那么這兩個日志條目存儲了同樣的指令。
b)若兩個日志條目分別來自兩個節點的日志,且存儲了相同的索引值和任期,那么這兩個節點的日志在這兩個日志條目之前的所有日志條目都保持一致。
Raft日志特性確保同索引和任期的條目指令相同,且與之前條目一致。領導者每任期在指定索引位置最多創建一個條目,索引不變,保障一致性。附加日志RPC確保跟隨者拒絕不一致的條目。不一致時,領導者刪除跟隨者不一致條目后的所有日志,并重新發送,確保一致。隨系統運行,日志增長占用空間,重置狀態機耗時。Raft采用快照系統壓縮日志,保存狀態機信息至持久化存儲,丟棄舊日志,解決可用性問題。
Raft算法問世以后被廣泛使用于區塊鏈共識算法中,這些Raft算法變體[17~19]提高了Raft算法在拜占庭環境下的容錯能力。文獻[20]引人動態線性投票機制提高了Raft集群的可用性。hhRaft[21]通過引用監控器的角色來優化Raft達成共識的過程,適用于高實時性和高對抗性環境。文獻[22]針對Raft算法提出了一種準確高效的用于跟隨者進行日志修復的算法。CRaft[23]通過使用糾刪碼降低了Raft算法運行的網絡成本和存儲成本。Kraft[24]通過在Kademlia協議中建立的K-Bucket節點關系,優化了Raft算法中領導者選舉和共識過程,提高了集群中領導者的選舉速度。文獻[25]提出了一種基于節點活動和信用機制的Raft共識算法,降低了共識時延并具有更高的吞吐量。在最新Raft算法研究中,針對算法的日志機制,產生了許多改進日志一致性、日志壓縮、日志復制等方面的優化方法[26~28],有效地解決了一致性和性能瓶頸。
1.2 帶虛擬節點的一致性哈希算法
當使用一致性哈希算法構建分布式系統,在服務節點比較少時,可能會面臨因節點在環上不均勻分布導致的數據傾斜問題,即在分布式系統中大量的數據集中存儲在環上的某個節點。為了解決數據傾斜的問題,帶虛擬節點的一致性哈希算法被提出。
帶虛擬節點的一致性哈希方法,核心思想是根據每個節點的性能,為每個節點劃分不同數量的虛擬節點,并將這些虛擬節點映射到哈希環中,然后再按照一致性哈希算法進行數據映射和存儲。這樣在分布式系統中新增或刪除節點時系統的變動就由變動節點周圍的虛擬節點分擔,大大降低了發生數據傾斜的可能性,提高了分布式系統的穩定性。帶虛擬節點的一致性哈希算法相對于普通的一致性哈希算法來說數據定位的算法保持不變,只是多了一步由虛擬節點到物理節點的映射,不僅適合硬件配置不同的節點的場景,而且適合節點規模會發生變動以及對系統穩定性要求更高的場景。
2 一致性哈希存儲集群設計
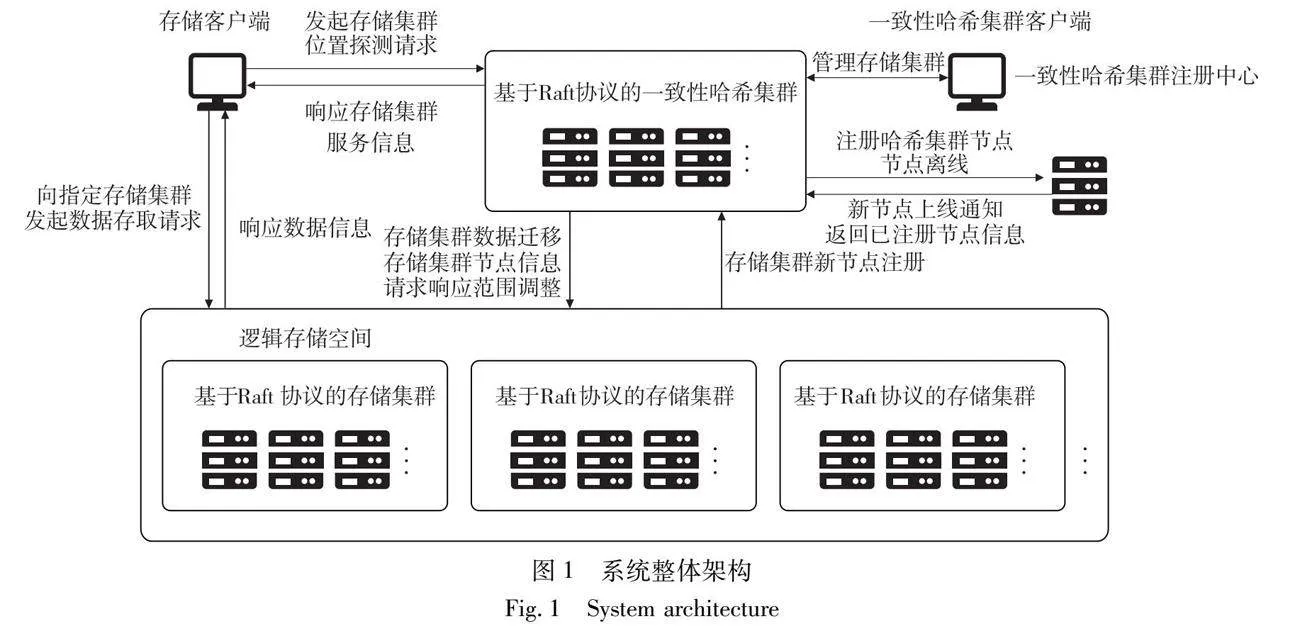
該方案主要由基于Raft協議的一致性哈希集群以及基于Raft 協議的存儲集群構成,其中一致性哈希集群充當路由集群并負責維護存儲系統的路由信息,每個存儲集群有少量節點構成,維護了屬于本集群所管理的數據元信息、文件并為存儲客戶端提供服務。本文方案避免了如圖1中直接在集群中增加節點的方式對系統進行水平擴展導致的集群性能下降等問題,而是通過在一致性哈希環中增加存儲集群并完成相關遷移數據的生成,然后上線新存儲集群中的節點并獲取遷移數據來實現系統的水平擴展,在數據遷移過程中,只會對文件和目錄的元信息以及涉及到的鎖信息進行遷移,文件數據繼續保留在原存儲集群中,降低了數據遷移的開銷。通過這種水平擴展方式,每個存儲集群中節點的數量維持在較小規模,單個存儲集群的性能不會受到節點數量龐大所帶來的影響,存儲集群之間相互獨立,每個存儲集群中都實現了對自己所在集群文件元數據以及文件數據的備份,具備更高的可靠性。
整個存儲系統由一致性哈希集群注冊中心、基于Raft協議的一致性哈希集群、基于Raft協議的存儲集群、客戶端四個部分構成。
一致性哈希集群注冊中心主要負責維護當前一致性哈希集群在線節點的狀態信息,當一致性哈希集群有節點上線或離線時會在注冊中心登記相關信息。當有新節點上線時也會返回注冊中心當前在線節點的相關信息,同時注冊中心會將該節點的信息廣播到一致性哈希集群的所有節點,以便上線節點加人到集群中。注冊中心由兩個RPC服務(節點注冊、節點離線)、一致性哈希集群節點信息、心跳維護這三部分構成。注冊中心會通過心跳始終保持跟一致性哈希集群中當前處于在線狀態的節點的聯系,并將這種節點的在線狀態告知后續新加人到一致性哈希集群中的節點,然后新加人的節點也會根據在線節點的信息維持跟其他在線的節點之間的聯系。
基于Raft協議的一致性哈希集群由RPC服務、狀態機、集群節點維護和Raft一致性模塊構成。一致性哈希集群負責接收面向用戶的存儲客戶端的路由請求,將集群內部維護的存儲集群的服務區間等路由信息響應給客戶端;接收面向系統管理者的一致性哈希集群客戶端的請求,對存儲集群的信息進行管理;接收來自存儲集群的請求,保存存儲集群的相關服務的地址和端口信息;維持一致性哈希集群節點中的所維護的一致性哈希環在集群內多個節點中一致,實現路由信息的冗余備份,保證系統的高可用性。
基于Raft協議的存儲集群由RPC服務、狀態機、存儲、集群節點維護、一致性哈希交互和Raft一致性模塊構成。存儲集群接收面向用戶的存儲客戶端的請求,將集群內部維護的目錄與文件元信息、文件數據以及客戶端對文件和目錄進行并發訪問控制的結果響應給客戶端;接收一致性哈希集群的請求,對自身所在存儲集群的服務區間信息進行管理:維持存儲集群內部節點之間目錄樹以及鎖目錄樹一致,實現文件和目錄元信息、鎖信息的冗余備份,保證集群的高可用性;將存儲集群中的文件分散存儲在集群中的節點并維護同一文件在存儲集群目錄樹中不同路徑下的映射信息,減少相同文件在不同路徑下重復上傳導致的存儲空間占用;響應其他存儲集群節點的對數據遷移文件拉取的請求。
客戶端分為一致性哈希集群客戶端和存儲客戶端,其中存儲客戶端面向用戶使用,通過請求一致性哈希集群獲得路由信息并將其在本地進行緩存,實現客戶端與存儲集群的交互以及結果的展示。一致性哈希集群客戶端面向系統管理員使用,通過管理員在終端鍵人的命令與一致性哈希集群進行交互并實現對系統中的存儲集群進行管理。
在本系統設計中,一致性哈希集群注冊中心能夠讓一致性哈希集群中的節點相互發現并構成一個基于Raft協議的分布式一致性哈希系統,這個一致性哈希系統中維護了每個存儲集群對應的虛擬節點的數量、虛擬節點在一致性哈希環上分布的位置信息以及每個存儲集群在一致性哈希環上負責響應的客戶端請求的區間,由管理員通過一致性哈希集群客戶端進行管理。基于Raft協議的存儲集群則負責真正處理來自客戶端的請求,將客戶端需要上傳的文件存儲到本集群中的節點中,同時在集群中記錄該集群負責的目錄樹和鎖目錄樹的相關信息以及文件信息。在這種設計下,客戶端對不同路徑文件的請求會被一致性哈希環上均勻分布的存儲集群所響應,減少了單個存儲集群被客戶端頻繁請求的壓力,同時存儲集群中的文件也被分散存儲到集群中的各個節點中,減輕了單個存儲集群節點的文件存儲壓力。
3 Raft日志分發機制優化
針對Raft算法在集群中節點數量變多時領導者節點需要更多的時間來將日志項復制到集群中的跟隨者節點時導致的集群對外界請求響應能力降低帶來的性能下降的情形,本文在對Raft算法進行優化的過程中,主要在領導者將日志項復制給跟隨者這個過程考慮優化的措施,設計了基于動態優先級分配和雙心跳機制和基于窗口流水線的委托復制機制。
3.1 基于動態優先級分配的日志分發機制
由于Raft協議是基于復制狀態機來實現集群內部中節點的數據一致,每個節點都會有自己的日志和狀態機,日志中包含了多個日志項,這些日志項中存儲了請求發起方對系統進行操作的指令,狀態機中則存儲了節點所維護的系統中副本數據在當前節點的狀態。當領導者將某個包含日志項分發給了系統中一半以上節點時,領導者就可以將該日志項包含的指令提交到狀態機中執行并更新相關數據的狀態并響應該指令的請求方,同時告訴系統中的其他節點當前可以進行提交的日志項的最大索引,系統中的其他節點就可以根據領導者告知的可以提交的日志項的最大索引往狀態機中提交相關日志項包含的指令,等待狀態機執行并實現對相關數據狀態的更新。在Raft構建的分布式系統正常運行過程中,領導者在每一輪與跟隨者節點的心跳函數中不斷地將日志項分發到系統中的跟隨者節點。最終所有節點上的日志中包含的日志項都一樣,提交到各自狀態機中執行的指令序列也一樣,所維護的副本數據狀態也就達成一致。但是在這個過程中會存在日志從領導者節點復制到系統中所有跟隨者節點中的這個開銷,領導者在每輪心跳中可以分發的日志項的數量并不是無限的。當一個由Raft協議實現的分布式系統中節點數量越多時,這種由領導者將日志復制到跟隨者所帶來的時間開銷就越大,將日志項復制到集群一半以上節點才能對日志項進行提交的時間開銷也就越大,這就會導致客戶端從發起一個更改集群狀態機數據的寫請求到得到集群響應的時間就越長。為此,本文在分布式存儲系統實現中對Raft協議在領導者復制日志到跟隨者節點這個過程中采取了基于動態優先級分配的日志分發機制來提高集群領導者對日志項的提交速度,從而提高系統對客戶端寫請求的寫請求的吞吐量。
Raft對象中在內部維護了兩個定時器,分別是用以重置選舉超時的定時器electionOutTimerId和用以發送攜帶心跳信息的附加日志請求的定時器heartBeat-TimerId。當節點身為領導者時,electionOutTimerId定時器被取消,heartBeatTimerId定時器被激活。每當heartBeatTimerId 定時器超時,領導者節點首先會在heart-BeatTimerId定時器超時回調函數(心跳)中對集群中的其他跟隨者節點的發起的附加日志請求中僅僅附加心跳信息來重置集群中跟隨者節點的選舉定時器electionOutTimerId,這樣領導者會獲得更加充足的時間來準備對日志項進行分發。領導者節點接著會根據Raft對象中存儲的集群中其他跟隨者節點在領導者節點下一次日志復制時的需要分發的日志項的起始索引記錄nextIndexMap,計算跟隨者節點與領導者節點日志同步程度并由低到高排序。排序在最中間的節點(跟隨者數量為N,則從排序在N/2的節點開始,舍棄掉N/2中計算結果的小數部分)的優先級最高。然后從中間節點開始到同步程度最高的節點之間優先級依次遞減,再從同步程度排序在最中間節點前面的節點到同步程度最低的節點之間依次遞減。由于日志項只需要被復制到集群中的一半以上節點時領導者就可以對該日志項進行提交,領導者通過這種動態優先級將每一輪心跳中有限的日志項分發數量優先分配給影響領導者對未提交日志項進行提交的跟隨者節點。將本輪心跳分發的日志項通過對優先級較高節點的第二次日志附加請求中發送,就能更快地對新增的日志項進行提交,從而更快地對請求的發起方進行響應。
領導者在每一輪heartBeatTimerId定時器超時回調函數觸發時都會根據當前跟隨者節點日志與自身日志的同步程度重新計算每個節點的日志分發優先級,然后按照優先級對每個節點分發日志項,跟隨者節點的日志分發優先級不是固定的,所以稱該機制為基于動態優先級分配的日志分發機制。基于動態優先級分配的日志分發機制的算法流程如算法1所示。
算法1 基于動態優先級分配的日志分發機制
輸入:跟隨者數量n;日志在一輪心跳中的分發數量load;領導者當前日志最大索引logIndex;跟隨者到下一次日志分發起始索引l的映射nextIndexMap。
輸出:nextIndexSortVec。
對每一個跟隨者發送不包含任何日志項的心跳附加日志請求,重置跟隨者中的選舉超時器,獲得更加充足的日志項分發準備時間;
根據nextIndexMap計算得到存放 [索引,對應節點] 的nextIndexSortVec;//同步程度由低到高排序
nextIndexSortVec=[[idx1,N1],[idx2,N2],…,[idxn,Nn]],(idx1lt;idx2lt;…lt;idxn);
/*優先級由同步程度排在最中間的節點到同步程度最高的節點遞減,然后再從同步程度排在最中間的節點左邊開始的節點到同步程度最小的節點之間遞減*/
根據nextlndexSortVec得到節點的優先級,PrioritySequence=[[idxn2+1,Nn2+1],[idxn2+2,Nn2+2],…,[idxn,Nn],[idxn2,Nn2],[idxn2-1,Nn2-1],…,[idx1,N1]];
//為優先級中的節點依次分配本輪心跳周期中的日志復制數
for i=1; ilt;=n; i++ do
node = PrioritySequence[i];
if loadgt;=(logIndex-node.idx+1) then
load = load - (logIndex-node.idx+1);
向跟隨者節點node.N發送攜帶從node.idx開始的(logIndex-node.idx+1)個日志項的附加日志請求;
else if loadgt;0 then
向跟隨者節點node.N發送攜帶從node.idx開始的load個日志項的附加日志請求;
load = 0;
end if
break;
end if
end for
圖2給出了一個Raft集群運行在某個時刻下各個節點中的日志示例圖,用以對優化算法進行講解。
在圖2中,假定領導者節點在一輪heartBeatTimerId定時器超時的日志分發數量為5,即在一次心跳超時中只能向集群中的所有跟隨者節點發送5個日志項。當領導者節點heart-BeatTimerId定時器超時后,其首先會向集群中的所有跟隨者發送僅用于維持與跟隨者節點之間心跳的附加日志請求用以重置跟隨者中的electionOutTimerId定時器。然后根據nextIndexMap中數據對集群中跟隨者節點按日志同步程度由低到高進行排序后,得到排序結果(C,E,D,B),領導者進行日志復制的優先級按從高到低的順序就是(D,B,E,C)。于是領導者節點從跟隨者節點D開始為跟隨者節點分配在本輪心跳周期的日志復制數量,將索引為5、6、7的三個日志項復制到發送給跟隨者節點D。然后再將索引為6、7的兩個日志項復制到發送給跟隨者節點B,領導者節點在該次心跳超時中的日志分發數量使用完畢,領導者節點等待跟隨者節點B、D關于這次附加日志請求的響應來更新集群中的CommittedIndex,在狀態機執行到該日志項時完成對產生相應日志項的請求的響應。
通過領導者在每輪心跳中優先將日志分發數量分配在系統中與自身日志同步程度最高的一半跟隨者節點的方式,在同等節點規模中的分布式存儲系統中,應用了基于動態優先級分配的日志分發機制的Raft算法構建的分布式系統比應用原始Raft算法構建的分布式系統能夠更快地對新日志項進行提交,客戶端也能更快地收到響應,提高了系統寫請求的吞吐量。
3.2 基于窗口流水線的日志分發委托機制
在上述基于動態優先級分配的日志分發機制的Raft算法優化中,Raft集群中的領導者在心跳周期函數觸發時按照一定的優先級排序方式優先將日志項復制給集群中日志與自己同步程度較高的節點。以期望于領導者中的未能提交的日志項能夠更快地被復制到集群中的一半以上節點中,從而能使領導者能夠更快地對集群中的日志項進行提交,提高系統整體對寫請求的吞吐量。
由于領導者總是優先考慮將日志項復制給與自己同步程度較高的節點,在每輪心跳周期函數中領導者可以進行分配的日志項數量有限的情況下,當系統出現寫請求大量不停到來的極端情況時,與領導者節點日志同步程度較低的節點就會出現“饑餓”的情況,日志同步程度遲遲跟不上領導者節點,基于窗口流水線的日志分發委托機制就是在上述背景中被構思而來。
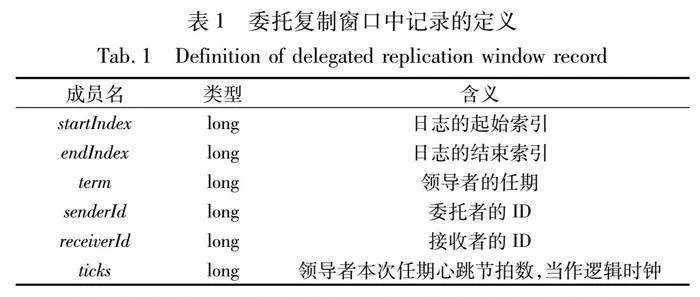
在基于窗口流水線的日志分發委托機制中,基于動態優先級分配的日志分發機制中領導者節點在每一輪心跳周期中都會計算集群中的跟隨者與自己日志的同步程度并以此作為優先級將該輪心跳周期中的日志項的復制數量進行分配。然后該同步程度排序結果會被基于窗口流水線的日志分發委托機制所使用,領導者會為每個跟隨者節點設定委托復制窗口,每個跟隨者的委托復制窗口中保存了領導者在之前的心跳周期中向其他跟隨者委托復制日志項給該跟隨者節點的記錄,記錄的定義如表1所示。
在領導者進行日志復制的心跳周期中,領導者根據跟隨者中日志與自身日志同步程度由低到高進行排序,然后在進行日志分發委托時根據跟隨者節點數量將跟隨者節點分為兩組。當跟隨者數量是偶數時,將排序在前一半的節點和后一半的節點各分到一組中;當跟隨者數量是奇數時,舍棄掉排序在最中間的節點,然后將排序在最中間節點前面的節點以及后面的節點各分到一組中。日志同步程度較高的那組分組被稱為委托者分組,日志同步程度較低的那組分組被稱為接收者分組,經過這樣的分組后,兩組中節點的數量相同。然后領導者節點會根據兩組中節點在其分組中同一位置進行日志項復制委托,如由委托者分組的同步程度最高的節點負責對接收者分組的同步程度最高節點進行委托復制,委托者分組的中同步程度最低的節點負責對接收者分組中同步程度最低的節點進行委托復制。
在領導者對跟隨者進行日志分發委托過程中會根據每個接收者委托復制窗口中的記錄、委托者和接收者節點的日志狀態計算委托者需要發送的日志項的起始索引以及結束索引,并將其他相關信息一起登記在該接收者的委托復制窗口中,然后向攜帶相關參數向委托者發起請求。
委托者節點在接收到來自領導者的委托復制請求后,會攜帶本次領導者委托的相應日志項以及其他參數向接收者發起請求并將日志項復制到接收者中。接收者在收到來自委托者的日志復制請求時的處理邏輯與Raft算法中跟隨者收到領導者的日志復制請求時保持一致,然后向領導者發起請求告知接收者此時日志的相關狀態,由領導者完成對接收者委托復制窗口中記錄的更新以及日志狀態的更新。領導者進行委托復制的算法流程如算法2所示。
算法2 基于窗口流水線的日志分發委托機制
輸入:跟隨者數量n;動態優先級分配的日志分發機制計算得到的nextlndexSortVec。
if n%2==0 then
/*跟隨者數量為偶數,則取同步程度最高的一半跟隨者節點成為委托者節點*/
senderVec=[[idxn2+1,Nn2+1],[idxn2+2,Nn2+2],…,[idxn,Nn]],(idxn2+1lt;idxn2+2lt;…lt;idxn);
else
/*跟隨者數量為奇數,舍棄同步程度排在最中間的節點,取剩余的同步程度最高的一半跟隨者節點成為委托者節點*/
senderVec=[[idxn2+2,Nn2+2],[idxn2+3,Nn2+3],…, [idxn,Nn]],(idxn2+2lt;idxn2+3lt;…lt;idxn);
end if
//接收者節點則取同步程度較低的另一組節點
receiverVec=[[idx1,N1],[idx2,N2],…,[idxn2,Nn2]],(idx1lt;idx2lt;…lt;idxn2);
receiverNum=n2
for i=1; ilt;=receiverNum; i++ do
/*針對每一個接收者分配一個委托者對其進行日志分發,分配原則是委托者中同步程度最低的節點對接收者中同步程度最低的節點進行日志分發,委托者中同步程度最高的節點對接收者中同步程度最高的節點進行日志分發*/
sender = senderVec[i];
receiver = receiverVec[i];
if sender.idxgt;receiver.idx then
if receiver.N委托復制窗口未滿or有過期記錄then
領導者根據receiver.N節點的委托復制窗口中的記錄計算sender.N節點本次委托中需要向receiver.N節點發起復制的日志的起始索引和結束索引以及其他相關信息;
領導者更新receiver.N節點的委托復制窗口中的相關記錄;
領導者攜帶相關委托的參數向sender.N節點發起日志分發委托的請求;
end if
end if
end for
同樣用圖2對基于窗口流水線的日志分發委托機制進行講解,假設領導者當前的心跳節拍為10(心跳節拍隨著每輪心跳函數觸發增加),任期為1,每個節點委托復制窗口的容量為3,窗口中的記錄在其記錄中的ticks參數3個心跳節拍以后過期,在一次分發委托中包含的日志數量限制為5。根據算法對跟隨者節點按照日志同步程度由低到高進行排序后,排序結果為CEDB,跟隨者節點D、B被分組到委托者分組,跟隨者節點C、E被分組到接收者分組,然后領導者節點委托節點B對節點E進行索引I范圍為4到5的日志復制,委托節點D對節點C進行索引范圍為3到4的日志復制。
在原始Raft算法中,領導者對跟隨者進行日志分發這個過程中所有跟隨者節點中日志項都來自于領導者,跟隨者之間并不會相互發送日志項,這就會導致當系統節點數量增多時領導者節點會面臨非常大的日志分發的壓力。基于窗口流水線的日志分發委托機制通過在領導者進行每一次心跳函數進行日志分發這個過程中為日志同步程度較低的節點分配日志同步較高的節點進行一次指定區間日志的分發委托,窗口中具備多個存放記錄的容量是為了提高這種分發委托機制的效率。在跟隨者的委托復制窗口中記錄未滿時,領導者不用等待跟隨者在接收來自委托者的日志復制請求后的響應就可以在下一次心跳函數中根據窗口中記錄信息給相應跟隨者繼續安排委托者對其進行指定區間日志的分發。通過這種日志分發委托機制,領導者節點能夠加速集群中所有節點日志趨于一致的時間,每個節點都能更快實現在本節點狀態機中所維護的數據一致。
4 Raft算法優化性能對比測試
4.1 測試環境
系統測試環境的網絡拓撲結構為總線型,由千兆網絡連接服務器A、B、C,服務器A和B是通過VirtualBox虛擬機軟件分別在兩臺物理設備上虛擬化構建而成, 然后將它們通過虛擬網卡接入到千兆交換機中。三臺服務器的系統均為 Ubuntu 20.04 LTS 64 bit,文件系統為EXT4,網卡速度100 Mbps,具體差異配置如表2所示。
4.2 基于動態優先級分配的日志分發機制
為了減少系統中其他因素對基于動態優先級分配的日志分發機制性能測試的影響,在測試時,限制了存儲集群中每個節點成為領導者時在一次心跳周期(200 ms)中只能向集群中的所有跟隨者節點傳輸1 000個日志項。這樣就能在一定程度上減少日志項由領導者節點傳輸給跟隨者節點時其他因素成為瓶頸帶來的影響,同時分別在集群中節點的數量為3個和5個的部署方式下進行測試。
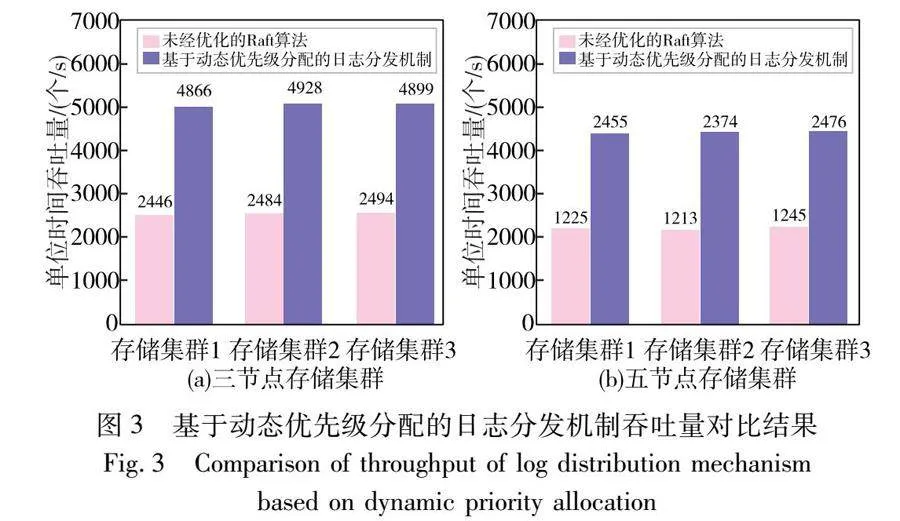
在系統中分別采用未經優化的Raft算法和基于動態優先級分配的日志分發機制優化下的Raft算法對存儲集群1、2、3進行寫請求的吞吐量測試,每次測試通過腳本提交數量為20 000的寫請求,多次測試并統計系統的平均吞吐量,測試結果如圖3所示。
根據圖3的結果可以計算得到,基于動態優先級分配的日志分發機制優化的Raft算法在三個和五個節點分別構成的集群中單位時間內吞吐量對比未經優化的Raft算法提升了97.9百分點和98.3百分點。在三節點構建的集群和五節點構建的集群中,跟隨者數量分別為兩個和四個。在基于動態優先級分配的日志分發機制中,與原始Raft算法構建的集群中領導者在心跳函數中將日志分發給所有跟隨者節點相比,三節點集群領導者在每輪心跳函數中優先將1 000個日志項分配數量分發給其中一個跟隨者,五節點集群領導者在每輪心跳函數中優先將1 000個日志項分配數量分發給其中兩個跟隨者。由于領導者只需要將日志項復制到集群一半以上節點時就可以對其進行提交并響應,理論上在偶數個跟隨者的集群中領導者對寫請求的吞吐量能提升一倍,通過上述實驗可以看到寫請求的吞吐量的提升都在95個百分點以上。由此可見,基于動態優先級分配的日志分發機制優化的Raft算法對比原始Raft算法在單位時間內能對更多的日志項進行提交,提高集群對寫請求在單位時間內的吞吐量。
4.3 基于窗口流水線的日志分發委托機制
在測試時,在三個節點構成的集群中限制了每個節點成為領導者時在一次心跳周期(200 ms)中只能向集群中的所有跟隨者節點傳輸500個日志項,這樣就能在一定程度上減少日志項由領導者節點傳輸給跟隨者節點時其他因素成為瓶頸的帶來的影響,同時允許領導者節點在對其他節點進行一次日志分發委托時允許復制的日志項數最多為500個。在五個節點構成的集群中限制了節點成為領導者時在一次心跳周期(200 ms)中只能向集群中的所有跟隨者節點傳輸1 000個日志項,同時允許領導者節點在對其他節點進行一次日志分發委托時允許復制的日志項數最多為1 000個。同樣分別在集群中節點的數量為3個和5個的部署方式下進行測試。
在系統中分別采用未經優化的Raft算法和在基于動態優先級分配的日志分發機制上實現的基于窗口流水線的日志分發委托機制優化的Raft算法對存儲集群1、2、3進行集群所有節點日志最終同步到一致時所需時間的測試。基于動態優先級分配的日志分發機制會使得集群中跟隨者節點之間日志同步程度分為較高和較低兩個群體,跟隨者這兩個群體的日志同步程度差異也是基于窗口流水線的日志分發委托機制發揮作用的基礎。然后在三節點集群中通過腳本提交數量為20 000的寫請求并統計所有節點中日志同步的時間,在五節點集群中通過腳本提交數量為10 000的寫請求并統計所有節點中日志同步的時間,多次運行上述腳本求得同步時間平均值,測試結果如圖4所示。
根據圖4的結果可以計算得到,基于窗口流水線的日志分發委托機制優化下的Raft算法在三個和五個節點構成的集群上的日志同步時間分別為未經優化的Raft算法同步時間的54.3%、53.5%。
在三節點和五節點構建的集群中,跟隨者數量分別為兩個和四個。在基于動態優先級分配的日志分發機制中,領導者節點將每輪心跳函數中的日志項分配數量優先分發給系統中一半的跟隨者節點,造成系統中在所有節點日志在完全同步前有一半跟隨者節點中日志的同步程度始終比另一半跟隨者節點高。然后在基于窗口流水線的日志分發委托機制中,領導者節點為日志同步程度落后的節點分配日志同步程度較高的節點進行日志復制,將部分領導者對跟隨者進行日志復制的壓力轉移到同步程度較高的跟隨者節點中。
通過實驗可以得到基于窗口流水線的日志分發委托機制對比原始Raft算法能夠更快地使得Raft集群中節點的日志趨向一致。
4.4 吞吐量測試
清空之前功能測試建立的所有存儲集群以及一致性哈希集群中的信息,在服務器A中啟動注冊中心和一致性哈希集群節點1、2、3,分別新增存儲集群1,在服務器A中啟動存儲集群1中的節點1、2、3;新增存儲集群2,在服務器B中啟動存儲集群2中的節點4、5、6;新增存儲集群3,在服務器C中啟動存儲集群3中的節點7、8、9;然后分別進行由同個服務器三個節點構成的單存儲集群進行寫請求和讀請求的吞吐量的性能測試。
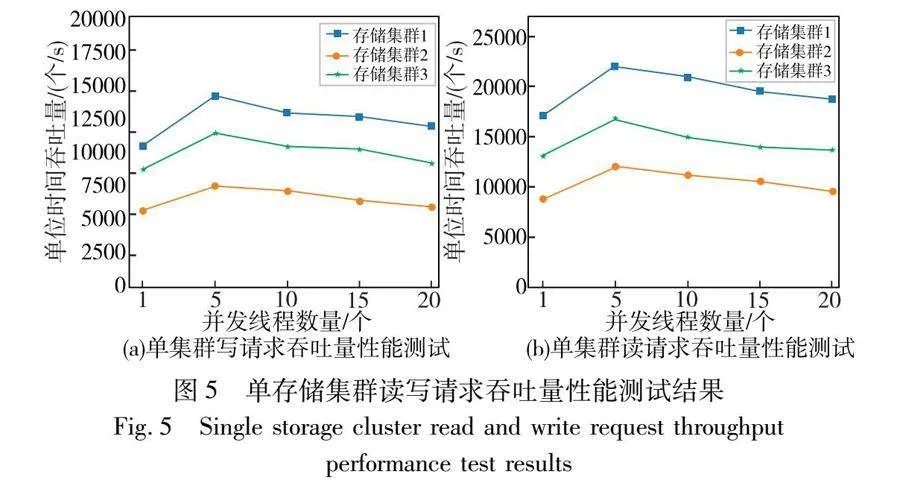
對上述測試步驟重復多次并統計不同數量線程下所有請求完成的平均時間,吞吐量性能測試結果如圖5所示。
在吞吐量性能測試中,根據圖5可以發現不同存儲集群對寫請求的吞吐量隨著構成存儲集群的虛擬機的配置不同而產生差異。
原因在于寫請求需要由存儲集群中的領導者寫到日志中并在心跳周期函數中被復制到集群中一半以上節點后領導者才可以將其提交到狀態機中執行并對其進行響應,同時還要將日志項存儲到本地文件中保存,這些操作對時間的需求較大,所以寫請求吞吐量的性能測試結果對比起讀請求吞吐量性能測試結果來說較低。
讀和寫請求的吞吐量在剛開始都會隨著并發線程的數量增加而提升,在并發線程數量增加到5個線程的時候吞吐量達到系統峰值,吞吐量在達到峰值后會隨著并發線程數量的增加而降低,系統寫請求吞吐量的瓶頸主要在對包含寫請求的日志項進行本地存儲并在集群中達成一致這個過程。
吞吐量隨著并發數先增加再降低的現象可以通過系統資源利用與并發數的關系來解釋。在低并發數時,系統資源充足,能夠快速處理請求,響應時間短,因此吞吐量隨著并發數的增加而增加。然而,隨著并發數的繼續增加,系統資源逐漸被占滿,處理每個請求所需的資源變多,導致響應時間增長。當并發數達到某個臨界點時,系統資源接近或達到上限,處理請求的效率降低,響應時間大幅增加,根據吞吐量的計算公式,響應時間增長導致吞吐量下降。
4.5 可擴展性測試
清空之前測試建立的所有存儲集群以及一致性哈希集群中的信息,在服務器A中啟動注冊中心和一致性哈希集群節點1、2、3,然后分別啟動存儲集群1和2、存儲集群1、2和3,進行兩個、三個存儲集群下的吞吐量的性能測試,查看系統在集群規模增大情況下的吞吐量的性能變化情況,驗證系統是否具備較高的可擴展性。
運行腳本啟動不同數量的線程對隨機生成數量為50 000的目錄路徑調用mkdirs向當前啟動的存儲集群發起創建目錄請求進行寫請求吞吐量的性能測試,然后以同樣的方式啟動不同數量的線程對隨機生成的50 000數量的目錄路徑并調用lsdir對當前啟動的存儲集群發起查看目錄請求進行讀請求吞吐量的性能測試。
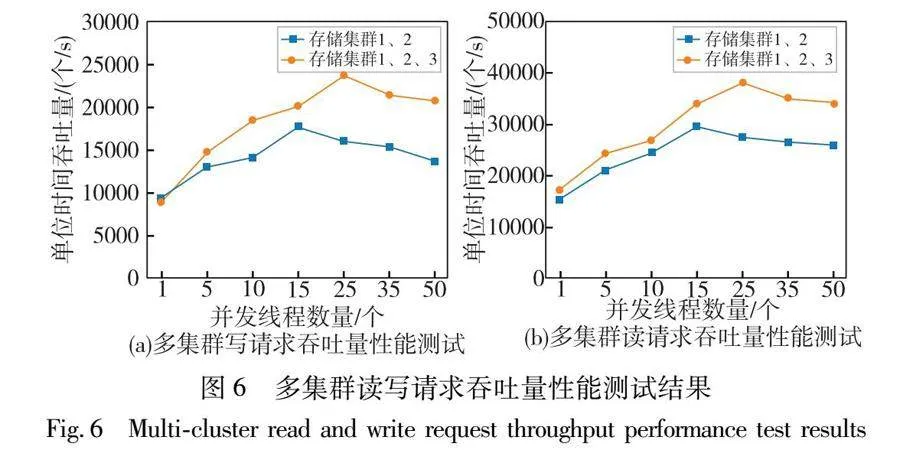
對上述測試步驟進行多次并統計不同數量線程下所有請求完成的平均時間,不同集群數量規模下的吞吐量性能測試結果如圖6所示。
在多集群吞吐量性能測試中,根據圖6測試結果,系統在啟動集群1和2的時候隨著并發線程數量的增加,系統的讀寫請求的吞吐量也在增加,在并發線程數量達到15時吞吐量達到峰值,隨后隨著并發線程數量的增加,吞吐量開始降低。系統在啟動集群1、2和3時在并發線程數量達到25時吞吐量達到峰值,隨后同樣隨著并發線程數量的增加,吞吐量開始降低。根據系統在啟動多個集群下吞吐量的變化情況可以得到隨著系統集群數量的增加,在并發線程未達到系統性能峰值時系統的整體吞吐量會提升,能夠隨著并發線程數量的增加在單位時間內處理更多的讀寫請求,同時隨著系統中集群數量的增加系統在達到吞吐量峰值時的并發線程數量也在增加。
在系統吞吐量未到達峰值時,提升并發線程數量能夠更加充分地利用系統中集群的資源從而提高吞吐量,但是在系統吞吐量達到峰值后再增加并發線程時,由于線程之間的競爭導致系統吞吐量下降。由上述測試可知,增加系統中的集群數量可以提高系統吞吐量,系統具備一定的可擴展性。
5 結束語
Raft算法的強領導特性在節點數量增多時會帶來巨大的日志分發開銷,限制了系統性能和水平擴展能力。本文在Raft的基礎上,提出了一種新的支持高并發、海量存儲、高可靠的分布式存儲方案。在 Raft 算法領導者進行日志分發過程中,本文提出了一種基于動態優先級分配的日志分發機制,該機制讓領導者根據系統中跟隨者節點日志與自己日志的同步程度來決定日志分發到不同跟隨者節點的先后順序,從而更快地將日志項復制到集群一半以上節點中,加快日志項的提交速度并提高系統寫請求的吞吐量。在 Raft 算法領導者進行日志分發過程中,本文提出了一種基于窗口流水線的日志分發委托機制,該機制讓領導者節點指派日志同步程度較高的跟隨者節點對日志同步程度較低的跟隨者節點進行日志分發,將領導者部分日志分發的壓力轉移到跟隨者,縮短了系統中節點日志趨向一致的時間。
在未來的研究過程中,可以通過改進一致性模型和引入更高效的共識算法,增強分布式系統的可靠性;利用新型硬件降低延遲并通過智能數據分片提升吞吐量;采用強加密技術和隱私保護計算,加強安全與隱私保護;集成云原生與邊緣計算,提升系統靈活性和響應速度。
參考文獻:
[1]Reinsel D, Gantz J,Rydning J. Data age 2025: the evolution of data to life-critical [EB/OL]. (2017) [2024-04-12] . https://www. seagate.com/files/www-content/our-story/trends/files/data-age-2025-white-paper-simplified-chinese.pdf.
[2]Burrows M. The chubby lock service for loosely-coupled distributed systems [C]// Proc of the 7th Symposium on Operating Systems Design and Implementation.Berkeley,CA: USENIX Association, 2006: 335-350.
[3]Calder B, Wang J,Ogus A, et al. Windows azure storage: a highly available cloud storage service with strong consistency [C]// Proc of the 23rd ACM Symposium on Operating Systems Principles. New York: ACM Press, 2011: 143-157.
[4]Chandra T D, Griesemer R, Redstone J. Paxos made live: an engineering perspective [C]// Proc of the 26th Annual ACM Symposium on Principles of Distributed Computing. New York: ACM Press, 2007: 398-407.
[5]Lamport L.Byzantizing Paxos by refinement [C]//Proc of International Symposium on Distributed Computing. Berlin: Springer, 2011: 211-224.
[6]Marandi P J, Primi M,Schiper N, et al. Ring Paxos: a high-throughput atomic broadcast protocol [C]// Proc of IEEE/IFIP International Conference on Dependable Systems and Networks. Piscata-way, NJ: IEEE Press, 2010: 527-536.
[7]Marandi P J, Primi M, Pedone F. Multi-RingPaxos [C]//Proc of IEEE/IFIP International Conference on Dependable Systems and Networks. Piscataway, NJ: IEEE Press, 2012: 1-12.
[8]Kumar V, Agarwal A. HT-Paxos: high throughput state-machine replication protocol for large clustered data centers [J]. The Scientific World Journal, 2015, 2015 (1): 1-13.
[9]Biely M, Milosevic Z, Santos N,et al. S-Paxos: offloading the leader for high throughput state machine replication [C]//Proc of the 31st" IEEE Symposium on Reliable Distributed Systems. Piscataway, NJ: IEEE Press, 2012: 111-120.
[10]Dang H T, Sciascia D, Canini M, et al. NetPaxos: consensus at network speed [C]// Proc of the 1st ACM SIGCOMM Symposium on Software Defined Networking Research. New York: ACM Press, 2015: 1-7.
[11]Hunt P, Konar M, Junqueira F P,et al. ZooKeeper: wait-free coordination for Internet-scale systems [C]//Proc of USENIX Annual Technical Conference. Berkeley,CA: USENIX Association, 2010: 145-158.
[12]Moraru I, Andersen D G, Kaminsky M. There is more consensus in egalitarian parliaments [C]// Proc of the 24th ACM Symposium on Operating Systems Principles. New York: ACM Press, 2013: 358-372.
[13]LiuFagui, Yang Yingyi. D-Paxos: building hierarchical replicated state machine for cloud environments [J]. IEICE Trans on Information and Systems, 2016, 99 (6): 1485-1501.
[14]Li Bin, Jiang Jianguo, Yuan Kaiguo. Adv Paxos: making classical Paxos more efficient [J]. The Journal of China Universities of Posts and Telecommunications, 2019, 26 (5): 33-40,59.
[15]Charapko A, Ailijiang A, Demirbas M. PigPaxos: devouring the communication bottlenecks in distributed consensus [C]// Proc of International Conference on Management of Data. New York: ACM Press, 2021: 235-247.
[16]Ongaro D, Ousterhout J. In search of an understandable consensus algorithm [C]//Proc of USENIX Annual Technical Conference. Berkeley,CA: USENIX Association, 2014: 305-319.
[17]Tian Sihan, Liu Yun, Zhang Yansong, et al. A Byzantine fault-tolerant raft algorithm combined with schnorr signature [C]//Proc of the 15th International Conference on Ubiquitous Information Management and Communication. Piscataway, NJ: IEEE Press, 2021: 1-5.
[18]Zhou Shumeng, Ying Bidi. VG-Raft: an improved Byzantine fault tolerant algorithm based on Raft algorithm [C]//Proc of the 21st International Conference on Communication Technology. Piscataway, NJ: IEEE Press, 2021: 882-886.
[19]王謹東,李強." 基于Raft算法改進的實用評占庭容錯共識算法[J].計算機應用2023, 43(1): 122-129. (Wang Jindong, Li Qiang. Improved practical Byzantine fault tolerance consensus algorithm based on Raft algorithm [J]. Journal of Computer Applications, 2023, 43(1): 122-129.)
[20]Paris J F, Long D D E. Pirogue, a lighter dynamic version of the Raft distributed consensus algorithm [C]//Proc of the 34th IEEE International Performance Computing and Communications Conference. Piscataway, NJ: IEEE Press, 2015: 1-8.
[21]Wang Yuchen, Li Shuang, Xu Lei, et al. Improved Raft consensus algorithm in high real-time and highly adversarial environment [C]// Proc of the 18th International Conference on Web Information Systems and Applications. Cham: Springer, 2021: 718-726.
[22]Guo Jinwei, Cai Peng, Qian Weining, et al. Accurate and efficient follower log repair for Raft-replicated database systems [J]. Frontiers of Computer Science, 2021, 15: 1-13.
[23]Wang Zizhong, Li Tongliang, Wang Haixia, et al. Craft: an erasure-coding-supported version of raft for reducing storage cost and network cost [C]// Proc of the 18th USENIX Conference on File and Storage Technologies. Berkeley,CA: USENIX Association, 2020: 297-308.
[24]Wang Rihong, Zhang Lifeng, Xu Quanqing, et al. K-bucket based Raft-like consensus algorithm for permissioned blockchain [C]// Proc of the 25th IEEE International Conference on Parallel and Distributed Systems. Piscataway, NJ: IEEE Press, 2019: 996-999.
[25]Wu Yusen, Wu Yuansai, Liu Yiran, et al. The research of the optimized solutions to Raft consensus algorithm based on a weighted Page-Rank algorithm [C]// Proc of Asia Conference on Algorithms, Computing and Machine Learning. Piscataway, NJ: IEEE Press, 2022: 784-789.
[26]Dautov R, Husom E J. Raft protocol for fault tolerance and self-recovery in federated learning [C]// Proc of the 19th International Symposium on Software Engineering for Adaptive and Self-Managing Systems. New York: ACM Press, 2024: 110-121.
[27]Liu Xiao, Huang Zhao, Wang Quan. An optimized snapshot Raft algorithm for log compression [C]//Proc of the 2nd International Conference on Artificial Intelligence and Blockchain Technology. Piscata-way, NJ: IEEE Press, 2023: 6-10.
[28]Tong Shihua, Zhou Xiang, Fu Wei, et al. Improved Raft algorithm based on communication bottleneck and log inconsistency [C]// Proc of China Automation Congress. Piscataway, NJ: IEEE Press, 2023: 4833-4838.
