基于聯邦學習和圖卷積神經網絡的交通流預測研究
2024-12-31 00:00:00劉華儲蓄蓄
西部交通科技 2024年9期


基金項目:
廣西高校中青年教師科研基礎能力提升項目“基于‘AI視覺+機器學習’的城市交通場景應用研究”(編號:2023KY1157);廣西教育科學“十四五”規劃課題“人工智能時代高校思想政治教育質量評價的改革研究”(編號:2022ZJY475)
作者簡介:
劉 華(1984—),碩士,工程師,講師,研究方向:計算機應用技術、人工智能、大數據。
摘要:為實現交通流預測中的數據隱私保護,并提高預測準確性,文章提出一種基于聯邦學習(FL)和圖卷積神經網絡(GCN)的交通流預測方法,即采用GCN模型對交通網絡進行建模,通過聯邦學習框架在客戶端訓練模型并只共享模型更新。結果表明,該方法有效地保護了數據隱私,同時也取得了良好的預測效果。
關鍵詞:聯邦學習;圖卷積神經網絡;隱私保護;交通流預測
中圖分類號:U491.1+4文獻標識碼:A 48 160 3
0 引言
隨著國民經濟的發展和城市化進程的加快,我國的汽車數量迅速增加,截至2023年末全國民用汽車保有量達到3.4億輛,交通擁堵現象日益嚴重。通過建設智慧交通系統來有效緩解交通擁堵和減少交通事故受到了廣泛關注,其中準確預測實時交通流量至關重要。
交通流量預測模型通常可以分為兩類:參數化模型和非參數化模型。早期的交通流預測研究主要是參數化模型如歷史平均模型(HA)、自回歸移動平均模型(ARMA)[1]、差分整合滑動平均自回歸模型(ARIMA)和季節性ARIMA模型(SARIMA)[2]等,這類模型適用于處理線性關系和變化模式相對簡單的交通流量數據,通常無法捕捉復雜的時間序列數據。隨著數據存儲和計算的改進,非參數化模型在交通流量預測中取得了更好的效果,主要包括機器學習和深度學習模型等。其中機器學習模型有K最近鄰(KNN)[3]、隱馬爾可夫(HMM)、支持向量機(SVM)[4]等,其缺點是無法自動提取數據中的非線性特征。近年來,基于深度學習模型的交通流預測取得了巨大成功,如深度置信網絡(DBN)、長短期記憶網絡(LSTM)、卷積神經網絡(CNN)[5]和圖卷積神經網絡(GCN)[6]等能夠提取交通流量數據的復雜時空特征,顯著提高了預測準確性。
目前,大多數交通流量預測方法都采用集中式訓練和預測,先由客戶端將收集的原始交通流量數據上傳到云數據中心進行模型訓練,然后將預測結果發送給客戶端。上傳原始交通流量數據極易導致信息泄露,引起隱私和安全問題。鑒于現在國家、企業和個人對數據安全以及數據隱私保護的重視程度越來越高,數據存儲本地化引發的“數據孤島”問題愈發嚴重。谷歌在2016年提出了聯邦學習(FL)方法,可在分布式節點之間進行本地協作式訓練,旨在確保數據交換期間的信息安全和客戶端數據隱私。
本文為了實現交通流預測中的數據隱私保護,并提高預測準確性,提出了一種基于聯邦學習和圖卷積神經網絡(GCN)的交通流預測方法,下面進行詳細介紹。
1 基于聯邦學習的交通流預測系統架構
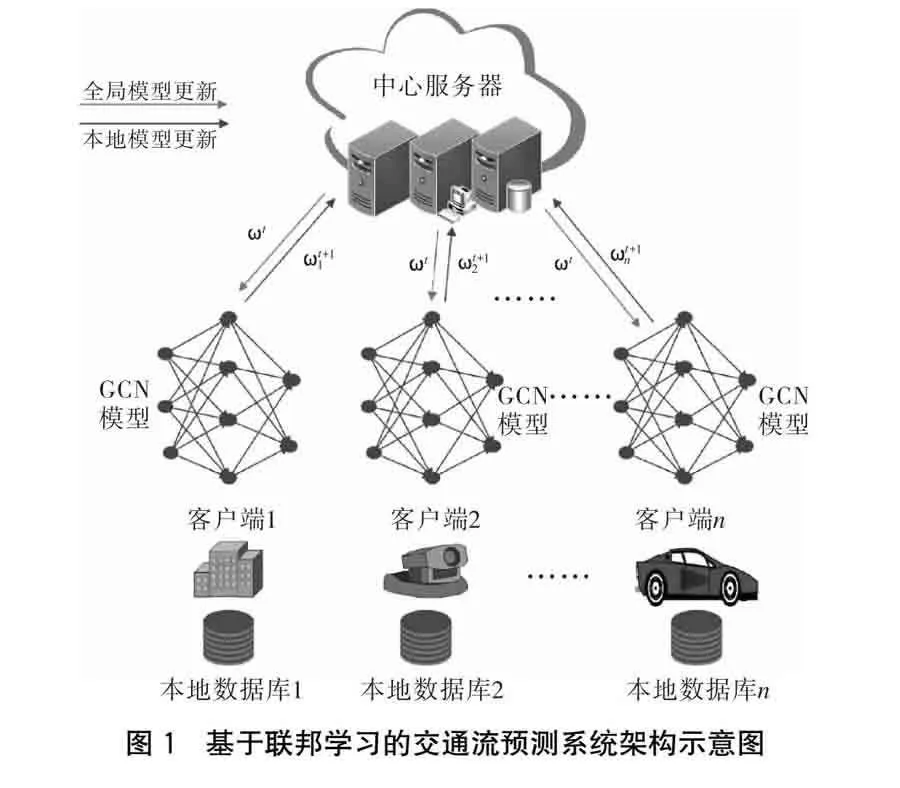
在交通流預測系統中,為了解決“數據孤島”問題,采用聯邦學習可以使各個客戶端(如交通管理部門、出租車企業、移動設備、車輛、手機等)在保持數據本地化的同時,通過聯合訓練可以得到一個全局交通流量預測模型。聯邦學習系統包含的關鍵組件有中心服務器、客戶端、隱私保護機制、局部模型和全局模型等。該系統架構如圖1所示。
2 基于FL-GCN的交通流預測模型
本文采用圖卷積神經網絡(GCN)模型對交通網絡進行建模,提取每個監測點的歷史交通流數據特征,然后使用聯邦學習,并在客戶端模型訓練時給梯度添加高斯噪聲實現差分隱私,通過分布式聯合訓練,最終得到收斂的全局交通流預測模型。構建FL-GCN交通流預測模型的方法和步驟如下。
基于聯邦學習和圖卷積神經網絡的交通流預測研究/
劉 華,儲蓄蓄
2.1 交通網絡建模
現有的圖卷積網絡(GCN)在處理大型交通網絡時,需要構建一個詳盡的鄰接矩陣來捕捉復雜的網絡拓撲,這給模型帶來了巨大的計算負擔,無法發揮聯邦學習分布式訓練的優勢。針對該問題,本文采用了Metis圖分割算法將交通網絡劃分為多個子圖,通過將圖中的頂點分割成多個簇,使得每個簇內的連接盡可能多,而簇間的連接盡可能少,這種劃分更能保留子圖內的時空相關性,有助于保持模型的預測準確性。
將整個交通網絡定義為一個無向圖G=(V,E,A),其中V表示道路上的節點或傳感器{v1,v2,…,vn};E是圖中的邊集合,表示節點之間的連通性;A是加權鄰接矩陣,Ai,j表示節點vi和vj之間是否存在邊(如果有邊則為1,否則為0);Di,i則是節點vi的度,即節點vi連接的總邊數,Di,i=∑nj=1Ai,j。交通網絡可以進一步劃分為子圖,設G=(G1,G2,…,Gm),每個子圖的中心節點設為Zc,可以收集和聚合來自子圖中其他節點的數據。交通網絡的GCN模型計算公式如式(1)~(3)所示。
H(l+1)=σ(A︿Hlwl)
(1)
M~=D-1~/2A︿D-1~/2
(2)
M~=A+IN
(3)
式中:wl——特定層l的可訓練權重矩陣;
Hl——第l層的激活函數,如ReLU。
交通流數據通常包括監測點的車輛數量、速度、密度等相關信息,設在時間點t,路網時空圖G上的交通流量為Xt∈Rn×r,n為圖G的節點數,r為采集到的交通流特征維數,則交通流的兩層GCN預測模型如式(4)所示。
fA,Xt=σA︿Hlwl=σA︿ReLUA︿XW0w1
(4)
式中:W0和W1——第一層和第二層的權重矩陣。
2.2 差分隱私實現
聯邦學習雖然在保護數據隱私方面提供了一種有效的解決方案,但并不完美,仍然存在一些潛在的風險。參與方有可能通過分析上傳的模型參數來推斷出其他參與方的原始訓練數據,攻擊類型包括成員推理攻擊、模型反演攻擊、數據的推理重建,以及基于生成對抗網絡(GANs)的攻擊等。差分隱私是一種加強保護用戶數據隱私的方法,核心思想是在處理包含個人隱私信息的數據集時引入一定噪聲,使得攻擊者無法準確識別出任何單個個體的具體信息。本文在客戶端本地GCN模型訓練反向傳播過程中,給梯度添加高斯噪聲來實現差分隱私,具體的定義如下:
設有一個定義域為Nx的隨機算法M,若對于任意兩個至多相差1條記錄的鄰近數據集D和D′都滿足式(5),則稱算法M滿足(ε,δ)差分隱私。
PrMD∈S≤eεPrMD′∈S+δ
(5)
參數ε被定義為隱私預算,參數δ則為松弛項,當δ=0時,該定義為嚴格的差分隱私定義。ε越小,算法保護隱私能力越強,但同時也會降低模型的準確性。拉普拉斯機制和高斯機制是常用的兩種差分隱私噪聲機制,高斯機制更為松弛,在實現隱私保護的基礎上也能兼顧準確性,算法M定義如下:
M(D)=f(D)+N(0,σ2)
(6)
σ≥Δf2log 1.25δε
(7)
Δf=maxD~D′‖f(D)-f(D′)‖2
(8)
式中:Δf——全局敏感度;
N(0,σ2)——服從高斯分布的隨機噪聲。
2.3 聯邦學習策略
聯邦學習有兩類實體,分別是客戶端和中心服務器。客戶端是參與協作模型訓練的數據所有者,中心服務器則負責協調整個訓練過程和模型參數的聚合工作。設交通網絡中存在N個客戶端,Dk表示客戶端自己的數據集,ωn表示客戶端n的模型參數,ω表示所有客戶端共同訓練的模型參數。中心服務器與所有參與第t輪學習的客戶端共享全局模型ωt,客戶端n使用梯度下降等優化算法更新本地模型參數公式如下:
(9)
式中:fn(ω)——客戶端n的損失函數;
η——一個固定的學習率。
第t輪聯邦學習中心服務器的模型更新公式如下:
ωt=∑Nk=1DkDωtk
(10)
聯邦學習的目標是最小化全局損失函數,從而找到一個最優化的模型ω*。pk是客戶端k聚合時的權重,計算公式如下:
ω*=argminω fD,ω=argminω∑Nk=1pkfk(Dk,ω)
(11)
2.4 聯邦學習算法
基于FL-GCN的交通流預測算法完整流程如下:
輸入:交通網絡模型G,交通流量數據Xt,子圖數量m,中心節點Zc,本地訓練輪數E。
輸出:全局最優模型ω*。
(1)交通網絡圖分割:將G劃分為m個子圖:G=(G1,G2,…,Gm),每個子圖Gi與一個中心節點Zc相關聯。
(2)在中心服務器端初始化全局模型參數 ω0。
(3)隨機選擇客戶端子集Ck。
(4)對每個客戶端并行執行子模型初始化。
(5)對于每個訓練輪次t=1到E:選擇一部分中心節點Zc參與當前訓練周期。
(6)將當前的全局模型參數ωt發送給所有參與的Zc。
(7)在Zc上使用本地交通流量數據Xt進行模型訓練,并計算局部模型參數ωtn。
(8)本地迭代結束后,客戶端將計算得到的局部最優模型參數ω*n發送給中心服務器。
(9)中心服務器收集所有客戶端的模型參數,并進行聚合操作得到新的ωt。
(10)重復步驟(3)~(9),直到全局模型收斂或達到預定的通信輪次。
通過實踐以上步驟,算法能夠在GCN模型上進行聯邦學習,最終得到較優的全局交通流預測模型。
3 試驗結果分析
為了驗證本文模型的有效性,使用LibCity[7]交通預測庫進行統一模型評估,其中與交通流量預測相關的模型共15個。進行試驗的交通流量數據集采用美國加州交通管理系統提供的標準化公開數據集PeMSD4,其中包含29條道路上的3 848個傳感器監測的車輛流量占用信息,選取的數據時間段為2018-01-01至2018-02-28。試驗環境為Win10操作系統計算機(Intel Core(TM)i7-9700處理器,內存為32 G),并開啟了GPU加速進行模型訓練。
模型評估指標使用均方誤差(MSE)、平均絕對百分比誤差(MAPE)和均方根誤差(RMSE)來衡量預測模型的性能,其數值越小,預測效果越好。MSE、MAPE和RMSE的計算公式如式(12)~(14)所示。
MSE=1n∑ni-1yi-y︿i2
(12)
MAPE=100%n∑ni-1yi-y︿iyi
(13)
RMSE= 1n∑ni=1yi-y︿i2
(14)
式中:n——樣本的數量;
yi——實際值;
y︿i——預測值。
如表1所示,在同樣的試驗環境下對比本文設計的FL-GCN模型與三個基準模型(FNN、TGCN、STTN)的性能,FL-GCN模型在三個評估指標上都有所降低,表明該模型有更小的誤差,驗證了FL-GCN模型預測交通流量的有效性。
4 結語
本文結合了聯邦學習和圖卷積神經網絡的優勢,提出了基于FL-GCN的交通流量預測模型。聯邦學習方法通過在客戶端訓練模型并只共享模型更新,對原始數據也進一步引入了差分隱私技術,有效增強了對用戶數據隱私的保護。GCN尤其適合處理圖結構數據,能夠很好地捕捉交通網絡中的復雜時空依賴關系。試驗結果表明,該方法提高了交通流預測的安全性和準確性。
聯邦學習方法需要在客戶端和中心服務器之間頻繁交換模型參數,在大規模部署時可能導致顯著的通信成本支出。客戶端的數據往往是異構的,也會導致模型訓練的不均衡和性能下降。未來的研究要繼續開發更高效的算法、改進通信協議、增強模型的魯棒性,提高模型的收斂性和泛化能力。
參考文獻
[1]楊高飛,徐 睿,秦 鳴,等.基于ARMA和卡爾曼濾波的短時交通預測[J]. 鄭州大學學報(工學版),2017,38(2):36-40.
[2]孫湘海,劉潭秋.基于SARIMA模型的城市道路短期交通流預測研究[J].公路交通科技,2008(1):129-133.
[3]劉 釗,杜 威,閆冬梅,等.基于K近鄰算法和支持向量回歸組合的短時交通流預測[J].公路交通科技,2017,34(5):122-128,158.
[4]楊 剛,王 樂,戴麗珍,等.自適應權重粒子群優化LS-SVM的交通流預測[J].控制工程,2017,24(9):1 838-1 843.
[5]晏 臻,于重重,韓 璐,等.基于CNN+LSTM的短時交通流量預測方法[J].計算機工程與設計,2019,40(9):2 620-2 624,2 659.
[6]陳喜群,周凌霄,曹 震.基于圖卷積網絡的路網短時交通流預測研究[J].交通運輸系統工程與信息,2020,20(4):49-55.
[7]Wang J,Jiang J,Jiang W,et al.LibCity:An Open Library for Traffic Prediction[C].Proceedings of the 29th International Conference on Advances in Geographic Information Systems,2021.
