基于YOLOv8-seg的巖心CT圖像顆粒目標(biāo)提取算法
2025-02-10 00:00:00郭俊青何小海滕奇志呂朝陽


關(guān)鍵詞: YOLOv8-seg; 巖心CT 圖像; 顆粒目標(biāo)提取
1 引言
巖心顆粒的結(jié)構(gòu)與形態(tài)的研究不僅對(duì)研究巖層的演化過程[1]、形成環(huán)境、形成機(jī)制有重要的意義,也有助于研究巖層的沉積特性[2]和土壤的侵蝕特性[3]. 近年來,隨著數(shù)字巖心技術(shù)的快速發(fā)展及計(jì)算機(jī)斷層掃描技術(shù)(Computer Tomography, 簡稱CT)的廣泛應(yīng)用,巖心CT 數(shù)字圖像處理技術(shù)不僅允許研究者分析單一截面內(nèi)的顆粒細(xì)節(jié),而且通過運(yùn)用三維重建技術(shù),使得構(gòu)建三維顆粒模型并在三維空間中進(jìn)行顆粒信息分析成為可能,為深入理解巖石內(nèi)部顆粒結(jié)構(gòu)提供了一種新的途徑[4].
但是在將射線數(shù)據(jù)重構(gòu)為巖心CT 圖像的過程中,噪聲的引入不可避免,當(dāng)前的巖心CT 成像技術(shù)因此面臨著圖像質(zhì)量不佳、含有不同強(qiáng)度噪聲以及信噪比較低的挑戰(zhàn). 并且,由于CT 數(shù)據(jù)的采集基于對(duì)巖心樣本的恒定功率掃描,無法確保樣本顆粒與背景之間的適宜對(duì)比度,存在著灰度級(jí)范圍的重疊現(xiàn)象,特別是在中心區(qū)域的亮度值往往高于周圍區(qū)域,這導(dǎo)致使用基于閾值分割等傳統(tǒng)圖像處理方法時(shí)容易發(fā)生過度分割或欠分割的問題.
隨著圖像處理技術(shù)的演進(jìn),眾多算法已被應(yīng)用于CT 圖像顆粒分割這一關(guān)鍵領(lǐng)域. 高揚(yáng)等[5]采用模糊距離變換方法對(duì)巖心圖像顆粒進(jìn)行分割,該方法有效識(shí)別粘連顆粒,但分割得到的顆粒邊緣缺乏平滑性. Wang 等[6]基于Otsu 法的基本原理,提出依據(jù)煤體CT 圖像中不同礦物組分和孔裂縫結(jié)構(gòu),選擇不同閾值公式的MP-Otsu 閾值分割法,提高了CT 技術(shù)在觀測煤體微觀組分領(lǐng)域的準(zhǔn)確性. 吳未等[7]提出一種邊界勾勒算法,通過彈性膠囊算法獲取單顆粒在分水嶺算法唯一種子點(diǎn),從而獲取炸藥CT 圖像單像素顆粒邊界,有較高的算法自動(dòng)化程度,大大縮減人力成本. Wang 等[8]通過分析煤巖CT 圖像灰度分布特征,提出了灰度束閾值分割方法,該方法相比其他射束閾值分割方法,更加便于操作和準(zhǔn)確. Pandey 等[9]提出一種基于Morse 理論的框架,用于分割CT 圖像顆粒并計(jì)算顆粒集合的結(jié)構(gòu)和相對(duì)排列,該方法相比分水嶺算法,能取得更高質(zhì)量的細(xì)粒度集合分割. 這些研究針對(duì)CT 圖像顆粒分割提出了各類解決思路,在提高CT 圖像顆粒分割提取效率方面取得了進(jìn)展.
在近年來的研究進(jìn)展中,深度學(xué)習(xí)技術(shù)通過整合底層特征至高層抽象信息,有效地解決了自動(dòng)特征學(xué)習(xí)的難題. Yann 等[10]開發(fā)的卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,簡稱CNN)為自然圖像分割領(lǐng)域提供了一種新的思路,相比傳統(tǒng)方法展現(xiàn)出更佳的性能. CNN 作為一種包含卷積計(jì)算并具備深度結(jié)構(gòu)的前饋神經(jīng)網(wǎng)絡(luò),在圖像分割任務(wù)上的成就促使研究者越來越多地采用此技術(shù)[11]. Lin 等[12]引入的特征金字塔網(wǎng)絡(luò)(FeaturePyramid Networks,簡稱FPN)采用特征金字塔結(jié)構(gòu),解決了小目標(biāo)檢測中多尺度變換的挑戰(zhàn),同時(shí)保持了較低的計(jì)算成本. He 等[13]提出的Mask RCNN,通過將目標(biāo)檢測和語義分割結(jié)合起來,與傳統(tǒng)的Faster R-CNN[14]相比,新增了一個(gè)預(yù)測分割mask 的分支,證明了網(wǎng)絡(luò)能夠同時(shí)學(xué)習(xí)兩項(xiàng)任務(wù),并實(shí)現(xiàn)相互促進(jìn). Strudel 等[15]探索將Transformer模塊引入圖像分割領(lǐng)域,這一創(chuàng)新嘗試突破了CNN 在訪問圖像全局信息方面的局限性,為圖像分割技術(shù)提供了新的方向. Tang 等[16]使用Transformer模塊結(jié)合多尺度空洞卷積和注意力機(jī)制,解決顆粒之間長距離依賴問題,提高了網(wǎng)絡(luò)對(duì)于顆粒邊緣特征的提取能力. Manzoor 等[17]使用Seg?Net 實(shí)現(xiàn)對(duì)于不同類別顆粒之間的識(shí)別與分割. 這些進(jìn)展不僅展示了深度學(xué)習(xí)在圖像分割領(lǐng)域的潛力,也為未來的研究開辟了新的路徑.
但是,針對(duì)噪點(diǎn)多、對(duì)比度低、光照不均、顆粒粘連甚至難以肉眼區(qū)分的巖心CT 圖像顆粒的分割,這些模型均很難取得較好的分割效果. 而YOLO(You Only Look Once)系列自從2015 年由Redmon 等[18]提出后,經(jīng)過多代的改進(jìn),并且在v5之后引入實(shí)例分割后,v8 又在實(shí)例分割方面實(shí)現(xiàn)了較大的突破. YOLOv8 相較于原來的anchorbased檢測方法,它所采用的anchor-free 方法具有更高的檢測精度和檢測速度. 但是在實(shí)際復(fù)雜實(shí)例分割任務(wù)中,僅僅使用 YOLOv8 分割算法仍存在著定位誤差和對(duì)目標(biāo)感知能力不足等缺點(diǎn). Yue等[19]用RepBlock 模塊代替C2f 模塊,在特征融合網(wǎng)絡(luò)中的2 次上采樣之前添加SimConv 卷積代替剩余的傳統(tǒng)卷積,提出了一種改進(jìn)的YOLOv8-seg網(wǎng)絡(luò),實(shí)現(xiàn)準(zhǔn)確地分割受病害的番茄. 譚旭等[20]基于YOLOv8 提出了改進(jìn)的實(shí)例分割模型EISYOLO,在汽車傷損實(shí)例分割方面實(shí)現(xiàn)了模型輕量的同時(shí)也提高了小目標(biāo)傷損及傷損邊緣的精確識(shí)別. Pandey 等[21]結(jié)合Segment Anything Mode(l 簡稱SAM)提出了YOLOv8+SAM 的模型,在醫(yī)學(xué)圖像分割表現(xiàn)出了更高的分割精度和整體性能.
本文針對(duì)上述巖心CT 圖像顆粒目標(biāo)提取中存在的分割困難問題,基于YOLOv8-seg 的改進(jìn),提出了融合CBAM[22]和BoTNet[23]的多頭處理模塊CBoTNet,使用Wise-IoU[24] 損失函數(shù)替換CIoU[25]損失函數(shù),提高模型的泛化能力和目標(biāo)檢測分割精度.
2 基于改進(jìn)YOLOv8-seg 的顆粒目標(biāo)提取算法
2. 1 YOLOv8-seg 網(wǎng)絡(luò)模型
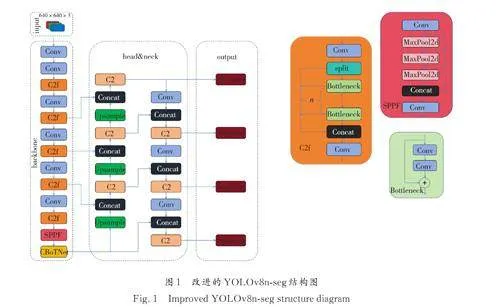
YOLOv8-seg 算法模型[26]分為input 端、backbone端、headamp;neck 端和output 端. 在input 端使用Mosaic 數(shù)據(jù)增強(qiáng)、自適應(yīng)圖片縮放和灰度填充等操作進(jìn)行圖片的預(yù)處理;backbone 端通過Conv、C2f、SPPF 結(jié)構(gòu)進(jìn)行卷積、池化,在殘差連接的同時(shí)加入跳層連接實(shí)現(xiàn)特征融合,并且在輕量化的同時(shí)包含豐富的梯度流信息;headamp;neck 端通過Upsample、Concat、C2 模塊通過上、下采樣,實(shí)現(xiàn)特征拼接;output 端使用segment 解耦頭,每個(gè)尺度都有獨(dú)立的檢測器,每個(gè)檢測器由一組卷積和全連接層組成,用于預(yù)測該尺度上的邊界框.
YOLOv8-seg 損失函數(shù)由四部分組成,分別是分割損失BCEWithLogitsLoss(BCELoss+sigmoid)、分類損失BCEWithLogitsLoss(繼承目標(biāo)檢測任務(wù))和邊界框回歸損失(CIoU Loss 和DFLLoss).
2. 2 改進(jìn)的YOLOv8-seg 網(wǎng)絡(luò)模型
由于巖心CT 圖像通常是以組為單位的需要同時(shí)處理大量圖像的序列圖,因此本文使用參數(shù)量小、檢測速度快的YOLOv8n-seg 網(wǎng)絡(luò)模型. 本文提出的改進(jìn)模型在backbone 端加入CBoTNet模塊,并在邊界框回歸損失中將CIoU 替換為Wise-IoU,針對(duì)自建巖心數(shù)據(jù)集粘連分割問題提升明顯,其網(wǎng)絡(luò)如圖1 所示.
2. 2. 1 CBoTNet 模塊 在巖心CT 圖像中,往往會(huì)因?yàn)閳D像中存在的大量噪聲破壞像素之間的依賴關(guān)系,模型的檢測識(shí)別和分割能力也會(huì)大幅下降,從而導(dǎo)致漏檢和錯(cuò)檢的產(chǎn)生.
引入注意力機(jī)制模塊,可以有效的提取有用的特征信息,提高模型性能. 比較典型的注意力機(jī)制包括自注意力機(jī)制、空間注意力機(jī)制和通道注意力機(jī)制.
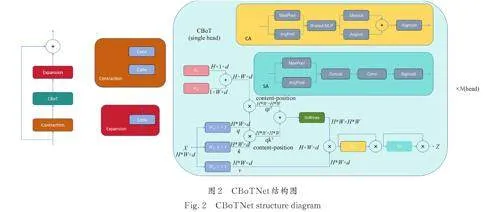
本文使用的CBoTNet 結(jié)合了多頭自注意力機(jī)制、空間注意力機(jī)制和通道注意力機(jī)制. 多頭自注意力機(jī)制使模型能夠同時(shí)關(guān)注圖像的多個(gè)區(qū)域,提取不同區(qū)域的特征,并對(duì)這些特征進(jìn)行整合;空間注意力機(jī)制通過對(duì)圖像中的特定區(qū)域進(jìn)行重點(diǎn)處理,使模型能夠更加關(guān)注于圖像中潛在的重要部分;通道注意力機(jī)制關(guān)注不同通道的特征,能夠強(qiáng)化對(duì)特定特征的識(shí)別,如顏色、紋理等. 這三者結(jié)合可以使模型不僅能夠關(guān)注單個(gè)維度的特征(如僅空間或通道),而且能夠全面地理解和分析圖像數(shù)據(jù),從而提供更準(zhǔn)確的檢測和分割結(jié)果.
CBoTNet 的結(jié)構(gòu)如圖2 所示,輸入經(jīng)過Contraction之后得到的X 是一個(gè)H×W×d 的張量,代表從之前層中學(xué)到的特征. 其中,H 和W 代表空間維度,即圖像的高度和寬度,而d 代表特征維度或通道數(shù). 輸入特征圖X 首先通過3 個(gè)不同的1×1卷積層(或線性層),轉(zhuǎn)換為3 個(gè)新的特征集:查詢(Q),鍵(K),和值(V). 這些1×1 卷積層相當(dāng)于對(duì)特征進(jìn)行線性變換,其權(quán)重矩陣分別為 WQ,WK,WV. 位置信息以2 個(gè)獨(dú)立的編碼Rh 和Rw 形式融入,分別代表垂直和水平方向的位置信息,這些編碼相加后,引入位置信息r 以保持空間關(guān)系. 位置信息r 通過與輸入特征圖相乘的形式加入到轉(zhuǎn)換后的Q 特征中,形成內(nèi)容-位置編碼qrT. 查詢(Q)和鍵(K)進(jìn)行點(diǎn)積,生成一個(gè)注意力得分矩陣,形成內(nèi)容-內(nèi)容編碼qkT,表示特征之間的相互關(guān)系.這個(gè)得分矩陣的大小為H*W×H*W,其中H*W 是展平后的空間維度,代表每個(gè)位置與其他所有位置的關(guān)系強(qiáng)度. 兩個(gè)矩陣qrT 和qkT 相加,意味著模型在計(jì)算注意力得分時(shí)同時(shí)考慮了內(nèi)容的相似性和位置關(guān)系. 通過這種方式,自注意力機(jī)制不僅能夠識(shí)別特征內(nèi)容的相關(guān)性,還能保持空間或序列的結(jié)構(gòu)信息. 這個(gè)合并的注意力得分矩陣將通過softmax 函數(shù)進(jìn)行歸一化,并用于加權(quán)值(V)向量,生成加權(quán)的特征表示F. 自注意力后的特征F 送入通道注意力(CA)模塊,在此模塊中,特征圖首先通過最大池化和平均池化操作,以產(chǎn)生全局空間信息的兩個(gè)描述. 這兩個(gè)描述共享一個(gè)多層感知機(jī)(MLP),該MLP 有一個(gè)隱藏層(通常包含ReLU激活函數(shù)). MLP 的輸出是兩個(gè)通道注意力圖,這兩個(gè)圖隨后會(huì)通過元素加法操作合并. 最后,通過sigmoid 激活函數(shù)得到最終的通道注意力圖,該注意力圖通過廣播機(jī)制與原始輸入特征圖相乘,對(duì)每個(gè)通道的特征進(jìn)行加權(quán),得到特征圖F'. 特征圖F'再進(jìn)入空間注意力(SA)模塊,經(jīng)過通道軸上的最大池化和平均池化,將通道信息壓縮成2 個(gè)二維圖. 這2 個(gè)圖像隨后被合并(通常是通過串聯(lián)),并通過一個(gè)卷積層來生成一個(gè)二維的空間注意力圖. 空間注意力圖通過sigmoid 函數(shù)激活,再用來對(duì)輸入特征圖進(jìn)行加權(quán),生成特征圖Z,最后通過Expansion 得到最終結(jié)果. 一個(gè)單頭的描述至此,而CBoTNet 使用的是多頭結(jié)構(gòu),并會(huì)將以上過程復(fù)制多次,本文多頭的數(shù)量取值為4,每個(gè)頭關(guān)注輸入數(shù)據(jù)的不同方面. 然后,所有頭的輸出會(huì)被合并或拼接起來,形成一個(gè)更為全面的輸出特征表示,這樣就可以在處理后續(xù)任務(wù)時(shí)提供更豐富的信息.網(wǎng)絡(luò)對(duì)該區(qū)域的關(guān)注度越高,在網(wǎng)絡(luò)學(xué)習(xí)中更關(guān)鍵. layer4 和layer13 分別為選取圖像經(jīng)過網(wǎng)絡(luò)第4和第13 層后的熱力圖,其中l(wèi)ayer13 為是否使用CBoTNet 的對(duì)比熱力圖. result 為上述兩個(gè)網(wǎng)絡(luò)的結(jié)果圖,圖中紅色圈區(qū)域?yàn)閷?duì)比區(qū)域. 由圖3 的layer4、layer13 和result 可知,在layer4 中,是否使用CBoTNet 熱力圖相似;在layer13 中,不使用CBoTNet 模塊相比使用CBoTNet 模塊,其特征信息會(huì)大量丟失,此處在result 中表現(xiàn)為邊緣特征流失,顆粒之間存在粘連. 因此通過加入CBoTNet,可以讓網(wǎng)絡(luò)學(xué)習(xí)到更多顆粒的特征信息,并加強(qiáng)顆粒目標(biāo)檢測和分割.
2. 2. 2 損失函數(shù)改進(jìn) 在目標(biāo)檢測和實(shí)例分割任務(wù)中,邊界框回歸損失函數(shù)的設(shè)計(jì)對(duì)于提升模型性能至關(guān)重要. YOLOv8-seg 的邊界框回歸損失函數(shù)CIoU,通過預(yù)測框和真實(shí)框的重疊面積、中心點(diǎn)距離和長寬比來計(jì)算損失, 公式如下:
其中,Bgt表示真實(shí)框,Bpred表示預(yù)測框,ρ2 ( Bgt,Bpred )表示預(yù)測框和真實(shí)框中心點(diǎn)的歐氏距離,C 表示能夠包含預(yù)測框和真實(shí)框的最小外接矩形的對(duì)角線長度,α 表示平衡參數(shù),ν 用來衡量長寬比是否一致.
盡管CIoU 針對(duì)目標(biāo)的位置和形狀提供了一種比較精確的回歸策略,但是是在假設(shè)訓(xùn)練數(shù)據(jù)的質(zhì)量較高的前提下. 實(shí)際的目標(biāo)檢測分割訓(xùn)練集常含有質(zhì)量較低的樣本,過分強(qiáng)調(diào)這些低質(zhì)量樣本的邊界框回歸會(huì)對(duì)模型的性能提升造成負(fù)面影響. 如果預(yù)測框和gt 框的長寬比是相同的,那么長寬比的懲罰項(xiàng)恒為0,并且,長和寬的梯度是一對(duì)相反數(shù),兩者不能同時(shí)增大或減小,存在縱橫比模糊的問題.
針對(duì)這一問題,Zhang 等[27]提出了Focal-EIoU,在 CIOU 的懲罰項(xiàng)基礎(chǔ)上將預(yù)測框和真實(shí)框的縱橫比的影響因子拆開,分別計(jì)算預(yù)測框和真實(shí)框的長和寬,來解決 CIOU 存在的問題,并且加入FocalLoss[28],通過修改交叉熵?fù)p失,增加了一個(gè)調(diào)整因子,來解決在某些訓(xùn)練情境下,尤其在一些目標(biāo)檢測任務(wù)中,背景樣本數(shù)量遠(yuǎn)大于前景樣本數(shù)量時(shí),即正負(fù)樣本數(shù)量不平衡的問題,提升了對(duì)小目標(biāo)或者在復(fù)雜環(huán)境下的檢測性能. Gevorgyan[29]在EIoU 基礎(chǔ)上提出了SIoU,通過融入角度考慮和規(guī)模敏感性,引入了一種更為復(fù)雜的邊界框回歸方法,解決了以往損失函數(shù)的局限性,SIoU損失函數(shù)包含四個(gè)組成部分:角度損失、距離損失、形狀損失和第4 個(gè)未指定的組成部分. 通過整合這些方面,從而實(shí)現(xiàn)更好的訓(xùn)練速度和預(yù)測準(zhǔn)確性.
但是,這些方法都是通過聚焦機(jī)制提升了對(duì)較難樣本的識(shí)別能力,但其聚焦機(jī)制是靜態(tài)的,未能充分利用非單調(diào)聚焦機(jī)制的潛力. 基于此,Tong 等[24]提出了一種動(dòng)態(tài)非單調(diào)聚焦機(jī)制,并設(shè)計(jì)了名為 Wise-IoU( WIoU) 的新型損失函數(shù),公式如下:
其中,點(diǎn)(x,y)、(xgt,ygt)分別表示預(yù)測框中心坐標(biāo)和真實(shí)框中心坐標(biāo),Wg 和Hg 表示預(yù)測框和真實(shí)框最小外接矩形的長和寬,Su表示預(yù)測框和真實(shí)框的并集.
WIoUv1 構(gòu)造了基于距離注意力的邊界框損失;WIoUv2 在v1 基礎(chǔ)上構(gòu)造了單調(diào)聚焦系數(shù),從而提高對(duì)復(fù)雜目標(biāo)的分類識(shí)別能力;WIoUv3 則是在v1 基礎(chǔ)上采用“ 離群度”代替?zhèn)鹘y(tǒng)的交并比(IoU)來評(píng)估錨框的質(zhì)量,并引入了一種動(dòng)態(tài)的梯度增益分配策略. 該策略在降低高質(zhì)量錨框的優(yōu)勢的同時(shí),減少了由低質(zhì)量樣本產(chǎn)生的有害梯度,從而使WIoUv3 能夠更有效地關(guān)注普通質(zhì)量的錨框,提升檢測器的整體性能.
3 實(shí)驗(yàn)與結(jié)果分析
3. 1 實(shí)驗(yàn)環(huán)境和參數(shù)設(shè)置
實(shí)驗(yàn)在Windows10 系統(tǒng)上運(yùn)行,內(nèi)存128 GB,CPU 為Intel(R) Core(TM) i9-12900K,GPU 為NVIDIA GeForce RTX 3060,顯存為12GB,采用的深度學(xué)習(xí)框架為Pytorch2. 2. 1,CUDA 版本為12. 1,編譯語言為python3. 10. 13. 采用YOLOv8nseg作為基底網(wǎng)絡(luò)模型,輸入圖片大小為640×640.
3. 2 實(shí)驗(yàn)數(shù)據(jù)集
本文數(shù)據(jù)集采用計(jì)算機(jī)斷層掃描技術(shù)(CT)獲得的多組巖心序列圖,從6 組巖心CT 序列圖像中各選取了800 幅圖像,按照7∶3 的比例劃分訓(xùn)練集和驗(yàn)證集,共制作了4800 幅圖像. 為了防止過擬合,另選2 組巖心CT 序列圖像共計(jì)1600 幅圖像制作成數(shù)據(jù)集作為測試集.
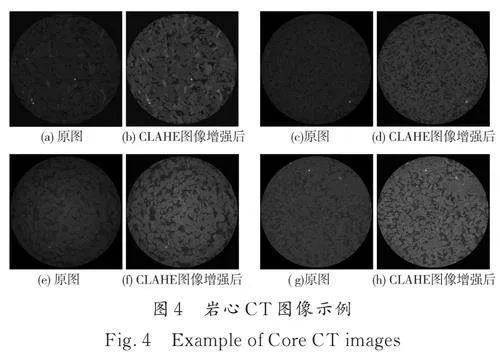
由于使用CT 掃描時(shí)會(huì)不可避免的引入噪聲使得巖心CT 序列圖存在噪點(diǎn)多、亮度不均、對(duì)比度低等問題,從而影響訓(xùn)練效果,因此本文使用對(duì)比度受限的自適應(yīng)直方圖均衡化(Contrast LimitedAdaptive Histogram Equalization, 簡稱CLAHE)[30]對(duì)圖像進(jìn)行增強(qiáng),得到去除陰影環(huán)、亮度矯正后的圖像,如圖4 所示. 訓(xùn)練之前再通過垂直翻轉(zhuǎn)、水平翻轉(zhuǎn)、對(duì)比度調(diào)整等操作進(jìn)一步圖像增強(qiáng),從而實(shí)現(xiàn)數(shù)據(jù)集拓展,提高模型泛化能力.
3. 3 評(píng)價(jià)指標(biāo)
實(shí)驗(yàn)采用精確率(Precision)、召回率(Recall)、mAP50 和mAP50: 95 評(píng)價(jià)模型精度,采用模型內(nèi)存占用大小(Model size)、模型參數(shù)量(Param)、每秒浮點(diǎn)運(yùn)算次數(shù)(FLOPs)和每秒檢測圖片數(shù)量(FPS)來衡量模型復(fù)雜度.
其中,TP 表示預(yù)測為正且正確的正樣本數(shù)量,F(xiàn)P表示預(yù)測為正且錯(cuò)誤的負(fù)樣本數(shù)量,F(xiàn)N 表示預(yù)測為負(fù)且錯(cuò)誤的正樣本數(shù)量.
3. 4 改進(jìn)實(shí)驗(yàn)效果對(duì)比
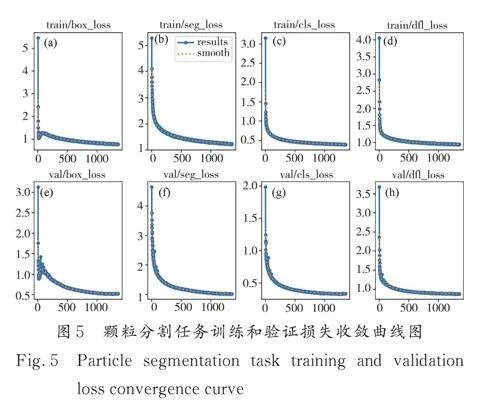
本文模型在顆粒分割的訓(xùn)練任務(wù)中的訓(xùn)練和驗(yàn)證損失收斂曲線如圖5,結(jié)果表明改進(jìn)的YOLOv8n-seg 網(wǎng)絡(luò)可以有效收斂.
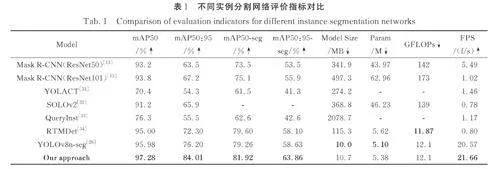
3. 4. 1 不同網(wǎng)絡(luò)效果及模型復(fù)雜度對(duì)比 為了客觀驗(yàn)證模型改進(jìn)效果的可行性,使用了相同數(shù)據(jù)集經(jīng)過CLAHE 進(jìn)行圖像增強(qiáng)后,分別在MaskR-CNN[13] 、YOLACT[31] 、SOLOv2[32] 、Query?Inst[33]、RTMDet[34]等實(shí)例分割網(wǎng)絡(luò)上進(jìn)行對(duì)比實(shí)驗(yàn).
由表1 可知,改進(jìn)后的YOLOv8n-seg 網(wǎng)絡(luò)不僅繼承了原網(wǎng)絡(luò)的小模型計(jì)算量,并且在檢測和分割的精確度mAP50 和mAP50:95 上均達(dá)到了最高. 相比于Mask R-CNN(ResNet50)這些指標(biāo)分別提高了4. 08%、20. 51%、8. 42%、10. 36%;相比于Mask R-CNN(ResNet101)這些指標(biāo)分別提高了4. 68%、16. 81%、6. 82%、7. 96%;相比于YOLACT 這些指標(biāo)分別提高了26. 88%、29. 71%、20. 42%、22. 56%;相比于SOLOv2 這些指標(biāo)分別提高了6. 08%、18. 11%;相比于Query?Inst 這些指標(biāo)分別提高了20. 98%、28. 51%、19. 32%、21. 26%;相比于RTMDet 這些指標(biāo)分別提高了2. 28%、11. 71%、2. 32%、5. 76%;相比于原網(wǎng)絡(luò)YOLOv8n-seg 這些指標(biāo)分別提高了1. 30%、7. 81%、2. 66%、5. 23%.
在模型復(fù)雜度方面,本文選取648 張測試集圖片在同一硬件條件下進(jìn)行測試. 由表1 可知,YOLOv8n-seg 與RTMDet 參數(shù)量Param 和每秒浮點(diǎn)運(yùn)算次數(shù)(FLOPs)相近,但是YOLOv8n-seg 每秒檢測圖片數(shù)量(FPS)遠(yuǎn)優(yōu)于RTMDet,且實(shí)際分割效果也優(yōu)于RTMDet. 而其余網(wǎng)絡(luò)的參數(shù)量Param和每秒浮點(diǎn)運(yùn)算次數(shù)(FLOPs)都遠(yuǎn)大于YOLOv8n-seg,每秒檢測圖片數(shù)量(FPS)也不如YOLOv8n-seg.
由此可見,加入多頭處理模塊CBoTNet 和邊界框回歸損失函數(shù)WIoUv3 可以在保持較小模型計(jì)算量的同時(shí)有效的提取顆粒目標(biāo)特征,并且檢測速率能夠提高到21. 66 f/s.
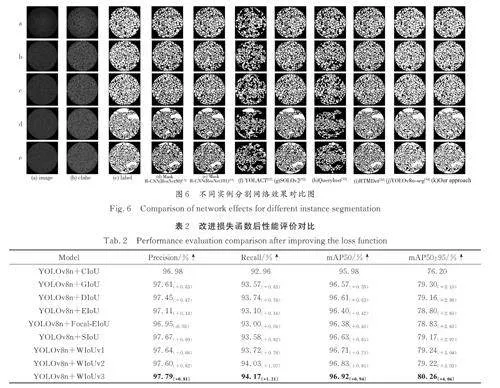
圖6 展示了a~e 不同網(wǎng)絡(luò)下對(duì)測試集巖心圖片顆粒目標(biāo)分割的效果圖. 其中,YOLACT 和QueryInst 在自制數(shù)據(jù)集的測試中未能取得有效的目標(biāo)檢測和分割;SOLOv2 和Mask R-CNN 分割效果相比前兩個(gè)網(wǎng)絡(luò)較好,但是模型運(yùn)算量較大;RTMDet 目標(biāo)檢測和分割效果與YOLOv8n-seg 較為接近,并且模型復(fù)雜度也較為接近,但是檢測速度遠(yuǎn)不如YOLOv8n-seg;本文方法可以在不顯著提高模型運(yùn)算量的同時(shí)提高目標(biāo)檢測和分割精度,并且可以實(shí)現(xiàn)在檢測速度上的提高.
3. 4. 2 損失函數(shù)改進(jìn)效果對(duì)比 將WIoUv3 損失函數(shù)與CIoU、GIoU[35]、DIoU[36]、EIoU、SIoU 等損失函數(shù)進(jìn)行實(shí)驗(yàn)對(duì)比. 由表2 可知,使用WIoUv3損失函數(shù)的精確率、召回率和平均精度均達(dá)到最高,相比于YOLOv8n-seg 的原邊界框回歸損失函數(shù)CIoU 在精確率(Precision)上提高了0. 70%,在召回率(Recall)上提高了0. 91%,在平均精度mAP50 和mAP50:95 上分別提高了0. 61% 和3. 14%,說明改進(jìn)的損失函數(shù)能夠使得預(yù)測更加準(zhǔn)確穩(wěn)定.
3. 5 消融實(shí)驗(yàn)
從表3 可知,在主干網(wǎng)絡(luò)中加入BoTNet 模塊可以將顆粒識(shí)別準(zhǔn)確率mAP50 和mAP50:95 分別提高0. 43% 和1. 35%;使用CBoTNet 之后可以顯著的提高對(duì)小目標(biāo)的識(shí)別和分割能力,在準(zhǔn)確率mAP50 和mAP50:95 上分別能提高1. 01% 和5. 21%;在邊界框回歸損失函數(shù)中將CIoU 替換為WIoUv3 可以在不明顯提高模型大小的同時(shí)將顆粒識(shí)別準(zhǔn)確率mAP50 和mAP50:95 提高0. 94%和4. 06%.
在模型復(fù)雜度方面,加入BoTNet 可以將FPS提高到21. 87 f/s,但是也略微增加了模型大小;使用CBoTNet 并加入WIoUv3 之后繼續(xù)增加了模型大小,F(xiàn)PS 相比原網(wǎng)絡(luò)提高了5. 30%,相比加入BoTNet 降低了0. 96%.
綜合實(shí)驗(yàn)結(jié)果,同時(shí)使用CBoTNet 和WIoUv3 可以比原模型在mAP50 和mAP50:95 上分別提高1. 30% 和7. 81%,并且可以提高檢測速率FPS,達(dá)到21. 66f/s.
4 結(jié)論與展望
本文提出了一種改進(jìn)的YOLOv8n-seg 的顆粒目標(biāo)提取的分割網(wǎng)絡(luò),通過加入多頭機(jī)制模塊CBoTNet 能夠顯著的提高對(duì)小目標(biāo)的識(shí)別和分割能力,并通過改進(jìn)邊界框回歸損失函數(shù)為WIoUv3進(jìn)一步提高目標(biāo)檢測精度,總體相比原YOLOv8nseg網(wǎng)絡(luò)在mAP50 和mAP50:95 上分別提高了1. 30% 和7. 81%. 檢測速率也相比原網(wǎng)絡(luò)略微提高,但是并不明顯,后期可以通過進(jìn)一步輕量化模型,提高檢測速率. 并且針對(duì)本文自制數(shù)據(jù)集,網(wǎng)絡(luò)結(jié)構(gòu)嘗試過在上采樣、卷積優(yōu)化等方面進(jìn)行過改進(jìn),但是未能達(dá)到較好效果,因此后續(xù)工作可以在這些方面繼續(xù)改進(jìn)優(yōu)化,達(dá)到更好的檢測和分割效果.
