
500 Internal Server Error
基于機器學習的信貸違約預測研究
2023-04-06 22:14:58趙川鞠紅梅王美玲
電腦知識與技術 2023年5期
趙川 鞠紅梅 王美玲
關鍵詞:大數據;風險預測;機器學習;信貸違約;投票算法
0 引言
為了響應國家穩經濟的政策,金融機構對資金困難的企業和個人進行信貸支持,幫助供企業打通供應鏈資金需求,鼓勵個人進行創業創新、開展副業、互聯網辦公等多種靈活就業方式,共渡難關,起到穩定市場經濟作用。面對如此龐大的資金需求,金融機構需要依托機器學習模型,輔助進行風險評估和風險預測。
1 文獻回顧
隨著計算機技術在金融領域的應用,許多學者加入信貸風險的研究,其中Linwei Hu等人在相關文獻中分析了監督學習算法在銀行中的應用場景[1];XiaojunMa等人使用多觀測數據清洗的LightGBM算法,表明該算法在預測違約方面具有較高的準確性[2];馬海花針對性地在個人信用風險評估中,使用隨機森林和XG?Boost模型進行對比分析,指出XGBoost模型更加適合處理大量高緯度的噪音和非線性信用風險的數據[3];陳紅在文獻中構建邏輯回歸模型、樸素貝葉斯、支持向量機、決策樹、組合模型進行綜合對比,同時對違約客戶進行客戶畫像分析,給出合理化建議和應用方向[4]。
國內外學者對于信貸風險預測的相關問題進行了大量的可行性分析與研究,不同學者選取的研究數據、評價指標和模型有所不同,最終得出不同的研究結果,這些研究具有重要的參考和借鑒意義。本文將結合銀行數據集,以機器學習算法中XGBoost、Light?GBM模型、邏輯回歸模型和隨機森林模型為基礎,結合Voting投票算法,進行個貸違約預測方面的研究。
2 算法及方案簡介
2.1 算法簡介與預備知識
1) 邏輯回歸
邏輯回歸是在線性回歸的基礎上進行改進的,增加了sigmoid激活函數[5]。線性回歸模型為輸入,f (x)為預測值,W T 為截線,b 為真實值和預測值的差值,具體公式為:
邏輯回歸把預測值映射到0-1區間。當預測值y > 0.5時,判斷為正例,y < 0.5時,判斷為反例,以此進行分類。
2) 隨機森林
隨機森林的特點在于隨機性和集成學習,通過隨機采取樣本,隨機挑選特征,形成多棵決策樹,每棵決策樹都有自己判斷權力,隨機森林收集每一棵樹投票結果,以少數服從多數的原理,進行最終分類判斷[6]。
3) XGBoost
XGBoost的預測模型通過設定損失函數,并根據參數進行一階、二階導數計算,以提高泛化能力[7]。令k 表示全部樹的數量,t 表示預測輪數,fk 是第k 顆預測結果,ft (xi )為第t 輪改善參數,Y ti 表示基于xi 樣本第t輪預測結果,預測公式為
4) LightGBM
LightGBM由微軟研究院研究開發,基于不犧牲速度的情況下,盡可能使用更多的數據運算,具有準確率高、區分能力強的特點[8]。基于直方圖(Histogram)算法、基于梯度的單邊采樣算法(GOSS)和互斥特征捆綁算法(EFB),這3個算法的引入下,降低了葉子生成的復雜度,從而節約了大量的運行計算時間和存儲空間。
5) Voting投票算法
Voting投票算法是集成算法中的一種,該算法又分為硬投票(Hard Voting) 和軟投票(Soft Voting) 兩種使用方式。其中硬投票是基于少數服從多數的原則,將不同分類器的結果分別進行統計,看最終哪個投票多來確定分類結果;而軟投票可以為不同分類器設置不同權重,由于每個分類器都有獨立估算分類的概率,軟投票法將所有概率再進行平均,最后平均概率最大的作為分類結果。
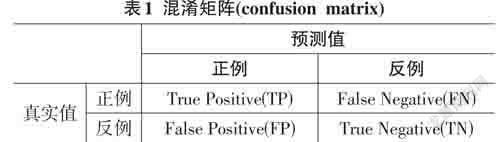
6) 淆矩陣(confusion matrix)
假如收到一些樣本,倘若該樣本集中只存在兩種類別,即正例和反例。而當預測值為正例時,本文將其記為positive(P),而當預測值為反例的時候,本文將其記為negative(N)。此時如果預測值與真實值相同的時候,本文記為true(T),而當預測值和真實值相反不一樣的時候,則記為false(F)。從而有了以下的混淆矩陣(confusion matrix),如表1所示。
7) ROC曲線
ROC曲線以假正例率(FPR)為X軸,以真正例率(TPR)為Y軸,進行圖形的繪制。由于ROC曲線能夠反映出分類效果,但從表現程度上還是不夠直觀,對此,通過AUC來直觀地凸顯出分類能力,即該指標實際為ROC曲線下的面積。
2.2 方案流程
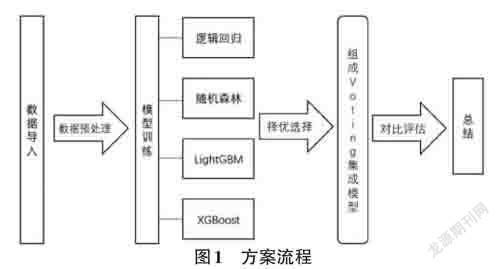
本文研究的方案流程主要包括7個步驟:數據導入、數據預處理、模型訓練、擇優選擇、集成、對比評估、總結,如圖1所示。
3 數據處理及模型訓練
3.1 數據描述
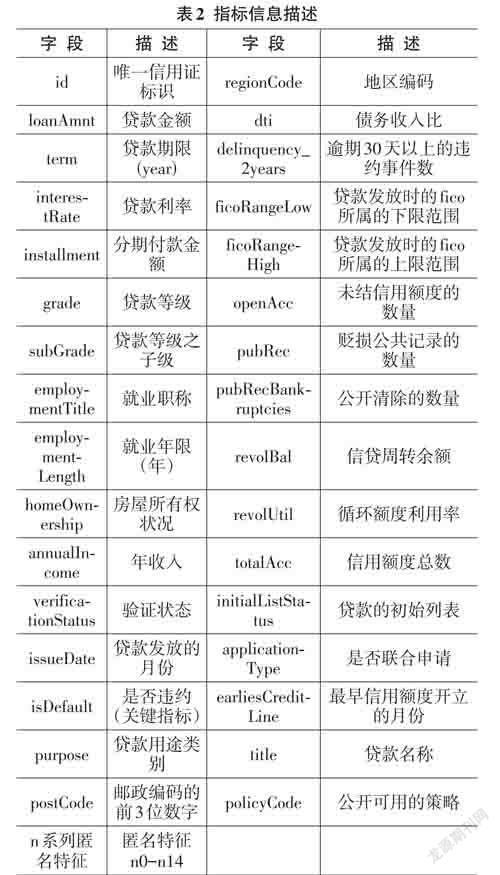
本文采用天池公開銀行貸款數據集,該數據總量有47類指標信息,80萬條用戶數據。47類指標信息具體描述如表2所示。
3.2 數據處理
數據處理是模型訓練的前提,圍繞關鍵指標進行數據處理,通過對數據缺失值占比、數據異常值篩查進行多次降維,缺失部分采取為向上填充法的方式進行空值填充,特殊字符進行數字化處理。表3 為Grade指標數字化處理前后對比。
3.3 繪制相關性熱力矩陣圖
經過數據處理,最終將數據集降維至23項指標,并制作成相關性矩陣熱力圖,觀察各個指標與關鍵指標之間的相關性。呈現如圖2所示。
由相關性熱力矩陣圖可以看出,與isDefault關鍵性指標相關度較高的為loanAmnt、term、interestRate、installment、grade和dti,而其他指標起到相關性較小,用于提供輔助性作用。
3.4 模型訓練及評分結果
數據集采取8:2的分配比例,即訓練集為640000 條,測試集160000條,進行數據集的拆分,分別帶入到模型中訓練和測試,并記錄邏輯回歸、隨機森林、XG?Boost、LightGBM這四種單一模型的AUC評分。單一模型評分結果如表4所示。
3.5 模型集成及對比結果
本文選擇AUC評分較高的模型,即邏輯回歸模型、LightGBM模型和隨機森林模型,使用Voting硬投票算法進行模型融合,發現Voting模型融合后的AUC 評分有較大提升。對比數據如表5所示。
4 總結
通過對數據集的清洗篩選,選出部分相關聯的特征值進行多種模型的訓練,以數學原理闡述了不同模型的處理方式,本文測試中以最優的模型進行Voting 投票算法的融合,其結果表明十分優異,能夠起到提升預測準確度的作用,具體得出以下結論。
1) 在進行數據集處理時,將數據字符類型進行定量數值化,能夠更好地形成圖像,進行指標的選擇,比如在等級劃分時,采用數值的形式,進行數據集優化。
2) 不同模型在處理同一數據集的處理效果差異性很大,如在XGBoost模型處理與隨機森林模型在處理同一數據集時,AUC評分差距很大。
3) 作為Voting投票融合算法,將三種有效的單一模型進行融合,能夠有效提升AUC評分,證明融合算法相較于單一的模型,能夠發揮融合算法的強化性,提高準確度。
猜你喜歡
中國綠色畫報(2016年11期)2017-02-18 15:00:39
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
現代經濟信息(2016年24期)2016-11-09 04:12:25
科學與財富(2016年28期)2016-10-14 21:19:17
科技視界(2016年20期)2016-09-29 10:53:22
商(2016年6期)2016-04-20 17:54:08
科技與創新(2015年8期)2015-05-06 23:08:15
