譜聚類欠取樣下自編碼網絡不平衡數據挖掘①
2022-01-06 08:59:58王舒梵姜新盈
計算機系統應用 2021年10期
王舒梵,嚴 濤,姜新盈
(上海工程技術大學 數理與統計學院,上海 201620)
1 引言
信息化時代加快了數據量的增長速度,各行各業的數據總數日漸龐大,為在海量數據資源中挖掘出隱藏規律,聚類算法應運而生且重要性日益顯著.在同一數據集中,若某類別樣本個數遠超出余下類別樣本個數,則該數據集叫做不平衡數據[1].此類數據多用于故障診斷、目標檢測等實際應用中,但當前算法大部分都是以數據集均衡分布為前提的,在處理不平衡數據時極易偏向多數類,產生錯分情況,降低分類準度,所以,研究不平衡數據集的數據挖掘方法具有重要的實踐意義.
向鴻鑫等人[2]通過總結常用的不平衡數據預處理方法與挖掘算法,從多維度梳理策略性能,分析各應用領域的不平衡問題與解決方案后,實現不平衡數據挖掘方法綜述; 蔡莉等人[3]構建出一種時空特征位置數據融合模型,通過數據與算法層面,解決不平衡數據的挖掘問題,利用架構的綜合評價指標,反映聚類質量,融合不平衡數據后,完成熱點區域挖掘; 文獻[4]中許統德等人設計的多層級聯式少數類聚類高精度數據挖掘算法中,在聚類欠采樣的前提下,聚類多數類樣本,獲取與少數類相同數量的質心,架構新的平衡訓練集,采用合成少數類過采樣技術(Synthetic Minority Oversampling TEchnique,SMOTE)過采樣,級聯K-means聚類與C4.5決策樹算法,改善分類決策邊界.
鑒于上述文獻方法在融合不平衡數據樣本時存在一定的盲目性,故基于譜聚類欠取樣,采用自編碼網絡來構架一種不平衡數據挖掘方法.通過譜聚類方法聚類多數類數據,在更改數據空間結構的基礎上,有選擇地欠取樣處理了多數類數據集,通過選取代表性數據作為訓練數據,經過數據篩選,使分類邊界適當偏移,提升劃分準確率; 利用自編碼器升、降維數據,實現初始數據重構; 引入網絡調整操作,增加了目標領域網絡的學習空間,使其與目標領域樣本特征表示更匹配.
2 譜聚類欠取樣分類
譜聚類就是按照譜圖理論[5]完成數據分類,將聚類問題轉換成無向圖多路徑劃分問題.
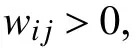

采用下列公式界定無向圖G的度矩陣:

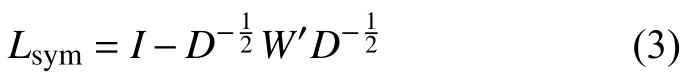
譜聚類算法流程具體描述如下:
(3)經過標準化處理建立拉普拉斯矩陣;
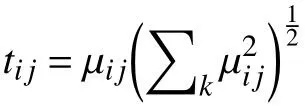
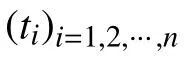
在不平衡數據挖掘過程中,多數類數據通常會攜帶多個冗余數據信息與噪聲數據,導致分類邊界偏移至少數類數據方向,加大錯分概率,若想解決該問題,就要對多數類數據實施相應處理,即欠取樣處理,使分類邊界偏移至多數類數據方向.傳統欠取樣處理方法多為去除與邊界距離較遠的數據點,或隨機去除多數類數據,這種不考慮數據信息的處理手段雖然均衡了不同類數據集,但分類界限調整得并不夠理想,因此,采用譜聚類方法聚類多數類數據,在更改數據空間結構的基礎上,有選擇地欠取樣處理了多數類數據集,通過選取代表性數據作為訓練數據,經過數據篩選,獲取分類邊界偏移量.
3 基于自編碼網絡的不平衡數據挖掘
通過訓練令網絡輸入與輸出相等,完成數據隱藏特征學習的一種神經網絡模型就是自編碼器(Auto-Encoder,AE)[8],作為深度學習網絡的一種主要結構,自編碼網絡在深度神經網絡預訓練中被廣泛應用.該網絡即便不用帶標簽數據樣本,也能夠達成訓練目的,也就是說,其學習過程屬于無監督學習.自編碼網絡中的編碼階段是輸入數據學習至高效表示特征,解碼階段是以習得的隱藏特征為依據,實現初始數據重構.自編碼器經過升、降維數據,把提取出來的數據特征轉換為適用、高效的隱藏特征后,輸送至有監督學習模型內,即可實現挖掘目標.圖1所示為自編碼器的基本框架形式,由輸入層、輸出層以及隱含層組成,近似于一個3層神經網絡[9].
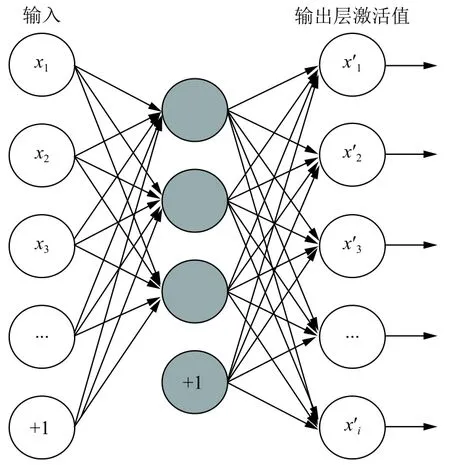
圖1 自編碼器框架示意圖
假設(x1,x2,···,xi)是一個輸入樣本,Sigmoid激活函數[10]用S表示,輸入層與隱含層間、隱含層與輸出層間的權值分別為w1與w2,則自編碼器前向傳播表達式如式(4)和式(5)所示.

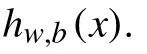
由于自編碼器的訓練標準期望是輸入與輸出相等,所以,采用下列表達式描述自編碼器的最終學習結果:

根據各隱藏單元數,獲取各維度隱藏特征,升、降維處理初始數據,通過堆疊多個自編碼器,結合約束條件,實現各層面的數據高效表示學習.
利用無監督學習與有監督學習,在譜聚類欠取樣條件下架構用于挖掘不平衡數據的自編碼網絡.因為無標簽樣本數據在源領域與目標領域中均可輕易取得,因此,當最大均值差異[11]比預設閾值低時,直接跳過網絡調整階段,無監督訓練目標領域數據; 反之,當最大均值差異比預設閾值高時,按照圖2中所示的自編碼網絡形式進行調整,并完成隨機初始化.網絡調整操作增加了目標領域網絡的學習空間,使其與目標領域樣本特征表示更匹配.
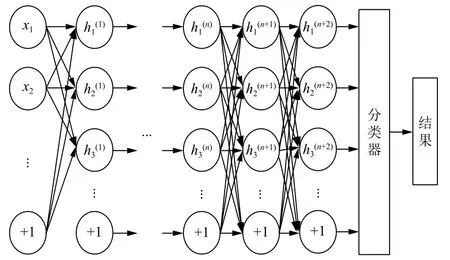
圖2 自編碼網絡結構示意圖
在自編碼網絡中輸入譜聚類欠取樣處理的不平衡數據集合,依照以下流程實現數據挖掘:
(2)若多數類數據樣本有n個,則高斯核[12]相似矩陣表達式如下:

(4)根據各聚類結果以及聚類中心與少數類數據點的間距大小,選取代表性數據點,使分類界面偏移至多數類樣本,并最大程度刪除多數類數據點的邊界點.各聚類結果中,數據點選用數量隨著多數類樣本個數的增加而增多,隨著聚類中心與少數類數據點間距的增加而上升,基于此,采用下列選取公式,篩選出有效數據點.

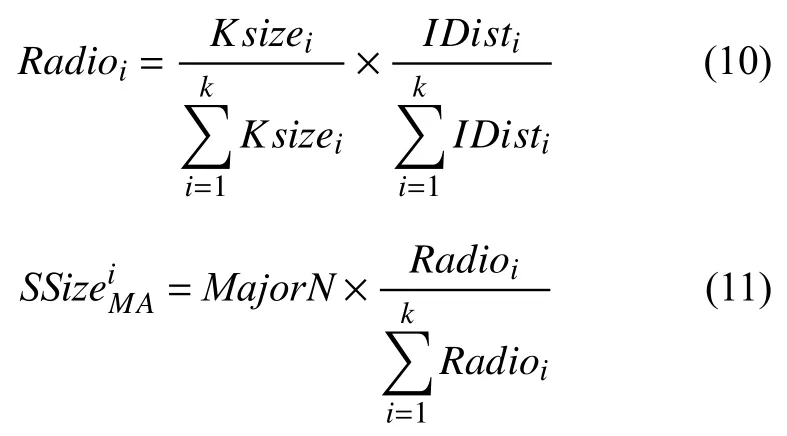
(6)訓練上述多數類代表數據點與所有少數類數據,將處理完的數據輸入自編碼網絡,在相同數據空間中,實現其與譜聚類算法的無縫連接,選取相同參數,令網絡和參數與譜聚類相似矩陣保持一致.
(7)根據上述訓練得出的分類界面,完成不平衡數據挖掘.
4 不平衡數據挖掘模擬分析
4.1 數據集選取
選用具有不同實際應用背景的UCI數據集[13],從中抽取sonar、breast-w、vehicle、artificial、pendigits、letter、page-blocks、car、seg1、yeast5等10組數據作為測試集(如表1所示),驗證挖掘策略的有效性.當數據包含多個類別時,設定任意一類為少數類,多數類則為其余各類別的合并結果,所有不平衡數據集均經過譜聚類欠取樣處理.
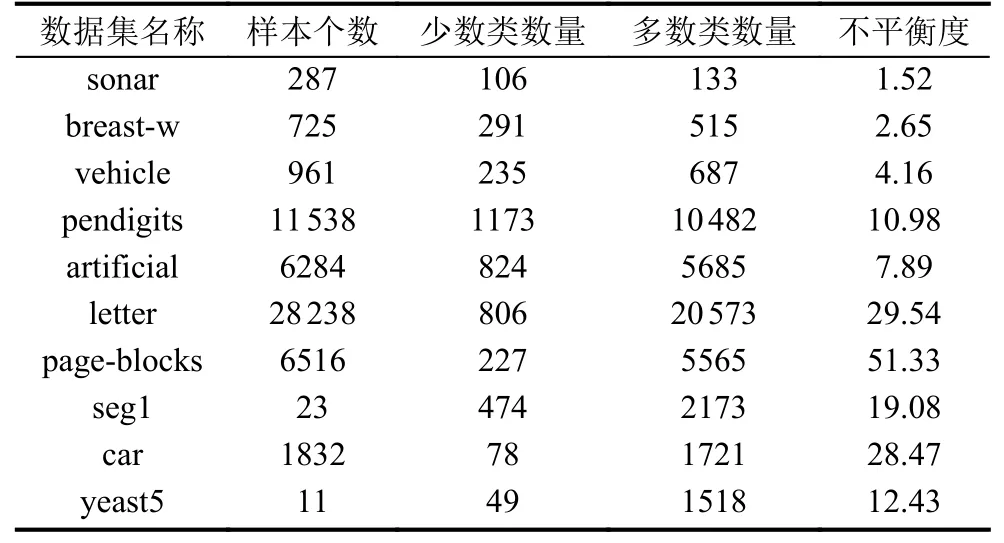
表1 UCI數據集具體信息統計表
將表1中的不平衡度劃分成下列等級表,如表2所示.

表2 不平衡度等級表
sonar與breast-w兩個低度不平衡等級數據集的選取原因是驗證挖掘方法在處理一般數據集時的有效性.
4.2 性能評估指標
針對不平衡數據集,采用合理的查全率 Recall、查準率 Precision、綜合F-measure、AUC(Area Under ROC Curve,ROC曲線下方圖面積)值、G-means等類別不平衡評估指標,使少數類挖掘情況得以充分反映,各指標均以表3中所示的混淆矩陣為依據完成創建.

表3 類別混淆矩陣表
其中,具有描述少數類分類性能的指標為F-measure,是查全率與查準率的調和均值; AUC作為不同判決閾值對應的分類性能反映指標,性能隨數值的增加而提升.各評估指標表達式分別如下所示:

4.3 不平衡數據挖掘效果
分別模擬文獻[2-4]方法以及本文方法在挖掘10組不平衡數據集時的效果,通過對比不同方法的評估指標數據,驗證方法的適用性與可行性.對比結果如表4-表6所示.
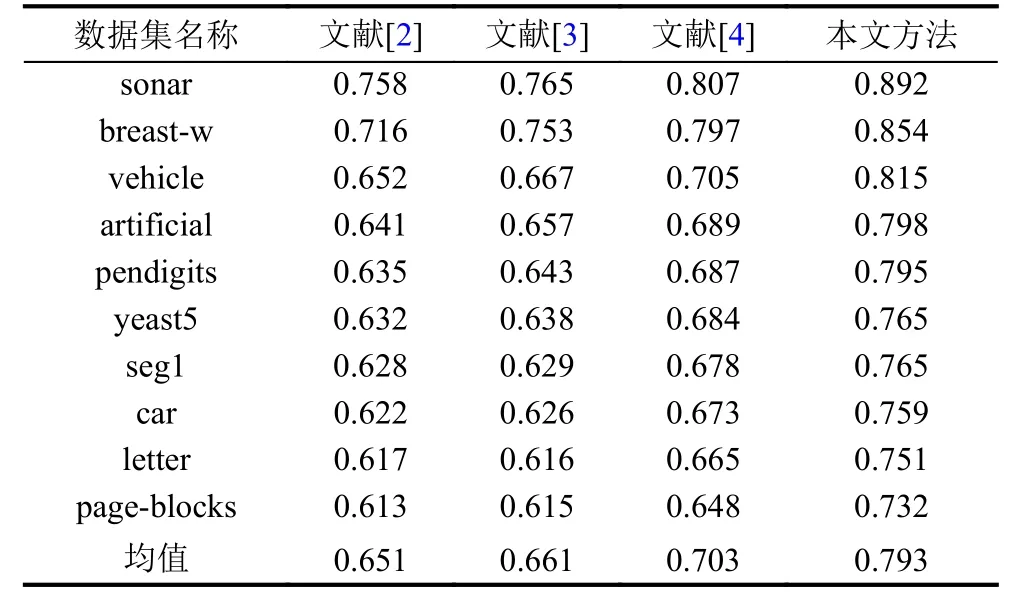
表4 各方法F-measure實驗數據結果比對表

表5 各方法AUC值實驗數據結果比對表
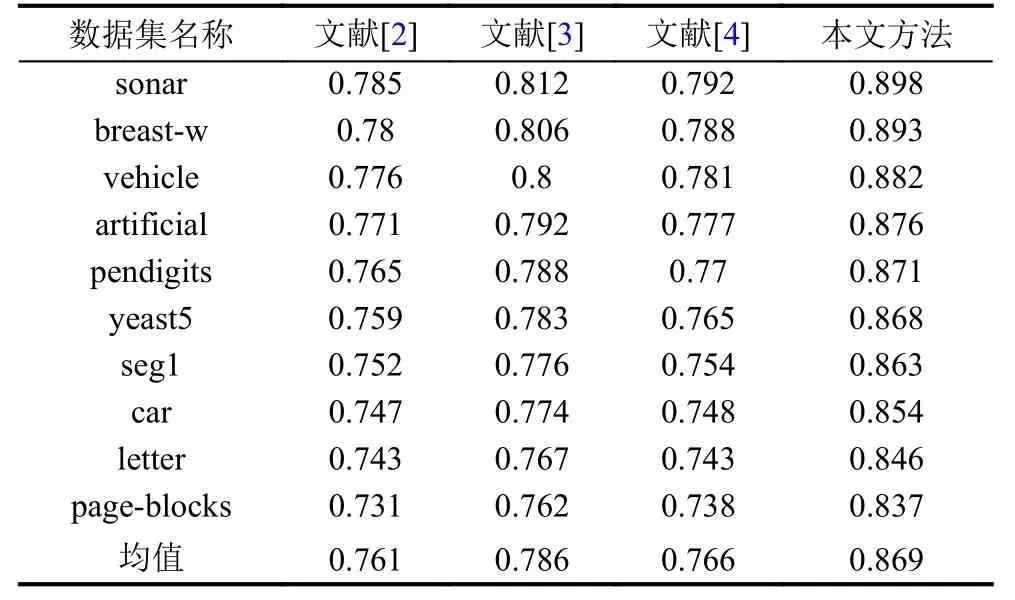
表6 各方法G-means實驗數據結果比對表
結合上列各表可以看出,各方法少數類評估指標均隨著不平衡度的增加而略有下降; 少數類樣本數據個數總量相對較少,導致文獻[2-4]方法的F-measure值整體偏低; 造成文獻方法AUC值與G-means指標較低的原因是未考慮樣本屬性間的相關性,忽略了監督判別性的類別標簽信息; 而本文方法因引用了自編碼網絡,根據各隱藏單元數,獲取各維度隱藏特征,實現了各層面的數據高效表示學習,通過對比最大均值差異比預設閾值,完成了網絡調整與隨機初始化,利用K-means算法與自編碼網絡,充分結合了無監督學習與有監督學習形式,因此,取得了較為理想的少數類樣本分類效果.
5 結論
在多個實際應用數據里找到可用且易于用戶理解的知識,這一過程就叫做數據挖掘.當挖掘的數據集內某類別樣本個數與另外類別樣本個數相差較大時,該種數據集即為不平衡數據.隨著信息時代與大數據時代的來臨,網絡入侵檢測、文本分類、醫療診斷等各種領域中普遍存在不平衡數據,一旦出現錯分情況,將引發極大損失,因此,本文以自編碼網絡為核心,提出一種譜聚類欠取樣下的不平衡數據挖掘方法.由于時間限制,方法未對運行時間展開針對性的改善,準備將其作為下一步工作的研究重點,結合創新型、組合型算法,縮短挖掘時長; 譜聚類方法以圖譜理論為基礎,因KNN圖復雜度相對更低,因此,在今后的研究中需探索一種近似于KNN圖的圖構建方法,減小復雜度.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
Coco薇(2016年2期)2016-03-22 02:42:52
信息通信技術(2015年6期)2015-12-26 01:16:46
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
