基于行業差異視角的財務預警模型比較研究
2007-12-29 00:00:00楊淑娥陳強
會計之友 2007年30期
【摘要】財務指標是構建預警模型的數據基礎,往往因行業不同而表現出不同的特征。財務指標的行業差異是否會影響到財務預警模型的預測精度以及對不同模型的影響程度如何,成為財務預警領域一個值得研究的重要問題。本文就此作一探討。
一、問題提出
為了研究在財務指標行業差異影響下不同預警模型的預測精度,本文以深滬兩市A股市場信息技術業和批發零售業170家上市公司為研究對象,以區分行業與否為條件,主要使用多元判別分析(MDA)和BP神經網絡(BPNN)在不同條件下建模。通過比較不同條件下構建模型的精度,可以發現MDA模型易受行業差異影響,而BPNN模型無論區分行業與否都比較穩定,而且預測精度均好于MDA模型。因此筆者認為BPNN是一種優秀的預警方法,尤其適合數據來源存在部分缺失或較復雜時的模型構建。
二、文獻回顧
(一)財務預警模型發展回顧
1.單變量模型:1966年,Beaver建立了單變量模型來預測財務危機。他研究比較了30個財務比率在企業陷入財務困境前1~5年的預測能力,發現營運資金/總負債這一指標的預測能力最強,前1年的預測正確率達到了87%。但是,由于單個財務指標不能全面反映企業的財務特征,因此多變量模型成為隨后研究的主流。
2.多變量模型:常用的多變量模型主要通過使用統計方法和人工神經網絡方法(ANN)構建。
(1)統計方法主要有多元判別分析(MDA)、Logistic回歸、主成分分析(PCA)等。國內外眾多學者(如Altman,1968;Ohlson,1980;陳靜,1999;吳世農、盧賢義,2001;楊淑娥、徐偉剛,2003)使用這些方法進行了大量的實證研究。統計方法比較成熟,但是往往受制于眾多的假設前提,難以適應復雜多變的企業運作環境,因而預測精度受到了影響。
(2)ANN是近年來新興的計算方法,具有自我學習、調整能力和較強的容錯性。ANN中的BP神經網絡(BPNN)應用最為廣泛。國內學者劉洪(2004)運用MDA、Logistic回歸、BPNN進行了比較研究,發現BPNN對檢驗樣本的預測精度高達90.1%,而MDA、Logistic回歸分別只有54.4%和56.6%。楊淑娥(2005)對比研究發現BPNN也優于PCA方法,兩種模型對檢驗樣本的預測精度分別為90%和81.7%。這些研究均表明BPNN優于傳統的統計方法。
(二)財務指標行業差異研究回顧
1969年,Gupta使用美國21個二級行業分類中的制造業公司進行分析,發現這些公司的財務指標存在顯著的行業差異。Lev(1969)使用部分調整模型對美國18個行業245家公司的6個財務比率進行了回歸,證實了財務比率具有顯著的行業效應,并且公司比率不斷向本行業該比率均值進行調整。
近年來,國內學者也展開了有關上市公司財務指標的行業差異研究。郭鵬飛等(2003)使用我國A股上市公司2001年的7個財務比率進行了分行業統計分析,結果顯示除凈資產收益率外其余財務比率的行業效應均非常顯著。連玉丹等(2006)研究發現總負債率等6個財務比率都顯著地向行業均值收斂,但調整成本和行業特性的差異導致了不同的財務比率具有不同的收斂速度。
鑒于上述研究,筆者發現已有財務預警研究往往局限于預警指標和方法的選擇,而忽視了樣本選擇時行業差異對預警效果所帶來的影響。為此,本文以信息技術業和批發零售業為研究對象,以區分行業與否為條件,使用多種方法構建模型進行精度比較來研究這一問題。
三、實證研究
(一)研究方法
筆者選用了MDA、Logistic回歸、BPNN這幾種常用的預警方法。但是,在使用Logistic回歸法時,由于始終沒有變量進入模型,因而本文主要使用其他兩種方法進行比較研究。
MDA是一種常用的分類分析方法,它通過根據已知類別的事物的性質建立判別函數,然后對未知類別的新事物進行判斷以將之歸入已知的類別中。
BPNN是一種多層前向神經網絡,具有一個或多個隱含層,一般使用Sigmoid函數f(x)=1/(1+e-x),通過信號的正向傳播與誤差的反向傳播兩個過程實現。
(二)樣本選取
本文以深滬兩市A股市場中信息技術業和批發零售業上市公司作為研究樣本,樣本期間為1998~2005年,數據來源于國泰安信息技術有限公司提供的上市公司數據庫。財務危機樣本界定為因以下原因而被ST的公司:(1)連續兩年虧損;(2)每股凈資產低于每股面值。為了避免傳統配對選擇的方式高估模型的預測能力,財務健康樣本的選擇界定為1998~2005年從未被ST過的公司。
筆者使用T-1年的樣本數據建模和檢驗,其中危機樣本數據取自1997~2004年,健康樣本的數據取自2004年,避免了數據收集過程中的重復性。這樣共收集到31個危機樣本,139個健康樣本,各類型樣本具體劃分見表1。
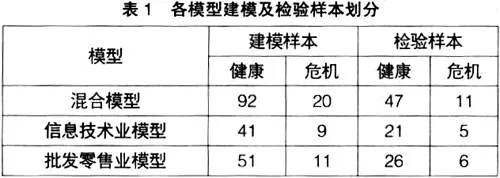
(三)指標選取
1.指標選取
借鑒已有研究,筆者選擇了6個財務指標來構建模型,這些指標既能全面反映企業的財務狀況,也具有顯著行業差異。它們是:(1)短期償債能力:流動比率(X1);(2)長期償債能力:資產負債率(X2);(3)營運能力:應收賬款周轉率(X3)、存貨周轉率(X4)、總資產周轉率(X5);(4)盈利能力:凈利潤率(X6)。
為了檢驗所選樣本財務指標的行業差異性,筆者對兩個行業的不同類型樣本分別進行了檢驗。檢驗的方法是:對于正態分布的樣本,使用T檢驗;而對于非正態分布的樣本,使用非參數檢驗中的Mann-Whitney U檢驗,結果見表2。
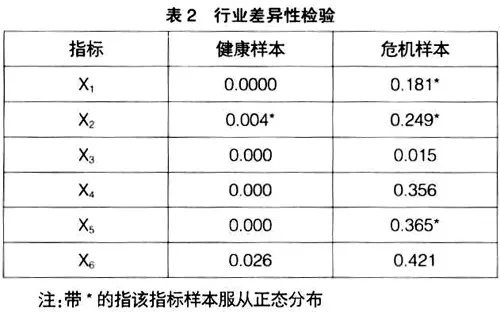
注:帶*的指該指標樣本服從正態分布
從表2中可以看出,在0.05的顯著性水平上,健康樣本的6個財務指標都具有顯著的行業差異,而危機樣本僅有應收賬款周轉率這一指標差異顯著。針對這一現象,筆者認為危機樣本往往具有相似的財務特征,具體來說盈利能力都出現重大問題、無法清償到期債務等,同時考慮到財務指標取自不同期間,也可能造成了差異不顯著。
2.數據歸一標準化
為了去除不同量綱的影響,又將選出來的6個財務指標數據進行歸一標準化處理。由于選取的指標中含有效益性指標(如X6)和適度性指標(如X1),因此需要針對不同類型的指標分別進行處理。具體處理方法是:
對于效益性指標,采用以下公式處理:

其中q為該指標最合適值。
(四)建立模型
1.MDA
首先選用逐步判別法選擇構建模型的變量。信息技術業模型僅有凈利潤率指標進入;批發零售業模型則有資產負債率、存貨周轉率和總資產周轉率三個指標進入;混合模型則包含了以上4個指標。
使用篩選后的指標建立模型,得到非標準化的典則判別函數的系數如表3。
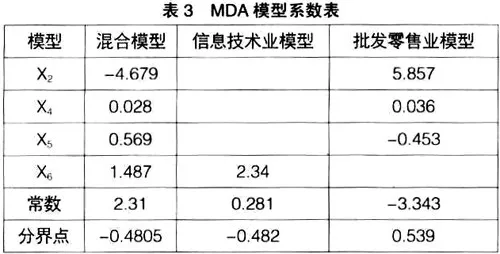
2.BPNN
一個單隱層的BPNN可以逼近任何的連續函數,因此本文選擇了單隱層的BPNN結構。網絡的輸入層節點數取決于選取指標的個數,設置為6。筆者期望輸出(1,0)和(0,1)分別代表危機樣本和健康樣本,因此輸出層節點個數為2。隱含層節點個數根據經驗公式(2P1+P3)1/2
(五)模型比較
使用兩種方法建立模型之后,再將樣本分別帶入模型進行檢驗,結果見表4。
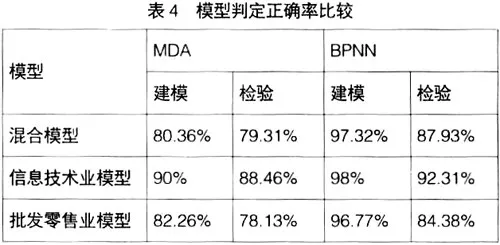
從表4可以看到無論是建模還是檢驗,BPNN都比MDA的判別效果要好,并且從MDA的判別結果來看,區分行業預測效果要好一些。為了進一步清楚地觀察行業差異對模型精度的影響,筆者把兩種情況下的誤判情況列示在表5中。在對誤判情況進行比較時,錯誤被分為兩類:Ⅰ類錯誤是指把危機樣本誤判為健康樣本,Ⅱ類錯誤是指把健康樣本誤判為危機樣本。
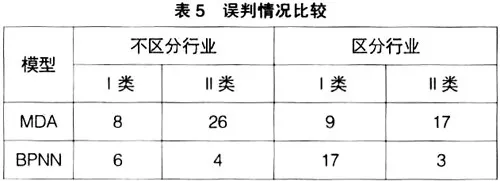
從表5可以看出,MDA模型受行業差異影響較大,而且主要集中在健康樣本的誤判上,區分行業建模可以使健康樣本的誤判減少1/3,但是危機樣本差異不大。對BPNN模型而言,是否區分行業對模型的誤判影響很小。因此,筆者認為MDA較BPNN易受財務指標行業差異的影響。
四、結論
筆者通過研究發現,MDA模型與BPNN模型受行業差異的影響不同:MDA較易受財務指標行業差異的影響,而且主要體現在對健康樣本的誤判顯著增多上;BPNN無論區分行業與否,各類錯誤差異均不大,而且各種條件下的預測精度均超過了MDA。這啟示我們構建預警模型時,一方面要注意財務指標行業差異的影響;一方面要注意預警方法的選擇。從本文的研究來看,BPNN是一種優秀的預警方法,適合數據存在部分缺失或來源較復雜時的模型構建。
本文的局限性在于樣本僅取自信息技術業和批發零售業,而且在建模時使用的財務指標均具有顯著的行業差異,未考慮所選財務指標行業差異不顯著或含有非財務指標時的情形,需要今后進一步的研究。
