
基于B/S架構的Web網頁結構檢測應用研究
2009-05-12 03:14:34陳圣儉孫明濤
現代電子技術 2009年2期
關鍵詞:檢測
陳圣儉 孫明濤
摘 要:隨著互聯網的普及,大型的跨國公司要求公司對內對外的所有網站都遵循統一的框架結構,因此為了判斷網頁結構是否符合標準,需要對網頁結構進行檢測。Web結構分析是指從Web文檔中自動分析網頁結構的過程,檢測不符合標準的網頁。依據W3C Markup Validation Service的設計理念,基于DOM結構樹和正則表達式的操作,以分析Web網頁結構為基礎,提出了Web頁面結構檢測的設計思想。在解析Html和CSS代碼的基礎上,網頁結構檢測正確率達到80%以上。
關鍵詞:正則表達式;網頁結構樹;檢測;文檔對象模型;屬性元素
中圖分類號:TP311文獻標識碼:A
文章編號:1004 373X(2009)02 135 04
Application and Research on Web Structure Inspection Based on B/S Construction
CHEN Shengjian,SUN Mingtao
(Computer Science and Technology College,North China Electronic Power University,Beijing,102206,China)
Abstract:As the popularization of Internet,like the multinational companies,the company is asked to follow the unified guideline to all the Website,in order to judge whether the Webpage is consistent with the guideline,the Webpage′s structure is needed to inspect.Web structure′s analysis refers to the course of auto-analyzing Webpage′s structure,and inspect the page that is not with the guideline.Based on W3C Markup Validation Service,the DOM tree and regular expression,with analyzing the Webpage′s structure,the designing idea of how to inspect Webpage′s structure is brought forward.Based on the Html parse and CSS code parse,the correct rate on Web structure inspection is up to 80%.
Keywords:regular expression;web page structure tree;inspection;document object model;attribute element
0 引 言
隨著網絡的發展,互聯網上信息量的激增,在網頁上合理地布局信息的格式變得非常重要,因此Web結構的設計越來越受到開發者的重視。在一般情況下,頁面的框架被大多數開發者定義為3部分(上、中、下)或者有規律的幾部分,對于大型的跨國公司,他們要求位于不同國家的各個部門的所有網站都遵循統一的標準結構。根據某跨國公司中國研究院制定的網頁設計標準,依據W3C的Markup Validation Service[1]設計思想,提出了Web頁面結構檢測系統的設計方案,分別對各部門的網站進行半自動檢測,省略了人工測試的隨意性,同時使開發者的設計更加規范。
1 Web頁面概述
1.1 HTML簡介
HTML(Hypertext Markup Language)超文本標記語言[2],被用來結構化信息,并通過瀏覽器表現信息設計的內容,作為構造網頁的通用語言,具有簡單、多樣、靈活的特性。
Web上的數據大部分是以HTML的形式出現的。HTML文檔由標記(TAG)和元素組成。HTML標記確定了瀏覽器所顯示文檔元素的格式,大多數HTML標記是成對出現的,它們分別用作開始標記和結束標記,HTML的結束標記與開始標記的惟一區別是多了斜杠“/”。HTML標記放在尖括號里,如 <HTML>是位于HTML文檔中的第一個條目,HTML文檔由標題<HEAD>和主體<BODY>兩部分組成。HTML文件的基本結構為[3]:
(1) <HTML>和</HTML>是HTML文件的首標記和最后一個標記,用來表示HTML文件的開始與結束;
(2) <head>和</head>標記是第二個出現的,用來表示HTML文件的頭區域;
(3) <title>和</title>標記用來表示HTML文件的標題,出現在瀏覽器的最頂端左上角;
(4) <body>和</body>表示文件的主題信息,也就是正文。是Web結構分析的主體部分。
可以根據HTML的屬性,靈活地擴展HTML元素的能力。
1.2 DOM簡介
DOM(Document Object Model) [1]是一個獨立于平臺和語系的接口,它是相關于文檔的一系列對象列表,通過操作這些對象,可以對XML文檔進行讀取、遍歷、修改、添加和刪除操作。在DOM中最基本的對象是Node,從Node中又派生出了幾種具體的節點類型。對應于XML中各種相應的節點[4]。在使用DOM加載XML文檔后,在內存中形成一個節點樹,也就是相應的Web結構樹,由XML的標簽節點形成的對象模型組成。這些對象包括相應的屬性、方法,以對數據進行操作。
在DOM規范的設計思想下,HTML跟XML一樣是一種樹形結構的文檔,<HTML>是根(Root)節點,<head>,<body>是<HTML>的子節點(Children Node),互相之間是兄弟節點(Sibling Node);<body>下面才是子節點<table>,<div>,<span>,<p>等。
所謂樣本文檔分析[5],就是把文檔輸入HTML分析器(Parser),按照文檔對象模型生成一種樹形結構表示。DOM 是W3C 制定的一種獨立于平臺和具體編程語言的API 接口標準。它提供了一個標準的對象集合用以表示HTML或XML文檔及其各組成部分(即對象)之間的關系,并為存取和處理這些對象提供了標準的編程接口。
1.3 總結
雖然HTML語言具有一系列的優點,便于表達Web頁面信息,但是HTML語言同樣存在缺點。HTML的“標記”只是告訴瀏覽器軟件如何顯示所定義的信息,卻不包含任何語義,因此由HTML語言所表述的Web頁面經過瀏覽器分析后只適合人們瀏覽,不適合作為一種數據交換的方式由機器處理[4]。在此以文檔對象模型為基礎,構造一棵DOM樹,把需要的信息在DOM樹的不同層次中的路徑作為信息抽取的標記,根據父子節點和兄弟節點的關系的基本原理為基礎,設計了一種檢測學習算法來半自動地提取并檢測Web頁面框架。
2 網頁結構的檢測
2.1 對于W3C Markup Validation Service的認識
W3C的標記驗證服務,是在SGML的基礎上,將待驗證頁面的HTML同DTD(Document Type Definition)[1]進行比較,檢測HTML語法隨意性的缺點,提示正確的HTML文檔定義格式。這種方法可以確保頁面HTML的有效性,從而使頁面能夠在所有的瀏覽器中正常的顯示,同時給出開發者或相關人員有針對性的提示。
2.2 Web結構檢測的設計思想
根據網頁的URL,利用基于HTTP協議的WebRequest,WebResponse[6]類操作,可以獲取頁面對應的HTML和CSS源代碼的字符流,根據W3C的標記驗證服務對網頁代碼進行相應的檢測,并且糾正其中的錯誤,然后將源代碼構造成DOM樹;根據制定的檢測標準(主要是網頁框架的限制標準值),提取源代碼中對應的屬性值,再者根據兄弟節點和父子節點之間的聯系,分析原始網頁的框架,從而匹配該網頁是否符合給定的標準;對于符合標準的框架給出其準確值,對于不符合標準的框架則予以提示,并要求糾正。具體的流程圖如圖1所示。
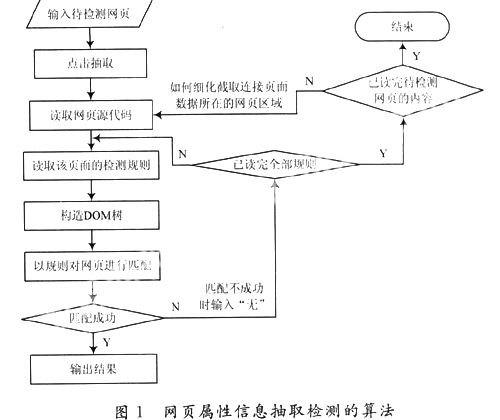
2.3 源代碼的過濾體系
為了使頁面源代碼形成的DOM樹的結構更加清晰,首先應清理源代碼中的空格信息、注釋信息以及頁面內容信息和多余的操作信息。
對于空格信息和Js信息可以利用正則表達式快速、精確的清除或者替換(部分空格要保留,用作結束標識位);對于注釋信息可以利用字符串匹配的判斷規則,清除<!-- --!>之間的內容;<style>的內容應利用正則表達式快速取出,同CSS文件相似,需要獲取color,font以及頁面框架涉及到的寬、高等信息;對于tag標簽內的style屬性值,可以在Dom樹構造完成后,直接獲取。
2.4 網頁結構樹的構造算法
在構造DOM樹的過程中,可以利用HTML頁面的Tag的Element特征,采用標記匹配和回溯相結合的方法構造Web文檔結構樹[7]。這是因為大多數HTML標記是成對出現的,在起始標記和結束標記之間,包括網頁描述屬性信息和網頁內容信息,如<td width = "393"><fontcolor="# 666666"><img src="" width="393"></font></td>。在起始標記<td>和結束標記</td>之間的width ="393"><font color="#666666"><img src="" width="393"></font>是屬性信息,<img src="" width="393">是內容信息。在構造文檔結構樹時,需要對Tag標記進行分析,并將屬性作為節點信息。由于HTML的隨意性,它的規范性差,所以在對代碼進行清理后,還要對剩余代碼進行規范化整理,比較實用的Tidy工具即可實現該功能。如果主要是對框架內容的抽取,則需要考慮HTML的標記主要有<STYLE>,<STYLE>,<BODY>,</BODY>,<TABLE>,</TABLE>,<DIV>,</DIV>,<TR>,</TR>,<TD>,</TD>,<A>,</A>,<IMG>。對于其他的HTML標記可視為無用HTML標記,在程序處理中將忽略對這些標記的處理。網頁文檔結構樹的每個結點對應1個Tag標記,因此構建DOM樹的前提條件是正確地讀取標記,分析開始標記、結束標記和沒有得到匹配的標記。結點對應的Tag開始與結束標記之間的內容存在Tag Node類中[8]。
2.5 網頁代碼檢測的過程
根據檢測需要,篩選tag標簽信息,保留tag標記和element元素。在構造過程中,借鑒HtmlParser[9]的設計思想,過濾HTML中的tag標簽,將<HTML></HTML>之間的部分tag標簽構造成DOM樹;這種構造DOM樹的算法,在讀取過程中可能產生部分重復,因此應該進一步優化。具體的算法設計為:
(1) 讀入獲取到的字符流源文件,設置狀態機;
① 判斷第1個字符是否是“<”,如果是,則可能是標簽入口,需要取下1個字符確認;
② 如果不是,設置狀態機開始解析一個Node,如果是“<”,繼續讀取下一字符;
③ 根據</HTML>判斷是否到達頁尾,如果是則產生一個Node返回;
④ 如果讀取到“%”,則說明是JSP(Java Server Page) [10]標簽,進入JSP狀態機去解析;
⑤ 如果讀取到“?”,則說明是XML標簽,進入XML狀態機去解析;
⑥ 如果讀取到“/”或任何字符,說明是Tag標簽,進入Tag標簽狀態機去解析;
⑦ 如果讀取到“!”,則說明進入一個注釋標簽,需要再讀取一個字符,如果到頁尾,則產生一個Node返回,如果字符為”>”則生成一個Remark Node返回,否則,回溯一個字符,再判斷字符如果是“-“則回溯一個字符,進入Remark狀態機去解析,如果不是,則回退一個字符進入Tag狀態機去解析。
(2) 當進入Tag標簽狀態機后,開始Tag標簽的解析:
① 如何讀取到“<body”,則將body插入隊列,以body為父節點開始構造樹;
② 如果遇到“<table”,則將table作為body的第一個孩子節點插入到樹中;
③ 繼續讀取,如果遇到“<tr”,則將tr作為table的第一個孩子節點插入到樹中;
④ 如果遇到“table”,則將table作為body的第二個孩子節點(前一個table的右兄弟節點插入樹中);
⑤ 繼續讀取,如果遇到“td”,則將td作為tr的第一個孩子節點插入樹中;
⑥ 如果遇到“<tr”,則將其作為tr的兄弟節點,table的孩子節點插入樹中;
⑦ 繼續讀取,如果是“td”,則將其作為td的兄弟節點(tr的孩子節點)插入樹中。
以此遞歸,直到遇到“</”,表示每一節點的結束,“</body>”整棵DOM樹建立完畢。DOM樹結構可用圖2表示。
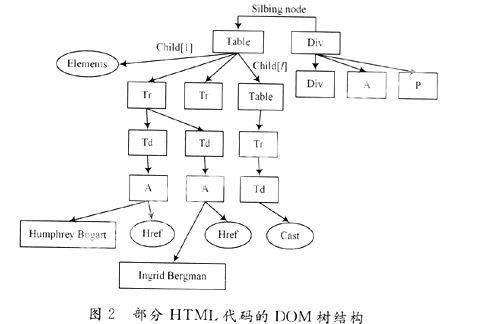
2.6 網頁結構的檢測
具體的匹配檢測需要根據實際的標準頁面結構,利用HTML中的兄弟節點和父子節點的關系,由兄弟節點確定頁面的各個子框架結構,然后再根據子框架下的兄弟節點和父子節點的屬性值(例如width,height等)判斷該框架是否符合給定的標準。
例如在檢測頁面時,首先取定body的子節點的個數,如果等于1,則判斷其子節點的孩子節點,從而判斷出頁面的布局。可以利用如下代碼:其中parserCompare()函數為將獲取到的值與標準值進行匹配的函數,利用遞歸操作,分析各個部分的框架。
if(node.Children!=null&&node.Children.Count;>0)
{
parserLogoCompare(node.FirstChild);
start.Add(tag.StartPosition);
}
INode siBlingNode = tag.NextSibling;
while (siBlingNode != null)
{
parserCompare(siBlingNode);
paserData(siBlingNode);
siBlingNode = siBlingNode.NextSibling;
}
將網頁的各部分框架分析出來后,取得各部分對應的color和font等的值,對于<style>和<div>中的css信息,通過正則表達式獲取style信息;然后分析字符串,得到相應的命名;再結合標準庫中的color,font 等標準值,匹配并檢測得到相關信息。
根據制定的標準以及DTD的規定,將不同的提示信息綁定到頁面顯示中,將不同的審核數據綁定不同的顏色。這樣,用戶在輸入網址之后,就可以得到頁面結構的相關信息,根據公
司內部標準規范設計。
3 結 語
參照W3C Markup Validation Service分析HTML的規范性檢測方式,分析并檢測網頁結構是否符合開發者制定的標準,對于不同開發者在同一模板下開發的規范性做出檢測。其中引入DOM樹結構中的路徑表達式來定位HTML文檔中要分析的屬性,在分析頁面結構的同時,可以利用關鍵字提取頁面的內容信息,以及獲取鏈接頁面的各種信息,同時實現信息提取和Web檢測。
參考文獻
[1]W3C.Markup Validation Service.http://validator.w3.org/,2007.
[2]Lauren W,Arnaud LH,Vidur A,et al.Document Object Model(DOM) Level 1 Specification[EB/OL].http://www.w3.org/TR/REC2DOM2Level21,1998,10(4).
[3]王建.Web建站標準.北京:人民郵電出版社,2007.
[4]侯彥娥,蒲寶明.基于.NET的Web應用系統通用平臺中構件技術研究.沈陽:中國科學院沈陽計算技術研究所,2006.
[5]李效東.基于DOM 的Web信息提取.計算機學報,2002,25(5):526-533.
[6]Simon Robinson,K Scott Allen.C#高級編程.北京:清華大學出版社,2002.
[7]袁宇麗,左志宏.基于HTML的Web信息提取研究.成都:電子科技大學,2006.
[8]陳瓊,蘇文健.基于網頁結構樹的Web信息抽取方法.計算機工程,2005,31(20):54-55,140.
[9]王琳琳,劉知青.基于HtmlParser的Web信息提取技術.北京:北京郵電大學,2007.
[10]JavaServer Pages Technology.http://www.javasoft.com/products/jsp,SDN,2007.
作者簡介
陳圣儉 男,1966年出生,博士后,教授,博士生導師。主要研究方向為計算機測控技術。
孫明濤 男,1983年出生,碩士研究生。主要研究方向為計算機測控技術。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
