
一種基于主題的Web文本聚類算法
2010-01-10 03:36:22袁曉峰
成都大學學報(自然科學版) 2010年3期
袁曉峰
(鹽城師范學院信息科學與技術學院,江蘇鹽城 224002)
0 引 言
隨著計算機網絡的高速發展,人們越來越依賴于網絡,而網絡上信息劇烈的膨脹又會讓人們覺得在網絡上尋找自己想要的信息越發變得困難了.為了幫助人們更快地找到想要的信息,文本聚類技術得到廣泛的研究[1-3].雖然目前有許多文本聚類方法,但是還很少有主題聚類的方法,而主題聚類的結果更能讓用戶一目了然.主題聚類的思想是根據文本的主題來劃分類別,將具有相同主題的文本歸為一類.我們認為,Web文本的標題有助于主題的歸納,甚至有些文本的標題就是主題,例如我們搜索的關鍵字序列為“世界重新認識中國”,搜索引擎返回的結果中包含標題為“汶川地震讓世界重新認識中國”的文本,這個標題就直接能反應文本的主題;而有些就不能反應文本的主題,對此,還必須進一步從正文中抽取出文本的主題.基于此,本文提出一種基于主題的Web文本聚類算法(HTBC),同時,在實驗中我們還將 HTBC與經典的文本聚類算法(KMeans、AHC、STC)做了比較,實驗結果表明,HTBC在聚類的準確率、召回率方面比傳統的算法要好.
1 文本聚類算法概述
目前,文本聚類算法大致上可以分為層次聚類(Hierarchical Clustering)和非層次聚類 (Partitional Clustering)[1,2].層次聚類算法的代表是會聚層次聚類方法(AHC),它首先假設所有文本自成一類,然后將最相似的兩類合并,并繼續這一過程,直到將所有文本合并為一類,因而可以形成一棵聚類樹.AHC的優點是能夠清晰地顯示整個聚類過程以及中間聚類方法.非層次聚類方法的代表是K-均值聚類方法(K-Means).K-Means是一種典型的基于劃分的方法,其基本原理是首先選擇k個文本作為初始的聚類點,然后根據簇中對象的平均值,將每個文本重新賦予最類似的簇,并更新簇的平均值,然后重復這一過程,直到簇的劃分不再發生變化.
上述兩種方法最主要的缺點是需要事先確定一個停止條件.比如,AHC要求事先確定所要聚成的類別數,而K-均值聚類則需要設定K值.而上述條件往往在實際應用中很難事先確定.此外,它們都不能很好地描述和解釋聚類的結果.再者,這些方法限定每個文本只能屬于一個類,而沒有考慮一個文本可能屬于多個主題的情況.
后綴樹聚類算法[3](STC)較好地克服了上述缺點.STC利用一種名為后綴樹的數據結構來發現文本所共同含有的短語信息并進而利用這些信息來構建基本類.為了避免出現大量重復的或非常相似的類別,STC合并那些高度重疊的基本類.但STC不是一種基于主題的聚類方法,因為它無法保證一個類別中包含共同短語信息的文本都是關于同一主題的.
2 HTBC算法
HTBC算法首先根據文本的標題和正文提取文本的主題詞向量,然后通過訓練文本集成生詞聚類,并將每個主題詞向量歸類到其應屬的詞類,再將同屬于一個詞類的主題詞向量對應的文本歸并到用對應詞類的名字代表的類,從而達到聚類的目的.HTBC算法的步驟包括預處理、建立主題向量、生成詞聚類和主題聚類等環節.
2.1 預處理
由于文本中有些詞語對文本主題的概括幫助甚微,甚至沒有幫助且會干擾主題的提取,所以必須要對文本集進行預處理.有一些詞在文本中出現頻率極高,可將其稱為停用詞,如“的”“我”“你”“地”等,停用詞對主題概括沒有任何幫助.此外,還有一些出現頻率極低的詞同樣對主題概括沒有幫助,所以在預處理時應考慮將其剔除.
另外,在預處理時應將正文部分做中文分詞的同時進行詞性標注,去除停用詞、副詞、形容詞、功能詞和虛詞等對主題基本沒幫助或者幫助甚微的詞,僅保留動詞、名詞.同樣,對文本的標題,也應按上述方法進行處理.
2.2 計算各特征項的權重
文本聚類之前需要將文本表示為計算機能夠處理的形式.目前,向量空間模型(VSM)是使用較多且效果較好的表示方法之一[4],其計算特征權值w的一種方法是TFIDF[5],詞條ti在文本d中的TFIDF值由下式定義:
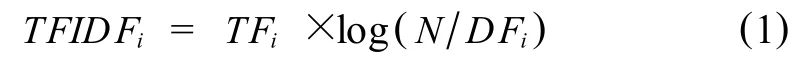
其中,TFi是詞條ti在文本d中出現的頻數,N表示全部訓練文本的總數,DFi表示包含詞條ti的文本頻數.
通常,標題中出現的詞肯定是比正文中出現的詞對主題的概括更為重要.據統計,標題中出現的詞的重要性是正文中出現的相同詞的5倍[6].
在計算文本正文中每個詞的頻率時,考慮是否有與標題中相同的詞,如果有則按下式計算,
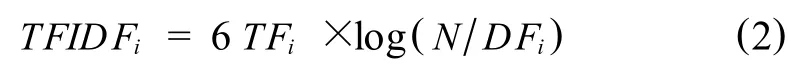
在此基礎上,挑選每篇文本中 TFIDF值高于閾值v的詞作為一個主題用向量加以保存,用以聚類.
2.3 聚 類
在進行聚類時,可考慮利用計算詞序列之間的相關度來排除干擾詞,同時進行合并.
詞的相關度通常采用互信息(MI)來計算[7],因為這種方法在處理中文文本時具有較好的性能[8].
如果用A表示包含詞條t且屬于類別c的文本頻數,B為包含t但是不屬于c的文本頻數,C表示屬于c但是不包含t的文本頻數,N表示語料中文本總數,t和c的互信息可由下式計算:
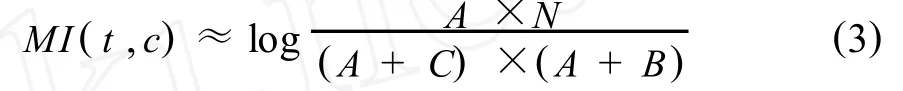
通過在訓練文本集中計算各主題詞向量中特征項的相關度,然后用一個最能反映主題的詞作為種子詞,并將其作為最終類的代表.
2.4 HTBC算法的具體步驟
HTBC算法的具體步驟如下:
(1)特征項選取.對待聚類文本集中的文本進行預處理,得到詞集,W={W1,W2,…,Wm},Wi= {wi1,wi2,…,wim}.其中,i表示所在文本序號.對 W中的詞進行詞頻統計,并選取頻度大于閾值f的詞構成特征項集,T={T1,T2,…,Tm},Tij={twil1, twi2,…,twij,…,twim}.
(2)生成訓練詞序列.將訓練文本集進行預處理,得到詞序列,U={w1,w2,…,wn}.
(3)詞聚類.先將U中每個詞wi作為一個類.對U中每個詞wi(i=1,2,…,n),按(3)式依次計算它與U中每個詞wj(j=1,2,…,n)的互信息 MI(wi, wj),若MI(wi,wj)≥r(r為給定的聚類閾值),則將詞wj歸于wi所屬的類,否則繼續計算wi與U中下一個詞的互信息,直到U中所有詞都計算完畢,得到詞類序列.其中,每個詞類由一個詞表示,每個詞類記為 uwi(uwi1,uwi2,…,uwik),uwi為U中的第i個詞表示的詞類.
(4)文本聚類.從 T取出未處理的特征項Ti,在詞類中查找,如果任意 Tij都屬于同一個詞類wi,則標注 Ti屬于wi.否則將少數不屬于wi的干擾詞剔除,并標注Ti屬于wi.重復該過程,直到所有的Ti都處理過.最后將同屬一個詞類的特征項對應的文本劃分到以詞類名表示的簇.
3 實 驗
在實驗中,我們用“世界重新認識中國”作為搜索語句,隨機下載的100篇相關文本作為測試語料,文本平均長度約為325字,利用HTBC算法中步驟(1)、(2)得到特征項集T.再將特征項集中每個詞在新華網站的新華搜索中進行搜索,并隨機選取500篇網頁文本下載作為訓練語料庫,有312個詞頻大于6的詞.根據初步實驗及分析取聚類閾值 r=0. 005,共產生27個詞類,每個詞類至少包含2個元素.
在實驗中,我們使用準確率(precision)和召回率(recall)對算法進行評價.準確率、召回率的定義如下:

其中,n(i,r)是聚類 r中包含類別i中的文本的個數,nr是聚類形成的類別個數,ni是預定義類別的個數.
我們將待聚類文本集分別用 K-means、AHC、STC、HTBC算法進行聚類,并計算聚類的準確率、召回率,得到如圖1、圖2所示結果.
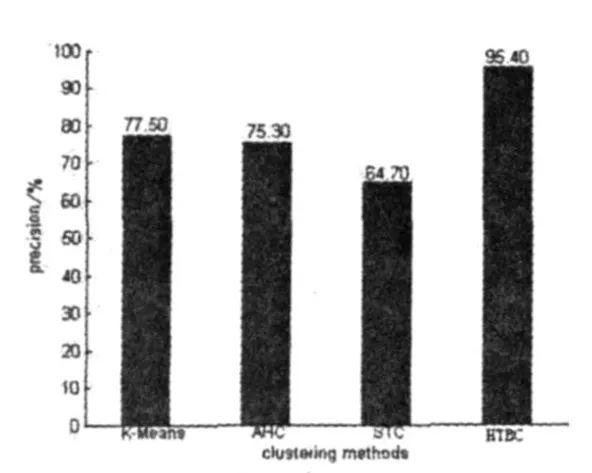
圖1 4種算法準確率比較
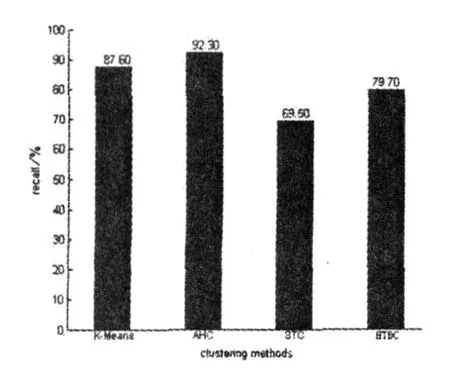
圖2 4種算法召回率比較
從圖1、圖2的比較結果可看出,HTBC算法的精確度較其余3種經典聚類算法要高許多,但召回率卻低于K-Means和AHC算法.這主要是因為語言的復雜性,即同義詞可能擁有相去甚遠的表達方式.但是,79.7%的召回率對互聯網上文本聚類方法來說應該是可以接受的.
4 結 語
在本文中,我們提出一種基于主題的Web文本聚類算法:即通過提取Web文本中的高頻詞,并結合文章的標題,計算這些詞在文本中出現的頻率,取頻率最高的幾個組成主題向量,然后通過在訓練文本集中計算每個主題向量中詞與詞之間的相關度,剔除相關度低的干擾詞,再計算不同主題向量中各個詞之間的相關度,并將相關度高的聚為一類.實驗表明,本文提出的文本聚類算法具有較高的精確度和召回率,特別是精確度,較其他幾種經典的聚類算法要高.
[1]劉泉鳳,陸 蓓,王小華.文本挖掘中聚類算法的比較研究[J].計算機時代,2005,6(1):7-8.
[2]Yanjun Li.Text Document Clustering Based on Frequent Word Meaning Sequences[J].Data and Knowledge Engineering,2008, 64(1):381-404.
[3]ZAMIR O E.Clustering Web Documents:A Phrase-Based Method for Grouping Search Engine Results[D].Washington DC:Unioversity of Washinton,1999.
[4]陳 濤,謝陽群.文本分類中的特征降維方法綜述[J].情報學報,2005,24(6):690-695.
[5]Xu D X.Energy,Entropy and Information Poterntial for Neural Coputation[D].Florida:Universtiy of Florida,1999.
[6]韓客松,王永成,沈 洲,等.三個層面的中文文本主題自動提取研究[J].中文信息學報,2005,15(4):45-49.
[7]Yang Z R,Zwolinski Z.Mutual Information Theory for Adaptive Mixture Models[J].IEEE Transactions on Pattern Analaysis and Machine Intelligence,2001,23(4):26-32.
[8]代六玲,黃河燕,陳肇雄.中文文本分類中特征抽取方法的比較研究[J].中文信息學報,2004,18(1):26-32.
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
