一種基于人眼視覺特性的壓縮方法*
2010-03-14 09:04:32魏小文石旭利趙子武
電視技術 2010年10期
魏小文,石旭利,趙子武
(上海大學 通信與信息工程學院,上海 200072)
1 引言
近幾十年來,隨著通信和多媒體技術的迅速發展,視頻編碼技術得到了廣泛的應用。而數字無損壓縮作為其核心技術就變得越來越重要。醫學成像、遙感、視頻傳輸都要求編碼比特數盡可能少,并且傳輸的圖像與原始圖像在主觀質量上幾乎是一樣的。JM軟件正是在這樣的背景下由國際視頻編碼組織提出并作為視頻編碼的標準,且隨著視頻編碼技術的發展而進步,經歷了H.261,H.263,H.264 以及 MPEG-1,MPEG-2,MPEG-3和目前的MPEG-4。當前的視頻編碼標準軟件及相應的改進方法可以很好地解決時間冗余、空間冗余及編碼冗余等問題,也就是無損地對視頻編碼比特數進行壓縮。例如,文獻[1]通過時域與空域相結合的自適應預測來達到無損壓縮,視頻編碼器通過運動估計去除時間冗余。文獻[2]通過人眼對圖像灰度變化的不同敏感程度特性對DCT塊進行分類,從而去除空間冗余。文獻[3]根據圖像內容的變化并且用小波變換來對視頻圖像進行無損壓縮以去除空間冗余及編碼冗余。但以上方法及當前的視頻編碼標準卻很少考慮視覺冗余。筆者提出的基于人眼視覺特性的壓縮方法可以有效地去除視覺冗余。其思想就是找到合適的恰可觀測失真 (亮度變化不可見的最大值),也就是人眼對圖像亮度變化的敏感度因子,通過敏感度因子對JM86代碼流程中DCT變換前的亮度殘差系數先進行量化,然后再變換、量化、編碼,由此來進一步壓縮比特數,去除視覺冗余,試驗結果表明此方法有效。
2 人眼視覺系統(HVS)
當光進入人眼后,人眼視網膜上的光感受器對其進行采樣,然后通過神經元發送光信號到大腦,從而形成了圖像,視網膜上的光感受器(由桿狀物和圓錐細胞組成)在人眼視覺系統中的作用就相當于傳感器。這些桿狀物對光照極其敏感并在光照較弱時不能感受到彩色[4]。如果由3種截然不同類型組成圓錐細胞,那么它的敏感度就要低得多,但是在適當的光照范圍內能夠讓人眼感受到彩色,進入人眼的光信號有一個動態的范圍,約為1∶1014,然而神經元傳輸信號的動態范圍僅僅只有1∶103,人眼能夠辨別的動態范圍是10-12的數量級[5-7]。因此,這就要求人眼有一種自適應的機制,也就是人眼先感受到的是一些不變的亮度值,然后在亮度變化非常小的范圍內來察覺圖像,而亮度就是人眼對可見光主觀感覺的大小。雖然人眼能夠很容易檢測到亮度的閃爍,但是很難用具體的數值對其強度進行量化。盡管如此,大量的試驗已經證明了亮度強度通常近似為亮度的對數[6],當然這種關系取決于對周圍發光體人眼的適應水平。人眼對亮度的不同適應水平就會產生不同的閾值,這是人眼視覺系統的一個重要特性。在這個閾值以內,人眼是不可見的。因此,可以將閾值看成是人眼不可見的最大值(MAX)。信號強度越大,其MAX也就越大。因此,對于視頻編碼而言,可以對亮度強度大的信號增大其MAX,然后進行量化。文獻[7]將Weber原則和人眼對圖像的感知習慣結合,其中背景亮度與恰可觀測失真max的關系式為

式中:M指預測像素的亮度,K,a為依據經驗設定的參數。這里用預測像素而不用預測塊是因為預測塊內的像素亮度不是恒定不變的,用預測像素可以更準確預測不可見的最大值,用預測像素的亮度代替當前像素的亮度是因為當前像素亮度不易得到。
3 量化
在JM86代碼中,假定A′代表預測亮度像素值,A代表當前亮度像素值,那么亮度殘差值B為
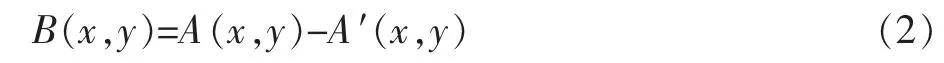
然后通過恰可觀測模型來對B(x,y)進行第一次量化,去除視覺冗余。得到

將C(x,y)進行整數DCT變換,得到變換后的殘差值 D(x,y),令

對 D(x,y)進行第二次量化,得到 E(x,y),量化后分為兩步,一步是進行熵編碼,形成碼流,進行傳輸;另一步就是反量化,得到 F(x,y),再對 F(x,y)進行反 DCT 變換,進行重構,得到的重構圖像為A″

將重構圖像與當前圖像相減得到差值G(x,y),即
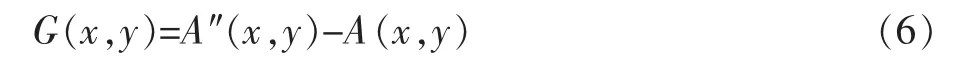
進一步去除視覺冗余

4 試驗結果與分析
筆者提出的方法是在JM86上實現的。因為JM86使用的是整數DCT變換,所以要對恰可觀測失真表達式取整,即 max=ceil[K×(1.219+M0.4)2.5+a],通過對 JM 代碼亮度數據的分析,K的取值只能在[0.01,0.10]之間。本試驗測試的視頻序列為Bream,Mobile,Mother_Daughter,Container,Akiyo等 5個 QCIF標準視頻測試序列(176×144),每個序列編碼 50幀,幀內周期為 0(第 1幀是I幀,其余都是P幀)。 在幀率為30 f/s(幀/秒),RDO為1的狀態下改變P幀QP的值來統計測試結果 (這里QP 取 24,26,28,30,32),可得最佳的經驗值為 K=0.06,a=0,此時的試驗結果如表1所示。

表1 試驗前后比特數的變化
由表1中5個標準測試序列在不同的量化參數值比特數的變化可以看出每個測試序列的平均總比特數都有明顯的下降,且下降的比特率在8%~20%之間。說明此方法能很好地去除視覺冗余,提高編碼效率。下面通過圖1檢驗視頻測試序列的主觀質量。
通過解碼出來的主觀圖像效果對比可以看出,兩者幾乎是沒有明顯的差別,說明在量化之后(也就是進一步去除冗余之后)圖像的主觀質量并沒有下降,但是比特數的壓縮率卻減少了近一半(Akiyo為44.44%,Bream為41.93%,Mother_Daughter為37.6%),有的甚至超過一半(Mobile為77.42%)。這說明了通過人眼的視覺系統,圖像中存在較多的視覺冗余,有進一步優化的必要。
5 小結
針對人眼的視覺特性,也就是對恰可觀測失真區域內亮度不敏感的特性,提出了一種基于恰可觀測失真背景亮度模型來對亮度殘差進行量化,在保證視頻主觀質量沒有明顯變化的前提下,提高了編碼效率。另外,本方法還能在一定程度上降低JM86參考軟件的復雜度,因為通過恰可觀測失真模型對亮度殘差進行量化處理之后,其數據得到明顯的壓縮,再進行DCT變換時,其運算量就會得到明顯的降低,從而達到了降低其運算復雜度的效果。試驗結果表明,5個標準視頻測試序列的主觀質量并沒有下降,但各個測試序列總比特數的平均壓縮率在8%~20%之間,證明了此方法有效。

[1]ZHANGMingfeng, HU Jia, ZHANGLiming.Losslessvideocompression using combination of temporal and spatial prediction[C]//Proc.IEEE International Conference on Neural Networks and Signal Processing.Shanghai,China:IEEE Press,2003,2:1193-1196.
[2]WEIZhenyu,NGAN K N.Spatio-temporal just noticeable distortion profile for grey scale image/video in DCT domain[J].IEEE Trans.Circuits and Systems for Video Technology,2009,19(3):337-346.
[3]DING JR, YANG JF.Adaptive entropy coding with (5,3) DWT for H.264 lossless image coding[C]//Proc.TENCON 2007-2007 IEEE Region 10 Conference.Taipei,China:IEEE Press,2007:1-4.
[4]XU Shilin,YU Li,ZHU Guangxi.A perceptual coding method based on the luma sensitivitymodel[C]//Proc.IEEE International Symposium on Circuitsand Systems.New Orleans,LA,USA:IEEEPress,2007:57-60.
[5]YANG X K, LIN W S, LU Z, et al.Motion-compensated residue preprocessing in video coding based on just-noticeble-distortion profile[J].IEEE Trans.Circuits and Systems for Video Technology,2005,15(6):742-752.
[6]徐士麟.于人眼觀測特性的視頻編碼技術研究[D].武漢:華中科技大學,2009.
[7]IRANLIA,WONBOK L,PEDRAM M.HVS-aware dynamic backlight scaling in TFT-LCDs[J].IEEE Trans.Very Large Scale Integration(VLSI) Systems,2006,14(10):1103-1116.
