基于DSP的網(wǎng)絡(luò)并行計(jì)算系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)*
2010-06-13 11:33:06卜祥飛柏正堯洪田榮李新慶
微處理機(jī) 2010年3期
關(guān)鍵詞:系統(tǒng)
卜祥飛,柏正堯,洪田榮,李新慶
(云南大學(xué)信息學(xué)院,昆明650091)
1 引言
為了處理日益復(fù)雜的實(shí)時(shí)計(jì)算問(wèn)題,當(dāng)今的通信系統(tǒng)采用了大量的高性能計(jì)算芯片,包括各種CPU,F(xiàn)PGA和DSP。對(duì)更高計(jì)算速度的需求促使人們相應(yīng)地提高時(shí)鐘頻率,但是受到微電子技術(shù)發(fā)展速度的制約不可能無(wú)限制的提高時(shí)鐘頻率,于是人們開(kāi)始使用多塊DSP芯片并行處理高實(shí)時(shí)性數(shù)據(jù)。目前最常見(jiàn)的高性能硬件體系結(jié)構(gòu)是基于總線的分布式多處理器,以其結(jié)構(gòu)簡(jiǎn)單、成本相對(duì)較低、可靠性高的優(yōu)點(diǎn)得到很多人的青睞。但是總線是系統(tǒng)的“瓶頸”,一旦系統(tǒng)總線出現(xiàn)故障,將使整個(gè)系統(tǒng)受到影響,而且在軟件開(kāi)發(fā)過(guò)程中難度較高。更重要要的是如果系統(tǒng)計(jì)算能力無(wú)法滿足實(shí)際需求,硬件部分必須重新設(shè)計(jì),成本較高,開(kāi)發(fā)周期長(zhǎng)。于是提出一種基于以太網(wǎng)主從模式的多DSP并行計(jì)算系統(tǒng),用以太網(wǎng)作為傳輸媒介代替?zhèn)鹘y(tǒng)總線,采用UDP協(xié)議進(jìn)行數(shù)據(jù)通信,其中主機(jī)移植了uclinux操作系統(tǒng)來(lái)進(jìn)行全局任務(wù)調(diào)度,從機(jī)采用ADI公司提供的VDK實(shí)時(shí)操作系統(tǒng)內(nèi)核進(jìn)行數(shù)據(jù)計(jì)算。
2 并行計(jì)算
并行計(jì)算是一種用多臺(tái)處理機(jī)聯(lián)合求解問(wèn)題的過(guò)程,其執(zhí)行過(guò)程是將給定的問(wèn)題首先分解成若干個(gè)盡量相互獨(dú)立的子問(wèn)題,然后使用多臺(tái)計(jì)算機(jī)同時(shí)求解它,從而最終求得原問(wèn)題的解。并行計(jì)算的提出是當(dāng)今人們對(duì)快速處理大量復(fù)雜數(shù)據(jù)的迫切需求。首先,對(duì)于那些要求快速計(jì)算的應(yīng)用問(wèn)題,單處理機(jī)由于器件受物理速度的限制而無(wú)法滿足要求,所以使用多臺(tái)處理機(jī)聯(lián)合求解就勢(shì)在必行了;其次,對(duì)于那些大型復(fù)雜的科學(xué)工程計(jì)算問(wèn)題,為了提高計(jì)算精度,往往需要加密計(jì)算網(wǎng)格,而細(xì)網(wǎng)格的計(jì)算也意味著大計(jì)算量,它通常需要在并行機(jī)上實(shí)現(xiàn);最后,對(duì)于那些實(shí)時(shí)性要求很高的應(yīng)用問(wèn)題,傳統(tǒng)的串行處理往往難以滿足實(shí)時(shí)性的需要而必須在并行機(jī)上用并行算法求解。設(shè)計(jì)一個(gè)針對(duì)要求實(shí)時(shí)性較高的數(shù)據(jù)處理系統(tǒng),它不依賴(lài)于傳統(tǒng)的PC或多陣列DSP芯片作為處理器,而是使用可以靈活配置的單個(gè)DSP芯片組成一個(gè)以太網(wǎng),在此基礎(chǔ)之上采用UDP協(xié)議進(jìn)行數(shù)據(jù)通信。通過(guò)實(shí)驗(yàn)測(cè)試表明,這樣可以得到較高的實(shí)時(shí)數(shù)據(jù)處理能力。
3 系統(tǒng)開(kāi)發(fā)
3.1 移植uclinux操作系統(tǒng)
uclinux的優(yōu)點(diǎn)在于它的版權(quán)免費(fèi)、源碼開(kāi)放、結(jié)構(gòu)緊湊,這為日益增長(zhǎng)的應(yīng)用軟件提供了堅(jiān)實(shí)的基礎(chǔ)。ucLinux是一個(gè)全功能的操作系統(tǒng),支持完整的TCP/IP協(xié)議,網(wǎng)絡(luò)編程易于實(shí)現(xiàn),這對(duì)嵌入式系統(tǒng)來(lái)說(shuō)是很重要的,因?yàn)樗仨氃谌魏螘r(shí)間任何地點(diǎn)進(jìn)行計(jì)算。系統(tǒng)的服務(wù)器端是在BF548開(kāi)發(fā)板上移植了uclinux操作系統(tǒng),移植步驟如下:
(1)在裝有 linux操作系統(tǒng)的 PC機(jī)下建立blackfin交叉編譯環(huán)境
(2)移植u-boot
(3)移植uclinux操作系統(tǒng)
所有用到的源代碼可以在 http://blackfin.uclinux.org上免費(fèi)下載。移植成功后借助uclinux操作系統(tǒng)對(duì)socket和多線程編程良好的支持來(lái)實(shí)現(xiàn)復(fù)雜的任務(wù)調(diào)度。
3.2 VDK 編程
VDK(Visual DSP Kernel)是ADI公司DSP軟件開(kāi)發(fā)工具Visual DSP的一個(gè)重要組成部分,它特別適合用來(lái)編寫(xiě)需要精巧控制代碼的應(yīng)用程序。某些大型系統(tǒng)可能需要許多算法完成,而每個(gè)算法還可能包含許多功能模塊,這就要由控制代碼加以組織。處理器日益強(qiáng)大功能的發(fā)揮也需要精巧的控制代碼。基于VDK開(kāi)發(fā)的程序中,這些控制碼是由一個(gè)叫“內(nèi)核”的程序管理的,內(nèi)核常駐在DSP中。VDK實(shí)際上是一種帶API(Application Program Interface)函數(shù)庫(kù)的實(shí)時(shí)操作系統(tǒng)內(nèi)核,特別適合算法的實(shí)現(xiàn),并且屏蔽了嵌入式系統(tǒng)開(kāi)發(fā)過(guò)程中的一些硬件細(xì)節(jié),在Visual DSP++開(kāi)發(fā)平臺(tái)下直接建立VDK/LwIP工程,利用VDK提供的一些socket API函數(shù),實(shí)現(xiàn)了UDP客戶端通信。
4 并行計(jì)算的實(shí)現(xiàn)
4.1 服務(wù)器端實(shí)現(xiàn)
服務(wù)器端軟件運(yùn)行在已經(jīng)移植好uclinux操作系統(tǒng)的BF548 EZ-KIT評(píng)估板上,服務(wù)器端軟件流程圖如圖1所示。首先創(chuàng)建一個(gè)socket套接字,使用bind函數(shù)進(jìn)行綁定,在主函數(shù)中分別創(chuàng)建兩個(gè)線程來(lái)完成服務(wù)器端數(shù)據(jù)的收發(fā)。線程函數(shù)recv_thread()負(fù)責(zé)接收客戶端的數(shù)據(jù),其中調(diào)用了socket API函數(shù)recvfrom()運(yùn)行在阻塞模式下,等待接收各個(gè)客戶端發(fā)送的測(cè)試字符串,同時(shí)存儲(chǔ)客戶端的地址信息。待所有客戶端準(zhǔn)備好之后,利用send_thread()函數(shù)向各個(gè)客戶端發(fā)送數(shù)據(jù),該發(fā)送過(guò)程中調(diào)用了sendto()函數(shù)。出于調(diào)試目的,當(dāng)所有客戶端的運(yùn)算結(jié)果返回之后,在服務(wù)器端把得到的結(jié)果打印到終端上輸出,之后再次把新數(shù)據(jù)發(fā)送給各個(gè)客戶端。
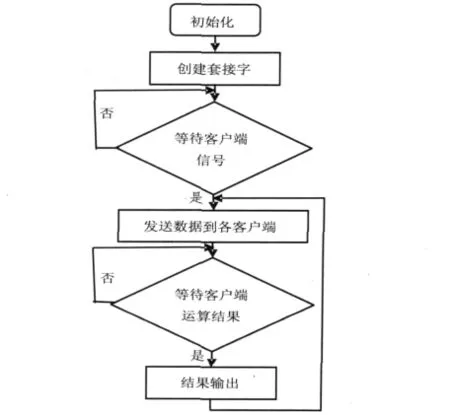
圖1 服務(wù)器端軟件流程圖
4.2 客戶端實(shí)現(xiàn)
客戶端程序的編寫(xiě)采用了ADI公司提供的VDK+lwIP進(jìn)行開(kāi)發(fā),采用這種方式進(jìn)行開(kāi)發(fā)主要是考慮到客戶端軟件復(fù)雜程度遠(yuǎn)遠(yuǎn)小于服務(wù)器端(主要用于運(yùn)算),而且Visual DSP開(kāi)發(fā)環(huán)境已經(jīng)提供了一個(gè)完整的網(wǎng)絡(luò)應(yīng)用程序開(kāi)發(fā)框架,無(wú)需手工編寫(xiě)大量底層代碼。因?yàn)榭蛻舳说膽?yīng)用程序主要用于數(shù)據(jù)運(yùn)算,過(guò)程相對(duì)簡(jiǎn)單,客戶端軟件流程圖如圖2所示。首先創(chuàng)建一個(gè)socket套接字,但無(wú)需進(jìn)行綁定,創(chuàng)建套接字成功之后,向服務(wù)器端發(fā)送一個(gè)測(cè)試字符串,表示該客戶端已經(jīng)準(zhǔn)備好接收數(shù)據(jù),然后等待服務(wù)器端發(fā)送來(lái)的數(shù)據(jù)。待需要進(jìn)行運(yùn)算的數(shù)據(jù)接收完整之后開(kāi)始進(jìn)行數(shù)據(jù)運(yùn)算,再把運(yùn)算得到的結(jié)果發(fā)送給服務(wù)器端,再次進(jìn)入等待接收服務(wù)器端數(shù)據(jù)狀態(tài)。
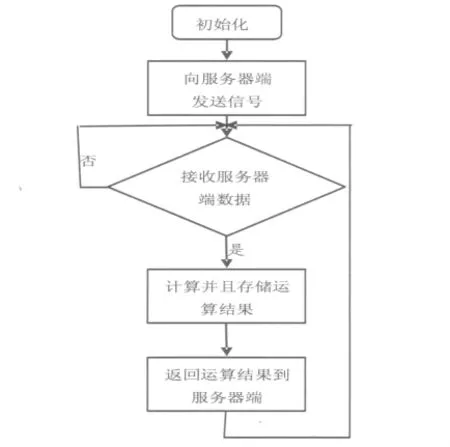
圖2 客戶端軟件流程圖
5 實(shí)驗(yàn)與結(jié)果
5.1 矩陣的乘法實(shí)現(xiàn)
為了驗(yàn)證這個(gè)并行計(jì)算系統(tǒng)的性能,設(shè)計(jì)了一個(gè)矩陣乘法運(yùn)算試驗(yàn)。假設(shè)矩陣A、B、C均是n階方陣,其中A被劃分為n個(gè)n階的子矩陣,A、B是將要進(jìn)行乘法運(yùn)算的初始矩陣,C存放運(yùn)算結(jié)果,C在運(yùn)算前為零矩陣。現(xiàn)在假設(shè)有Pn個(gè)客戶端(n≥2),初始化進(jìn)程后,各個(gè)客戶端的存儲(chǔ)器中存有劃分好的子矩陣A和完整的矩陣B,用于存放局部運(yùn)算結(jié)果的矩陣Ci(2≤i≤n)。然后利用各個(gè)客戶端已有的數(shù)據(jù)進(jìn)行局部矩陣運(yùn)算并傳輸數(shù)據(jù)結(jié)果,最后將各客戶端的子矩陣進(jìn)行匯總,即得矩陣相乘的結(jié)果矩陣C。作為對(duì)比,又把矩陣相乘在單處理機(jī)上進(jìn)行試驗(yàn),即將A矩陣的一行和B矩陣的一列一一做串行運(yùn)算。理論上來(lái)講,除去通信開(kāi)銷(xiāo)外,并行計(jì)算矩陣乘法的速度應(yīng)該是單處理機(jī)進(jìn)行同一矩陣乘法的2倍(所有處理機(jī)的硬件配置相同)。
衡量一個(gè)并行計(jì)算系統(tǒng)的優(yōu)劣主要有以下幾點(diǎn)標(biāo)準(zhǔn):各計(jì)算結(jié)點(diǎn)負(fù)載的均衡性,即應(yīng)使各計(jì)算結(jié)點(diǎn)的計(jì)算量盡量相同;算法的效率(即計(jì)算結(jié)點(diǎn)計(jì)算能力的利用率)及加速比(即計(jì)算速度和計(jì)算結(jié)點(diǎn)數(shù)之間的關(guān)系),理想的情況是效率為100%,計(jì)算速度和計(jì)算結(jié)點(diǎn)數(shù)成正比關(guān)系;算法的容錯(cuò)性,即在系統(tǒng)中若干計(jì)算結(jié)點(diǎn)出故障,不會(huì)影響計(jì)算結(jié)果的正確性,好的算法應(yīng)有強(qiáng)的容錯(cuò)性。有關(guān)參數(shù)定義如下:
加速比=單機(jī)計(jì)算時(shí)間/n個(gè)計(jì)算結(jié)點(diǎn)并行計(jì)算完成時(shí)間;
并行效率=加速比/n;
5.2 結(jié)果及分析
采用不同節(jié)點(diǎn)對(duì)1000×1000矩陣做乘法矩陣運(yùn)算,由于網(wǎng)絡(luò)延遲的不確定性,于是對(duì)同一結(jié)點(diǎn)數(shù)進(jìn)行了5次矩陣運(yùn)算,取平均值后得到的實(shí)驗(yàn)結(jié)果如表1所示。并行計(jì)算的運(yùn)行時(shí)間取決于結(jié)點(diǎn)計(jì)算時(shí)間最長(zhǎng)的那個(gè)。
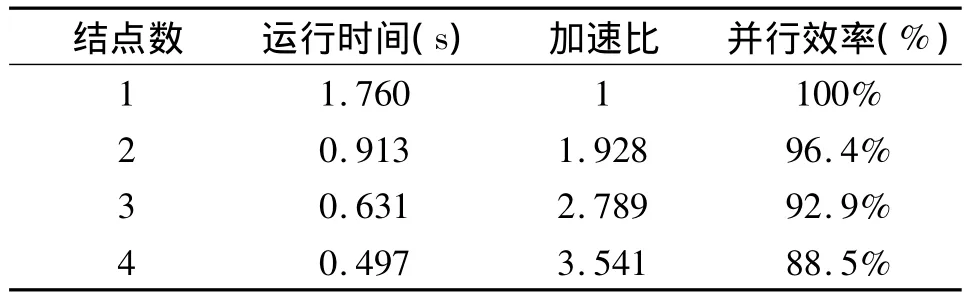
表1 不同計(jì)算結(jié)點(diǎn)的實(shí)驗(yàn)結(jié)果
客戶端均采用相同的硬件結(jié)構(gòu),因此運(yùn)算速度比較接近。通過(guò)表中的數(shù)據(jù)可知,與單個(gè)處理機(jī)的矩陣運(yùn)算速度相比,多結(jié)點(diǎn)情況下的矩陣運(yùn)算速度有明顯提高。系統(tǒng)具有很好的可伸縮性,為解決大量實(shí)時(shí)性數(shù)據(jù)的處理速度問(wèn)題提供了新的途徑。
6 結(jié)束語(yǔ)
基于以太網(wǎng)的多DSP并行計(jì)算系統(tǒng)對(duì)大量實(shí)時(shí)性數(shù)據(jù)的運(yùn)算速度有明顯的提高,并且易于擴(kuò)展。首先移植了uclinux操作系統(tǒng),在此操作系統(tǒng)基礎(chǔ)之上建立了以太網(wǎng)通信,并移植了并行算法到此操作系統(tǒng)進(jìn)行試驗(yàn),以矩陣相乘為例,得到了較好的處理結(jié)果。在下一步的研究工作中,將把并行算法的改進(jìn)作為提高系統(tǒng)效率的重點(diǎn)。
[1]戴光明,戴曉明.基PVM的微機(jī)網(wǎng)絡(luò)并行計(jì)算及其應(yīng)用[J].計(jì)算機(jī)工程與應(yīng)用,2000,25(4):154 -156.
[2]張新菊,劉羽,韓梟.行劃分的矩陣相乘并行改進(jìn)及其DSP實(shí)現(xiàn)[J].微計(jì)算機(jī)信息(嵌入式與 SOC),2008,24(7):216-218.
[3]朱美能,李德華,金良海,黃翔.基于多DSP的并行實(shí)時(shí)視頻處理系統(tǒng)[J].計(jì)算機(jī)與數(shù)字工程,2007,35(8):41-44.
[4]Pierre G Paulin,Chuk Pilkington.Parallel programming models for a multiprocessor SoC platform applied to networking and Multimedia[J].IEEE Transactions on Very Large Scake Integration(VLSI)Systems,2008,33(7):667-680.
[5]ADI.Visual DSP++4.5 Kernel(VDK)User’s Guide[M].Analog Devices,Inc.April 2006.
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:47:06
中國(guó)洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
鐵道通信信號(hào)(2018年5期)2018-06-28 03:06:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
知識(shí)經(jīng)濟(jì)·中國(guó)直銷(xiāo)(2017年5期)2017-06-15 20:28:19
通信電源技術(shù)(2016年6期)2016-04-20 06:21:32
