計算機考試數據分析中數據挖掘技術的應用
2010-07-07 08:47:52劉俊熙
制造業自動化 2010年9期
吳 英,劉俊熙
(上海政法學院,上海 201701)
0 引言
我院是一所文科類學校,計算機教研室承擔全校所有的計算機基礎課程,過去計算機考試都是采用局域網加FTP的上機考試形式,考試過程中存在一些弊端。在計算機課程的教學中,把傳統筆試與計算機技術結合到一起的考試方式越來越被師生所接受。我院智能在線考試系統的設計和建立實現了學生上機考試。該系統通過網絡服務器的設置,學生所用的計算機作為客戶端來登錄服務器獲得試題,答題完畢后網上提交試卷,軟件系統對學生的答卷按班級學號等進行分類、整理。然后進行智能化的判卷、給分(對部分題目類型能夠實現)。
目前我們的考試系統經過一年多的實際運用已經可以快捷、安全的上傳答卷,監考教師的負擔大大減輕,并且可以通過該系統獲取大量的、具體的考試數據。但是如何利用智能在線考試系統所積累的考試數據來分析教師的教學效果和學生的學習效果一直是該系統建立以來我們所需要分析和研究的,因為我們知道這些數據的分析有助于下一步的教學計劃的制定和教學任務的實施,尤其是對學生對教學內容的興趣、教學效果的檢驗等內容的分析和了解有助于我們有的放矢地進行教學活動的計劃和實施。正是在這樣的背景下,采用數據挖掘方法中的交叉表分析和相關分析,獲得的分析結果將有助于完善計算機教學計劃的更好實施。
1 數據挖掘技術的基本理解
人們在日常生活中經常會遇到這樣的情況:超市的經營者希望將經常被同時購買的商品放在一起,以增加銷售;保險公司想知道購買保險的客戶一般具有哪些特征;醫學研究人員希望從已有的成千上萬份病歷中找出患某種疾病的病人的共同特征,從而為治愈這種疾病提供一些幫助。
對于以上問題,現有信息管理系統中的數據分析工具無法給出答案。因為無論是查詢、統計還是報表,其處理方式都是對指定的數據進行簡單的數字處理,而不能對這些數據所包含的內在信息進行提取。隨著信息管理系統的廣泛應用和數據量激增,人們希望能夠提供更高層次的數據分析功能,從而更好地對決策或教學工作提供支持。正是為了滿足這種要求,從大量數據中提取出隱藏在其中的有用信息,將機器學習應用于數據庫的數據挖掘(Data Mining)技術得到了充分的應用。
數據挖掘就是從大量的、不完全的、有噪聲的、模糊的、隨機的數據中,提取隱含在其中的、人們事先不知道的、但又潛在有用的信息和知識的過程。其方法通常可以分為兩大類:
1)統計型。常用的技術有概率分析、相關性、聚類分析和判別分析等,統計學的領域包括概率論和統計推理,這些都慣用于創建代表數據集的模型。一些數學家還認為數據挖掘中使用的模型實際上都是統計方法。統計方法的優點是精確、易理解且已廣泛使用。許多人認為統計方法是數據挖掘最準確的形式,事實上,許多數據挖掘技術都利用存在已久的統計技術。如關聯算法使用了支持度和置信度;聚類技術使用A均值算法;
2)人工智能中的機器學習型。通過訓練和學習大量的樣品集得出需要的模式或參數。數據挖掘的應用中,最終的目標都是發現有價值的知識和信息,有共同的思路和步驟,但也存在很大的差異和區別。由于各種方法都有自身的功能特點以及應用領域,數據挖掘技術的選擇將影響最后結果的質量和效果,通常是將多種技術結合使用,形成優勢互補。
2 數據挖掘技術的方法分析
在本文中我們以SPSS中的多維交叉表分析和關聯分析為例,闡述數據挖掘在我學院智能在線計算機教學考試系統中的應用。
2.1 多維交叉表分析
所謂多維交叉表分析是顯示兩個或多個變量的聯合頻數分布表,簡稱列聯表或交叉表。它屬于離散多元分析的范疇,生成二維或多維交叉表,主要用以分析各事物、現象的差異性,判明所考察的各變量之間有無關聯。例如想了解不同性別,受教于同一教師情況下,對學習所關心內容之間的關系,可以利用該過程形成一個二維統計表,以顯示不同性別,受教于同一教師情況下,對學習所關心內容人數頻數分布情況、相關度,并可選擇適宜的方式進行檢驗。在多維交叉表分析可以選擇輸出所選變量之間的相關系數表,下面就相關分析和相關系數做簡單介紹。
2.2 關聯分析
在數據挖掘中關聯規則挖掘就是從大量的數據中挖掘出有價值描述數據項之間相互聯系的有關知識。隨著收集和存儲在數據庫中的數據規模越來越大,人們對這些數據中挖掘相應的關聯知識越來越有興趣,早先關聯挖掘應用于超市和大賣場等零售行業,人們從大量的交易記錄中發現有價值的關聯知識,幫助進行商品目錄的設計、交叉營銷或幫助進行其它有關的商業決策。根據關聯規則所涉及的關聯特性來進行分類劃分,關聯挖掘可擴展到其它數據挖掘應用領域,如進行分類學習,或進行相關分析。
客觀事物之間是相互聯系、相互影響和相互制約的,事物之間的這種相互聯系反映到數量上,說明相關的變量之間存在著一定的關系。一般來說,變量之間的關系可以分為兩類,一類是確定性關系,即通常的函數關系,例如圓面積S與半徑r的關系,S=∏r2。又如電流強度I、電阻R和電壓V之間的關系I=V/R。另一類是非確定關系,即相關關系,例如人的身高與體重,身高不同的人體重有差異,但是身高相同的人,體重有不一樣。同樣,體重相同的人,身高也不一定一致。這說明身高和體重之間不是確定的函數關系。但是人們大概不會懷疑身高越高的人體重越重這一事實,身高和體重的關系就屬于相關關系。相關分析就是是以分析變量間的線性關系為主的,研究他們之間線性相關密切程度的一種統計方法。
通過幾個描述相關關系的統計量可以確定相關的密切程度和線性相關的方向。這些統計量中包括:
1)皮爾遜(Pearson)相關系數,通常用R表示。如果對變量X和Y進行觀測,得到一組數據:xi,yi( i=1,2…,n),X 和Y之間相關系數的公式為:
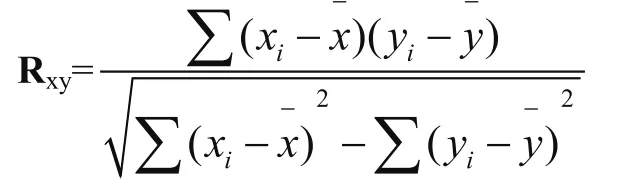
|Rxy|≤1。0< Rxy<1,稱Y與X正相關;-1<Rxy<0,稱Y與X負相關;且|Rxy|越接近1,則
說明變量Y與變量X之間的線性關系越顯著。如果Rxy則稱Y與X不(線性)相關。當|Rxy|=1時,稱X與Y完全(線性)相關。
3 數據挖掘具體實證及步驟
3.1 數據采集
數據采集就是從大量數據中取出一個與挖掘目標相關的數據子集,通過數據樣本的精選,不僅能減少數據的處理量,還能突出相關的規律性,為此數據采集中的取樣的代表性和質量尤關重要。本文選擇以下數據作為分析指標,如表1所示。
3.2 分析數據、定義變量
對于選擇題,要先考慮將每道題目定義成一個變量,如性別定義為Gender變量、上傳時間定義為Time變量、考試得分定義為Score變量、任課教師定義為Teacher變量。又由于SPSS不能處理字符型變量,因此要將定性答案轉換為數字型答案,轉換前后變量值的對應關系如表2所示。
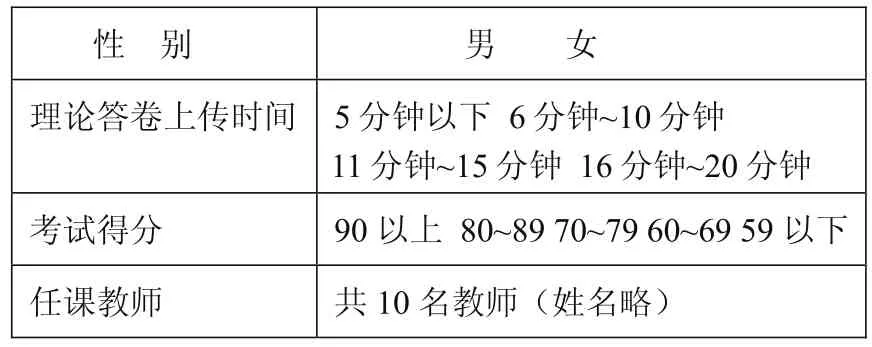
表1 數據采集樣本表
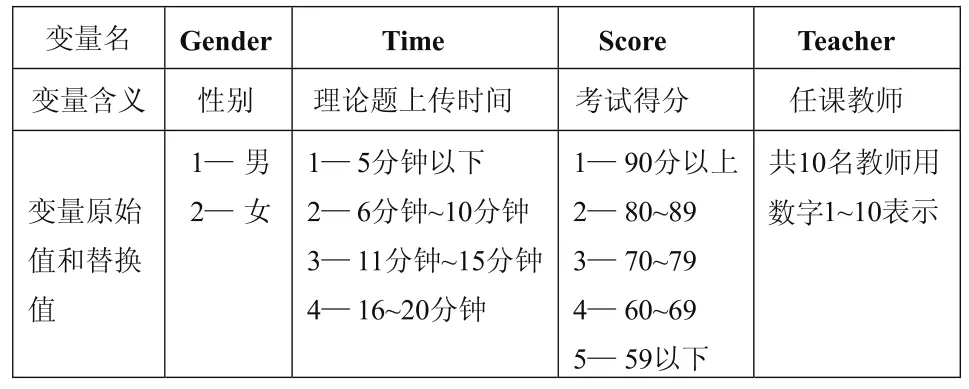
表2 數據分析和定義變量表
替換好以后的數據表如下圖所示。

3.3 交叉表分析

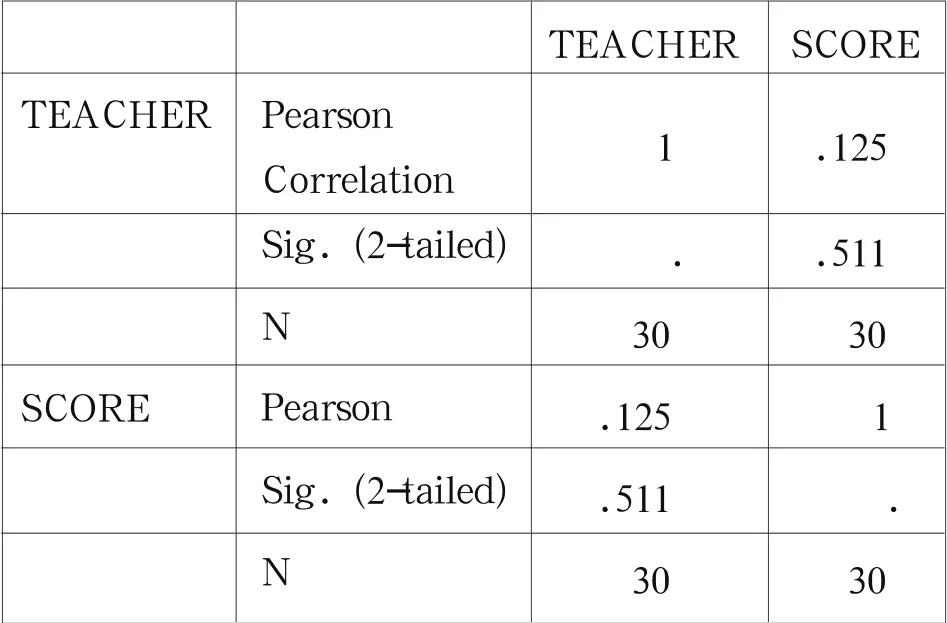
3.4 相關分析
4 結論分析
1)從交叉表中我們可以看出不同性別層次的學生、不同任課教師、學生考試成績分布的交叉情況。例如對于男同學來說,共計15個人,任課教師分別為2和3(教師代號):其中2號教師取得90分以上成績1人,60~70分3人,不及格一人;3號教師90分以上1人,80~90分1人,60~70分6人,不及格2人。從總體來看,男同學成績兩極分化比較嚴重,極個別男同學成績優秀,而多數男同學成績徘徊在及格邊緣;與此相比,女同學成績相對較好,多分布在70分以上。根據這一分析,授課教師應該加大對班級男同學的監督力度,授課時適當多考慮男同學的聽課興趣所在,一般來說,只要激發其興趣,男同學會有很強的鉆研精神和動手能力。
2)從相關分析我們可以看出,教師同學生成績之間的相關系數并不高,僅為0.125,說明兩者之間并不存在明顯相關性,這可能同我校計算機基礎課教師統一教材、統一試驗、統一教學重點有關,因為課程內容高度統一,所以教師個性發揮在成績中表現不明顯。
應該指出,本文舉例僅僅是是數據挖掘在我院計算機教學智能在線考試系統數據分析中的一個小樣本數據具體應用,在實際統計工作中可擴大樣本容量進行更深入的分析后再對問題下一個較準確的結論。事實上數據挖掘的功能遠不止如此。采用數據挖掘方法可以將原本獨立的、分散的問題聯系起來,展現了問題的本質和潛在聯系。可以幫助教師更深入的了解學習效果同哪些因素有關,從而加強相關因素的建設工作,以求達到更高的目標。
同時通過分析總結,筆者對數據挖掘應用到計算機考試系統數據分析運用上提出更具體的建議:
1)對需要解決的問題擬定更為詳細的挖掘目標。雖然數據挖掘的最后結構是不可預測的,但對要探索的問題應該有所預見,不能盲目地為了數據挖掘而數據挖掘。清晰地定義出要解決問題,認清挖掘目標是數據挖掘的重要一步。
2)數據準備。數據挖掘對數據有著嚴格的要求,先期的數據準備工作要占60%的時間,且對數據挖掘的成敗至關重要。如果是根據考試系統進行搜集,事先要根據待解決問題和打算采用的更為周全而完善的數據記錄方式;在數據收集的過程中要注意收集指標的全面,對于缺失的數據要采用一定方法進行彌補。數據準備工作不到位,意味著后面的工作注定是不完整而且是缺乏代表性的。
3)選擇適當的數據挖掘方法和軟件。很多數據挖掘方法都是成熟算法,但根據挖掘對象和挖掘目標的不同而選擇不同的算法則需要一定的經驗或創新,借助數據挖掘軟件可以使數據挖掘變得簡單易行,目前使用最廣泛的數據挖掘軟件是SPSS和SAS。
[1] 袁燕.決策樹算法在高校教學評價系統中的應用[J].浙江海洋學院學報,2006,04.
[2] 彭玉清,等.數據挖掘技術及其在教學中的應用[J].河北科技大學學報,2002,04.
[3] 韓冬.數據挖掘在學分制教學管理中的應用[J].教育信息化,2007,07.
[4] 盛宇,劉俊熙.數據挖掘在政府電子公共化服務中的應用[J].情報雜志,2007,7.
[5] 羅雨滋,付興宏.數據挖掘在教育信息化中的應用[J].固原師專學報,2005,06.
[6] 林少培,董伯懦.工程MIS中的數據挖掘和知識深化的探討[A].智能技術應用與CAD學術討論會,論文集,2004.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
大眾投資指南(2021年35期)2021-02-16 01:06:26
科技傳播(2019年22期)2020-01-14 03:06:34
學苑創造·A版(2018年11期)2018-02-01 06:29:20
消費導刊(2017年20期)2018-01-03 06:26:40
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
信息通信技術(2015年6期)2015-12-26 01:16:46
衡陽師范學院學報(2015年3期)2015-02-10 06:02:23
