基于核心圖聚類的郵件網絡社區發現
2010-07-25 00:33:42徐汀榮喬志偉
網絡安全與數據管理 2010年17期
彭 玲,徐汀榮,喬志偉
(蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
隨著互聯網的發展,網絡成為工作和生活中相互聯系的重要工具,與此同時,網絡社區[1]也應運而生。網絡社區是指基于電腦網絡的虛擬社會關系網絡的載體,在這種網絡中,相同類型的節點之間存在較多的連接,而不同類型節點之間的連接則相對較少。網絡社區通常滿足六度分割理論及150法則[2]等特征,通常是現實社區的近似。因此對網絡社區的發現,對了解現實社會中的社會關系網絡有著特別重要的意義。
郵件社區作為一種網絡社區,同樣與現實的社會關系網絡同構,滿足小世界網絡模型[3],由于電子郵件本身的優勢[4],有利于發現社會關系網絡的動態特性。目前有關網絡社區發現的研究較多,具有代表性的方法有Girvan和 Newman提出的基于去邊的 G-N算法[5]、Aaron和Newman的層次聚類的算法以及基于三角環的Radicchi方法[5]等。但這些算法時間復雜度高,不易于處理大規模的網絡。
本文從圖論的角度出發,首先采用基于貪心的圖形聚類算法,通過計算節點序列密度變化確定社區劃分的個數及每個社區的核心代表節點,然后以這些核心節點為中心,采用基于節點相似度的動態中心調整算法將節點劃分到其所屬的社區中,從而完成對郵件社區的劃分。
1 基本概念
郵件網絡是社會網絡的一種,可以采取社會網絡的相關方法對郵件網絡進行社區劃分。為了便于算法的描述,首先對文中使用的社會網絡圖及相關概念進行數學描述和說明。
(1)網絡圖。通信結構包括收件人和發件人的聯系信息,為了表示通信次數和方向,本文選擇有權有向網絡圖對郵件網絡進行表示。設 G=(V,E,W),其中,V是全部頂點vi的集合,表示電子郵件的收件人或發件人;E是所有邊 eij的集合,其中與每個頂點 vi直接相連的頂點被定義為 Ai,則 Ai={vj|eij∈E};W 為邊的權重集合,任 意 兩 個 節 點 vi、vj若 有 e=(vi,vj)或 e=(vj,vi)則 表 明vi、vj之間存在通信聯系,而 W(e)∈W,可以用郵箱 vi、vj的通信次數來描述。
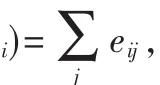
(3)節點的密度。設節點 i∈H?V,則 i關于 H的局部密度為:
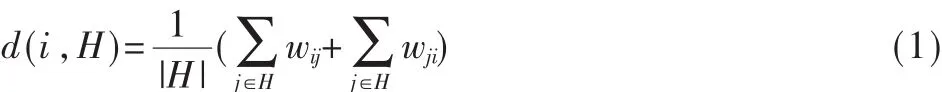
其中,wij為節點 i向節點 j發送郵件的次數,而 wji為節點j向節點i發送郵件的次數。

D(H)表示H內密度最弱的節點集合。
(4)網絡社區中心。在一個包含m個節點 v1,…,vm的社區中,設Xi記錄郵箱vi與其他郵箱的通信次數,則社區中心:

它是社區中的節點與其他節點相互關聯的平均值,是整個社區的代表節點。
(5)社區密度及社區有效直徑[3]。設Gk是G的子圖,表示一個社區。社區Gk的密度記作D(Gk),定義為所有節點出入度之和與節點個數之比,即:
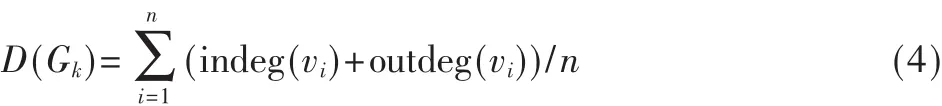
社區有效直徑記作R(Gk),定義為Gk中至少有90%以上的節點對,它們的距離小于或等于R(Gk)。
(6)節點v與社區中心vˉ的相似度。為了便于公式的描述,設X記錄了節點v與其他節點的通信次數,Y記錄了社區中心與其他節點的平均通信次數。則:

2 挖掘社會關系網絡
基于電子郵件的社會網絡分析可以分為兩個步驟:(1)利用郵件日志信息構建有向有權社會網絡,網絡圖中頂點表示電子郵件的收件人或發件人,連線表示兩節點之間存在收發聯系;(2)使用改進的算法來挖掘隱含在此網絡圖中的社會關系,即對網絡圖進行社區挖掘。
2.1 構建社會關系網絡
根據電子郵件地址直接構造一個有向有權圖,圖中頂點表示聯系人,連線表示頂點之間聯系的收發頻率。為了減少噪聲節點對整個網絡的影響,在構圖之前,通過設定閾值,選取收發郵件大于該閾值的節點,然后構造社會關系網絡圖并通過鄰接表和逆鄰接表進行存儲,從而有利于節省空間并方便節點的出入度計算(在本文中,選取 indeg(vi)≥3以及 outdeg(vi)≥3的節點,即閾值為3)。
2.2 郵件社區劃分
郵件社區劃分的基本思想:從圖的劃分以及聚類的角度出發,分別從節點的密度變化和節點對之間的相似度進行考察,并采取社區中心動態調整的技術,主要分為以下步驟:
(1)通過檢測網絡圖中節點的密度變化,確定聚類個數及聚類核心;
(2)節點的劃分和各社區中心的調整。
2.2.1 聚類個數及聚類核心求解算法
假設每一個郵件網絡圖中都存在一個被稱為“聚類核心點”的高密集區域,這些聚類核心點被密度稀疏的點所包圍。則聚類核心中的節點被稱為核心節點,核心節點的集合為核心節點集,而包含這些核心節點的子圖叫做核心子圖。
根據式(1)、(2)求解出每個節點的局部密度以及集合H中密度最弱的節點集合。因此,通過分析最小密度值D(H)的變化,可以近似地求出所有的核心節點集。即如果密度最小的節點存在于稀疏區域,則當刪除該節點時D值會增大,那么下一個被刪除的節點必將存在于密度更高的節點區域內。如果某個節點的刪除引起D值的急劇下降,則該節點很有可能存在于密度較高的區域,也有可能因為節點的刪除導致了周圍其他節點的密度下降。算法(1)給出了計算密度序列變化的執行步驟。
輸入:圖 G=(V,E,W)。
輸出:節點密度變化D及對應的節點集合M。
算法:
①H初始值為所有節點,參數t;
②repeat;
③ 根 據 式(1)、(2)計 算 d(i,H)和 D(t),Mt={i|i∈H∧D(t)=d(i,H)};
④如果集合Mt包含2個或以上相互連接的單個子圖,則取相互之間連接數最小的節點集合;
⑤H=H-Mt,t=t+1;
⑥until集合H為空
計算出節點密度變化序列之后,可以通過式(6)來識別核心節點集。

其中,?為 0到 1之間的可調參數,并且參數?的選擇必須要保證社區劃分滿足以下兩條規則[5]:(1)最小組件規則。社區中節點個數必須≥6;(2)社區穩定性規則。社區節點個數約120最為穩定。若集合Mt滿足式(6),則集合Mt為一核心節點集。
找出了所有滿足條件的核心節點集,可以通過多種方法將這些核心節點集劃分為核心子圖并最終確定聚類個數及聚類核心點。由于郵件網絡圖為稀疏圖,由核心節點所構成的連通子圖稱為核心子圖,核心子圖個數為聚類個數,則核心子圖中的節點就為聚類核心點。
2.2.2 社區劃分算法
算法(2)描述了郵件網絡社區劃分步驟,ENCD(Email Network Community Detecting)郵件網絡社區劃分算法。
輸入:圖 G=(V,E,W)。
輸出:社區號及每個社區對應的節點。
算法:
①輸入求出的核心子圖個數K及核心子圖節點;
②repeat;
③for t=(T,T-1,K,2,1);
④ for每個社區中心cj; //尋找與集合中相似度最大的社區中心cj
⑤ if集合 Mt中包含非核心節點記作 xi,計算 xi與 cj的相似度,若 Sim(xi,cj)≥β則將 xi的社區號記為 j并將其加入到社區cj中; //考慮了一個節點屬于多個社區的情況
⑥for社區網絡中每個社區community[j]
⑦調整該社區的社區中心; //根據式(3)計算
⑧until所有的社區中心均未改變。
3 社區劃分實驗
本文所選實驗數據集為enron郵件數據集以及蘇州大學2009年2月至5月之間的郵件日志內容。其中在http://www-2.cs.cmu.edu/~enron/可下載到 enron數據集,它包括預處理后的151個節點以及252 759條邊。蘇州大學郵件日志內容有183 925個節點以及391 347條邊,內容含校內郵箱間的郵件收發信息以及相關的校外郵箱的郵件收發信息。
在本實驗中,由于考慮到蘇州大學郵箱用戶的隱私問題,對郵箱地址進行了MD5轉換,并且對于每個郵箱mailbox,均由一個郵箱編碼mailboxlD唯一標識。
本實驗的實驗環境為 2.80 GHz Pentium CPU,1GB內存,80 GB硬盤,操作系統為 Microsoft Windows XP,程序開發平臺為Myeclipse。社區劃分結果的每一項由兩個字段組成:郵箱編碼mailboxlD和社區標號CommunitylD。
圖1是enron數據集構成的社會網絡圖,圖2顯示了本文參數對enron數據集社區劃分最終結果的影響。由圖可以看出,不同的?值對確定社區劃分數量影響不大。
表1顯示了使用本文算法與G-N算法在enron以及蘇州大學郵件數據集上的結果比較,其中?取值0.26。modularity[5]為算法的評價指標之一,通常為(0,1)的小數,且值越大說明社區劃分的質量越高。圖3描述了本文算法與G-N算法在enron數據集上社區密度的對比。圖4是在enron數據集上社區有效直徑的對比圖。
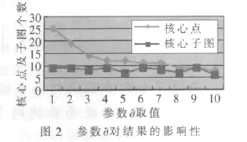
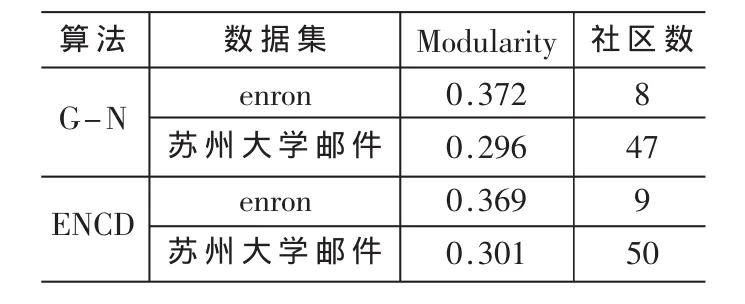
表1 G-N與ENCD算法在相同數據集上的結果對比
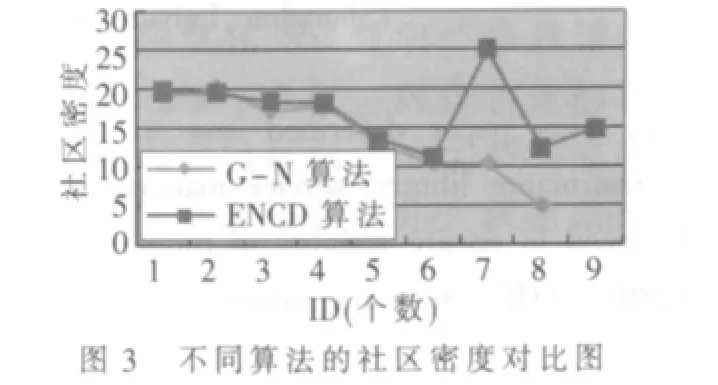
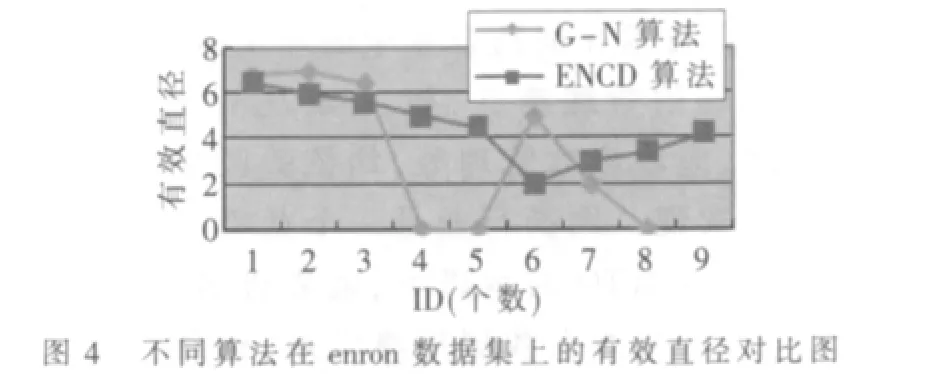
由表1可以看出,本文提出算法在社區劃分個數方面與G-N相當。但是,G-N算法用于enron數據集所發現的社區結果中,有兩個社區中的節點只有1個,還有一個社區的節點個數為2個。這顯然與社區劃分步驟(1)矛盾,而本文提出的算法所求出的每個社區中節點個數則相對比較平均。圖3中G-N算法得出的社區密度最小為5,最大約為20;而本文算法得出的最小值約為10,并且最大峰值為25。可見,本文算法在enron上劃分的社區內部聯系更加緊密。圖4說明了G-N算法與ENCD算法得出的社區有效直徑均相當,因此本文算法用于網絡社區劃分是可行的。
4 分析與評估
郵件社區的劃分本質上是稀疏圖聚類的問題,而此類劃分又是NP完全問題[6]。Girvan和Newman提出的基于去邊的G-N算法,在圖劃分上得取得了很好的效果,但是時間復雜度較高,為O(E2V),其中,E為網絡圖中邊數、V為節點數。因此,不利于大規模的網絡社區發現。而本文算法(1)由于使用了鄰接表及逆鄰接表結構,所以,時間復雜度為 O(|E|+|V|log|V|)+O(|V|)+O(|Ec|),其中Ec為核心圖中的連接邊數。算法(2)時間復雜度為O(E)。所以最壞的間復雜度為O(|E|+|V|log|V|)。蘇州大學郵件數據集上測試的結果表明,本文方法執行效率要優于G-N算法。
本文提出了一種新型的基于核心圖聚類算法的郵件網絡社區劃分,首先通過計算節點的密度變化找出滿足條件的核心節點,然后將這些核心節點集劃分為核心圖,最后通過節點相似度將未劃分的節點劃分到最相似的子圖中。在enron以及蘇州大學郵件數據集上的結果表明,本文算法在社區劃分的質量上與G-N算法相當,但是執行效率要高于G-N。此外,本文算法還支持一個節點屬于多個社區的情況,而這種情況在現實生活中是極為常見的。
[1]ZHANG Y C, YU Xj, HOU L Y.Web communities:Analysis and construction[M].Berlin:Springer,2005.
[2]STROGATZ S H.Exploring complex networks[J].Nature,2001(410):268-276.
[3]陳紹宇,宋佳興,劉衛東,等.關系網絡:一種基于小世界模型的社會關系網絡[J].計算機應用研究,2006,23(5):194-197.
[4]ALSTYNE M V,ZHANG J.EmailNet:A system for automatically mining social networks from organizational email communication[C].In NAACSOS2003,2003.
[5]MARK E J,NEWMAN M.Finding and evaluating community structure in networks [M].PhysicalReview E,69.026113,2004.
[6]GIRVAN M,NEWMAN M.Community structure in social and biological networks[J].Proc.Natl.Acad.Sci.USA 2002(99):8271-8276.
