自中心網絡生成的高效分布式設計與實現*
2010-08-09 08:07:58沈奇威
電信科學 2010年11期
關鍵詞:用戶
金 欣,王 晶,沈奇威
(北京郵電大學網絡與交換技術國家重點實驗室 北京100876;東信北郵信息技術有限公司 北京100191)
1 概述
隨著社會的發展和技術的進步,人與人之間的聯系越來越緊密,手機正是一種為了滿足人們互相溝通需求而出現的工具。根據工業和信息化部2010年2月公布的數據,中國的手機用戶已經達到了7.74億[1],而在這個龐大的數字之后,慢慢浮現出來的是更加豐富的用戶需求,用戶不僅僅滿足于打電話、發短信,各種數據業務正在飛速走進我們的生活,如手機閱讀、多媒體業務、移動廣告等。
隨著數據業務的不斷豐富和電信運營商之間的競爭愈發激烈,提供更好的服務,提高用戶體驗成為降低用戶流失、保證市場份額的關鍵。然而,如何提供更好的服務呢?通過對用戶數據的分析了解用戶喜好,并向用戶提供個性化的信息服務是最主要的方式之一。通過數據挖掘的方式,電信運營商可以了解用戶的個人喜好、消費傾向等,利用這些信息,在提高服務質量的同時努力實現精準的廣告投放增加收益。如何高效地對數以億計的手機用戶的個人數據、業務數據、通話數據等進行處理,成為運營商面臨的新挑戰。
社會網絡分析是數據挖掘的一個分支,它通過分析人與人之間的關聯尋找有價值的信息。自中心網絡是指以個人為中心的社會網絡,通過分析個人與周圍環境的交互來挖掘個人特征。手機本身就是人們之間溝通的工具,運用社會網絡分析方法對手機用戶的通話網絡、短信網絡等進行分析是利用數據挖掘尋找用戶特征的重要手段。
本文將逐步設計基于hadoop分布式計算平臺的自中心網絡生成算法實現,該算法針對mapreduce的分布式計算模型,從數據分布、IO等方面對算法進行改進,最終給出一種適合mapreduce的高效、自中心網絡生成算法。
2 社會網絡分析和自中心網絡
傳統的機器學習和數據挖掘任務處理的對象是單獨的數據實例,這些數據實例往往可以用一個包含多個屬性值的向量來表示,同時假設這些數據實例之間是統計上獨立的。而社會網絡分析以人為個體,通過分析人與人之間的關聯尋找網絡和個人特征。社會網絡分析分為兩個部分:一是對網絡整體進行分析,例如對分群、網絡演變等的研究;二是自中心網絡,就是以個人為中心通過分析其與周圍環境的交互來分析其特征。由于自中心網絡的分析可以挖掘出個人的特征,相比整體網絡分析更加適合個人喜好、消費傾向、騷擾電話分析等信息的挖掘。
相比facebook等構建的社會網絡,手機用戶構建的網絡更加生活化和真實,因此對社會網絡分析具有更大的價值。隨著手機用戶的不斷增多和移動業務的不斷豐富,人與人之間的交互越來越復雜,用戶交互數據無論從維度上還是數量上都對移動運營商的數據分析工作提出了挑戰。近年來分布式計算技術的高速發展為這種海量數據分析的應用提出了新的解決方案,并且隨著分布式計算技術的愈發成熟,其在移動領域的應用也越來越多[2]。通過將用戶數據分布在各個節點上進行分布計算可以顯著提高運算速度,特別是對于自中心網絡,由于是以每個用戶為中心來分析數據的,因此更加適合通過分布式方式進行計算。由于社會網絡分析是通過數據之間的關聯進行的,所以用戶與用戶之間的數據傳遞會使得系統的IO消耗十分嚴重,這是研究分布式社會網絡分析算法必須要解決的問題。
3 基于mapreduce的傳統自中心網絡生成算法
mapreduce是一種計算模型,每個mapreduce分為一個map過程和一個reduce過程,map和reduce的輸入、輸出數據采用鍵值對的方式進行描述,map會對每一個鍵值對進行處理,處理結果用鍵值對的形式進行輸出,輸出結果相同鍵值的會匯總到一起,由reduce進行處理。詳細的mapreduce編程模型介紹可以參照參考文獻[3]。
算法的存儲模型采用以點為基礎存儲整個社會網絡圖。每個點被分配一個ID,用一個對象表示。這個對象除了存儲點的ID之外,還有與該點所有相連的邊。對象表示的點本身為中心點,邊用除了中心點之外的另外一個點來表示,這樣就可以構成一個完整的社會網絡圖。
一個點的自中心網絡由兩部分組成:一是所有與自己相連的點,二是這些點之間的邊。任何一個自中心網絡算法都要首先找出每個點所在的自中心網絡。在現有的存儲模型中,對于一個點對象來說,已經存儲了自己中心網絡中的點以及和自己相連的邊,因此,自中心網絡生成工作的核心就是找到這個點的鄰居之間的邊。傳統的自中心網絡生成算法就是遍歷自己所有鄰居的鄰居來找到自己鄰居之間相連的邊,下面給出傳統自中心網絡算法的分布式實現。
整個算法由一次mapreduce過程就可以完成。在map中對所有點依次進行處理,每個點的處理過程如下。
·遍歷該點的所有鄰居,以鄰居的ID為鍵,以點對象本身為值輸出記錄。
·以自身點ID為鍵,對象本身為值輸出數據。
經過map過程,reduce接收到的每個鍵值對應的是中心點和它的所有鄰居,鄰居對象包含了這個鄰居的邊信息。通過將鄰居對象和中心點對象的邊進行比較可以找到該鄰居與中心點其他鄰居之間是否有邊存在。最終,我們可以找到所有相連的鄰居,從而形成該點的自中心網絡,如圖1所示。
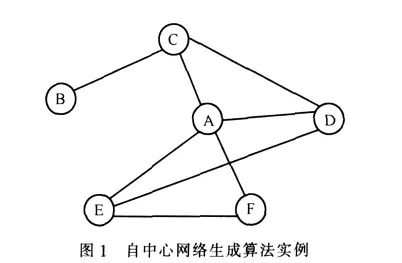
A至F是其中的6個點,設A至F代表的是點對象,而a至f是點的ID,則在map中,A會輸出5條鍵值對分別為a→A、c→A、d→A、e→A、f→A;在reduce中,a對應的數組包含的是(A,C,D,E,F),通過對這些對象的邊信息的遍歷,可以找到
由于在reduce中相同鍵值下的數據排序不能確定,所以不能知道哪一個是中心點,所以不得不將所有數組中的數據先存儲在內存中,然后通過將每個對象的ID和鍵值進行比較,相等的就是中心點。這種方式在一個點有很多鄰居的情況下會導致內存消耗非常嚴重。這個問題可以用mapreduce中常用的技巧secondary sort[4]來解決,這里不再詳述。
4 基于尋找三角形的分布式自中心網絡生成算法設計與實現
§3描述的算法是自中心網絡生成算法基于mapreduce的一個直接而簡單的實現,該算法有3個明顯的不足。
·mapreudce程序的主要瓶頸在IO,而社會網絡分析算法的IO消耗也是非常嚴重的。在這個算法中傳輸了許多不必要的信息,比如點C以a為鍵輸出的數據是為了生成以A為中心的自中心網絡,由于傳輸的是對象,所有該點的鄰居信息,包括B都在對象中,但實際上是不需要的,由于其不了解A的情況,所以不能判斷哪些邊是冗余的。在一個龐大的網絡中,這種不必要的數據將是非常巨大的,大大影響了系統的IO負載,降低了算法的性能。
·分布式算法的效率和數據的分布有很大關系。根據參考文獻[5]分析,在一個真實的網絡中,往往有很少的一些點,這些點的度數非常大,在一個龐大的社會網絡圖中點的度數呈指數分布。§3描述的算法由于以中心點為計算的核心,必然會因為一些度數很大的點使得某些點的計算量非常大,從而影響整個程序的執行效率。
·一個點如果有很多的鄰居,為了找到所有相連的邊,對每一個鄰居的邊都要進行一次完整的遍歷,在遍歷過程中有很多是不必要的。
可以看出,這些缺陷都是由于算法實現采用基于中心點遍歷鄰居的方式導致的。這種方式由于圖中點的差異必然導致數據分布的不均衡,而由于在每個點的處理過程中的重復且復雜的計算,使得單點負載嚴重影響性能。
因此,需要換一種思路才能解決上述問題。一個點的鄰居如果相連,那么這兩個相連的鄰居和中心點就可以構成一個三角形。如果找到與一個點相關的所有三角形,就相當于找到了所有屬于該點自中心網絡的邊。通過參考文獻[6]的介紹可以看出,找三角形這種操作實際上是將一個大的圖打散成為許多很小的部分,非常適合分布式計算。
基于以上分析提出了一種新的生成自中心網絡的算法。該算法首先要找出圖中的所有三角形,之后只要計算每個點存在于哪些三角形中,就可以判斷該點有哪些鄰居之間是相連的。
改進后的算法需要兩個mapreduce過程,第一個mapreduce過程是找出所有三角形,第二個過程是通過三角形得到自中心網絡。
在第一個mapreduce過程中,在map中輸出一個點鄰居的所有鄰居對,以中心點和兩個鄰居用分隔符相連作為鍵,值為空。reduce中每個鍵對應的相當于是一個3個點組合。如果一個三角形存在,則這個組合會收到3條記錄。通過簡單的計數就可以判斷這3個點在圖中是否可以組成三角形,如果可以,則將該記錄分別以3個點為鍵值輸出3條記錄。例如圖1,A點需要輸出6條記錄,每條記錄是一個字符串,而采用原算法需要輸出4條記錄,每條記錄都是保存該點所有邊信息的點對象。由于新思路沒有以點為中心來計算,所有的數據會更加均勻地分布在各個節點上,保證了負載的均衡,解決了單點負載問題。實際上,這個過程可以優化,如果3個點構不成三角形,那么肯定只能接收到一條記錄,這樣利用ID排序可以為每個三角形只輸出兩條記錄,相當于節省了三分之一的IO。通過這個mapreduce過程,可以得到
在第二個mapreduce過程中,將原圖和第一個mapreduce運算的結果同時作為輸入進行一次計算,在reduce中一個點可以接收到許多三角形,每個三角形對應一條邊,將這些邊匯總起來可以形成該點的自中心網絡。這個過程也有單點的問題,但是由于運算過程僅僅是簡單存儲,所以負載問題并不嚴重。
5 算法比較
為了比較兩種算法的性能,對算法進行了測試。測試數據是某論壇數據,通過回帖信息建立起一個社會網絡。用戶數量為78 790,為了使得輸入會分布在不同的機器上,我們將其按大小均勻分為6個文件,相應地使用3臺性能相同的機器搭建了一個hadoop集群,每臺機器可以同時執行兩個map任務和兩個reduce任務。
使用原算法總共運行時間為1 min 57 s,而使用找三角形方式兩步過程運行時間總共為44 s。效率提升的原因主要有3個:一是map到reduce的IO,原算法為794 MB,新算法兩步總共為296 MB,IO消耗降低很明顯;二是原算法不同reduce之間運行時間最短為1 min 18 s,最長為1 min 42 s,運行時間最長的機器使得整個算法運行時間延長了24s,而新算法中不同reduce運行時間相差不超過2s;三是由于算法的不同,每個reduce運行時間都少了很多。
雖然這個數據量不是很大,但是可以明顯看出新的實現方式對算法性能的影響。如果數據量進一步增大,那么由于IO和負載平衡的原因,新算法的優勢將會更加明顯。新算法的優勢在于利用了社會網絡的整體稀疏和度數指數分布的特點改進了算法的IO和負載平衡,從而提高了算法性能。如果圖的密度很大,且所有點度數都很大,新算法的優勢就不存在了,而且由于多了一個mapreduce過程,整個算法的性能可能還低于原算法,但是根據參考文獻[5]中的驗證和分析,幾乎所有的真實網絡都是屬于前一種的。
6 結束語
本文針對真實的社會網絡特征和mapreduce分布式計算模型,提出了一種基于三角形查找的分布式自中心網絡生成算法,用于解決海量數據自中心網絡生成問題。該算法在處理真實社會網絡過程中,很好地利用了真實網絡的分布特征,通過對IO和負載均衡的優化大幅提高了算法性能。如果整個網絡是高密度且度數均勻分布的話,算法性能會低于直接的網絡生成算法。對于手機用戶構建的真實的社會網絡的分析問題,該算法的優勢還是比較明顯的。
1 http://www.enicn.com/article/2010-02-04/0204610402010.shtml
2楊戈,廖建新,朱曉民等.流媒體分發系統關鍵技術綜述.電子學報,2009(1):137~141
3 Jeffrey D,Sanjay G.Mapreduce:simplied data processing on large clusters.In:Proceedings of the 6th Symposium on Operating Systems Design and Implementation(OSDI04),San Francisco,California,USA,December 2004
4 Venner J.Pro hadoop.USA:Berkely,2009
5 Albert R,Barabasi A L.Statistical mechanics of complex networks.Rev Mod Phys,2002(74):10~97
6 Graph twiddling in a mapreduce world.Computing in Science and Engineering,2009,11(4):29~41
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
