平行語料庫設(shè)計(jì)及對(duì)應(yīng)單位識(shí)別
2010-12-07 02:12:02李文中
當(dāng)代外語研究 2010年9期
李文中
(河南師范大學(xué)語料庫研發(fā)中心,新鄉(xiāng),453007)
本研究屬于國家社科基金項(xiàng)目“基于語料庫英語本土化研究及應(yīng)用,編號(hào):07BYY022”及“平行語料庫對(duì)應(yīng)意義單位研究,編號(hào):07BYY002”研究。本文基于李文中2006年在“上海交通大學(xué)慶賀楊惠中先生執(zhí)教50周年暨應(yīng)用語言學(xué)研討會(huì)”的演講“From Translation Units to Corresponding Units: a Corpus-driven Approach”,以及李文中在2007年“第五屆中國英語教學(xué)國際研討會(huì)暨第一屆中國應(yīng)用語言學(xué)大會(huì)”主題研討會(huì)“Corpus-based Language Research”上的主題發(fā)言:“Corresponding Units: Identification and Application”。
1. 作為翻譯數(shù)據(jù)源的平行語料庫
語料庫語言學(xué)研究的出發(fā)點(diǎn)是自然語言,其研究成果的應(yīng)用也應(yīng)回歸到自然語言,研究的基本目的和任務(wù)是探索語言中的意義。在一個(gè)自然文本中,任何一個(gè)意義單位的識(shí)別和理解都不能脫離其共生的語境,也不能脫離文本中該意義單位與其他意義單位構(gòu)成的復(fù)雜同義解釋關(guān)系。同理,任何文本也不是孤立的,理解一個(gè)文本需要借助其他同義文本或已知信息的參照。翻譯是一個(gè)高度依賴語境的過程,在翻譯過程中,譯者交互的對(duì)象包括文本、讀者,以及其他譯者。“好的翻譯”是指那些在譯者社團(tuán)中通過談判交際不斷被重復(fù)的翻譯,并通過重復(fù)應(yīng)用得以確立。因此,當(dāng)前的翻譯文本不僅僅是一種終端產(chǎn)品,還是聯(lián)接前后翻譯文本的重要環(huán)節(jié),繼承了以往翻譯文本中大量的翻譯特征。基于平行語料庫的對(duì)應(yīng)單位翻譯轉(zhuǎn)換對(duì)比分析,其主要意義在于充分尊重語言事實(shí),尊重翻譯事實(shí)。
對(duì)應(yīng)單位指對(duì)應(yīng)源文本和目的文本中任何可識(shí)別的文本塊或片段。對(duì)應(yīng)單位具有意義的完整性和相同性,并且具有各自的句法結(jié)構(gòu)特征。由于其對(duì)語境高度敏感,并在結(jié)構(gòu)上動(dòng)態(tài)變化,對(duì)應(yīng)單位可逆或不可逆。我們研究的問題是:1)在平行語料庫中如何界定等值性,如何在操作層面測量它?2)如何在平行語料庫處理中體現(xiàn)語料庫驅(qū)動(dòng)原則?3)雙語視角對(duì)識(shí)別對(duì)應(yīng)單位有何意義?本研究的目的是通過開發(fā)平行語料庫,確定對(duì)應(yīng)單位識(shí)別程序,并建立對(duì)應(yīng)單位數(shù)據(jù)庫。本研究的主要目標(biāo)為:1)建立一定規(guī)模的平行語料庫,其語料應(yīng)范圍廣泛,包括政治、經(jīng)濟(jì)、科技等領(lǐng)域的現(xiàn)存中英文互譯文本。2)開發(fā)語料庫處理軟件,包括平行語料庫雙語對(duì)應(yīng)單位的提取、儲(chǔ)存、記憶及檢索工具。3)漢英翻譯研究:基于所建平行語料庫,以初期在有限領(lǐng)域建立的模型為基礎(chǔ),深入研究雙語文本的翻譯對(duì)應(yīng)關(guān)系,并建立動(dòng)態(tài)開放的對(duì)應(yīng)單位數(shù)據(jù)系統(tǒng)。4)漢英對(duì)比研究:在雙語語料庫的基礎(chǔ)上進(jìn)行文本的平行、對(duì)應(yīng)及關(guān)聯(lián)研究,分析兩種語言的意義屬性、評(píng)價(jià)體系及批評(píng)價(jià)值。研究方法主要包括:1)利用網(wǎng)絡(luò)等手段,搜集平行文本語料,建立包括廣泛均衡語料的平行語料庫。2)對(duì)應(yīng)單位識(shí)別:前期通過大量人工干預(yù),在有限領(lǐng)域內(nèi)建立初始模型,通過對(duì)應(yīng)的識(shí)別單位數(shù)確認(rèn)句子對(duì)應(yīng),利用后臺(tái)數(shù)據(jù)庫計(jì)算對(duì)應(yīng)單位的頻率,再通過文類、體裁等參數(shù)確定對(duì)應(yīng)單位的分布及頻率。3)對(duì)應(yīng)單位分析。4)基于建成的平行語料庫和開發(fā)的軟件開展相關(guān)研究。
Teubert認(rèn)為,正如自然語言運(yùn)用一樣,翻譯實(shí)踐中譯者群體構(gòu)成了一個(gè)特殊的語用話語社團(tuán),一切翻譯活動(dòng)和行為都在這一特定的話語內(nèi)進(jìn)行。譯者通過翻譯活動(dòng),實(shí)現(xiàn)交互和談判,并促生和確立源語言和目的語之間的意義對(duì)應(yīng)和翻譯轉(zhuǎn)換(Lecture,2004)。在這里,翻譯的過程不是簡單的詞語或句子對(duì)等,也不像Weaver所說的那樣,是一種信息的編碼和解碼過程(1949,轉(zhuǎn)引自馮志偉2003)。翻譯是一項(xiàng)復(fù)雜的社會(huì)活動(dòng)和語用事件,是一種語言交際行為。翻譯中意義的轉(zhuǎn)換和對(duì)應(yīng)產(chǎn)生于譯者內(nèi)部的交流和溝通,并實(shí)現(xiàn)于譯語文本。在這一交互過程中,“正確的翻譯被采用并重復(fù),錯(cuò)誤的翻譯被淘汰”(Teubert 2005)。所以說,翻譯知識(shí)既不來自詞典,也不來自預(yù)設(shè)的規(guī)則和知識(shí)原型,而是存在于翻譯文本中的翻譯事實(shí)。平行語料庫通過收集大量的雙語對(duì)應(yīng)文本,通過對(duì)翻譯事實(shí)的系統(tǒng)描述,利用概率統(tǒng)計(jì)發(fā)現(xiàn)重復(fù)出現(xiàn)的翻譯對(duì)應(yīng)單位,以確立翻譯的對(duì)應(yīng)性。
與基于語料庫實(shí)例研究不同的是,我們所說的平行語料庫不是作為類比和推理的基礎(chǔ)數(shù)據(jù),而是作為翻譯知識(shí)庫;平行語料庫的作用也不僅僅是為了提取翻譯實(shí)例,而是把翻譯文本與數(shù)據(jù)庫作為一個(gè)交互處理的整體。在構(gòu)建平行語料庫時(shí),我們提出以下幾個(gè)基本原則:1)平行文本的來源和領(lǐng)域必須嚴(yán)格界定。領(lǐng)域越廣闊,文本翻譯的對(duì)應(yīng)性變異就越大。能適應(yīng)所有文本的翻譯對(duì)應(yīng)非常少,如人名、地名、機(jī)構(gòu)名稱等,有時(shí)甚至這些普遍被認(rèn)為無歧義的名稱,在不同領(lǐng)域的文本中也會(huì)表達(dá)不同的含義,從而產(chǎn)生獨(dú)特的對(duì)應(yīng)。在語料庫處理中,盡可能劃分一個(gè)大領(lǐng)域內(nèi)部的層級(jí)關(guān)系,并應(yīng)用XML標(biāo)準(zhǔn)進(jìn)行標(biāo)注。2)選取的文本類型應(yīng)從科技領(lǐng)域及對(duì)應(yīng)關(guān)系相對(duì)單純的平行文本開始。語用結(jié)構(gòu)復(fù)雜、話題多元、且對(duì)應(yīng)相對(duì)自由的平行文本一般不作為初始研究的對(duì)象,如虛構(gòu)性文本。文學(xué)文本的自動(dòng)翻譯幾乎難以逾越。3)平行文本的對(duì)齊是分析的結(jié)果,而不是前提。僅僅追求文本結(jié)構(gòu)形態(tài)的對(duì)齊,如通過人工介入或通過概率計(jì)算達(dá)到對(duì)齊的目的,仍需人工對(duì)句子進(jìn)行分析和判斷,這是由于對(duì)齊后的文本要么單位過大,如段落和句子,要么過小,如單詞,都難以得到有效利用。4)文本應(yīng)保持整體性和原貌,與標(biāo)注信息分開(Sinclair 2005:1-16)。標(biāo)注系統(tǒng)應(yīng)動(dòng)態(tài)開放,允許定制并多層多次標(biāo)注。
2. 對(duì)應(yīng)單位的界定及工作原則
Sinclair(2005)在提出“意義單位”這個(gè)概念時(shí),主要考慮的是為語言分析確立一個(gè)基本的分析單位,這個(gè)單位必須是構(gòu)成文本最小的意義單位,它由核心詞(core)和搭配詞構(gòu)成,所以又稱作“詞項(xiàng)”(lexical item)。意義單位的單義性通過詞項(xiàng)內(nèi)部的微型語境得到保證。意義單位可以作擴(kuò)展分析,或稱為“擴(kuò)展的意義單位”,在抽象度上依次分析其類聯(lián)結(jié)結(jié)構(gòu)特征、語義傾向以及語義韻(參見李文中2010)。意義單位這一概念體現(xiàn)了Sinclair的學(xué)術(shù)思想,即1)意義在多詞序列(搭配)中得到呈現(xiàn)①,多詞序列體現(xiàn)了真實(shí)的語用環(huán)境,并框定其意義取向;2)意義、形態(tài)、結(jié)構(gòu)模式甚至語用意向是一個(gè)相互依存的統(tǒng)一體,任何一個(gè)構(gòu)成元素都不可分割和抽離。3)意義單位確立的基礎(chǔ)是復(fù)現(xiàn)頻率(frequency of recurrence)。其基本理據(jù)是,在詞語層面,單個(gè)或多個(gè)詞共現(xiàn),并呈線性組合,順序固定,結(jié)構(gòu)相對(duì)穩(wěn)定,或只允許部分變異;該單位具有復(fù)現(xiàn)概率,在文本中表現(xiàn)為固定詞語序列或詞塊;在語義層面,詞語組合表達(dá)意義完整,具有單義性;在發(fā)生學(xué)層面,意義單位的選擇大多不是單個(gè)詞語的多次選擇,而是同時(shí)選擇的,是一連串說出來的;在語音學(xué)層面,該單位表現(xiàn)為一個(gè)連續(xù)的語音流,與其它意義單位具有明顯的界限。該單位在文本中具有可預(yù)測性,使文本理解從分析走向綜合。意義單位的提出為多詞序列(或稱詞塊、多詞組合)分析提供了理論基礎(chǔ),具有重要的語言學(xué)意義。但意義單位是一種單語理論,其統(tǒng)計(jì)基礎(chǔ)是復(fù)現(xiàn)頻率,且必須通過人工分析才可以獲得。在此基礎(chǔ)上,針對(duì)雙語平行文本,Teubert(2004)進(jìn)一步提出“翻譯單位”概念,即“源語言表達(dá)由一個(gè)節(jié)點(diǎn)詞加上所有搭配詞構(gòu)成,并且在目的語文本中只有一個(gè)無歧義的等值表達(dá),如果存在多個(gè)等值表達(dá),則這些表達(dá)具有同義關(guān)系”。Teubert認(rèn)為翻譯單位是平行文本中可識(shí)別的最小的等值單位,具有單義性,不能被進(jìn)一步分析,并且具有可逆性(reversibility)。
我們注意到,翻譯單位這一概念雖然基于雙語視角,但在平行文本處理中仍存在難題:1)由于強(qiáng)調(diào)“最小分析單位”和“可逆性”,翻譯單位與詞語對(duì)等這兩個(gè)概念幾乎沒什么區(qū)分;有些單位在平行文本中對(duì)應(yīng)嚴(yán)謹(jǐn),卻不一定是最小的;翻譯單位確立后,其意義仍然極不穩(wěn)定,其“無歧義”屬性很難得到保證②。如以下對(duì)應(yīng)包含多個(gè)翻譯單位(用中括號(hào)“[]”隔開):
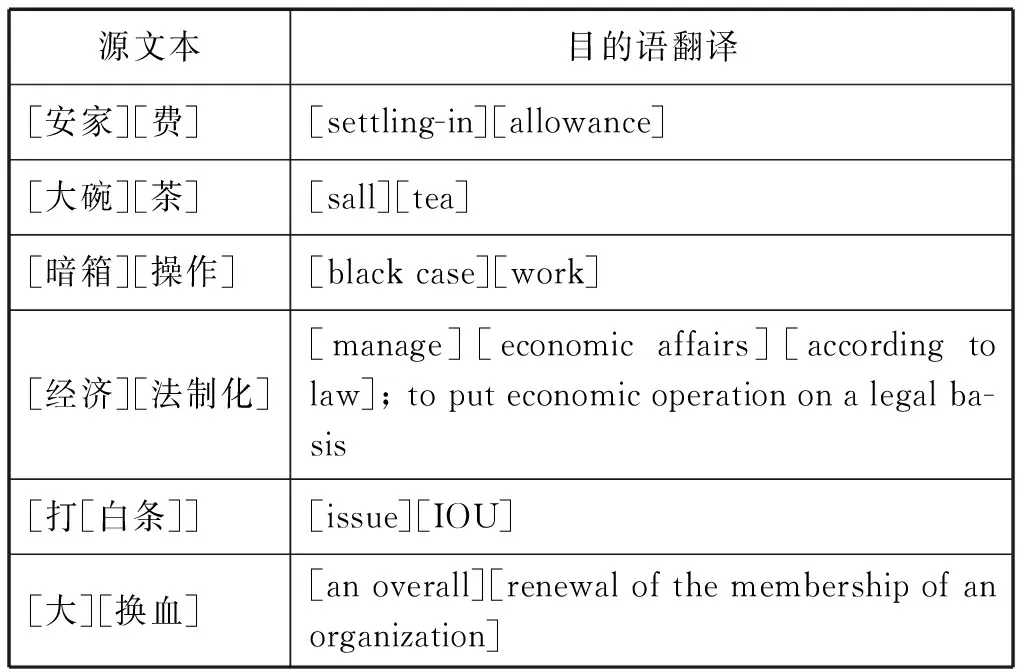
表1 對(duì)應(yīng)及翻譯單位
2) “可逆性”標(biāo)準(zhǔn)忽視了不同源語言文本翻譯視角的差異及語言具體運(yùn)用語境的差異。如漢語源文本“打白條”的對(duì)應(yīng)是“issue IOU”,但英語源文本中的“issue IOU”就不一定對(duì)應(yīng)“打白條”,因?yàn)椤癐OU”和“白條”的文化含義和運(yùn)用語境不一樣。“大換血”的例子亦是如此。3)翻譯單位與意義單位一樣,是一種分析理論,而不能用于識(shí)別操作。因此,我們提出“對(duì)應(yīng)單位”這一概念,即“平行文本中意義對(duì)應(yīng)完整、并具有清晰邊界的任何片段或序列”(李文中2006)。對(duì)應(yīng)單位是平行文本雙語視角下確切對(duì)應(yīng)的片段,其序列可擴(kuò)展,其意義在抽離語境后仍能保持相對(duì)穩(wěn)定;在大型平行語料庫中,可以通過計(jì)算同現(xiàn)對(duì)應(yīng)單位的閾值,擴(kuò)展對(duì)應(yīng)單位的序列;對(duì)應(yīng)單位具有可逆性或不可逆性,這要取決于翻譯文本的具體語境。與翻譯單位不同,對(duì)應(yīng)單位是針對(duì)平行文本處理的操作概念,用于對(duì)應(yīng)片段(或?qū)?yīng)塊)的識(shí)別和提取,是對(duì)以后分析的文本準(zhǔn)備。對(duì)應(yīng)單位的識(shí)別標(biāo)準(zhǔn)是對(duì)應(yīng)邊界的適當(dāng)性和確切性。在此原則下,表1中“安家費(fèi)”作為一個(gè)整體與“settling-in allowance”構(gòu)成對(duì)應(yīng)單位,因?yàn)椤鞍布摇迸c“settling-in”、“費(fèi)”與“allowance”的對(duì)應(yīng)邊界并不清晰。下表中所列都被看作是單一的對(duì)應(yīng)單位,其內(nèi)部不再分割:
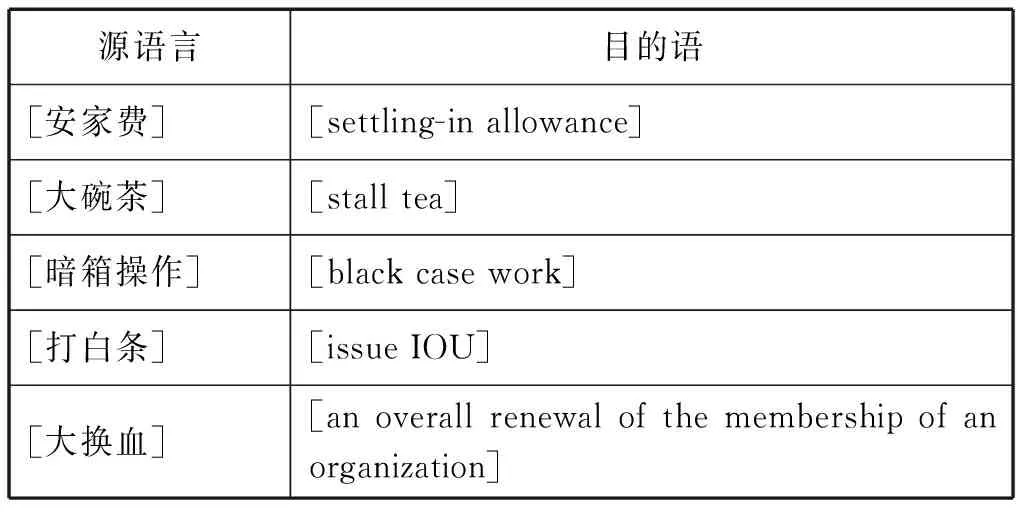
表2 對(duì)應(yīng)單位的邊界
對(duì)應(yīng)單位識(shí)別的工作原則為:1)人工識(shí)別與智能識(shí)別相結(jié)合原則。對(duì)翻譯的對(duì)應(yīng)性判斷依賴雙語語言文化及行業(yè)知識(shí)的運(yùn)用,這是計(jì)算機(jī)不可能做到的,所以初始階段需要人工判斷和識(shí)別文本中的對(duì)應(yīng)單位,軟件系統(tǒng)對(duì)識(shí)別出的對(duì)應(yīng)單位自動(dòng)提取和標(biāo)注,并利用數(shù)據(jù)庫管理起來。之后,軟件應(yīng)用對(duì)應(yīng)單位數(shù)據(jù)庫對(duì)新入庫文本進(jìn)行智能識(shí)別和提取,剩余部分仍由人工完成。2)最優(yōu)邊界原則。由于對(duì)應(yīng)單位的定義非常靈活,所以人工識(shí)別對(duì)應(yīng)單位時(shí)較難把握其邊界。最優(yōu)邊界原則即是在保證對(duì)應(yīng)完整、邊界清晰的前提下,對(duì)對(duì)應(yīng)單位做最小劃分。如“中國社會(huì)各階級(jí)”(the classes in Chinese society)可以進(jìn)一步分為“中國社會(huì)”(in Chinese society)和“各階級(jí)”(the classes)。人工劃分的大小并不是一個(gè)關(guān)鍵問題,但如果劃分的對(duì)應(yīng)單位太大,其在語料庫中的復(fù)現(xiàn)頻率就越低,這可能對(duì)系統(tǒng)后續(xù)的智能翻譯構(gòu)成風(fēng)險(xiǎn)。3)窮盡原則。盡可能匹配最大量單位,使剩余非匹配文本片段減到最少。所以,不同源語言的對(duì)應(yīng)單位應(yīng)分別標(biāo)注。4)區(qū)分連續(xù)性單位和非連續(xù)性單位,標(biāo)記并提取非對(duì)應(yīng)單位。如表2中“以……為代表的”在源語言中是一個(gè)非連續(xù)性單位,而對(duì)應(yīng)的目的語卻是一個(gè)連續(xù)的單位③。對(duì)應(yīng)單位識(shí)別完成后,系統(tǒng)對(duì)平行文本進(jìn)行檢查,并把非對(duì)應(yīng)單位標(biāo)注起來。實(shí)際上,非對(duì)應(yīng)單位標(biāo)注后,也作為一個(gè)序列看待,這是因?yàn)閿?shù)據(jù)庫要與文本不斷交換數(shù)據(jù),平行文本應(yīng)保持完整并與數(shù)據(jù)庫對(duì)應(yīng)起來。
3. 系統(tǒng)設(shè)計(jì)與開發(fā)
我們?cè)谠O(shè)計(jì)系統(tǒng)時(shí),主要考慮到以下需求:1)基于網(wǎng)絡(luò)服務(wù)器,面向多用戶群開放的動(dòng)態(tài)交互平臺(tái),體現(xiàn)“用戶既是享用者,又是參與者和貢獻(xiàn)者”的思想。一方面,多家單位需要分工合作,需要系統(tǒng)對(duì)數(shù)據(jù)實(shí)時(shí)匯總和發(fā)布。另一方面,用戶群共同使用并識(shí)別平行文本中的對(duì)應(yīng)單位,分享和交流對(duì)應(yīng)單位的識(shí)別和判斷經(jīng)驗(yàn)與知識(shí),系統(tǒng)追蹤和記錄參與者識(shí)別與判斷行為,并通過系統(tǒng)智能匹配體現(xiàn)出來。2)把建庫、分析及識(shí)別翻譯看作一個(gè)動(dòng)態(tài)的過程,并整合這幾大模塊,使軟件系統(tǒng)在學(xué)習(xí)和訓(xùn)練中成長。以往的平行語料庫建庫、分析及應(yīng)用被分為多個(gè)相互獨(dú)立的階段,平行文本庫和數(shù)據(jù)庫完成后成為封閉系統(tǒng),個(gè)別系統(tǒng)甚至把文本庫棄之不用,只保留數(shù)據(jù)庫,這可能會(huì)導(dǎo)致數(shù)據(jù)衰老,不堪應(yīng)對(duì)日益變化的語言運(yùn)用。3)人工介入遞減原則。在初始階段,需要大量人工介入,隨著平行庫及數(shù)據(jù)庫的壯大和成長,系統(tǒng)智能匹配能力增強(qiáng),人工介入應(yīng)逐步減少,在以后階段,人工只對(duì)系統(tǒng)析出的非對(duì)應(yīng)塊進(jìn)行判斷和識(shí)別。4)模塊化管理及軟件熱插拔思想。平行語料庫系統(tǒng)內(nèi)部各個(gè)模塊應(yīng)相對(duì)獨(dú)立,并且可定制。軟件一次開發(fā)完成后,不需要重復(fù)開發(fā)。
系統(tǒng)的基本工作流程可分為:1)平行文本的導(dǎo)入與預(yù)處理,包括文本清理、段落和句子XML自動(dòng)標(biāo)注和管理。2)對(duì)應(yīng)單位智能識(shí)別和人工識(shí)別。3)對(duì)應(yīng)單位自動(dòng)提取及入庫管理。4)處理后平行語料庫入庫及數(shù)據(jù)庫關(guān)聯(lián)(見下圖)。
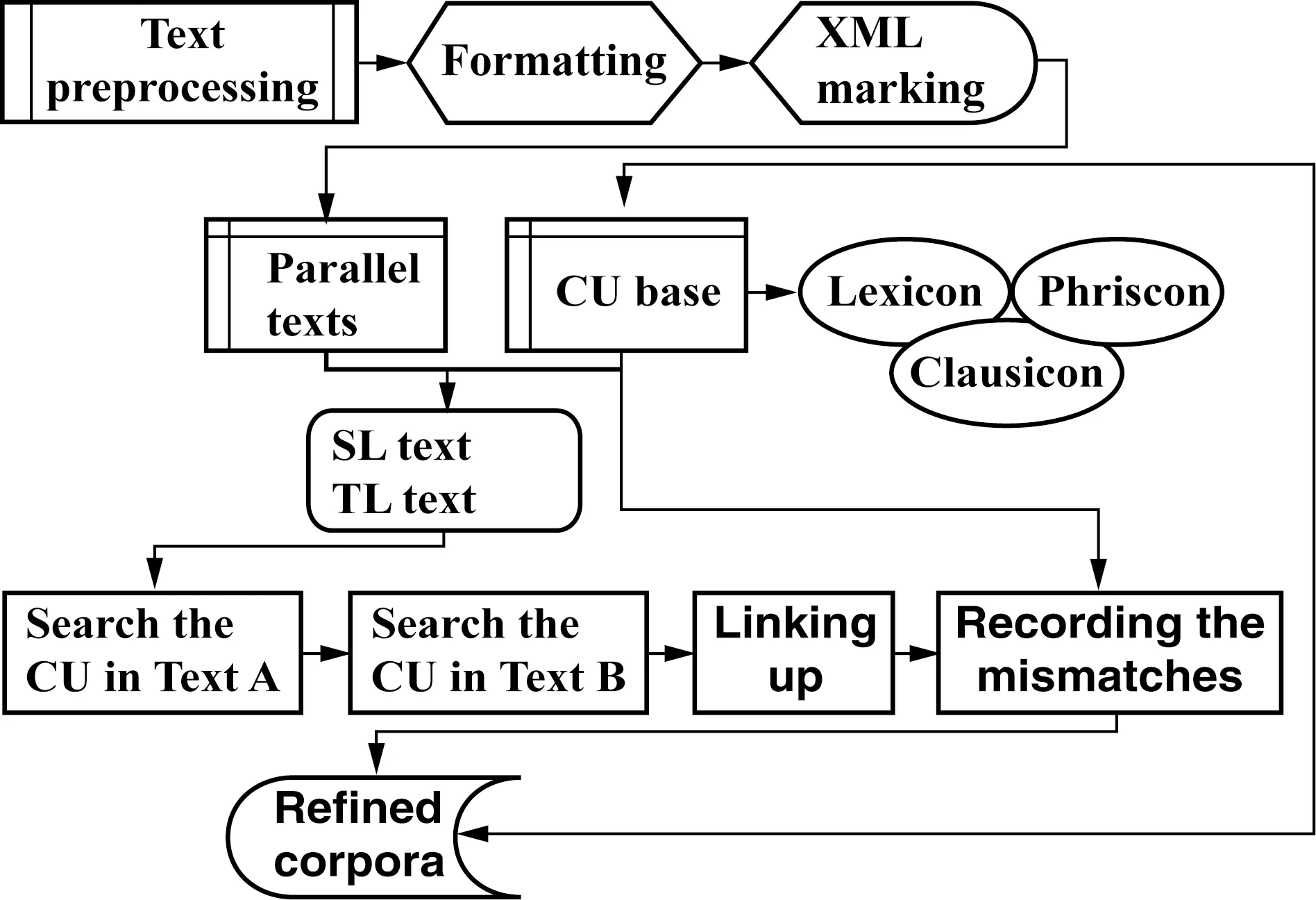
圖1 平行語料庫建庫及對(duì)應(yīng)單位識(shí)別流程示意圖
圖2 軟件系統(tǒng)對(duì)平行文本的預(yù)處理
在智能匹配時(shí),軟件在目的語文本制定區(qū)域內(nèi)查找,并根據(jù)頻率顯示最佳選擇,由人工判斷是否接受。為便于人工觀察,智能匹配在一個(gè)獨(dú)立窗口顯示匹配的單位和語境。智能匹配可以隨時(shí)中斷,開始人工識(shí)別和匹配。識(shí)別者在源語言文本和目的語文本中通過“點(diǎn)擊選中”或“拖拉選中”選擇對(duì)應(yīng)單位,并點(diǎn)擊入庫④。
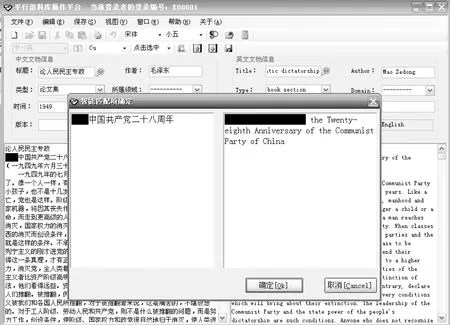
圖3 對(duì)應(yīng)單位智能匹配
平行語料庫統(tǒng)計(jì)和檢索分析分為兩大模塊:1)對(duì)應(yīng)單位檢索和基本信息統(tǒng)計(jì)。2)全文檢索及索引分析。在這里,檢索詞及語境信息都是可以定制的,所以我們把它稱作“語境中的自適應(yīng)單位”(Self-adapted Unit in Context,SUIT),以和傳統(tǒng)語料庫中的KWIC區(qū)別開來。
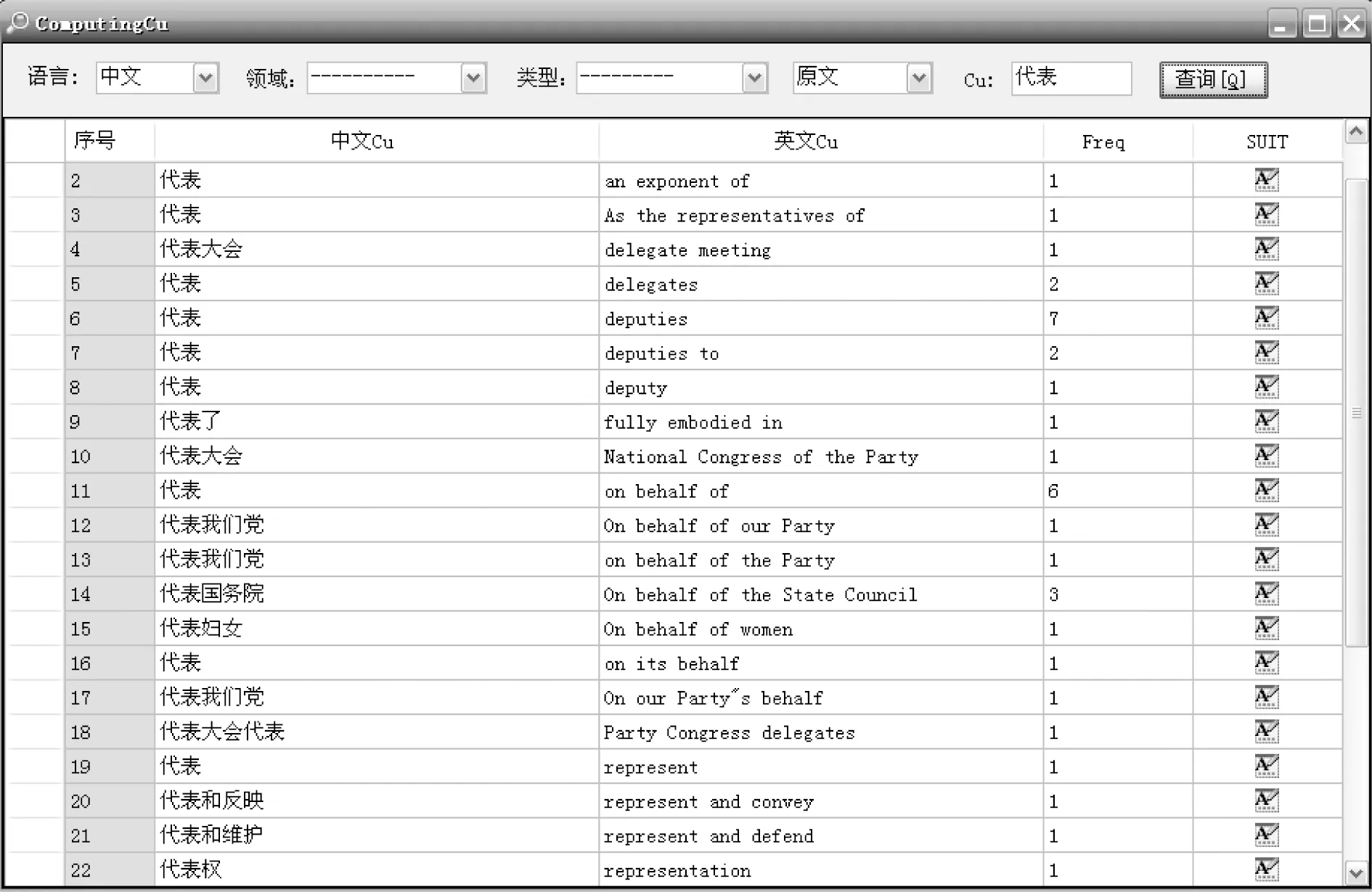
圖4 對(duì)應(yīng)單位檢索及基本信息統(tǒng)計(jì)
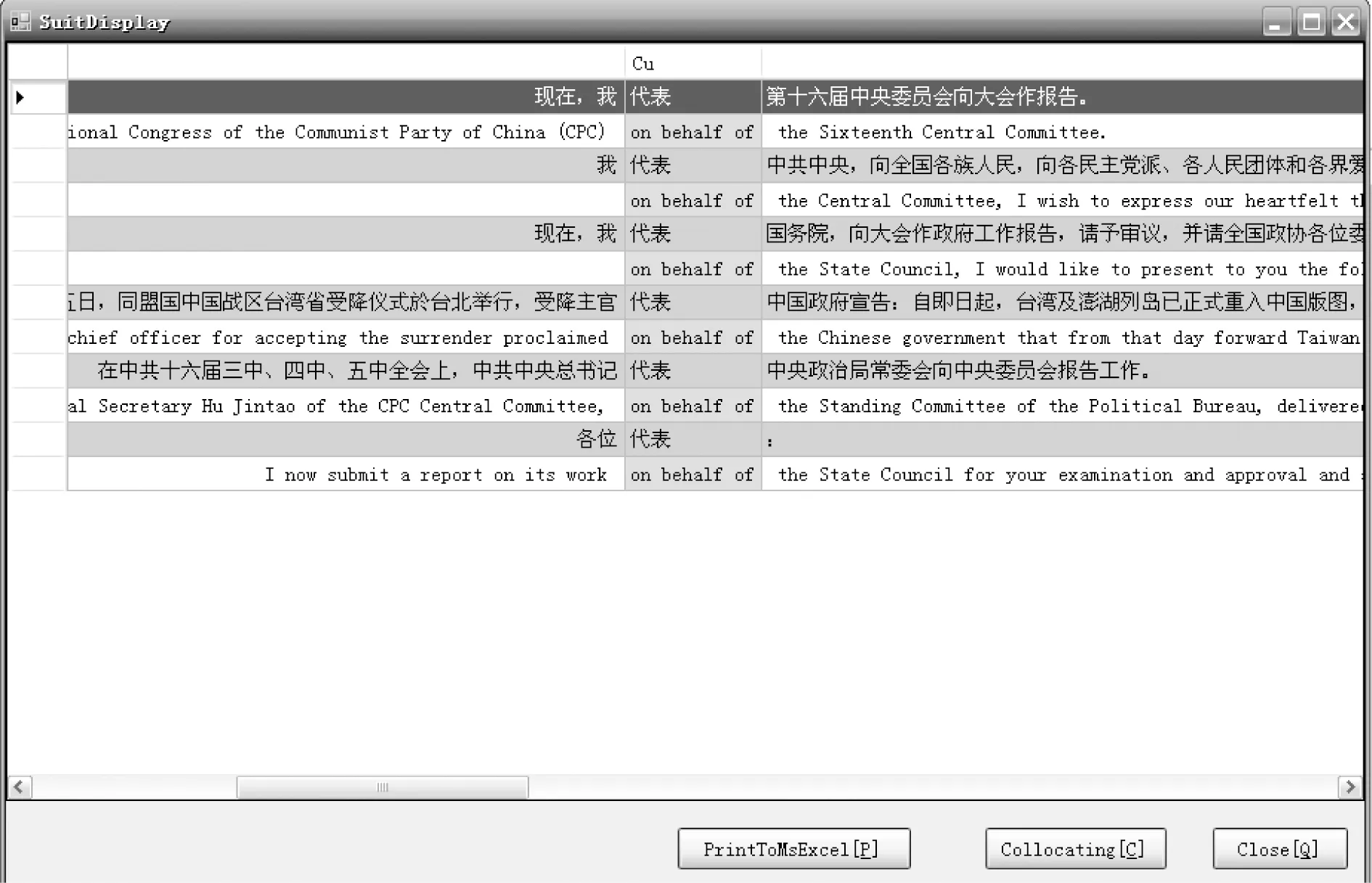
圖5 對(duì)應(yīng)單位的索引分析
在平行文本索引檢索中,實(shí)現(xiàn)對(duì)應(yīng)單位的平行檢索,這時(shí)對(duì)齊的基本依據(jù)是各個(gè)對(duì)應(yīng)塊,在進(jìn)一步計(jì)算對(duì)應(yīng)單位的共現(xiàn)搭配,只計(jì)算所檢索的對(duì)應(yīng)單位左右位置的線性序列。
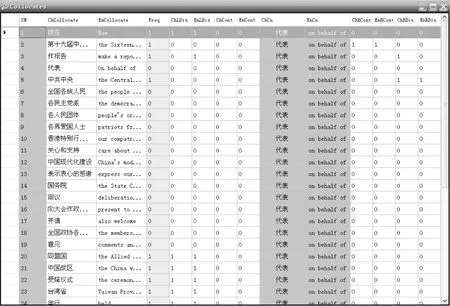
圖6 對(duì)應(yīng)單位的搭配統(tǒng)計(jì)
4. 翻譯對(duì)應(yīng)的復(fù)雜性
盡管目前該平行語料庫尚未完全建成,但初始檢索和統(tǒng)計(jì)顯示的翻譯對(duì)應(yīng)復(fù)雜性,卻遠(yuǎn)遠(yuǎn)超出我們最大膽的想象。從呈現(xiàn)的對(duì)應(yīng)關(guān)系上,我們發(fā)現(xiàn)以下幾種情況:1)一對(duì)多或多對(duì)一對(duì)應(yīng),即一個(gè)源語言表達(dá)在目的語文本中具有多種翻譯,詞語序列越短,翻譯的變異性越強(qiáng)。如“發(fā)展”一詞僅在政治領(lǐng)域文本中就有十余種不同的譯法,使用的詞語(歸元處理后)包括“develop,accelerate,advance,cultivate,promote,evolution,expand,furthering,improve,introduce,move,progress,grow”;作為對(duì)比,以英語為源語言文本中的“develop”一詞分別被譯為“發(fā)展、建設(shè)、開拓、加強(qiáng)、樹立、形成、產(chǎn)生、開發(fā)、建立、拓寬、搞上去、闡明、推動(dòng)”等。2)零對(duì)一或零對(duì)多對(duì)應(yīng)。由于兩種語言語境應(yīng)用及語體運(yùn)用特征不同,源語言中通過語境指涉或預(yù)示的意義,在目的語文本中得到重構(gòu),或者在源語言文本中顯性表達(dá)的意義,在目的語文本中通過指涉進(jìn)行隱性表達(dá)。此外源語言中的贅詞在翻譯過程中被濾除,如漢語中的“X+水平、問題、情況”結(jié)構(gòu),后加的詞語如不表達(dá)實(shí)際意義一般不被譯出。3)簡對(duì)繁或繁對(duì)簡對(duì)應(yīng)。源語言的習(xí)語、略語或成套的表達(dá)在目的語中往往被展開或解釋,如“米袋子省長負(fù)責(zé)制”(譯語:provincial governors assuming responsibility for the rice bag (grain supply))中對(duì)“米袋子”,“打破‘三鐵’”(譯語:break the Three Irons: iron armchairs (life-time posts), iron rice bowl (life-time employment) and iron wages (guaranteed pay))中對(duì)“三鐵”的解釋等。與上述對(duì)應(yīng)關(guān)系相比,功能詞的翻譯對(duì)應(yīng)更加復(fù)雜多變。這表明,以詞語為依據(jù)進(jìn)行形態(tài)、結(jié)構(gòu)和意義分析及轉(zhuǎn)換十分靠不住。也有人把這種翻譯的變異性歸結(jié)為缺乏規(guī)范和標(biāo)準(zhǔn),對(duì)翻譯研究表現(xiàn)出一種規(guī)約性態(tài)度。我們認(rèn)為,翻譯研究應(yīng)該是描述性的,研究者不應(yīng)該凌駕于翻譯實(shí)踐之上,而隨意對(duì)翻譯事實(shí)作出價(jià)值性判斷。
5. 結(jié)語:難題與討論
在對(duì)應(yīng)單位識(shí)別及應(yīng)用中,我們發(fā)現(xiàn)尚存在以下難題:1)對(duì)應(yīng)單位的邊界問題與人工判斷的可靠性問題。從表面來看,每個(gè)識(shí)別者在判斷對(duì)應(yīng)單位時(shí),依靠的是個(gè)人知識(shí)經(jīng)驗(yàn)以及對(duì)語境的把握,似乎是以直覺和經(jīng)驗(yàn)為主,且每個(gè)人判斷的標(biāo)準(zhǔn)及標(biāo)注的邊界不盡一致,這樣很容易得出結(jié)論:對(duì)應(yīng)單位的判斷僅僅是實(shí)驗(yàn)性的,結(jié)果并不可靠。此外,人工判斷某一個(gè)單位時(shí),添加了XML標(biāo)簽,似乎是對(duì)文本進(jìn)行了人工干預(yù),使用了預(yù)定義的框架,不符合“干凈文本”原則和語料庫驅(qū)動(dòng)思想。這是一種誤解甚至是曲解。理由如下:
(1) 人工判斷不是憑空作出的,必須以雙語視角及對(duì)應(yīng)邊界為依據(jù),對(duì)文本中的對(duì)應(yīng)單位進(jìn)行判斷,判斷的結(jié)果可能存在長度上的差異(即對(duì)應(yīng)單位的大小),而不會(huì)產(chǎn)生對(duì)應(yīng)移位或非對(duì)應(yīng)錯(cuò)誤。
(2) 人工判斷錯(cuò)誤不可避免,因而有可能產(chǎn)生非對(duì)應(yīng)性錯(cuò)誤,但該錯(cuò)誤被重復(fù)的幾率很小。當(dāng)另一個(gè)識(shí)別者(在智能識(shí)別過程中)看到這種不得當(dāng)?shù)膶?duì)應(yīng)單位時(shí),會(huì)拒絕接受,并重新作出判斷。我們可以把識(shí)別者看成是一個(gè)社團(tuán),其互相溝通的基本平臺(tái)是動(dòng)態(tài)數(shù)據(jù)庫支持的對(duì)應(yīng)界面,以及對(duì)數(shù)據(jù)庫中對(duì)應(yīng)單位的多次重復(fù)判斷。一個(gè)對(duì)應(yīng)單位的每一次被認(rèn)可和接受,不僅增加了該單位的頻數(shù),也使得該單位的地位逐步得到確立。可接受性強(qiáng)的對(duì)應(yīng)單位總是會(huì)被接受,反之得到拒絕。群體行為的重復(fù)構(gòu)成了對(duì)應(yīng)單位的概率基礎(chǔ)。這種多人多次的判斷,實(shí)際上就是對(duì)某一單位的多重驗(yàn)證,這種驗(yàn)證不僅來自人工,還來自實(shí)際的文本,其過程可表述為:
a) 當(dāng)前文本中必須有完全匹配的序列;
b) 識(shí)別者依據(jù)自己的經(jīng)驗(yàn)和直覺認(rèn)可這種對(duì)應(yīng)。
以上二者缺一不可。
(3) 反過來說,假定一個(gè)“錯(cuò)誤”的判斷也被多次重復(fù)和接受,且有很高的復(fù)現(xiàn)率,那么需要重新評(píng)價(jià)的不是數(shù)據(jù)庫中對(duì)應(yīng)單位,而是該單位是“錯(cuò)誤”的說法本身就有問題。
(4) 關(guān)于可靠性。當(dāng)我們說什么東西是否可靠時(shí),必須有一個(gè)基本指向和參照,任何事物本身無所謂可靠與不可靠,可靠性是一種主觀認(rèn)知。也就是說,當(dāng)我們說某個(gè)數(shù)據(jù)是否可靠時(shí),實(shí)際上是參照某種理論和框架體系而言的。說直白一些,就是想拿數(shù)據(jù)做什么:當(dāng)研究者有一個(gè)具體目標(biāo)框架體系時(shí),才會(huì)產(chǎn)生所使用數(shù)據(jù)是否可靠的問題。以后的研究者可以完全拋開對(duì)應(yīng)單位這種數(shù)據(jù),直接到原文本中去爬梳;目前的對(duì)應(yīng)單位實(shí)際上只是一種經(jīng)過組織的底層數(shù)據(jù)。對(duì)應(yīng)單位的識(shí)別與標(biāo)注與任何先入為主的語言學(xué)研究無關(guān)。但如果研究者的目的是觀察雙語文本,研究翻譯事實(shí),對(duì)應(yīng)單位的提取改進(jìn)了數(shù)據(jù)呈現(xiàn)的方式,同時(shí)也提高了數(shù)據(jù)的可用性。當(dāng)然,對(duì)應(yīng)單位本身是一個(gè)操作概念,是一種處理和呈現(xiàn)數(shù)據(jù)的方法,但可以從對(duì)應(yīng)單位中生發(fā)理論或驗(yàn)證某個(gè)理論。2)進(jìn)一步限制平行文本的領(lǐng)域和文類問題。在設(shè)計(jì)平行語料庫初始階段,應(yīng)盡量避免大而全,避免虛構(gòu)性作品,盡量限定一個(gè)特定領(lǐng)域并選擇翻譯對(duì)應(yīng)較為嚴(yán)謹(jǐn)?shù)奈谋尽?)對(duì)應(yīng)單位的分類和分析。對(duì)應(yīng)單位不是一個(gè)預(yù)先設(shè)定的理論概念,所以對(duì)它的分類和分析是后延的。同時(shí),也不能在對(duì)應(yīng)單位識(shí)別過程中就建立分類框架。
在平行語料庫系統(tǒng)進(jìn)一步開發(fā)中,我們將充分利用網(wǎng)絡(luò)數(shù)據(jù)庫資源,進(jìn)行給定文本中對(duì)應(yīng)單位的識(shí)別和判斷,提高系統(tǒng)的可操作性,也為平行語料庫的應(yīng)用開發(fā)奠定基礎(chǔ)。
附注:
① Sinclair也提到,單個(gè)的詞也可能構(gòu)成意義單位,但屬于個(gè)別現(xiàn)象(Sinclairetal. 2004)。
② 一個(gè)翻譯單位在原語境中是無歧義的,但抽離以后就難說了。
③ 2007年12月與衛(wèi)乃興、濮建忠共同修訂了操作原則,并通過“上海交大國家課題研討——平行文本對(duì)應(yīng)單位識(shí)別Workshop”討論確定如下:1)基本原則。A.區(qū)分源語文本和目的語文本;B.雙語視角原則:以平行文本相互參照確定對(duì)應(yīng)單位的邊界,要求邊界清晰對(duì)應(yīng);C.預(yù)測原則:確立一個(gè)對(duì)應(yīng)單位時(shí),預(yù)測其將來的應(yīng)用性價(jià)值。2)操作原則。A.習(xí)語原則:優(yōu)先判斷源語文本中習(xí)語、成語、熟語等成套出現(xiàn)的單位;B.專指名稱原則:判斷源語言文本中的專指名稱,如人名、地名、機(jī)構(gòu)組織名稱、術(shù)語等,作為對(duì)應(yīng)單位的依據(jù);C.自由判斷原則:對(duì)一些詞語的自由組合,是否進(jìn)一步拆分,個(gè)人判斷不一。應(yīng)用自由判斷原則,即操作者根據(jù)自己的判斷,確定對(duì)應(yīng)單位的邊界,如“真正的朋友”(“real friends”)是一個(gè)單位還是兩個(gè)單位,由個(gè)人判定。D.虛詞處理原則:對(duì)一些獨(dú)立使用的虛詞,如冠詞、介詞、連詞以及代詞或含有話語指代的詞語,不進(jìn)行對(duì)應(yīng)處理。E.非連續(xù)性對(duì)應(yīng)單位的處理原則:對(duì)一些非連續(xù)性對(duì)應(yīng)單位,使用不同的標(biāo)簽標(biāo)記;軟件界面作出響應(yīng)。
④ 該系統(tǒng)的技術(shù)開發(fā)由河南師范大學(xué)語料庫應(yīng)用研發(fā)團(tuán)隊(duì)軟件工程師韓朝陽負(fù)責(zé)。
Sinclair, J. M., S. Jones & R. Daley. 2004.EnglishCollocationStudies:TheOSTIReport[M]. London/New York: Continuum.
Sinclair, J. 2005. Corpus and text—Basic principles [A]. In M. Wynne (ed.).DevelopingLinguisticCorpora:AGuidetoGoodPractice[C]. Oxford: Oxbow Books: 1-16. Available online from http:∥ahds.ac.uk/linguisitc-corpora [Accessed 2009-05-12].
Teubert. W. 2004. Translation Unit [R].新鄉(xiāng):河南師范大學(xué).
Teubert, W. 2005. My version of corpus linguistics [J].InternationalJournalofCorpusLinguistics10(1): 1-14.
馮志偉.2003.機(jī)器翻譯的現(xiàn)狀和問題[A].徐波,孫茂松、靳光瑾主編.中文信息處理若干重要問題[C].北京:科學(xué)出版社:353-377.
李文中.2010.語料庫語言學(xué)的研究視野[J].解放軍外國語學(xué)院學(xué)報(bào)(3):37-40.
李文中.2006.From translation units to corresponding units: a corpus-driven approach[R].上海交通大學(xué)慶賀楊惠中先生執(zhí)教50周年暨應(yīng)用語言學(xué)研討會(huì),上海交通大學(xué).
猜你喜歡
新少年(2022年9期)2022-09-17 07:10:54
小天使·一年級(jí)語數(shù)英綜合(2020年6期)2020-12-16 02:56:41
甘肅教育(2020年8期)2020-06-11 06:10:02
文苑(2020年12期)2020-04-13 00:54:10
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·中考版(2019年12期)2019-09-23 06:23:28
電子制作(2018年18期)2018-11-14 01:48:06
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
北極光(2014年8期)2015-03-30 02:50:51
