基于遺傳神經(jīng)網(wǎng)絡的相似重復記錄檢測方法研究*
2011-01-15 08:28:20郭樂江胡亞慧
艦船電子工程 2011年2期
關鍵詞:檢測
肖 蕾 郭樂江 胡亞慧 程 敏
(空軍雷達學院 武漢 430019)
基于遺傳神經(jīng)網(wǎng)絡的相似重復記錄檢測方法研究*
肖 蕾 郭樂江 胡亞慧 程 敏
(空軍雷達學院 武漢 430019)
設計實現(xiàn)了一個相似重復記錄檢測系統(tǒng),該系統(tǒng)包括預處理模塊、聚類模塊、字段匹配模塊和記錄匹配模塊,支持聚類算法和字段匹配算法的定制擴充。并通過實驗對比了幾種著名的算法,實驗結果表明該系統(tǒng)提高了相似重復記錄檢測的精確度。
遺傳神經(jīng)網(wǎng)絡;相似重復記錄檢測系統(tǒng);聚類算法;字段匹配算法
Class NumberTN958
1 引言
相似重復記錄清洗技術的核心是重復記錄檢測,即如何判定兩條記錄是不是重復記錄。在判定記錄是否是重復的過程中,絕大多數(shù)的重復記錄檢測算法都采用了“等值理論”,引入了相似度的概念,用記錄相似度對記錄之間的等值程度進行量化,根據(jù)相似度的大小判定記錄是否等值。所以重復記錄檢測的核心是準確的計算兩條記錄的相似度。在數(shù)據(jù)倉庫或數(shù)據(jù)庫中,記錄都是由多個字段值組成,因此,計算記錄的相似度的基礎是記錄各個字段的相似度。我們發(fā)現(xiàn)不同的字段相似度計算方法往往對特定的類型的字符特別有效,并不能對所有類型的字段值都有很好的效果,例如:Jaro-Winkler算法對拼寫錯誤類型的字段有很好的檢測效果。
基于以上分析,提出了一種基于遺傳神經(jīng)網(wǎng)絡的相似重復記錄檢測系統(tǒng)。首先,該系統(tǒng)由用戶選擇字段匹配算法計算記錄對應的字段值的相似值;其次,在字段相似度基礎上使用遺傳神經(jīng)網(wǎng)絡模型計算記錄對的相似度;最后,根據(jù)記錄的相似度值進行判定。
2 EADDS的整體結構和特點
2.1 EADDS的整體結構[1~2]
相似重復記錄檢測系統(tǒng)EADDS的工作流程圖如圖1所示。
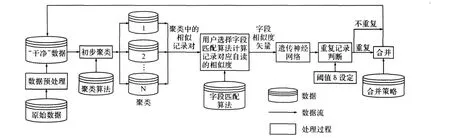
圖1 EADDS的工作流程圖
圖1描述了EADDS的工作流程圖,原始數(shù)據(jù)經(jīng)過數(shù)據(jù)準備、初步聚類、重復記錄檢測、重復記錄判定處理后,最后檢測出原始數(shù)據(jù)集中所有的重復記錄。下面分別介紹4個模塊。
1)數(shù)據(jù)準備模塊
為了保證清洗的效率和精度,在進行重復記錄清洗之前要對原始的數(shù)據(jù)進行預處理。EADDS的數(shù)據(jù)準備模塊,通過對原始數(shù)據(jù)進行解析、轉換、標準化,解決了原始數(shù)據(jù)中的各種問題,如異構數(shù)據(jù)源中屬性定義不同、字段空缺值處理、數(shù)據(jù)格式等。數(shù)據(jù)準備模塊的功能就是使數(shù)據(jù)以統(tǒng)一的格式存入到數(shù)據(jù)庫中。
2)聚類模塊
通常,在重復記錄檢測時要對數(shù)據(jù)集進行初步聚類,目的是降低檢測的時間復雜度。在EADDS中,我們集成了當前的各種聚類算法,包括鄰近排序法(SNM)[3~4],多趟排序法(MPN)[3~4],優(yōu)先權隊列算法[5]等。在進行重復記錄的檢測時,EADDS允許用戶對所有的聚類算法進行選擇,利用所選擇的聚類算法對數(shù)據(jù)集進行初步聚類。EADDS也允許用戶對聚類模塊進行擴展,即將新的聚類算法引入系統(tǒng)中,以供用戶進行選用。
3)字段相似度計算模塊
該模塊主要是計算兩條記錄對應的字段的相似度值。針對不同的字段一般只對特定類型的字段有效的特性,EADDS集成了多種有效的字段相似度計算方法,對于不同的字段允許用戶選擇相應的字段相似度計算方法,計算相應的相似度值。EADDS也允許用戶對該模塊進行擴展,即將新的字段相似度計算方法引入系統(tǒng)中,以供用戶進行選用。
4)基于遺傳神經(jīng)網(wǎng)絡的相似重復記錄檢測模塊
該模塊主要是在字段相似度值的基礎上計算兩個記錄對的相似度的值。該模塊以字段相似度矢量作為輸入,輸出為兩個記錄對的相似度值。基于遺傳神經(jīng)網(wǎng)絡的相似重復記錄檢測的模型如下:系統(tǒng)分為訓練階段和檢測階段,如圖2所示。
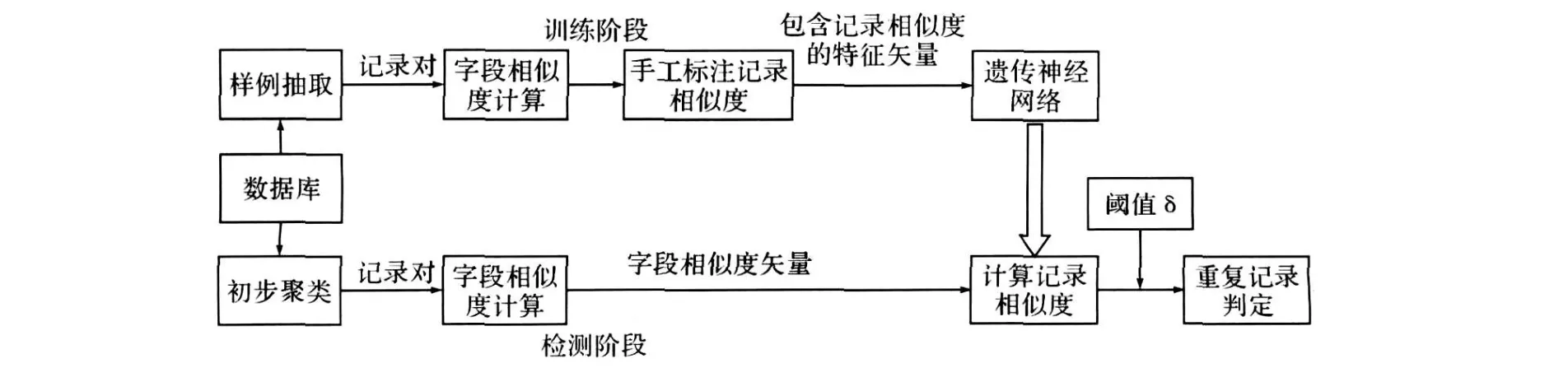
圖2 基于遺傳神經(jīng)網(wǎng)絡的檢測模型
在訓練階段,首先,從數(shù)據(jù)集中抽取若干個記錄對作為訓練樣例,在抽取的記錄對中盡可能的包含各種字符串類型的記錄對;其次,計算出兩個記錄對應字段的相似度,并手工標注記錄對的相似值;最后,將包含記錄相似度的特征矢量作為輸入,訓練神經(jīng)網(wǎng)絡。
在檢測階段,計算出記錄對對應字段的相似度,得到記錄對的相似度矢量,再利用訓練好的遺傳神經(jīng)網(wǎng)絡計算記錄的相似度;最后,選擇合適的閾值δ,確定是否是重復記錄。
2.2 EADDS的特點
1)可擴展性
EADDS允許對數(shù)據(jù)數(shù)據(jù)準備模塊、聚類模塊、字段相似度計算模塊進行擴展,使各種新技術可以應用到系統(tǒng)框架中,從而可以提高各個模塊的性能,最終提高重復記錄檢測的整體性能。
2)可交互性
EADDS通過各個模塊與用戶進行交互。在運行過程中,要求用戶對聚類算法、字段相似度計算方法、閾值的選取進行選擇,并通過日志存儲處理過的歷史記錄,用戶可根據(jù)日志對各個模塊中運行的算法以及閾值進行調(diào)整。
3)組件模塊的可重用性
EADDS的各個模塊各自完成特定任務,相互獨立,因此相互之間耦合度較低,可以實現(xiàn)重用。基于該系統(tǒng)框架可以開發(fā)出不同領域的重復記錄檢測系統(tǒng)。
3 評價標準
在重復記錄清洗領域,研究人員一般采用召回率(Recall)和精確率(Precision)作為相似重復記錄檢測的評價標準。
召回率,也稱為命中率,定義為正確檢測出的重復記錄數(shù)(True Positives)與所有的重復記錄(Real Duplicates)的比值,如式(1)所示:
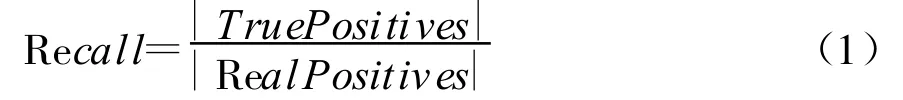
準確率是指正確檢測出的重復記錄數(shù)(True Positives)占所有檢測出的重復記錄(Detected Duplicates)中所占百分比,如式(2)所示:
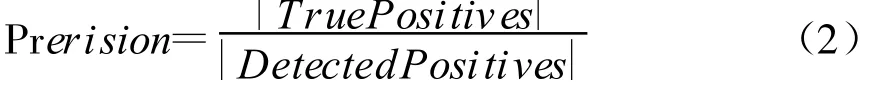
性能好的檢測方法應具有較高的召回率和準確率。由定義分析可知,召回率和準確率與閾值δ有關,當δ值增加時,在檢測出的重復記錄中應該含有更多的檢測正確的重復記錄,即準確率提高了,但是由于檢測正確的重復記錄數(shù)少了,所以召回率降低了;反之,當δ值減小時,準確率降低,召回率提高。
為了更加直觀的對清洗算法進行評價,在召回率和準確率的基礎上又定義了一個新的評價標準—最大F1值。F1的定義如式(3)所示:

其中,R表示召回率,P表示準確率。
F1值是召回率和準確率的函數(shù),平均值反應了檢測方法的性能。F1值越大,檢測算法性能越好。
4 仿真對比實驗
為了驗證本文提出方法的性能,將實驗結果與TF-IDF與Marlin兩種著名的相似重復記錄檢測方法進行了比較。TF-IDF方法首先將記錄所有的字段值連接為一個字符串,然后利用TF-IDF方法計算字符串的相似度,進而進行重復記錄的判定;Marlin是一種基于編輯距離的方法,提出了一種可學習的帶放射間隔的字符串編輯距離,具有良好的整體性能。
采用的實驗數(shù)據(jù)是由Febrl[5]系統(tǒng)中的數(shù)據(jù)生成程序生成的數(shù)據(jù)。測試數(shù)據(jù)生成器生成的數(shù)據(jù)包括姓名(surname,given name),地址(address,suburb,street number),出生日期(date or birth),電話號碼(phone number),郵政編碼(postcode),社會保險號(social security number)和年齡(age)等字段,其中原始數(shù)據(jù)信息來源于美國的電話手冊中。實驗數(shù)據(jù)集中共有7200條記錄,其中包含650條相互重復的記錄。
EADDS中,選擇優(yōu)先隊列作為初步聚類算法,字段匹配算法的選則為,字段 given_name、surname采用 Jaro,字段 street_number采用Levenshtein,字段 address_1、suburb采用 TF-IDF,字段date_of_birth、soc_sec_id采用Smith-Waterman。EADDS的實際測試輸出如圖3所示。
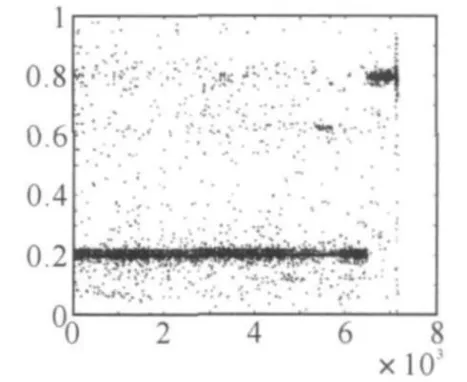
圖3 EADDS測試輸出
從測試輸出圖上可以看出,大部分輸出比較接近0.2和0.8。若我們把閾值定為0.5,即相似度小于0.5的為非重復記錄,相似度大于0.5的為重復記錄。在7200條測試記錄中,EADDS檢測出有672條重復記錄,在檢測出的重復記錄中,有631條記錄為真正的重復,錯誤檢測為重復記錄的記錄為41條,所以,精確率為0.93,召回率為0.97。
在實驗數(shù)據(jù)集上分別對 TF-IDF和Marlin進行實驗。首先確定精確率的值,然后再確定三種方法相應的召回率,如圖4所示。
從實驗結果圖上可以看出,對于不同的準確率值,EADDS的召回率值要比其他兩種方法高,這說明在進行相似重復記錄檢測時,在用戶指定的精確度的情況下,EADDS比其他的方法能夠更多的檢測出數(shù)據(jù)集中的相似重復記錄。同樣,對于不同的召回率值,EADDS的準確率值也比其他兩種方法高,這也說明檢測時,在用戶指定的召回率的情況下,EADDS比其他的方法能夠更加精確的檢測出重復記錄。

圖4 測試結果圖
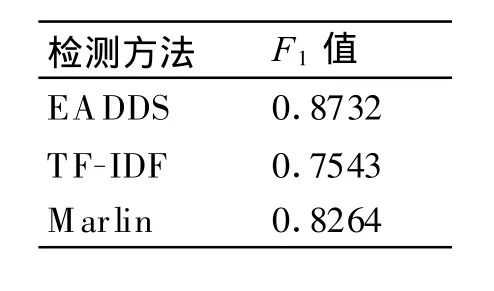
表1 相似重復記錄檢測的最大 F1值
表1顯示了在數(shù)據(jù)集上進行實驗所得到最大的F1值的平均值。因為F1的值表示了一種檢測算法的整體性能,因此從表中可以看出,EADDS比TF-IDF和Marlin具有更高的整體性能,具有良好的檢測效果。
5 結語
設計并實現(xiàn)了一個基于遺傳神經(jīng)網(wǎng)絡的相似重復記錄檢測系統(tǒng)EADDS。該系統(tǒng)是一個可擴展的檢測系統(tǒng),支持聚類算法和字段匹配算法的定制擴充,具有較好的通用性。實驗對比了EADDS與現(xiàn)有相似重復記錄檢測方法的性能,證明了EADDS的有效性。
[1]Hernandez M,Stolfo S.The merge/purge problem for large databases[J].ACM SIGMOD Record,1995,24(2):127~138
[2]Monge A,Elkan C.An efficient domain-independent algorithm for detecting approximately duplicate database records[C]//Proceedings of the ACM-SIGMOD Workshop on Research Issues on Knowledge Discorvery and Data Mining,Tucson,AZ,1997
[3]Hernandez M A,Stolfo S J.Real-world data is dirty:data cleansing and the merge/purge problem[J].Data Mining and Knowledge Discovery,1998,2(1):9~37
[4]周芝芬.基于數(shù)據(jù)倉庫的數(shù)據(jù)清洗方法研究[D].上海:東華大學碩士學位論文,2004
[5]A.Monge,C.Elkan.An effieient domain independent algorithm for detecting approximately duplicate database reeords[J]//proeeedings of the SIGMOD workshop on Data Mining and Knowledge Diseovery,Tueson,Arizona,1997:211~217
Study on Approximately Duplicate Record Detection Method Based on Genetic Neural Network
Xiao Lei Guo Lejiang Hu Yahui Cheng Min
(Air Force Radar Academy,Wuhan 430019)
An extensible duplicates detecting system is designed and implemented.This system includes data preparation module,clustering module,field matching module and record matching module.The working principle and implementation mechanism in process of the four modules are given respectively in this dissertation.In our experiments,we compare the performance of our method with some famous approximately duplicate records detecting algorithms.The experiment results show that the system improved the precision.
genetic neural network,approximately duplicates detecting system,clustering algorithm,field matching algorithm
TN958
2010年8月10日,
2010年9月17日
肖蕾,女,助理實驗師,研究方向:計算機網(wǎng)絡。郭樂江,男,博士,講師,研究方向:計算機網(wǎng)絡。胡亞慧,女,碩士,講師,研究方向:計算機結構。程敏,女,助教,研究方向:計算機網(wǎng)絡。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2019年9期)2019-11-25 07:34:36
中學生數(shù)理化·七年級數(shù)學人教版(2019年9期)2019-11-25 07:34:34
中學生數(shù)理化·七年級數(shù)學人教版(2019年12期)2019-05-21 02:53:50
中學生數(shù)理化·七年級數(shù)學人教版(2019年12期)2019-05-21 02:53:48
