復雜網絡社區挖掘——改進的層次聚類算法
2011-02-28 05:10:38鄭浩原
網絡安全與數據管理 2011年16期
關鍵詞:方法
鄭浩原,黃 戰
(暨南大學 信息科學技術學院 計算機科學系,廣東 廣州 510632)
復雜網絡表示現實世界中具有網絡結構特性的諸多系統,它通常具有顯著的社區結構,同質頂點聚集在同一社區,異質頂點分布于不同社區,表現為社區內部頂點之間連接邊稠密,社區之間連接邊數量相對稀疏[1]。社區挖掘是復雜網絡分析領域的熱點問題,可以將現有的社區挖掘算法歸納為三大類[2]:基于優化的算法、啟發式算法以及其他算法。基于相似度的層次聚類算法[3]屬于其他算法,這類算法不需要任何先驗知識就可以有效地發現復雜網絡中的社區結構。當前的層次聚類算法的主要缺點是需要計算所有頂點對之間的相似度,時間復雜度為O(n2),n表示圖中頂點數量,不適用于大規模網絡分析。針對這一缺點,受到社交網絡分析相關方法的啟發,本文提出一種改進的層次聚類算法。
社交網絡分析[4]是復雜網絡分析的一個分支,社交網絡中有一類Ego Networks,表現為有一個中心結點(即ego),圖中所有其他結點(稱為alters)與中心結點直接連接,alter之間也有邊相連。社會學理論[5]指出,關系緊密的角色之間相似度偏高,如果兩個角色之間共同點越多,則這兩者就越有可能是朋友或者具有緊密的聯系。當與某確定角色比較,角色A與角色B的相似度值接近時,可以認為角色A與B具有某種同質性。基于這一理論,對層次聚類算法進行改進,在探測出網絡中扮演ego角色頂點的前提下,計算其他頂點與ego的相似度,而不是計算所有頂點對之間的相似度,此種情況下,算法時間復雜度為O(n),計算負荷與網絡規模呈線性相關。實驗結果表明,該算法可能在準確性上稍有不足,但是能有效降低網絡分析規模、計算復雜度和大致發現網絡中的社區結構。
1 算法準備
1.1 相似度計算
相似度[3-4]是對圖中頂點之間的相似或者相異程度的度量,是層次聚類算法的核心概念,可以大致將現有的相似度計算方法分為三大類:
第一類,可以將頂點嵌入到n維歐式空間中,通過給頂點分配合理的n維坐標,將網絡聚類問題轉化為空間點聚類問題。給定兩個頂點,A=(a1,a2,…,an)和 B=(b1,b2,…,bn),則可以利用各種距離度量方法計算兩者的距離。例如,歐幾里得距離:
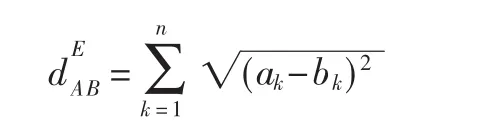
第二類,如果頂點不能嵌入到歐式空間中,這種情形下,還可以根據圖中頂點之間的鄰接關系計算相似度。一種方法將頂點間距離定義為:
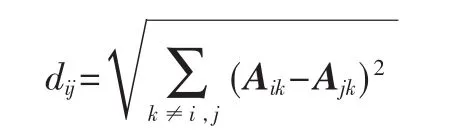
A表示圖的鄰接矩陣。這是一種基于結構同等概念的度量頂點相異度的方法。結構同等指兩個頂點之間有相同的鄰接頂點,若 i和 j結構同等,則 dij=0;頂點度高且存在較多不同鄰接頂點的頂點之間,相異度高。
根據圖的鄰接矩陣,可以利用行或列向量表示頂點之間的海明距離度量頂點間的匹配程度,也是相似度度量方法之一。例如,有如下鄰接矩陣A:

頂點 A=(0,1,1,1)、B=(1,0,0,1),則兩者之間的海明距離是3,表示了兩者對應位置不同位的個數。其他度量頂點間匹配程度的方法還包括計算頂點間的杰卡德系數等。
第三類,根據圖本身的構造和屬性特征設計的一些方法。例如,一種度量相似度的方法是利用兩個頂點間獨立于邊(或頂點)的路徑的數量。獨立路徑之間不共有任何邊(或頂點)。根據最大流/最小截理論,每條邊只能承載一個流單元,則獨立路徑數量等于兩個頂點間能夠傳遞的最大流。據此設計的算法(如增廣路徑算法)能夠在O(m)時間復雜度下計算最大流,m表示圖中邊的數量。
1.2 Ego角色的探測
復雜網絡分析中,中心度[6]是頂點在圖中重要性的度量,“重要”的具體含義要視具體情況而定,例如社交網絡中的中心人物角色。本文引入EgoNetworks中的概念,將重要頂點命名為ego。目前有四種中心度度量方法被廣泛使用。
(1)Degree Centrality,頂點的度指圖中與頂點相關聯的邊的數量(本文只討論無向圖)。用數學形式表示為,圖 G的鄰接矩陣 A,若 Aij=1,則存在連接 i和 j的邊;若Aij=0,則 i和 j無連接。 頂點數為 n時,頂點 i的度 ki:
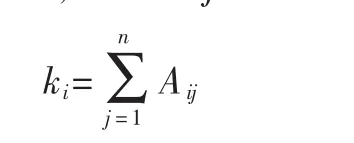
雖然形式簡單,頂點的度經常能有效地衡量頂點的重要性或影響力:在社交網絡中,擁有更多連接邊的角色往往更具影響力。
(2)Eigenvector Centrality,這種中心度量方法的基本思想是:給圖中所有頂點賦予相應的分值。賦分原則是:考慮某一頂點v,v的所有連接邊中,來自高分頂點的連接較來自低分頂點的連接給貢獻更多的分值。谷歌的PageRank算法即是這種度量方法的一個變種。
利用圖的鄰接矩陣計算Eigenvector Centrality:xi表示第i個頂點的分值,則xi與i的所有鄰接頂點的分值的和成正比:
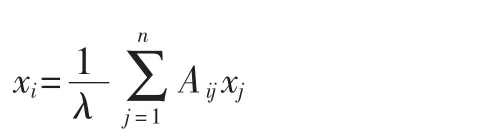
上式中λ是常量。定義中心度的向量形式x=(x1,x2,…),可以重寫上式為:

可見,x是鄰接矩陣A的特征向量,對應的特征值是λ。一個特征向量往往對應多個特征值,假設中心度值非負,根據Perron-Frobenius定量,λ則取所有特征值中最大的值,對應的特征向量為x。
(3)Betweenness Centrality,圖中那些位于更多的頂點對之間最短路徑上的頂點擁有更高的介度。頂點v的介度CB(v):
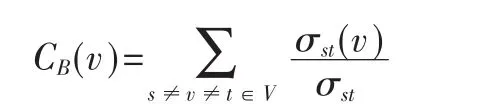
σst表示 s與 t之間最短路徑的總數,σst(v)則是這些最短路徑中經過頂點v的最短路徑數量。
(4)Closeness Centrality,定義為頂點v與圖中所有其他可達頂點之間的最短路徑的均值,表示為:
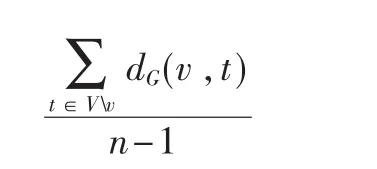
其中n≥2表示由v起始可以到達的網絡中的連接組件V的大小。親近度可以衡量圖中信息由給定的頂點傳播到其他可達頂點所需時間的長短。
1.3 模塊性標準
模塊性標準[7]由Newman等人引進,用以衡量算法發現的社區結構質量。復雜網絡G=(V,E),其中,V為頂點集合,E為邊集合,G包含了n個頂點,k個社區,定義模塊性:
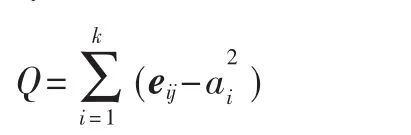
式中,e是一個k×k維的對稱矩陣,eij表示連接社區 i中角色(即頂點)和社區j中角色的邊的數量在邊總數中所占比例,表示與第i個社區中角色連接的邊在邊總數中所占比例。Q值介于0~1之間,Q值越接近1,說明發現的社區結構質量越高。實際網絡中,Q值一般在0.3~0.7之間。
2 改進的層次聚類算法
用于表示現實網絡系統的復雜網絡通常具有的層次結構特征,即較大的社區結構包含較小的社區結構。層次聚類算法能有效地發現這種層次結構,被廣泛應用于社交網絡分析、生物工程、市場分析等領域。層次聚類算法可以分為兩大類:
(1)凝聚方法:采用自底向上的策略,首先將每個對象作為簇(cluster),然后合并這些原子簇成為更大的簇,直到所有對象都在一個簇中,或者滿足某終止條件。
(2)分裂方法:采用自頂向下的策略,首先將所有對象置于一個簇中,然后逐步細分為越來越小的簇,直到每個對象各為一簇,或滿足某終止條件,例如達到了希望的簇數或每個簇的直徑都在某個閾值內。
由于分裂方法很少使用,本文討論的算法采用自底向上的策略。通常可以用樹狀圖(dendrogram)表示層次聚類的過程,如圖1所示。
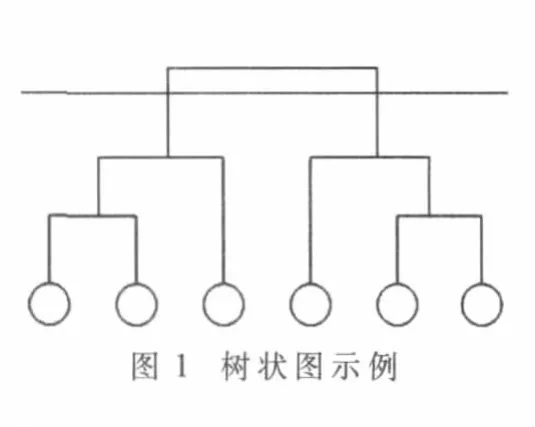
層次聚類算法將網絡劃分為幾個社區取決于在什么位置分割樹狀圖,如圖1中橫線位置將產生兩個社區結構。實際網絡中通常依據模塊性標準來確定最佳的劃分位置。
傳統層次聚類算法在確定相似度計算方法后,計算所有頂點對之間的相似度。本文在傳統方法的基礎上,引入ego角色探測過程,根據復雜網絡具體特征,首先確定相似度計算方法,然后確定ego角色的探測方法,一旦扮演ego角色的頂點被確定,則只計算圖中所有其他頂點與ego頂點之間的相似度,這種情況下,時間復雜度取決于ego探測過程,例如,選定Degree Centrality作為ego探測策略,總的時間復雜度可表示為O(n)。可見,在大規模網絡分析中,改進的層次聚類算法具有較大優勢。算法步驟如下。


該算法可以有兩種應用用途:在較理想的情形下,例如復雜網絡表示的是現實的EgoNetworks,則算法能有效挖掘網絡中的社區結構;對于準確度要求很高以及復雜網絡規模巨大、特征不明確的情形,本文算法可作為網絡預處理過程,用于降低網絡分析規模,此時算法只產生規模合適的粗糙的社區,再運用其他準確度較高的算法,劃分出更精確的社區。
3 實驗分析
3.1 EgoNetworks中的算法應用
該EgoNetworks數據采集自社交網站人人網,包含了一個Ego角色和49個alter角色。圖中頂點代表一個個體,邊表示個體之間的好友關系。由調查得知,該網絡包含三個同學群體,一個陌生人群體,一個親密好友群體。運用改進的層次聚類算法,成功地挖掘出了網絡中包含的五個社區,算法采用的相似度計算方法是頂點間海明距離,ego角色在初始狀態是已知的,第一次迭代后利用Degree Centrality探測新的ego角色。圖2描述了模塊度Q值隨社區個數變化的分布圖,x軸表示社區數量,y軸表示對應的Q值。
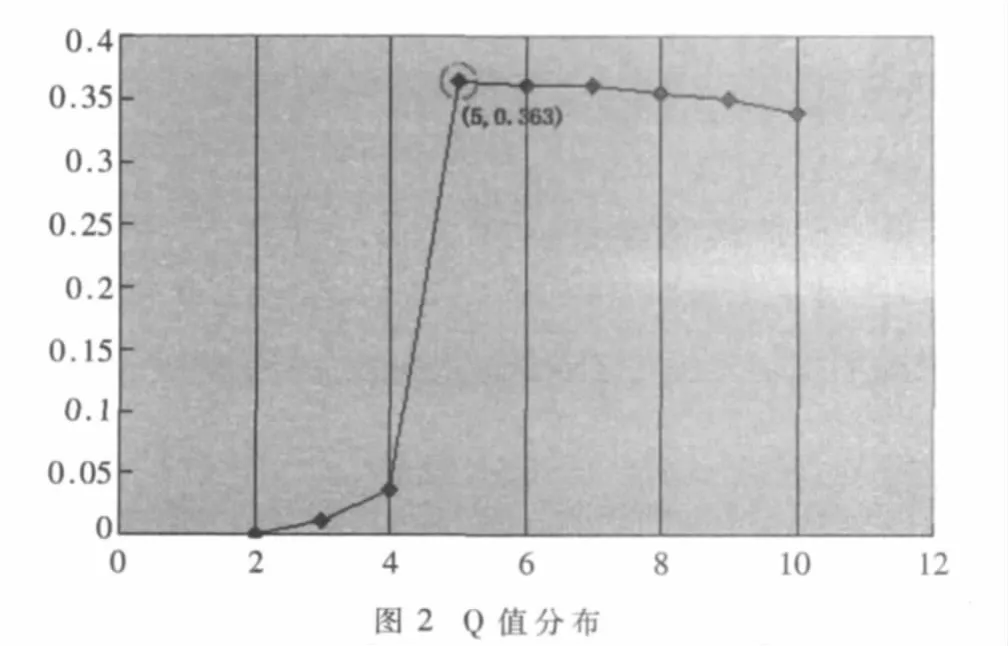
由圖2可見,當Q值取最大0.363時,對應的社區個數為5,此時劃分質量最高,網絡中社區結構圖如圖3所示。
3.2 “Zachary空手道俱樂部網絡”中的算法應用
Zachary空手道俱樂部網絡[8]是測試社區挖掘算法的經典網絡,該網絡描述了美國一所大學空手道俱樂部的34名成員之間的關系,其中包含了兩個已知的社區結構。圖4的劃分結果來自Girvan-Newman算法,不同社區用不同顏色頂點區分。

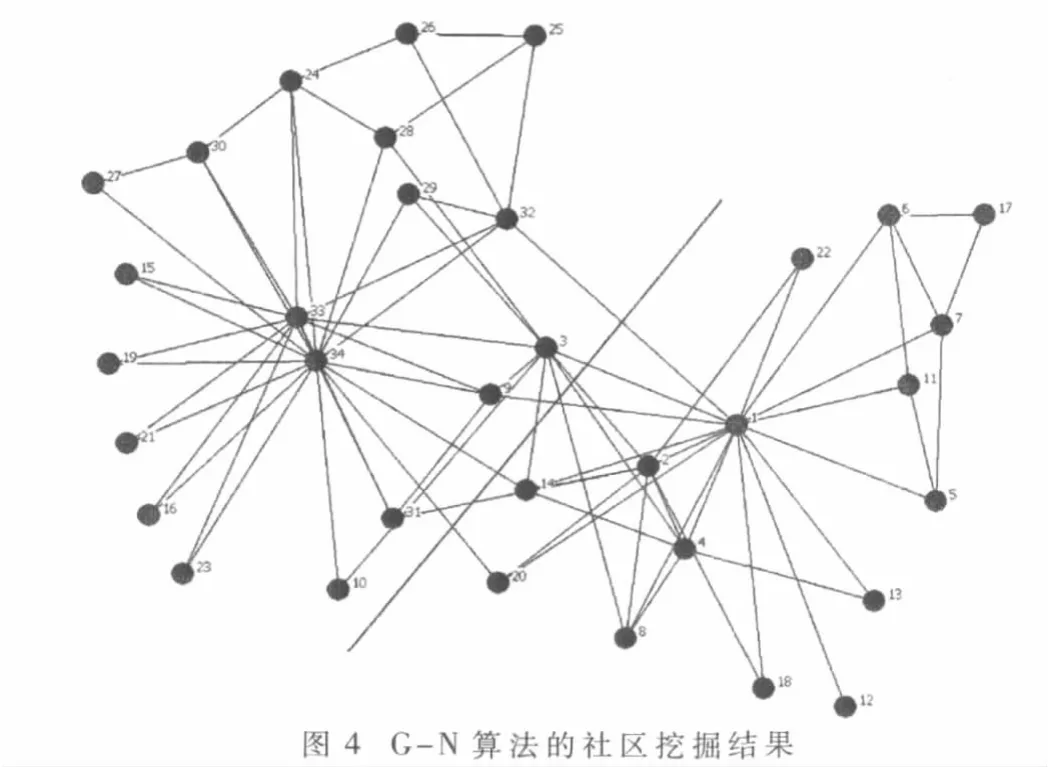
本文算法在選定Degree Centrality和海明距離分別作為ego角色探測和相似度計算策略后,劃分結果如表1所示。
表1中,除了10,12,32,28四個頂點劃分有誤,其他都正確。在這種非EgoNetworks中,根據網絡特征選取恰當的相似度計算和ego角色探測方法很重要,實驗中選擇了較簡單的方法,雖然在準確性上有不足,但是時間復雜度只有 O(n),較傳統方法的 O(n2),在大規模網絡中,改進的層次聚類算法優勢明顯。

表1 改進的層次類聚算法的挖掘結果
社區挖掘是復雜網絡分析的重要手段之一。本文總結了復雜網絡中常用的頂點間相似度計算方法和頂點重要性度量方法,在此基礎上,對傳統的層次聚類算法進行改進,引入網絡中“ego”角色的探測過程,并在現實的EgoNetworks以及經典實際網絡中驗證了算法的有效性。雖然改進的層次聚類算法能很好地提高社區挖掘效率,但是在準確性上仍有不足之處。如何提高算法準確度以及如何根據具體的網絡特征,制定合適的相似度計算和“ego”角色探測方法是以后研究的主要工作。
[1]GIRVAN M,NEWMAN M E J.Community structure in social and biological networks[C].Proc.Natl.Acad.Sci.USA 99,2002:7821-7826.
[2]Yang Bo,Liu Dayou,Liu Jiming,et al.Complex network clustering algorithms[J].Journal of Software,2009,20(1):54-66.
[3]FORTUNATO S.Community detection in graphs[C].arXiv:0906.0612,2010.
[4]HANNEMAN R A,RIDDLE M.Introduction to social network methods[M/OL].Riverside,CA:Universityof California,Riverside,2005.http://faculty.ucr.edu/~hanneman/.
[5]ADAMIC L A,ADAR E.Friends and neighbors on the web[J].Social Networks,2007,25(2):211-230.
[6]NEWMAN M E J.Mathematics of networks[M].In The New Palgrave Encyclopedia of Economics,2nd edition.Palgrave Macmillan,Basingstoke,2007.
[7]NEWMAN M E J,GIRVAN M.Finding and evaluating community structure in networks[J].Physical Review E,69,2004.
[8]ZACHARY W W.An information flow model for conflict and fission in small groups[J].Journal of Anthropological Research,1977,33(2):452-473.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
