基于時頻分布的漢語語音關鍵頻率分布研究
2011-03-14 05:12:48王鐘斐王彪
電子設計工程 2011年10期
關鍵詞:信號
王鐘斐,王彪
(寶雞文理學院數學系,陜西寶雞721013)
語音識別(speech recognition)是機器通過識別和理解過程把人類的語音信號轉變為相應的文本或命令的技術。其根本目的是研究出一種具有聽覺功能的機器,這種機器能直接接受人的語音,理解人的意圖,并做出相應的反映[1]。
目前,語音識別技術已成為世界上最熱門的技術之一,它以語音為研究對象。因此,掌握語音的關鍵信息將有助于提高語音識別效果,而本文就是通過時間-頻率聯合分布來研究漢語語音關鍵頻率分布的情況。
1 漢語語音簡介
語音是指人類通過發音器官發出來并且具有一定意義的聲音,其目的是進行社會交際。漢語語音[2]的特點是音節結構簡單,音節界限分明,聲調是音節的重要組成成分。音素是按照音質的不同劃分出的最小的語音單位。
音節是語音結構的基本單位,是說話時自然發出、聽話時自然感到的最小的語音片斷。一般來說,漢語中用一個漢字來代表一個音節。只有兒化韻兩個漢字只記錄一個音節。音節可以構成詞,詞可以構成句子。漢語的音節結構有很強的規律性。中國傳統把一個音節分為聲母、韻母和聲調3部分。聲母是指處在音節開頭的輔音。音節的開頭如果沒有聲母,就是零聲母音節。韻母是指音節中聲母后面的成分,可以只是一個元音,也可以是元音的組合或元音和輔音的組合。漢語各方言雖然語音分歧相當大,但聲母、韻母和聲調的基本結構是一致的。
研究漢語語音關鍵頻率分布,要首先研究聲母和韻母的頻率分布,因為二者結合起來就是漢語語音,了解了聲母和韻母的頻率分布,就必然能夠大體確定漢語語音關鍵頻率分布。因此,下面主要以聲母和韻母為例來研究。
2 語音信號時頻分析
語音信號時域分析和頻域分析都有一定的局限性:前者對語音信號的頻率特性沒有直觀的了解;而后者提供的信息中又沒有語音信號隨時間的變化關系,即無法標定信號發生的時間位置和發生變化的劇烈程度。因此要想比較準確的分析語音信號,單獨依靠時域分析或者是頻域分析,是不能完成的。要從時域、頻域兩方面同時入手,對語音信號進行分析,得到代表其本質的特征參數,才能達到辨析語音的要求。
而時頻分析方法就提供了時間域與頻率域的聯合分布信息,清楚地描述了信號頻率隨時間變化的關系。其基本思想是:設計時間和頻率的聯合函數,用它同時描述語音信號在不同時間和頻率的能量密度或強度。時間和頻率的這種聯合函數簡稱為時頻分布。利用時頻分布來分析信號,能給出各個時刻的瞬時頻率及其幅值,并且能夠進行時頻濾波和時變信號研究。也就是,借助于時間和頻率的聯合表示,能夠準確地描述非平穩信號的特性,從而能夠對其進行分析[3]。
2.1 時頻表示
對于非平穩信號,為了得到信號的頻率隨時間變化的情況,需要使用時間和頻率的聯合函數來表示信號,這種表示稱為信號的時頻表示。其目的是將一維時間信號x(n)或頻域信號X(ejω)映射成時間-頻率平面上的二維信號Px(n,ω)。那么,信號的瞬時能量和功率譜可以分別表示為

和

信號在時頻域n∈[n1,n2]和ω∈[ω1,ω2]的能量成分表示為:

可以根據函數Px(n,ω)計算在某一特定時間內的頻率密度,計算該分布的整體和局部的各階陣等。
目前,有很多種時頻表示方法,主要有線性時頻表示、二次時頻表示(又稱雙線性時頻表示)。線性時頻表示主要有短時傅里葉變換、Gabor變換及小波變換。二次時頻表示是由能量譜或功率譜演化而來,特點是變換為二次的。在某些實用場合,要用雙線性時頻表示來描述描述語言信號的能量密度分布,這種更嚴格意義下的時頻表示就稱為信號的時頻分布。
2.2 時頻分布
能量譜或功率譜具有雙線性變換特點,也就是說當信號之間滿足下式時

能量譜函數有如下的雙線性關系:

式中,ε(ejω)、ε1(ejω)與ε2(ejω)分別為x(n)、x1(n)和x2(n)的能量譜,而*號表示對信號的頻譜取共軛操作。此時,當x1(n)和x2(n)的頻譜隨時間變化時,根據能量譜或功率譜得到的時頻表示Px1(n,ω)和Px2(n,ω)是二次的,則有
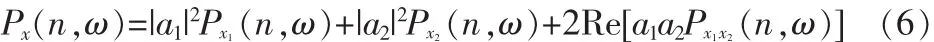
其中,Px(n,ω)是x(n)的時頻表示。上式右邊的最后一項稱為交叉項或互項,而Px1x2(n,ω)稱為x1(n)和x2(n)的互時頻表示。
此外,其他一些二次型能量化的時頻表示可統一的由Cohen L提出的廣義雙線性時頻表示,即
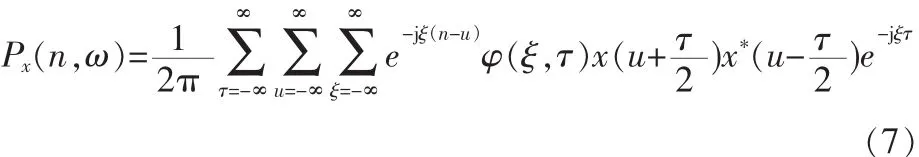
其中,φ(ξ,τ)表示核函數,它決定Px(n,ω)的特性。
采用不同的核函數,會得到不同的時頻分布。而對核函數要求是:一能壓縮交叉干擾項,二能有好的特性。
2.3 語譜圖
語譜圖是語音信號短時頻譜的時間-強度表示[4]。語譜圖是語音信號時頻分布的一個比較好的應用。其橫坐標表示時間,縱坐標表示頻率,每個像素的灰度值大小及顏色的濃淡反映相應時刻和相應頻率的能量。能量功率譜具體表示為
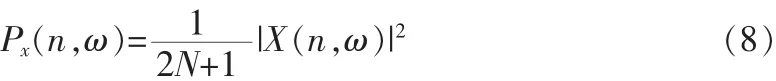
其中,
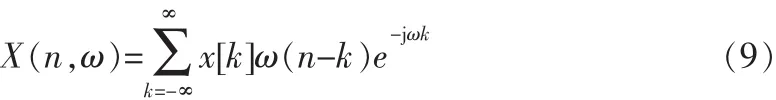
ω[n]是一個長度為2N+1的窗函數,X(n,ω)表示在時域以n點為中心的一幀信號的傅里葉變換在ω處的大小。
下面圖1給出了語音“開始”的語譜圖。圖中橫軸表示時間,縱軸表示頻率,顏色的深淺表示(n,ω)處的能量大小,一般用能量的對數表示,即lg(Px(n,ω))。語譜圖根據帶通濾波器的帶寬分為寬帶語譜圖和窄帶語譜圖。通過語譜圖很容易看出語音信號關鍵頻率的分布情況和能量的分布情況。圖1(a)和(b)分別是“開始”的寬帶語譜圖和窄帶語譜圖。
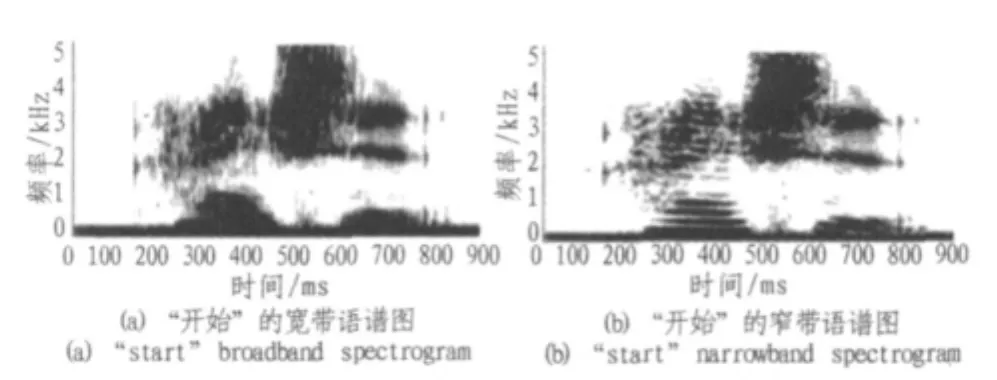
圖1 語音“開始”的寬帶語譜圖和窄帶語譜圖Fig.1Speech“start”broadband spectrogram and narrowband spectrogram
由于寬帶語譜圖的頻率分辨率較高,時間分辨率較低,因而語譜圖呈現的是垂直的條紋;而窄帶語譜圖則相反,從而呈現的是橫向的條紋。從上圖中可以看出,條紋較明顯的分成兩個部分,其中第一部分是漢字“開”的圖譜,第二部分是漢字“始”的圖譜。
3 語音采集及分析處理
3.1 語音信號采集
本文中所用的語音信號示例分為兩類:一是電視臺、廣播臺播音員的標準普通話語音錄音,二是現實生活中普通人的普通話錄音。這樣,語音示例既具有標準語音有具有普通語音,能夠比較全面的反映人類語音的大致情況,從而使下面得出的結論具有一定的代表性。
1)電視臺、廣播臺播音員的標準普通話語音錄音可以在網絡上下載,本文下載了播音員用普通話朗讀漢語拼音聲明、韻母的語音錄音,這樣就得到了較為標準的語音信號范本。
2)現實生活中的普通人用普通話朗讀漢語拼音聲明、韻母,然后通過電腦麥克風進行錄音,并保存為.wav的文件格式,音頻的位速為352 Kb/s,采樣大小為16位,級別為22 kHz,為單聲道錄音。而這就是普通人的語音信號范本。
上面的兩類語音信號范本作為后面的分析處理對象。其中,聲母共23個,即:b、p、m、f、d、t、n、l、g、k、h、j、q、x、zh、ch、sh、r、z、c、s、y、w;韻母共24個,即:a、o、e、i、u、v、ai、ei、ui、ao、ou、iu、ie、ve、er、an、en、in、un、vn、ang、eng、ing、ong。
3.2 語音信號分析處理
在前面介紹了時頻分布的特點和優勢,下面就利用時頻分布來處理上一小節中的語音信號范本。在此,本文采用了兩類方式進行處理:一是使用語音處理軟件Adobe Audition 3.0來播放語音文件,得到其頻率-能量-時域圖(即語譜圖),從圖中觀察總結其頻率分布等重要信息;二是使用自己設計的MATLAB程序來播放語音文件,得到其語譜圖,從而觀察總結其頻率分布等重要信息。兩種方式相互驗證比較,將使結論變得更全面、更具有說服性。
3.2.1 Adobe Audition 3.0軟件處理語音文件
將用Adobe Audition3.0軟件分別播放前面的語音信號文件,得到其語譜圖,并從中觀察總結出其關鍵信息。但由于聲母、韻母較多,在此不一一列舉,分別以韻母a、聲母b為例。
1)韻母
下面圖2是韻母a的語譜圖,分別是標準普通話、普通男聲和普通女聲的圖譜。
圖2中,橫軸表示時間,單位是ms,縱軸表示頻率,單位是Hz。圖中的帶顏色區域表示語音信號在對應時刻所攜帶的能量,顏色愈亮,表示能量愈大;反之,顏色愈暗,則表示此時刻能量愈小。圖中開始和結束的地方顏色發暗發黑,表示語音信號未發音及已發音結束,不攜帶能量,所以顏色發暗發黑。由于韻母a的發音平緩且變化不大,所以圖中反映的能量也呈不變趨勢,是一道較平滑的語音帶。從圖2(a)中可以看出,語音a的能量主要集中于0~4 000 Hz頻率范圍之間,在4 000~7 000 Hz的頻率范圍內能量分布較少,而當頻率高于7 000 Hz時,幾乎沒有能量。而在0~4 000 Hz頻率范圍內,能量分布具有如下的特點:幾乎語音一半的能量集中于0~1 600 Hz頻率范圍內,頻率在2 800 Hz及3 800 Hz處又具有較大的能量,其余地方能量相對較小。從圖2(b)中可以看出,語音a的能量主要分布在兩個頻率范圍內,其中第一個頻率范圍是0~1400Hz,第二個頻率范圍是3000~5000Hz,且從圖中顏色明亮度可以看出語音a的大約70%的能量集中于第一個頻率范圍內,即0~1 400 Hz之間。從圖2(c)中可以看出,語音a的能量主要分布在0~1 800 Hz頻率范圍內,其余頻率段內能量可以忽略不計。因此,可以得出結論:韻母a的能量集中分布于0~4 000 Hz頻率范圍之間,而這也就是其關鍵頻率范圍,而這個結論將為其后續處理提高一定的理論依據。
2)聲母
下面圖3是聲母b的語譜圖,分別是標準普通話、普通男聲和普通女聲的圖譜。
圖3(a)中可以看出:語音b的能量主要分布在兩個頻率范圍內,大約70%的能量分布在0~1 200 Hz頻率范圍內,其余的能量分布在2 200~4 000 Hz之間。而圖3(b)的情況與圖(a)類似,語音b的能量大致分布在兩個頻率范圍內,其中大約80%的能量分布在0~1 200 Hz頻率范圍內,其余能量大致分布在2 800~4 000 Hz之間,另外在頻率5 000 Hz以上的地方也有一定的能量,可以忽略不計。從圖3(c)可以看出,語音能量絕大部分分布在0~1 200 Hz頻率段內,其余能量可以忽略不計。因此,可以得出結論:聲母b的能量大致分布在0~4 000 Hz頻率段內,但主要分布在0~1 200 Hz之間,這也是其關鍵頻率所在頻率段,是后續研究的重點區域。

圖2 韻母a的語譜圖Fig.2Vowels a spectrogram

圖3 聲母b的語譜圖Fig.3Initials b spectrogram
3.2.2 自制MATLAB程序來處理語音文件
本文應用自制MATLAB軟件處理語音信號,通過調用MATLAB程序來得到語音文件的三維立體語譜圖,從中分析總結出其攜帶的關鍵信息。與上一小節類似,分別以韻母a、聲母b為例。
1)韻母
下面圖4是韻母a的語譜圖,分別是標準普通話、普通男聲和普通女聲的圖譜。
上圖中的語音信號語譜圖是表示時頻聯合分布的三維圖,它的橫坐標是時間,單位是ms,縱坐標是頻率,單位是Hz,豎坐標是幅度,表示語音的數據能量,單位是db(分貝)。能量值的大小是通過顏色深淺來表示的,顏色深,表示該點的語音能量越強;反之,顏色淺,則表示語音能量越小。從圖4(a)中可以看出,語音a的能量主要集中于0~4 000 Hz頻率范圍之間,在4 000~9 000 Hz的頻率范圍內能量分布較少,而當頻率高于9 000 Hz時,幾乎沒有能量。而在0~4 000 Hz頻率范圍內,能量分布具有如下的特點:幾乎語音70%的能量集中于600~1 600 Hz頻率范圍內,頻率在3 500 Hz及4 000 Hz處又具有大約20%的能量,其余地方能量相對較小。從圖4(b)中可以看出,語音a的能量主要分布在兩個頻率范圍內,其中第一個頻率范圍是0~2 000 Hz,第二個頻率范圍是2 500~4 500 Hz,且從圖中顏色明亮度可以看出語音a的大約80%的能量集中于第一個頻率范圍內,即0~2 000 Hz之間。從圖4(c)中可以看出,語音a的能量主要分布在0~2 000 Hz頻率范圍內,其余頻率段內能量可以忽略不計。因此,可以得出結論:韻母a的能量集中分布于0~4 500 Hz頻率范圍之間,而這也就是其關鍵頻率范圍,而這個結論將為其后續處理提高一定的理論依據。
2)聲母
下面圖5是聲母b的語譜圖,分別是標準普通話、普通男聲和普通女聲的圖譜。
在圖5(a)中可以看出:語音b的能量主要分布在兩個頻
圖4韻母a的語譜圖
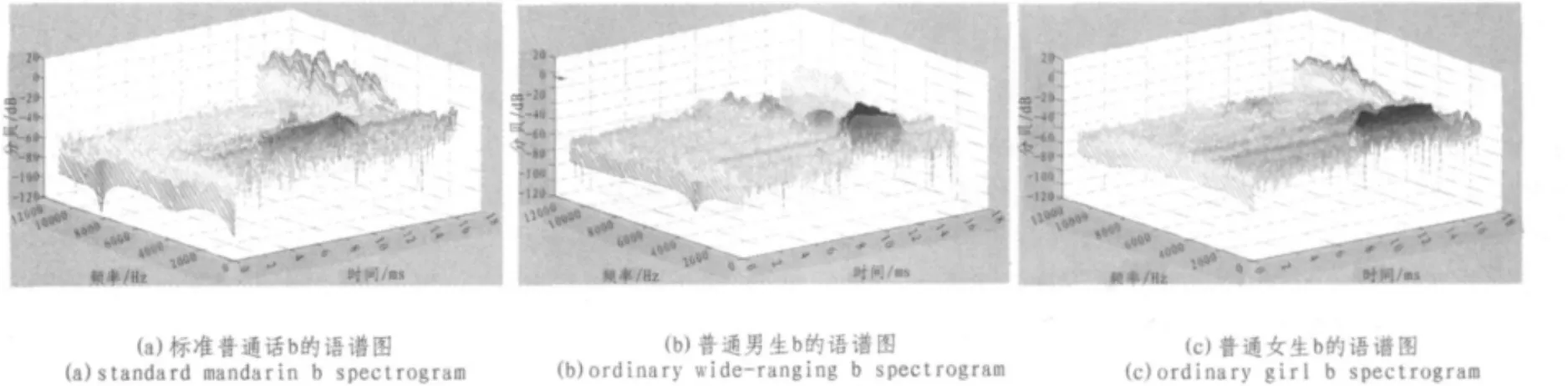
圖5 聲母b的語譜圖Fig.5Initials b spectrogram
Fig.4Vowels a spectrogram率范圍內,大約90%的能量分布在0~1 600 Hz頻率范圍內,其余的能量分布在2 000~4 000 Hz之間。從圖5(b)可以看出,語音b的能量大致分布在兩個頻率范圍內,其中大約70%的能量分布在0~1 700 Hz頻率范圍內,其余能量大致分布在3 000~4 200 Hz之間。從圖5(c)可以看出,語音能量絕大部分分布在0~1 700 Hz頻率段內,其余能量可以忽略不計。因此,可以得出結論:語音b的能量大致分布在0~4 200 Hz頻率段內,但主要分布在0~1 700 Hz之間,這也是其關鍵頻率所在頻率段,是后續研究的重點區域。
3.3 漢語語音關鍵頻率分布
按照上面3.2小節中的方法,將兩種方法結合起來,可以得出所有聲母和韻母的頻率大致分布情況,而漢語語音是有聲母和韻母拼合而成的,了解了聲母和韻母的頻率大致分布情況,那必然經能夠大體確定漢語語音的頻率分布情況,從而為后面的辨析語音提高一定的理論基礎。
經過比較分析得出如下結論:在所有聲母和韻母中,絕大部分的頻率分布范圍是0~5 000 Hz,在這個頻率范圍內,0~1 200 Hz是一個關鍵頻率分布范圍段,即在此頻率段內語音能量較多,接下來2 000~4 000 Hz又是一較為關鍵的頻率段,也具有一定的語音能量,其余頻率段內語音能量較小,幾乎可以忽略不計。由于漢語語音中用一個漢字來代表一個音節,一般來說,一個音節由聲母、韻母和聲調3部分組成,因此,確定了聲母和韻母的頻率分布情況,那么也就大體確定了漢語語音的頻率分布情況。所有上面的結論也適用于絕大部分的漢語語音,這個結論為后面的辨析語音提供了很好的理論基礎。
在有關電子耳蝸的研究中,有的研究所選用濾波器的通帶帶寬在300~6 250 Hz之間[5],說明通過電子耳蝸的語音信號的關鍵頻率大致分布在300 Hz到6 250 Hz這個頻率范圍內。而這也間接說明了上面的結論具有一定的準確性,是可行的,可以作為后續研究的理論依據。
4 結束語
本文首先介紹了有關漢語拼音[6]的知識;然后介紹了時頻分布的特點和優勢;最后通過時頻分布,用兩種方法分析總結了聲母和韻母的頻率分布情況及關鍵頻率分布特點,從而確定漢語語音的關鍵頻率分布情況,以為語音識別的研究提供一定的理論基礎。
當然,本文還要一定的不足:聲母和韻母的頻率分布情況能否更加細化、更加準確?這是以后工作中亟待解決的問題,需要進一步去研究。
[1]韓紀慶,張磊,鄭鐵然.語音信號處理[M].北京:清華大學出版社,2004.
[2]付妮妮.漢語拼音字母詞研究[D].遼寧:遼寧師范大學,
2007.
[3]鄭普亮,許剛.時頻分布不同特性進行語音分類[J].計算機工程與應用,2005(22):48-50.ZHENG Pu-liang,XU Gang.Classification of speech using the different properties of the time-frequency distributions[J].Computer Engineering and Applications,2005(22):48-50.
[4]馬義德,袁敏,齊春亮,等.基于PCNN的語譜圖特征提取在說話人識別中的應用[J].計算機工程與應用,2005(20):81-84.MA Yi-de,YUAN Min,QI Chun-liang,et al.Research of feature extraction from spectrogram based on pulse coupled neuralnetworkinspeakerrecognition[J].Computer Engineering and Applications,2005(20):81-84.
[5]孟麗,肖靈,李平,等.定點DSP實現電子耳蝸CIS策略研究[J].中國生物醫學工程學報,2009,28(3):386-392.MENGLi,XIAOLing,LIPing,etal.Researchonimplementation of CIS strategy for cochlear implants on fixed-point DSP[J].Chinese Journal of Biomedical Engineering,2009,28(3):386-392.
[6]吳葵.漢語拼音在對內漢語教學中的應用研究[D].湖南:湖南師范大學,2007.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
