動態文本會話抽取技術研究
2011-03-15 01:22:48張婭婷
電視技術 2011年11期
張 瑛,張婭婷
(湖南信息職業技術學院 計算機工程系,湖南 長沙 410200)
1 文本會話簡介
隨著網絡聊天室以及聊天工具的普及,以新聞報道為代表的長文本已經不是人們獲得信息源的唯一途徑,博客、門戶網站的新聞影響力正在降低,而網絡論壇、微博、網絡社群等新興輿論載體異軍突起。文本會話抽取就是針對此類動態數據,將屬于同一會話的不同消息文本組織在一起,為后續工作(如話題的檢測、網絡社區發現、熱點話題挖掘)奠定基礎。
1.1 基本概念
相對于話題檢測與追蹤(Topic Detection and Tracking,TDT)中的基本概念,文本會話抽取中的相同術語被賦予了新的含義。
消息:會話討論的參與者一次發表的言論信息,有一個或多個句子構成。如圖1所示,動態文本流中消息相互交織在一起,按序到達。
會話:由討論相關話題的一系列消息組成,起始于一個開始消息,跟隨相關的回復消息,并結束于一個結束消息。
話題:一個種子事件或活動,以及所有與之直接相關的事件或活動。在文本會話抽取研究中,一般認為一個會話對應一個話題,一個話題可以包含多個會話。
會話抽取:從動態交織的文本信息流中檢測出屬于同一會話的消息。
會話在有些研究中也被稱為線程,與操作系統中的線程的定義不同,文本會話中的線程是指一組相關的消息序列。同樣,會話抽取在有些研究中也稱為線程檢測。
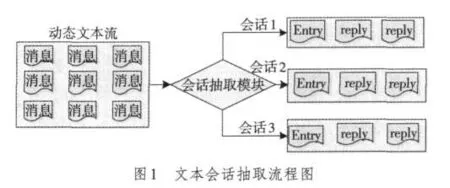
1.2 研究內容
與新聞報道的話題檢測和追蹤相比,動態文本會話抽取面臨更大的挑戰,主要研究內容有:
1)消息、會話模型
話題檢測與追蹤中的經典模型,如向量空間模型、LDA(Latent Dirichlet Allocation)模型等。向量空間模型在會話抽取中運用較多,但由于特征度量的限制并不明顯,生成模型LDA針對短文本有天然優勢,但目前在文本會話抽取中的運用較少。
2)模型特征信息度量
在向量空間模型中,TFIDF方法是針對靜態文本詞匯權重計算而設計的,直接用于動態文本會話流的權重計算存在很大不足。因而,找到更適合動態文本信息流的模型特征信息來表示詞匯權重顯得尤為重要。
3)語言學特征的利用
動態文本會話流中包含許多語言學信息,比如疑問句一般用陳述句回答。“再見”一般標識會話的結束。充分利用這些語言學信息挖掘上下文之間的關聯對文本會話抽取具有十分重要的意義。
4)相似度的計算方法
相似度比較是決定兩個消息是否屬于同一會話的決定性因素,傳統余弦相似度方法對處理短文本非常不利,并且在動態文本會話中,時間上相隔越遠的消息討論屬于同一會話的概率越小,因此,計算相似度時必須考慮時間因素。由此可見,找到合適的相似度計算方法是文本會話抽取的核心所在。
1.3 評測方法
動態文本會話抽取對評測方法研究較少,大多數使用已有的方法,通常采用兩種,一種是信息檢索中準確率、召回率以及F度量指標。另一種則是TDT中的評測方法。
在信息檢索系統中,準確率、召回率和F度量是經典的評估檢索結果的度量指標[1],并適用于評估聚類算法的性能。由于TDT與文本會話抽取歸根都屬于聚類的問題,從而采用TDT的評測標準作為文本會話抽取的評測標準有很大的參考價值。在此,只給出準確率、召回率F度量的計算公式以及TDT中DET曲線的計算方法,詳細內容參考文獻[2],這里不再詳述。
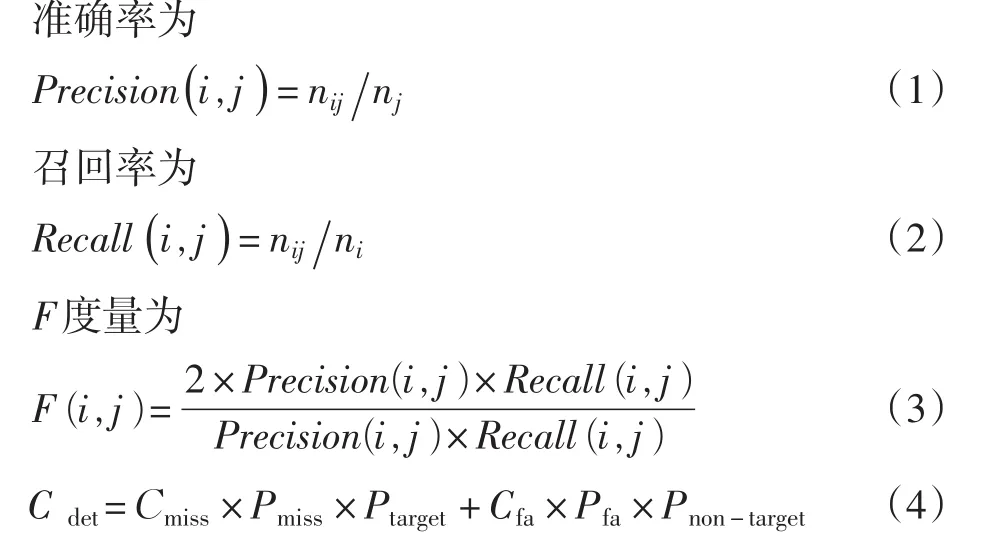
式中:nij為實際分類結果類j中分類正確的屬于人工標注的類i的文檔數目;nj為實際分類結果類j的文檔數目;ni為人工標注的類i的文檔數目;Cdet為系統的錯誤識別代價;Cmiss和Cfa分別是漏報和誤報的代價,通常根據應用預先給定;Pmiss與Pfa分別是系統識別的漏報率和誤報率,可由實際輸出與標準答案的性對照結果計算得到;Ptarget是一個先驗的目標出現率,表示關于某個話題的新網報道出現的可能性;Pnon-target=1-Ptarget。
2 統一研究框架
文本會話抽取的各個研究方面雖然采用不同的模型或者算法,但其系統結構仍存在內在統一性。對文本會話系統結構進行抽象,提出文本會話抽取統一研究框架,如圖2所示。

從圖2可以看出,文本會話抽取系統首先對消息進行預處理,去除噪聲。然后建立消息和會話模型,并充分利用消息的文本內容信息和語言學特征,綜合得到相似度值,并將最終相似度與相似度閾值比較,判斷加入已有會話還是建立新會話。
接下來詳細分析、比較圖中幾個主要模塊的關鍵技術。
3 關鍵技術分析
從圖2中可以看出,文本會話抽取統一研究框架中主要包括預處理、模型建立、相似度度量和相似度組織4個模塊,其關鍵技術分析如下。
3.1 預處理
文本會話抽取系統首先需要進行預處理,且基于以下事實:1)動態文本消息不同于新聞報道,并不是每篇消息都在談論特定的話題,并且部分回復簡短不規則,存在拼寫和語法錯誤,因此產生一些干擾性的噪音文本;2)中文網絡聊天語言具有奇異性的特點[3],奇異性文本需要轉換成標準文本才能為后面各個模塊所用。
為此,文獻[4]提出了一種基于社會網絡的聊天數據噪聲過濾方法,通過分析聊天數據的時序關系,推斷出聊天用戶間的社會網絡關系,并根據用戶交流特點判斷并過濾噪聲。另外,在文本層次上的噪聲過濾主要有兩種解決方案,第一種方案可以設置閾值,將太短的文本過濾掉。另一種解決方案為短文本,只參與會話抽取的聚類,而沒有建立新會話的權限,從而保證了系統不至于因為噪聲問題產生太多的會話。
3.2 表示模型
表示模型包括表示模型選取、特征度量以及模型本身的改進等。
向量空間模型是目前最簡便高效的文本表示模型之一,作為TDT的主流表示模型,在會話抽取中應用也頗為廣泛。向量特征的選取范圍通常是對消息詞集進行停用詞過濾后的候選集合,其基本思想是:給定一自然語言文檔D=D(t1,w1;t2,w2;… ;tN,wN),其中ti是從文檔D中選出的特征項,wi是項的權重,1≤i≤N。這時可以把t1,t2,…,tN看成一個N維的坐標系,而w1,w2,…,wN為相應的坐標值,因而D(w1,w2,…,wN)被看成是N維空間中的一個向量。
特征選取會直接影響使用該模型的系統性能。目前針對會話抽取模型的研究大都是在向量空間模型基礎上對特征度量的改進。
傳統的特征度量包括TFIDF、TFIWF、信息互增益和熵等,其中TFIDF度量應用最廣泛。如1.2節所述,傳統TFIDF值在文本會話抽取中存在很大局限性。文獻[5]運用增量改變TF和DF值的方法,使特征度量值隨時間動態改變:dft(w)=dft-1(w)+dfCt(w),tft(d,w)=tft-1(d,w)+tfCt(d,w),有一定程度上提高了模型精度。文獻[6]提出了一種專門針對聊天數據的詞匯權重計算方法CDTF*IDF,通過分別計算詞匯在不同數據源中的權值并匯總,同時對重點詞匯提高權重等方式來計算聊天數據的詞匯權重。除了TFIDF度量外,文獻[7]提出通過知網抽取概念屬性,用CHI-MCOR方法構建特征集合,文檔信息由出現頻率高的詞和出現頻率低但有重要意義的詞組成,從而避免了重要詞語被海量無用信息淹沒。
會話模型一般對應于消息文檔模型。在傳統向量空間模型中,會話模型表示為各消息模型的向量和,所有消息文本對會話模型占有相同的權重。但動態文本會話對時間的敏感性使得在會話中新到來的消息對會話模型的貢獻更大。文獻[8]基于權重質心的Single-Pass算法中線性衡量隨時間到來的消息的權重在話題檢測與追蹤的研究中,IBM提出動態改變話題項權重的方法,初始化IDF值為標準的與話題無關的IDF0,隨著文檔變化,IDF值不斷調整,從而動態改變話題中項的權重。這對基于向量空間模型的會話抽取也同樣適用。
3.3 相似度度量
相似度計算和表示模型關系密切,需要結合模型本身特點并充分利用表示模型的內容。一般來講,會話相似度由兩部分組成,一是文本內容相似度,二是語言學特征相似度。
1)文本內容相似度
由于話題發現與追蹤中的相似度計算是針對新聞報道的內容而進行的研究,因而用于TDT中的相似度計算方式也同樣適用于會話抽取中的文本相似度計算。對于向量空間模型計算方法很多,如Okapi公式、Clarity公式、Hellinger、Tanimoto等,其中余弦相似度最常用,也最有效。如果采用概率模型表示文檔,如LDA,則常用KL(Kullback Leibler)相對熵來衡量主題之間的相似度。
2)語言學特征相似度
如上文所述,相鄰消息間的語言特征并不是隨機的,而是隱含某種隱形規則,這種隱含在上下文之間的關系用條件概率來標識。文獻[8]引入了兩種參考指標:句式和人稱代詞。采用M.STF和M.STL表示消息開始句和結束句的類型。用M.PPF和M.PPL表示消息開始句和結束句的人稱代詞,從而前后消息的條件概率可以用P(T(Mi,Mi)|Mi.STL,Mi.STF)和 P(T(Mi,Mi)|Mi.PPL,Mi.PPF)表示,通過貝葉斯條件公式及訓練集的最大似然估計得到兩個概率值,然后加權平均作為消息Mi和Mj的語言特征相似度。
3)最終相似度決定
消息文本最終相似度一般取決于上述兩種相似度度量。文獻[8]采用兩者平均值作為最終相似度,文獻[9]在此基礎上引入了權衡因子,通過調整權衡因子的大小可改變各相似度所占的比重。除此之外,文獻[5]提出了將用戶活動作為相似度的一部分,并基于社會網絡中的社區用戶模型提出了UF-ITUF模型,動態改變會話抽取系統中用戶活動的影響。文獻[8]在計算相似度時還考慮了姓名、內容、時間、地點等實體要素。
3.4 會話組織策略
不同于靜態的新聞報道,文本會話流具有動態性,隨著時間變化文檔不斷到來。K-means聚類算法等靜態聚類算法,由于其要事先制定聚類數目,并不適用于文本會話抽取。目前采用最多的是Single-Pass策略。文獻[8]提出了3種不同的Single-Pass策略,其中基于最鄰近距離的Sing-Pass策略中消息的分類算法類似于KNN。KNN算法在新會話的檢測中運用廣泛,而從系統實現的角度講,通常采用相似度直接與閾值比較的策略。
除此之外,文獻[11]提出基于頻繁刺激的短文本聚類算法FTSDC和基于密度的短文本聚類算法DSDC,首先根據頻繁刺激進行初始簇劃分,然后利用語義信息進行簇優化。DSDC使用語義信息來計算樣本距離,基于共享近鄰圖來進行基本聚類,并通過數據抽樣和子圖劃分來實現并行聚類。
4 難點與展望
由于文本會話本身的特點和處理對象的特殊性,使得話題發現與追蹤中的許多經典方法不如在原來領域中那么有效。與TDT相比較,文本會話的難點包括消息語言奇異性與標準語言的映射和表示模型的修正、相似度的度量等,這也是今后研究的重點內容。
動態文本會話雖然與話題檢測和追蹤相比有很大的特殊性,但是都同屬于文本聚類問題。隨著網絡的普及和論壇、社區、微博的迅速發展,動態文本會話抽取技術的研究將得到越來越多的重視。到目前為止,國內外的研究并不是很多,而且其研究方法大都是借鑒于話題檢測與追蹤中的方法,文本會話抽取技術要得到飛躍必須沖破傳統思想的禁錮,結合本身問題及處理對象的特點,創造適合自己的模型。從應用的角度來說,隨著文本會話研究的深入,其相關領域也受到越來越多的關注。動態文本會話系統將在會話抽取后的話題檢測、社區發現、基于話題的多文本摘要等方面體現其越來越重要的地位。
[1]WANG Lin,JIANG Minghu,LIAO Shasha,et al.Concept features extraction and text clustering analysis of neural networks based on cognitive mechanism[J].Concept Features Extraction and Text Clustering Analysis of Neural Networks Based on Cognitive Mechanism,2006,4113:235-246.
[2]XI W,LIND J,BRILL E.Learning effective ranking functions for newsgroup search[C]//Proc.SIGIR’04.Sheffield,UK:[s.n.],2004:394-401.
[3]夏云慶,黃錦輝,張普.中文網絡聊天語言的奇異性與動態性研究[J].中文信息學報,2007,21(3):83-91.
[4]高鵬,曹先彬.基于社會網絡的聊天數據噪聲過濾[J].計算機工程,2008,34(5):166-168.
[5]HONG Yu,ZHANG Yu,LIU Ting,et al.Topic detection and tracking rewiew[J].Journal of Chinese Information Processing,2007,21(6):71-87.
[6]李卓爾,胡運發.一種對BBS語料進行話題提取的聚類算法[J].計算機應用與軟件,2008(8):1-3.
[7]WANG Le,JIA Yan,CHEN Yingwen.Versation extraction in dynamic text message stream[J].Urnal of Computers,2008(10):86-93.
[8]ZHU Mingliang,HU Weiming,Wu Ou.Topic detection and tracking for threaded discussion communities[C]//Proc.the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology.[S.l.]:IEEE Press,2008:77-83.
[9]SHEN Dou,YANG Qiang,SUN Jiantao,et al.Thread detection in dynamic text message streams[C]//Proc.the 29th annual international ACM SIGIR conference on Research and Development in Information Retrieval.New York,USA:[s.n.],2006:35-42.
[10]STENBACH M,KARYPIS G,KUMAR V.A comparison of document clustering techniques[EB/OL].[2011-01-02].http://rakaposhi.eas.asu.edu/cse494/notes/clustering-doccluster.pdf.
[11]王永恒.海量短語信息挖掘技術的研究與實現[D].長沙:國防科學技術大學,2006.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
