無向圖同構的快速算法*
2011-06-25 06:33:22侯愛民郝志峰胡傳福陸海鵬
華南理工大學學報(自然科學版) 2011年10期
侯愛民 郝志峰 胡傳福 陸海鵬
(華南理工大學計算機科學與工程學院,廣東廣州510006)
在研究圖論的問題中,經常需判斷兩個圖是否同構,即從頂點和邊的拓撲結構上來看,兩個圖是否有可能以同樣的方式畫出.換句話說,當兩個圖同構時,兩個圖的頂點之間具有保持相鄰關系的一一對應.判斷兩個圖是否同構是一個NP難問題.
至今為止,國內國際上公認的實際可行的判斷算法分為兩類:一類是對頂點編號進行特殊處理[1-2],另一類是通過不斷刪除頂點來對頂點集合的劃分進行細分[3-7].Babai等[1]使用頂點度數對隨機圖進行規范標記,能產生同樣規范標記的兩個圖是同構的,不能產生同樣規范標記的兩個圖是不同構的.該算法的時間復雜度為O(n2),是目前為止運算速度最快的著名算法.其缺點是對于不能進行規范標記的兩個圖,算法失效;而且拒絕率上界為n-1/7.對其改進的算法[2]也具有非零非負的拒絕率,即雖然它們的平均運行時間非常快,也不能處理所有類型的圖.頂點集合劃分是判斷圖同構的一種有效方法,可以有效減小同構函數候選集.這一思想也是目前許多常見的圖同構判斷算法[3-7]的基本思想.但這些算法不可避免地都要進行回溯,也就是要構造一棵搜索樹,不斷進行試探和剪枝,算法的時間復雜度取決于回溯的深度和次數.
文獻[8]中提出了判斷無向圖同構的一個高效的必要條件,使用這個條件,可以更細地對頂點集合進行劃分.文獻[9]中提出了判斷無向圖同構的一個充分必要條件,使用這個條件,可以判斷同構的兩個圖在新增頂點和關聯邊后構成的新圖是否同構.因為新圖是否同構取決于舊圖的同構函數,所以利用必要條件篩選舊圖的同構函數候選集,可以降低時間開銷.文中采用基于子圖同構判斷父圖同構的策略,提出一種新的無需回溯的快速算法,用于降低時間開銷,保證正確判斷.通過理論論證、實際案例測試,驗證了該算法的有效性.
1 無向圖同構的相關理論
使用必要條件可以對頂點集合V(G)進行劃分.針對某種劃分{cell1,cell2,…,cellk},(celli?V(G),1≤i≤k),同構函數候選集的大小為.必要條件不同,導致頂點集合劃分的細分程度不同.細分程度越細(即k越大,且越小),同構函數候選集越小,從而導致需檢驗的頂點對應關系越少,越能有效地降低判斷算法的時間開銷.文獻[8]中提出一個必要條件,其細分程度比“頂點度”必要條件和“頂點的鄰接點的度序列”必要條件更細,也比文獻[3]中提出的必要條件更細.
本算法核心思想使用文獻[9]中提出的充分必要條件進行判斷,既可以保證完備性和收斂性,又可以避免回溯.
定義1[8]設無向圖G=(V,E),在其鄰接矩陣AG=(aij)n×n中,第i行與第j行的行碼距異或距離定義為第i行與第j行對應列上取不同值(即一個取0,另一個取1或k)的諸列上各元素之和,記為xord(i,j).如果 i≠j,則令 byij=xord(i,j);否則令byij=aii.稱矩陣BYG=(byij)n×n為圖 G 的行碼距異或矩陣.
定義2[8]設無向圖G=(V,E),在其鄰接矩陣AG=(aij)n×n中,第i行與第j行的行碼距同或距離定義為第i行與第j行對應列上取相同值(即一個取1或k,另一個也取1或k)的諸列上各元素之和,記為aord(i,j).對于所有的 i和 j,令 btij=aord(i,j).稱矩陣BTG=(btij)n×n為圖G的行碼距同或矩陣.
定義3[8]設兩個矩陣 A=(aij)n×n和 B=(bij)n×n,A 中的行編號為 u1,u2,…,un,B 中的行編號為 v1,v2,…,vn.如果存在一個置換[u1? v'1,u2?v'2,…,un? v'n],其中(v'1,v'2,…,v'n)是(v1,v2,…,vn)的一種排列,使得A中編號為ui的行與B中編號為v'i的行具有元素一樣的特征(不考慮元素的位置次序),則稱[u1?v'1,u2?v'2,…,un?v'n]為矩陣 A 和 B的行-行置換.
定理1[8]設兩個無向圖G和H同構,則圖G的鄰接矩陣、行碼距異或矩陣、行碼距同或矩陣分別與圖H的鄰接矩陣、行碼距異或矩陣、行碼距同或矩陣具有同一的行-行置換.
定理2[8]設兩個無向圖G和H同構,則一定存在圖G的一個子圖Gi和圖H的一個子圖Hj同構.對于任意一對同構的子圖Gi和Hj,必有圖Gi的鄰接矩陣、行碼距異或矩陣、行碼距同或矩陣分別與圖Hj的鄰接矩陣、行碼距異或矩陣、行碼距同或矩陣具有同一的行-行置換.這種關系一直保持到Gi和Hj只有兩個頂點.
定理3[9]同構的兩個無向圖G和H,各自增加一個頂點unew和vnew,以及與新增頂點關聯的若干條邊,形成兩個新圖G+unew和H+vnew.新圖G+unew和H+vnew同構,當且僅當存在G?H的一個同構函數f,使得新頂點的所有鄰接點在同構函數f的作用下,在G和H中保持同構關系.
2 無向圖同構的快速判斷算法
步驟1 根據圖G和H的鄰接矩陣AG和AH,分別計算圖G和H的行碼距異或矩陣BYG和BYH,以及行碼距同或矩陣BTG和BTH.
步驟2 根據圖G的行碼距異或矩陣BYG,依次考慮每個頂點ui(1≤i≤n)所在的行.對于每個頂點ui所在的行,在圖H的行碼距異或矩陣BYH中尋找保持元素一樣的對應行,構成頂點ui的一個匹配集S_ui.如果某個頂點不存在匹配集,則可以判斷圖G和H不同構,算法結束;如果所有匹配集的并集沒有n個元素,則可以判斷圖G和H不同構,算法結束;否則,在鄰接矩陣AG和AH、行碼距同或矩陣BTG和BTH中,檢查這些匹配集是否依然成立.如果不成立,則可以判斷圖G和H不同構,算法結束;否則,根據匹配集,生成若干個行-行置換.
步驟3 考慮圖G的任意一個頂點ui.對于vj∈S_ui,依據步驟1和步驟2的方法,判斷子圖G-ui和H-vj是否同構.如果存在某個頂點ui,使得對于vj∈S_ui,都有子圖G -ui和H -vj不同構,則可以判斷圖G和H不同構.算法結束.
步驟4 考慮圖G的具有相同最小度數的每個頂點ui.對于vj∈S_ui,分別判斷子圖G -ui和H -vj是否為完全圖.若是,則可以判斷圖G和H同構.算法結束.此時,G-ui?H-vj的任何同構函數f,補充對應關系vj=f(ui)后,都將構成G?H的同構函數.
步驟5 考慮圖G的具有相同最小度數的每個頂點ui.對于vj∈S_ui,檢查ui的所有鄰接點和vj的所有鄰接點在子圖G-ui和H-vj中是否保持同構關系.具體做法如下根據子圖G-ui和H-vj的頂點匹配集,檢查ui的所有鄰接點和vj的所有鄰接點是否滿足這些匹配關系;在滿足的前提下,根據排列組合生成若干個行-行置換,這些行-行置換構成一個潛在的同構函數候選集;檢查每一個行-行置換是否是子圖G-ui和H-vj的同構函數;如果有一個行-行置換是子圖G-ui和H-vj的同構函數f,則可以判斷圖G和H同構.算法結束.此時,對這個同構函數f補充對應關系vj=f(ui)后,將構成G?H的同構函數.否則,所有的行-行置換都不是子圖G-ui和H-vj的同構函數,可以判斷圖G和H不同構,算法結束.
3 實驗及案例分析
文中給出了一些典型案例(見圖1)來說明上述算法的可行性,同時給出了與其它必要條件/算法的對比分析,以說明上述算法的有效性.
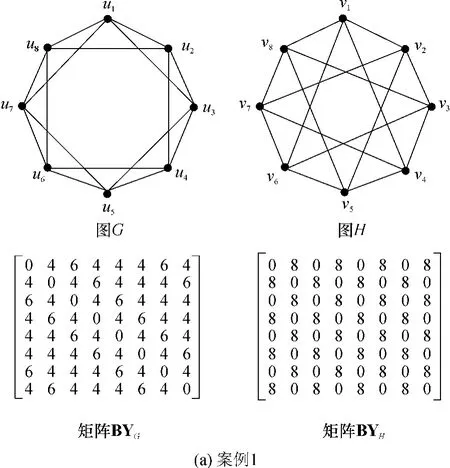
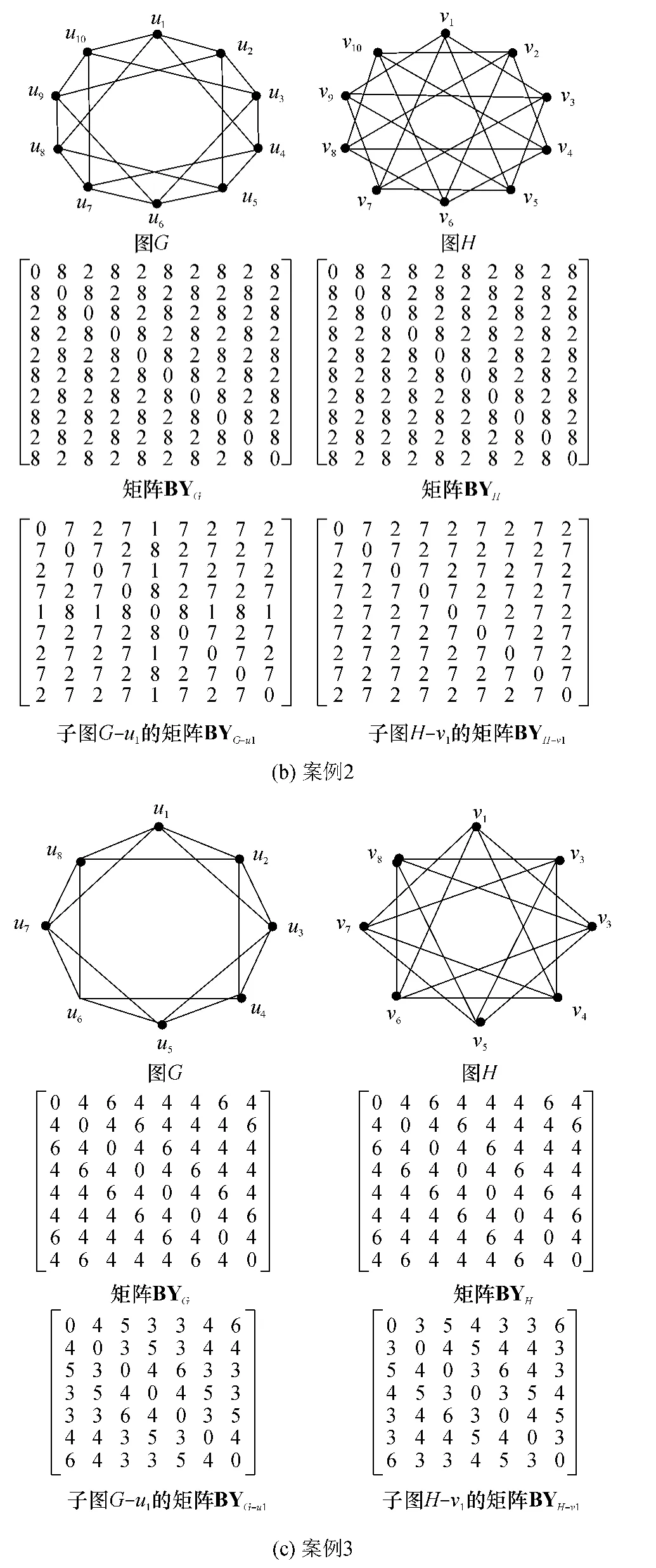
圖1 一些典型案例Fig.1 Some typical cases
如圖1(a)所示,案例1中,原始圖G和H的行碼距異或矩陣BYG和BYH之間不存在同一的行-行置換,因為BYG中存在一行(04644464),在BYH中不存在對應行.相反,使用“頂點度”必要條件和“頂點的鄰接點的度序列”必要條件,以及文獻[3]中提出的必要條件,都不能直接判斷出G和H不同構.此外,文獻[1]中提出的算法不能對圖1(a)案例進行規范標記,從而無法判斷是否同構.
如圖1(b)所示案例2中,原始圖G和H的行碼距異或矩陣BYG和BYH之間存在同一的行-行置換,但是子圖G-u1的行碼距異或矩陣BYG-u1和子圖 H-vj(1≤j≤10)的行碼距異或矩陣BYH-vj之間不存在同一的行-行置換.使用“頂點的鄰接點的度序列”必要條件,能直接判斷出G-u1和H-vj(1≤j≤10)不同構.但使用“頂點度”必要條件和文獻[3]中提出的必要條件,都不能直接判斷出G-u1和H-vj(1≤j≤10)不同構.另一方面,在處理圖1(b)案例時,文獻[3-7]中算法需要進行多次回溯操作.此外,文獻[1]中提出的算法不能對圖1(b)案例進行規范標記,從而無法進行判斷.
此外,文獻[1-2]是目前為止平均時間開銷最少的判斷算法,其缺點是具有非零非負的拒絕率.也就是說,這類算法不能處理所有類型的圖.例如,文獻[1]中的拒絕率上界為n-1/7.針對頂點個數n=128的兩個無向圖,最壞情況下將有50%的圖不能進行判斷,而文中算法可以處理所有類型的圖.
事實上,對隨機生成的無向正則圖和無向非正則圖、無向強正則圖、無向偽圖等進行案例驗證,都能證明了文中算法的正確性和有效性.限于篇幅所限,不再贅述.
使用C語言編程實現上述圖同構判斷算法,對隨機生成的一對隨機圖(包括正則圖和非正則圖),以及圖數據庫[10]中的11900個樣本進行程序判定.這些樣本共分5大類,根據頂點個數和其它參數,每個大類又分為若干子類.每個子類測試了100個樣本,即50個配對圖.所有實驗均在AMD Athlon(tm)64×2 Dual Core Processor 3600Hz/1GB內存的計算機上進行,結果如表1所示.測試結果表明,無一例外,對于同構的兩個圖,文中算法均能正確判斷,并給出同構函數;對于不同構的兩個圖,也能正確判斷,且用時合理.
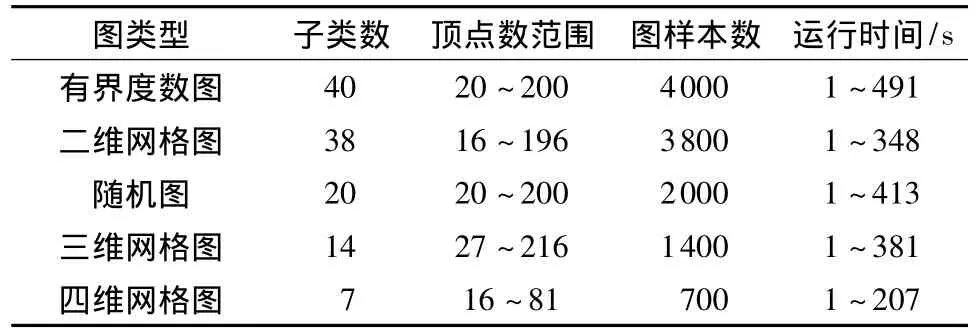
表1 圖同構判斷算法對5種典型類型圖的測試結果Table 1 Test results of the five categories by the proposed graph isomorphism algorithm
程序運行的實驗數據表明:對于同構的兩個圖,可以在100s之內判斷同構,找到一個同構函數.對于不同構的兩個圖,運行時間取決于頂點個數和正則性.在頂點個數相同的情況下,非正則圖的運行時間少于正則圖的運行時間.頂點個數越多,運行時間越長.強正則圖的運行時間最長.這些結論與實際案例驗證的結果一致.
4 結論
無向圖同構的判斷問題至今沒有完全解決.規范標記算法具有O(n2)的時間復雜度,但是不完備,不能處理所有類型的圖.頂點劃分算法需要不斷地回溯和試探,從而造成最壞情況下指數階時間復雜度.為了避免回溯,同時保證完備性,文中提出一種基于充要條件的快速判斷算法.為了進一步降低時間開銷,采用基于子圖同構判斷父圖同構的策略,使用一種高效的必要條件篩選同構函數候選集的范圍.最后通過理論論證、實際案例測試,驗證了該算法的有效性.
[1]Babai L,Erds P,Selkow S M.Random graph isomorphism[J].SIAM Journal of Computing,1980,9(3):628-635.
[2]Czajka Tomek,Pandurangan Gopal.Improved random graph isomorphism [J].Journal of Discrete Algorithms,2008,6(1):85-92.
[3]Ullmann J R.An algorithm for subgraph isomorphism[J].Journal of the Association for Computer Machinery,1976,23(1):31-42.
[4]Schmidt D C,Druffel L E.A fast backtracking algorithm to test directed graphs for isomorphism using distance matrices[J].Journal of the Association for Computer Machinery,1976,23(3):433-445.
[5]McKay B D.Practical graph isomorphism[J].Congressus Numberantium,1981,30:45-87.
[6]Cordella L P,Foggia P,Sansone C,et al.An improved algorithm for matching large graphs[C]∥Proceedings of International Workshop on Graph-based Representation in Pattern Re-cognition.Ischia:[s.n.],2001:149-159.
[7]Cordella L P,Foggia P,Sansone C,et al.Subgraph transformations for the inexact matching of attributed relational graphs[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(10):1367-1372.
[8]侯愛民.圖同構的矩陣初等變換判定及算法設計[J].計算機工程與應用,2006,42(20):51-54.Hou Ai-min.Elementary operations on a matrix to determine the isomorphism of graphs[J].Journal of Computer Engineering and Applications,2006,42(20):51-54.
[9]侯愛民.圖同構的一個充分必要條件[J].計算機工程與應用,2009,45(30):57-61.Hou Ai-min.Necessary and sufficient condition of graphic isomorphism [J].Journal of Computer Engineering and Applications,2009,45(30):57-61.
[10]Foggia P,Sansone C,Vento M.A Database of graphs for isomorphism and sub-graph isomorphism benchmarking[C]∥Proceeding of the 3rd IAPR-TC15 International Workshop on Graph-based Representions.Berlin:Springer,Italy,2001:176-187.
