云計算平臺生存性研究
2011-06-27 02:30:06趙淦森王維棟季統凱
電信科學 2011年9期
趙淦森,王維棟,孫 偉,季統凱
(1.華南師范大學計算機學院 廣州510631;2.中山大學軟件學院 廣州510275;3.廣東電子工業研究院 東莞 523808)
1 引言
云計算(cloud computing)是一種計算模式,它實現了對共享可配置計算資源(網絡、服務器、存儲、應用和服務等)方便、按需的訪問;這些資源可以通過較小的管理代價或服務提供者的交互被快速地準備和釋放。云計算具有以下基本特性:按需索取、廣泛的網絡訪問、資源池化管理和供應、快速彈性伸縮和服務度量[1]。
依據部署模型分類,云計算可以分為私有云、社區云、公共云和混合云。依據服務模式分類,云計算可以分為軟件即服務 (software as a service,SaaS)、平臺即服務(platform as a service,PaaS)和基礎設施即服務(infrastructure as a service,IaaS)。SaaS通過瀏覽器把程序傳給成千上萬的用戶。對用戶來說,這個模式會省去在網絡/系統軟件授權和應用軟件開發上的開支;從供應商角度來看,同一系統可供多次使用并多次收取使用費以實現效益最大化。Salesforce[2]即是典型的SaaS應用。PaaS可以認為是SaaS的延伸。這種形式的云計算把開發、部署環境作為服務來提供,可創建自己的應用軟件并部署在供應商的基礎架構上運行,然后通過網絡從供應商的服務器傳遞給用戶,例如Google App Engine[3]。IaaS提供給消費者的服務是對所有設施的利用,包括處理、存儲、網絡和其他基本的計算資源,用戶能夠部署和運行任意軟件,包括操作系統和應用程序。消費者不管理或控制任何云計算基礎設施,但能控制操作系統的選擇、儲存空間以及應用的部署,也有可能獲得有限制的網絡組件 (如防火墻、負載均衡器等)的控制。典型的例子有EC2[4]、vSphere[5]等。本文的研究主要面向IaaS云。
自從Barnes等人于1993年首次提出信息系統的生存性概念開始,對于生存性的研究就開始逐漸引起人們的關注。生存性是指系統能夠在遭受攻擊、出現故障或意外事故后仍然能夠及時完成其任務的能力[6,7]。這種能力意味著系統可以遭受入侵、部分受損,但能夠保證所執行的關鍵任務按時完成。在這種情況下,雖然系統的安全策略失敗了,但是其生存策略卻是成功的。生存性是一個非常重要的系統性能參數,可以作為系統在遭受攻擊、軟硬件故障等意外事故后對其運行性能優劣進行評價和判定的指標。
目前國內外已有不少有關生存性的研究成果。例如Irving Vitra Paputungan等人進行的生存能力相關的恢復過程建模[8]、Andrew P.Moore等人進行的信息安全與生存性的攻擊建模[9]、陳左寧進行的大規模計算機系統的可信性技術研究[10]等。云計算作為一種新興并迅速發展的計算模式,在其先進、靈活、高效的服務理念備受贊譽的同時,云計算平臺的穩定性和生存性也受到了廣泛的關注。
2 生存性分析方法
目前已經存在許多進行生存性分析的方法,其中最為權威、應用最廣泛的是CMU/SEI提出的SNA(survivable network analysis)[11]方法。SNA方法分為4個步驟,如圖 1所示。

其中3R分析[12]是SNA方法最重要的部分。3R包括以下3種能力。
(1)攻擊識別能力(recognition)
指系統識別攻擊或者攻擊掃描的能力。這種面臨入侵的反應和適應的能力是系統應對攻擊的核心能力。
(2)攻擊抵抗能力(resistance)
指系統遭受攻擊時的抵抗能力。抵抗在滲透和探測階段比破壞發生的時候更重要。現在的抵抗策略包括防火墻、認證、加密等。
(3)系統恢復能力(recovery)
指系統在遭受攻擊后恢復服務以及抵抗和識別未來潛在攻擊的能力。
3 生存性機制
3.1 基礎模型
云計算平臺,尤其是IaaS云平臺的用戶所關心的,是自己所請求的云服務是否可用以及云平臺發生異常后云服務能否在盡可能短的時間內恢復。對于服務提供商來說,要滿足用戶的需求,就必須對云平臺的基礎設施進行監控,避免可能發生的攻擊或系統異常,并在盡可能短的時間內恢復已經停止的云服務。
依據以上分析,結合SNA方法,提出“監控—分析—決策—處理—反饋”模型,如圖2所示。
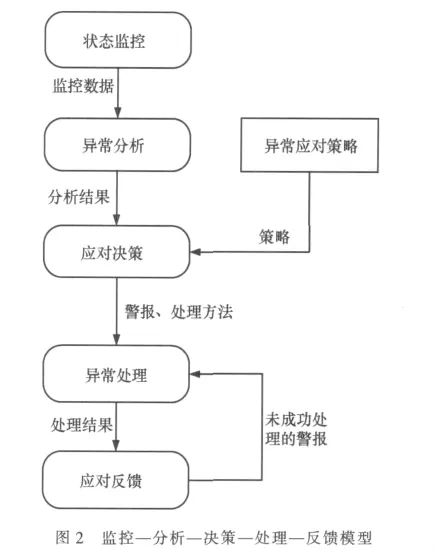
監控—分析—處理—反饋模型的基本思路是:
·通過對云平臺的物理設備以及必需服務進行監控,獲取監控數據;
·分析監控數據,提取異常狀況,分析異常狀況原因和定位相關起因并生成警報;
·根據異常應對策略以及分析得到的異常原因,生成故障應對的方法,通知相關責任人;
·根據警報狀況和處理方法進行自動或手動處理;
·對處理結果進行反饋,未能成功自動處理的警報將留待相關責任人手動處理。所有未能成功處理的警報都將重新提交至處理環節。
3.2 生存性機制
本文提出的生存型機制基于虛擬機的在線遷移,而虛擬機遷移的基礎則是虛擬化技術。
虛擬化[13]是IaaS云平臺的基礎,通過在物理設備和應用服務之間加入虛擬化層,使得應用服務不再依賴于固定的物理設備。應用服務由此可以在不同物理設備間遷移。大部分IaaS云平臺提供的計算資源粒度是虛擬機。
當某臺物理設備遭遇外部攻擊、系統異常或硬件異常時,系統在進行異常應對過程中,需要將運行于有風險或異常的物理設備上的虛擬機遷移[15]至其他狀態正常的物理設備。遷移后的虛擬機的狀態與遷移前保持一致,從而保證了云平臺能夠在不影響服務可用性的前提下把云服務從有風險或異常的物理設備轉移到穩定的物理設備之上,避免了云服務因為系統異常或硬件異常而失效的風險。
虛擬機的遷移有離線遷移和在線遷移兩種。離線遷移過程需要把虛擬機暫停,從而虛擬機承載的服務也將停止。系統通過把暫停后的虛擬機的狀態和數據同步到目標的機器后,再把虛擬機重新運行。在線遷移在不需要暫停虛擬機的前提下,把在運行狀態的虛擬機的狀態和數據同步到目標機器,然后在關閉原來的虛擬機的同時啟動目標機器上的虛擬機。
當某臺物理設備因為系統異常而不可用,則它的物理資源對于云平臺來說是失效的。本生存性機制通過向運行于該物理設備上的控制器發送命令,恢復該物理設備上異常的系統服務或重啟設備,使物理設備恢復為可用狀態,從而實現云平臺自動恢復失效物理資源的能力。
當沒有提供處理預案的異常發生,或者異常自動處理失敗時,本生存性機制能夠通過用戶界面通知相關責任人,也可以調用第三方監控軟件的相關功能,通過E-mail、短信等方式通知相關責任人手動處理異常。
3.3 物理設備運行狀態建模
通過對物理設備運行狀態進行建模,可以明確物理設備運行狀態正常與否的標準,并為各種可以預期的外部攻擊、系統異常或硬件異常提供有針對性的處理預案。當部分物理設備遭受攻擊、發生或可能發生異常時,云平臺可依據處理預案做出響應,并執行對應的指令,從而在無需人工干預的情況下,處理大部分可預期的攻擊和系統異常,保證云服務的正常運行。
對物理設備運行狀態進行建模,首先需要依據該物理設備的功能來制定監控計劃,界定需要監控的硬件狀況、必要服務和資源使用情況,生成監控項;然后對每個監控項制定判定異常發生的標準以及異常的級別;最后針對各個監控項的異常狀態提出對應的處理預案。下面是一個簡單的例子。
節點主機指運行節點控制器(node controller,NC)的物理主機,提供云平臺實際物理資源并管理運行于其上的虛擬機。針對該類物理機進行運行狀態建模見表1。
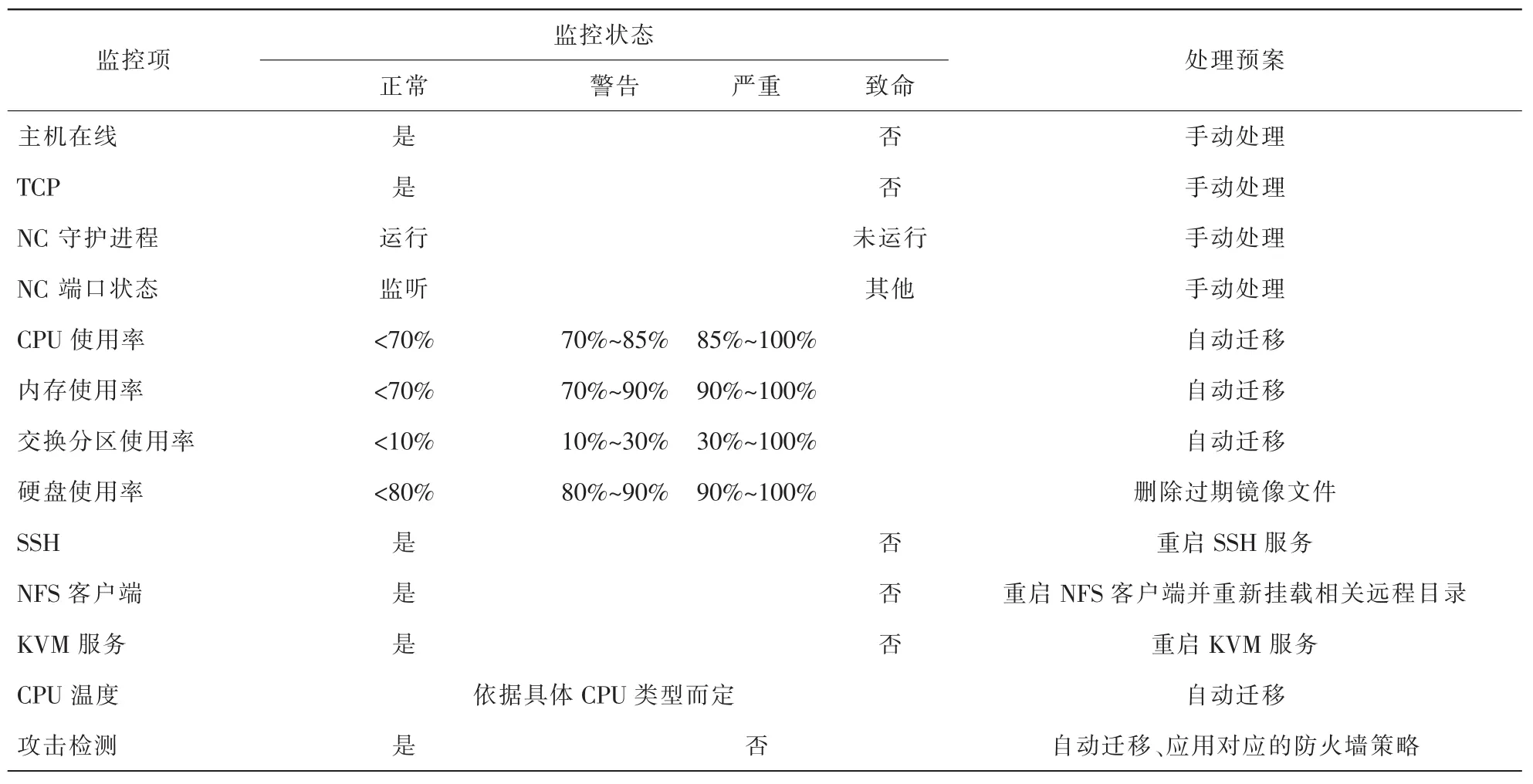
表1 節點主機運行狀態建模
與上例類似,也可以用同樣的方法對云平臺內的其他物理設備進行運行狀態建模。完成對所有類型的物理設備的運行狀態建模工作并將這些模型整合后,就得到了云平臺的運行狀態模型。云平臺內的任何一個物理設備都可以映射到云平臺運行狀態模型中對應的物理設備運行狀態模型。所以,對云平臺內物理設備的監控數據的分析就轉化為對該物理設備的實時運行狀態模型和正常運行狀態模型的匹配,對云平臺的監控數據的分析也就轉化為對云平臺實時運行狀態模型和云平臺正常運行狀態模型的匹配。
3.4 異常應對
當云平臺中某臺物理設備的實時運行狀態模型和云平臺正常運行狀態模型的匹配失敗時,該物理設備將被判定為有風險的物理設備。本生存性機制將通過匹配過程得到匹配失敗的具體監控項,并根據該監控項的實時監控數據得到發生的風險或異常的嚴重程度,嚴重程度較高的風險或異常將被優先處理。
在處理風險或異常時,本生存性機制從該物理設備的運行狀態模型中獲取與當前異常對應的處理預案。依據處理預案,本生存性機制對異常處理方法進行決策,具體可以分為以下兩種情況。
第一種,應對必要服務狀態異常、存儲空間不足等問題,本生存性機制通過向該物理設備上的控制器發送相應的處理指令來解決異常。
第二種,當設備負荷過重、資源利用過高、硬件狀況異常、遭受或可能遭受外部攻擊時,本生存性機制將運行于該物理設備上的虛擬機遷出。對于設備負荷過重、資源利用過高、硬件狀況異常等問題,將虛擬機遷出可以有效保證虛擬機內部署的應用不會因為這些問題而變得效率低下或中斷。對于虛擬機遭受或可能遭受外部攻擊的情況,將該虛擬機遷出并更新相應配置可使外部攻擊失去目標,從而防止因為外部攻擊導致的虛擬機內的應用中斷或數據泄漏。
本生存性機制依據以下幾個原則來進行虛擬機遷移目標的決策。
原則一:當用戶無特殊要求時,將虛擬機遷移到哪個物理設備由云平臺當前所應用的自動調度策略決定。這些自動調度策略可能包括節能策略、最小需求策略、高性能策略等。
原則二:當用戶有安全性需求,或需要遷出的虛擬機對物理設備的架構有所要求時,本生存性機制將允許用戶制定相應的遷移規則(例如某個部署敏感應用的虛擬機只能被遷移到指定網段的物理設備等),并在遷移規則允許范圍內應用云平臺現有的自動調度策略決定虛擬機遷移的目標。
原則三:用戶手動指定遷移目標。完成對異常處理方法的決策后,本生存性機制原型向異常發生的物理設備上的控制器發送對應指令,并獲取指令執行結果。參考§3.1中提出的“監控—分析—決策—處理—反饋”模型,當異常處理失敗時,其警報將被重新提交到處理環節,留待用戶手動處理。
4 原型架構設計
4.1 整體架構
依據上文提出的生存性機制,進行原型的整體架構設計。為了實現預想功能,整體架構設計需要包括監控、分析、處理、反饋4個方面,此外,監控項目和處理方法應該具有可定制性,以期適應不同的監控需求。本原型將分析、處理、反饋以及可定制性進行整合,得到云監控(cloud monitor)模塊。監控功能通過使用第三方開源監控軟件Nagios[14]實現,實現可定制性需要與用戶界面交互,實現自動處理功能需要與其他云平臺的其他控制器(controller)交互。綜合考慮以上各個方面,得出生存性方案的整體架構如圖3所示。
云監控模塊與底層監控軟件Nagios運行于云監控主機上,通過插件監控狀態讀取插件和配置器控制底層監控軟件Nagios。Nagios則通過調用運行于遠端受監控主機上的NRPE插件實現對遠端主機的實時監控。云監控模塊通過與用戶界面交互來提供可定制性,通過與其他云平臺控制器交互來實現警報自動處理功能。對該架構進行詳細分析如下。
(1)部署情況
云監控模塊和底層監控軟件Nagios均部署在云監控主機上,Nagios的遠程監控插件NRPE則部署在所有被監控主機上。
(2)云監控模塊結構
為保證能夠獨立穩定地運行,且盡量少地受到操作系統的影響,云監控模塊被設計成Daemon進程(即守護進程,是一種后臺服務進程,通常生存期較長并獨立于控制終端。常用于周期性地執行某項任務,等待處理某些可能發生的事件),在云監控主機啟動時加載并開始監控服務。
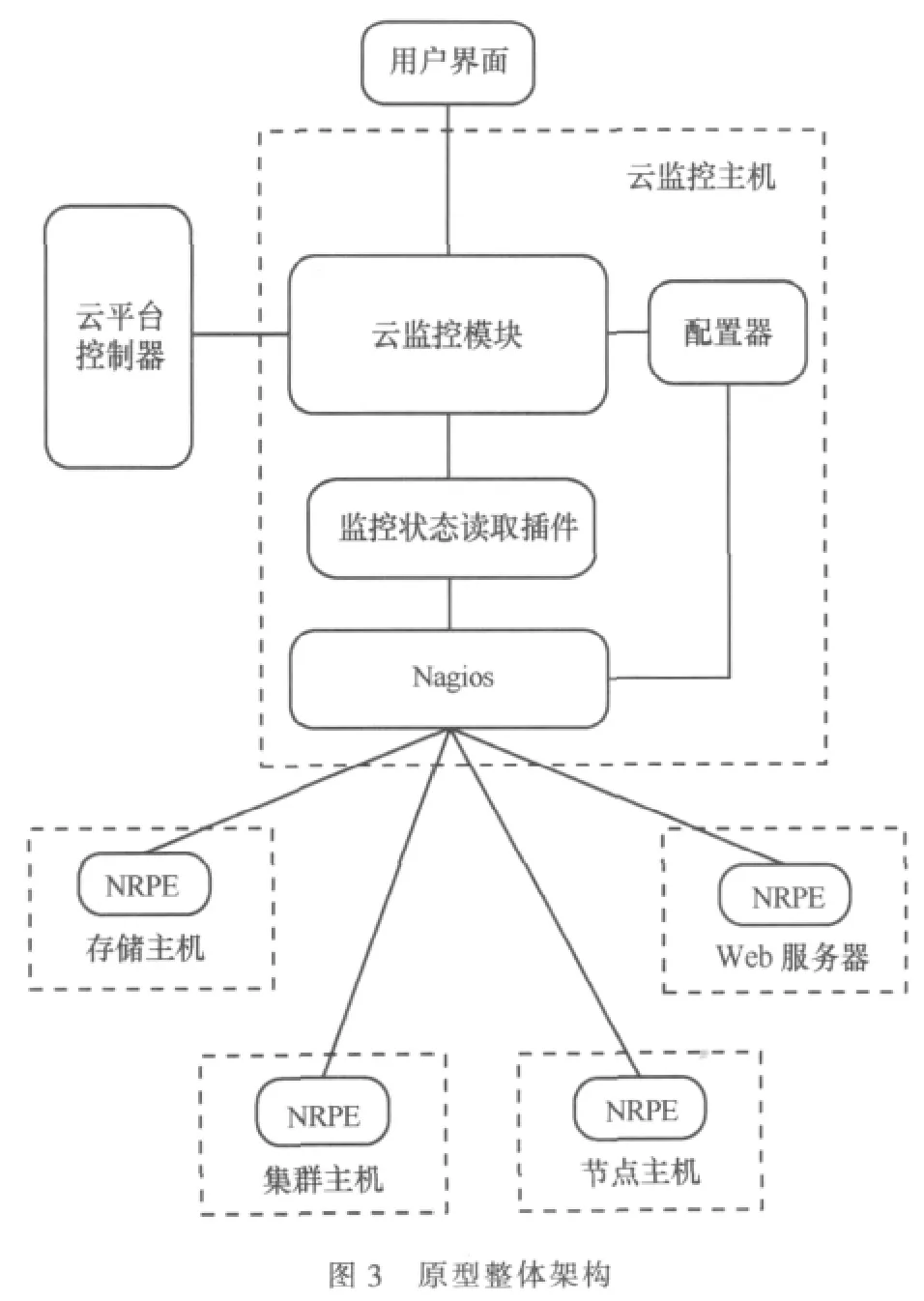
(3)通信方式
云監控模塊通過基類已實現的套接字(socket)接口與用戶界面和云平臺其他控制器進行通信。Nagios與其插件NRPE之間的通信則依靠SSL(secure sockets layer,安全套接字,是Netscape為保證網絡通信安全及數據完整性提出的一種安全網絡通信協議,SSL在傳輸層對網絡連接進行加密以實現通信安全)協議實現。
(4)云監控模塊與底層監控軟件的關系
出于可擴展性考慮,云監控模塊與底層監控軟件沒有包含或直接調用關系。二者的交互通過插件完成。如果需要用其他監控軟件代替現有的Nagios,云監控模塊將無需修改,僅針對新的監控軟件開發相關插件即可實現兼容。
(5)云監控模塊插件
云監控模塊通過相關插件與底層監控軟件交互。插件包括監控狀態讀取插件和配置器。監控狀態讀取插件用于讀取并規格化底層監控軟件監控數據。配置則用于配置底層監控軟件參數并重啟監控服務以應用改變。
4.2 云監控模塊架構設計
根據本文提出的生存性機制和§4.1中的分析設計,設計云監控模塊的基本運行流程,如圖4所示。
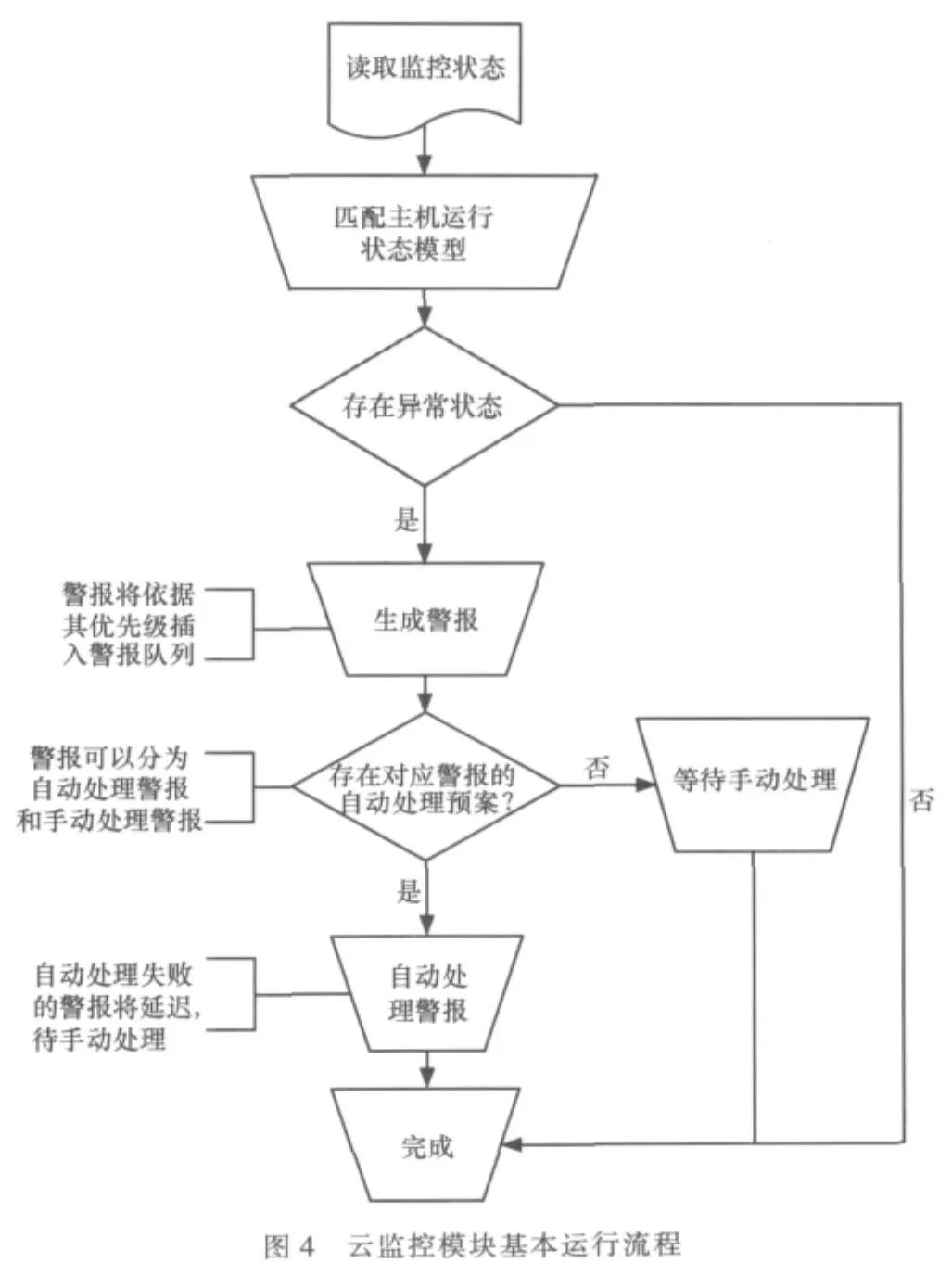
云監控運行流程分為以下幾個步驟。
(1)監控
通過控制第三方監控軟件遠程監控各個服務器,并生成狀態記錄。云監控模塊讀取監控狀態記錄。
(2)分析
分析監控數據,建模并匹配,對異常狀態生成警報,并通知維護人員。
(3)處理
嘗試依據警報自動處理預案處理警報。
(4)反饋
獲取自動處理結果,處理失敗的警報留待維護人員手動處理。維護人員手動處理后通過用戶界面通知云監控模塊。
警報處理預案一般分為以下幾個類型。
·向發生警報的主機發送對應指令,解決系統相關服務異常等問題。
·應用自動遷移策略,將運行于異常節點主機的虛擬機動態遷移[15]到正常運行的節點主機上。
·延遲處理警報,留待維護人員手動處理。
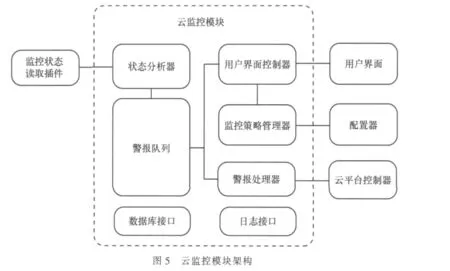
依據以上分析,設計云監控模塊架構如圖5所示。
對云監控模塊的各個子模塊功能分析如下。
(1)狀態分析器
監控循環中,從監控狀態文件讀取已規格化的監控數據,依據物理機類型生成運行狀態模型,與對應的正常狀態模型進行匹配,對匹配失敗的監控項生成警報,依據警報優先級將警報插入警報隊列。
(2)警報隊列
存儲現存的所有未處理警報,隊內警報按優先級降序排列,需手動處理的警報將被視為最低優先級警報并置于隊尾。
(3)用戶界面控制器
管理與用戶界面的交互,包括監控策略管理、警報管理和監控服務的啟動與停止。
(4)策略控制器
云監控模塊啟動時,調用數據庫接口讀取監控策略,并對云平臺不同類型的物理機分別建立正常狀態模型,監控策略變更時,更新數據庫和正常狀態模型,調用配置器配置并重啟底層監控軟件。
(5)警報處理器
從警報隊列依次取出警報,依據預置自動處理預案向其他云平臺控制器發送命令并獲取返回結果。分析返回結果,處理成功則從警報隊列刪除警報,處理失敗則更改警報類型和優先級,然后再次插入警報隊列,完成后調用數據庫接口更新數據庫。
(6)數據庫接口
管理數據庫操作。
(7)日志接口
對云監控模塊的所有關鍵操作進行日志記錄。
5 生存性機制原型的應用
本文提出的生存性機制的原型的具體應用和測試平臺為Vebula私有云基礎設施平臺。Vebula云計算基礎設施平臺是一個提供系統虛擬化、資源整合、按需提供虛擬化資源、安全驗證等服務的云計算解決方案。其核心架構如圖6所示。
Vebula私有云基礎設施平臺的核心架構主要分為以下幾個模塊。
(1)云控制器(cloud controller,CLC)
通過與Vebula Web進行交互,來接受和反饋用戶請求。負責云平臺的最高層統一調度。
(2)集群控制器(cluster controller,CC)
轉發CLC的事件請求,收集并上報集群信息,管理屬于本集群的節點控制器。
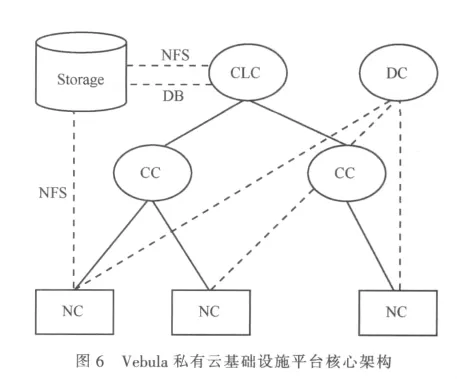

表2 可用性機制原型應用前后對比
(3)節點控制器(node controller,NC)
相應上層發出的事件請求,管理節點主機上運行的虛擬機(VM)和其他虛擬化資源,收集并上報節點主機及節點主機上運行的虛擬機信息。
(4)DHCP 控制器(DHCP controller,DC)
提供DHCP服務,管理云平臺的IP資源。
(5)存儲設備(storage)
存儲云平臺的內部數據,包括數據庫、虛擬機鏡像、用戶虛擬磁盤等。
下面,通過舉例若干個Vebula私有云基礎設施平臺可能發生的異常來對比說明應用本文提出的可用性機制原型前后,云平臺應對異常的情況。具體舉例見表2。
6 結束語
本文通過分析IaaS云計算平臺的生存性問題,確立了IaaS云計算平臺的生存性需求,并提出了基于虛擬資源遷移的生存性機制。在設計并實現了該生存性機制的原型后,將其整合進已有的Vebula私有云基礎設施平臺并進行了測試。
測試證明,該生存性機制原型能較好地應對系統異常和硬件異常。在出現發生部分可預期的異常的趨勢時,該原型能夠將虛擬機由可能發生異常的物理設備遷移到正常運行的物理設備。當異常已經發生時,該原型能夠在很短時間內監測到異常,并通過遷移、重啟系統服務等方式自動解決異常。當出現無法自動解決的異常時,該原型也能夠及時通過用戶界面以及第三方監控軟件提供的E-mail、短信等方式通知相關責任人手動解決異常,從而較好地保證了云服務的可用性,大大提升了云計算平臺的生存性。
在目前工作的基礎上,本文提出的生存性機制可以在攻擊檢測和攻擊避免方面進行擴展,通過整合IDS等第三方入侵檢測軟件并在生存性機制中加入應對外部攻擊的遷移策略,可以提升云計算平臺抵御外部攻擊的能力,進一步提升云計算平臺的生存性。
1 Peter Mell,Tim Grance,The NIST definition ofcloud computing,national institute of standards and technology,http://csrc.nist.gov/groups/SNS/cloud-computing/,2010
2 Salesforce,http://www.salesforce.com/,2011
3 Google App Engine,http://en.wikipedia.org/wiki/Google_App_Engine,2011
4 EC2,http://aws.amazon.com/ec2/,2011
5 Vsphere,http://communities.vmware.com/community/vmtn/vsphere,2011
6 Hollway B A,Neumman P G.Survivable computer-communication systems:the problem and working group recommendations,Washington:US Army Research Laboratory,1993
7 Ellison R J,Fisher D A,Linger R C,et al.Survivable network system:an emerging discipline,Tech ReportCMU/SEI-97-TR-013,Pittsburgh,Software Eng Inst,Carnegie Mellon Univ,1997
8 Irving Vitra Paputungan, Azween Abdullah. Survivability assessment:modeling a recovery process,seminarnasional aplikasi teknologi informasi,2007
9 Moore A P,Ellison R J,Linger R C.Attack modeling for information security and survivability,technicalnote CMU/SEI-2001-TN-001,2001
10 陳左寧.大規模計算機系統可信性技術的研究.高性能計算技術,2004(6)
11 Mead N R,Ellison R J,Linger R C,et al.Survivable network analysis method.Carnegie Mellon University,2000
12 Lin Xuegang,Xu Rongsheng,Zhu Miaoliang.Survivability computation of networked information systems.Computer Science,2005(3802):407~414
13 Intel開源軟件技術中心,復旦大學并行處理研究所.系統虛擬化—原理與實現.北京:清華大學出版社,2008
14 Nagios.http://www.nagios.org/,2011
15 Liu Pengcheng,Yang Ziye,Song Xiang,et al.Heterogeneous live migration ofvirtualmachines,internationalsymposium on computer architecture,2008
猜你喜歡
井岡教育(2022年2期)2022-10-14 03:11:44
中國特種設備安全(2022年6期)2022-09-20 02:52:28
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
電子制作(2018年11期)2018-08-04 03:26:08
商周刊(2017年9期)2017-08-22 02:57:56
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
工業設計(2016年12期)2016-04-16 02:52:00
